OpenAIGymで強化学習
OpenAIGymのFrozenLakeと、強化学習の一種であるQ学習を使って、簡単なスクリプトをPythonで実装したいと思います。
強化学習とQ学習
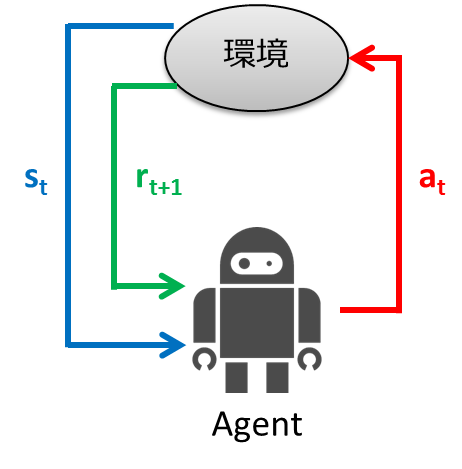
強化学習とは、実際に試行錯誤を行って最適解を求める学習モデルです。
引用 https://qiita.com/Hironsan/items/56f6c0b2f4cfd28dd906
ある環境s(t)においてエージエントが行動a(t)を行います。それによって報酬r(t+1)が得られ、この報酬を最大化するように最適解を求めます。
より詳しい理論の解説などはこちらのサイトをご覧くださいPythonではじめる強化学習
Pythonで実装するにあたり重要なのはこの式です。

Q学習では、まず数値を保存するためのQテーブルを作り、この式をもとに数値を更新していき、最適解を求めるといったイメージです。
FrozenLake
FrozenLakeはOpenAIGymで提供されているゲームの一つです。
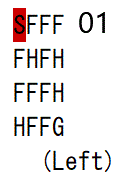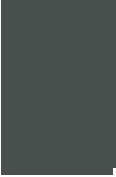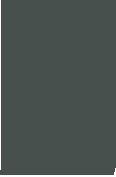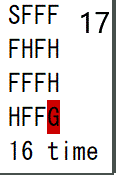
ルール
4×4の16マスで、S=スタート、F=凍った床、H=穴、G=ゴール(赤は今いる場所)。
穴に落ちずにスタートからゴールまで目指すゲームです。
このゲームでは、床が凍っているので進みたい方向に確実に進めるわけではありません。
進みたい方向へは1/3の確率でしか進めず、残り1/3ずつの確率で進む方向が90度変わります。
例えば、下を選択した場合、1/3で下に進み、1/3で右、1/3で左に進みます。
つまり、**行きたい方向を100%選ぶことはできないけど、行きたくない方向は100%選ぶことができます。**穴がある方向の逆を選択すれば、100%穴には落ちません。
報酬
デフォルトでは報酬は穴に落ちたら0、ゴールに着いたら1です。
Pythonで実装
では実際にpythonを使って実装していきたいと思います。
もし、OpenAIGymの使い方がうろ覚えな方は前回の記事をご覧くださいOpenAIGymの基本的な使い方
Qテーブル
まず、Q関数の数値を保存するためのQテーブルを作成します。
FrozenLakeではobservationが0~15までの16あります(例:observation=0がスタートS、observation=15がゴールG)。
actionは0(左)、1(下)、2(右)、3(上)の4つです。
なので、16×4のQテーブルをつくります。
import gym
import numpy as np
env=gym.make("FrozenLake-v0")
q_table=np.random.uniform(0,1,(16,4)) #q_tableを乱数で初期化
初期値は0~1までの一様乱数です。
行動a(t)を求める関数
ε-greedy法を用いて行動を決めます。
何の対策もせずに強化学習を行うと、一度最適(と思われる)解にハマった場合、二度とそこから抜け出せなくなります。
そこで、確率εでランダムな行動を行うことでこの問題を回避します。
人間でもそうですよね。ずっと正しいと思っていた方法を気まぐれで変えてみたら、もっと効率のいいやり方が見つかるとか。
# 行動a(t)を求める関数
def get_action(next_state,episode):
#徐々に最適行動のみをとる、ε-greedy法
epsilon=0.001
if epsilon<np.random.uniform(0,1):
next_action=np.argmax(q_table[next_state])
else:
next_action=np.random.randint(4)
return next_action
確率εでランダム行動し、確率1-εでQ関数が最大となるような行動をとります。
Qテーブルを更新する関数
上で説明した式をそのまま実装します。

# Qテーブルを更新する関数
def update_Qtable(q_table,state,action,reward,next_state):
gamma=0.99
alpha=0.3
q_table[state,action]=(1-alpha)*q_table[state,action]+\
alpha*(reward+gamma*max(q_table[next_state]))
return q_table
メインルーチン
10,000 episodes学習させます。
# パラメータ
max_number_steps=100 #1試行のstep数
num_episodes=10000 #総試行回数
# メインルーチン=====================================================
for episode in range(num_episodes):
state=env.reset()
action=np.argmax(q_table[state])
for t in range(max_number_steps):
#行動a_tの実行により、s_{t+1},r_{t+1}などを計算する
next_state,reward,done,_=env.step(action)
if done:
#ゴールしたとき
if next_state==15:
reward=100
#穴に落ちたか、時間切れになったとき
else:
reward=-10
#q_tableの更新
q_table=update_Qtable(q_table,state,action,reward,next_state)
#次の行動a_{t+1}を求め、状態s_{t+1}に遷移する
action=get_action(next_state,episode)
state=next_state
if done:
break
#途中経過の表示
if (episode+1)%100==0:
print("{} episodes finished".format(episode+1))
env.reset()で環境をリセットし、action=np.argmax(q_table[state])でQ関数が最大の値となる行動をとります。
その後、env.step(action)で実際に行動し、次の状態や報酬next_state,rewardを得ます。
if done:はゲームが終了したときです(穴に落ちる、ゴールする、時間切れのどれか)
それらを用いてQテーブルを更新し、q_table=update_Qtable(q_table,state,action,reward,next_state)
次の行動を求め、次の状態に移行します。
action=get_action(next_state,episode)
state=next_state
学習したQ関数を使ってテスト
強化学習によって得られたQ関数を使って1,000 episodesテストします。
test_num_episodes=1000 #テストの総試行回数
# 学習したQ関数を使ってテスト
for episode in range(test_num_episodes):
state=env.reset()
env.render()
for t in range(max_number_steps):
action=np.argmax(q_table[state])
state,reward,done,_=env.step(action)
total_reward+=reward
env.render()
if done:
print("{} time steps finished".format(t+1))
break
# テスト結果
print("\n q_table=\n",q_table)
print("\n average_reward=",total_reward/test_num_episodes)
完成したスクリプト
最後に完成したスクリプトをすべて載せておきます。
import gym
import numpy as np
# パラメータ設定
env=gym.make("FrozenLake-v0")
max_number_steps=100 #1試行のstep数
num_episodes=10000 #総試行回数
test_num_episodes=1000 #テストの総試行回数
q_table=np.random.uniform(0,1,(16,4)) #q_tableを乱数で初期化
total_reward=0
# 行動a(t)を求める関数
def get_action(next_state,episode):
#徐々に最適行動のみをとる、ε-greedy法
epsilon=0.001
if epsilon<np.random.uniform(0,1):
next_action=np.argmax(q_table[next_state])
else:
next_action=np.random.randint(4)
return next_action
# Qテーブルを更新する関数
def update_Qtable(q_table,state,action,reward,next_state):
gamma=0.99
alpha=0.3
q_table[state,action]=(1-alpha)*q_table[state,action]+\
alpha*(reward+gamma*max(q_table[next_state]))
return q_table
# メインルーチン=====================================================
for episode in range(num_episodes):
state=env.reset()
action=np.argmax(q_table[state])
for t in range(max_number_steps):
#行動a_tの実行により、s_{t+1},r_{t+1}などを計算する
next_state,reward,done,_=env.step(action)
if done:
#ゴールしたとき
if next_state==15:
reward=100
#穴に落ちたか、時間切れになったとき
else:
reward=-10
#q_tableの更新
q_table=update_Qtable(q_table,state,action,reward,next_state)
#次の行動a_{t+1}を求め、状態s_{t+1}に遷移する
action=get_action(next_state,episode)
state=next_state
if done:
break
#途中経過の表示
if (episode+1)%100==0:
print("{} episodes finished".format(episode+1))
# 学習したQ関数を使ってテスト
for episode in range(test_num_episodes):
state=env.reset()
env.render()
for t in range(max_number_steps):
action=np.argmax(q_table[state])
state,reward,done,_=env.step(action)
total_reward+=reward
#env.render()
if done:
print("{} time steps finished".format(t+1))
break
# テスト結果
print("\n q_table=\n",q_table)
print("\n average_reward=",total_reward/test_num_episodes)
q_table_max=[]
for i in range(16):
q_table_max.append(np.argmax(q_table[i]))
print("\n q_table_max=",q_table_max)
結果

だいたいaverage_rewardは0.70~0.75あたりになると思います。
Q学習によって70~75%の確率でゴールできるようになりました。
ただ、ブレるのでもっと低くなるときもあるかもしれません。
このQテーブルでactionの最大値をそれぞれ取ってみます。
q_table_max=[]
for i in range(16):
q_table_max.append(np.argmax(q_table[i]))
print("\n q_table_max=",q_table_max)
q_table_max=[0, 3, 3, 3, 0, 2, 2, 0, 3, 1, 0, 3, 2, 2, 1, 2]
となります。これは4×4のマスのなかで、
左上上上
左右右左
上下左上
右右下右
と動くことにより、70~75%の確率でゴールできるということです。