TL;DR
StyleGAN2著者らのtensorflow実装で学習・保存された重みを変換してPyTorchで実装したモデルで使用する.
- StyleGAN : 論文, 実装
- StyleGAN2 : 論文, 実装
- 作成した PyTorch実装 (https://github.com/yuuho/stylegans-pytorch)
概要
StyleGAN2はStyleGAN1から色々と変更されている.
StyleGAN2論文中の図でもあるとおり,
StyleGAN1論文でも詳細な実装について説明が省かれていた.
StyleGAN1,StyleGAN2について再現実装をし,
著者オリジナル実装の出力と,実装したモデル(PyTorch)で学習済みの重みを利用したものが,同じ出力になることを確かめた.
また,オリジナル実装ではカスタムCUDA関数を用いて高速化されていたため,
CUDAコンパイル環境が必須であったが,本実装は PyTorch で書き直したためCUDAコンパイル環境は不要である.
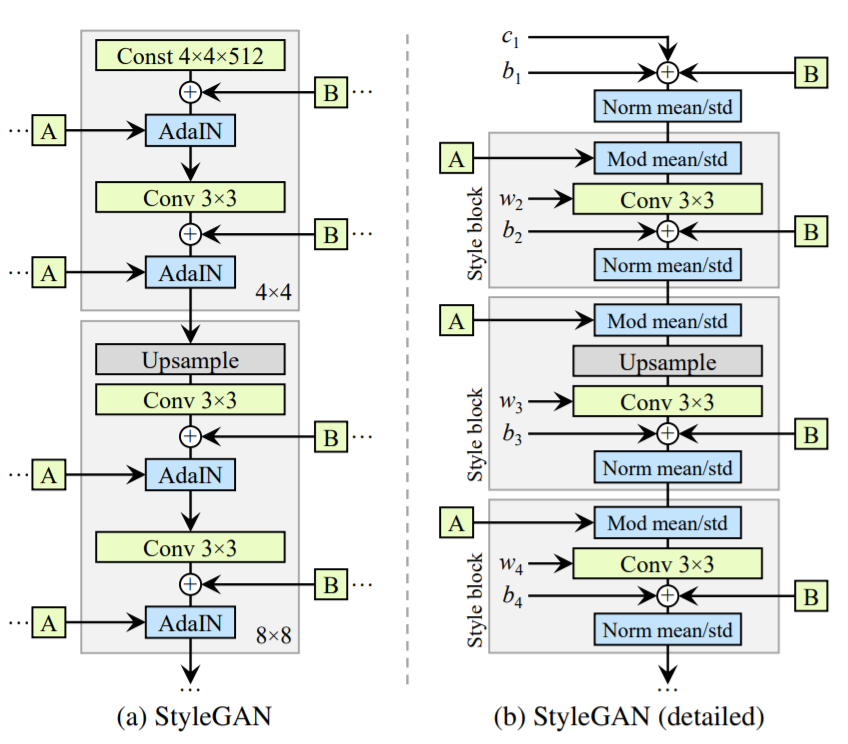
([2] より引用)
(a)はStyleGANv1での構造の説明の図,(b)はStyleGANv2論文でStyleGANv1についてもう少し詳しく説明したときの図
StyleGANとは
高解像度/高品質な画像を生成できることで有名.
よくdisentanglementされており,
各画像をStyleで表現可能.

([2] より引用)
StyleGAN2では畳み込み層で重みを Modulation して利用する
Modulated Convolution が利用されている.
実装
どのように動かしたかは リポジトリ のREADMEに詳しく書いたのでそちらを参照.
- 著者オリジナル実装を利用して,著者配布の重みをnumpy形式に変換して抜き出す.
同時に生成画像とその入力ノイズをファイルに出力しておく. - PyTorchで再現実装したコードに読み込めるようにnumpy形式のものをTensorに変換.
再現実装のほうで画像を出力する
結果だけを載せることとする.
結果
- 著者オリジナル実装 StyleGAN1

- 再現実装 StyleGAN1
- 著者オリジナル実装 StyleGAN2

- 再現実装 StyleGAN2

また,Making Anime Faces With StyleGAN - Gwernで配布されているパラメータを利用することで
二次元キャラクターの顔画像が生成できることも確認した.

気になったところ/勉強になったところ
Modulation
StyleGAN2では畳み込み層の重みはスタイルによって
Modulationされます.
modulationされた重みを
demodulationによってノルム1となるように正規化し,
畳み込みに利用します.
ただし,toRGBではdemodulationは行いません.
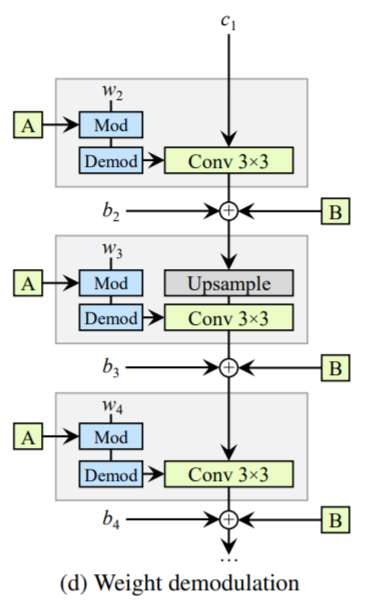
([2] より引用)
AdaIN/Modulationの学習
学習するパラメータは全て平均0になるようにしておきたい(?)
ので,
AdaINやModulationのような
$$ y = \alpha \times x + \beta $$
という式になっているところの
学習するパラメータ $\alpha, \beta$ は
$$ y = (1+\hat{\alpha}) \times x + \beta $$
のようにしておく.
$\hat{\alpha}, \beta$が0のままなら $y=x$ となって具合がよろしい.
これらのパラメータは0で初期化しておく.
信号の増幅
StyleGANの実装を見ていると,
mapping network の各全結合層の後や,
各畳み込み層の後に強制的に特徴マップを $\sqrt{2}$ 倍している箇所がある.
論文で述べられていたか覚えていないですが重要?
StyleGAN1とStyleGAN2で増幅処理している場所が違う.
StyleGANには線形変換な処理が入っている場所が大きく分けて3つある.
(ⅰ) Mapping Network (ⅱ) Conv Blocks (ⅲ) toRGBs
| 場所 | 順番 |
|---|---|
| StyleGAN1 mapping | linear -> gain -> bias |
| StyleGAN2 mapping | linear -> bias -> gain |
| StyleGAN1 conv | conv -> gain -> noise -> bias |
| StyleGAN2 conv | conv -> noise -> bias -> gain |
| StyleGAN1 toRGB | conv -> bias (増幅なし) |
| StyleGAN2 toRGB | conv -> bias (増幅なし) |
画像拡大処理
信号処理的観点から bilinearを使うのが良いらしい[3]が,
bilinear upsampling してconvolutionをするのは計算量的によろしくない.[要出典]
-
nearest-neighbor upsampling してからconvolutionし,ブラーを掛ける
実際,StyleGAN1の実装では低解像度な場所ではそのようにしている.
これもそこまで速くはない? -
転置畳み込み(transposed convolution)を利用する方法
3x3フィルタで転置畳み込みをしたものは,そのままではアーティファクトが
強く出る.
なのでアーティファクトが出ないように出力を1ピクセルずつズラして配置し,足し合わせることでアーティファクトを消し,さらにブラーを掛ける- これは畳み込みフィルタのほうを1ピクセルずつズラして貼り合わせる方法でもOK.(StyleGAN1ではこっちを採用)
linear activation
Progressive GAN から生成器の最終的な出力は
従来の sigmoid や tanh ではなく linear function を使うということが言われています.
実装としては, 1x1 convolution でこれは実現可能です.
(詳しい実装をみると bias ありなので linear ではなく affine ?
数学に詳しくないのでわからないですが,これも linear と呼んで良いのでしょうか?)
潜在変数(入力ノイズ)の正規化
pixel normalizationをしているが,
結局のところ超球面上の一点に投影しているだけである.
ノルムが $1$ になるようにする.
$$\hat{z} \leftarrow \frac{z}{|z |} $$
truncation trick
学習時の mapping network の出力の平均を記録しておく.
学習終了前の何iterationかぶんの平均を平均的なスタイルとしておいて,
学習後の実際の画像生成では低解像度の層に与えるスタイルだけ
平均に寄せる.
単純に線形的に補間するだけ
$$\hat{w} \leftarrow \alpha w + (1- \alpha) \mathbb{E} [w] $$
(truncationする層の個数については後述のStyle Mixing参考)
ノイズの入れ方
StyleGAN1では要素毎にノイズを入れる.
固定ノイズは (H,W) で保持しておいて,
ノイズの重みを (C,) で保持.
StyleGAN2ではピクセル毎にノイズを入れる.
あるピクセルの特徴ベクトルはチャンネルごとに違う値を足すのではなく,
すべてのチャンネルに同じ値を足す.
固定ノイズは (H,W) で保持しておいて,
ノイズの重みを (1,) = スカラー で保持.
equalized learning rate
全ての畳み込み層について学習するパラメータのそれぞれの要素は同じぐらいの勾配の大きさであって欲しい.
フィルタブロックの大きさに応じて適応的に学習するパラメータを定数倍して利用する.
「すべての trainable parameter は同じ値だとしたときに,
すべての線形変換の重みベクトルを同じノルムにしたい.」という状況を考えると
実装が理解しやすい?
畳み込みが 入力チャンネル $c_{\rm i}$ ,出力チャンネル $c_{\rm o}$ ,
カーネル高さ $k_{\rm h}$ ,カーネル幅 $k_{\rm w}$ とすると,
$$ \hat{w} \leftarrow \frac{1}{\sqrt{c_{\rm i} \times k_{\rm h} \times k_{\rm w}}} w $$
と処理する.
また,パラメータの初期化にはHeの初期化を行う.(Progressive GrowingをしているStyleGAN1では特に重要)
その他
Style Mixing
Style Mixingを利用すると複数の画像の持つ特徴を合成した画像を生成できる.

([1] より引用)
前半の層ではスタイルA,後半の層ではスタイルBといったような感じで2つのスタイルを
混ぜ合わせた画像を生成可能.
実装としては,18個ほどある Style Injection において,
最初の4層,真ん中の4層,最後の10層で分けて,
それぞれに別のスタイルを適用する.
学習時の mixing regularization では,ランダムな確率で
それぞれの層に入れるスタイルを別のスタイルに入れ替えて,
それでも本物らしい画像が生成できるように学習させる.
全ての層を独立に動作させるための正則化.
あとがき
StyleGAN2の実装が微妙に間違っていると思う(出力画像の色味が微妙に違う)のですが,
原因箇所が特定できていないので助けていただけるとありがたいです.
わかりにくいところがあれば随時,図などを入れて修正していきます.
参考文献
- 参考にしたPyTorch実装
- 参考にした記事
- 論文
- [1] A Style-Based Generator Architecture for Generative Adversarial Networks [Karras+, CVPR2019/TPAMI2020] (https://doi.org/10.1109/TPAMI.2020.2970919)
- [2] Analyzing and Improving the Image Quality of StyleGAN [Karras+,arXiv2019.12 ](https://arxiv.org/abs/1912.04958)
- [3] Making Convolutional Networks Shift-Invariant Again [Zhang, ICML2019] (http://proceedings.mlr.press/v97/zhang19a.html)
- [4] Progressive Growing of GANs for Improved Quality, Stability, and Variation [Karras+, ICLR2018] (https://openreview.net/forum?id=Hk99zCeAb)
- [5] Deconvolution and Checkerboard Artifacts [Odena+, Distill2016] (https://research.google/pubs/pub46191/)