AutoMLの理論、Neural Architecture Searchを説明する
GoogleがGCPで画像分類のCloud AutoMLをアルファ版公開したのが2018年初頭で、すでに半年ほど経過しました。
Cloud AutoMLは機械学習の専門家でなくても高品質な画像分類モデルを生成できるというものですが、その背景にある理論がNeural Architecture Searchです。
Neural Architecture Search(略称:NAS)が従来のニューラルネットワーク設計と違うのは、NASはニューラルネットワークのアーキテクチャ自体を最適化するということです。
従来のニューラルネットワークでは、事前に人間がニューラルネットワークの構造(VGG、Resnet、GoogleNet等々)を設計して、ネットワークの重みを最適化しますが、NASではニューラルネットワークの構造自体やパラメータを最適化したうえで、重みを最適化します。
パラメータ最適化のみであればベイズ最適化や遺伝アルゴリズム、GridSearch等で実現されていましたが、NASはそのさらに前段階で構造を最適化します。
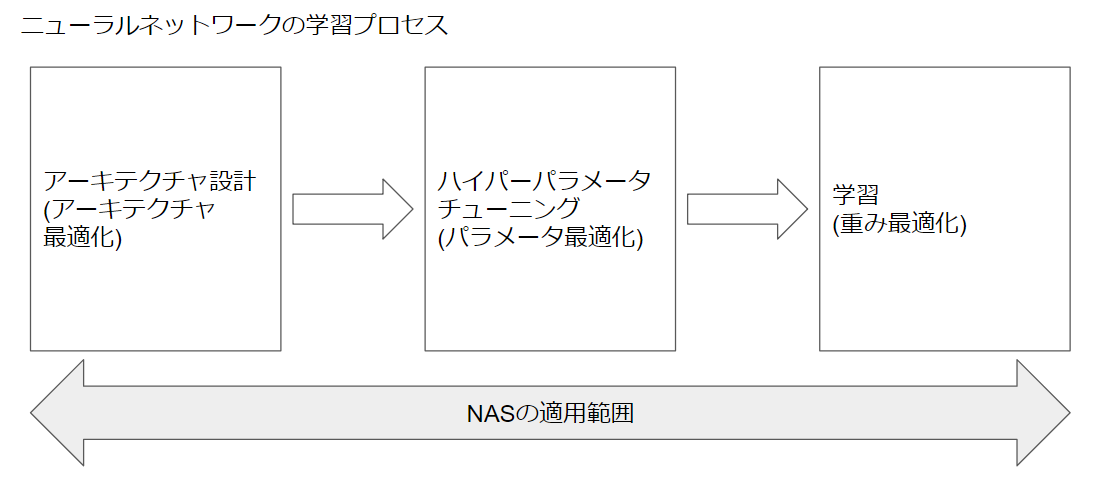
- 通常のニューラルネットワーク:ニューラルネットワークは重みを最適化し、目的関数を改善する。
- パラメータ最適化を含んだニューラルネットワーク:「通常のニューラルネットワーク」の前段階で最適なパラメータ(ニューロン数、ドロップアウト率、学習率等々)を探索する。
- Neural Architecture Search:「パラメータ最適化」の前段階でニューラルネットワークの構造を最適化する。
本記事では以下論文をもとに、NASが実践しているニューラルネットワークの構造探索について整理します。
- Neural Architecture Search with Reinforcement Learning
- Learning Transferable Architectures for Scalable Image Recognition
- Efficient Neural Architecture Search via Parameter Sharing
なお、本記事ではNASの説明にフォーカスします。NASで用いられる周辺的な手法(強化学習、Attentionメカニズム、PPO等々)については書きませんが、適宜参考URLを掲載していくので、興味あればご参照ください。
続編はこちら
TLDR
- NASはニューラルネットワークのアーキテクチャを最適化する。
- NASのボトルネックは計算量(GPU 800台で並列学習しても28日間!)。
- しかしENASはGPU 1台、半日程度で実行可能。しかもあまりパフォーマンス劣化しない。
NAS事始め Neural Architecture Search with Reinforcement Learning
CNNやRNNの実用化によってニューラルネットワークで音声認識や画像認識、機械翻訳の分野で目覚ましい改善が成されていますが、ニューラルネットワーク自体の設計には高度に専門的な知見が必要になります。
Neural Architecture Search with Reinforcement Learningで提唱されているNeural Architecture Searchは、ニューラルネットワークの設計を強化学習で実装するという試みになります。
TLDR
- NASはCNNやRNNのアーキテクチャを強化学習で探索し、最適化する。
- CNN探索ではレイヤー間の接続を探索している。
- RNNではRNNセルを探索している。
- CNNはCifar10(画像分類)、RNNはPenn Treebank(自然言語処理)で良い結果が出た。
- 論文はこのプレゼンでわかりやすく解説されている。
概要
ここでは2つのニューラルネットワークが登場します。
- Controller RNN:上図の赤四角。下記Child Networkの構造を探索する。
- Child Network:構造探索対象のニューラルネットワーク。画像認識や機械翻訳等、実際のタスクを実行する。
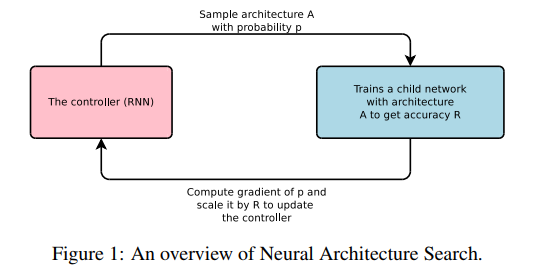
Controller RNNでChild Networkの構造を探索し、タスクに最適なChild Networkを生成しようというのがNASのあらましです。
大まかな流れとしては・・・
- Controller RNNが設定したChild Networkのハイパーパラメータ(フィルターサイズ、フィルター数、ストライドサイズ等々)でChild Networkを学習する。
- 学習後のChild Networkで検証データに対するAccuracyを算出する。
- このAccuracyをController RNNの報酬とする。
- 報酬をもとに方策勾配法(Policy Gradient)によってController RNNを更新する。
- 1.に戻る。
・・・というものになります。
Controller RNNと強化学習
Controller RNNの役割はChild Networkのハイパーパラメータを探索することです。
Controller RNNの構造は以下のようになっています。
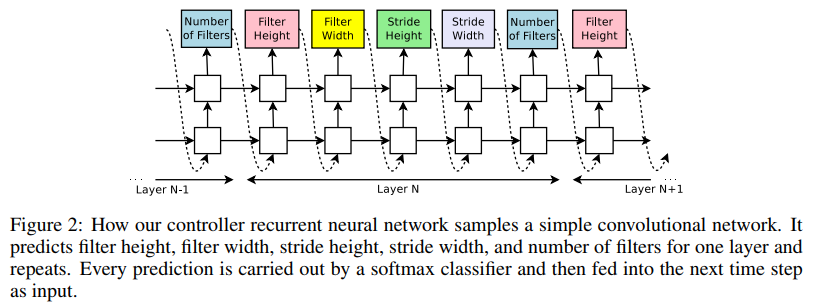
この図はChild NetworkをCNNとした場合のController RNNです。
Child NetworkをRNNとした場合のController RNNは後述しますが、まずはCNN前提で説明していきます。
Controller RNNとChild Network(CNN)の関係は以下のような全体像になります。
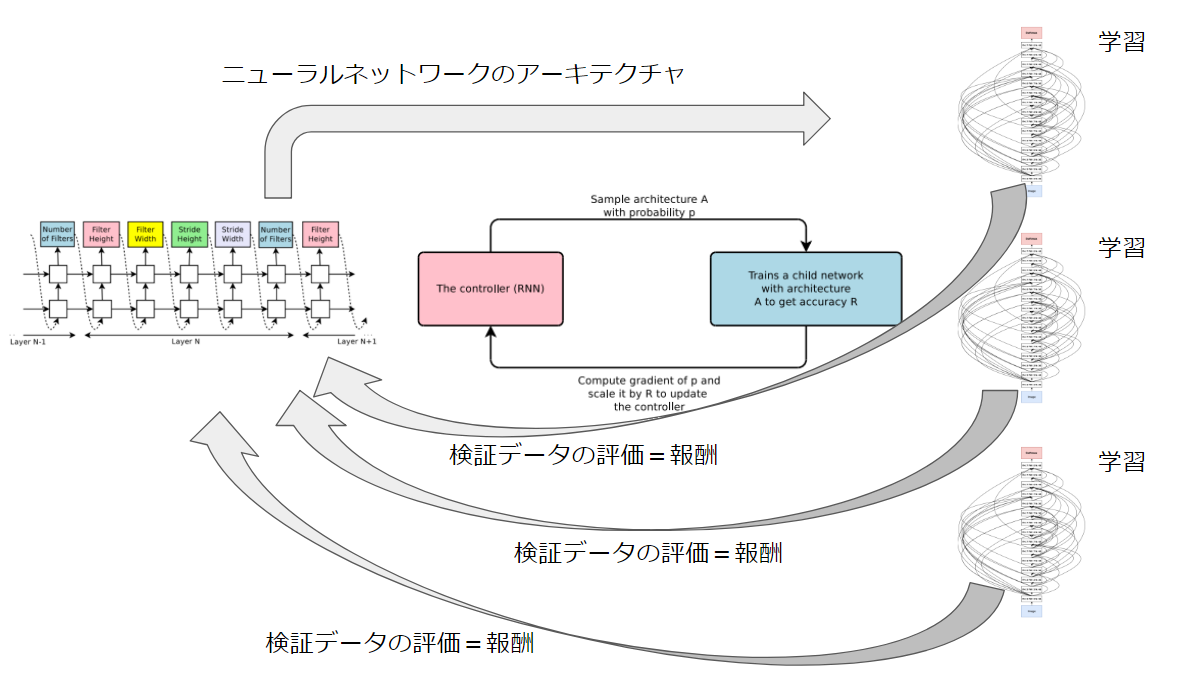
以降で詳細を説明していきますが、この全体像がイメージできていればNASの手法は概ね理解しやすいと思います。
Controller RNNの各セルの出力がChild Networkの各レイヤーのハイパーパラメータそのものとなっています。各出力は次セルの入力としてChild Networkの最終レイヤーまで連結していくようになっています。
Controller RNNの目的はChild Networkの検証データに対するAccuracyを最大化することです。
Controller RNN自体の学習ではChild Networkの検証データAccuracyを報酬とします。ハイパーパラメータ($ \theta_{c} $とする)を方策勾配法によって更新することで、期待報酬$ J(\theta_{c}) $を最大化することを目指します。
期待報酬$ J(\theta_{c}) $は以下の式で定義されます。
J(\theta_{c})\,=\,E_{P_(a_{1:T};\theta_c)}\bigl[R\bigr]
$ a_{1:T} $はController RNNの行動(Action)であると同時に、Child Networkのアーキテクチャ設定値でもあります。Controller RNNは強化学習であるため、一連の行動を最適化することで(報酬を最大化することで)、Child Networkのアーキテクチャを最適化することを目指します。
期待報酬$ J(\theta_{c}) $を以下の式で更新します。
▽_{\theta_c}J(\theta_{c})\,=\,\sum_{t=1}^{T}E_{P_(a_{1:T};\theta_c)}\bigl[▽_{\theta_c} \log P(a_t|a_{(t-1):1};\theta_c)R\bigr]
これを以下に近似します。
\frac{1}{m}\sum_{k=1}^{m}\sum_{t=1}^{T}▽_{\theta_c} \log P(a_t|a_{(t-1):1};\theta_c)(R_k-b)
$ m $はController RNNが1ミニバッチで検証するアーキテクチャ数。
$ T $は推定するハイパーパラメータ数。
$ R_k $は$ k $番目のニューラルネットワークアーキテクチャでの検証データAccuracy。
$ b $はそれまでのニューラルネットワークアーキテクチャのAccuracy指数移動平均。
Skip Connection
これでController RNNはChild Networkのハイパーパラメータを探索することができるようになりました。
ここで実現可能なChild NetworkはあくまでAlexNetやVGGのような逐次的なニューラルネットワークになります。
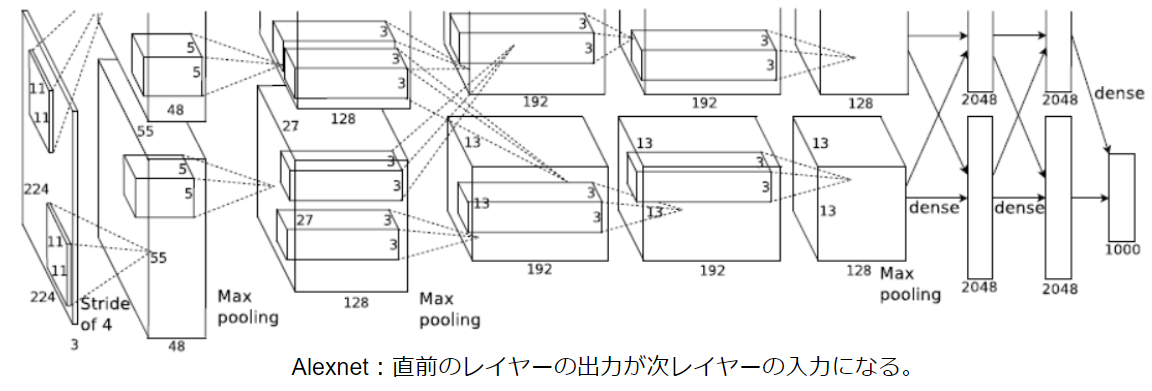
しかし昨今のニューラルネットワークはResnet然りGoogleNet然り、レイヤーを飛び越えて接続するアーキテクチャが主流です。
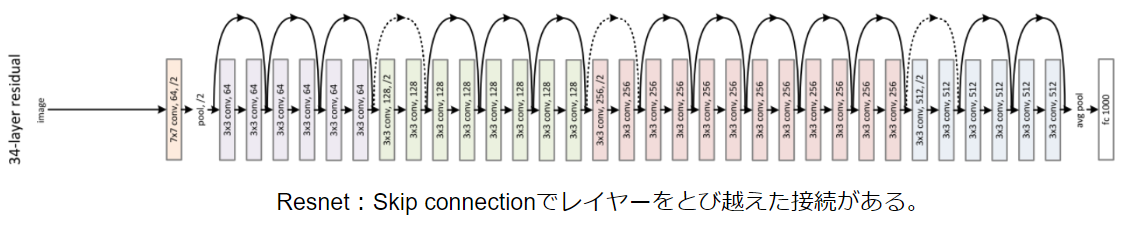
レイヤーの飛び越えを実現するため、Controller RNNにSkip connectionを導入します。
Skip connectionは以下のような図式で実装されます。
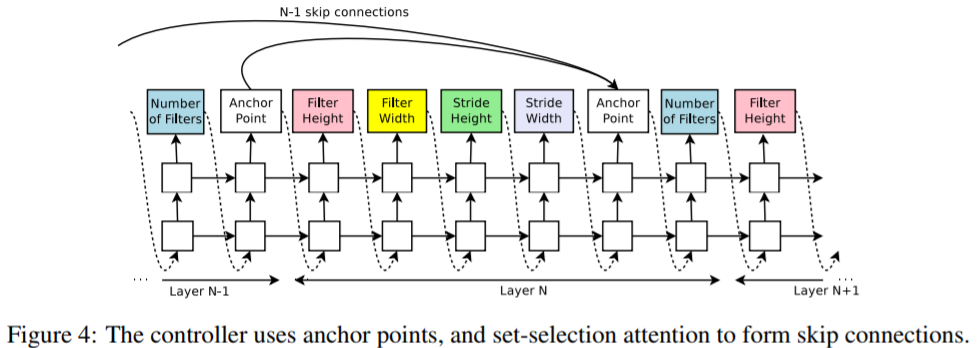
Controller RNNのうち、Child Networkの各レイヤーを後半にAnchor pointを設けて、前レイヤー(N-1以前)のAnchor pointから現レイヤー(N)のAnchor pointに接続するかどうか(入力するかどうか)を判定します。
接続は以下の式で判定します。
P(レイヤーjはレイヤーiの入力)\,=\,sigmoid(v^{T}tanh(W_{prev}*h_{j}+W_{curr}*h_i))
$ h_j $はjレイヤーのAnchor pointにおける隠れ状態。
$ W_{prev},,,W_{curr},,,v $は重み(学習パラメータ)。
この式はレイヤーj(0~i-1)がレイヤーiの入力となる確率を計算しています。
Skip connectionでiレイヤーに複数レイヤーの入力がある場合、入力レイヤーは深さ方向に結合します。この時、入力レイヤー間で結合できないとき(サイズが違うとき)は、小さいほうの入力サイズをゼロパディングして調整します。
Skip connectionはAttentionをもとにしていますが、Attentionについては以下論文が参考になります。
Neural Machine Translation by Jointly Learning to Align and Translate
Neural Programmer: Inducing Latent Programs with Gradient Descent
なお、Child Networkの学習率やプーリング、BatchNormalizationの有無についても、Controller RNNに該当するセルを追加することで学習可能です。
Cifar10でCNNのアーキテクチャを探索する
ここまで説明した手法でCNNのアーキテクチャ探索を説明します。
Cifar10を学習データとします。
探索空間として以下を設定します。
- 活性化関数はReLu
- BatchNormalization利用
- Skip connection利用
- 畳み込みレイヤーのフィルターサイズは高さ[1,3,5,7]、幅[1,3,5,7]、フィルター数[24,36,48,64]から探索
- ストライドは1固定 または [1,2,3]から探索
パラメータをController RNNにプロットすると以下のようになります。
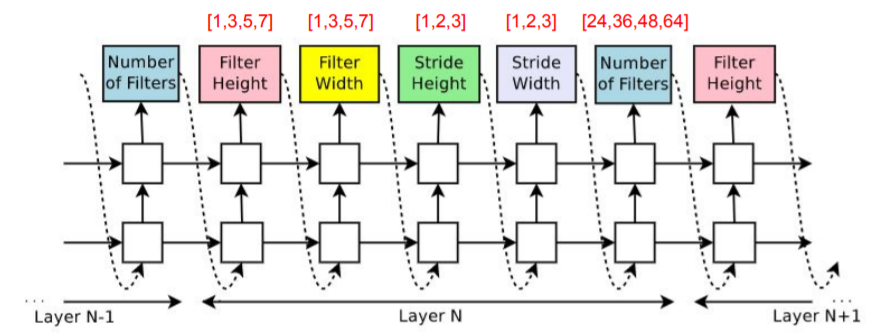
これでController RNNを組み、合計で12,800個(!)のChild Networkを探索します。
このとき生成されたCNNとCifar10のエラー率が以下になります。
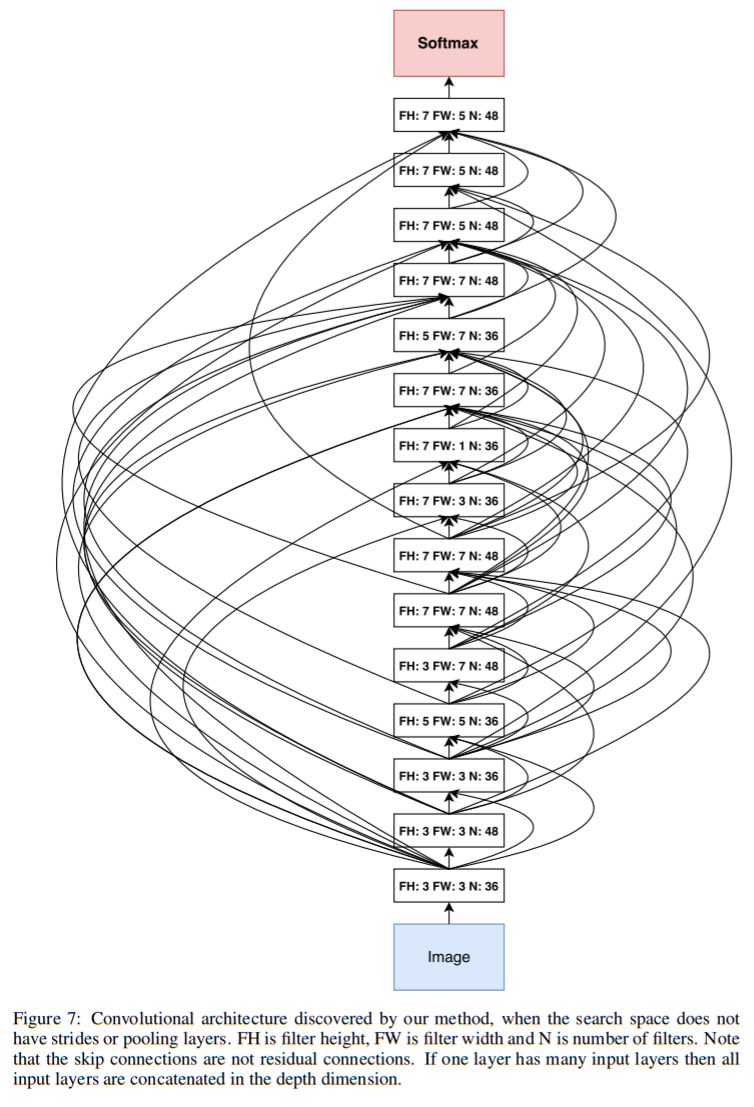
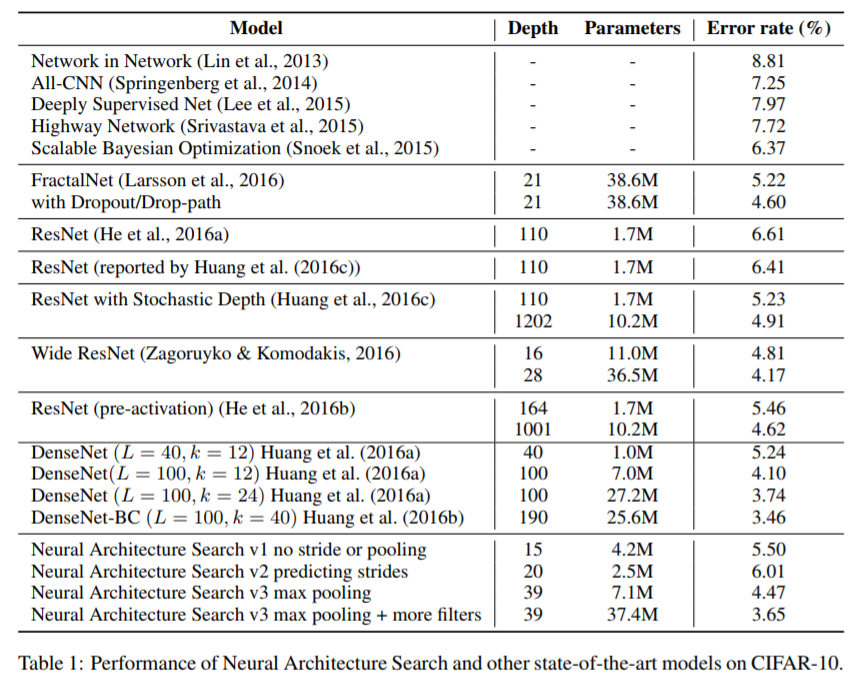
RNNのアーキテクチャ探索
ここまではCNNのアーキテクチャ探索を説明してきましたが、論文ではRNNの探索手法も説明されています。
RNNの探索対象はRNNセルの探索になります。
RNNは系列的なデータに対してセルを連結して学習するため、探索し調整するのはセルになります。
RNNのセルは$ h_{t-1} $(前セルからの入力)、$ x_t $(当該セルへの入力)、$ c_{t-1} $(LSTMのメモリ)を入力とし、$ h_t $(当該セルの出力=次セルへの入力)と$ c_t $(LSTMのメモリ)を出力する木構造の計算ステップとして定義できます。Controller RNNは木ごとに計算ステップで実行する処理を探索します。探索対象の処理は$ h_{t-1} $と$ x_t $を入力とし、結合処理(和算、要素積)と活性化関数(tanh、sigmoid等々)で構成されます。計算ステップの処理がController RNNは各セルの出力となります。
Controller RNNのRNN探索の模式図を以下に例示します。
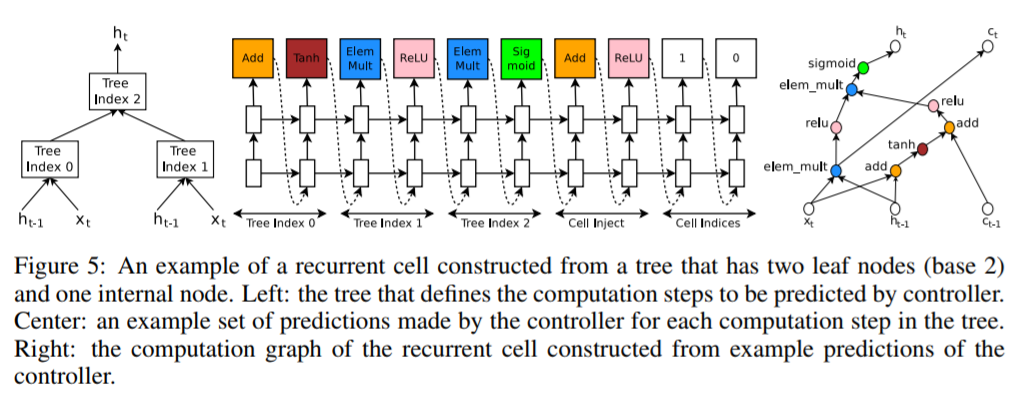
左の図では最初に2木で入力を受け取ります(Tree Index0、Tree Index1)。この入力を各木の計算ステップで処理したのち、Tree Index2で統合して出力($ h_t $)としています。
真ん中の図ではTree Indexの計算ステップをController RNNに配置しています。Tree Index0ではAdd後に活性化関数Tanhが呼ばれているのが分かります。この要領で最後の出力(Cell Indices)まで処理を選択し、Child Networkのセルを生成します。なお、途中でCell InjectでTree Index0の処理に$ c_{t-1} $をAddし活性化関数ReLUが呼ばれています。
右の図が生成されたChild Networkセルの計算グラフです。
この図では2木を入力として探索しています。
この方式でLSTMの計算グラフを図示すると以下のようになります。
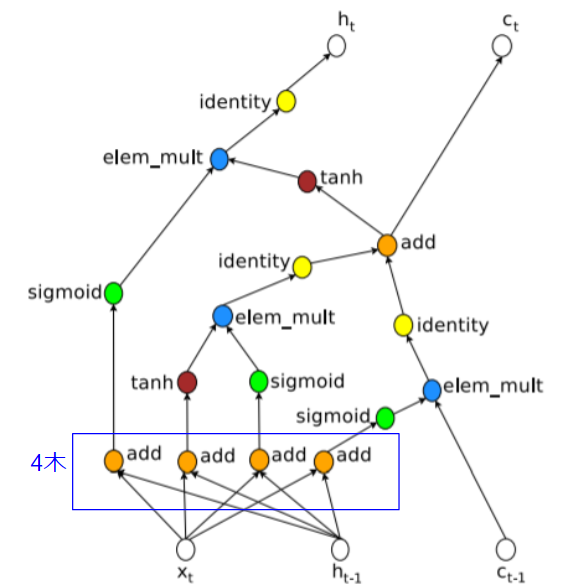
LSTMでは入力が4木で構成されていることがわかります。
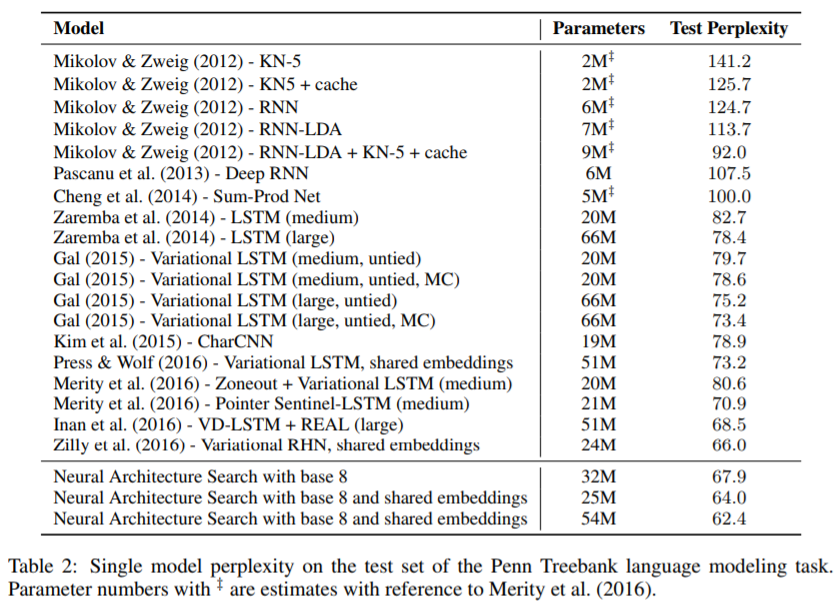
Penn TreebankでRNNセルの探索
上記の手法でRNNのセル探索を説明します。
データセットにはPenn Treebankという英語のコーパスを利用します。
探索空間として以下を設定します。
- 入力は8木で構成。
- 結合処理の選択肢は[add, elementwise multiplication, max]。
- 活性化関数の選択肢は[identity, tanh, sigmoid, relu, sin]。
結果として生成されたChild NetworkのRNNセルとPenn Treebankに対するperplexityは以下のとおりです。
NASまとめ
ここまでNeural Architecture Search with Reinforcement Learningで提案されたNASの手法と実践を説明してきました。
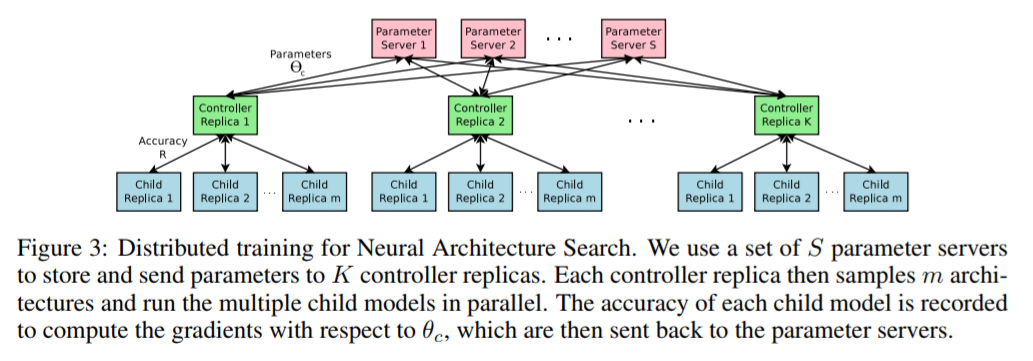
最初のNAS論文で、すでにCNNとRNNの探索手法が提唱され、高性能を叩きだしているのですが、実は計算量に大きな課題があります。
NASでは探索されたすべてのChild Networkをスクラッチから学習して検証データのAccuracyを算出しています。そのため、膨大な計算を継続して実施するものとなっています。
例えばCifar10を用いたCNNの探索では12,800アーキテクチャを学習しています。
高速化するために800台のGPU(NVIDIA K40)で以下のような並列学習(800並列)を組んでいるようですが、探索完了までに28日要したそうです。
以降で紹介する論文では、NASを改良して計算量を削減しつつChild Networkの性能を保つ手法を説明します。
NASNetの登場 Learning Transferable Architectures for Scalable Image Recognition
Learning Transferable Architectures for Scalable Image RecognitionではCNNに焦点を絞ってChild Network探索の効率化をはかります。
NASのCNN探索では畳み込みレイヤー定義(フィルターサイズやフィルター数、ストライドサイズ)とレイヤー間の接続(Skip connection)を探索しました。本論文では畳み込みレイヤーのまとまりをセルと定義し、CNNの探索をセルの最適化に絞ります。
CNNのセルというのは新しい概念ですが、ResNetの構造をみるとわかりやすいと思います。
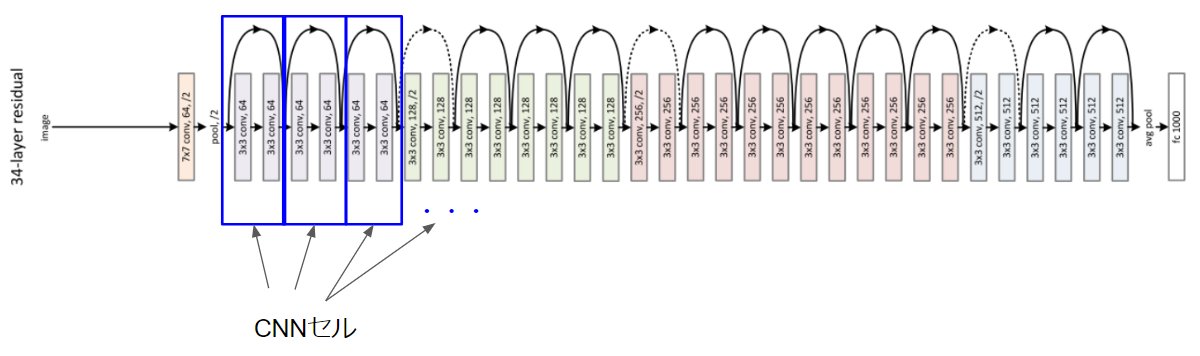
上図の青四角で囲ったレイヤーのまとまりをCNNのセルとします。
本論文ではCNNの構造を最適化された同じセル(ただし重みは違う)の繰り返しと定義し、セルを最適化して深さ(繰り返し数)を調整します。更にはあるデータセット(例:Cifar10)で最適化されたセルは他のデータセット(例:ImageNet)でも応用可能と考えます。こうすることにより、セルを汎用化し計算量を大幅に削減できる、というのが本論文の主旨です。
TLDR
- NASNetはCNNに限定してアーキテクチャを探索し、最適化する。
- CNNの畳み込みやプーリングをCNNセルと定義し、CNNセルの最適化を行う(NASのRNNセルと類似)。
- 最適化されたCNNセルは多様なデータセットや用途に転用可能(Cifar10(画像分類)で得たCNNセルをImageNet(画像分類)やFaster-RCNN(物体認識)に転用可能)。
概念
本論文のセル探索手法は前論文のNASを応用しており、Controller RNNとChild Networkの関係はそのままです。
本論文の工夫は探索空間をCNNのセルに限定した点です。この探索空間をNASNet探索空間と呼びます。CNNのセルとは畳み込みやプーリングのまとまりのことです。ResNetをイメージするとわかりやすいと思いますが、ResNetでは以下のような畳み込みや活性化をひとまとまりにしていますが、このまとまりのことをCNNのセルと定義します。
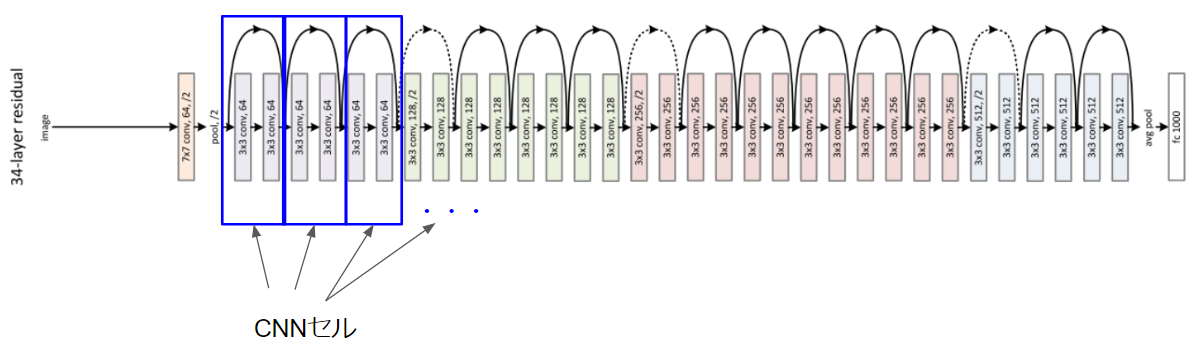
NASNetでは最適化された同一構造のCNNセルを繰り返すことでニューラルネットワークのアーキテクチャを最適化できると考えています。そのため、探索対象はCNNセルになります。最適化されたCNNセルを探索するという発想自体、CNNはResNetのように同じレイヤー構造の繰り返しで構成可能ということにインスピレーションを得ています。
前論文のNASで、Child NetworkをRNNとしたときにはRNNセルの探索を行いましたが、NASNetのCNNセルはこれと似ています。
NASNetでは多様なサイズの画像に対応するため、2つのセルを探索しています。
- Normal Cell:入力と同じサイズの特徴マップを出力する畳み込みレイヤー。
- Reduction Cell:入力よりもサイズが2の倍数で削減された特徴マップを出力する畳み込みレイヤー。
これらNormal CellとReduction Cellを任意の回数積み重ねることによって、以下のようにCifar10(画像サイズ:3232)やImageNet(画像サイズはまちまち。300300くらいに拡縮することが多い)に対応したニューラルネットワークを構成します。小さな画像サイズのデータセット(Cifar10)で探索されたセルがより大きなサイズの画像データセット(ImageNet)でも活用できるとしている点も、NASNetの新規性です。
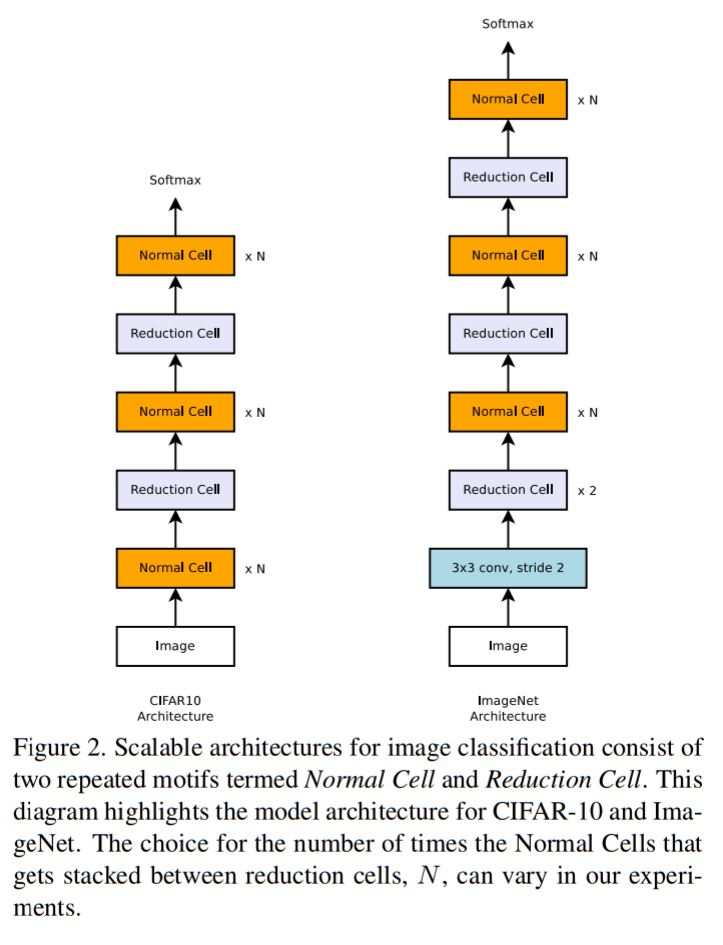
手法
Normal CellとReduction Cellの構造はController RNNで探索されます。
Controller RNNは以下図のようになりますが、これはNASのRNNセル探索で入力を木構造で表していたのと類似のモデルになっています。
NASのRNNセル探索では処理のまとまりを木構造と呼びましたが、NASNetではこの木構造を「ブロック」と呼びます。以下の図は2ブロック(2レイヤー)の入力となっています。
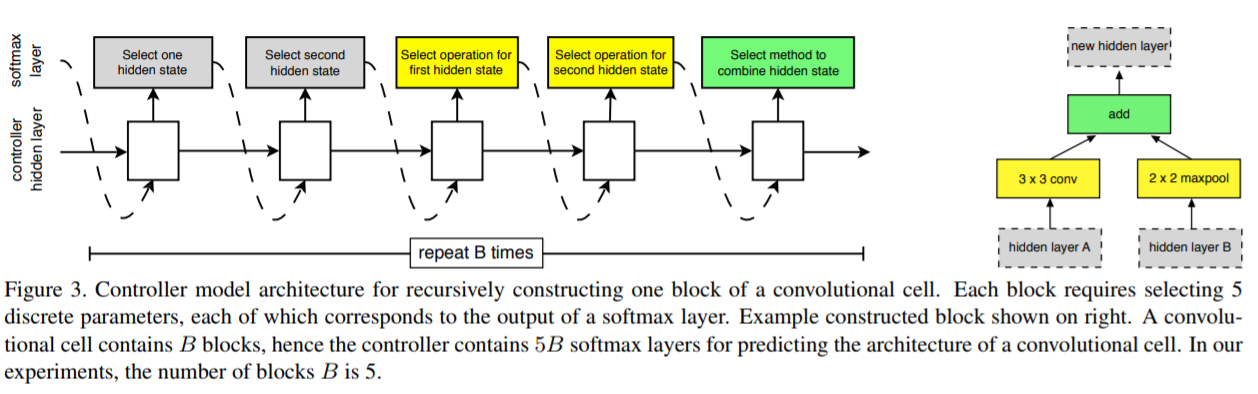
Child Networkの入力となる隠れレイヤーに処理(畳み込みやプーリング)を施し、結合して出力とするという構造はRNNセル探索とほぼ同じです。
1ブロックでは5段階のパラメータ探索をSoftmaxで行っています。各段階の説明は以下のとおりです。
- 入力とする隠れレイヤーを$ h_i $、$ h_{i-1} $またはもっと以前の隠れレイヤーから選択する。
- 1.と同じように、入力とする隠れレイヤーを選択する。
- 1.に施す処理を選択する(選択肢は後述)。
- 2.に施す処理を選択する(選択肢は後述)。
- 3.と4.の結合処理を選択し(選択肢は後述)、このレイヤーの出力とする。
手順を図示すると以下のようになります。
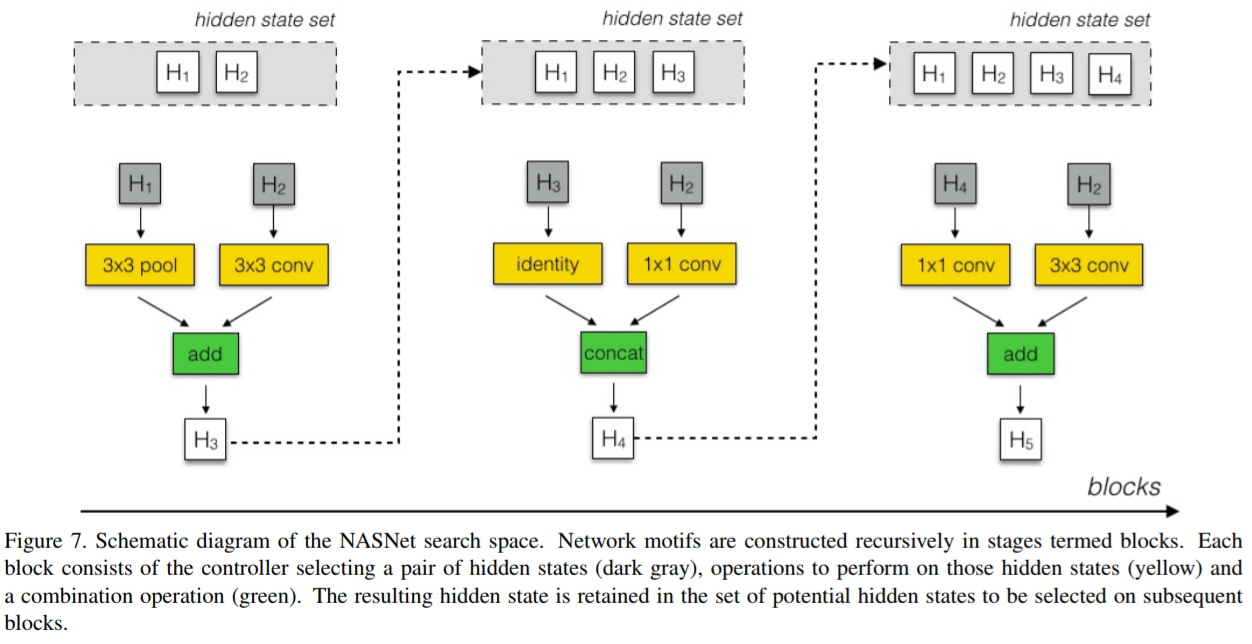
3.と4.の選択肢(NASNet探索空間)は以下のとおりです。
- Identity
- 1x3 then 3x1 convolution
- 1x7 then 7x1 convolution
- 3x3 dilated convolution
- 3x3 max pooling
- 3x3 average pooling
- 5x5 max pooling
- 7x7 max pooling
- 1x1 convolution
- 3x3 convolution
- 3x3 depthwise-separable convolution
- 5x5 depthwise-separable convolution
- 7x7 depthwise-separable convolution
なお、上記のconvolutionはいずれも活性化関数にReLUとBatchNormalizationを導入しています(ReLu→convolution→BatchNormalizationの順)。
また、depthwise-separable convolutionではBatchNormalizationを導入せず、加えてdepthwiseとpointwise間にReLuを導入していません。
5.の選択肢(NASNet探索空間)は以下になります。
- 2レイヤーのelement-wise addition
- フィルターの寸法(filter dimension)による2レイヤーconcatenation
なお、結合時の入力サイズを同一にするため、必要に応じて1x1 convolutionが挿入されます。
上記手順をNormal CellとReduction Cellでブロック数分繰り返します(つまり1探索における出力は$ 5ステップ * ブロック数 * 2セル $になります)。
なお、3.と4.のフィルター数は以下の方式で可変で決めます。
- 最初のレイヤーのフィルター数を任意に設定し、以降はReduction Cellで前レイヤーの2倍のフィルター数、Normal Cellでは前レイヤーと同数のフィルター数とする。
Controller RNNは1レイヤーのLSTMとし、隠れレイヤー100、出力は$ 5ステップ * ブロック数 * 2セル $という構成です。出力はSoftmaxで推論しています。
なお、NASNetはController RNNを方策勾配法ではなくProximal Policy Optimization(PPO)で学習し、高速化と安定をはかっています。方策勾配法もPPOも、いずれも強化学習の手法ですが、違いは以下の記事を読むとわかりやすいと思います。
強化学習のアルゴリズムマップ
Cifar10とImageNetでの検証
NASNetのNormal CellとReduction Cell探索は前述のとおりです。
検証ではブロック数を5に固定して探索しています(つまり1探索における出力は$ 5ステップ * 5ブロック * 2セル $になります)。
NASNetではニューラルネットワーク自体のレイヤー数や順番(=Normal Cell数、Reduction Cell数、その順番)や、最初のレイヤーのフィルター数は手動で設計します。
論文の検証では、Cifar10やImageNetのニューラルネットワークで、Normal Cellの繰り返し数を下図のようにして検証しています。
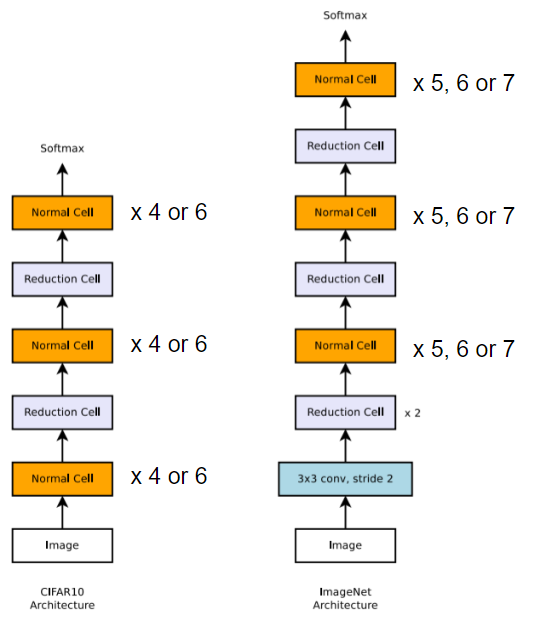
検証ではCifar10でNormal Cell、Reduction Cellの構造を探索し、そこで最適化されたセルをImageNetに適用するという手順をとっています。
Cifar10で得られたNormal CellとReduction Cellは以下のような構造になっています。
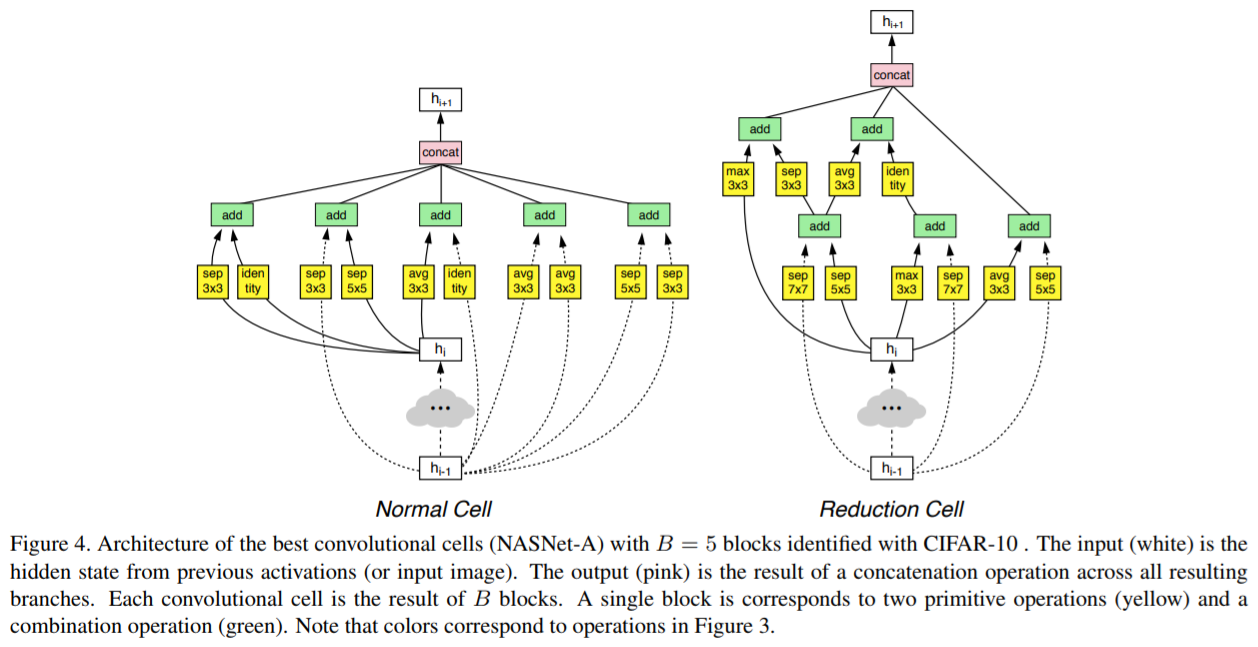
このセルを用いたCifar10、ImageNetの評価結果は以下です。
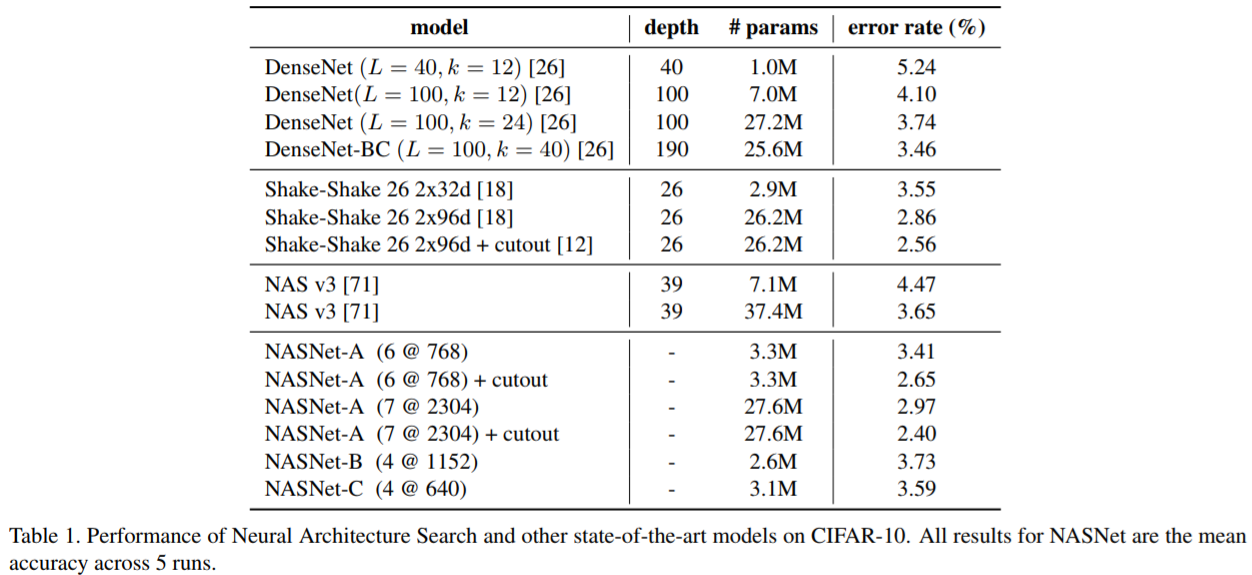
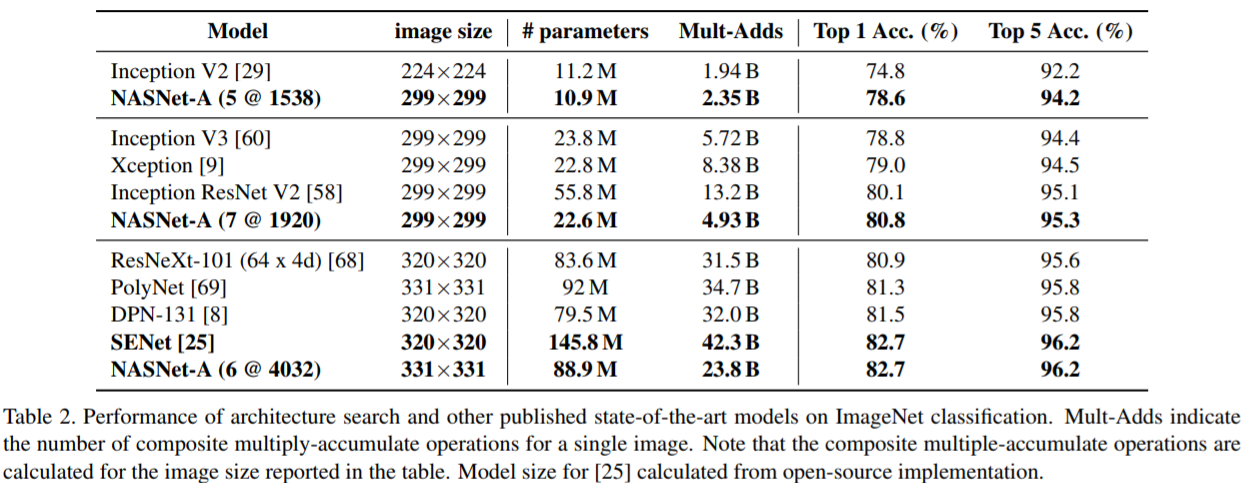
なお、NASNetのあとの(6@768)は、6がNormal Cellの繰り返し回数、768が最後から2番めのレイヤーのフィルター数(つまりは分類レイヤー直前の畳み込みレイヤーのフィルター数)を表します。
ScheduledDropPath
NASNetの探索の仕組みから話が逸れますが、 NASNetでは学習にScheduledDropPathという手法を採用しています。これはNASNetの検証で発見したDropoutの一手法で、DropPathのDropout率を学習の進捗に対してリニアに比例させて増加させるというものです。ただし、ScheduledDropPathの詳細は不明です。論文では「素晴らしい効果があった(significantly improves)」以上の言及はなく。
なお、DropPathはFractalNetで提唱されている手法です。
NASNetまとめ
NASNetの利点は探索対象をCNNセルに限定したことに加えて、あるデータセットで探索したCNNセルを別のデータセットに適用可能ということです。論文ではCifar10で得たCNNセルをImageNetに適用し、効果を得ています。
また上記では省略しましたが、画像分類(image classfication)で得たCNNセルを物体認識(object detection)に適用することも可能です。論文ではCifar10の画像分類で得たCNNセルをCOCOの物体認識に適用し、Faster-RCNNで結果を残しています。
CNNにおいて、NASの探索空間をCNNセルに限定することでNASの計算量課題を解決しようとしたNASNetですが、Cifar10のNormal Cell、Reduction Cell探索には4日を要したようです。
NASが28日間かかっていたのに比べて7倍の高速化が実現され、Cifar10のエラー率もNASNetのほうが改善されているという結果になりました。
(※ ただし、論文にも書かれていますが、NASはNVIDIA K40 GPUを800台使っているのに対し、NASNetではNVIDIA P100を500台使っているそうで、比較するにはスペックが違います)
初期のNASから7倍の効率化が実現されていますが、それでもGPUを500台使うというもので、NASはまだまだ高コストです。
次に説明する論文では、NASNetの計算量を更に効率化する手法を紹介します。次が最後の論文になりますが、ここまできてようやく、NASを現実的なコスト(時間、費用)で実行できるようになります。
効率的なNAS Efficient Neural Architecture Search via Parameter Sharing
NASを効率化する手法として、Efficitent Neural Architecture Search(ENAS)が登場しました。
ENASではNASの課題の原因を、Child Networkをスクラッチから学習している点に見出し、Child Network間で重みを共有する(転移学習する)手法を提唱します。
NASNetではCNNセルの最適化に焦点を絞りましたが、ENASでは最初のNAS同様、CNNとRNN両方の最適化を行います。CNNではニューラルネットワーク自体とCNNセルの探索が可能です。RNNはRNNセルの探索になります。
TLDR
- ENASではCNN、RNNともに有向非巡回グラフと定義し、ノード間のエッジ有効化とノードの処理を探索する。
- なんとENASはGPU 1台半日程度の計算時間でNASやNASNet同等のパフォーマンスを発揮する!
概念
ENASがController RNN-Child Network構造でニューラルネットワークのアーキテクチャを探索することはNASから変わりません。ENASではChild Network間で重みを共有すると書きましたが、その仕組として以下のような計算グラフを組みます。
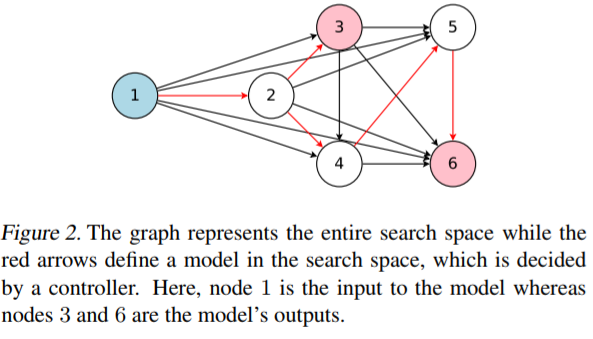
ENASでは全体像となる計算グラフを最初に想定し、その中の一部となる有向非巡回グラフ(Directed Acyclic Graph, DAG)を探索空間とします。たとえばRNNセルは上図の①ノードを入力とし、②、③、④、⑤、⑥の各ノードが互いに矢印方向に接続する可能性があるとします。矢印は小さい番号ノード → 大きい番号ノードに接続されます(つまり、①ノードは②、③、④、⑤、⑥ノード宛に矢印があり、②は③、④、⑤、⑥ノード宛に矢印があり・・・⑥ノードは最も大きい番号ノードなのでどこにも接続されません)。
DAGはすべての矢印は使いません。接続可能な矢印のうち、赤矢印の接続を有効化し、これを探索対象のRNNセルのひとつとしてController RNNは学習する、という仕組みです。
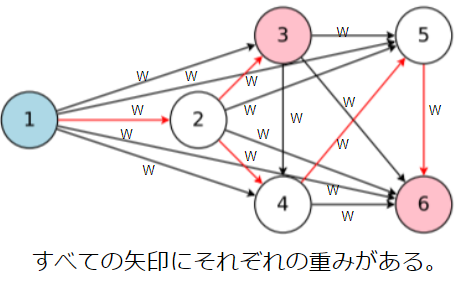
ここで重要なのは、矢印のすべてに重みがあるということです。DAGで矢印が有効化されているかどうかにかかわらず、ENASでは矢印に重みが設定されます。矢印が有効化された場合は、その重みを転移してChild Networkが学習するというものになります。
RNNセル探索の手法
以下の図のようにすれば、DAGによるRNNセル探索がNASのRNNセル探索と類似したものであることがわかると思います。
丸数字のついたノードが処理(活性化)で、矢印(エッジ)がノード間の接続になります。
Controller RNNは探索において以下を決定します。
- どの矢印を有効化するかどうか。
- 各ノードの活性化関数(選択肢はidentity, ReLU, tanh, sigmoid)。
NASとの違いは1.です。NASではノード間(木構造)の接続が任意に決められた状態で、各ノードの処理を探索していましたが、ENASでは接続の有無も探索対象としており、より柔軟なRNNセルが可能となっています。
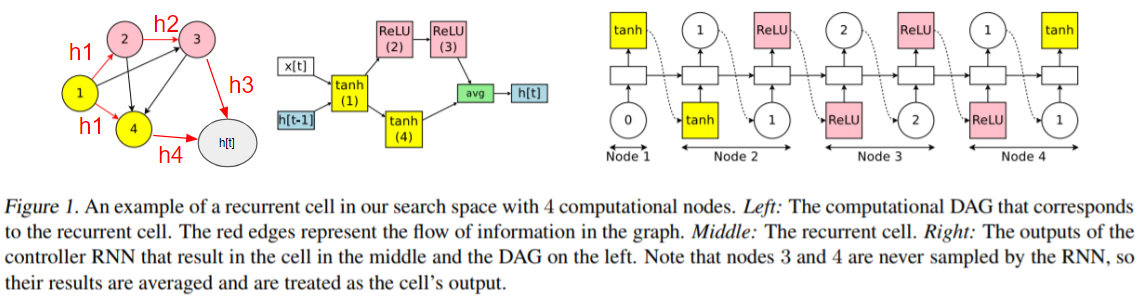
上図のノード数4のDAGでは、RNNセルは以下の手順で探索されます。
- ①ノードの活性化関数を選択する。上図ではTanhを選択。$ h_1 = tanh(x_{t} * W^{(x)} + h_{t-1} * W^{(h)}_1) $
- ②ノードに入力される矢印(①ノードからの矢印)のどれを有効化するかを決定し、②の活性化関数を選択する。上図では①ノードからの矢印を有効化し、ReLUを選択。$ h_2 = ReLU(h_{1} * W^{(h)}_{2,1}) $
- ③ノードに入力される矢印(①、②ノードからの矢印)のどれを有効化するかを決定し、③の活性化関数を選択する。上図では②ノードからの矢印を有効化し、ReLUを選択。$ h_3 = ReLU(h_{2} * W^{(h)}_{3,2}) $
- ④ノードに入力される矢印(①、②、③ノードからの矢印)のどれを有効化するかを決定し、④の活性化関数を選択する。上図では①ノードからの矢印を有効化し、Tanhを選択。$ h_4 = tanh(h_{1} * W^{(h)}_{4,1}) $
- 他ノードの入力になっていないノードの出力の平均値をRNNセルの出力とする。上図では③ノードと④ノードの出力の平均値をRNNセルの出力としている。$ h_t = (h_3 + h_4) / 2 $
先述のとおり、DAGのすべての矢印には重み($ W^{(h)}_{l,j} $)が設定されています。上図では赤矢印が有効化されるので、その矢印に設定されている重みを使ってChild Networkは学習(=重みの更新)します。つまり、Controller RNNで探索されたChild Networkにおいて、その都度、共有の重みが更新されていく仕組みになっています。
CNNの探索手法
ENASでは2種類のCNN探索が可能です。
- ニューラルネットワーク自体の探索(マクロ探索)
- CNNセルの探索(ミクロ探索)
1.はNASの探索空間、2.はNASNetの探索空間と対応付けられます。
マクロ探索とミクロ探索は排他の関係になります。つまり、マクロ探索とミクロ探索を組合せて実行することはできません。
CNNのマクロ探索
マクロ探索の全体像は以下のとおりです。
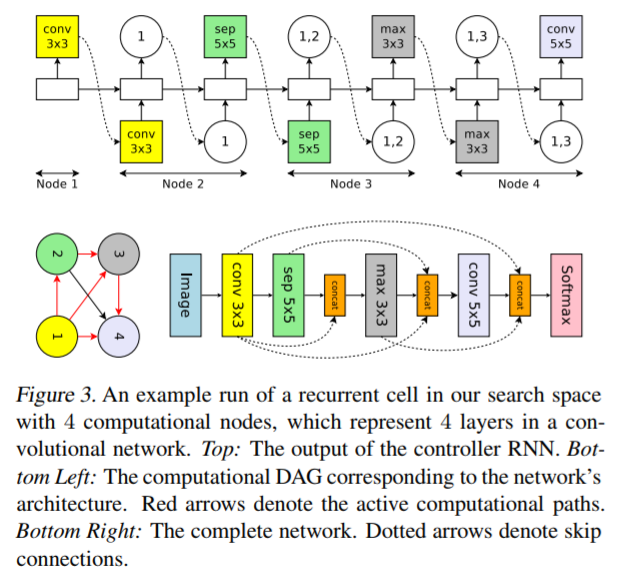
レイヤー間の接続をDAGとみなして以下の探索を行います。
- どの矢印を有効化するかどうか(どのレイヤーを入力とするか)。
- 各レイヤーの処理。
2.の選択肢は以下になります。
- 3x3 convolution
- 5x5 convolution
- 3x3 depthwise-separable convolution
- 5x5 depthwise-separable convolution
- 3x3 max pooling
- 3x3 average pooling
CNNアーキテクチャをDAGとすることで、複数ノードからの接続はSkip connectionとなります。Skip connectionでは矢印の有効化されたレイヤーの出力を深さ方向に結合して、現レイヤーへの入力とします。
CNNのミクロ探索
ミクロ探索では、CNNの全体像はNASNet同様のものを想定しています。
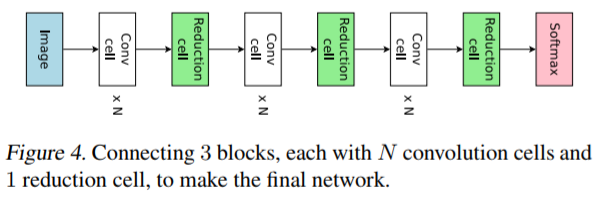
上図のConvolution CellとReduction Cellを探索して最適化するのがミクロ探索になります。
Convolution CellがNASNetのNormal Cellに対応付けられると思います。
ミクロ探索の全体像は以下のとおりです。
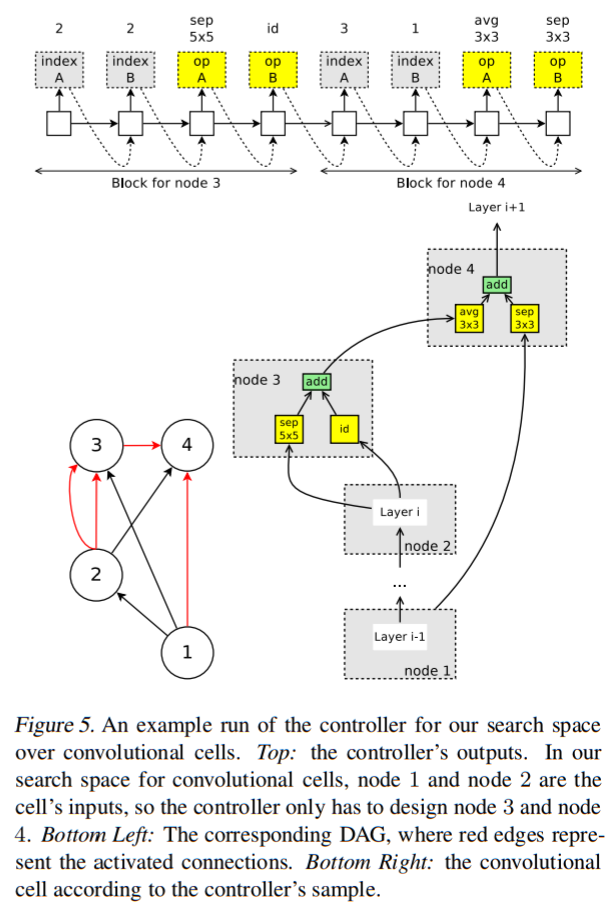
Convolution CellとReduction Cellをそれぞれ別のDAGとします。
ミクロ探索のDAGでは①ノードと②ノードは他ノードへの入力となります。
$ 全ノード数-2 $について、Controller RNNは以下の探索を行います。
- 入力となる2ノードを選択する(単一ノードを2重で選択可能)。
- 入力ノードそれぞれに対する処理を選択する(第一入力ノードの処理、第二入力ノードの処理)。
2.の選択肢は以下です。
- identity
- 3x3 separable convolution
- 5x5 separable convolution
- 3x3 max pooling
- 3x3 average pooling
2.の処理後には合算され、当該ノードの出力となります。
上図(4ノード)をもとに探索手順を段階的に説明すると以下になります。
- ①ノード、②ノードの出力(それぞれ$ h_1, h_2 $とする)は他ノードの入力となる。
- ③ノードは2つの入力ノードとして両方とも②ノードを選択し、それぞれに5x5 separable convolutionとidentityの処理を適用する。$ h_3 = sepconv5\times5(h_2) + id(h_2) $
- ④ノードは①ノードと③ノードを入力とし、それぞれに3x3 separable convolutionと3x3 average poolingの処理を適用する。$ h_4 = sepconv3\times3(h_1) + avgpool3\times3(h_3) $
- ④ノードのみが他のノードの入力になっていないので、④ノードをセルの出力とする。入力となっていないノードが複数ある場合は、各ノードを結合して出力とする。
Convolution Cellは上記で探索されます。
Reduction Cellでは上記に加え、各処理のストライド幅を2とすることで、出力サイズを縮小します。
Penn TreebankでRNNセルの探索
NAS同様、RNNセル探索はPenn Treebankで検証しています。
ENASで最適化されたRNNセルと評価結果は以下になります。
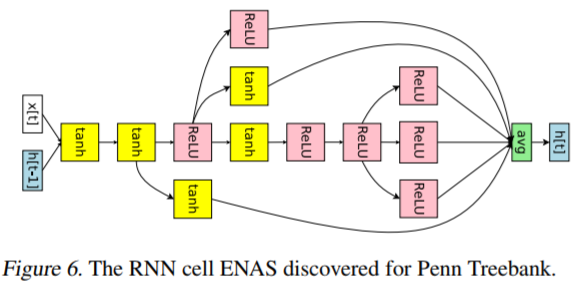
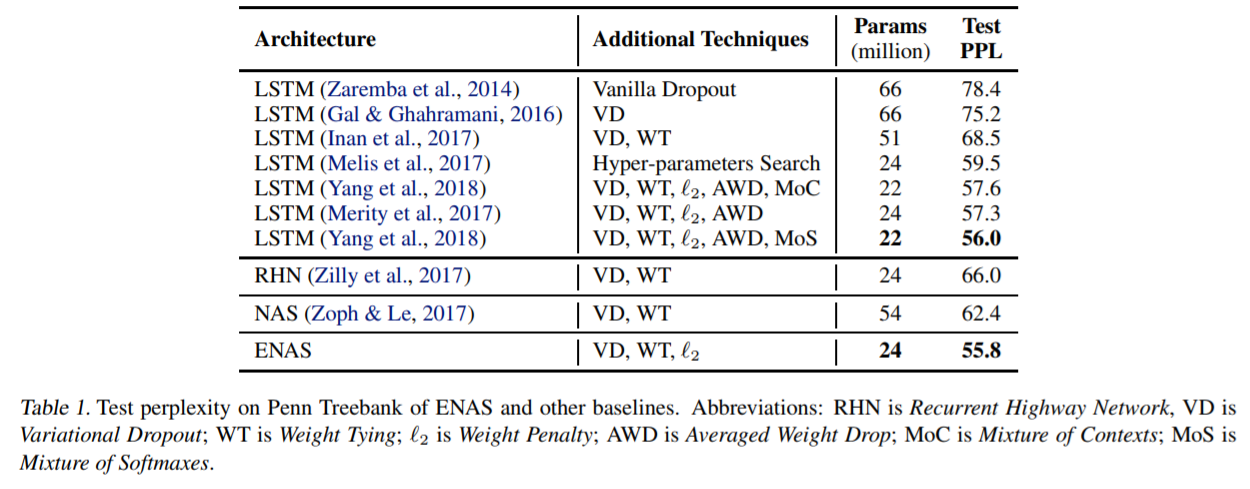
結果のとおり、NAS(62.4)よりもENAS(55.8)のほうが改善されていことがわかります。
ENASが目標としていた計算量の効率化についても、ENASの検証ではNVIDIA GTX 1080Tiを1台使って10時間で探索しており、NASに比べて1000倍以上の高速化を実現したそうです。
Cifar10でCNN探索
ENASのCNN探索手法はマクロ探索とミクロ探索があります。Cifar10で両方の探索を行い、以下の評価結果を得ています。
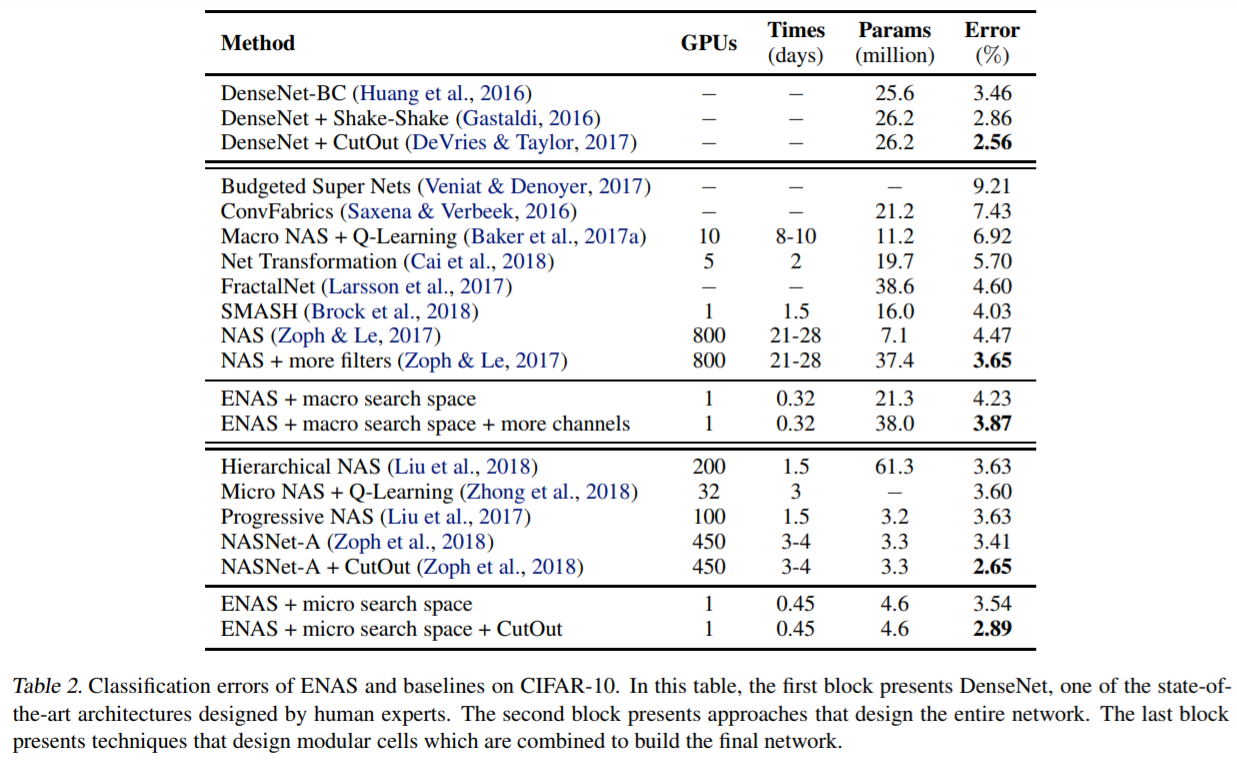
表中にはENASマクロ探索、ミクロ探索、NAS、NASNetのエラー率と計算時間が記載されています。
エラー率ではNAS(vsマクロ探索)やNASNet(vsミクロ探索)のほうが多少優っていますが、計算時間ではENASはいずれもGPU 1台で半日程度(マクロ探索は0.32日、ミクロ探索は0.45日)で完了しています。
そのとき最適化されたマクロ探索、ミクロ探索のCNNは以下のとおりです。
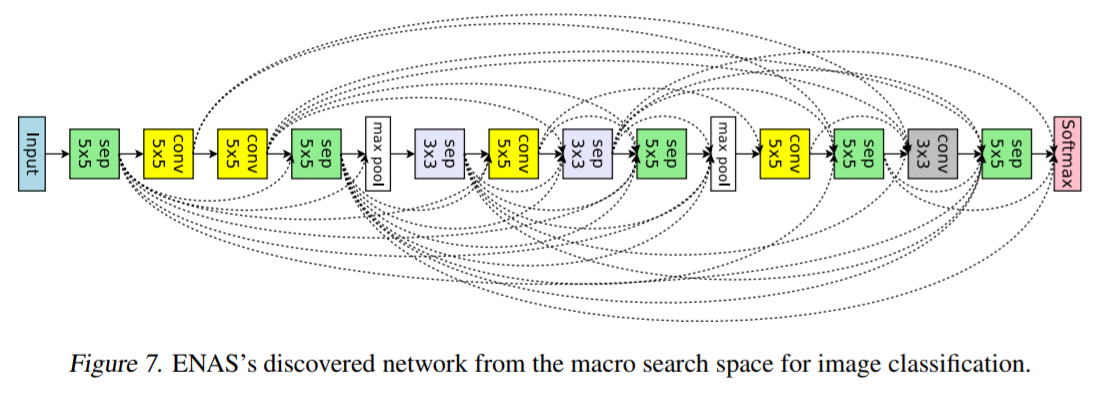
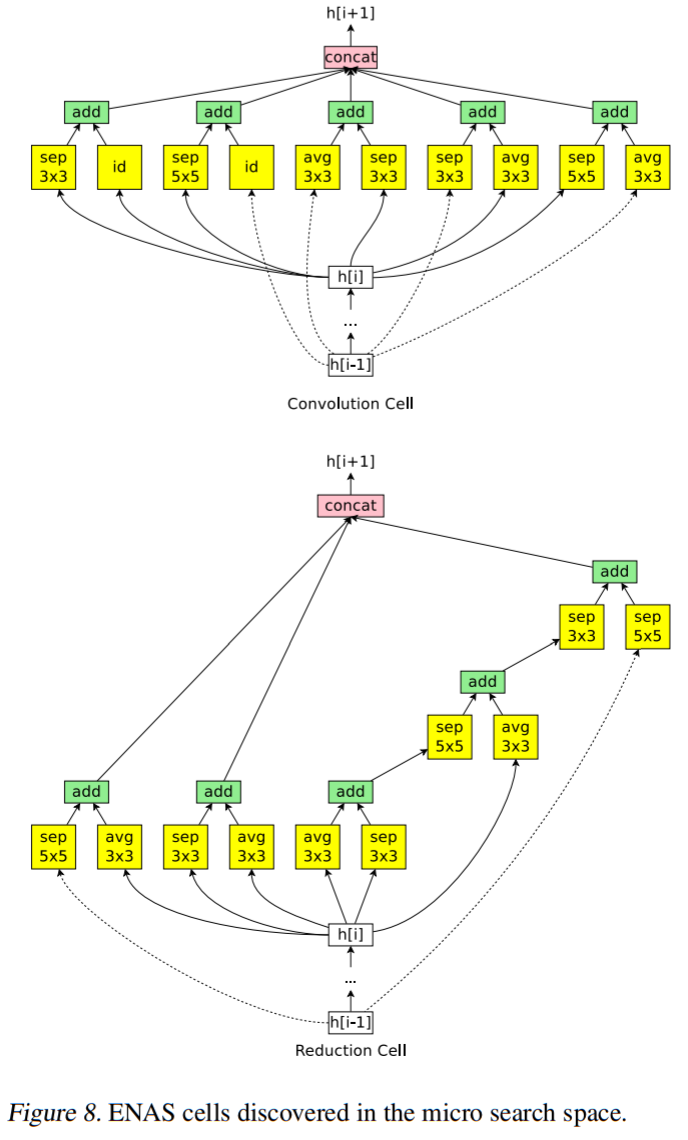
ENASまとめ
NAS登場時はGPU 800台で28日かかっていたニューラルネットワークアーキテクチャの最適化が、ENASではGPU 1台で半日程度で完了するまで短縮されました。
この計算時間であれば、企業や個人でも現実的なコストでNASを実施できるのではないかと思います。
最後に
長くなりましたが、Neural Architecture Searchと呼称される手法について、可能な限り論文に沿って説明していきました。
理解が間違っている箇所があるかもしれませんが、おかしいところはご指摘ください。
論文としてNeural Architecture Search with Reinforcement Learningが登場してから2年弱が経過しましたが、ENASでようやく試してみようと思えるくらいの計算コストになった気がします。
その他のNeural XXX Search
本記事ではニューラルネットワークのアーキテクチャを最適化する論文を紹介しましたが、同様の発想で最適化関数を最適化する手法が以下で論じられています。
Neural Optimizer Search with Reinforcement Learning
また、ニューラルネットワークアーキテクチャの最適化手法として、強化学習ではなくSMBOを適用する論文もあります。
Progressive Neural Architecture Search
実装
NAS
ENAS
- Tensorflow(論文作者): https://github.com/melodyguan/enas
- Pytorch: https://github.com/carpedm20/ENAS-pytorch
- Keras(筆者実装中): https://github.com/shibuiwilliam/ENAS-Keras
Progressive Neural Architecture Search
- Keras+Tensorflow: https://github.com/titu1994/progressive-neural-architecture-search