Supabase の概要を 別記事 に書きましたが、要たるデータベースの詳細を省いたので、こちらはその補完です。
難しく感じたところの解決方法や使うときに読み直したいことをまとめています。
※RDB、SQL の基本的な知識を既にお持ちの方向けです。
※確認作業などをローカル開発環境のみで行ったため、ホスティングの場合の操作の情報はありません。
※サンプルコードには Dart を用いていますが、他の言語も大きく違わないと思います。
全体的なことを知りたい方はまず概要のほうの記事をお読みください。
記事公開より後に Dart 用パッケージが v1.0.0 に達し、そこからさらに改善されてきています。
エラーのハンドリング方法など大きく変わっている部分がありますので、ドキュメントをよくご確認ください。
テーブル結合
ちょっと癖があります。
使う前にここを読んでおくと入っていきやすいと思います。
準備
国と都市のテーブルを例として使うので、そのテーブルとデータを用意します。
テーブル作成
結合するには外部キー制約を設定しておく必要があります。
SQL では外部キー制約なしで結合できるのに PostgREST での結合では必須なのはちょっと不便ですね。
でも使う利点はあるので良しとしましょう。
この例では country_id に適用しています。
CREATE TABLE public.countries (
country_id int PRIMARY KEY,
country_name varchar(32) NOT NULL
);
CREATE TABLE public.cities (
city_id int PRIMARY KEY,
country_id int REFERENCES public.countries (country_id) NOT NULL,
city_name varchar(32) NOT NULL,
population int NOT NULL
);
※テーブル名のところに public. を記述しているのは、ローカル環境の Docker で使う auth_schema.sql というファイルの末尾にある search_path をいじったらカレントスキーマが変わったようで、public を指定せずに作成したテーブルが auth スキーマのほうにできてしまったためです。
それ以来念のために指定していますが、通常はおそらく省略しても大丈夫です。
データ追加
INSERT INTO public.countries
(country_id, country_name)
VALUES
(1, 'Japan'),
(2, 'United Kingdom');
INSERT INTO public.cities
(city_id, country_id, city_name, population)
VALUES
(1, 1, 'Osaka', 2760000),
(2, 1, 'Nagoya', 2330000),
(3, 1, 'Sapporo', 1960000),
(4, 2, 'London', 9000000);
データ取得
国名は countries テーブル、都市名と人口は cities テーブルにしかないので、結合して取得したいです。
次の SQL 文と同様の取得を行うという意味です。
SELECT co.country_name, ci.city_name, ci.population
FROM public.countries AS co
LEFT JOIN public.cities AS ci ON ci.country_id = co.country_id;
Supabase では select() で次のようにするとできます。
select('country_name, cities (city_name, population)')
Dart のコード全体は下のようになります。
import 'package:supabase/supabase.dart';
const _kSupabaseHost = 'http://localhost:8000';
const _kSupabaseAnonKey = 'eyJ0eXAiOi...(略)';
Future<void> main() async {
final client = SupabaseClient(_kSupabaseHost, _kSupabaseAnonKey);
final response = await client
.from('countries')
.select('country_name, cities (city_name, population)')
.execute();
}
エラーがあれば response.error にそのエラー、なければ response.data に取得結果が入ります。
下記は response.data の print 出力を整形したものです。
[
{
country_name: Japan,
cities: [
{city_name: Osaka, population: 2760000},
{city_name: Nagoya, population: 2330000},
{city_name: Sapporo, population: 1960000}
]
},
{
country_name: United Kingdom,
cities: [
{city_name: London, population: 9000000}
]
}
]
このように問題なく取得できました。
では、人口が 200 万以上の都市に絞ってみます。
.select('country_name, cities (city_name, population)')
.gte('cities.population', 2000000)
[
{
country_name: Japan,
cities: [
{city_name: Osaka, population: 2760000},
{city_name: Nagoya, population: 2330000}
]
},
{
country_name: United Kingdom,
cities: [
{city_name: London, population: 9000000}
]
}
]
これも期待どおりの結果です。
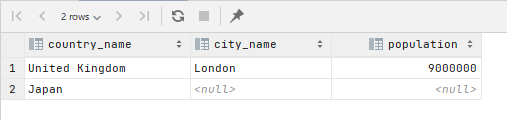
では 500 万人以上にするとどうでしょうか。
.gte('cities.population', 5000000)
[
{
country_name: Japan,
cities: []
},
{
country_name: United Kingdom,
cities: [
{city_name: London, population: 9000000}
]
}
]
該当データのみが得られると思ったら、該当都市がない Japan も一緒に得られてしまいました。
Japan のほうの cities は空配列になっています。
SQL では WHERE ci.population >= 5000000 とすれば一行だけが得られます。
SELECT co.country_name, ci.city_name, ci.population
FROM public.countries AS co
LEFT JOIN public.cities AS ci ON ci.country_id = co.country_id
WHERE ci.population >= 5000000;
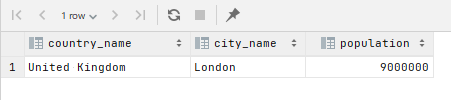
一方 Supabase(PostgREST)では、下記のように左外部結合の ON のところで条件を指定したときの結果に近いです。
LEFT JOIN public.cities AS ci
ON ci.country_id = co.country_id AND ci.population >= 5000000
Dart の postgrest パッケージのコードや Supabase の issues を見ていると「embed」という言葉が出てきます。
その言葉のとおりに「埋め込み」と考えると違和感が減りそうです。
埋め込んだデータを使ったフィルタリングはその埋め込みデータのみに適用されるという感覚です。
古い情報(クリックで開く)
500 万人以上という条件に該当しないデータが含まれないようにするには、埋め込まれる側を抽出条件に使わないようにすればできます。
つまり、from を cities に変えて countries のカラムを埋め込み、cities のほうを使った条件で絞るようにします。
.from('cities')
.select('city_name, population, countries (country_name)')
.gte('population', 5000000)
ただし、from() に countries を指定すると国別の構造になるのに対し、cities を指定すると市単位になるという違いはあります。
追記
2022 年 7 月
!inner を付けるだけで INNER JOIN のように結合側の存在しない行を除外して取得できるようになっていました!
気づくのが遅れましたが、今年 2 月には対応が済んでいたようです。
.select('country_name, cities!inner (city_name, population)')
.gte('cities.population', 5000000)
古い情報(クリックで開く)
結合されるテーブル側のデータを用いた抽出条件によって結合する側も一緒にフィルタリングできるようにする改善作業が進められているようです。
https://github.com/supabase/postgrest-js/issues/197
PostgREST がその機能をサポートしないと実現しないため改善の可能性は低いと思っていたので、意外でした。
Supabase の人が PostgREST のメンテナでもあるようです。
この改善が終われば、先ほどのような埋め込みを逆にする方法など使わなくてもできるようになりますし、後述の View 等を用いる方法に逃げざるを得ないケースも減りそうです。
期待して待ちましょう。
2021 年 10 月
PostgREST 側の作業は終わり、そのリリースと Supabase 側の更新を待つのみになりました。
JavaScript のライブラリが優先されるとすれば Dart はそれより少し遅いかもしれません。
2021 年 12 月
JavaScript は対応が完了して使えるようになりました!
https://supabase.com/blog/2021/11/28/postgrest-9#resource-embedding-with-inner-joins
複雑なクエリを楽にする
先ほどの例では、想定と異なる形式にはなるものの一応近い形では取得できました。
しかし複雑になってくると Supabase のクエリビルダでは不可能な場合も出てきそうです。
また、複雑でなくても SELECT EXTRACT(EPOCH FROM created_at) のような日付/時刻関数、集約関数などは利用できません。1
Supabase の PostgREST のライブラリ/パッケージ は、PostgREST が提供する REST API をそれぞれの言語のメソッドとして利用できるように薄くラップしているだけなので、PostgREST で可能な範囲のことしかできません。
PostgREST で可能なのにライブラリ/パッケージが未対応の場合もあります。
方法 1 - View
難しいことやできないことは View を作ると楽にできます。2
国と都市を結合した View は次のようになります。
CREATE VIEW public.cities_view AS
SELECT co.country_name, ci.city_name, ci.population
FROM public.countries AS co
LEFT JOIN public.cities AS ci ON ci.country_id = co.country_id;
このように作っておけば
.from('cities_view')
.select('*')
.gte('population', 5000000)
で
[
{
country_name: United Kingdom,
city_name: London, population: 9000000
}
]
のように条件に該当するデータだけが返ってきます。
方法 2 - RPC
もう一つは RPC(Remote Procedure Call)でストアドプロシージャ/ファンクションを呼び出す方法です。
ファンクション作成
CREATE FUNCTION public.get_cities(gte int)
RETURNS TABLE (
country_name varchar(32)
, city_name varchar(32)
, population int
) AS $$
BEGIN
RETURN QUERY
SELECT
co.country_name
, ci.city_name
, ci.population
FROM public.countries AS co
LEFT JOIN public.cities AS ci ON ci.country_id = co.country_id
WHERE ci.population >= gte;
END;
$$ LANGUAGE plpgsql;
クライアントからこのファンクションを呼び出すには rpc() メソッドを使います。
RPC の利用方法について ドキュメント の JavaScript の例では
const { data, error } = await client
.rpc('echo_all_cities')
.eq('name', 'The Shire')
となっていて、取得結果に対して eq() 等のフィルタを利用できるようなのですが、Dart のパッケージでは rpc() の結果の型が select() の場合と異なっていて eq()・gte() などが存在しなくて使えませんでした。3
古い情報(クリックで開く)
代わりにファンクションに gte という引数を設け、呼び出すときに人口の下限値を渡すようにしました。
.rpc('get_cities', params: {'gte': 5000000})
.execute()
言語間の API の差異でしかないので、そのうち修正されるのではないかと思います。
その後、postgrest パッケージの v0.1.8 にて修正されていました!
セキュリティポリシー
Supabase のデータベースは、クライアントからの直接アクセスを安全にできるようになっています。
その仕組みには PostgreSQL の RLS(Row Level Security: 行単位セキュリティ)が活用されています。
セキュリティポリシーは Authentication と関わりが深いものです。
認証したユーザのデータが PostgreSQL 内の auth スキーマにあり、そこのデータと照らす形でアクセスを制限できます。
準備
TODO の例を使って説明しますので、まずそのテーブルとデータを用意します。
ユーザがタグを追加して TODO タスクに設定できる仕様とします。
この説明ではタグの追加はあらかじめ行っておきます(「買い物」「学習」「いろいろ」の三つ)。
テーブル作成
CREATE TABLE public.tags (
tag_id serial PRIMARY KEY,
tag_name varchar(64)
);
CREATE TABLE public.tasks (
task_id bigserial PRIMARY KEY,
task text NOT NULL,
tag_id int REFERENCES public.tags (tag_id) NOT NULL,
user_id uuid REFERENCES auth.users (id) DEFAULT auth.uid() NOT NULL
);
user_id のところが肝です。
デフォルト値として auth.uid() を指定しているので、レコードを追加したときにログイン中のユーザの ID が自動的に入ります。
また、外部キーで auth.users テーブルの id カラムと紐づけています。
データ追加
タグを追加。
INSERT INTO public.tags (tag_name)
VALUES ('買い物'), ('学習'), ('いろいろ');
tasks テーブルのデータはユーザに紐づいたものになるので、Dart でログインしてから追加します。
「user1@example.com」というメールアドレスでサインアップ済みのユーザが既にいるとして、次のようにログインします。
await client.auth.signIn(
email: 'user1@example.com',
password: 'password',
);
user1 にログインした状態で tasks テーブルに一行追加します。
final response = await client.from('tasks').insert([
{'task': '牛乳を買う', 'tag_id': 1},
]).execute();
成功すると response.data は下記のようになっていて、たった今追加したデータが入っています。
わざわざ取得し直さなくていいのは良いですね。
[{task_id: 1, task: 牛乳を買う, tag_id: 1, user_id: ecaa9bc1-0891-4d4f-a6c7-94aafcf889de}]
「user2@example.com」のユーザでも一行追加しておきます。
下のスクリーンショットのように、user_id のカラムには task_id が 1 の行では user1、2 の行では user2 の ID がそれぞれ入った状態になります。

ポリシーなしで取得
どちらかのユーザで tasks テーブルから抽出条件なしで取得すると、両ユーザのデータが返ってきます。
final response = await client.from('tasks').select('id, tag_id').execute();
[{task: 牛乳を買う, tag_id: 1}, {task: Supabaseの勉強をする, tag_id: 2}]
ポリシーを適用して取得
各ユーザが自分の TODO タスクしか取得できないようにしましょう。
CREATE POLICY "Users can fetch only their own tasks."
ON public.tasks
FOR SELECT USING (auth.uid() = user_id);
文法等の間違いがあると、これを実行したときにエラーになって気づけます。
USING と WITH CHECK の使い分けが少し難しいですが、PostgreSQL の CREATE POLICY のドキュメント に載っている説明や表を見ると理解しやすいです。
注意点は、CREATE POLICY の実行だけでは効かないことです。
ALTER TABLE によってテーブル単位で RLS を有効にしないといけません。
-- 有効化
ALTER TABLE public.tasks
ENABLE ROW LEVEL SECURITY;
-- 無効化
ALTER TABLE public.tasks
DISABLE ROW LEVEL SECURITY;
有効にしてから user1 のほうで再度取得すると、user1 のレコードだけが得られます。
final response = await client.from('tasks').select('id, tag_id').execute();
[{id: 1, task: 牛乳を買う}]
セキュリティポリシーで設定した条件が問い合わせ時にフィルタとして働くため、WHERE 句を指定しなくてもポリシーに該当するデータのみになります。
WHERE 句を使ったほうが安全だと思いますが、説明のためにあえて使わないで取得しています。
この例では「現在のユーザと user_id が一致するタスクのみ取得可能」にしましたが、「認証済みユーザなら誰でも取得可能」にしたければ 「NULL でない」という指定をすればいいようです。
FOR SELECT
USING (auth.uid() IS NOT NULL)
INSERT/UPDATE のポリシー
user1 でログインした状態で、もし何らかの方法で user2 の ID を用いてデータを追加してしまったら困ります。
試しにその対策となるセキュリティポリシーを設定せずに追加しようとしてみたのですが、ポリシーを一切設定せず tasks の RLS を有効にしただけの状態でも「new row violates row-level security policy for table "tasks"」というエラーが出て、異なるユーザでのデータ追加が阻止されました。
どのような仕組みでそうなるのかわからなくてすっきりしませんが、自動的に安全になることは悪くはないですね。
もし明示的にポリシーを設定するならおそらく下記のようになると思います(INSERT の場合)。
CREATE POLICY "Users can insert tasks only with own ID."
ON public.tasks
FOR INSERT WITH CHECK (auth.uid() = user_id);
この代わりとして、セキュリティポリシーを使わずに検査制約を用いる方法もあります。
次のように user_id カラムの定義に CHECK (user_id = auth.uid()) を付ければ、そのカラムに入る値として現在のユーザの ID しか許可されなくなります。
CREATE TABLE public.tasks (
...,
user_id uuid REFERENCES auth.users (id) DEFAULT auth.uid() CHECK (user_id = auth.uid())
);
このカラムに対して INSERT や UPDATE によって異なるユーザの ID を設定しようとするとエラーが出ます。
new row for relation "tasks" violates check constraint "tasks_user_id_check"
ポリシーの確認
RLS の有効状態
SELECT tablename, rowsecurity
FROM pg_tables
WHERE schemaname = 'public';
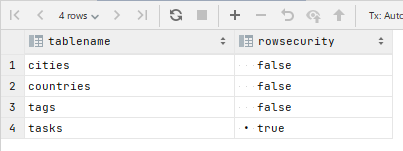
A5:SQL Mk-2 では自分で問い合わせなくてもテーブルの「RDBMS固有の情報」のところで確認できました。
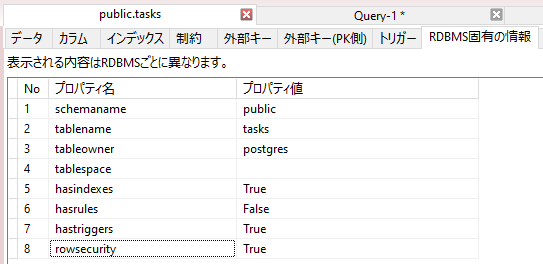
設定済みのセキュリティポリシー 4
SELECT * FROM pg_policies;

ウェブの UI でも確認できるようになっていると思いますが、ローカル環境/セルフホスティングのダッシュボードはまだ作業途中で、その PR は こちら です。
2021-12-1
ローカルでもダッシュボードが利用できるようになり、ポリシーの状態の確認、新たなポリシーの追加、ボタンでの切り替えなどができることを確認しました。
ポリシーの削除
設定したポリシーを消すには、作成時に設定したのと同じコメント(ポリシーの名前)を指定して DROP POLICY します。
DROP POLICY "Users can fetch only their own tasks."
ON public.tasks;
複雑なポリシー
先ほどのセキュリティポリシーはシンプルすぎるので、違うポリシーも設定してみます。
その準備として tags テーブルを用意していました。
まず、そのテーブルにポリシーを設定しないで user1 で取得してみます。
final response = await client.from('tags').select('tag_name').execute();
全タグが得られました。
[{tag_name: 買い物}, {tag_name: いろいろ}, {tag_name: 学習}]
このままでは自分以外の人が設定したタグまで取得できてしまいます。
自分のタスクに使われているタグしか取得できないようにしましょう。
CREATE POLICY "Users can fetch only their own tags."
ON public.tags
FOR SELECT USING (
tag_id IN (
SELECT tag_id
FROM public.tasks
WHERE auth.uid() = user_id
)
);
ALTER TABLE public.tags
ENABLE ROW LEVEL SECURITY;
これで先ほどと同じように取得すると、user1 の TODO タスクで使われている「買い物」タグのみが得られます。
[{tag_name: 買い物}]
IN とサブクエリを使った条件なのでわかりやすいのではないでしょうか。
セキュリティポリシーを SQL で設定できるのは脳を別言語に切り替えなくて済んで良いですね。
データのバリデーション
セキュリティポリシーでは Auth のデータと連携してユーザを限定できます。
しかしそれだけでなくバリデーション全般に用いることができます。
WHERE 句のように SQL で条件指定できるので、複雑なバリデーションも可能です(負荷を無視すれば)。
その他に、INSERT/UPDATE のポリシーのところでも用いた検査制約がまさにバリデーション用です。
詳細は PostgreSQL のドキュメントをご覧ください。
例(ドキュメントより)
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0)
);
他にも非 NULL 制約は積極利用したほうがいいでしょうし、別テーブルに存在する値しか許可したくない場合には外部キー制約を用いるのが良いでしょう。
排他制約は使ったことがないですが、とても便利そうなので調べて使えるようにしておきたいところです。
View とファンクションへのポリシー適用
View やファンクションを使うと複雑なクエリが楽になることを先述しましたが、セキュリティポリシーにご注意ください。
View
View のほうは設定しないとポリシーが効きません。
古い情報(クリックで開く)
https://github.com/supabase/supabase/issues/190#issuecomment-785143167
View のオーナーを BYPASSRLS 以外か SUPERUSER(View を作成した admin ユーザなど)に変えればセキュリティポリシーが View にも適用されるそうです。
ALTER VIEW public.xxxxx
OWNER TO authenticated;
リンク先に書かれているとおり、このように設定すると適用されました。
(xxxxx の部分はテーブル名です。)
なお、変更前のオーナーは postgres になっていました。
普通のテーブルは同じく postgres なのにオーナーを変更しなくてもポリシーが適用されるのがなぜなのか理解できていません。
PostgreSQL 15 では、View を作るときにオプションを指定するだけでポリシーが効くようになりました。
CREATE VIEW View名 WITH (security_invoker = on) AS クエリ;
2022 年 12 月の Supabase の Launch Week 6 で投稿されたブログです。
それ以前に作成したプロジェクトでは自動的には 15 にアップグレードされないようです。
手順は下記のドキュメントに書かれています。
ファンクション
見当たらなかったので試したところ、関連するテーブルにポリシーが設定されていて RLS が有効化されていればファンクションにも自動的に適用されていました。
お使いになるときにご自身でも確認してみてください。
ポリシーの効率
条件指定の SQL は問い合わせるたびに使われるため、負荷が極力小さくなるように考える必要があると思います。
SELECT 文に変えてその実行計画を確認しながらポリシーの記述を決めるのがいいですね。
EXPLAIN SELECT *
FROM public.tags
WHERE tag_id IN (
SELECT tag_id
FROM public.tasks
WHERE auth.uid() = user_id
);
MySQL のほうの経験では、サブクエリで取得されるレコード数が少なくなるようにしたほうが効率が良いことが多いので、内側の SELECT で取得するカラムに DISTINCT を付けた場合との実行計画の違いを確認してみたいと思います。
DISTINCT なし
Hash Semi Join (cost=30.76..46.50 rows=5 width=150)
Hash Cond: (tags.tag_id = tasks.tag_id)
-> Seq Scan on tags (cost=0.00..14.50 rows=450 width=150)
-> Hash (cost=30.70..30.70 rows=5 width=4)
-> Seq Scan on tasks (cost=0.00..30.70 rows=5 width=4)
" Filter: ((NULLIF(current_setting('request.jwt.claim.sub'::text, true), ''::text))::uuid = user_id)"
DISTINCT あり
Hash Join (cost=30.90..46.59 rows=5 width=150)
Hash Cond: (tags.tag_id = tasks.tag_id)
-> Seq Scan on tags (cost=0.00..14.50 rows=450 width=150)
-> Hash (cost=30.83..30.83 rows=5 width=4)
-> Unique (cost=30.76..30.78 rows=5 width=4)
-> Sort (cost=30.76..30.77 rows=5 width=4)
Sort Key: tasks.tag_id
-> Seq Scan on tasks (cost=0.00..30.70 rows=5 width=4)
" Filter: ((NULLIF(current_setting('request.jwt.claim.sub'::text, true), ''::text))::uuid = user_id)"
おっと、これは…。
MySQL と違いすぎて全然わかりません!(涙)
DISTINCT を付けたほうが複雑になっているように見えるので、付けないほうがいいということでしょうか。
思った結果と逆でした。
でも見方が間違っているかもしれないので今後の自分の学習課題にします。
ついでに次のように EXISTS を使ったバージョンの実行計画も見てみましたが、上記の DISTINCT なしの場合と全く同じ計画になっていました。
CREATE POLICY "Users can fetch only their own tags."
ON public.tags
FOR SELECT USING (
EXISTS (
SELECT 1
FROM public.tasks
WHERE tag_id = public.tags.tag_id AND auth.uid() = user_id
)
);
Infinite recursion
「infinite recursion detected in policy for relation テーブル名」というエラーが出ることがあります。
以前に起こったときのメモが簡潔すぎたので不確かですが、下記のようなポリシーで起こったと記憶しています。
ON public.shared_users
FOR SELECT
USING (
post_id IN (
SELECT post_id
FROM public.shared_users
WHERE auth.uid() = user_id
)
)
「投稿をシェアされた人だけがシェアされたユーザの一覧を取得できる」というややこしめのポリシーです。
shared_users というテーブルに関するセキュリティポリシーのサブクエリでそのテーブル自体を使ったことで、再帰のループが起こっているようです。
この問題について情報があったのですが、いま見たらリンク切れになっていて 5 、たまたま アーカイブ はありました。
Dec 16, 2016; 11:36pm
CREATE FUNCTION get_owner_id(luser text) RETURNS integer AS $$
SELECT id FROM accounts WHERE name = luser
$$ LANGUAGE sql STRICT STABLE SECURITY DEFINER;
Dec 18, 2016; 3:18am
RLS does not get applied to the superuser, and the
get_owner_id procedure was 1) SECURITY DEFINER, and 2) created/owned by
postgres. Thus the procedure executes without invoking the RLS policy
and avoids the infinite recursion.
Dec 18, 2016; 4:04am
as with views, a USING() clause is executed as the caller not the
owner of the relation. Security Definer functions can be used to
execute actions in the policy as another user.
知識不足で難しいですが、SECURITY DEFINER を付けたファンクションをポリシー内で使うと別のユーザとして実行できて RLS を回避できる(それによって再帰が起こらずに済む?)ようです。
CREATE FUNCTION public.get_post_id(userId uuid, postId int)
RETURNS int AS $$
DECLARE
id int;
BEGIN
SELECT post_id INTO id
FROM public.shared_users
WHERE user_id = userId AND post_id = postId;
RETURN id;
END;
$$ LANGUAGE plpgsql SECURITY DEFINER;
こうやってファンクションを作って下記のようにポリシーで利用することでエラーをなくすことができました。
※これも不十分なメモを基にしているので多少間違っているかもしれません。
CREATE POLICY "Only shared users can see shared users."
ON public.shared_users
FOR SELECT
USING (
post_id = get_post_id(auth.uid(), post_id)
);
上記の 4:04am のところにはもう一つの情報があります。
Note that RLS won't be applied for the table owner either (unless the
relation has 'FORCE RLS' enabled for it), so you don't have to have
functions which are run as superuser to use the approach Joe
recommended.
「リレーションで FORCE RLS を有効にしていない限り RLS はそのテーブルのオーナーにも適用されないので、スーパーユーザで動くファンクションを作る方法を使わなくてもできる」という情報です。
いま見たファンクション以外の方法もあることはわかったのですが、具体的な書き方がわかりませんでした。
(わかる方にはわかると思われるので念のために書き添えておきました。)
ユーザを public のテーブルに追加
auth.users にあるユーザの情報はクライアントからアクセスできませんが、必要な項目を public スキーマのテーブルにコピーしておけばアクセスできます。
ユーザがサインアップして auth.users テーブルに追加されたのをトリガーにして public.users テーブルに反映することでそれが可能になります。
古い情報(クリックで開く)
その方法が以前は公式ドキュメントに書かれていた記憶があるのに見当たらなくなっていて、GitHub にだけありました。
https://github.com/supabase/supabase/issues/563#issuecomment-772954907
ドキュメントから消えた理由がわからないので、自己責任でお使いください。
そこに書かれているままを転記します。
public.users テーブルを作成
create table users (
id uuid references auth.users not null primary key,
email text
);
public.users にユーザを追加するファンクションを作成
create or replace function public.handle_new_user()
returns trigger as $$
begin
insert into public.users (id, email)
values (new.id, new.email);
return new;
end;
$$ language plpgsql security definer;
ファンクションのトリガーを作成
create trigger on_auth_user_created
after insert on auth.users
for each row execute procedure public.handle_new_user();
公式ドキュメントから消えたと思って別ソースの情報を載せていましたが、見つかりました。
Infinite recursion のところで出てきた SECURITY DEFINER がここでも使われていますね。
そういうところも理解して自分で使えるように PostgreSQL をもっと学ばないといけないなと思いました。
別の方法として、View かファンクションを経由して auth.users にアクセスできるという情報を Reddit で見つけました。
Supabase の人が書いていることなので安全だと信じたいですが、アクセスできないはずのところにアクセスできるようにするのは全く安全だとは言い難い気がします。
トランザクション
トランザクションはとても大事です。
失敗したときにロールバックされなくてゴミデータが残るだけならまだいいですが、データに不整合が起こるのは防がないといけません。
しかし Supabase ではクライアント側の操作ではできないようです。
代わりの方法の情報は issue にありました。
これもまたファンクションです。
CREATE OR REPLACE FUNCTION just_fail() RETURNS json AS $$
BEGIN
-- do some logic here
-- RETURN
-- in case of an error, fail:
RAISE EXCEPTION 'I refuse!'
USING DETAIL = 'Pretty simple',
HINT = 'There is nothing you can do.';
-- the above will cause a rollback
END
$$ LANGUAGE plpgsql;
トランザクションを必要とする一連の処理をファンクション内で行い、失敗したときに RAISE EXCEPTION でエラーを起こすことでロールバックを作動させるだけです。
そのファンクションを supabase-js で呼んだときのエラーの中身は次のようになるそうです。
{
"message":"I refuse!",
"details":"Pretty simple",
"hint":"There is nothing you can do.",
"code":"P0001"
}
PostgreSQL の エラーに関するドキュメント によると RAISE のデフォルトは EXCEPTION なので、EXCEPTION は省略することができそうです。
また、ウェブ検索してみると ここ では少し違った書き方がされていました。
このようなファンクションを利用しなくてもできるように Supabase でサポートされると良いのですが、上記 issue ではその予定はなさそうな雰囲気になっていて残念です。
追記
しばらく使ってみて、物は考えようだと思いました。
トランザクションが必要になるのは単純でない複数処理(いくつかの読み書きの組み合わせ)であり、そういったことはクライアントでごちゃごちゃと行うよりもバックエンドにまとめたほうがいいという考え方もできます。
Supabase / PostgreSQL では幸いそのために別サービスを組み合わせる必要がなく、テーブル作成などと同様に SQL の記述としてまとめておくことができて管理しやすく、実行も簡単です。
例:
クリックして開く
CREATE FUNCTION blog_add_post(
p_id TEXT
, p_draft_id TEXT
, p_title TEXT
, p_body TEXT
, p_categories TEXT[]
)
RETURNS void AS $$
BEGIN
-- 1. 公開記事用のテーブルに記事を追加
INSERT INTO blog_posts
(id, title, body)
VALUES (p_id, p_title, p_body);
-- 2. カテゴリのテーブルに反映(別関数)
PERFORM blog_replace_categories(p_id, p_categories);
-- 3. 下書きのテーブルから削除
DELETE FROM blog_drafts
WHERE post_id = p_draft_id;
END
$$ LANGUAGE plpgsql;
ブログの下書き状態の記事を公開状態に切り替える関数です。
この関数一つを呼ぶだけで三つの処理が一括実行されます。
(2 では別の関数を読んで二つの処理を行っているので、実際には計四つ。)
このようにバックエンドですっきりと済ますことができるので、トランザクションをクライアントで使えないことは必ずしも大きな不便ではありません。
VACUUM
PostgreSQL では VACUUM が必要で、自動的に行うのが推奨されています。
必要な理由等は ドキュメント に書かれていますので、聞いたことがないという方は読んでおくと良いと思います。
デフォルト設定については次のとおり書かれています。
デフォルトの設定では、自動バキュームは有効で、関連するパラメータも適切に設定されています。
設定されている内容は、こちら によれば下記のどちらかで確認できるとのことです。
(pg_class テーブルのデータを見る方法も書かれていますがダメでした。)
SELECT * FROM pg_settings WHERE name LIKE '%autovacuum%';
または
SELECT * FROM pg_settings WHERE category LIKE 'Autovacuum';
ローカル環境の Docker で利用されるファイルを見ても関連設定がないので、デフォルト設定のまま有効なのだろうと思いつつ、念のために確認するとやはり autovacuum が on になっていて安心できました。
ホスティングのほうは未確認ですが、あえて無効にする意味はないのでおそらく有効だと思います。
おわりに
情報量が多い記事になりましたが、このくらい見ればだいぶ理解が進んだ状態になると思います。
でもなかなか難しいところもありますね。
PostgREST をラップしたメソッドやセキュリティポリシーで Auth の情報を使う方法などは Supabase 独自の部分ですが、それ以外のほとんどは PostgreSQL そのものですので、困ったときにはウェブ検索時に「Supabase」のキーワードで絞らずに PostgreSQL の情報を探すと見つかりやすいかもしれません。
-
データベースは負荷が高くなってボトルネックになりやすいため、何でもかんでもデータベースで処理せずにアプリケーションでできることはそちらでやるほうが良いと考えることもできるので、使えないことをあまりにネガティブに捉えなくてもいいと思います。 ↩
-
昔 SQL を学び始めたころに「使いすぎるのは良くない」と聞いたのですが、どうなんでしょうね。オプティマイザがどんどん賢くなっているとすれば今は積極的に使っても問題ないのかもしれません。 ↩
-
select()の結果がPostgrestFilterBuilder型なのに対し、rpc()の結果はPostgrestTransformBuilder型になっています。 ↩ -
DataGrip では 2021.1 以降のバージョンでは 確認する機能があるとのこと ですが、どこで見られるのかわかりませんでした。 ↩