はじめに
以前公開したAIのデモサイト「AI World2」に、7つのデモを追加し、計20デモになりました。スマホでも遊べるので、良かったら触ってみて下さい。
■サイトリンク
AI World
■環境
Python, AWS(Lightsail), Flask, Docker
デモ一覧
以前公開したものも含めた、デモの一覧は以下になります。
| # | タイトル | 内容 | 利用モデル |
|---|---|---|---|
| 1 | Digit Recognition | 異常検知付き手書き文字認識 |
|
| 2 | Image Denoising | ノイズ画像のデノイズ |
|
| 3 | Face Generation | 存在しない人物の顔画像生成 |
|
| 4 | Face Transition | 存在しない人物の顔画像のトランジション |
|
| 5 | Face Manipulation | テキストでの顔画像編集 |
|
| 6 | Human Detection | 画像内の人物検出 |
|
| 7 | Object Detection | 画像内のオブジェクト検出 |
|
| 8 | Image Inpainting | 画像のマスク箇所の再構成 |
|
| 9 | Instance Segmentation | 画像内のオブジェクトのセグメンテーション |
|
| 10 | Image Sampling | シングルショット画像からのサンプリング |
|
| 11 | Text to Image | テキストからの画像生成 |
|
| 12 | Landscape Generation | 風景画像生成 |
|
| 13 | Mask Tracking | 動画でのインスタンスセグメンテーション |
|
| 14 | Anomaly Detection | 欠陥を含む画像の教師なし異常個所検知 |
|
| 15 | Skelton Estimation | 動画内の人物骨格推定 |
|
| 16 | Style Transfer | 画像のスタイル変換 |
|
| 17 | Semantic Segmentation | 画像のセマンティックセグメンテーション |
|
| 18 | Sky Replacement | 動画内の空領域の検知とリプレイス |
|
| 19 | Super Resolution | 画像超解像 |
|
| 20 | Video Inpainting | 動画でのインペインティング |
|
今回追加したデモは、#14-20の7種類になります。
デモ#1-9については「AI World」、デモ#10-13については「AI World2」の過去記事をそれぞれ参照頂ければと思います。
以下、今回追加したデモについて簡単に紹介していきます。
※15, 18, 20の動画デモについてはGIF画像のサイズ制約上、本ページ上は画質がかなり低くなっているので、実際のデモサイトで見て頂ければと思います。
14. Anomaly Detection
こちらはPaDiMを用いた、教師なし異常箇所検知のデモです。
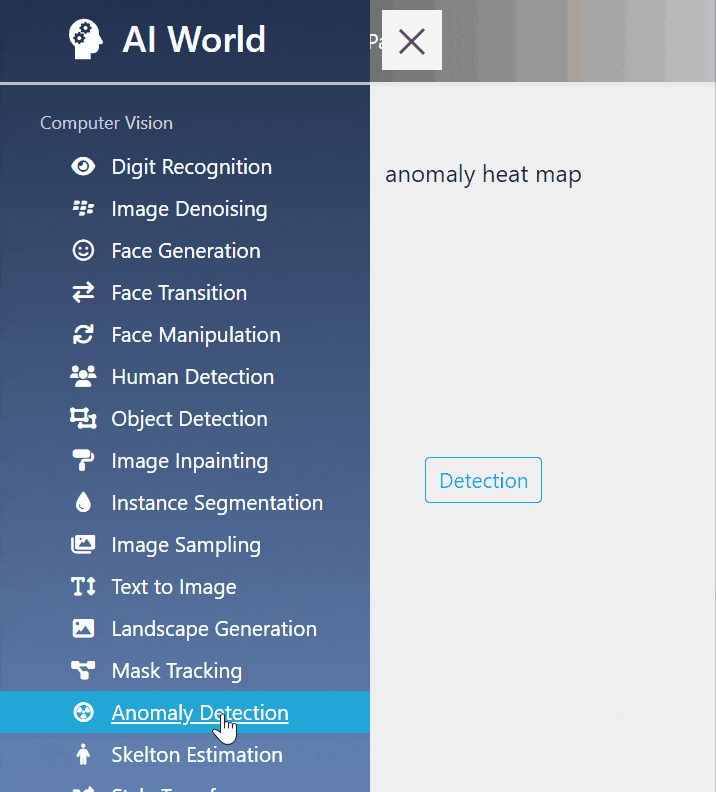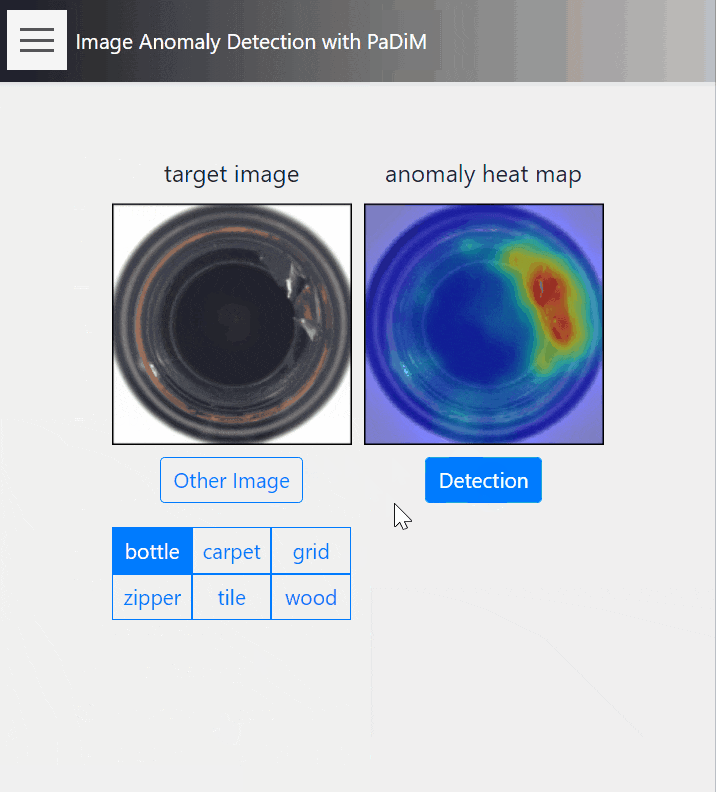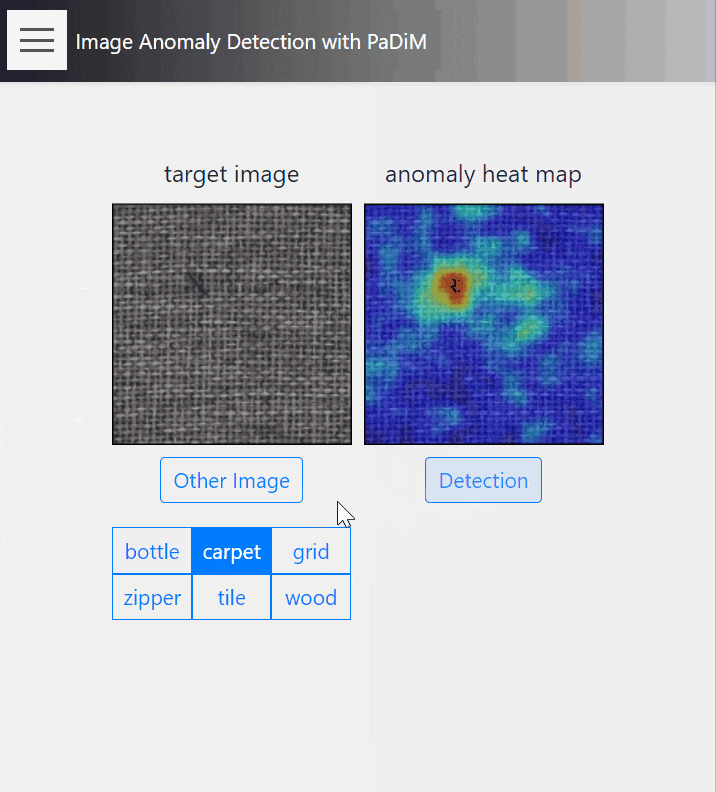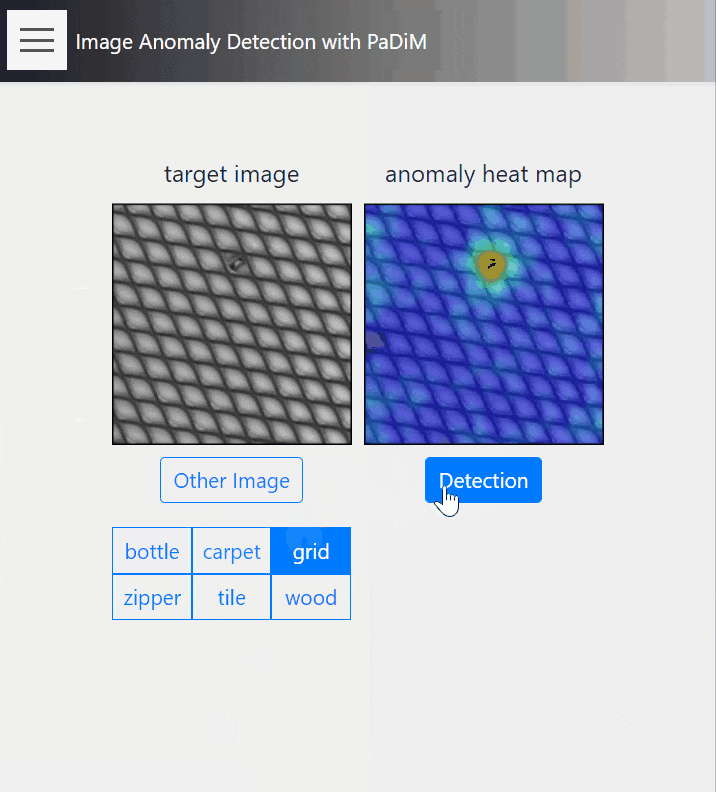
正常画像群から局所領域の埋め込みベクトルを学習し、未知画像に対して、正常画像で学習した埋め込みベクトルからの乖離度で異常の大きさを定義します。学習には正常画像しか使用しないため、汎用性の高い教師なし学習になっています。
自然言語処理でもよく利用される埋め込みですが、改めてその汎用性の高さを感じました。直感的にわかりやすい点も良いですね。
15. Skelton Estimation
こちらはOpenPoseを用いた、動画内の人物の骨格推定のデモです。
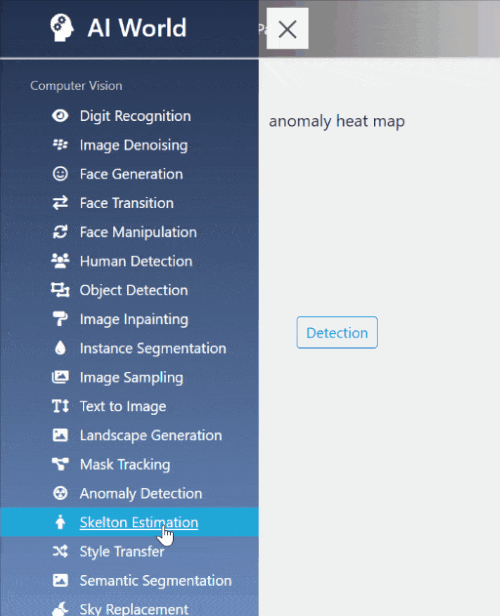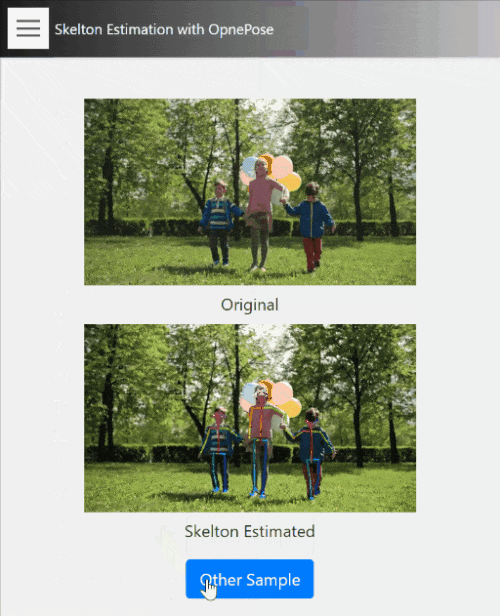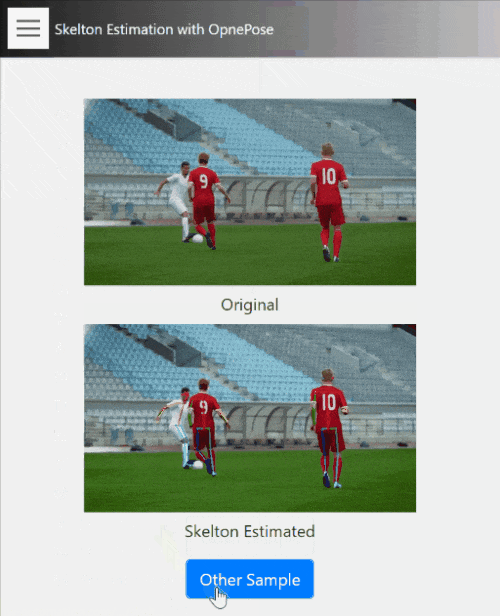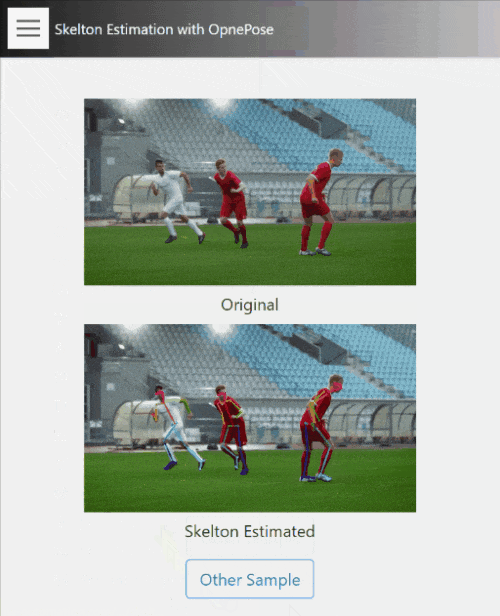
動画内の各人物領域における骨格を推定しています。インプットはあくまで動画のみで、少しわかりにくいですが、顔の輪郭も取れます。
このような一般的な動画に対しても概ね違和感のない推定ができており、目的に応じた適切な撮影環境を用意すれば、姿勢推定などかなり実用的なデータが取れる事がイメージできるかと思います。
16. Style Transfer
こちらはおなじみCycleGANを使った、画像のスタイル変換のデモです。

スタイル変換した画像を元の画像に戻せる制約(サイクル性)を課してGANを学習させる事で、画像の構成自体は変えずに、スタイルだけ変換した画像を生成することができます。やはりpix2pixと違い、1対1の画像を用意しなくても学習できる点が大きな利点ですね。
CycleGANについては馬をシマウマしたり、写真をモネ風にしたりといった画像があまりに有名だったので、かなり限定的なテクスチャ変更しかできないのかなと思っていたのですが、マップを航空写真にしたり、塗り絵のような建物のラベル情報を写真化したりと、想定以上にラディカルな変化にも対応できるという事に少し驚きました。これについては、どこまでいけるのかまた色々と試したいと思います。
17. Semantic Segmentation
こちらはPSPNetを利用した、セマンティックセグメンテーションのデモです。
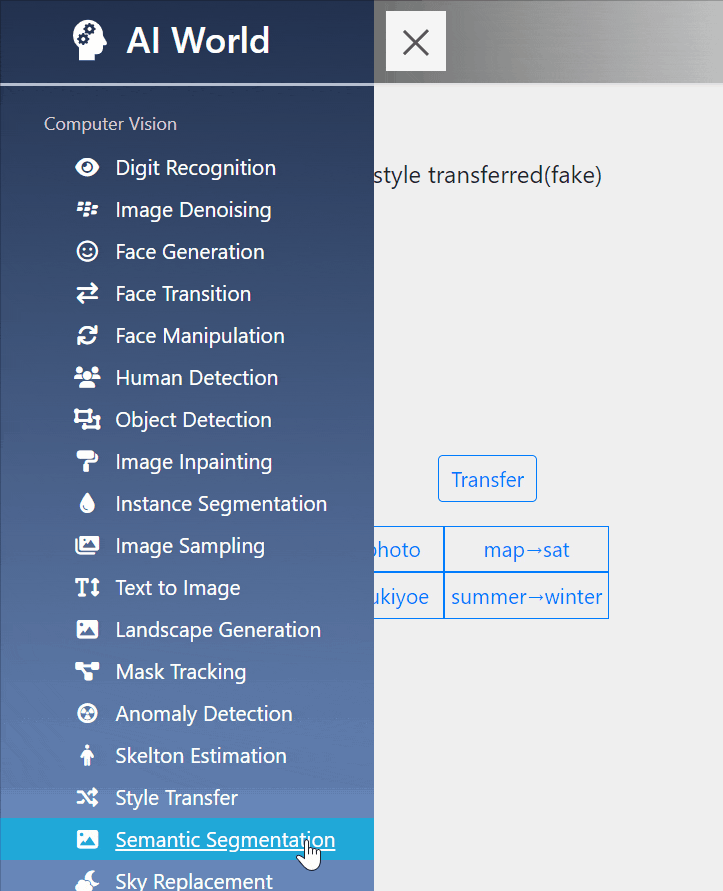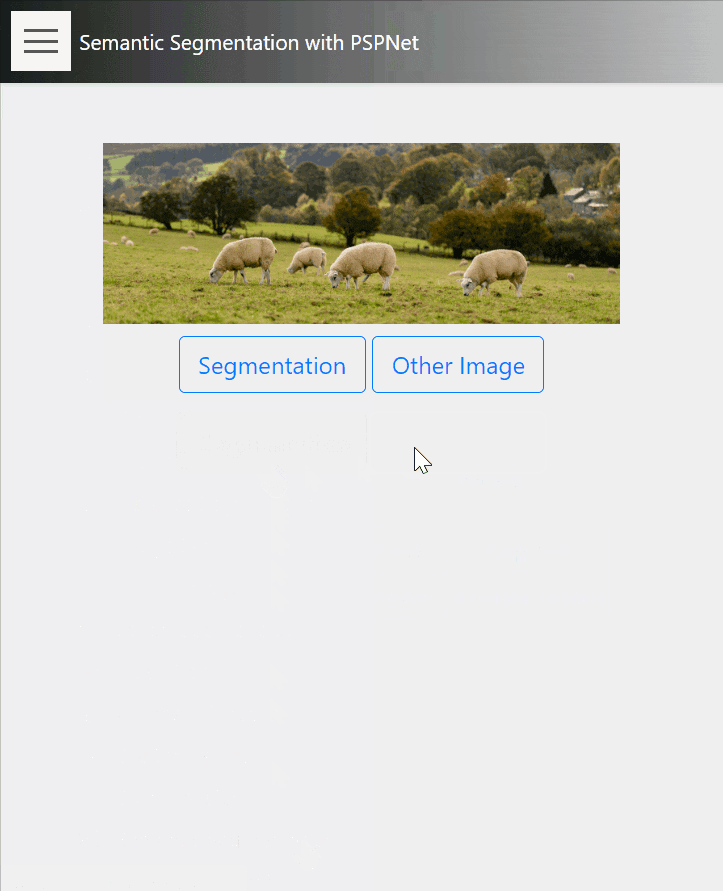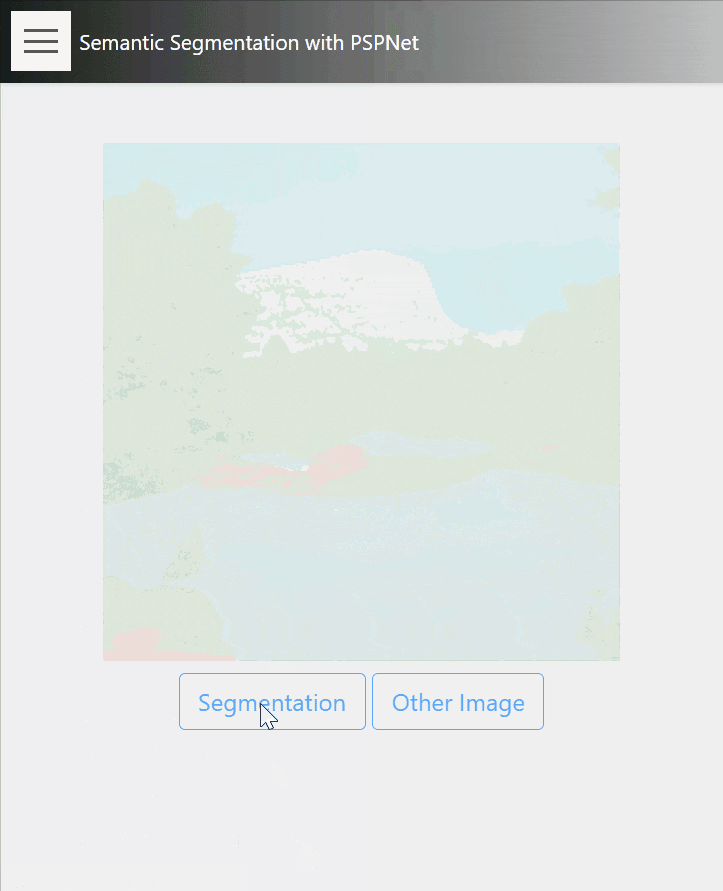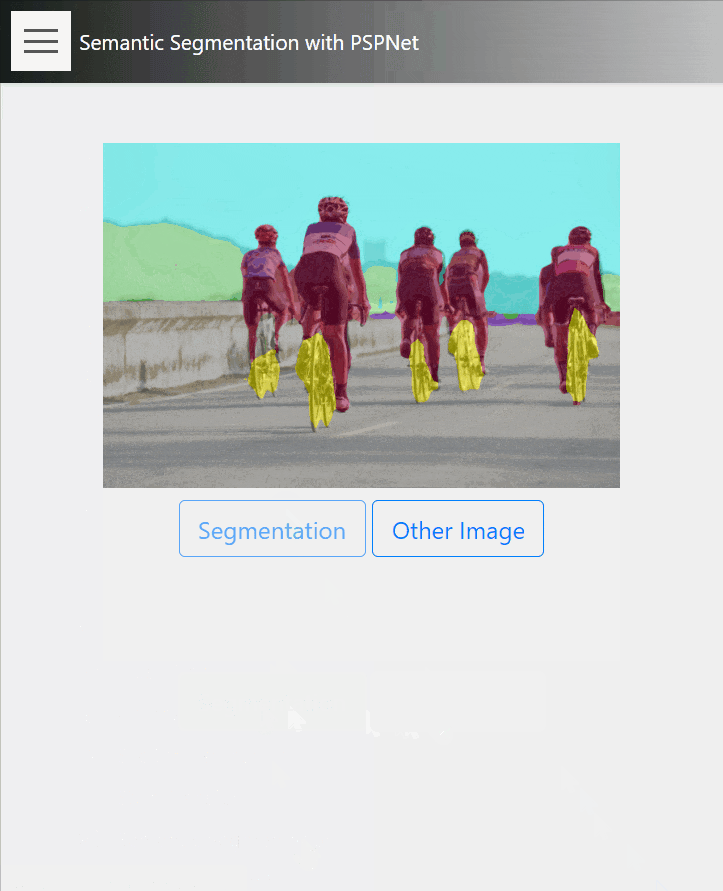
インスタンスセグメンテーションと違い、こちらは画像の全ピクセルがセグメンテーションの対象になっています。
タスク自体の難易度が高いので、汎用的なデータセットで学習したモデルでは、オブジェクトの厳密な境界についてはやはり難しい面があり、学習データの重要性がよくわかるタスクですね。
18. Sky Replacement
こちらはSkyARを利用した、動画内の空の領域の検知とリプレイスのデモです。

左上の「original」が元動画で、元動画に対して空の領域をセグメンテーションで検知し、検知した領域を任意の素材で置き換えています。
単なる素材置き換えだと不自然な動画になってしまうのですが、元動画からモーションも検出し、置き換える素材を元動画と同じモーションで動かす事で、自然なリプレイスを実現しています。
staticが静止画の置き換え、dynamicは動画の置き換えで、こちらもいくつかパターンを用意しているので遊んでみて下さい。
19. Super Resolution
こちらはLIIFを利用した、画像の超解像のデモです。

上がオリジナル画像(128px)で、下は超解像によって解像度を上げた画像(512px)になります。
ぼやけた元画像が超解像によって、くっきりと表示されていることがわかります。
特に顔画像については、おそらく超解像の画像だけ見せられた場合、AIが生成した画像であることに気づかないレベルかと思います。
20. Video Inpainting
こちらはE2FGVIを利用した、動画のインペインティングのデモです。

上がオリジナルの動画で、下はオリジナル動画に対して、オブジェクトにマスクをかけて再構成した動画になります。元動画における人や車が消えていることがわかるかと思います。
1つ目と3つ目はオリジナルの用意されたマスクを利用しましたが、2つ目と4つ目はインスタンスセグメンテーションで自動生成したマスクを使用しています。
インペインティングはマスク生成が非常に面倒なのですが、インスタンスセグメンテーションと組み合わせると、面倒なマスク生成を回避して、動画から任意のオブジェクトを自由に消せそうですね。
まとめ
いかがだったでしょうか。
AIにそこまで詳しくない方でも直感的にわかるように作ったので、少しでも楽しんで頂けたのであれば幸いです。
「16-Style Transfer」「18-Sky Replacement」「20-Video Inpaintng」の3つについては、色々と面白い使い道がありそうだなと思っているので、もう少し深堀りした形で、個別のデモをまた公開できればと思います。
■参考
Qiita記載記事
・AIで遊べるデモサイト「AI World」
・AIで遊べるデモサイト「AI World2」
・Deep Metric Learning
・Deep Learning for Image Denoising
・画像処理で遊べるデモサイト「IP World」
・ホテル暮らしはクラウドである
・AIの実業務適用に必須なHITLという考え方と、HITLを加速させるAI×RPA
・RPAの推進に必須なRPAOpsという考え方
・RPAは誰でも簡単に作れるという罠
・VBAが組める人ならRPAは簡単に作れるという罠
個人ブログ
・キャリア・フレームワークなど