ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽にフォローしてください!
-
EffcientNetV2についても解説しておりますのでこちらもご参照ください!
2021年最強になるか!?最新の画像認識モデルEfficientNetV2を解説
最強の画像認識モデルEfficientNet
2019年5月にGoogle Brainから発表されたモデルで、従来よりかなり少ないパラメータ数で高い精度を叩き出したState-of-The-Artなモデル。その性能の高さからあのKaggleでも早速多用されているとのこと。
2019年10月現在でQiitaにEfficientNetを解説した記事がないのでここでまとめる。
読んでわかりやすかったら、いいねやコメントなどをもらえるとモチベーションになります!
↓元の論文
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).(ICML 2019採択)
著者のGitHubのモデルはこちら(TensorFlow)

論文「EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks」解説
忙しい方へのまとめ
- モデルスケールアップによる精度の向上を研究したらSoTA叩き出したよ
- モデルの「深さ」と「広さ」と「解像度(=入力画像の大きさ)」の3つをバランスよく調整するよ
- ImageNetを含む5つのデータセットでSoTAを叩き出したよ
- しかも従来のモデルよりもパラメータ数がぐんと($\frac{1}{8}$くらい)小さいよ
- そして転移学習にも最適だよ
- その割にモデル(下図)が複雑じゃないよ
0. 要約(Abstract)
ConvNetsにおけるネットワークの深さや広さ、解像度などがモデルの性能にどう影響を及ぼすかを調べ、Compound Coefficient(複合係数) というものを導入することで性能を上げた。これにより作ったEfficientNet-B7はImageNetでSoTAである84.4% top-1 Acc., 97.1% top-5 Acc. を叩き出した。しかも、モデル自体は今までのSoTAモデルと比べて8.4倍も小さく6.1倍も速い。転移学習でもいい結果を残している。この論文ではモデルの大きさに応じてEfficientNet-B0からEfficientNet-B7まである。
1. 導入(Introduction)
モデルの精度をあげるために、そのモデルの大きさをスケールアップするというのは常套手段である。例えば、ResNetはその層の数によってResNet-18からResNet-200まである。GPipeもベースラインモデルから4倍の大きさにすることでSoTAに到達している。
しかし、ConvNetsのスケールアップ方法は多種多様であまり理解が進んでいない。
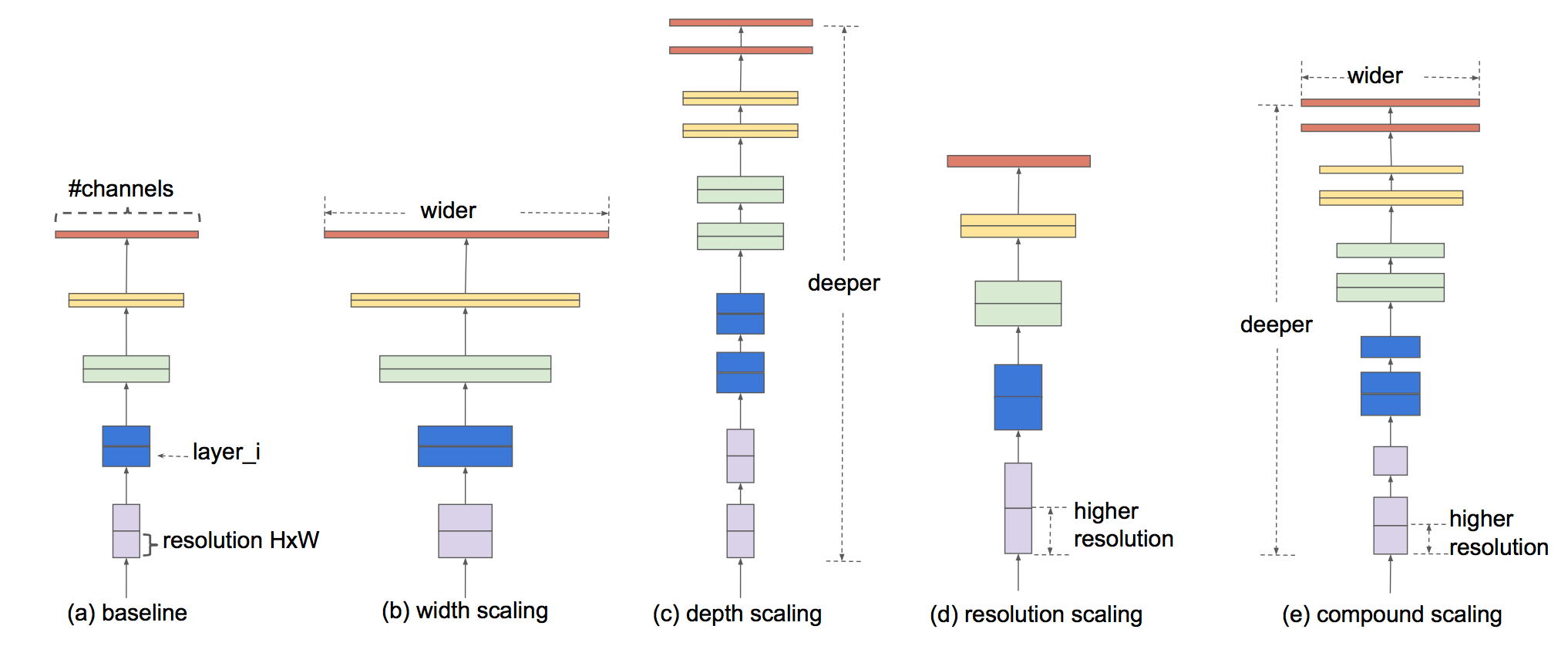
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
モデルのスケールアップにはだいたい以下の3つをいじる。
- 広さ(1レイヤーのサイズ(=カーネル数=出力のchannel数))(上図b)
- 深さ(レイヤーの数)(上図c)
- 解像度(入力画像の大きさ)(上図d)
この論文ではこの3つを使ったConvNetsのスケールアップ方法について深く調べていく。
結論から言うと、各要素をある数で定数倍すれば良いだけ ということが分かった。
例えば、計算リソースが$2^N$倍にできるのであれば、広さと深さと解像度をそれぞれ $\alpha ^N$,$\beta ^N$,$\gamma ^N$ 倍すればいいだけ。これらの $\alpha$, $\beta$,$\gamma$ は元々のモデルに対してグリッドサーチすることで見つかる。
今回の論文ではMobileNet(解説記事は拙著)とResNetのスケールアップと、NAS(=Neural Architecture Search)によって作られた新しいモデルのスケールアップを行なった。この新しいモデルをEfficientNetと呼ぶ。
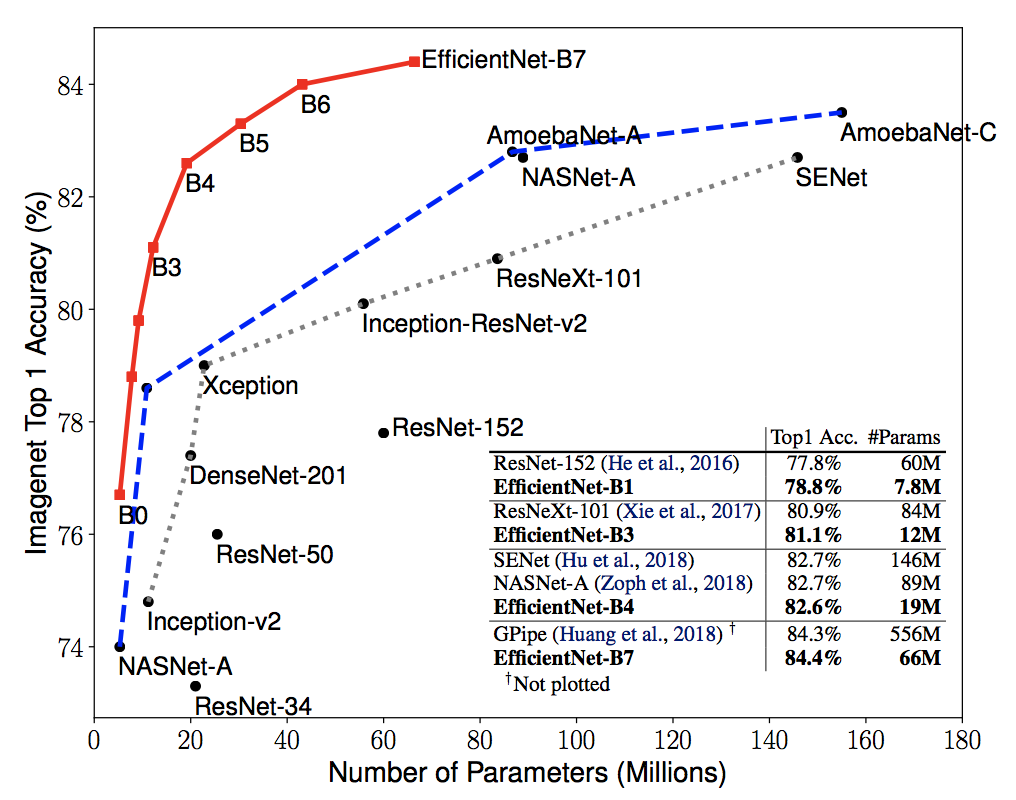
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
上図のグラフとその中のテーブルを見るとEfficientNet(赤線)が小さいパラメータ数で高い精度を叩き出していることがわかる。
要点は以下。
- EfficientNet-B7はSoTAのGPipeに勝る精度でかつパラメータ数が約1/8
- EfficientNet-B4はResNet-50と同じくらいの処理速度で精度が6.3%も高い
- EfficientNetはImageNetを含むよく使われるデータセット8つのうち5つでSoTA
2. 先行研究(Related Work)
2.1 ConvNetの精度(ImageNet)
| モデル | 年 | Top-1 | パラメータ数 |
|---|---|---|---|
| GoogLeNet | 2014 | 74.8 % | 6.8 M |
| SENet | 2017 | 82.7 % | 145 M |
| GPipe | 2018 | 84.3 % | 557 M |
GPipeは大きすぎてハードウェアのメモリに限界がきてしまっている。
そのため、効率的なモデルが求められる。
2.2 ConvNetの効率性
モデル圧縮やハンドクラフトによる効率的なモデル作成などがあったが、近年ではNAS(=Neural Architecture Search)によるモデル作成が性能が良く、流行っている。
この論文ではモデルの広さ、深さ、解像度をいじるモデルスケーリングを使ってConvNetの効率性を高める。
3. Compound Model Scaling(複合モデルスケーリング)
3.1 問題の定式化
繰り返しになるが、モデルスケーリングはあくまで広さ、深さ、解像度を変えるだけで、
レイヤーのアーキテクチャを変えたりはしない。
そのため、いじるのは広さ、深さ、解像度だけで良くなるが、全てのレイヤーでそれらを最適な値にするのはまだ候補が多すぎるため、この論文では、全てのレイヤーの3つの値をある定数倍で同じようにスケーリングしていく。
これを最適化問題として定式化すると、以下のようになる。
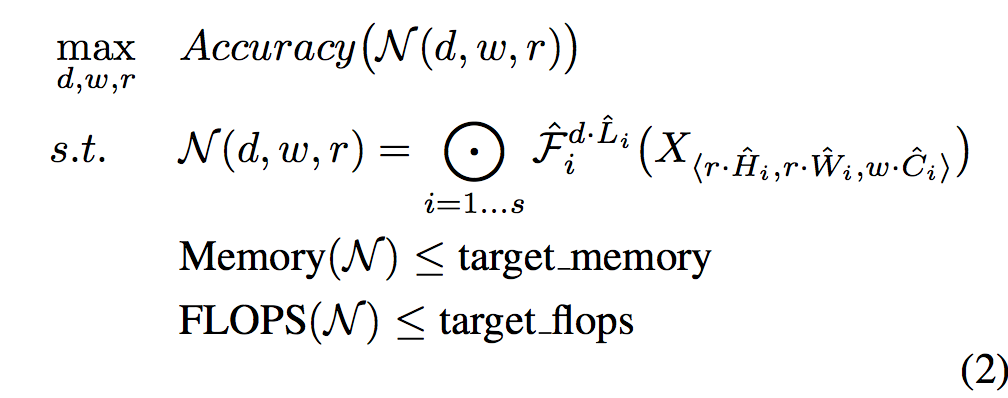
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
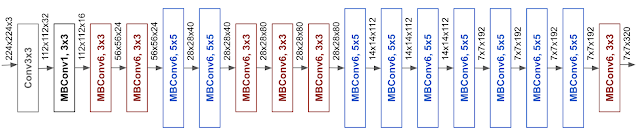
ここで、$\mathcal{N}$ はベースラインのConvNet自体を表しており、$w, d, r$はそれぞれモデルの広さ、深さ、解像度のスケーリング係数(1.導入の例でいうと $\alpha^N, \beta^N, \gamma^N$のこと。)である。それ以外の $\mathcal{F}, \hat{L_i}, \hat{H_i}, \hat{W_i}, \hat{C_i}$ はベースラインのモデルで定義されている値たちで、下表のテーブルみたいな感じ。その下にモデル図を再掲。$\bigodot_{i=1...s}$ はモデル $\mathcal{N}$ がs個のステージ(ブロック)で成り立っているということで、ステージ内では同じレイヤーが $d \cdot \hat{L_i}$ 回繰り返されている。
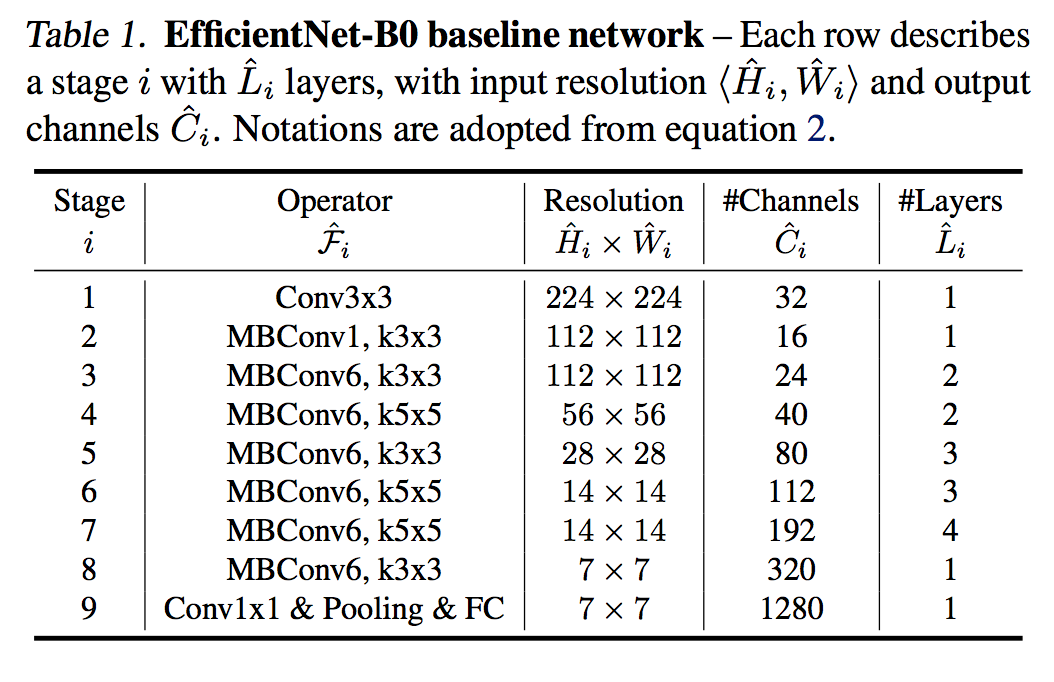
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
3.2 深さ、広さ、解像度による精度の変化
深さ、広さ、解像度(以降, $d, w, r$ )はそれぞれ関係しあっており、使用できるリソースによってそれぞれの値が変化されるべき。この節ではまず各パラメータを変化させた時の精度の違いを見る。なお、ここで使っているモデルはEfficientNet-B0(上記表を参照)である。
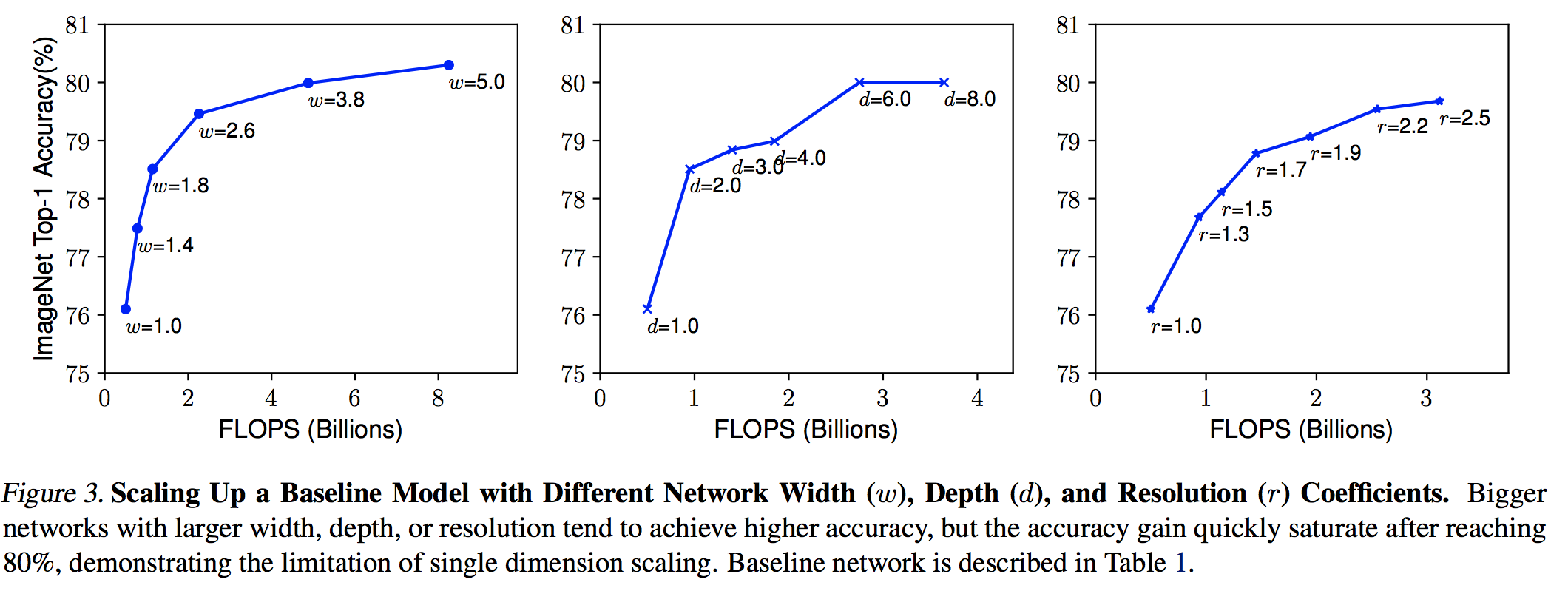
実験結果は以下の図のようになり、それぞれを簡単に解説する。
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
-
広さ$w$ (左図)
レイヤーのサイズ(=カーネル数=出力のchannel数)。
小型端末用の小さなモデルの精度をあげるときに広さを調整する。
広いモデルはより細かな特徴を取ることができるが、極端に広くて浅いモデルはハイレベルの特徴量を掴むのが難しい。上左図の実験結果によると 広いモデル(大きい$w$)は精度が高くなるが、すぐに飽和してしまう。 -
深さ$d$ (真ん中図)
レイヤーの数。
モデルの精度をあげる際に最も一般的な方法。
深いモデルは複雑な特徴量も掴むことができ、他のタスクに対する汎化性能も高い。ただ、ResNet-1000とResNet-101がほぼ同じような精度を持つように、深すぎるモデルではあまり精度向上が得られなくなってしまう。
上真ん中図でも 深いモデル(大きい$d$)に対して精度の向上があまり見られないことがわかる。 -
解像度$r$ (右図)
インプット画像の縦横の大きさ。
インプット画像の解像度が高いと、モデルはより細かなパターンまで認識することができる。上右図において、解像度が高いモデル(大きい$r$)の精度が上がっていることは確認できるが、そのゲインはだんだんと小さくなっている ことがわかる。
[この節のまとめ]
スケールアップによって精度はあがるものの、モデルが大きくなるとその恩恵を受けづらい。
3.3 Compound Scaling(複合スケーリング)
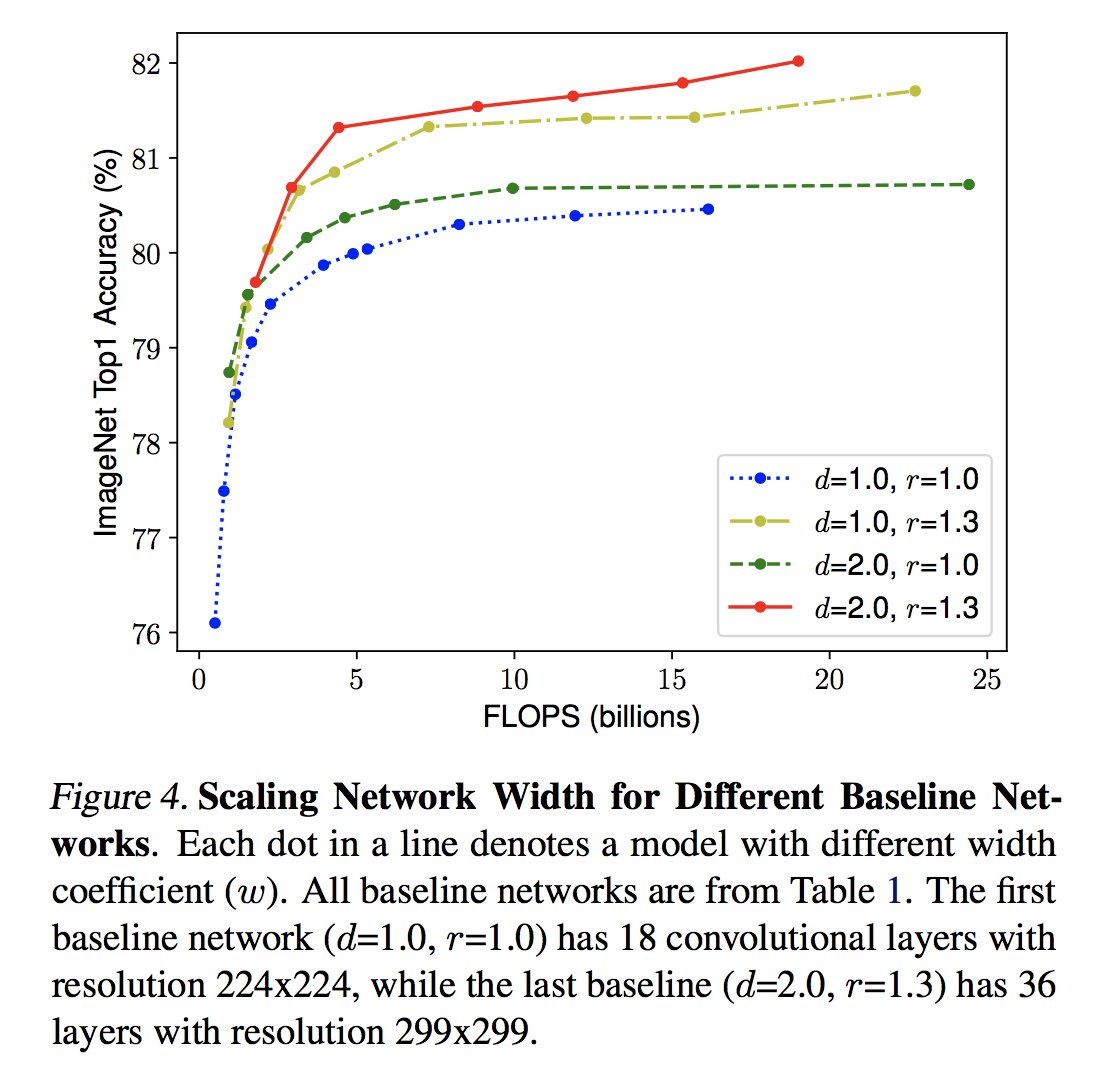
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
上図の実験結果から同じ広さでも深くかつ高い解像度を持つものの方が高い精度を出していることがわかる。そして、3つのパラメータはそれぞれ関係しあっているため、従来のように別々にスケーリングするのではなく、3つのバランスをとりながらスケーリングをしなければならない。
そのため、この論文ではcompound scaling method なるものを提案している。
ユーザーが決めるcompound coefficient $\phi$ で広さ、深さ、解像度を下式のように全て同じように決定する というもの。
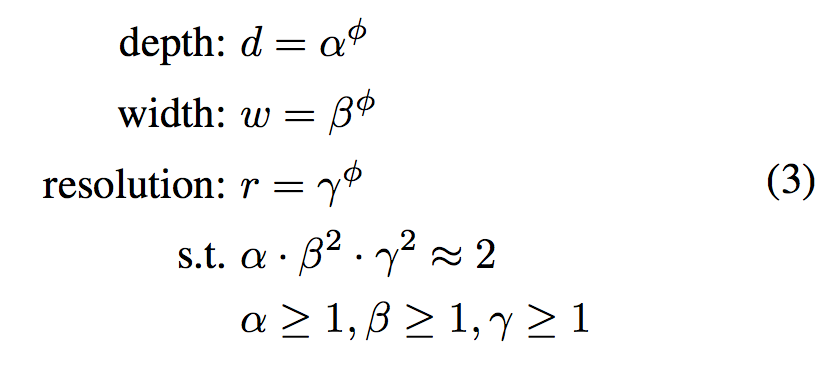
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
ここで $\alpha, \beta, \gamma$ はグリッドサーチによって決まる定数で、$\phi$ は前述したようにユーザーが使えるリソースに従って決める値。ただし、このときに深さが2倍になった時はFLOPSが2倍になり、広さと解像度が2倍になった時はFLOPSは2乗の4倍になってしまう。つまり、上の式で FLOPSは $(\alpha \cdot \beta^2 \cdot \gamma^2)^\phi$ に従って増えてしまうため、$\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2$にすることで増え方を $2^\phi$ で増えるようにした。
4.EfficientNetのアーキテクチャ
モデルスケーリングはレイヤー自体の処理は変えないため、ベースラインのモデルは精度が高いものであることも大切である。そのため、この論文では繰り返しになるが、NASによるベースラインのモデル構築 を行なった。そのモデルの作り方はこの論文に則っているため、EfficientNet-B0はその論文で提案されているMnasNetとほぼ同じ。モデルのアーキテクチャは再掲になるが下表。ここでMBConvというのはMoble Inverted BottleneckにSEモジュールを追加したもので、MobileNet-v3にも使われている。(詳細は拙著)
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
このモデルをベースラインとして以下のステップでスケールアップした。
- STEP1: $\phi=1$として、式(2)と式(3)を使って $\alpha, \beta, \gamma$に対してグリッドサーチをすることで、EfficientNet-B0に対しては $\alpha=1.2, \beta=1.1, \gamma=1.15$ が最適な値
- STEP2: あとは $\alpha, \beta, \gamma$ を定数として固定して、式(3)において $\phi$ を変更することでスケールアップ(B1-B7までモデルを作成。)
5.実験
5.1 MobileNetsとResNetのスケールアップ(ImageNet)
まず、EfficientNetに行く前に従来からよく使用されているMobileNetとResNetに複合スケーリングを適用し、その効果を見る。それが下の表。複合スケーリングにより1つのパラメータのスケーリングよりも精度が上がっていることから、既存のConvNetsに対して複合スケーリングが有効的であることがわかる。
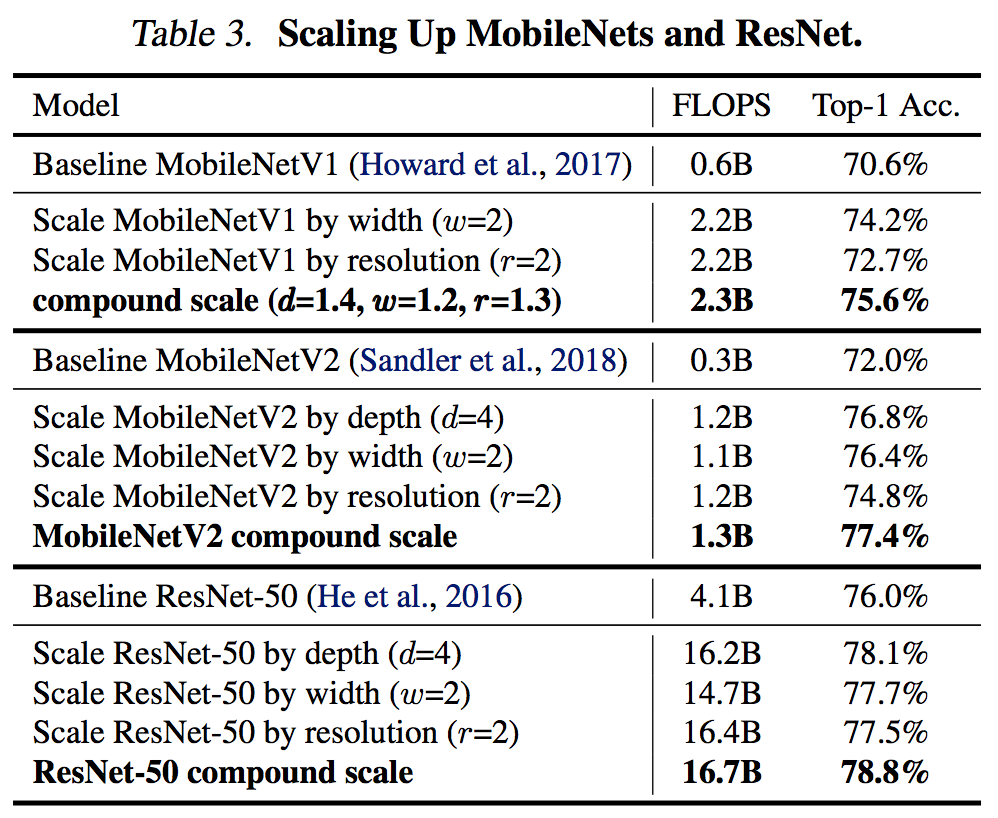
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
5.2 EfficientNetのスケールアップ(ImageNet)
同等の精度のモデルと比べると、EfficientNetのFLOPSは軽く $\frac{1}{10}$ 以下という驚異的な少なさ。具体的には以下。もっと知りたい場合は原論文を参照。
- SoTAを記録したEfficientNet-B7は従来のSoTAのGPipeより約 $\frac{1}{8}$ のパラメータ数
- EfficientNet-B7はGPipeより6.1倍速い
- EfficientNet-B3はResNeXt-101よりも高い精度でFLOPSに関しては $\frac{1}{18}$ 倍も少ない
- EfficientNet-B1は広く使われるResNet-152よりも精度が良く、5.7倍も速い
5.3 EfficientNetによる転移学習
転移学習により、よく使われる8つのうち5つのデータセットでSoTA超え。
下の表で特筆すべきは、2点。
- EfficientNetは高い精度でかつ平均して4.7倍(最大21倍)ものパラメータ削減を達成。
- EfficientNetは9.6倍ものパラメータ削減でSoTAモデルよりも精度がいい。
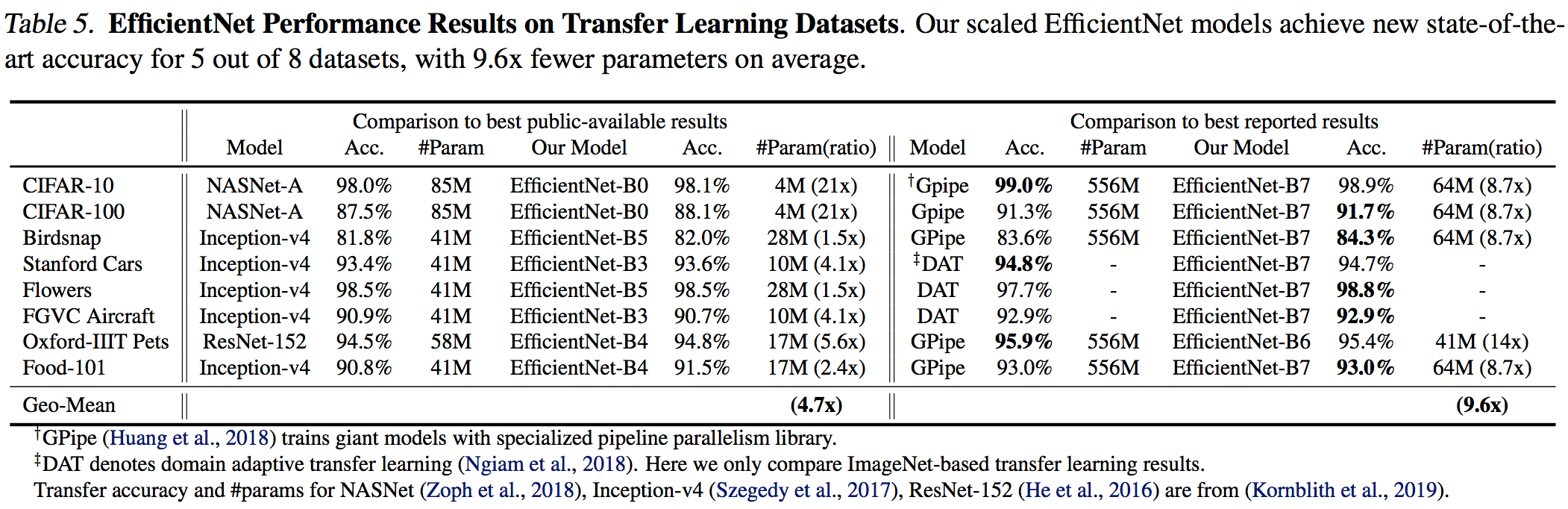
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
6. 考察
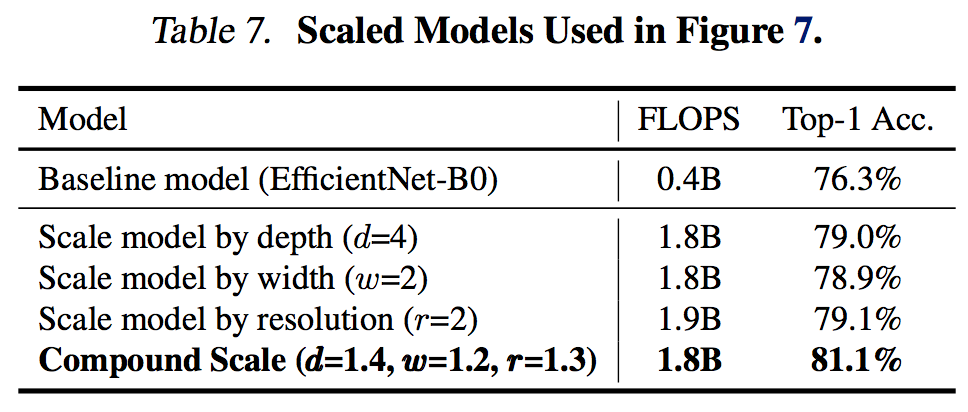
6.1 複合スケーリングによる精度向上
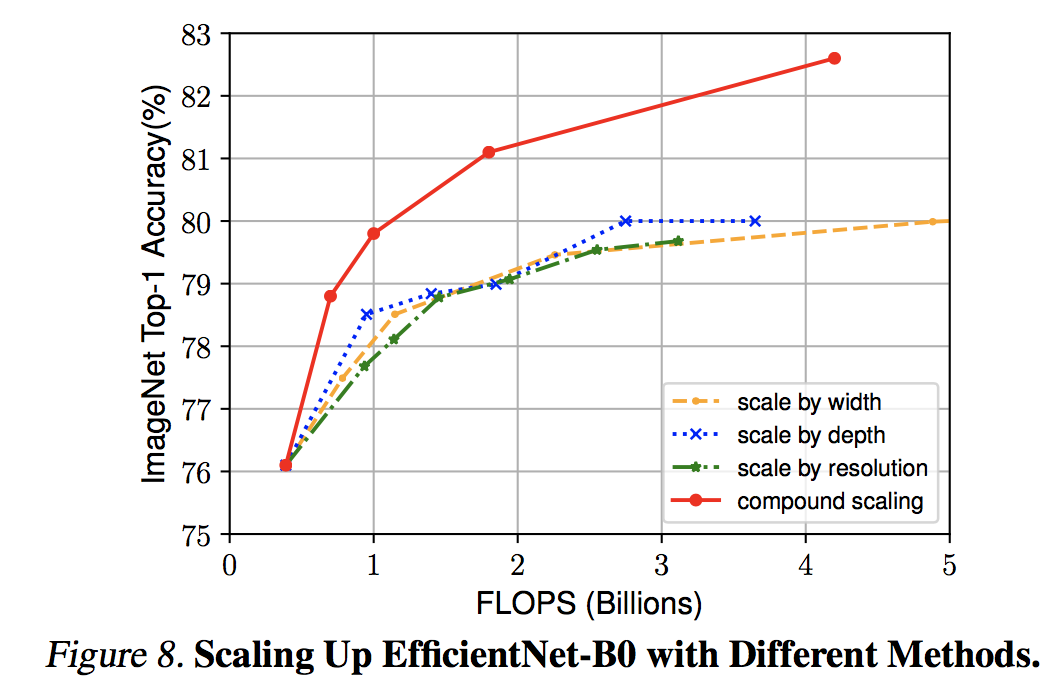
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
上図からも 複合スケールアップの方が単体のスケールアップよりも圧倒的に精度が高い ことが明らか。
6.2 アクティベーションマップの比較
複合スケーリングによってアクティベーションマップ(つまりモデルがどこを見ているのか)はどう変わるのかを比較する。図がそのアクティベーションマップと表は図中の各列のモデルの情報。一番左が画像で右には5つのモデルの比較がされている。
複合スケーリングのモデル(一番右)が画像内のモノの形をしっかりと捉えている。
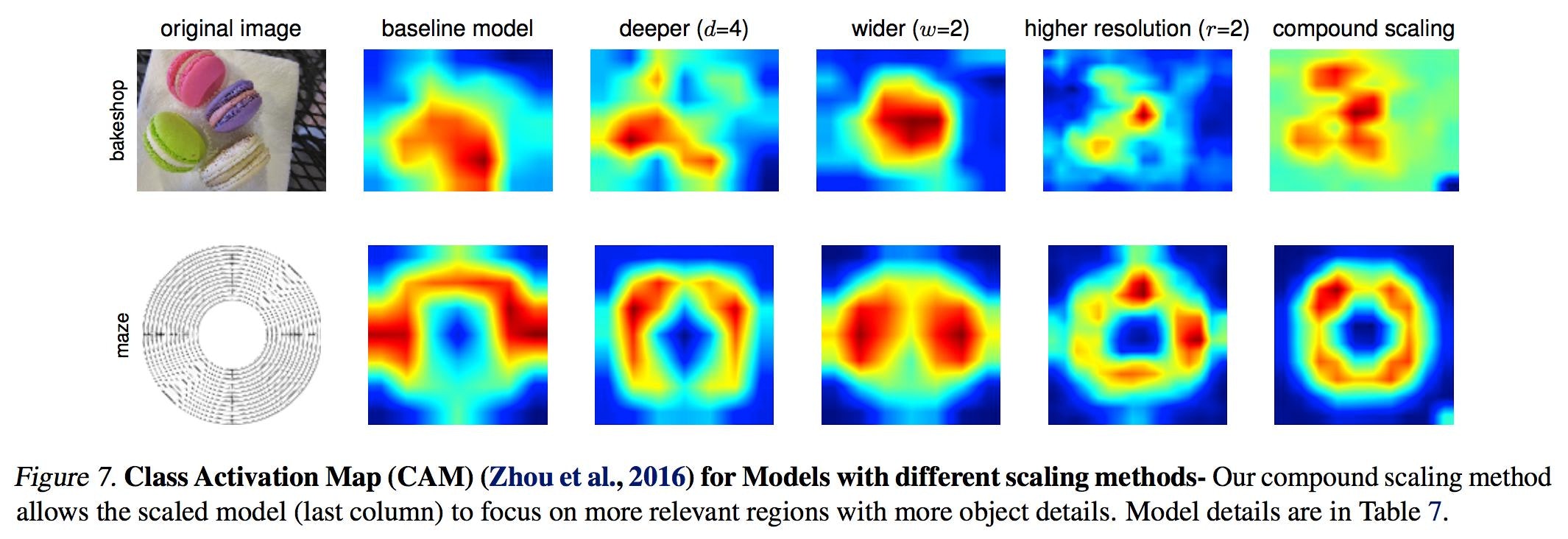
Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).
7.結論
モデルの深さと広さと解像度をバランスよく調整する複合スケーリングにより、
簡単にベースラインのモデルをスケールアップし、かつパラメータ数をあまり増やすことなく精度をあげることができる。転移学習にも高い精度を示す。
まとめと所感
モデルの深さと広さと解像度を同時に調整することで、ここまで精度が高くなるとは驚いた。
内容がとても簡潔で論文自体も読みやすかった。
Compound Scaling Methodで従来のSoTAであるGPipeを最適化したらどうなるんだろうか。
何かわからないことや間違っていることがあればご指摘ください!
いいねやコメントをもらえるとありがたいです!
用語や補足
Top-N accuracy
モデルの吐き出したクラスに対する確率において上位Nに正解ラベルが入っていれば、
それを正解としてカウントするもの。
例)正解がりんごの画像をインプットとして入れた場合
モデル出力)
Peach: 0.45
Cherry: 0.30
Apple: 0.15
Prime: 0.07
Banana: 0.02
Pineapple: 0.01
この場合、Top-1 Acc.では不正解だが、Top-5 Acc.なら正解と判断。
(Appleが上位5位に入っているから。)
FLOPS
FLOPS(=FLoating-point Operations Per Second)とは
1秒あたりにできる浮動小数点演算の回数
のこと。単純。