経緯
最近論文を読んでいて、たまに出てくる単語がありました。AdaINというものです。normalizationの手法の一種という感じで流していましたが、割と出てくる(styleGANやStarGAN v2など)ので論文を読みました。論文自体が2017年のものなので、もしかしたらもっと良い手法が出ているかもしれません。基本的に論文の和訳をしていますが、所々省いたり、まとめたりしています。元論文はこちらです。コードとpretrainedモデルはこちらです。
ざっくりとはどんな論文?(忙しい方へ)
- リアルタイムで任意のstyle transferを可能にするAdaptive instance normalizationという手法を開発しました。
- コンテンツ画像に対するスタイルの様々なコントロールが可能になりました。
0. 要約
これまでstyle transferには低速なiterative optimization processが必要でした。高速なものも提案されましたが、そのネットワークは通常、固定されたスタイルのセットに関連付けされており、任意の新しいスタイルに適応できませんでした。この論文では、シンプルで効果的なアプローチを初めて提示し、リアルタイムで任意のstyle transferを可能にします。私達の手法の中心にあるのは、コンテンツの特徴量の平均と分散をスタイルの特徴量の平均と分散に合わせるAdaptive instance normalization(AdaIN)レイヤーです。事前定義されたスタイルのセットに制限されることなく、既存の最速のアプローチに匹敵する速度を実現しています。さらに、コンテンツスタイルのトレードオフ、スタイルの補間、色と空間のコントロールなど、柔軟なコントロールがすべて単一のfeed-forward neural networkを使用して可能になっています。
補足: style transferについて
style transferとはコンテンツ画像(下の画像の真ん中)の内容と、スタイル画像(下の画像の左)の画風を混ぜ合わせた画像(下の画像の右)を出力するタスクです。左の絵の画風にアレンジされたようなブラピになっています。

1. 導入
Gatysの研究では、Deep neural networkが画像の内容だけでなく、スタイル情報もencodeすることを示しています。さらに、画像のスタイルとコンテンツはある程度分離可能であり、コンテンツを保持したまま画像のスタイルを変更することが可能です。Gatysのstyle transferの手法は、任意の画像のコンテンツとスタイルを組み合わせることができる柔軟性を持っています。しかし、この手法は処理に長い時間がかかります。この問題に対処した最近の研究がいくつかありますが、それらはまだ有限のスタイルセットに限定されているか、または単一のstyle transferの手法よりもはるかに遅いです。本研究では、この柔軟性と速度のジレンマを解決する最初のneural style transferアルゴリズムを提案します。私達の手法はinstance normalization(IN) layerに触発されており、feed-forward style transferにおいて驚くほど効果的です。instance normalizationの成功を説明するために、画像のスタイル情報を伝達することがわかっている特徴量の統計値を正規化することによって、instance normalizationがstyle normalizationを行うという新しい解釈を提案します。この解釈に基づいて、INのシンプルな拡張、Adaptive instance normalization(AdaIN)を導入します。コンテンツ入力とスタイル入力が与えられると、AdaINはシンプルにコンテンツ入力の平均と分散をスタイル入力のものと一致するように調整します。実験により、AdaINは特徴量の統計値を伝達することで、前者の内容と後者のスタイルを効果的に組み合わせていることがわかりました。その時decoder networkは画像空間にAdaINの出力を落とし込むことによって、スタイル化された画像を生成するように学習されます。私達の手法は、入力を任意の新しいスタイルに変換する柔軟性を持ちつつ、Gatysの手法よりも3桁近く高速です。さらに学習プロセスに手を加えることなく、実行時に豊富なユーザコントロールを提供します。
2. 関連研究
Style transfer
Gatysは、DNNの畳み込み層の特徴量の統計値をマッチングさせることで、印象的なstyle transferの結果を初めて示しました。また、Gatysはこちらの論文で色の保存、空間的な位置、sytle transferのスケールをコントロールする方法を提案しています。Gatysらのフレームワークは,損失ネットワークによって計算されたコンテンツ損失とスタイル損失を最小化するために画像を反復的にアップデートする低速な最適化プロセスに基づいています。 最近のGPUでも収束するのに数分かかることがあります。そのため、モバイルアプリケーションでのオンデバイス処理は遅すぎます。一般的な回避策は、最適化プロセスを、同じ目的関数を最小化するように訓練されたfeed-forward neural networkに置き換えることです。このアプローチは、最適化ベースの代替手法に比べて約3桁分速く、リアルタイム・アプリケーションへの扉を開いています。
Deep generative image modeling
画像生成のためのフレームワークには、variational auto-encoders、auto-regressive models、generative adversarial networksなどがある。驚くべきことに、GANは最も印象的なクオリティを実現しています。GANはstyle transferやクロスドメイン画像生成にも応用されています。
3. 背景
3.1. Batch Normalization
IoffeとSzegedyは、特徴量の統計値を正規化することでfeed-forward networkの学習を大幅に容易にするbatch normalization(BN) layerを導入しました。BN layersはもともと識別器の学習が加速されるようにデザインされていますが、画像生成モデリングにも効果的であることもわかっています。BNの式は以下の通りです。
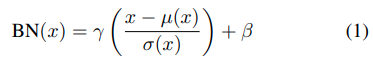
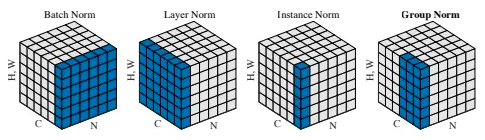
Γとβはデータから学習するaffine parameterです。μ(x)とσ(x)はミニバッチごとの平均値と標準偏差であり、各feature channelごとにバッチサイズと入力の次元にわたって計算されます。下の図の一番左のようなイメージです。参考元
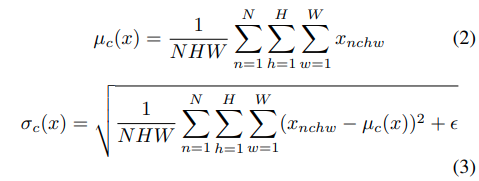
BNについてはこちらの記事に詳しくまとめられています。
3.2. Instance Normalization
style transfer networkはそれぞれの畳み込み層の後にBNを入れ込んでいますが、それをinstance normalization(IN) layersに入れ替えるだけで大きな改善があることがわかりました。
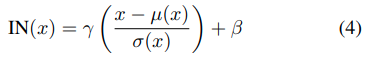
BNと違う点は、各チャンネル独立に画像の縦横方向についてのみ平均・分散を取る点です。下の図の右から2番目のような感じです。
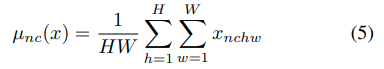
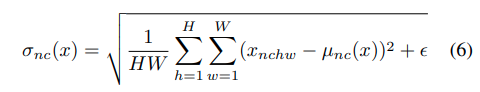
他の違いは、INレイヤーは推論時に変更されずに適用されるのに対し、BNレイヤーは通常、ミニバッチの統計値を母集団の統計値に置き換えます。
3.3. Conditional Instance Normalization
Dumoulinらは、単一のアフィンパラメータγおよびβのセットを学習する代わりに、スタイルsごとに異なるパラメータΓsおよびβsのセットを学習するconditional instance normalization(CIN) layerを提案しました。
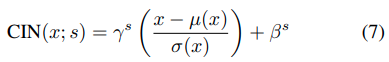
学習の間、sはランダムに選ばれます。コンテンツ画像は、対応するγsとβsがCINレイヤーで使用される、style transfer networkによって処理されます。正規化層のないネットワークと比較して、CIN層のあるネットワークには2FSの追加パラメーターが必要です。Fはネットワーク内のfeature mapsの総数です。追加のパラメーターの数はスタイルの数に比例して変化するため、そのメソッドを拡張して多数のスタイル(たとえば、数万)をモデル化することは困難です。また、彼らのアプローチは、ネットワークを再訓練することなしに、任意の新しいスタイルに適応することはできません。
4. Interpreting Instance Normalization
instance normalizationは大成功を収めていますが、style transferに特にうまく機能する理由はいまいちわかっていません。驚くべきことは、INのaffine parameterが出力画像のスタイルを完全に変更できるという事実です。私達は、instance normalizationが平均と分散を正規化することによって、styleの正規化を実行していると主張します。単一のstyle tranferをINまたはBNを用いて実行した結果が下の図です。(a)は元画像、(b)は輝度チャネルに対して正規化して同じコントラストになった画像、(C)は予めスタイル正規化した画像を使っています。(a)と(b)ではINの有効性が示されているが、(c)ではBNとほとんど変わらない結果となっている。このことからINが一種のスタイル正規化を実行していることがわかります。
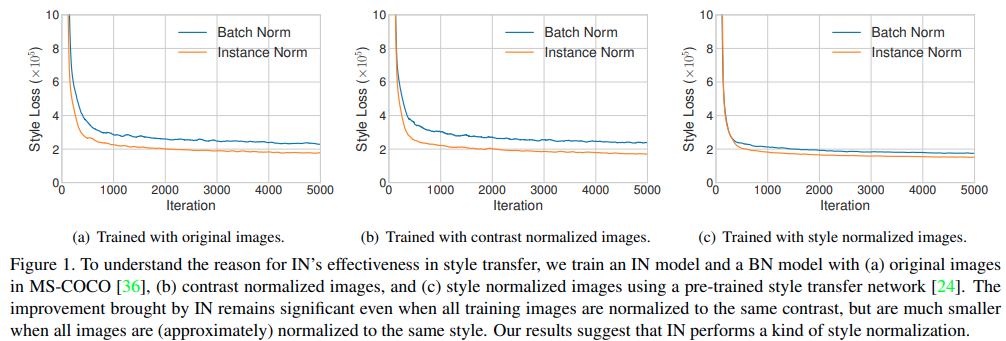
**BNはバッチごとに正規化を行うため、全ての画像を同じスタイルに変換するのには適していません。**それに対して、INは個々のサンプルのスタイルをターゲットスタイルに正規化できます。 残りのネットワークは、元のスタイル情報を破棄しながらコンテンツ操作に集中できるため、トレーニングが容易になります。
5. Adaptive Instance Normalization
ここでは、adaptive instance normalization(AdaIN)と呼ぶ、INのシンプルな拡張を提案します。 AdaINはコンテンツ入力xとスタイル入力yを受け取り、xのチャネルごとの平均と分散を調整して、yのそれらと一致させます。 BN、IN、CINとは異なり、AdaINには学習可能なaffine parameterはありません。 代わりに、スタイル入力からaffine parameterを計算します。正規化されたコンテンツ入力をσ(y)でシンプルにスケーリングし,それをμ(y)でシフトしています。
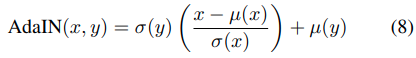
6. 実験のセットアップ
Fig 2は、提案されたAdaIN層に基づくstyle transfer networkの概要を示しています。コードとpretrainedモデルこちらから入手可能です。
6.1. Architecture
私達のstyle transfer network Tは、コンテンツ画像cと任意のスタイル画像sを入力とし、前者のコンテンツと後者のスタイルを再結合した出力画像を合成します。encoder fが事前に訓練されたVGG-19の最初の数層に固定されているシンプルなencoder-decoderアーキテクチャを採用します。コンテンツ画像とスタイル画像を特徴空間にencodeした後,コンテンツfeature mapの平均と分散をスタイルfeature mapの平均と分散に合わせるAdaIN層に両方のfeature mapを送り,目標とするfeature map tを生成します。
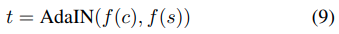
ランダムに初期化されたdecoder gはtを画像空間にマップするようにトレーニングされ、スタイル化されたimage T(c,s)を生成します。

decoderは、checkerboard effectsを減らすために全てのpooling layersをnearest up-samplingに置き換えたencoderを、ほとんどミラーリングしています。border artifactsを避けるためにencoder fとdecoder gの両方でreflection paddingを用います。他の重要な選択としては、decoderがinstance、batchのどちらかをを用いるのか、それともnormalization layersを用いないのかというものです。
補足: checkerboard effectsについて
checkerboard effectsとは、生成した画像に格子状の模様が発生してしまう現象です。具体的には下のような感じです。このような現象が起こる理由とその回避策はこちらにまとめてあります。

6.2. Training
MS-COCOをコンテンツ画像として使用し、主にWikiArtからスタイル画像として収集された絵画のデータセットを使用して、ネットワークをトレーニングします。adam optimizerと8個のcontentとstyle imageペアのバッチサイズを使います。学習中、アスペクト比を維持しながら両方の画像を512に変更し、ランダムに256*256にクロップします。私達のネットワークはfully convolutionalなので、テストのときにどのサイズの画像でも可能です。FCN(Fully Convolutional Network)は、全結合層を持たず、ネットワークが畳み込み層のみで構成されています。decoderを学習させるために、pre-trained VGG19を使って下のloss functionを計算します。

これは、コンテンツ損失Lcとスタイル損失Lsとスタイル損失重みλの重み付きの組み合わせです。コンテンツの損失は、target featureと出力画像のfeature間のユークリッド距離です。
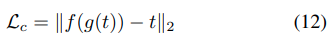
AdaINレイヤーはスタイルフィーチャの平均と標準偏差のみをtransferするため、これらの2乗誤差を計算します。
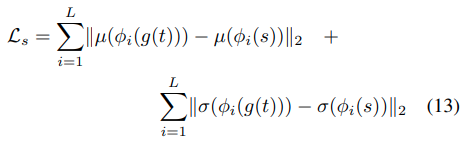
7. Results
7.1. Comparison with other methods
このサブセクションでは、3つのタイプのstyle transferと私たちのアプローチを比較します。(1)柔軟性があるが遅い最適化ベースの方法(Fig 4の1番右)、(2)単一のスタイルに制限された高速feed-forward法(Fig 4の右から2番目)、(3)中速の柔軟なパッチベースの方法(Fig 4の右から3番目)。
Qualitative Examples
各手法とoutput画像を比較したものが下のFIg4です。(1)(2)と比較すると同等か若干劣っています。ただ、速度、柔軟性、品質の間には3者間のトレードオフがあると私たちは考えているので、これは予想外のことではありません。(3)と比較するとほとんどの画像でより忠実にstyle transferを実行しています。

Quantitative evaluations
私たちのアルゴリズムは、速度と柔軟性を高めるためにいくつかの品質をトレードオフしているか、という問題に定量的に答えるために、コンテンツとスタイルの損失に関して、(1)と(2)を使用して比較します。私たちの方法はIN統計に基づくスタイル損失を使用するため、公平な比較のために(1)と(2)の損失関数も変更します。
報告された数値は、WikiArtデータセットとMS-COCOのテストセットからランダムに選択された10のスタイル画像と50のコンテンツ画像の平均です。
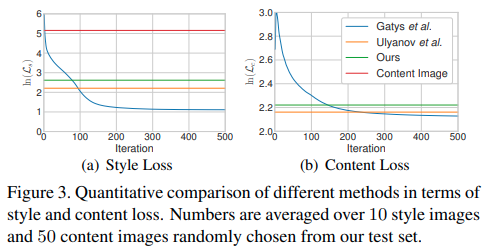
Figure3を見ると私達の方法と(2:図のオレンジ)は少ないiterationで(1:図の青)に近いlossになっています。また、(2)がテストデータで学習しているのに対して、私達のモデルは学習データに含めていないので汎化性能が高いことがわかります。
Speed analysis
私たちの方法の計算のほとんどは、コンテンツのencode、スタイルのencode、およびdocodeに費やされ、それぞれおよそ3分の1の時間がかかります。 動画処理などのアプリケーションでは、スタイル画像を1回だけencodeする必要があり、AdaINは保存されたスタイル統計値を使用して後続のすべての画像を処理できます。 他のいくつかのケース(たとえば、同じコンテンツを異なるスタイルに転送する)では、コンテンツのencodeに費やされた計算を共有できます。
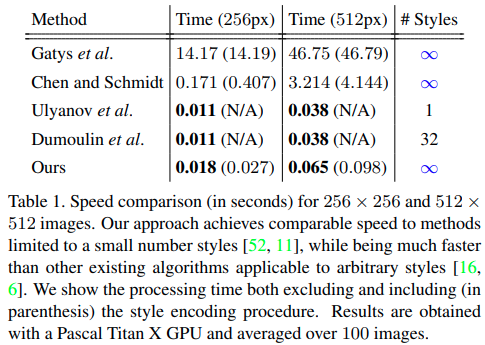
Table 1では、私達の手法の速度を既存の手法と比較します。スタイルencodingの時間を除くと、アルゴリズムは256×256および512×512の画像に対してそれぞれ56および15FPSで実行され、ユーザーがアップロードした任意のスタイルをリアルタイムで処理できます。いくつかの手法より私達の手法がわずかに長いのは、主に手法の問題ではなく、大規模なVGGベースのネットワークが原因です。より効率的なアーキテクチャを使用すると、速度をさらに向上させることができます。
7.2. Additional experiments.
このサブセクションでは、私達の重要な設計上の選択を正当化するために実験を行います。Enc-AdaIN-DecとしてSec6で記述されたアプローチについて特に言及します。AdaINをconcatenationに置き換えたEnc-Concat-Decと呼ばれるモデルを実験します。これは、コンテンツとスタイル画像からの情報を組み合わせるための自然なベースライン戦略です。それに加えて、decoderにBN/IN layersを加えたモデル、Enc-AdaIN-BNDecとEnc-AdaIN-INDecをそれぞれ実験します。学習における他の設定は同じです。Fig5とFig6で比較された方法のtraining curvesとexamplesを示します。

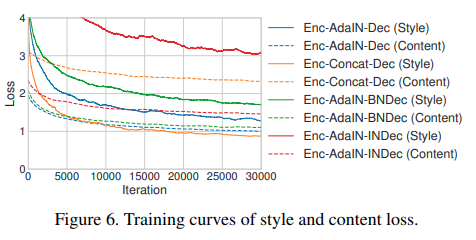
Enc-Concat-Dec baseline (Fig. 5 (d))で生成された画像において、スタイル画像の物体の輪郭(鳥みたいなやつ)ははっきりと見られ、ネットワークがスタイル画像からスタイル情報だけ取り出すことに失敗していると思われます。これはEnc-Concat-Decがstyle lossは低くなっているが、content lossを低くするのに失敗しているFig6にも一致しています。BN/IN layersがあるモデルも画像の質的に悪い結果かつ一貫して高いlossとなっています。IN layersがある結果は特に悪いです。これは、IN layersが単一のstyleの結果を正規化する傾向にあり、異なるstyleにおける画像を生成したいときには避けるべきであるという私達の主張を確認するものになっています。
7.3 Runtime controls
メソッドの柔軟性をさらに強調するために、style transfer networkを使用して、スタイル設定の度合いを制御し、異なるスタイル間を補間し、色を保持しながらstyle transferを行えることを示します。
Content-style trade-off
style weight λ(11の式)を調整することで学習中にstyle transferをコントロールできます。
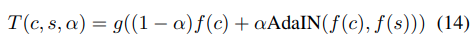
networkはα = 0のとき忠実にコンテンツ画像を再構築し、α = 1のときほとんどスタイル化された画像を生成します。Fig.7で示されるようにαを0から1に変えることによって、content-smilarityとstyle-similarityの間の滑らかな変化が見られます。

Style interpolation
K個の重みwがあるstyle images s1, s2, ...., sKの間を補間するためには、Fig8の結果のようにfeature mapsの間を補間します。
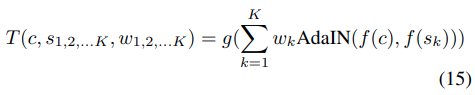
Spatial and color control
コンテンツ画像の色を保持するには、最初にスタイル画像の色分布をコンテンツの色分布と一致させます。次に、色調整されたスタイル画像をスタイル入力として使用して、通常のスタイル転送を実行します。Fig 9がその結果です。

Fig 10では、この方法でコンテンツ画像のさまざまな領域をさまざまなスタイルに転送できることを示しています。

8. 結論
この論文では、リアルタイムでの任意のstyle transferを初めて可能にするAdaIN layerを発表しています。魅力的なアプリケーション以上に、この技術は深い画像表現の理解に光を投げかけると信じています。私達のアプローチのシンプルさを考えると、まだまだ改善の余地があると考えています。今後の研究では、残差アーキテクチャやencoderからのスキップ接続を追加したアーキテクチャなど、より高度なネットワークアーキテクチャを探索する予定です。もう一つの興味深い方向性は、AdaIN を文章合成に適用することです。
感想
これだけ自由自在にstyle transferをコントロールできるのには驚きました。GANでは、男性の顔を少しずつ女性の顔にしたりなど、画像のスタイルをコントロールするものがあるので、AdaINを使う必要性が出てくるのだと思います。
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。