この記事はレコチョク Advent Calendar 2021の24日目の記事となります。
こんにちは、株式会社レコチョク入社1年目の早坂と申します。
本記事では、今年のレコチョク新卒エンジニア研修の一環で行われた、サービスの企画から開発までを行うハンズオンの中で、私が実装したレコメンド機能についてご紹介します。
まずは新人なので、自己紹介をします。
自己紹介
趣味
- カメラ
- ビートボックス(ボイパ)
- カラオケ
- 音楽鑑賞
- 好きなアーティスト : RADWIMPS・清水翔太・川崎鷹也・TWICE・SHOW-GO
実装に至った背景
レコチョクでは、新卒のエンジニア社員は4・5月にビジネス研修、6月~9月にエンジニア研修があります。
エンジニア研修では、フロントエンドからバックエンドまで様々な技術を学び、最後の1ヶ月間でグループ開発演習があります。演習内容は、新卒内でグループを組み、サービスの企画・設計・実装までを行うという、いわば研修の集大成を発揮する機会となっています。
企画したサービスについては後述しますが、開発期間としては、企画立案にかかった期間を除く3週間でサービスに必要なレコメンド機能を実装することとなりました。
開発したサービス・機能について
サービス概要
下記、エレベーターピッチを用いたサービスの概要です。
リモートワーク下で社内のコミュニケーションを促進したい企業向けの、
懇親会セッティングサービス。
これは面識のないユーザ同士の共通点・興味の有無が確認でき、
共通点・興味があるユーザーをグループ化して可視化することで、
懇親会のセッティングに活用することができる。
開発した機能
サービス概要の「共通点・興味があるユーザーをグループ化して可視化すること」を実現するために開発した機能です。
1. ユーザーのレコメンド機能
サービスのホーム画面で、"レコメンドユーザー"枠を作り、あるユーザーに対してデータ分析の結果近しい趣味・嗜好を持つと考えられる別ユーザーを表示します。これは、共通の趣味・嗜好を持った社内の人とのコミュニケーションにおけるきっかけづくりを目的にしています。
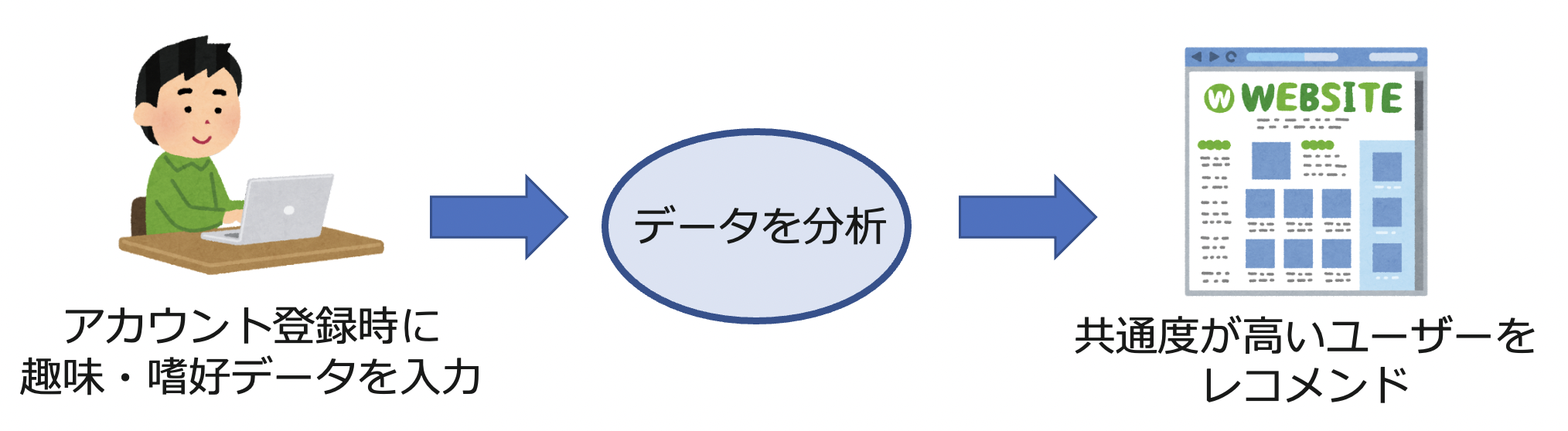
2. 懇親会のグループ分けにおけるレコメンド機能
1のデータを活用し、懇親会のセッティング(席の振り分け)時にデータ分析の結果近しい趣味・嗜好を持つユーザー同士を優先的に同じグループに配置します。懇親会の幹事がこの機能を利用したグループ分け結果を見て、懇親会の席決めに役立てます。

実装したロジックの全体像
実装した2つの機能の処理フローは下記です。

使用した技術
- 言語
- Python 3.7.3 (データ分析に使用)
- PHP 7.4 (クラスタリング結果の後処理に使用)
- Pythonモジュール
- scikit-learn
- KMeans (クラスタリングに使用)
- PCA (主成分分析に使用)
- Matplotlib (可視化に使用)
- NumPy (データ配列格納に使用)
- scikit-learn
1. ユーザーのレコメンド機能
カテゴリ評価データ(入力データ)
入力データは、"アート"や"ゲーム"、"音楽"など16種類のカテゴリに対する興味度1~5(1が最も低く、5が最も高い)を新規ユーザー登録時に評価してもらった結果をまとめた多次元配列です。

前処理
データ分析の前処理にはいくつかの手法や工程がありますが、今回の場合は前処理をしなくても良いと判断しました。そのため、ロジックの全体像では表記していません。理由としては、今回扱うデータはカテゴリの評価値で1~5の数値のみとなっており、指標は同じと考えることができるので、前処理をしなくても主成分分析の結果に妥当性はあると考えたためです。
ただ、注意点として、指標は同じでも、各指標ごとに分散は違うので、それらを前処理で揃えたほうがより良い分析結果が出る場合があります。さらに、上記の判断に至る中で考慮した前処理の手法は、正規化と標準化のみなので、別の手法を考慮すると、前処理を行ったほうがいい場合もあります。
データ分析は前処理が8割、「毒抜き」しないと危険
正規化・標準化を徹底解説 (Python 前処理 サンプルコード付き)
主成分分析
主成分分析については、このページで下記のような説明があります。
「主成分分析」とは、統計学上のデータ解析手法のひとつです。たくさんの量的な説明変数を、より少ない指標や合成変数(複数の変数が合体したもの)に要約する手法です。
言い換えると、たくさんの指標があるデータにおいて、全体の中でどのような相関・分散を持つのかを計算し、入力データ全体から見てデータのばらつきが相対的に大きい指標を取り出すことです。
今回主成分分析を用いた理由は、可視化した分析結果をサービス上で確認できるようにすることで、ユーザー同士の趣味・嗜好における共通度を視認できるようにするためです。
なお、視認がしやすくなるよう、16次元のカテゴリ評価データを2次元に削減します。
主成分分析のコードは下記です。
モジュールを用いることで、簡潔なコードで実装することができます。
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
# ファイルの読み込み
input_data = pd.read_csv('ファイル名')
# 主成分分析の実行
pca = PCA()
pca.fit(input_data)
# データを主成分空間に写像
pca_cor = pca.transform(input_data)
# 固有ベクトル
eig_vec = pd.DataFrame(pca_cor, index=input_data.index, columns=["PC{}".format(x + 1) for x in range(len(input_data.columns))])
# 第一主成分・第二主成分のみを取得(次元削減)
data_pca = eig_vec.iloc[:, 0:2]
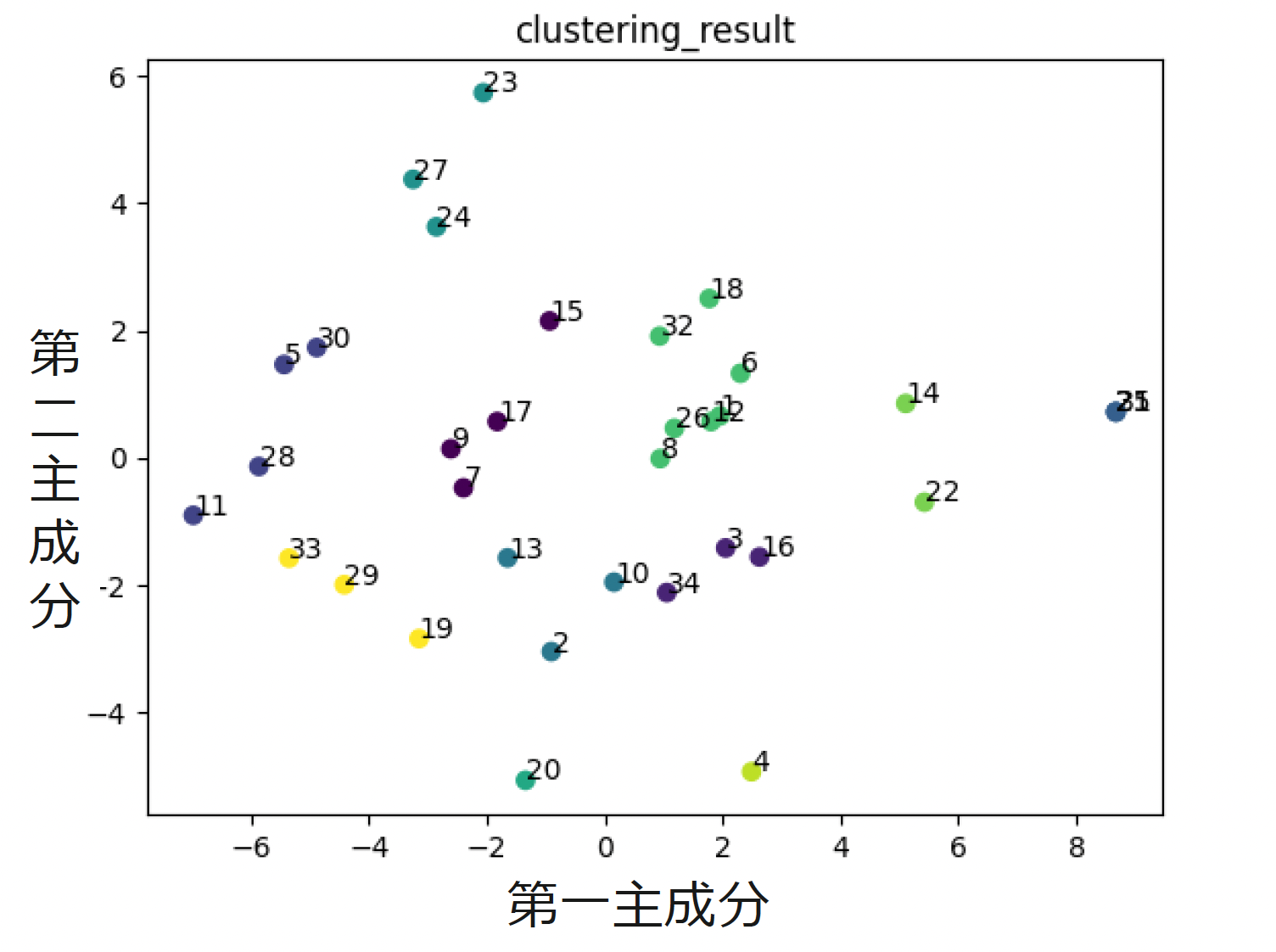
入力データに対して主成分分析を行い、第一主成分、第二主成分に取り出した結果を可視化したものが下図です。各点はユーザーの主成分データ、付近にある数字はユーザーIDです。
画像の中心付近を見ると、ユーザーIDが8・26・12・1のユーザーが趣味・嗜好の共通度が高いと考えることができます。

ユーザー間の共通度を計算
さて、ここまでで主成分分析を行うことはできましたが、主成分分析の結果のみではレコメンドとして機能しません。したがって、主成分分析結果からユーザー同士の共通度を計算することが必要になります。
そこで、ユークリッド距離によるユーザー間の共通度を考えました。主成分同士のユークリッド距離を計算し、ユークリッド距離が近いユーザーを趣味・嗜好が近いレコメンドユーザーとして表示する、というロジックです。
他に効率のいい方法があるのではと考えたものの、開発期間は限られていたため、実装が容易な手法を選択しました。
2. 懇親会のグループ分けにおけるレコメンド機能
クラスタリング
次は、懇親会用に席を振り分けるため、前章で主成分分析したデータをクラスタリングします。
クラスタリングについては、このページが参考になります。
クラスタリングとは、データ間の類似度にもとづいて、データをグループ分けする手法です。クラスタリングによってできた、似たもの同士が集まったグループのことをクラスタと呼びます。活用例として、顧客情報をクラスタリングして顧客をグループ分け(セグメンテーション)し、同じグループ内で同じ商品が複数回購入された場合、その顧客と同じグループに属している他の人たちにも同じ商品をレコメンドする、といったものがあります。
クラスタリングの代表的な手法である、k-means法を用いて下記のように実装しました。
クラスタリングを行う上での注意点として、今回は主成分分析を行い、2次元に削減したものに対してクラスタリングを行いましたが、主成分分析を行って次元削減をしなくてもクラスタリングは行うことができます。
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
# ファイルの読み込み
input_data = pd.read_csv('ファイル名')
# クラスタの個数
# ONE_GROUP_NUM はユーザーからの入力により設定される値
CLUSTER_NUM = int((len(input_data) / int(ONE_GROUP_NUM)))
# クラスタ, kmeans++で初期化, k-means++で初期クラスタを設定, 異なるセントロイドを用いたアルゴリズムの実行回数, 最大イテレーション数, 相対許容誤差, 乱数生成器の状態
km = KMeans(n_clusters=int(CLUSTER_NUM), init='k-means++', n_init=10, max_iter=300, tol=1e-04, random_state=0)
# クラスタリングの実行
y_km = km.fit_predict(input_data)
# 主成分データにクラスタlabel(グループ番号)を付与
input_data['label'] = y_km
下図がクラスタリングをした結果を示したものになっています。
同じ色の点は、同じクラスタに分類されたユーザーを示しています。
前章の主成分分析の結果を可視化した図で、趣味・嗜好の共通度が高い、IDが8・26・12・1のユーザーは緑色に着色されており、同じグループに分類されました。
クラスタリング結果の後処理
ここまでで、趣味・嗜好の共通度が高いユーザー同士をグルーピングすることができました。
しかし、クラスタリング結果における各クラスタの人数にはばらつきがあります。
今回の場合、懇親会のグループ分けにクラスタリング結果は使われるため、クラスタリング結果はそのまま懇親会のグループとして採用することはできません。
極端な場合、あるグループは数十人でワイワイ、あるグループは皆とは趣味・嗜好が違うために一人寂しく飲むという地獄絵図を作ってしまうことになりかねません。
そこで、クラスタリング結果に対して、各グループの人数を均すための後処理をします。
後処理のロジックについては、クラスタリング結果の使用場面によって変わるので、Web検索で出てくる記事は参考になりません。そのため、自身で下記のロジックを考えました。
- 各クラスタにおいて、ユーザーの主成分値とクラスタの重心座標値の距離を計算する
- 重心から距離が近いユーザーから順番に優先的に同じグループにする
- 優先度の低いユーザーは、人数が足りていないグループをランダムに選んで入れる
クラスタの重心座標値は、
centers = km.cluster_centers_
と一行で取得することができます。centersはクラスタリングされたグループに付与された番号順に重心点の座標が格納されている配列です。
2、3の内容は、下記のようなロジックで実装しました。
下図のイメージのような所属するユーザー数にばらつきのあるクラスタ群があるとします。
各クラスタに所属するユーザーは、重心からの距離が近い順に並んでいます。(図中の下にあるユーザーが一番重心からの距離が近い)
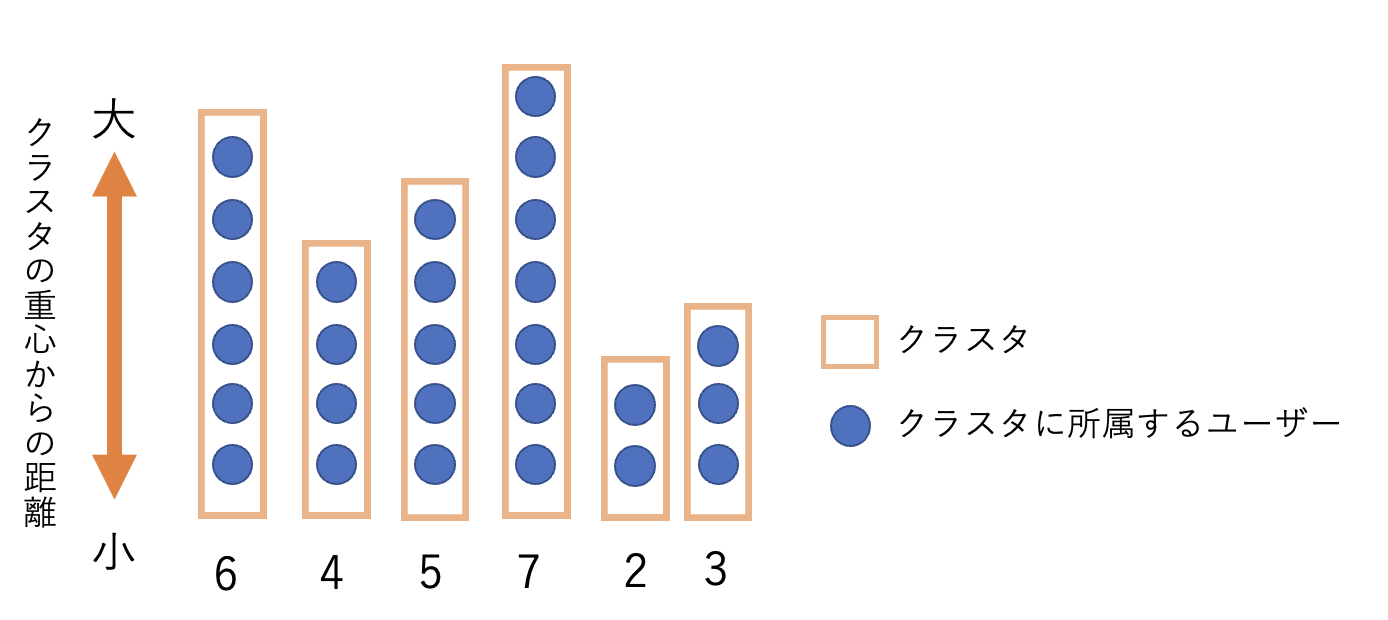
まず、クラスタ群を懇親会の1グループに入る"所定人数以上"と"所定人数未満"の2つに分類します。
図では所定人数を4人として考えています。
以下、"所定人数以上"のクラスタ群をA、"所定人数未満"のクラスタ群をBとします。

次に、クラスタの重心から近い順にAの中から所定人数分取り出し、一旦確定のグループとします(赤枠で赤背景の部分)。
これにより、Aの中で重心から遠く、足切りにされてしまったユーザー群(オレンジ枠)と、そもそも所定人数に達していないクラスタ群Bが残ります。

ここで、Aの足切りユーザー群からBへ人数の振り分けを行います。
Bのどのクラスタに振り分けるか、という基準は、いい方法が見つからなかったのでランダムとしました。(機会があればより良い方法を考えたいです)

最後に、Bに所定人数分のユーザーが補充されたものの、所定人数には余りが出てしまうことがあります。例えば、全体が42人だった場合、所定人数4人では10個のグループができて2人が余ることになります。
こうした場合、そのまま余り同士でグループになると1人だけのグループができてしまう可能性もあるので、所定人数が集まったBも含め、確定したグループの中から再びランダムで選んで1人ずつグループに入れます。
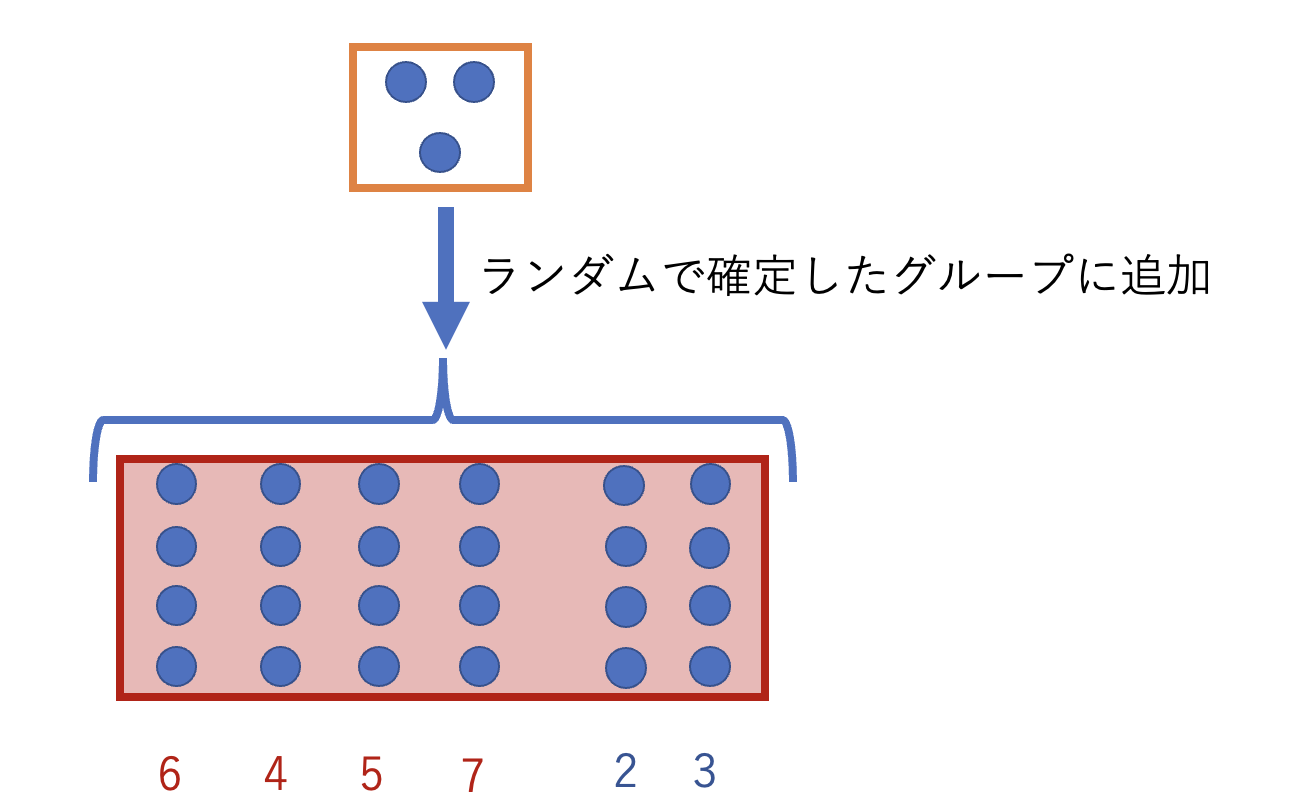
これで人数が均され、他の人と趣味・嗜好が違うために一人飲みを強制されてしまう、というかわいそうな結果を避けることができました。
まとめ
レコメンド機能の実装は、様々な手法を調べてもう少し試行錯誤できればよかったかなと感じています。ただ、その中でもクラスタリング結果の後処理については自分なりに工夫できた点でもあるので、楽しみながら開発ができました。
演習期間を通してデータ分析に触れてみて、データ分析は、各データに対して必ず最適解があり、すべての処理をパターン化できるわけではなく、様々な手法を試しつつ、データに対する妥当性を考えながら進めていくことが重要なのかなと感じました。
本記事で書いた内容は、3週間という期間で実現させたものであり、データの分析結果をどのように活用するのかによって用いる手法・手順は変わるため、レコメンド機能を実装するための数あるやり方の1つとして考えていただけますと幸いです。
明日のレコチョク Advent Calendarは最終日25日目「配属されて3週間の新卒社員がVIPERアーキテクチャのプロダクト開発に参戦した話」です。お楽しみに!
レコメンド機能を実装するにあたり参考にしたサイト
この記事はレコチョクのエンジニアブログの記事を転載したものとなります。