今日は、@Jiny2001です。
国内でも悪用され初めてついに逮捕者が出たDeepFake。本記事はDeepFakeの総まとめです。
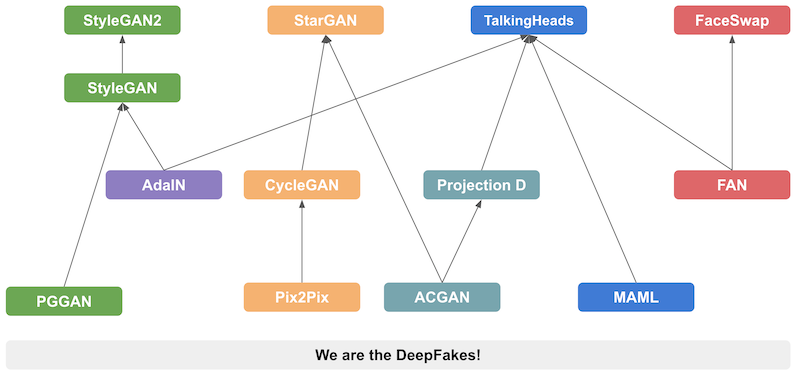
キーになる各技術の仕組みとしてStyleGAN, FaceSwap, StarGAN, Talking Headsについて解説してみました。何故AIがこれだけ進歩してきたのか、この技術部分の理解が超大事だと思ってます。気になるなら是非読んでみて下さい。
そして最後にちょっとだけ、今後のAI発展についての期待を書いてみました。
Too long; didn't read? 1行で要約すると → DeepFake ぱねぇ です。
目次
3) Attribute Manipulation: (StarGAN)
4) Expression Swap: (Talking Heads)
DeepFake系技術の現状
2020年10月2日、なんと国内でDeepFake系技術を使って女優やアイドルの顔をアダルト動画に合成し、ネット上で販売していたとして大学生ら2人が逮捕されています。ネット上で入手したソフトを使って400本以上の動画を作成していたということですから、既に誰でも、ある程度簡単に生産できるほど技術が進んでいるようです。
そして日本でさえこれなら、かの国ではもう無法地帯になってしまってることは想像に難くないですよね...
SensityというスタートアップではDeepFakeで作成された画像や動画を検出する技術を開発・提供しています。彼らによれば2020年6月の時点で既にネット上で4万9000件以上のDeepFake動画を検知したとのこと。画像も含めれば凄い数になりそうですね。
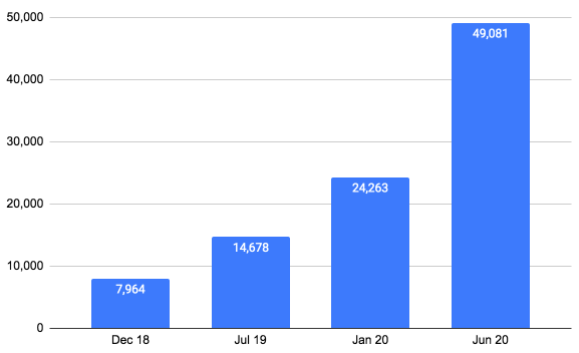
Sensity社 ウェブサイトより - 確認されたDeepFake動画の数の推移
DeepFakeの大まかな技術体系の解説
さてではその技術について踏み込んでいきましょう。2020年1月に公開されたDeepFake系技術のサーベイ論文です。
"DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection"
まずは上記の論文・記事にそって技術体系を大まかに4つに分けてみましょう。図にするとこうなります。
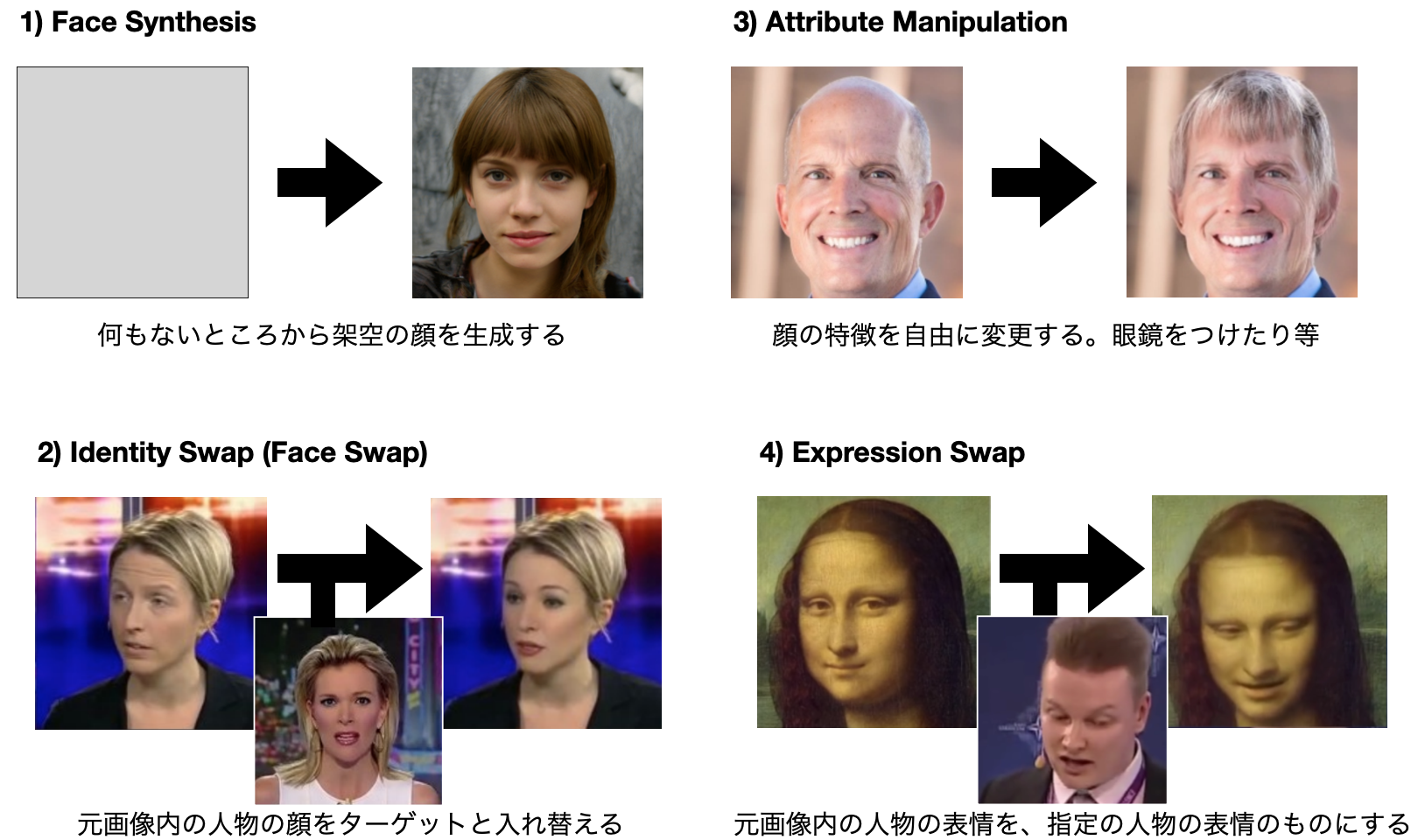
1) Face Synthesis: 完全に新しい顔・シーンを作成する
用途: ゲームでのキャラクター作成や広告用の架空モデルの起用(SNS用偽プロフィール生成)
2) Identity Swap: 2人の顔を入れ替える
用途: 映画製作での撮影(詐欺、ポルノ動画生成)
3) Attribute Manipulation: 顔の特徴 (髪型や性別など)を自由に変更する
用途: 美容・整形外科でのシミュレーション
4) Expression Swap: 表情や顔の動きを自由に変更する
用途: 動画製作・編集・オンラインミーティングやyoutubeのアバター(詐欺)
こうして分けて見ると初期のDeepFakeは 2)でした。Xpression Cameraは 4)なので実は違う技術なんですね。
そして恐ろしいのは、これらを組み合わせて使えることです。例えば架空の顔を作って自分の顔と入れ替えたり(1+2)、他人の顔の性別を変えてからこちらの意のままに喋らせたり(3+4)と、もはや何でもできてしまう感が強いです。
まとめ
こうして見るとDeepFakeと一口に言ってもいろいろありぞれぞれで適用分野も違いますね。しかし適用できる範囲が広く有用なため、恐らく今後も加速度的に技術発達する気がします。次章から各技術の詳細を見ていきましょう。
1) Face Synthesis: (StyleGAN)
Face Synthesisでの草分けはNVIDIAのStyleGANでしょうか。1024x1024の十分な高解像度で生成でき、既にぱっと見で区別するのは難しいレベルに到達しています。
"A Style-Based Generator Architecture for Generative Adversarial Networks"
そして2019年の12月には改良版のStyleGAN2が出ました。前バージョンでは水玉のような不自然なblobが出ることがあったり、目や歯などの小さなパーツが顔の向きとは違う向きで生成されてしまっていた問題を克服しています。

上の写真は StyleGAN2 の論文で示されているサンプルの生成画像です。顔のリアリティは凄いですね。(よく見ると背景の部分はなんか違和感がありますが...)
Style GANではProgressive GrowingやAdaINといったGANやスタイル変換の既存技術をベースに、Stochastic Variationという新規技術を用いることで人間の持っている顔の特徴をラベルなしで抽出しそれを元に復元できるようにしたところが画期的な論文です。
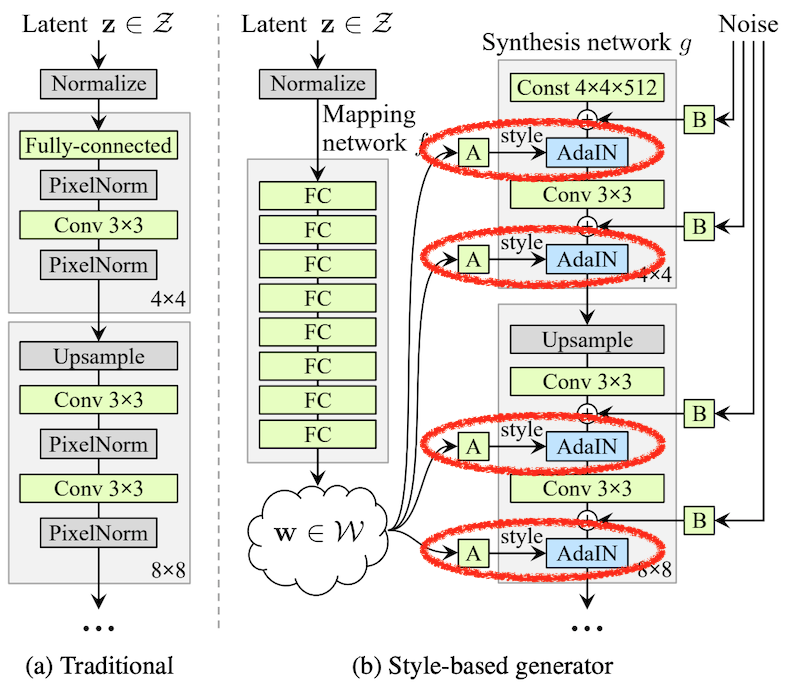
1. Style-based Generator
左側の(a)図が通常のGAN(PG-GAN)、右側の(b)図がStyle GANのGeneratorネットワークです。ポイントは(a)のように顔の特徴として与えられるラテントベクタzから直接顔画像を生成するのではなく、(b)のようにzからスタイル情報wを生成し、これをAdaptive Instance Normalization(AdaIN) レイヤーへのスタイル入力としている点です。
これはスタイル変換の技術・考え方を応用しています。スタイル変換は、例えば下の図で写っている対象[Content]とその表現手法[Style]を分離し、Styleだけを自由に入れ替えできる技術です。

AdaINを使うと入力画像(コンテンツ)の特徴量の平均と分散を、指定したスタイルの特徴量の平均と分散に合わせることができます。例えばBatch Normalizationと比べてみましょう。
\text{BN}(x) = \gamma\left(\frac{x - \mu(x)}{\sigma(x)}\right) + \beta
BNではσ(x)とμ(x)はミニバッチ内のデータから平均と分散が計算されます。その後トレーニング時のデータから学習により最適化されたγとβを用いて正規化します。この正規化によりどのレイヤー・特徴量でも常に一定の分散になるように出力値が調整されるわけです。
\text{AdaIN}(x, y) = \sigma(y)\left(\frac{x - \mu(x)}{\sigma(x)}\right) + \mu(y)
対してAdaINではxに追加してyが引数として与えられます。例えばyにはスタイル画像から得られた特徴量が入力となり、つまりこれによってレイヤー通過後のデータは入力スタイル特徴量の分散・平均となるように調整されるわけです。またσ(x)とμ(x)はミニバッチ内ではなく、一つのデータ、(コンテンツあるいは画像)から得られた値が使われます。これによってスタイルごとに異なった特徴が強調/減衰されます。
\text{AdaIN}(\mathbf{x}_i, \mathbf{y}) = \mathbf{y}_{s, i}\frac{\mathbf{x}_i - \mu(\mathbf{x}_i)}{\sigma(\mathbf{x}_i)} + \mathbf{y}_{b, i},
さて話をStyle GANに戻しましょう。Style GANでは上図の通り、yは直接$y_s$, $y_b$としてwから与えられます。つまりラテントベクタzから8層のFCNであるMapping networkによりスタイル情報 w ($y_s$, $y_b$) を生成し、これを使ってSythesis network gにスタイルをセットします。gへの入力値は定数(ただし一応トレーニングにより最適化される)なので、Generatorの出力画像は各層で足されたノイズに、zから得られたスタイルを適用したものとなります。
2. Stochastic Variation
二つ目のポイントです。この論文の中で最も新規性のある部分だと思います。
顔画像の特徴を顔の向いている方向や顔の大きさなどハイレベルな(大きな)特徴と、髪の生え方や肌のシワ、そばかすなどのローレベルな(細かな)特徴の二つに分けてみましょう。例えばローレベル特徴はどのように変わったとしてもハイレベル特徴さえ変わらなければ同一人物だと認識できるとします。このハイレベル特徴だけを抽出することを、人間のラベル付けを必要とせずにGANを用いて教師なしで学習できるところが最大のポイントです。
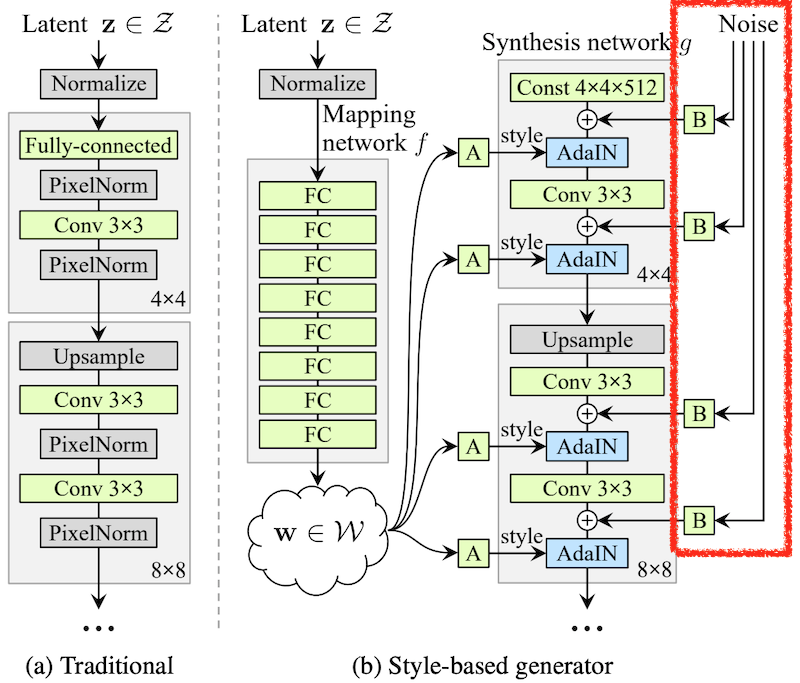
(b)図の一番右側にNoiseとしてラテントベクタzとは別に、各レイヤー+各ピクセルごとに正規分布によるノイズが入力されています。このノイズがローレベル特徴の入力として機能しており、毎回どのように値が変わったとしてもGeneratorは常に自然な画像を作成するようにトレーニングされるわけです。そうするとラテントベクタzからはハイレベル特徴のみを生成し、ノイズからの入力はローカライズを担当するように最適化されるということです。面白い!!
ちなみに図中Bはスケーリングファクターで、一律でその層の全てのノイズの大きさを変更するそうです。これは学習により各レイヤーごとの最適値が決まるとのこと。
3. Progressive Growing
なるほど、仕組みは分かったけれどそんな簡単にGeneratorの8層のフルコネクション+8ブロックのアップサンプリング層が思ったように学習してくれるのでしょうか??
ここでは前進となるPG-GANのProgressive Growingを解説しましょう。今回のStyle GANではトレーニングについての実装やハイパーパラメータ、Discriminatorのアーキテクチャなど大部分をPG-GANをベースにしています。そこから上記の新規アイデアを追加する以外にもアップ/ダウンサンプリング層を単純なニアレストネイバーからローパスフィルタ付きのバイリニアに変更するなど細かい調整も入っているようです。

Progressive Growingのアイデアは、まずGeneratorとDiscriminatorが4x4ブロックだけの最小限のネットワークを作成してトレーニングします。そしてトレーニングが終わったら次に8x8のブロックも足してトレーニングを行ない少しづつ層を増やして学習していくところがポイントです。(ただしファインチューニングとは違って全てのレイヤーのウェイトは常に学習可能)
これにより初期は大きな範囲に影響する解像度の低い部分だけに限定して学習しトレーニングを安定化できます。また一見余分なトレーニングステップを踏まないといけないように見えますが、この事前のステップでは解像度が小さいため全体のトレーニングにかかる時間も少なくでき、これによって最終レイヤーのトレーニングもすぐ収束できるようになるためトータルのトレーニングにかかる時間は1/2から1/6に短縮できるとのこと。ナイス。

また新しいレイヤーを追加する時は前のレイヤーの出力画像をアップサンプリング(Discriminatorではダウンサンプリング)してウェイトをかけて足し込んでいきます。αを最初は0にして徐々に1にすることで両ネットワークの出力を安定させ、かつ最終層に与えるペナルティを徐々に増やせるようになっていて、ネットワークが途中で発散することを徹底的に抑えながら学習するよう工夫されています。そのため途中にBatch Normalization層などがなくても大丈夫になっています。へぇぇ。
実験: Style mixing
さて、Generatorの説明図はずっと上の図中では4x4と8x8のレイヤーしか載っていませんが、実際は4,8,16,...と各レイヤーごとにアップサンプリングされて最終的には全8レイヤーで1024x1024までのブロックが存在します。
そしてスタイル入力とノイズ入力により各サイズの画像が生成されていくわけですが、ここでは実験として4x4と8x8(Coarse)、16x16と32x32(Middle)、64x64から1024x1024(Fine)の各ブロックに与えるスタイル入力をコントロールしてみます。

上図中で左端に上から並んでいるのがソースAで、全てのブロックにスタイルを提供している画像だとします。ここで、Coarse、Middle、Fineの各ブロックに提供するスタイルだけを、最上部に並んでいるソースBと入れ替えたのが上図になります。
Coarseの画像を入れ替えるとそれに合わせて顔の向きや輪郭が変わっています。Middleでは顔の特徴がメインで入れ替わり、Fineでは全体的な色のトーンや肌の質感が入れ替わっています。上の方の解像度が低いレイヤーで大まかな特徴を形作り、段々と解像度を上げながら肉付けしている動作を見てとることができ、なかなか興味深いです。
そしてここでは紹介しませんでしたが本論文ではさらに幾つかの章があってそこでも既存論文の技術を利用しており、他分野での技術革新が結集されています。そういった下支えがあって初めてこの全体のスキームがうまく行くのかもしれませんね。
まとめ
-
写っている物体の種類(コンテンツ)と表現手法(スタイル)を分離・入れ替えできるスタイル変換や、解像度ごとに段階的にちょっとづつ学習するPG-GANなど沢山の既存技術を応用している
-
人の顔からハイレベルな特徴の抽出を教師なしで学習できる新しいアーキテクチャを考案。それにより、顔の輪郭などの大きな特徴から肌の質といった細かな特徴などのレベルごとにうまく分離して学習・復元することが可能になった
2) Identity Swap: (FaceSwap)
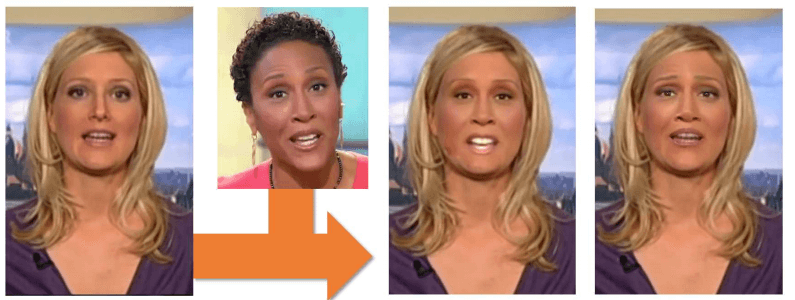
画像の中の人の顔を入れ替えてしまうIdentity Swapです。この中でインパクトが大きいのがFaceSwapでしょう。FaceSwapは論文は公開されていませんが、ソースコードがgithubで公開され、スターが現時点で3万件以上ついています。さらにWindowsやLinux用のフリーソフトまで公開されています。
技術解説はこちらの公式動画を見ると大変分かりやすいのですがここでもさらっと紹介しておきましょう。
顔画像のクロッピング、大きさや向きの正規化
前半の顔画像を動画からクロップしてくる部分は画像処理の手法がイメージしやすいですが、全てDLを使っているのが特徴的です。全体で4つのブロックがあります。
1. Face Detection:

画像の中から顔とその位置を検出します。よくあるやつですね。ResNet、 MTCNN、 S3FD 等のSoTAモデルから選べるようになっているようです。
2. Face Alignment

顔画像から顔の輪郭や目、口の形などのランドマーク座標を抽出します。FANという非常に良くできている論文の技術を使っています。元の顔のランドマーク座標情報を取得し、これを正規化された位置になるようにアフィン変換をかけて元の顔の向きや大きさに寄らず一定の向き・大きさの画像に正規化します。
3. Face Recognition

また、一つの画像内には複数の人物が写っていることが多いので、その中から目的の人物を取り出すために顔認識を行います。例えば上記の画像の二人は良く似ていますが実は別人だったります。顔画像からの人物特徴量を抽出するために、VGGやResNet構造の顔識別器であるVGGFace v1, v2や FaceNetを利用しています。
4. Face Segmentation

そして最後にセグメンテーションを行ってピクセル単位で顔であるか、それとも背景やボディであるかを判定します。使っているネットワークは恐らくVGGベースか、UNetベースのシンプルなモデルです。
これらの4つのネットワークを使って動画やWeb上の画像の中から目的の人物の画像を抽出し、背景を分離して顔の向きなどを正規化したデータセットを作成することができます。
FaceSwapの仕組み
ではいよいよターゲットの顔との入れ替えの仕組みを見ていきましょう。実は基本原理は非常にシンプルで、大変面白いアイデアです。まず、画像を入れ替える二人の人物(Aさん、Bさん)の顔画像データベースを上記の4つのモデルを使って作ります。
 まず入れ替え元のAさん(ソース)の画像だけからオートエンコーダーを使ってAさんの画像を圧縮し符号化してから復元するようトレーニングします。次にBさん(ターゲット)の画像の圧縮・復元もトレーニングします。しかしこの時にエンコーダー部分はモデルは共有しながらトレーニングするようにします。そうするとエンコーダーはAさん、Bさんから顔の表情特徴を抽出し、デコーダーAとBはその表情特徴からAさん、Bさんのそれぞれの顔画像を生成するようになるわけです!
まず入れ替え元のAさん(ソース)の画像だけからオートエンコーダーを使ってAさんの画像を圧縮し符号化してから復元するようトレーニングします。次にBさん(ターゲット)の画像の圧縮・復元もトレーニングします。しかしこの時にエンコーダー部分はモデルは共有しながらトレーニングするようにします。そうするとエンコーダーはAさん、Bさんから顔の表情特徴を抽出し、デコーダーAとBはその表情特徴からAさん、Bさんのそれぞれの顔画像を生成するようになるわけです!
 そして入れ替えたい元画像のAさん(ソース)の画像を抜き出してエンコーダー+デコーダーBに入力するとその元画像に対応するBさんの生成画像が作成されます。
そして入れ替えたい元画像のAさん(ソース)の画像を抜き出してエンコーダー+デコーダーBに入力するとその元画像に対応するBさんの生成画像が作成されます。
得られた画像は既存の画像処理技術を用いてアフィン変換され元画像に合成されます。このときFaceSwapのアプリでは合成時のブラーや輝度をマニュアルで調整できるようになっていますが、そのうちこのような処理も自動でできそうな気がしますね。
公式のフォーラムによれば、オートエンコーダのトレーニングのためにはソースとターゲットでそれぞれ最低で500枚、良い品質を得るためには1,000から10,000枚が必要になるそうです。これだと現状では有名人などWeb上に沢山の画像がある人か、あるいは動画などに顔を出している人に限られそうではありますね。
まとめ
- 4つの既存ディープラーニング技術を用いて高品位な顔抽出・正規化を行います。これが自動・高品位でできてこそです
- エンコーダーを共有することで2者の顔から抽出した表情特徴の表現を共通化しつつ、その特徴からのそれぞれの顔用の復元ネットワークを学習できます
3) Attribute Manipulation: (StarGAN)
人物の属性(性別、年齢、髪型やあごひげや眼鏡の有無など)を自由に変更することができてしまいます。有名なのはFaceAppというモバイルアプリや、SnapChatの性別を入れ替えてしまうフィルターなどでしょうか。

FaceAppのアプリ紹介画像より
ここでは草分けとしてStarGANを解説しましょう。
StarGANとは
顔の特徴を"属性"として考えます。例えば性別属性(男性/女性)、年齢属性(若い/老いた)などいろいろあり、一つの顔には複数の属性を持っています。ここである属性の組(男性/老いた)から別の属性の組(女性/若い)への変換を考えます。ここでは性別2種+年齢2種の組み合わせで4つのトータル属性(ドメイン)があるといましょう。
 従来の技術では(a)左側のように各4つのドメインから別のドメインへの変換にはそれぞれ専用のGeneratorが必要でした。この場合、トグル的な属性が4つあるとすれば全ての組み合わせとしてトータルで $2^4=16$ のドメインが存在します。ドメインの相互変換には全ての組み合わせとして16*(16-1)=240個の変換ネットワークが必要になってしまいます。
従来の技術では(a)左側のように各4つのドメインから別のドメインへの変換にはそれぞれ専用のGeneratorが必要でした。この場合、トグル的な属性が4つあるとすれば全ての組み合わせとしてトータルで $2^4=16$ のドメインが存在します。ドメインの相互変換には全ての組み合わせとして16*(16-1)=240個の変換ネットワークが必要になってしまいます。
(b)上図右側のStarGANでは、**各ドメイン間の相互変更をたった一つのネットワークで行えるようにしたところが画期的な点です。**図がカッコいいですよね... 余談なんですがDeepFakeとかStarGANとかJoJoのスタンド名に出てきそうな中二な名前がエンジニアの心をくすぐるのです。 :)
ドメイン変換の仕組み: CycleGAN
それではStarGANの仕組みをの中で応用されているドメイン変換の技術であるCycleGANを説明しましょう。

CycleGANは、馬とシマウマや、モネ風の風景画と実写画像を相互に変換できるとして話題になった技術です。
まず通常のGANの仕組みを簡略化して下記の図で説明してみましょう。下記ではNoiseからFake Imageを作っています。(図はStarGANの説明図を一部修正したものです)
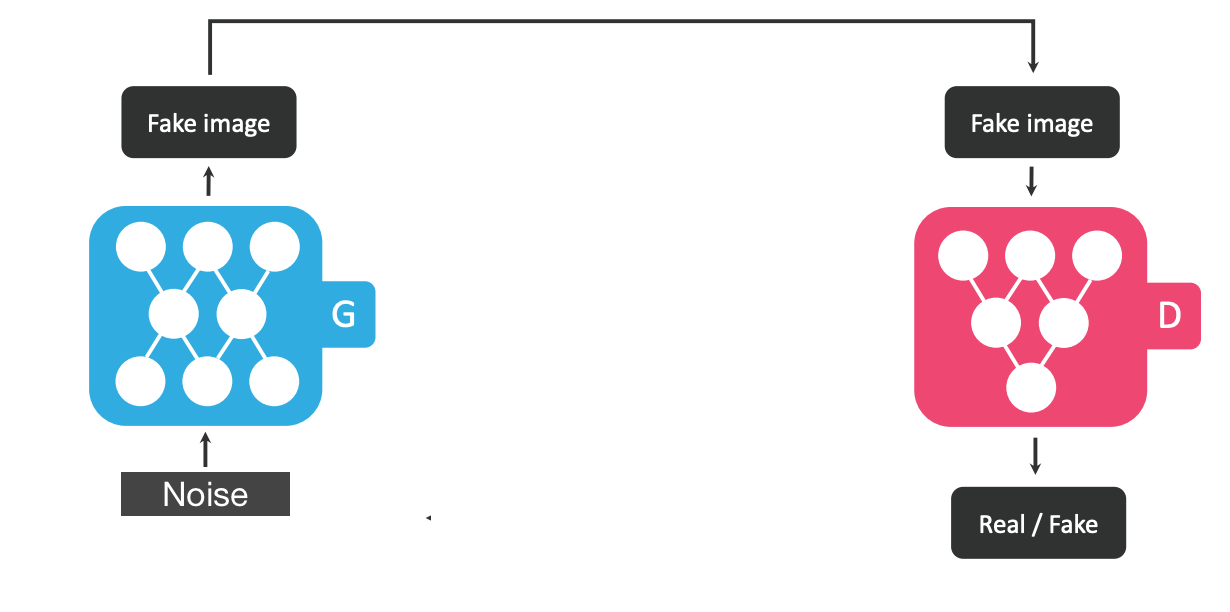
二つのGeneratorによる相互ドメイン変換
では次にこちらの参考図を見て下さい。Gへの入力にはある画像を入れてそこからFake Imageを作成することにします。さらに作成されたFake Imageを元の画像に戻すネットワークFを追加します。

Gの入力とFの出力画像が同じになるようにロスを追加すればこのFはGの逆変換を学習することが期待されます。ここだけ見るとオートエンコーダーと動きが似ていますね。

そして実際のCycleGANの動作が上図です。
ドメインXを持つ画像xをGに入れて、ドメインYを持ち対応する画像G(x)を生成します。このG(x)をFに入れて $\hat{x}$ を生成し、$x$ と $\hat{x}$ が同じになるようにします(サイクル一貫性ロス)。
そして次はGとFの順番を逆にして学習します。すなわちドメインYを持つ画像yをFに入れて、ドメインXを持ち対応する画像F(y)を生成します。このF(y)をGに入れて $\hat{y}$ を生成し、$y$ と $\hat{y}$ も同じになるようにします。
上記に加えてGとFの二つをGeneratorとして交換しながら通常のGANの学習サイクルもまわしてトレーニングします。これによってそれぞれのドメインへの変換Gと逆変換Fを学習しつつ、敵対的学習の効果により精度の高い生成を学習できると言う訳です。
ここだけ見ればGとFの相互変換だけ学習すればDiscriminatorによるGANの学習は必要ないのではとも思うのですが、実験によればこの両輪のサイクルがないとモード崩壊を起こして学習に失敗するケースが増えるらしくてなかなか面白いです。

CycleGANの効用: ペア画像なしでのドメイン変換学習
ちなみに説明が遅くなりましたが実はCycleGANを作ったのは、UCバークレーのPix2Pixという地図画像から航空写真を生成したりスケッチや線画からリアルな画像を生成してしまうモデルを作成したチームでした。
この論文でも同じくGANを使ってドメイン変換を実現しているのですが、それだと下図左のようにそれぞれがペアになる異なったドメインの同じ画像が必要になっていました。ところがCycleGANでは右図のようにペアでないデータでも学習できてしまうという非常に画期的な効果があります。

ドメイン判別 (ACGAN)
さて、StarGANではドメインの変換だけではなく、元の顔画像の各属性(ドメイン)の識別も必要になります。ここではベースとしてACGANを使っています。
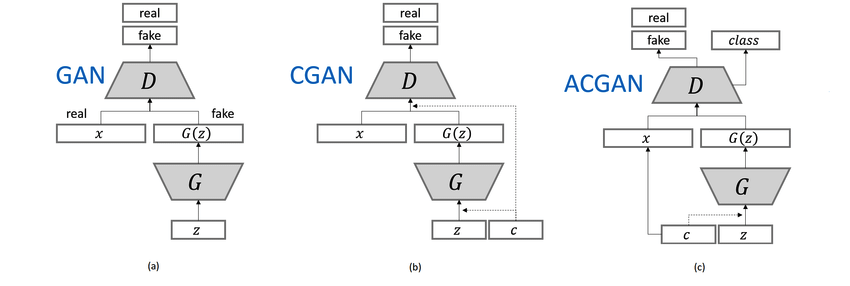 ACGANでは上図右のように、ラテントベクタzだけでなくその画像の属するクラスcも入力として与えています。これは上図中真ん中の[CGAN](https://arxiv.org/abs/1411.1784)(ConditionalGAN)でも同じですね。ただしACGANでのDiscriminatorは真贋だけでなく画像のクラスも出力するようにし、そのロスを加えています。
ACGANでは上図右のように、ラテントベクタzだけでなくその画像の属するクラスcも入力として与えています。これは上図中真ん中の[CGAN](https://arxiv.org/abs/1411.1784)(ConditionalGAN)でも同じですね。ただしACGANでのDiscriminatorは真贋だけでなく画像のクラスも出力するようにし、そのロスを加えています。
クラス情報を与えることで、Generatorは全体の一様な分布ではなく各クラスごとの分布を再現しやすくなり、Discriminatorはクラス識別を行うためにより細部やクラスらしさを判別して高度な真贋の判定ができるようになるのだと思います。
StarGAN
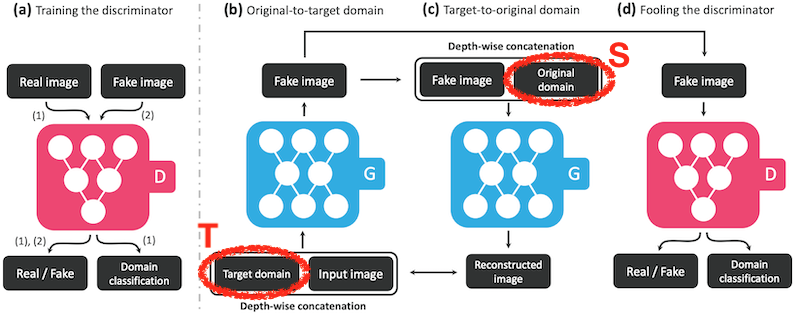 さていよいよStarGANです!
ドメイン判別(ACGAN)の項で見たようにStarGANのDiscriminatorでは上図左(a)のようにドメインの推定を行うようになっています。
さていよいよStarGANです!
ドメイン判別(ACGAN)の項で見たようにStarGANのDiscriminatorでは上図左(a)のようにドメインの推定を行うようになっています。
Generator部分ではCycleGANのものとは違って、GとFの2種類を使うのではなく、一つの同じネットワークGを使います。ただし入力として画像だけでなくその画像を変換したいドメインのクラスを入力として追加します。
入力画像からFake画像を生成する時は生成したいターゲットのドメイン(T)を受け取ります。作成されたFake画像はもう一度Gに入力されますが、この時は元の入力画像(ソース)のドメイン(S)を入力します。Generatorのネットワーク構成は恐らくこちらの超高速でスタイル変換をするモデルを参考にしていると思います。ダウンサンプリングを兼ねたCNN3層+Resisualブロックが6層+デコンボリューションによるアップサンプリングが3層。最後の層以外の全てでInstanceNormalizationが使われています。
そして最終的に以下のロスでトレーニングします。
- Adversarial Loss: Discriminatorが正しく真贋を判別できたかどうか(WGANのロスを利用しています)
- Domain Classification Loss: Discriminatorにリアル画像を入力した場合と、Generatorが作成したFake画像(ドメイン変換後画像)を入れた場合でそれぞれのドメインを正しく判別できたかどうか。
- Reconstruction Loss: Generatorにターゲットのドメインを入れて画像を生成し、その生成画像にソースのドメインを指定して再生成した画像が元のソース画像に近いかどうか
こうして各部がうまく連携してGeneratorは入力画像のドメインが何であれ指定ドメインのターゲット画像を生成し、かつソース画像と一対一の関係になるようにトレーニングできるそうです。
本当にそんなにうまく行くのか?ってうまく行っているから驚きなのですが。本論文では年齢や性別などの属性以外にも表情の変換などを試しておりいろいろ応用できそうです。
まとめ
- 適切なペア画像なしでドメイン変換を学習できる(既存技術)
- 各ドメインへの相互変換器を一つに統合することで、ドメイン(属性)に寄らない同一人物の特徴抽出と、そこからの年齢や性別・表情などによるパーツの生成を学習できています
4) Expression Swap: (Talking Heads)
随分長くなりましたがここでやっと四天王最後のボスキャラが登場します。”Few-Shot Adversarial Learning of Realistic Neural Talking Head Models"です。僕は__Talking Heads__と呼んでいます。
"First Order Motion Model for Image Animation"も非常に良くできているので是非こちらの動画も見て欲しいのですが、ここではメタ・ラーニングの考え方を紹介したいため上記のTalking Headsを解説しましょう。
 この論文ではソース画像(一番左)に対してターゲット画像を指定すると、ターゲットのランドマークを抽出してソース画像をそのランドマークに合う表情に変えてしまうことができます。
この論文ではソース画像(一番左)に対してターゲット画像を指定すると、ターゲットのランドマークを抽出してソース画像をそのランドマークに合う表情に変えてしまうことができます。
 上記の[デモ動画](https://www.youtube.com/watch?v=mDB-KJ8mHeo)を是非見て欲しいのですが、**たった一枚のデータしかない**モナリザの画像から、笑ったり目を閉じたりと違う表情にしたり、顔の向きを違う方向にすることができます。メタ・ラーニングという手法を使って少ない画像でのファインチューニングをできるようにしているところがポイントです。
上記の[デモ動画](https://www.youtube.com/watch?v=mDB-KJ8mHeo)を是非見て欲しいのですが、**たった一枚のデータしかない**モナリザの画像から、笑ったり目を閉じたりと違う表情にしたり、顔の向きを違う方向にすることができます。メタ・ラーニングという手法を使って少ない画像でのファインチューニングをできるようにしているところがポイントです。
TalkingHeads: Embedder ネットワーク
 TalkingHeadsでは3つのネットワークを利用しています。ではまずEmbedderを見てみましょう。
TalkingHeadsでは3つのネットワークを利用しています。ではまずEmbedderを見てみましょう。
Embedderでは人の顔画像とFaceSwapで紹介したFANというモデルを使って抽出したランドマーク情報画像を入力とし、その人間(i)の顔の特徴${e_i}$を出力します。その人間のいろいろな表情・向きの画像に対してEmbedderを適用し、それらの各画像に対しての全ての出力を平均したものをその人間(i)の特徴量$\hat{e}_i$とします。平均することでその向きや表情に寄らない特徴となっているはずとのこと。
また、 ${e_i}$ は後述するDiscriminatorの持つ、各人間(i)に対応する特徴ベクタ(Embedding表現?) ${W_i}$ に近づくようにトレーニングされます。これにも上記のように表情や向きに寄らない特徴を抽出するバイアスになっているのだと思います。
TalkingHeads: Generator ネットワーク
 GeneratorではEmbedderからの出力特徴量$\hat{e}_i$にMLPをかけてスタイルを計算し、StyleGANで紹介したAdaINへの入力としています。本論文では細かな説明がありませんが、[参考として挙げている論文](https://arxiv.org/pdf/1804.04732.pdf)を見るとMLPによって直接各レイヤー・特徴量の分散と平均値を計算しているように見えます。
GeneratorではEmbedderからの出力特徴量$\hat{e}_i$にMLPをかけてスタイルを計算し、StyleGANで紹介したAdaINへの入力としています。本論文では細かな説明がありませんが、[参考として挙げている論文](https://arxiv.org/pdf/1804.04732.pdf)を見るとMLPによって直接各レイヤー・特徴量の分散と平均値を計算しているように見えます。
その人間のクラス特徴$\hat{e}_i$によって調整されたGeneratorは入力としてEmbedderが見たことのない顔画像のランドマークを受け取り、Fake画像(図中Synthesized画像)を生成します。ネットワーク構成は恐らくStarGANと同じくこちらの超高速スタイル変換モデルをベースとして、アップサンプリング/ダウンサンプリングレイヤを改良したり、BNの代わりにAdaINを使ったものだと思われます。
TalkingHeads: Discriminator ネットワーク
 Discriminatorは6つのResBlock+ダウンサンプリングをベースとしたピラミッド型のベクタ出力器と、各人物ごとの異なった特徴ベクタを保持するW行列から構成されます。
Generatorの出力Fake画像かReal画像と、それぞれに対応するランドマーク情報を入力とするほか、W内のその人間のクラス(i)に対応する特徴ベクタ$W_i$を利用しています。
Discriminatorは6つのResBlock+ダウンサンプリングをベースとしたピラミッド型のベクタ出力器と、各人物ごとの異なった特徴ベクタを保持するW行列から構成されます。
Generatorの出力Fake画像かReal画像と、それぞれに対応するランドマーク情報を入力とするほか、W内のその人間のクラス(i)に対応する特徴ベクタ$W_i$を利用しています。
ここでDiscriminatorは入力がReal画像でありかつ、一緒に入力されたランドマーク情報の向きや表情にあっているかのRealism Scoreを出力します。
ここでのポイントは、StarGANで解説したACGANの改良モデルであるProjection Discriminator (by PFN+立命館大学!) のを使っているところです。
 (c) ACGANではDiscriminatorは真贋判定に加えてクラス(ドメイン)情報を出力しその出力がクラスラベルyと合っているかどうかをロスに加えていました。(d) Projection Discriminatorではクラスに対する特徴ベクタy(あるいはEmbedding表現)を持ち、Discriminatorの出力直前のベクタとこの特徴ベクタの内積をとってそれを出力に加えるものです。つまりDiscriminatorは人物の特徴ベクタを推定しそれが入力特徴である$W_i$に近ければ良いということになります。
(c) ACGANではDiscriminatorは真贋判定に加えてクラス(ドメイン)情報を出力しその出力がクラスラベルyと合っているかどうかをロスに加えていました。(d) Projection Discriminatorではクラスに対する特徴ベクタy(あるいはEmbedding表現)を持ち、Discriminatorの出力直前のベクタとこの特徴ベクタの内積をとってそれを出力に加えるものです。つまりDiscriminatorは人物の特徴ベクタを推定しそれが入力特徴である$W_i$に近ければ良いということになります。
そしてTalkingHeadsでのDiscriminatorの出力Dの式は下記になります。
D(\hat{\mathbf{x}}_i(t), \mathbf{y}_i(t), i; \theta, \mathbf{W}, \mathbf{w}_0, b) = \\
\qquad \qquad \qquad \qquad V(\hat{\mathbf{x}}_i(t), \mathbf{y}_i(t); \theta)^T(\mathbf{W}_i + \mathbf{w}_0) + b,
w0、bは人物特徴には寄らないトレーニングパラメータです。ベクタ出力Vと$(W_i+w_0)$の内積をとっているわけで、恐らく$W_i$の部分で指定された人物と近いかどうかが計算され、$w_0$の部分では全般的な人間の顔らしさやランドマーク入力と適合しているかどうかが計算されているのではないかと思います。個人的にはここが凄く大事なポイントです。
TalkingHeads: Loss
EmbedderとGeneratorは次の3つのロスでトレーニングされます。
- Content Loss: Generator出力と対応するReal画像が近いかどうか (Perceptual Lossで判定)
- Adversarial Loss: DiscriminatorがGeneratorの出力画像をRealと判定するかどうか+こちらの論文に載っているFeature Matching Loss。ただしあまり効果はないようなのでここでは説明は割愛します。
- Embedding Match Loss: その人物(i)のEmbedderの出力$e_i$とDiscriminatorモデル内のパラメータ$W_i$が同じかどうか。この項の効能は後述します。
また、Discriminatorは上記の項で見てきたように、Real画像とGeneratorの出力画像+(人物特徴+ランドマーク情報) を用いてRealism Scoreが正しく判定できるようにトレーニングされます。
ファインチューニングの仕組み(メタ・ラーニング)
それではいよいよ最後に、ソース画像(例えばモナリザの画像)が1枚しか無いのに高品位の出力が出せる仕組みを解説しましょう。ここではメタ・ラーニングという考え方が背景にあります。
例えば赤ちゃんが、まず四つん這いで進むことや立って歩くことを学習し終わってこれから階段を登ることを学習する場合を考えます。この時例えば「他人が階段を登っている様子を見てコピーする」「手も使って少しづつ登ることを考える」「大人に体を持ってもらって、階段を登る足の動作だけ訓練する」などいろいろな学習の方法が考えられます。既に学習した技術と新しい問題から、どのような方法を取ればその学習が上手くいくかを導くのがメタ・ラーニングです。
メタ・ラーニングの手法にもいろいろな種類があるのですが、ここでは本論文で引用されているMAML(の最初の論文)を取り上げてみます。興味のある人はこちらのスタンフォード大学の公開講義のシリーズがよくまとまっていてオススメです。
メタ・ラーニング (MAML)
"Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks"はモデルの初期値を調整することでその後の学習(ファインチューニング)をうまくいくようにするというシンプルな考えです。微分可能であればどんなモデルでも、またどんなタスク(分類・回帰・強化学習)にでも応用できます。
 ここで3種類の既存タスクがあったとします。例えば [タスク1:猫と犬を見分ける]、[タスク2:犬の品種を見分ける]、[タスク3:鳥と人間を見分ける] などです。識別器のパラメータをθとします。通常はこのθをデータセット内の各サンプルでのロスを計算して一点に最適化していくわけです。
ここで3種類の既存タスクがあったとします。例えば [タスク1:猫と犬を見分ける]、[タスク2:犬の品種を見分ける]、[タスク3:鳥と人間を見分ける] などです。識別器のパラメータをθとします。通常はこのθをデータセット内の各サンプルでのロスを計算して一点に最適化していくわけです。
MAMLではこのθを、各タスクについて再学習(ファインチューニング)した場合にできるだけ早く学習できるように調整します。現時点のパラメータ位置を $\theta_0$ としましょう。そこからまずタスク1用のデータサンプル $T_1$ を1点(あるいは複数点)取得し、そのサンプルでのロスに対するθの勾配を計算します。その勾配にステップサイズα(学習係数)を乗じてアップデート量 $\alpha\nabla_\theta L_{Ti}(f_\theta)$ を計算し次の $\theta_1'$ を求めます。まぁ通常のSGDによる学習と似ていますね。
そして各 $\theta_1',\theta_2',\theta_3'$ が求まったら、 $\theta_1'$ でのタスク1に対するθの勾配を求め、もう一つのステップサイズβを乗じてアップデート量 $\beta\nabla_\theta L_{Ti}(f_{\theta'_i})$ を求めます。全てのタスク(+もしサンプルを複数点とっていた場合は全てのサンプルで)のアップデート量を求め、総和をとってそれをθに追加します。

全体をまとめたものが上記のステップになります。もっと計算を効率化した改良版もいくつか提案されているので興味があれば見てみて下さい。こうやってモデルのパラメータθを決めておき、新しい見たことのない [タスク4:人間と犬を見分ける] が与えられた場合にそのθを初期値とすることで少ないステップ数でファインチューニングできるということが実験で示されています。
TalkingHeads: ファインチューニング
TalkingHeadsでは上記のメタ・ラーニングの考えを参考にしています。まずは色々な人間のクラスで全体をトレーニングします。その後に下記の流れで新しいソースサンプルだけからファインチューニングすることで、少ないサンプル画像からでも高品位な画像の入れ替えを実現しています。
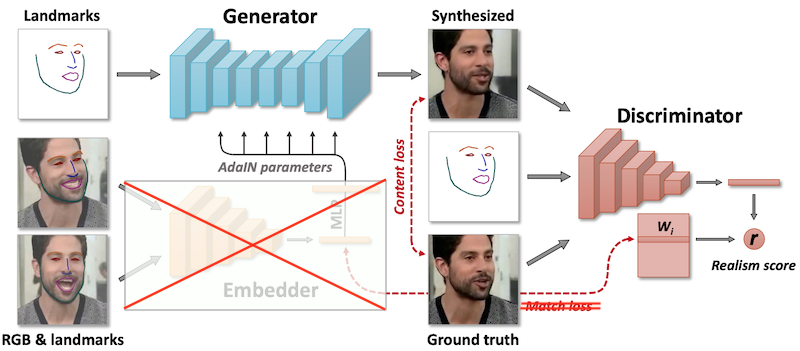
-
新しくファインチューニングしたい人間の画像をEmbedderに入力し、$\hat{e}_{NEW}$ を計算します(画像が複数ある場合はその出力平均値を利用する)。
-
Generatorは $\hat{e}_{NEW}$ からAdaINレイヤーのパラメータを更新します。
-
Discriminatorの $W_i$ は初期値として $\hat{e}_{NEW}$ からコピーします。この時点でEmbedderとその出力は不必要になります。
-
後は通常のサイクルと同じくGeneraotrとDiscriminatorを交互に学習させて行きます。ただしEmbedderはもう使わないため上記で利用していた Embedding Match Loss はここでは使用しません。
まとめ
- 既存技術の応用と統合が上手い(ランドマークのガイド入力やProjectionによる各人のEmbedding表現の獲得)
- Discriminatorでは各人間用のタスク依存の学習とタスクに依存しない学習(一般的な人の顔らしさの識別)に分けた学習ができている
- メタ・ラーニングの仕組みを応用して、見たことのない極少数のサンプル(n=1,8,16)からでも効率よく再学習できる
Ex) DeepFakeを見破る技術
さて、この章では簡単にDeepFakeを見破る技術について紹介しておきます。
1 肉眼で見破る
明らかに画像の一部の明るさが違ったり、あるいはぼやけていたり逆に境界線が見えたりすれば簡単に分かりますが、昨今では後段の画像処理技術の進歩によりなかなか見破るのが難しかったりします。
ですが全集中!すれば分かるポイントも幾つかあります。例えばStyleGANで生成されたDeepFake画像の例をこちらの記事から引用してみましょう。

不自然な点が見つけられますか?
答えは左右の非対称性です。例えば左の画像では髭の左右での濃さが違い、真ん中の画像では左右のイヤリングが違うものになり、右の画像では左右で髪の毛の長さが異なってしまっています。
しかしこういった不自然な点は技術改良によりどんどん克服されています。例えばこの引用した記事では水滴のような不自然なblobができたり歯の向きと顔の向きが一致しないなどの欠点が指摘されていましたが、これらは後の改良版であるStyleGAN2で解決されています。左右の対称性について拘束条件をいれたGANが出てくるのもそう遠くないと想像できます。
2 DeepFakeを検知するAI
歯に歯を、AIにはAIを。これは有望ですね。2019年10月にはAmazon,FacebookがDeepFakeの検出技術の開発をバックアップし始めました。
冒頭で紹介したDeepFakeのサーベイ論文によれば40件以上のDeepFake検出技術(論文)があるようです。多くはCNNによる学習ベースのものですが、例えば2020年1月の時点でIdentity Swap領域でのDeepFake検出論文だけで17件が提案されており、中にはAUC=99.9%とか100.0%というほぼ完全に検知できるものも提案されています。
"Exposing DeepFake Videos By Detecting Face Warping Artifacts”
ただこういった学習ベースの検知技術では対象のFake画像/動画が相当数ないと学習できず、見たことのない新しいDeepFake技術は検出しにくいという弱点があります。つまり高い性能は出せるものの、いたちごっこになりやすいわけです。
3 「DeepFakeを検知するAI」を惑わすAI
実際にGANで修正した痕跡を消し、学習ベースの検知AIの性能を大きく下げる技術が発表されています。GAN-fingerprint Removal、略してGANprintRです。
”GANprintR: Improved Fakes and Evaluation of the State of the Art in Face Manipulation Detection”
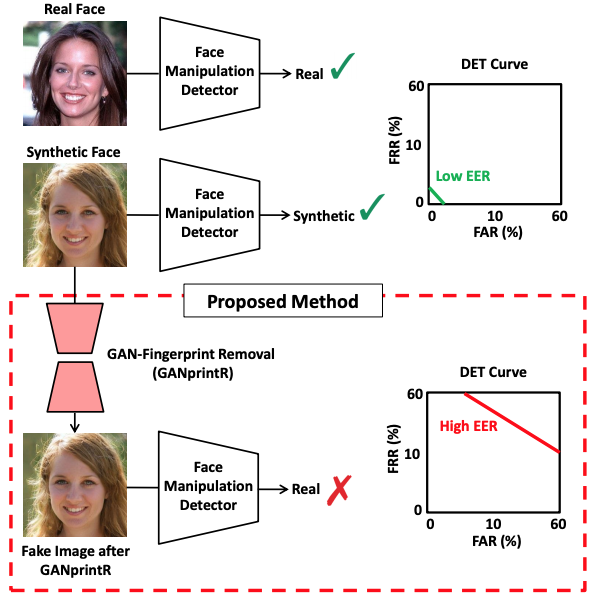
こうなると当然次は、「GANprintRで修正の痕跡が消されたことを検知する」AIが登場するのでしょうか。ワクワクが止まりませんね!(棒)
4 Vital Signを使って見破る
個人的に現時点で有効だと思っているのは、動画や他のセンサーからバイタル(生体)情報を取得して検知する方法です。
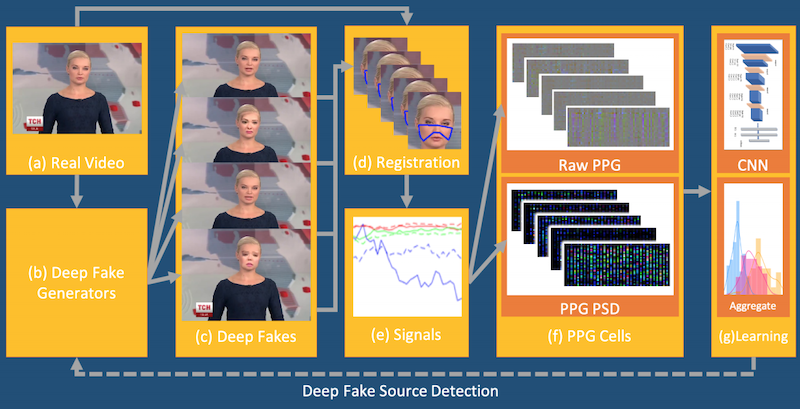
技術の詳細解説についてはもうお腹いっぱいだと思うのでここでは省きますが、簡単に言えば動画の中から同じ人の顔をトラッキングして取り出してきます。そして向きや大きさを正規化し、各画素の時間方向での周期的な輝度の変化から心拍を検出するという技術が核になっています。この周期的変化(PPG)を画素方向に並べてマップを作り、後はそれを画像としてDNNで検出器を作るというわけです。
この方法だと学習ベースではないので未知のDeepFake技術にも対抗できます。また他にもビデオであれば音声情報もあるのでそこから音声にあった動きをしているか検証できるかもしれません。
これに対抗するには元画像の生体情報を検出し、DeepFakeで画像を差し替えてからさらに元の生体情報を復元しないといけません。ただしこれも本質的にはいずれ克服できるだろうと思われる程度の難しさしかないように感じます。また対象が動画でないとだめで、画像には適用できません。
DeepFakeへの対抗策はあるのか?
技術的にはDeepFake画像/動画を見破ることは非常に難しくなっていくと思います。最終的には電子認証データが埋め込まれるようなカメラが普及して、通常のカメラでは証拠能力が無くなったりアップロードが禁止されたりなど、社会システム側の適応により防ぐ方向になるのではないでしょうか?その適応コストが高くても、人類はそれを乗り越えるだろう知恵があると信じます。
人を超えるAIを作るには
ここまで読んでくれた方、お疲れ様でした!
こうして見てみると、主要な4つの技術分野での発展は相互にかつ着実に革新が進んでいることが分かると思います。一見して異なる技術分野でも水面下では多くの既存技術を利用しています。各主要論文についてもここでは載せられなかったもっともっと沢山の土台になる論文があるのです。
他者の技術を取り込んで新たな革新が生まれるスピードは凄まじいです。今までの歴史上にこれほど早く世界中の技術が結晶し発展した実例はあるのでしょうか?
既に一部の性能で見ればAIは部分的に人の為せる技術を超えていると思えます。DeepFakeによる詐欺などの問題はもちろんありますが、オンラインミーティング中でのバーチャル背景やアバターの利用などそれ以上のベネフィットも既に受けているわけです。つまりこの技術発展の流れは今後ますます加速するだろうと感じています。
何を学んで、何を学ばないか
特に各技術について言えることは、__「何を学んで、何を学ばないか」__をうまくコントロールしている点です。人間には意識できないような微細なレベルでの知識化から、同一人物らしさのような抽象的な知識も獲得できているように思います。
またこのDeepFake技術は人間の顔だけにしか適用できないものではなくて、人の全身を入れ替えたり車や風景、部屋のFake画像を生成したりなどいろいろなものに応用できています。言い換えれば、目で見えるものについてならば、うまく学習をガイドすることで各種の知識表現を獲得できる土台ができ始めたということではないでしょうか。
クロスモーダルへの拡大
そしてもちろん画像だけでなく、現在は音声や3Dデータについてのシンセサイズや入れ替えなどのDeepFake系技術も進んでいます。特に音声と動画の組み合わせから得られる情報量は世界を認知するのに十分なも情報を含んでいます。
そしてこれがいずれ触覚や匂いなどデータ化しにくいものにまで拡がるのは間違いありません。
メタ・ラーニング+強化学習にかかる期待
メタ・ラーニングも少しづつ研究が進み始めています。
例えば人間がいろいろな動作を初見でなんでもこなせる理由としては、僕は脳内に高度なシミュレータ(予測器)が存在しているからだと思っています。例えば筋肉をどう動かせば自分の腕を目的の場所に持っていけるかを学習できたとします。すると今度は逆に、自分の腕を動かしたらどうなるのか(近くにあるコップにぶつけて落としてしまうとか)という予測ができることも必要です。人間はこの二つのネットワークを相互に連動させながら動いているような気がしています。
例えば最後に見たTalkingHeadsではEmbedder, Generator, Discriminator の3つのネットワークが相互に連動していたわけです。ちょっと例えは乱暴ですが、実は人間も一つ一つの機能を受け持つネットワークはそんなに複雑ではなくて、それよりもそれをうまく相互運用させて必要な情報のプライオリティづけやネットワークの切り替えがうまいだけかもしれないと感じてます。
既に一つのネットワークをあるタスク用に最適化する技術はだいぶ進んでいる気がするので、ここにメタ・ラーニングと強化学習がはまると凄いことになりそうな気がしているわけです。
最後に
AIはいずれコモディティになるとは良く言われています。もちろんなります。だから勉強なんてしなくて良い、という意見もあります。もちろん普通の人ならAIを勉強しなくても豊かな生活を送れるようにはなるでしょう。
ただしエンジニアにとっては違います!いずれコードを書くかのようにAI(ML)を使いこなせないといけなくなる日々もそう遠くはないかもしれません。
良ければフォローお願いします!! @Jiny2001
引用論文/qiita記事リスト
DeepFake系技術の現状
“Deepfake Detection API: The automated solution for identifying fake faces”
“DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection”
”Deepfakes: Face synthesis with GANs and Autoencoders”
1) Face Synthesis: (StyleGAN)
StyleGAN: “A Style-Based Generator Architecture for Generative Adversarial Networks”
→ qiita 解説記事
StyleGAN2: “Analyzing and Improving the Image Quality of StyleGAN”
→ qiita 解説記事
AdaIN: “Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization”
→ qiita 解説記事
PG-GAN: ”Progressive Growing of GANs for Improved Quality, Stability, and Variation”
→ qiita 解説記事
###2) Identity Swap: (FaceSwap)
FaceSwap: “deepfakes/faceswap”
MTCNN: ”Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks”
S3FD: ”S3FD: Single Shot Scale-invariant Face Detector”
FaceNet: ”FaceNet: A Unified Embedding for Face Recognition and Clustering”
###3) Attribute Manipulation: (StarGAN)
StarGAN: ”StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation”
→ qiita 解説記事
CycleGAN: ”Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”
→ qiita 解説記事
Pix2Pix: ”Image-to-Image Translation with Conditional Adversarial Networks”
→ qiita 解説記事
ACGAN: ”Conditional Image Synthesis with Auxiliary Classifier GANs”
→ qiita 解説記事
“Perceptual Losses for Real-Time Style Transfer and Super-Resolution”
###4) Expression Swap: (Talking Heads)
Taking Heads: ”Few-Shot Adversarial Learning of Realistic Neural Talking Head Models”
"First Order Motion Model for Image Animation"
AdaIN: “Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization”
“Perceptual Losses for Real-Time Style Transfer and Super-Resolution”
“Multimodal Unsupervised Image-to-Image Translation”
Projection Discriminator: “cGANs with Projection Discriminator”
“High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs”
MAML: “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks"
→ qiita 解説記事
###Ex) DeepFakeを見破る技術
"Exposing DeepFake Videos By Detecting Face Warping Artifacts”