これはcloudpack あら便利カレンダー 2018の記事です。
追記
2019/09/20
v0.9.1で動作させる方法をまとめました。
MacでUnity ML-Agentsの環境を構築する(v0.9.1対応) - Qiita
https://qiita.com/kai_kou/items/268ccf6f961f8ca8cba8
2019/04/05
2019/02/28にML-Agentsのv0.7.0がリリースされました。
@kingyo222 さんが利用手順をまとめてくれています。(Win)
Unity:ML-Agents 2019年04月(ver0.7.0)での使い方 – 初心者向けUnity情報サイト
https://www.fast-system.jp/unity%ef%bc%9aml-agents-2019%e5%b9%b404%e6%9c%88ver0-7-0%e3%81%a7%e3%81%ae%e4%bd%bf%e3%81%84%e6%96%b9/
2018/12/26
2018/12/15にML-Agentsのv0.6.0がリリースされました。
MacでUnity ML-Agentsの環境を構築する(v0.6.0対応) - Qiita
https://qiita.com/kai_kou/items/2a6545d1f9d83178d0c0
2018/09/13
記事投稿時はバージョンが0.4.0でしたが、2018/09/11にバージョン0.5.0がリリースされたので、0.4.0と0.5.0の手順を併記するようにしました。(2018/09/13)
概要
Unityで機械学習ができると聞いて試してみたくなり、環境をつくってみました。
参考)
【Unity】Unityで機械学習する「ML-Agent」を色々と試して得た知見とか
http://tsubakit1.hateblo.jp/entry/2018/02/18/233000
Unityをまだインストールしていないという方は下記をご参考ください。
Macでhomebrewを使ってUnityをインストールする(Unity Hub、日本語化対応)
https://qiita.com/kai_kou/items/445e614fb71f2204e033
手順
基本的には公式のドキュメントに沿えばよい感じです。
Unity-Technologies/ml-agents/docs/Installation.md
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Installation.md
Pythonをインストールする
Python 3.5または3.6が必要だそうなので、お手元に環境がない方は下記ご参照
現在、Python 3.6での動作がサポートされているそうです(2018/09/13現在)
We do not currently support Python 3.7 or Python 3.5.
お手元に環境がない方は下記をご参照ください。
https://qiita.com/kai_kou/items/f54931991a781b96bb9c
ML-Agentsリポジトリをダウンロード
適当なディレクトリにリポジトリをダウンロードする。
> mkdir 適当なディレクトリ
> cd 適当なディレクトリ
> git clone https://github.com/Unity-Technologies/ml-agents.git
必要なライブラリをインストールする
TensorFlowなどを利用するみたいなので、pipを利用してインストールします。
ここではPythonの仮想環境を作ってインストールします。
仮想環境?なにそれ?な方は下記をご参照(再掲
https://qiita.com/kai_kou/items/f54931991a781b96bb9c
> cd 適当なディレクトリ
> pyenv local 3.6.6
> python -m venv venv
> . venv/bin/activate
> cd ml-agents
# fishな方は下記
> . venv/bin/activate.fish
v0.5.0からディレクトリ構成が変更になり、python フォルダがml-agents に名称変更されています。
# v0.5.0からディレクトリ構成が変わったのでこちら
> cd 適当なディレクトリ/ml-agents/ml-agents
# v0.4.0はこちら
# > cd 適当なディレクトリ/ml-agents/python
> pip install .
Processing 適当なディレクトリ/ml-agents/ml-agents
Collecting tensorflow<1.8,>=1.7 (from mlagents==0.5.0)
(略)
Successfully installed MarkupSafe-1.0 Pillow-5.2.0 Send2Trash-1.5.0 absl-py-0.4.1 appnope-0.1.0 astor-0.7.1 atomicwrites-1.2.1 attrs-18.2.0 backcall-0.1.0 bleach-1.5.0 cycler-0.10.0 decorator-4.3.0 defusedxml-0.5.0 docopt-0.6.2 entrypoints-0.2.3 gast-0.2.0 grpcio-1.11.1 html5lib-0.9999999 ipykernel-4.9.0 ipython-6.5.0 ipython-genutils-0.2.0 ipywidgets-7.4.1 jedi-0.12.1 jinja2-2.10 jsonschema-2.6.0 jupyter-1.0.0 jupyter-client-5.2.3 jupyter-console-5.2.0 jupyter-core-4.4.0 kiwisolver-1.0.1 markdown-2.6.11 matplotlib-2.2.3 mistune-0.8.3 mlagents-0.5.0 more-itertools-4.3.0 nbconvert-5.4.0 nbformat-4.4.0 notebook-5.6.0 numpy-1.14.5 pandocfilters-1.4.2 parso-0.3.1 pexpect-4.6.0 pickleshare-0.7.4 pluggy-0.7.1 prometheus-client-0.3.1 prompt-toolkit-1.0.15 protobuf-3.6.1 ptyprocess-0.6.0 py-1.6.0 pygments-2.2.0 pyparsing-2.2.0 pytest-3.8.0 python-dateutil-2.7.3 pytz-2018.5 pyyaml-3.13 pyzmq-17.1.2 qtconsole-4.4.1 simplegeneric-0.8.1 six-1.11.0 tensorboard-1.7.0 tensorflow-1.7.1 termcolor-1.1.0 terminado-0.8.1 testpath-0.3.1 tornado-5.1 traitlets-4.3.2 wcwidth-0.1.7 werkzeug-0.14.1 wheel-0.31.1 widgetsnbextension-3.4.1
はい。
v0.4.0時点でのpip install . 時のログも置いておきます。
Processing 適当なディレクトリ/ml-agents/python
Collecting tensorflow==1.7.1 (from unityagents==0.4.0)
(略)
Successfully installed MarkupSafe-1.0 Pillow-5.2.0 Send2Trash-1.5.0 absl-py-0.3.0 appnope-0.1.0 astor-0.7.1 atomicwrites-1.1.5 attrs-18.1.0backcall-0.1.0 bleach-1.5.0 cycler-0.10.0 decorator-4.3.0 docopt-0.6.2 entrypoints-0.2.3 gast-0.2.0 grpcio-1.11.0 html5lib-0.9999999 ipykernel-4.8.2 ipython-6.4.0 ipython-genutils-0.2.0 ipywidgets-7.3.1 jedi-0.12.1 jinja2-2.10 jsonschema-2.6.0 jupyter-1.0.0 jupyter-client-5.2.3 jupyter-console-5.2.0 jupyter-core-4.4.0 kiwisolver-1.0.1 markdown-2.6.11 matplotlib-2.2.2 mistune-0.8.3 more-itertools-4.2.0 nbconvert-5.3.1 nbformat-4.4.0 notebook-5.6.0 numpy-1.15.0 pandocfilters-1.4.2 parso-0.3.1 pexpect-4.6.0 pickleshare-0.7.4 pluggy-0.6.0 prometheus-client-0.3.0 prompt-toolkit-1.0.15 protobuf-3.5.2 ptyprocess-0.6.0 py-1.5.4 pygments-2.2.0 pyparsing-2.2.0 pytest-3.6.3 python-dateutil-2.7.3 pytz-2018.5 pyyaml-3.13 pyzmq-17.1.0 qtconsole-4.3.1 simplegeneric-0.8.1 six-1.11.0 tensorboard-1.7.0 tensorflow-1.7.1 termcolor-1.1.0 terminado-0.8.1 testpath-0.3.1 tornado-5.1 traitlets-4.3.2 unityagents-0.4.0 wcwidth-0.1.7 werkzeug-0.14.1 wheel-0.31.1 widgetsnbextension-3.3.1
動かしてみる
引き続き、公式のドキュメントに沿って実際に動かして見ます。
Using an Environment Executable
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Executable.md
Installationから進むと下記ガイドへ自然と進んでしまうのですが、上記のほうが、お試しするには罠が少なかったです。(1敗)
Basic Guide
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Basic-Guide.md
Unityの起動とプロジェクトファイル読み込み
Unityを立ち上げます。
アプリが立ち上がったら「開く」ボタンからml-agentsの以下フォルダを選択します。

v0.5.0からディレクトリ構成が変更されたようです。
- v0.5.0
- ml-agents\UnitySDK
- v0.4.0
- ml-agents\unity-environment
Unityエディタのバージョンによって、再インポートするか、確認ダイアログが立ち上がります。
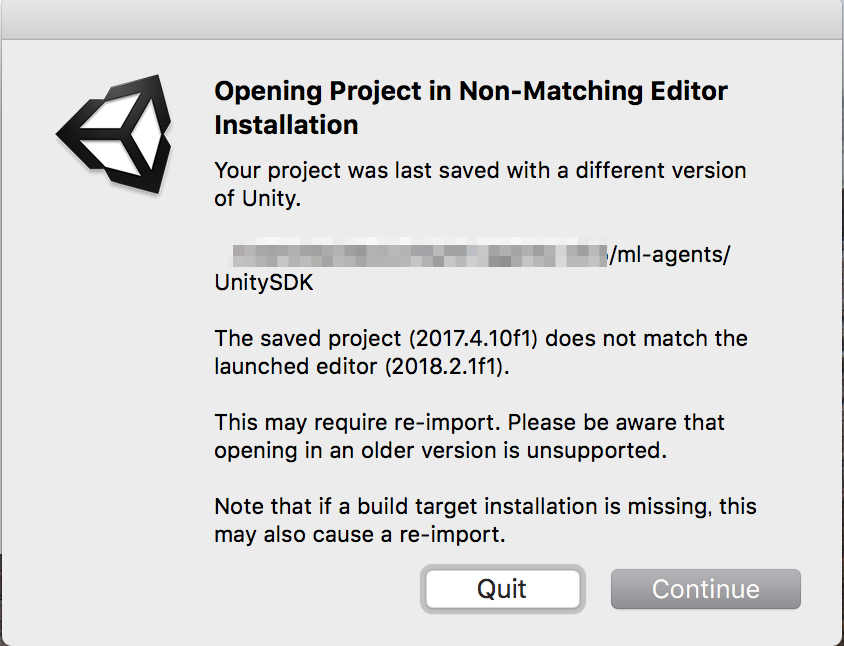
「Continue(続行)」ボタンをクリックして進めます。
再インポート処理すると初回、プロジェクトが開くまでに時間がかかります。

起動しました。
Scenes(シーン)が開くか確認する
サンプルが動作するか、Unityでプロジェクトを読み込み、動作させてみます。
参考)
Unityの公式サンプルml-agentsでAIを試す
http://am1tanaka.hatenablog.com/entry/2017/11/08/230525
- Unityの下パネルにある[Project]タブから以下のフォルダまで開く。
- [Assets] > [ML-Agents] > [Examples] > [3DBall] > [Scenes]
- 開いたら、[3DBall]ファイルがあるので、ダブルクリックして開く。

なんかでてきたー(感動)
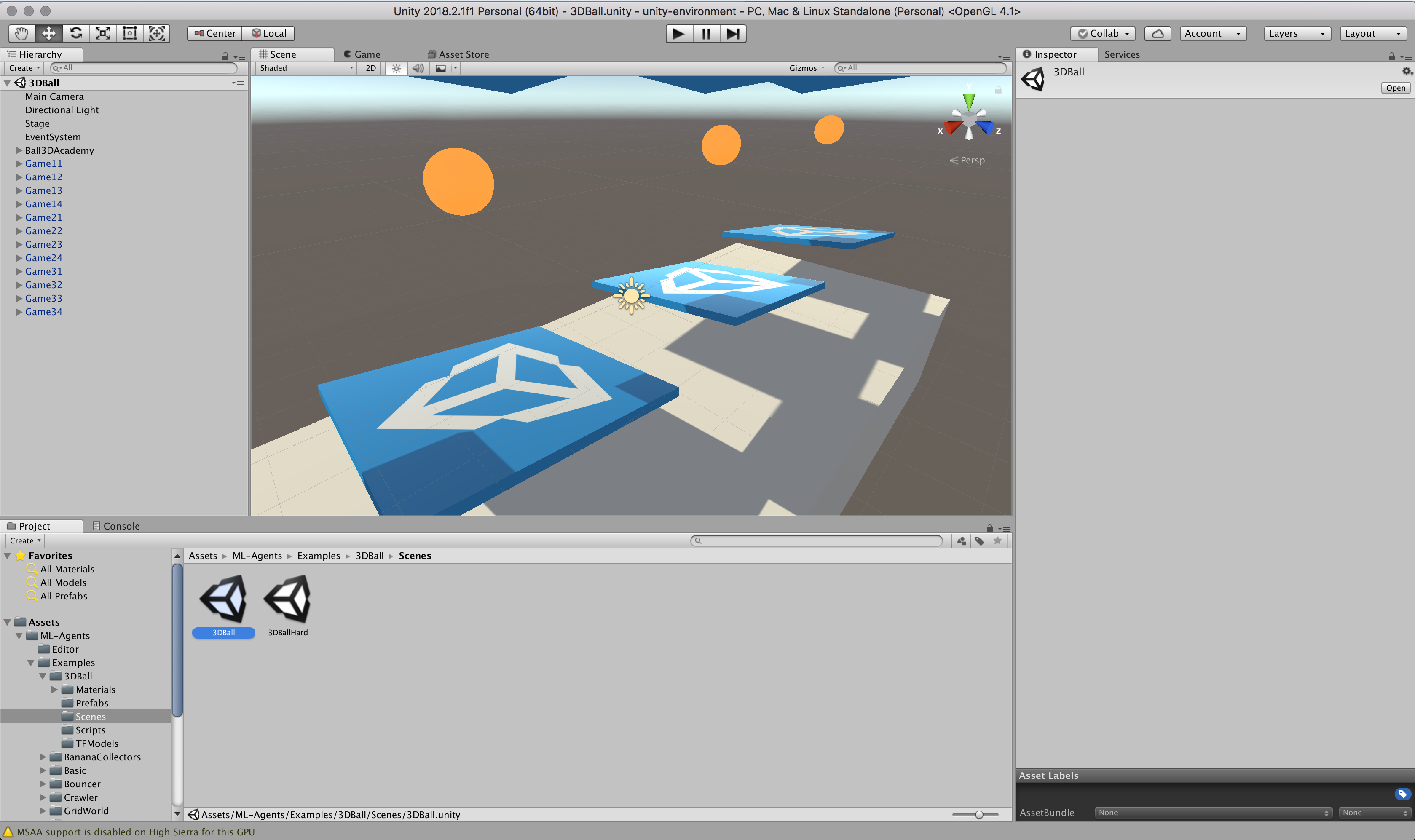
Unityの上にある再生ボタンをクリックします。
なんかうごいたー(感動)
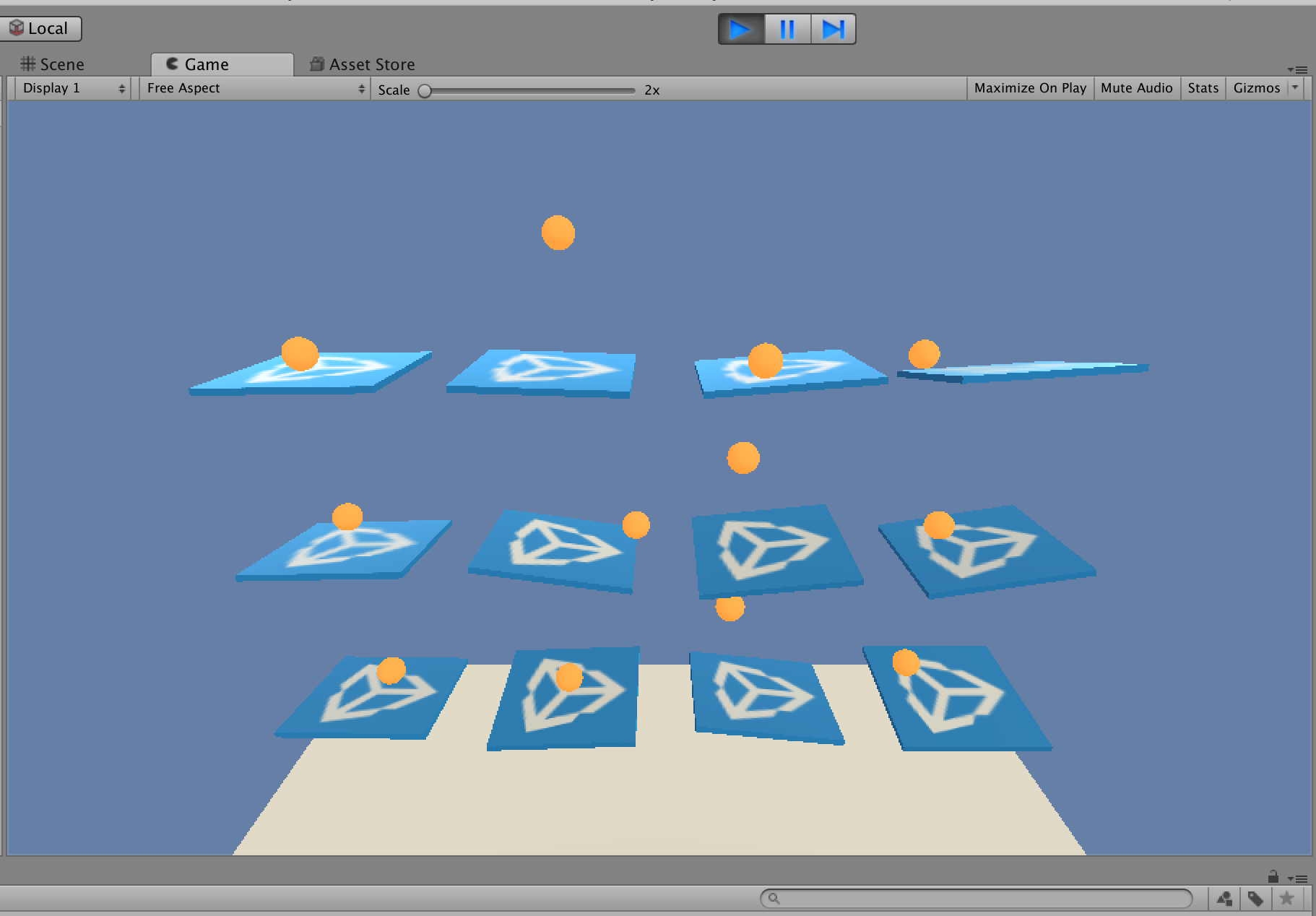
読み込んだサンプルが動作することが確認できました。
現時点ではボールが板からすぐに落ちてしまいます。これを機械学習させて、落とさないようにするわけです。
Scenes(シーン)の設定
ML-Agentsで学習させるための設定です。
- Unityの[Edit]メニューから[Project Settings] > [Player]を開く

- [Inspector]ビューで以下の設定を確認する。
- [Resolution and Presentation]の[Run In Background]がチェックされている
- [Display Resolution Dialog]がDisableになっている

- [Hierarchy]ビューから[Ball3DAcademy] > [Ball3DBrain]を開く
- [Inspector]ビューで[Brain Type]を[External]に変更する

- [Ctrl] + [s]キーでシーンを保存する
設定変更後、しっかりと保存しないとビルド時に設定が反映されなくてハマります。(1敗)
ビルド
- [File]メニューから[Build Settings]を選択する
- [Build Settings]ダイアログで[Platform]で[PC, Mac & Linux Standalone]が選択されていることを確認する
- [Build Settings]ダイアログで[Build]ボタンをクリックする
-
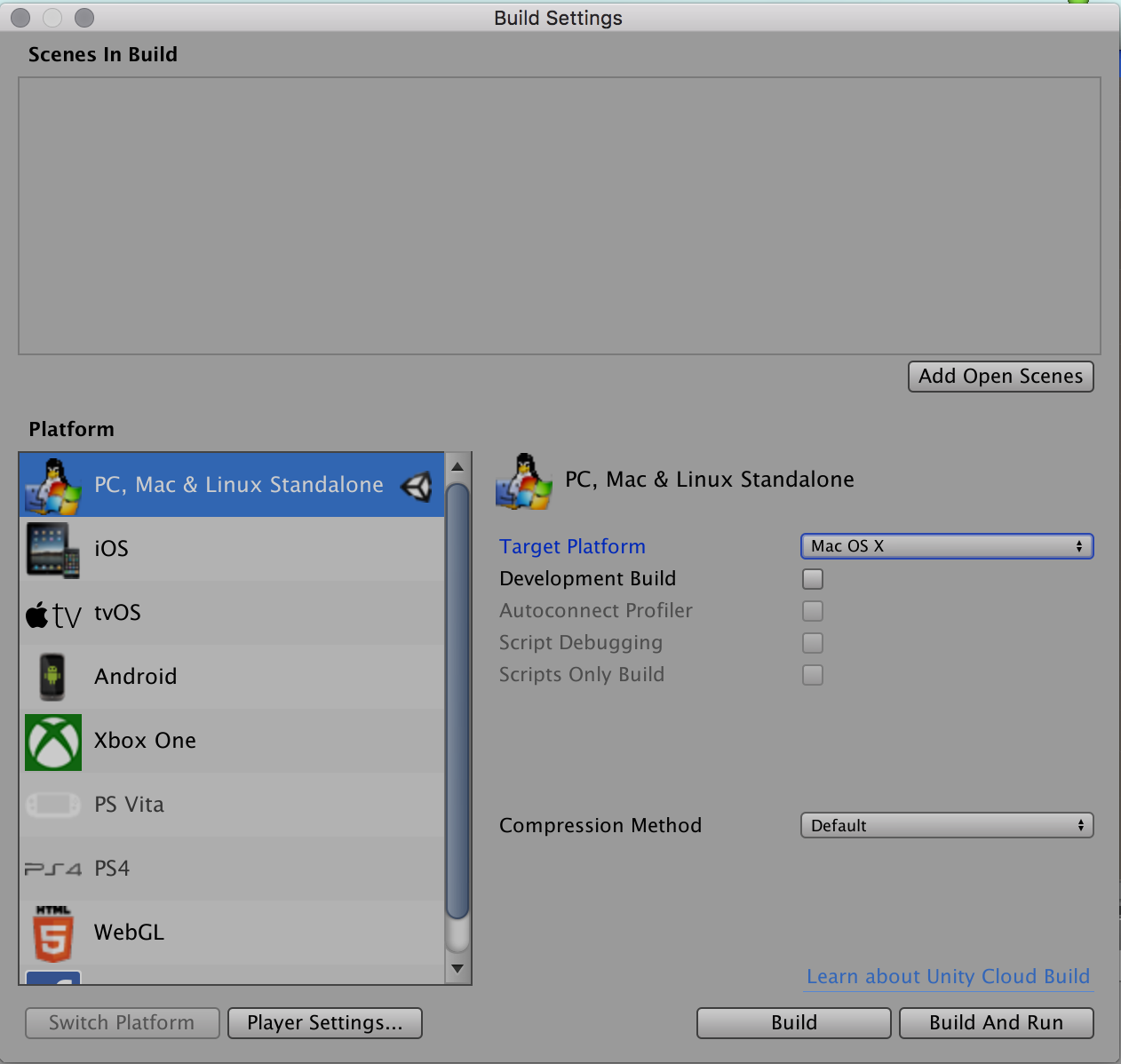
- ファイル保存ダイアログで以下を指定してビルドする
- v0.5
- ml-agents\ml-agents\3DBall.app
- v0.4
- ml-agents\python\3DBall.app
- v0.5
学習の実行
ターミナルで以下を実行して、学習を開始します。
実行時にビルドしたAppが起動して学習が開始されます。
trainer_config.yamlのmax_steps で指定されているステップ数が完了するか、ctrl+cキーで学習が終了します。
v0.5.0から学習開始のコマンドが変更されたようです。
- v0.5.0
mlagents-learn
- v0.4.0
python learn.py
# ../config/trainer_config.yaml: ハイパーパラメータ指定ファイル
# 3DBall: 出力したapp名(拡張子なし)
# firstRun: 実行ごとに結果が保存されるので、名称をつける(任意)
> mlagents-learn ../config/trainer_config.yaml --env=3DBall --run-id=firstRun --train
▄▄▄▓▓▓▓
╓▓▓▓▓▓▓█▓▓▓▓▓
,▄▄▄m▀▀▀' ,▓▓▓▀▓▓▄ ▓▓▓ ▓▓▌
▄▓▓▓▀' ▄▓▓▀ ▓▓▓ ▄▄ ▄▄ ,▄▄ ▄▄▄▄ ,▄▄ ▄▓▓▌▄ ▄▄▄ ,▄▄
▄▓▓▓▀ ▄▓▓▀ ▐▓▓▌ ▓▓▌ ▐▓▓ ▐▓▓▓▀▀▀▓▓▌ ▓▓▓ ▀▓▓▌▀ ^▓▓▌ ╒▓▓▌
▄▓▓▓▓▓▄▄▄▄▄▄▄▄▓▓▓ ▓▀ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▄ ▓▓▌
▀▓▓▓▓▀▀▀▀▀▀▀▀▀▀▓▓▄ ▓▓ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▐▓▓
^█▓▓▓ ▀▓▓▄ ▐▓▓▌ ▓▓▓▓▄▓▓▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▓▄ ▓▓▓▓`
'▀▓▓▓▄ ^▓▓▓ ▓▓▓ └▀▀▀▀ ▀▀ ^▀▀ `▀▀ `▀▀ '▀▀ ▐▓▓▌
▀▀▀▀▓▄▄▄ ▓▓▓▓▓▓, ▓▓▓▓▀
`▀█▓▓▓▓▓▓▓▓▓▌
¬`▀▀▀█▓
INFO:mlagents.trainers:{'--curriculum': 'None',
'--docker-target-name': 'None',
'--env': '3DBall',
'--help': False,
'--keep-checkpoints': '5',
'--lesson': '0',
'--load': False,
'--no-graphics': False,
'--num-runs': '1',
'--run-id': 'firstRun',
'--save-freq': '50000',
'--seed': '-1',
'--slow': False,
'--train': True,
'--worker-id': '0',
'<trainer-config-path>': '../config/trainer_config.yaml'}
CrashReporter: initialized
Mono path[0] = '/Users/kai/dev/unity/ml-agents-v0.5/ml-agents/ml-agents/3DBall.app/Contents/Resources/Data/Managed'
Mono config path = '/Users/kai/dev/unity/ml-agents-v0.5/ml-agents/ml-agents/3DBall.app/Contents/MonoBleedingEdge/etc'
INFO:mlagents.envs:
'Ball3DAcademy' started successfully!
Unity Academy name: Ball3DAcademy
Number of Brains: 1
Number of External Brains : 1
Reset Parameters :
Unity brain name: Ball3DBrain
Number of Visual Observations (per agent): 0
Vector Observation space size (per agent): 8
Number of stacked Vector Observation: 1
Vector Action space type: continuous
Vector Action space size (per agent): [2]
Vector Action descriptions: ,
2018-09-13 11:04:05.526598: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
INFO:mlagents.envs:Hyperparameters for the PPO Trainer of brain Ball3DBrain:
batch_size: 64
beta: 0.001
buffer_size: 12000
epsilon: 0.2
gamma: 0.995
hidden_units: 128
lambd: 0.99
learning_rate: 0.0003
max_steps: 5.0e4
normalize: True
num_epoch: 3
num_layers: 2
time_horizon: 1000
sequence_length: 64
summary_freq: 1000
use_recurrent: False
graph_scope:
summary_path: ./summaries/firstRun-0
memory_size: 256
use_curiosity: False
curiosity_strength: 0.01
curiosity_enc_size: 128
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 1000. Mean Reward: 1.163. Std of Reward: 0.703. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 2000. Mean Reward: 1.252. Std of Reward: 0.675. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 3000. Mean Reward: 1.426. Std of Reward: 0.822. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 4000. Mean Reward: 1.738. Std of Reward: 0.979. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 5000. Mean Reward: 2.171. Std of Reward: 1.435. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 6000. Mean Reward: 3.092. Std of Reward: 2.115. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 7000. Mean Reward: 5.216. Std of Reward: 4.223. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 8000. Mean Reward: 8.289. Std of Reward: 7.247. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 9000. Mean Reward: 14.327. Std of Reward: 16.329. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 10000. Mean Reward: 20.652. Std of Reward: 21.575. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 11000. Mean Reward: 31.991. Std of Reward: 30.879. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 12000. Mean Reward: 69.667. Std of Reward: 34.240. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 13000. Mean Reward: 69.212. Std of Reward: 30.811. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 14000. Mean Reward: 96.167. Std of Reward: 9.023. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 15000. Mean Reward: 84.800. Std of Reward: 32.185. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 16000. Mean Reward: 75.419. Std of Reward: 36.776. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 17000. Mean Reward: 62.006. Std of Reward: 37.141. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 18000. Mean Reward: 67.176. Std of Reward: 37.284. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 19000. Mean Reward: 62.800. Std of Reward: 38.609. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 20000. Mean Reward: 77.593. Std of Reward: 34.332. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 21000. Mean Reward: 57.233. Std of Reward: 38.476. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 22000. Mean Reward: 93.675. Std of Reward: 20.978. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 23000. Mean Reward: 84.953. Std of Reward: 31.018. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 24000. Mean Reward: 70.656. Std of Reward: 38.178. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 25000. Mean Reward: 97.483. Std of Reward: 5.971. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 26000. Mean Reward: 75.956. Std of Reward: 31.658. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 27000. Mean Reward: 83.686. Std of Reward: 29.105. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 28000. Mean Reward: 70.971. Std of Reward: 40.723. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 29000. Mean Reward: 68.047. Std of Reward: 37.695. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 30000. Mean Reward: 79.062. Std of Reward: 32.291. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 31000. Mean Reward: 95.692. Std of Reward: 14.922. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 32000. Mean Reward: 85.615. Std of Reward: 29.706. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 33000. Mean Reward: 95.538. Std of Reward: 11.622. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 34000. Mean Reward: 77.938. Std of Reward: 34.877. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 35000. Mean Reward: 86.019. Std of Reward: 28.801. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 36000. Mean Reward: 70.865. Std of Reward: 37.673. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 37000. Mean Reward: 70.993. Std of Reward: 38.820. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 38000. Mean Reward: 94.583. Std of Reward: 12.756. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 39000. Mean Reward: 88.071. Std of Reward: 29.266. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 40000. Mean Reward: 81.744. Std of Reward: 33.346. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 41000. Mean Reward: 92.908. Std of Reward: 16.905. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 42000. Mean Reward: 92.423. Std of Reward: 24.867. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 43000. Mean Reward: 93.900. Std of Reward: 20.231. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 44000. Mean Reward: 81.671. Std of Reward: 34.627. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 45000. Mean Reward: 99.733. Std of Reward: 0.884. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 46000. Mean Reward: 83.680. Std of Reward: 34.004. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 47000. Mean Reward: 94.323. Std of Reward: 19.665. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 48000. Mean Reward: 83.192. Std of Reward: 27.346. Training.
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 49000. Mean Reward: 79.593. Std of Reward: 31.094. Training.
INFO:mlagents.envs:Saved Model
INFO:mlagents.trainers: firstRun-0: Ball3DBrain: Step: 50000. Mean Reward: 83.050. Std of Reward: 33.231. Training.
INFO:mlagents.envs:Saved Model
INFO:mlagents.envs:List of nodes to export :
INFO:mlagents.envs: action
INFO:mlagents.envs: value_estimate
INFO:mlagents.envs: action_probs
INFO:mlagents.envs: value_estimate
INFO:tensorflow:Restoring parameters from ./models/firstRun-0/model-50001.cptk
INFO:tensorflow:Froze 16 variables.
Converted 16 variables to const ops.
# 3DBall: 出力したapp名(拡張子なし)
# firstRun: 実行ごとに結果が保存されるので、名称をつける(任意)
> python3 learn.py 3DBall --run-id=firstRun --train
▄▄▄▓▓▓▓
╓▓▓▓▓▓▓█▓▓▓▓▓
,▄▄▄m▀▀▀' ,▓▓▓▀▓▓▄ ▓▓▓ ▓▓▌
▄▓▓▓▀' ▄▓▓▀ ▓▓▓ ▄▄ ▄▄ ,▄▄ ▄▄▄▄ ,▄▄ ▄▓▓▌▄ ▄▄▄ ,▄▄
▄▓▓▓▀ ▄▓▓▀ ▐▓▓▌ ▓▓▌ ▐▓▓ ▐▓▓▓▀▀▀▓▓▌ ▓▓▓ ▀▓▓▌▀ ^▓▓▌ ╒▓▓▌
▄▓▓▓▓▓▄▄▄▄▄▄▄▄▓▓▓ ▓▀ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▄ ▓▓▌
▀▓▓▓▓▀▀▀▀▀▀▀▀▀▀▓▓▄ ▓▓ ▓▓▌ ▐▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▌ ▐▓▓▐▓▓
^█▓▓▓ ▀▓▓▄ ▐▓▓▌ ▓▓▓▓▄▓▓▓▓ ▐▓▓ ▓▓▓ ▓▓▓ ▓▓▓▄ ▓▓▓▓`
'▀▓▓▓▄ ^▓▓▓ ▓▓▓ └▀▀▀▀ ▀▀ ^▀▀ `▀▀ `▀▀ '▀▀ ▐▓▓▌
▀▀▀▀▓▄▄▄ ▓▓▓▓▓▓, ▓▓▓▓▀
`▀█▓▓▓▓▓▓▓▓▓▌
¬`▀▀▀█▓
INFO:unityagents:{'--curriculum': 'None',
'--docker-target-name': 'Empty',
'--help': False,
'--keep-checkpoints': '5',
'--lesson': '0',
'--load': False,
'--no-graphics': False,
'--run-id': 'firstRun',
'--save-freq': '50000',
'--seed': '-1',
'--slow': False,
'--train': True,
'--worker-id': '0',
'<env>': '3DBall'}
CrashReporter: initialized
Mono path[0] = '適当なディレクトリ/ml-agents/python/3DBall.app/Contents/Resources/Data/Managed'
Mono config path = '適当なディレクトリ/ml-agents/python/3DBall.app/Contents/MonoBleedingEdge/etc'
INFO:unityagents:
'Ball3DAcademy' started successfully!
Unity Academy name: Ball3DAcademy
Number of Brains: 1
Number of External Brains : 1
Lesson number : 0
Reset Parameters :
Unity brain name: Ball3DBrain
Number of Visual Observations (per agent): 0
Vector Observation space type: continuous
Vector Observation space size (per agent): 8
Number of stacked Vector Observation: 1
Vector Action space type: continuous
Vector Action space size (per agent): 2
Vector Action descriptions: ,
INFO:unityagents:Hyperparameters for the PPO Trainer of brain Ball3DBrain:
batch_size: 64
beta: 0.001
buffer_size: 12000
epsilon: 0.2
gamma: 0.995
hidden_units: 128
lambd: 0.99
learning_rate: 0.0003
max_steps: 5.0e4
normalize: True
num_epoch: 3
num_layers: 2
time_horizon: 1000
sequence_length: 64
summary_freq: 1000
use_recurrent: False
graph_scope:
summary_path: ./summaries/firstRun
memory_size: 256
use_curiosity: False
curiosity_strength: 0.01
curiosity_enc_size: 128
INFO:unityagents: Ball3DBrain: Step: 1000. Mean Reward: 1.293. Std of Reward: 0.742.
INFO:unityagents: Ball3DBrain: Step: 2000. Mean Reward: 1.345. Std of Reward: 0.802.
INFO:unityagents: Ball3DBrain: Step: 3000. Mean Reward: 1.592. Std of Reward: 1.001.
INFO:unityagents: Ball3DBrain: Step: 4000. Mean Reward: 2.028. Std of Reward: 1.306.
INFO:unityagents: Ball3DBrain: Step: 5000. Mean Reward: 3.289. Std of Reward: 2.465.
INFO:unityagents: Ball3DBrain: Step: 6000. Mean Reward: 5.163. Std of Reward: 4.913.
INFO:unityagents: Ball3DBrain: Step: 7000. Mean Reward: 9.106. Std of Reward: 10.157.
INFO:unityagents: Ball3DBrain: Step: 8000. Mean Reward: 17.119. Std of Reward: 17.467.
INFO:unityagents: Ball3DBrain: Step: 9000. Mean Reward: 41.421. Std of Reward: 28.326.
INFO:unityagents: Ball3DBrain: Step: 10000. Mean Reward: 48.120. Std of Reward: 34.576.
INFO:unityagents: Ball3DBrain: Step: 11000. Mean Reward: 72.271. Std of Reward: 33.733.
INFO:unityagents: Ball3DBrain: Step: 12000. Mean Reward: 69.794. Std of Reward: 34.551.
INFO:unityagents: Ball3DBrain: Step: 13000. Mean Reward: 95.523. Std of Reward: 15.509.
INFO:unityagents: Ball3DBrain: Step: 14000. Mean Reward: 92.423. Std of Reward: 26.247.
INFO:unityagents: Ball3DBrain: Step: 15000. Mean Reward: 76.550. Std of Reward: 35.733.
INFO:unityagents: Ball3DBrain: Step: 16000. Mean Reward: 81.850. Std of Reward: 29.841.
INFO:unityagents: Ball3DBrain: Step: 17000. Mean Reward: 69.775. Std of Reward: 32.864.
INFO:unityagents: Ball3DBrain: Step: 18000. Mean Reward: 87.154. Std of Reward: 25.547.
INFO:unityagents: Ball3DBrain: Step: 19000. Mean Reward: 81.967. Std of Reward: 36.149.
INFO:unityagents: Ball3DBrain: Step: 20000. Mean Reward: 83.971. Std of Reward: 24.420.
^]INFO:unityagents: Ball3DBrain: Step: 21000. Mean Reward: 93.446. Std of Reward: 22.703.
INFO:unityagents: Ball3DBrain: Step: 22000. Mean Reward: 90.321. Std of Reward: 25.878.
INFO:unityagents: Ball3DBrain: Step: 23000. Mean Reward: 89.362. Std of Reward: 26.171.
INFO:unityagents: Ball3DBrain: Step: 24000. Mean Reward: 82.127. Std of Reward: 33.026.
INFO:unityagents: Ball3DBrain: Step: 25000. Mean Reward: 72.694. Std of Reward: 40.881.
INFO:unityagents: Ball3DBrain: Step: 26000. Mean Reward: 91.575. Std of Reward: 16.235.
INFO:unityagents: Ball3DBrain: Step: 27000. Mean Reward: 81.640. Std of Reward: 32.242.
INFO:unityagents: Ball3DBrain: Step: 28000. Mean Reward: 100.000. Std of Reward: 0.000.
INFO:unityagents: Ball3DBrain: Step: 29000. Mean Reward: 80.227. Std of Reward: 39.547.
INFO:unityagents: Ball3DBrain: Step: 30000. Mean Reward: 79.075. Std of Reward: 38.136.
INFO:unityagents: Ball3DBrain: Step: 31000. Mean Reward: 95.458. Std of Reward: 15.063.
INFO:unityagents: Ball3DBrain: Step: 32000. Mean Reward: 100.000. Std of Reward: 0.000.
INFO:unityagents: Ball3DBrain: Step: 33000. Mean Reward: 83.950. Std of Reward: 32.743.
INFO:unityagents: Ball3DBrain: Step: 34000. Mean Reward: 76.846. Std of Reward: 36.478.
INFO:unityagents: Ball3DBrain: Step: 35000. Mean Reward: 93.162. Std of Reward: 23.689.
INFO:unityagents: Ball3DBrain: Step: 36000. Mean Reward: 93.200. Std of Reward: 23.246.
INFO:unityagents: Ball3DBrain: Step: 37000. Mean Reward: 93.077. Std of Reward: 17.433.
INFO:unityagents: Ball3DBrain: Step: 38000. Mean Reward: 87.154. Std of Reward: 29.409.
INFO:unityagents: Ball3DBrain: Step: 39000. Mean Reward: 87.671. Std of Reward: 28.051.
INFO:unityagents: Ball3DBrain: Step: 40000. Mean Reward: 98.158. Std of Reward: 6.108.
INFO:unityagents: Ball3DBrain: Step: 41000. Mean Reward: 83.300. Std of Reward: 30.993.
INFO:unityagents: Ball3DBrain: Step: 42000. Mean Reward: 83.147. Std of Reward: 34.732.
^C--------------------------Now saving model-------------------------
INFO:unityagents:Learning was interrupted. Please wait while the graph is generated.
INFO:unityagents:Saved Model
INFO:unityagents:List of nodes to export :
INFO:unityagents: action
INFO:unityagents: value_estimate
INFO:unityagents: action_probs
INFO:tensorflow:Restoring parameters from ./models/firstRun/model-42346.cptk
INFO:tensorflow:Froze 16 variables.
Converted 16 variables to const ops.
学習中の様子
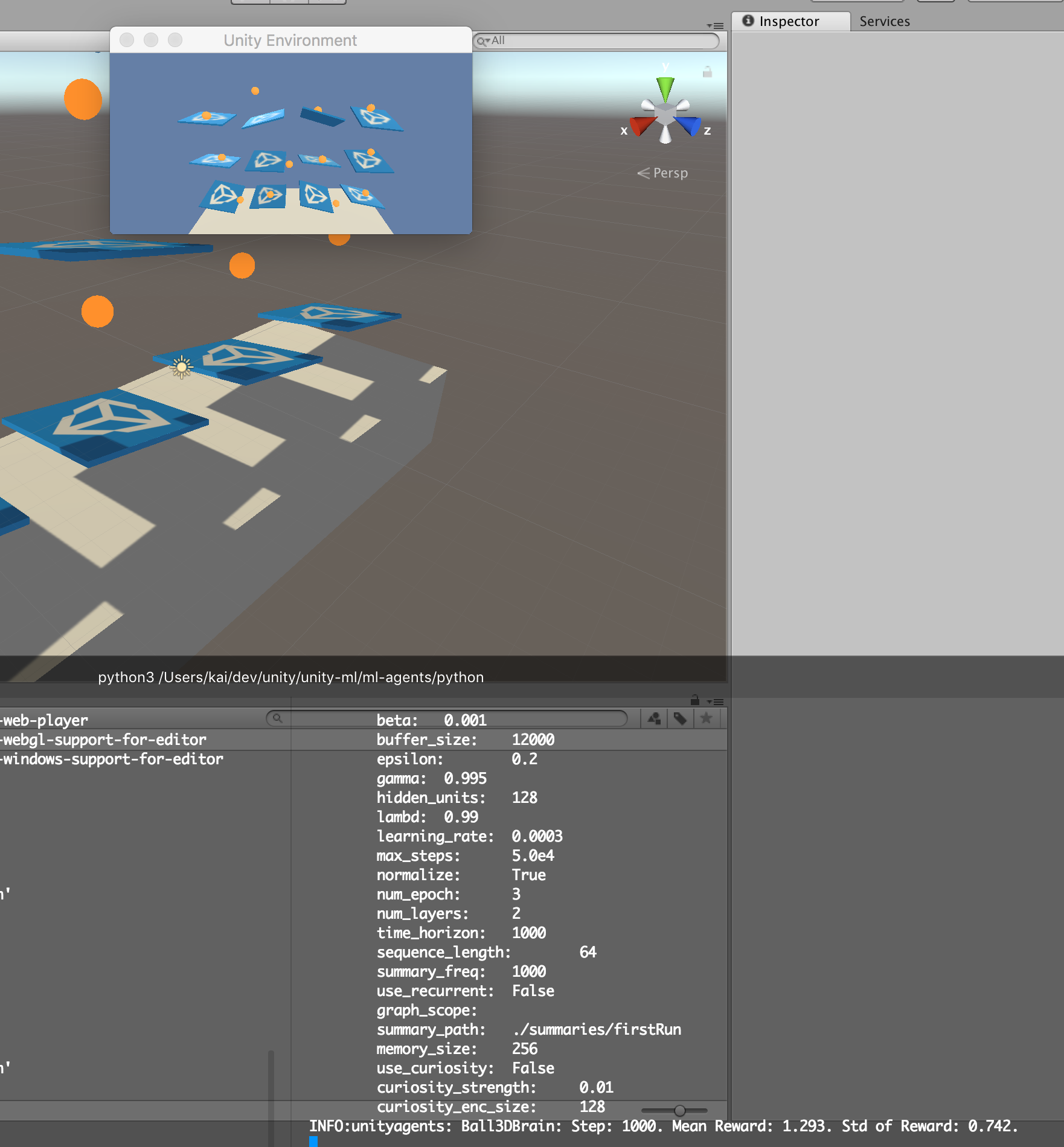
学習がすすむと、徐々にボールが落ちないようになっていきました。
学習結果をアプリに組み込む
学習が完了すると学習結果が.bytes ファイルに保存されます。
それをUnityでアプリに組み込むことができるようです。
Unityの設定
Unityの設定を確認します。
設定を変更したらUnityの再起動が必要です。
- [Edit]メニューから[Project Settings]>[Player]を選択する
- [Inspector]ビューの[Other Settings]欄で以下を設定する
- [Scripting Runtime Version]を[.Net 4.x Equivalent]にする
- [Scripting Defined Symbols]に
ENABLE_TENSORFLOWを入力する

TensorFlowSharpプラグインのインポート
TensorFlowSharpプラグインをダウンロードしてインポートします。
以下の、Basic Guideに説明がありますが、プラグインをダウンロードしてファイルを開くと、UnityでImport確認ダイアログが表示されます。[Import]ボタンをクリックしてインポートします。
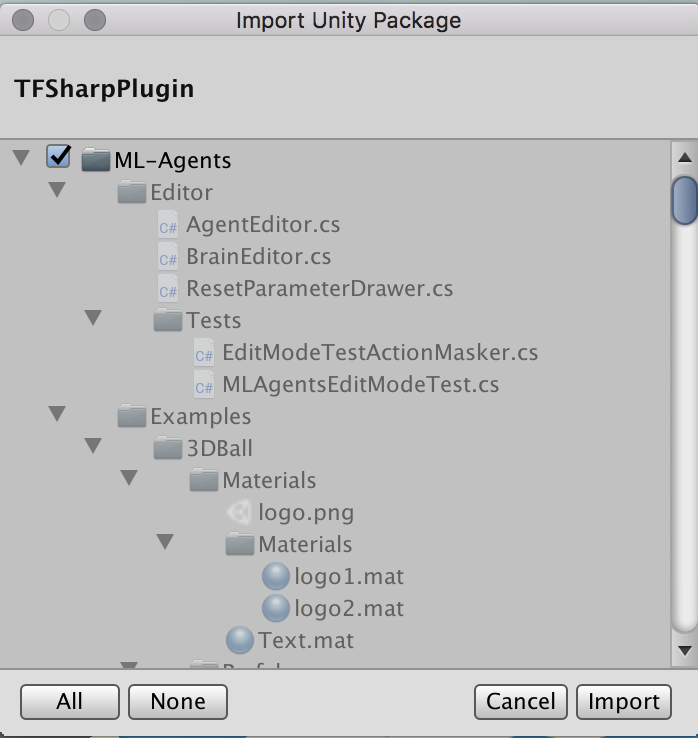
学習結果ファイルの取り込み
ターミナルかFinderで学習結果を以下フォルダにコピーします。
- v0.5.0
- 学習結果ファイル: ml-agents/models/firstRun-0/3DBall_firstRun-0.bytes
- 保存先: UnitySDK/Assets/ML-Agents/Examples/3DBall/TFModels/
- v0.4.0
- 学習結果ファイル: python/models/firstRun/3DBall_firstRun.bytes
- 保存先: unity-environment/Assets/ML-Agents/Examples/3DBall/TFModels/
> cp models/firstRun-0/3DBall_firstRun-0.bytes ../UnitySDK/Assets/ML-Agents/Examples/3DBall/TFModels
- Unityの[Hierarchy]パネルから以下を選択する
- [3DBall] > [Ball3DAcademy] > [Ball3DBrain]
- Unityの[Inspector]パネルにある[Brain Type]を[internal]に変更する
- [Project]パネルで以下フォルダを選択する
- [Assets] > [ML-Agents] > [Examples] > [3DBall] > [TFModels]
- [Brain Type]下に[Graph Model]という項目が現れてるので、そこに[TFModels]フォルダ内の以下ファイルをドラッグ&ドロップする
- v0.5.0
- 3DBall_firstRun-0.bytes
- v0.4.0
- 3DBall_firstRun.bytes
- v0.5.0
 - Unity上部にある再生(三角)ボタンをクリックする
- Unity上部にある再生(三角)ボタンをクリックする
これで、学習結果が組み込まれた状態でアプリが起動します。
50,000ステップ学習すると動きが穏やかで、もはやプロです。

サンプルは他にもあるので、いろいろとお試しあれ。
参考
【Unity】Unityで機械学習する「ML-Agent」を色々と試して得た知見とか
http://tsubakit1.hateblo.jp/entry/2018/02/18/233000
Unity-Technologies/ml-agents/docs/Installation.md
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Installation.md
Using an Environment Executable
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Executable.md
Unityの公式サンプルml-agentsでAIを試す
http://am1tanaka.hatenablog.com/entry/2017/11/08/230525