Neural Architecture Searchの新潮流 〜DARTSとFBNetの衝撃〜
AutoMLの理論、Neural Architecture Searchを説明する。でNeural Architecture Search(略称NAS)について説明したのですが、世の中の移り変わりは早いもので、また違う方法でニューラルネットワーク最適化する手法が提案されています。今回はそのうちの2つ、DARTSとFBNetについて説明します。
- DARTS: Differentiable Architecture Search
- FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
前置き
NASはニューラルネットワークの構造を最適化することを目的とする手法です。

これまでのNASではRNNベースのController RNNで強化学習を用いて対象のChild Networkが最良のテストAccuracyを出すように最適化しました。

初期のNASではChild Networkの最適化にGPU数百枚で数日〜数週間を必要としていましたが、より効率的に学習するEfficient Neural Architecture Search via Parameter Sharing(ENAS)も提案され、一日程度で学習を完了できるようになりました。
ENASでは最適化対象のニューラルネットワークを有向非巡回グラフ(Directed acyclic graph; DAG)の組み合わせと定義し、重みを共有しつつDAGを最適化することで計算効率を向上させる、という手法が論じられています。

ここまでのNASはいずれも強化学習をベースに対象のニューラルネットワークを最適化するという試みで、探索対象は非連続的な離散空間に限られていました(強化学習以外にも遺伝アルゴリズムやベイズ最適化をベースにしているものもありましたが、やはり離散空間のブラックボックス最適化であることは変わらない)。ここで離散空間と書いているのは探索パラメータ(畳み込みかプーリングか、畳み込みの種類、カーネルサイズ、ストライドサイズ、活性化関数・・・)のことで、対象はあくまで離散的な選択肢となっています。
今回はじめに説明するDARTSではENASのようにDAGを対象にして、離散空間探索を連続空間探索に緩和する手法を紹介します。
DARTS: Differentiable Architecture Search
DARTSでは離散空間探索を連続的な空間探索に緩和することで、対象となるニューラルネットワークのAccuracyを損なわずに探索時間を短縮します。
DARTSの探索空間
DARTSはENAS同様に探索空間をDAGとしますが、このDAGを以下の数式で定義します。
x^{(i)} = \sum_{j<i}o^{(i,j)}\bigl(x^{(j)}\bigr)
$ x $はノード、$ (i,j) $はノード(i,j)間のエッジとし、エッジに対するオペレーション$ o^{(i,j)} $によって$ x^{(j)} $を$ x^{(i)} $に変換する、ということを表しています。
DARTSではこの数式を元にエッジとオペレーションの選択を勾配法を用いて探索することで、ニューラルネットワークのアーキテクチャと重みを同時に最適化(bilevel optimization)することを目指します。
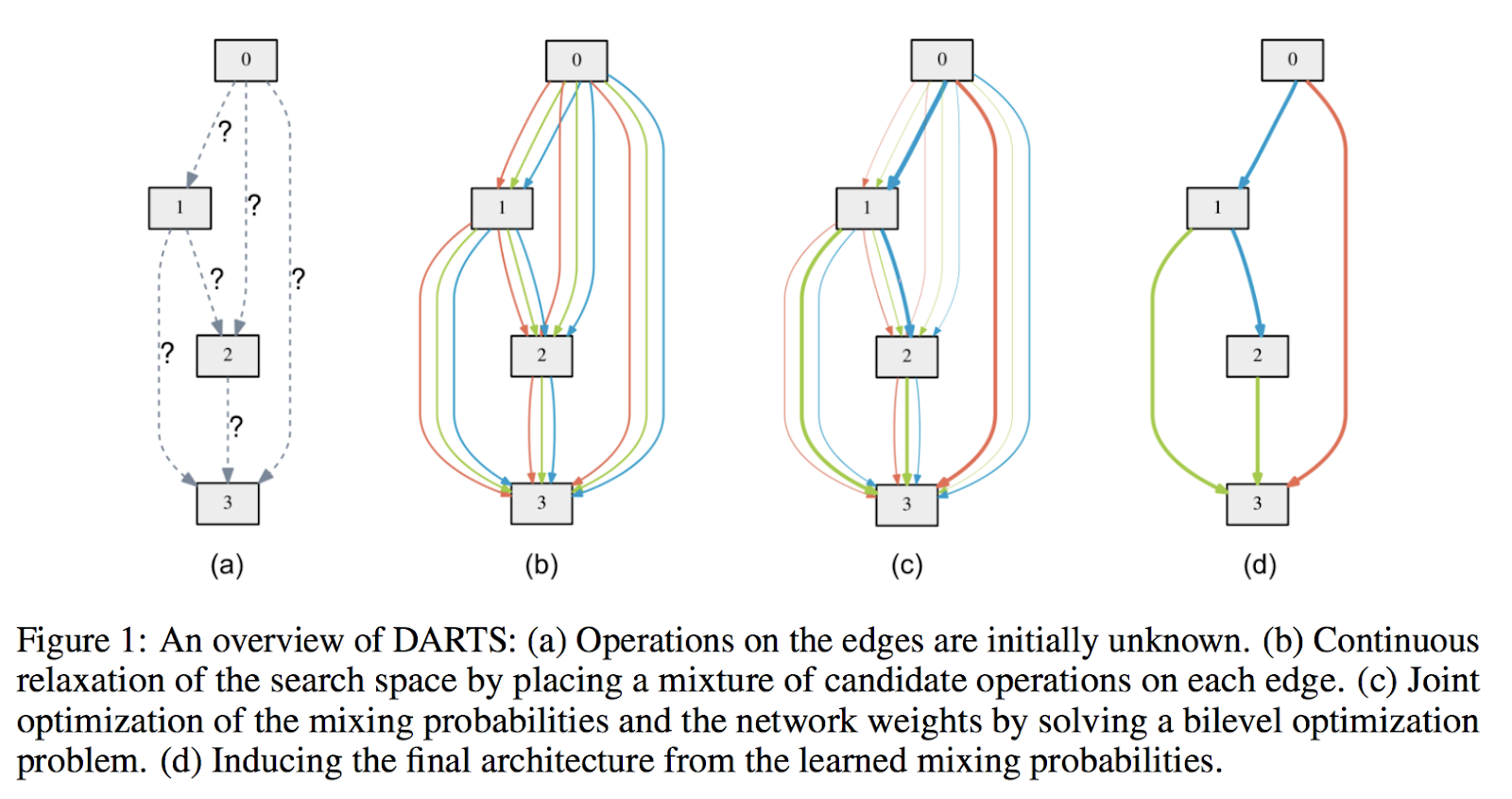
連続的な緩和と最適化(Continuous Relaxation and Optimization)
離散空間を連続空間に緩和するために、DARTSではオペレーション候補の選択をSoftmax関数で表現します。具体的には以下の数式で表します。
\bar{o}^{(i,j)}\bigl(x\bigr) = \sum_{o\in\sigma}\frac{exp\bigl(\alpha^{(i,j)}_{o}\bigr)}{\sum_{o^{'}}exp\bigl(\alpha^{(i,j)}_{o^{'}}\bigr)}o\bigl(x\bigr)\:\:...(1)
ここで$ \sigma $をオペレーション候補の集合(畳み込み、プーリング、何もしない・・・)とし、$ o(・) $で$ x^{(i)} $にそのオペレーションを適用することを表します。ノード$ (i,j) $間のオペレーションの重みはベクトル$ \alpha^{(i,j)} $でパラメータ化することで、探索対象を連続値$ \alpha=\bigl(\alpha^{(i,j)}\bigr) $($ \alpha $をアーキテクチャとする)に置換します。
この関数を用いてオペレーションを探索する利点は、この関数が微分可能であることです。DARTSではニューラルネットワークのアーキテクチャ探索を連続空間とみなすことで微分可能とし、勾配降下法によって最適化を行います。
対象ニューラルネットワークには、重み最適化(通常のニューラルネットワークの学習)とアーキテクチャ最適化(NAS)が同時に実行されます。アーキテクチャ最適化と重み最適化では同じニューラルネットワークに対して別々の目的関数が設定されます。
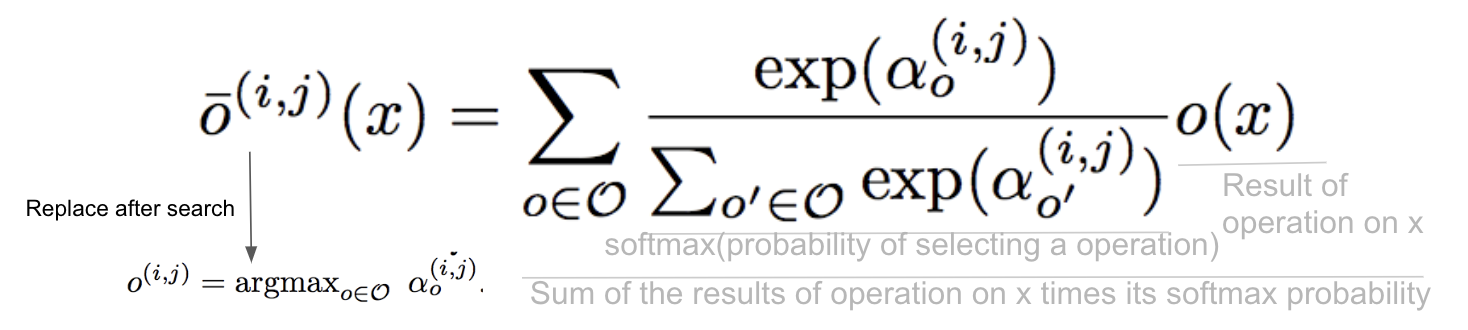
アーキテクチャ最適化の目的関数は以下になります。
min_{\alpha}\:\:L_{val}\bigl(w^{*}\bigl(\alpha\bigr),\alpha\bigr)
$ w^{*} $ を当該ニューラルネットワークの学習済みの重み(固定値)とし、 アーキテクチャ$ \alpha $を最適化することで$ L_{val} $(テストデータに対する損失関数)を最小化しようとします。
重みに対する最適化は以下の目的関数になります。
w^{*}\bigl(\alpha\bigr)=argmin_{w}\:L_{train}\bigl(w,\alpha\bigr)
要はアーキテクチャ最適化の目的関数のうち、$ w^{*}\bigl(\alpha\bigr) $を最適化するということを意味しています。ここではアーキテクチャ$ \alpha $は固定値です。重み最適化ではトレーニングデータを用いて1エポックで学習を行います。
要約すると、トレーニングデータを用いてアーキテクチャ$ \alpha $を固定値として重み$ w^{*}\bigl(\alpha\bigr) $の最適化を1エポック行い、最適化された重み$ w^{*}\bigl(\alpha\bigr) $(固定値)とテストデータを用いてアーキテクチャ$ \alpha $の最適化を行っています。そのため、エポック毎に違うアーキテクチャでニューラルネットワークの学習が行われます。違うアーキテクチャでも同一構成の重みに対しては、学習済みの重みを使う、という点はENASと同様です。
重みとアーキテクチャの更新は以下のステップで行います。

- 重み $ w $ を $ \Delta_{w}L_{train}\bigl(w,\alpha\bigr) $ で更新
- アーキテクチャ $ \alpha $ を $ \Delta_{\alpha}L_{val}\bigl(w-\xi\Delta_{w}L_{train}\bigl(w,\alpha\bigr),\alpha\bigr) $ で更新
- 収束するまで1., 2.をエポック毎に実行
まとめると、$ (1) $ 式をベースにオペレーション選択をSoftmaxで行い、選択されたオペレーションに対してニューラルネットワークをトレーニングデータで学習(重み最適化)し、最適化された重みを用いてテストデータによるアーキテクチャの最適化を行う、というものになります。
DARTSの手法ではニューラルネットワークのアーキテクチャがエポック毎に変化するため、以下のようにDAGが変化します。以下はCNNセルをDAGとした場合の変化なのですが、エポック毎に形が変化し、エポックが進むと収束することが見て取れます。
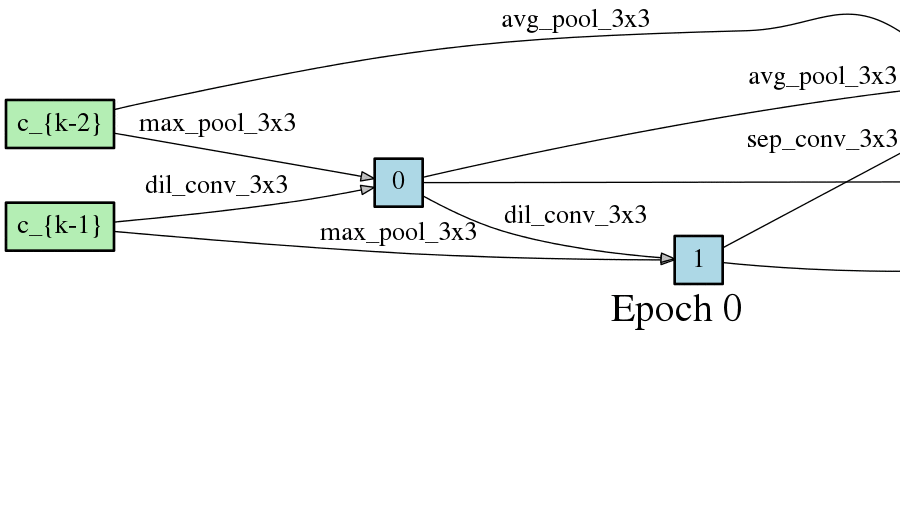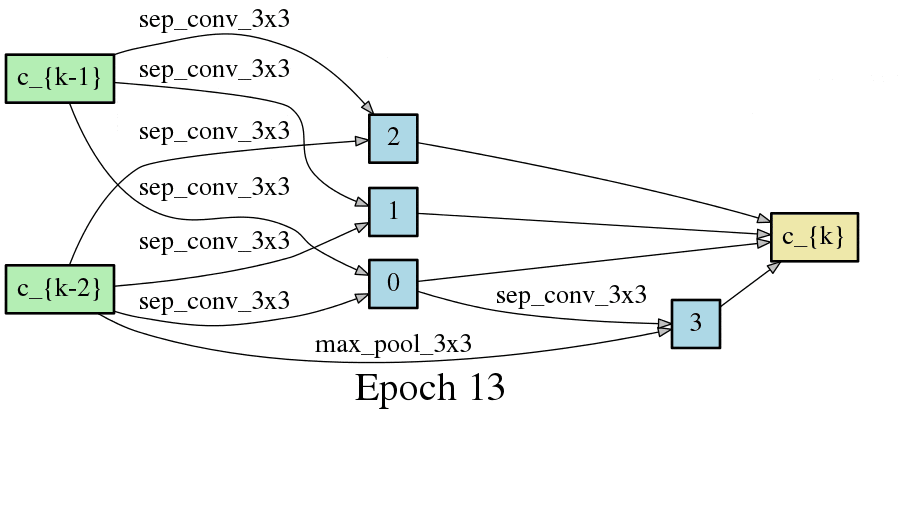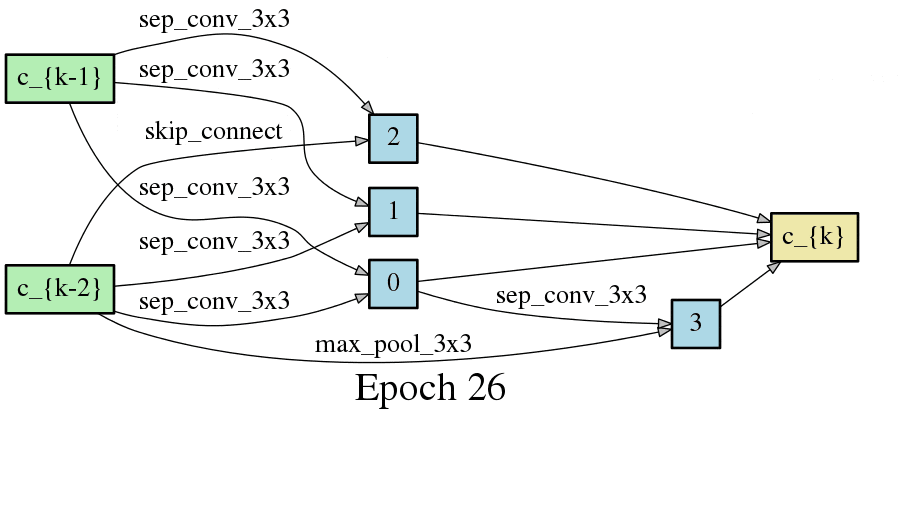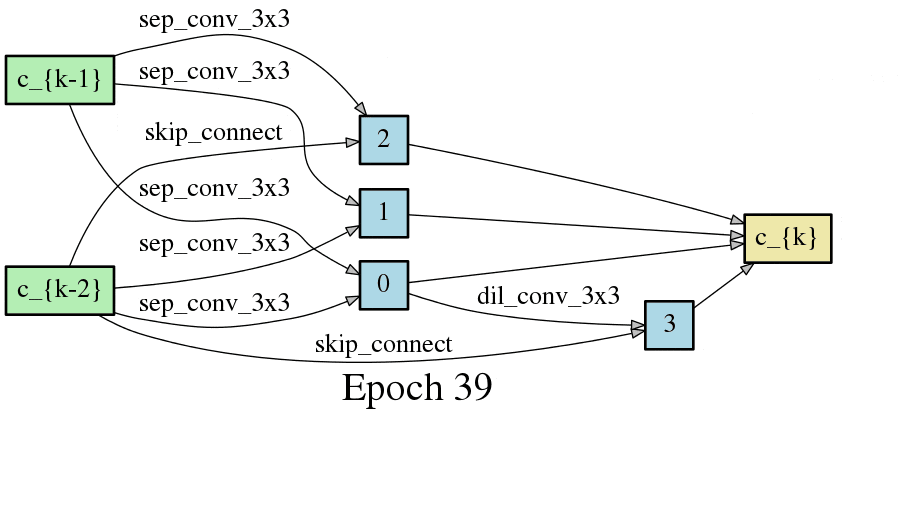
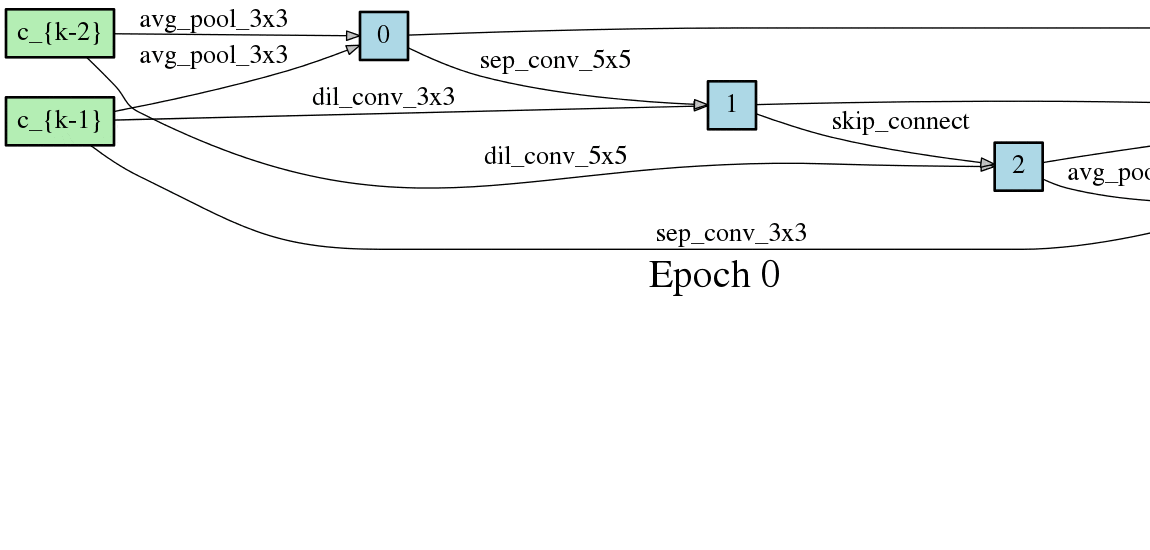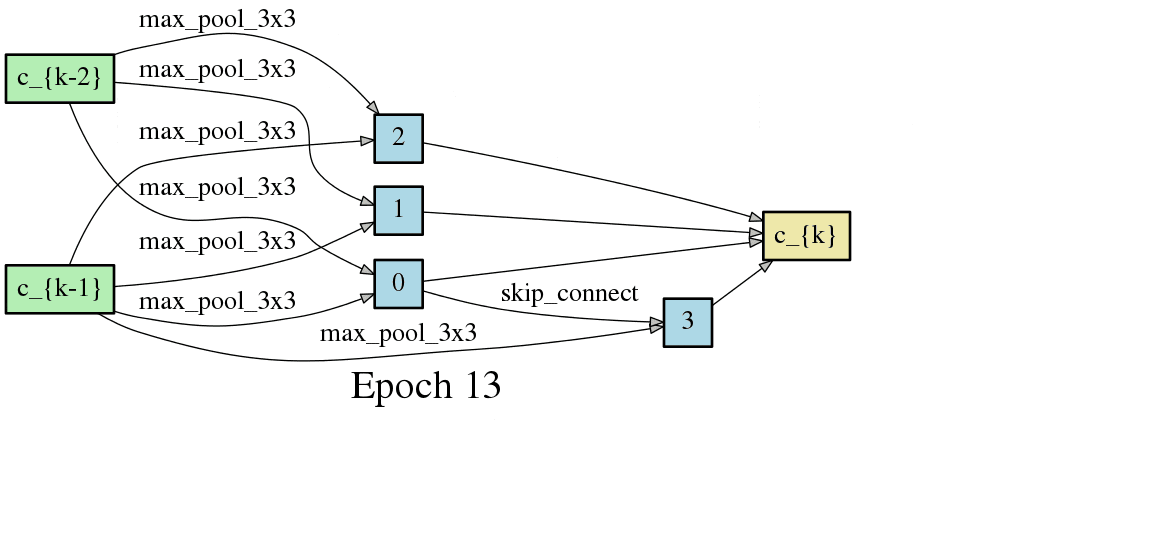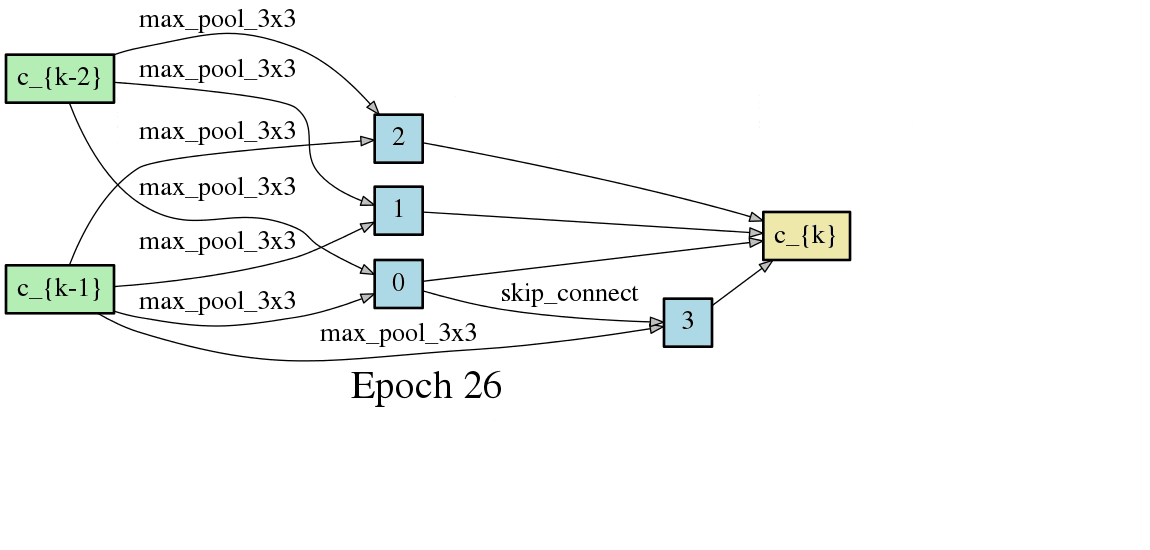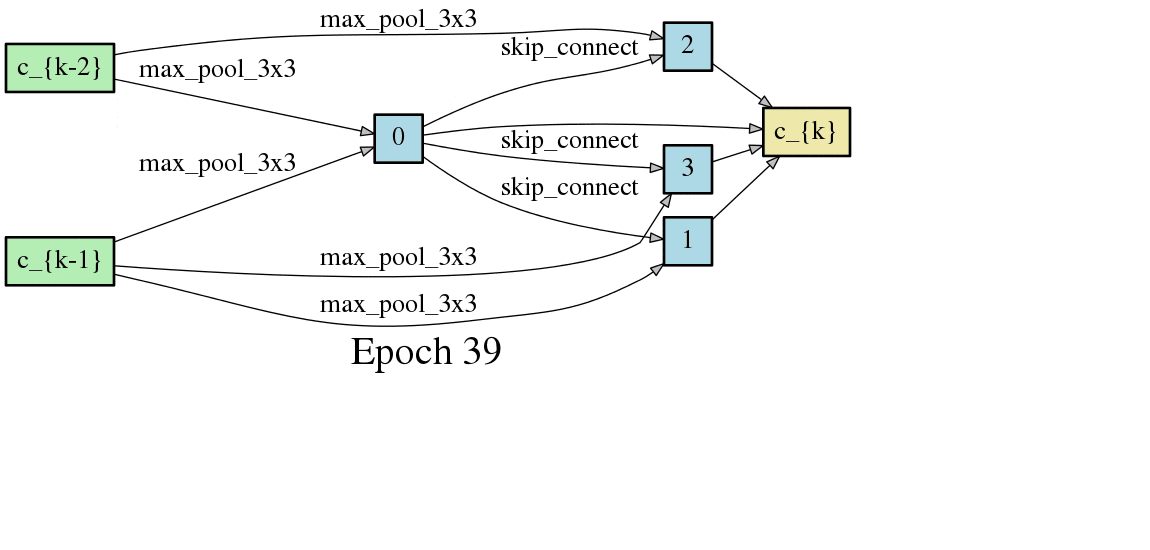
こちらはRNNセルの最適化です。やはりエポック毎に形が変化し、収束していく過程が見て取れます。
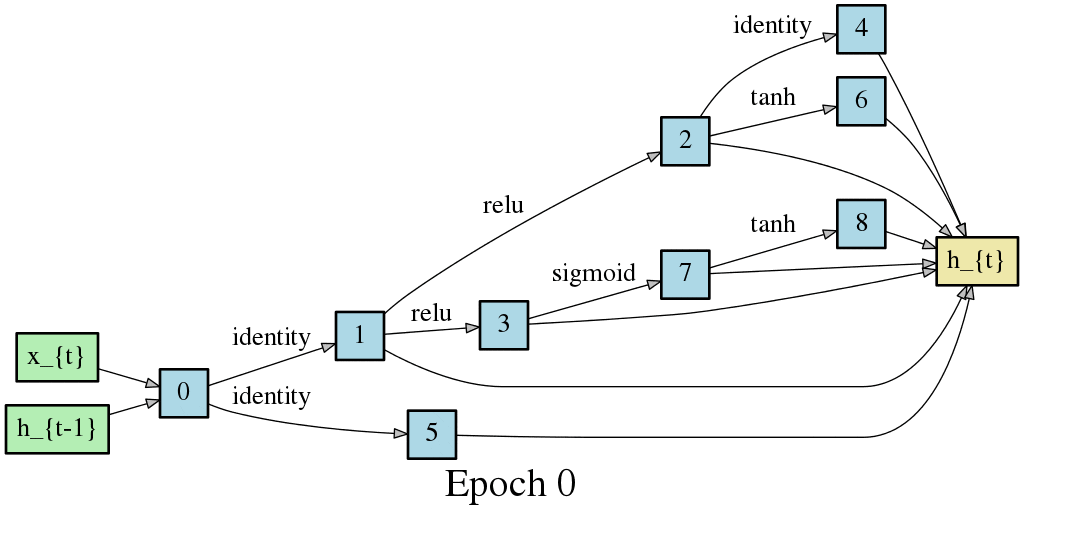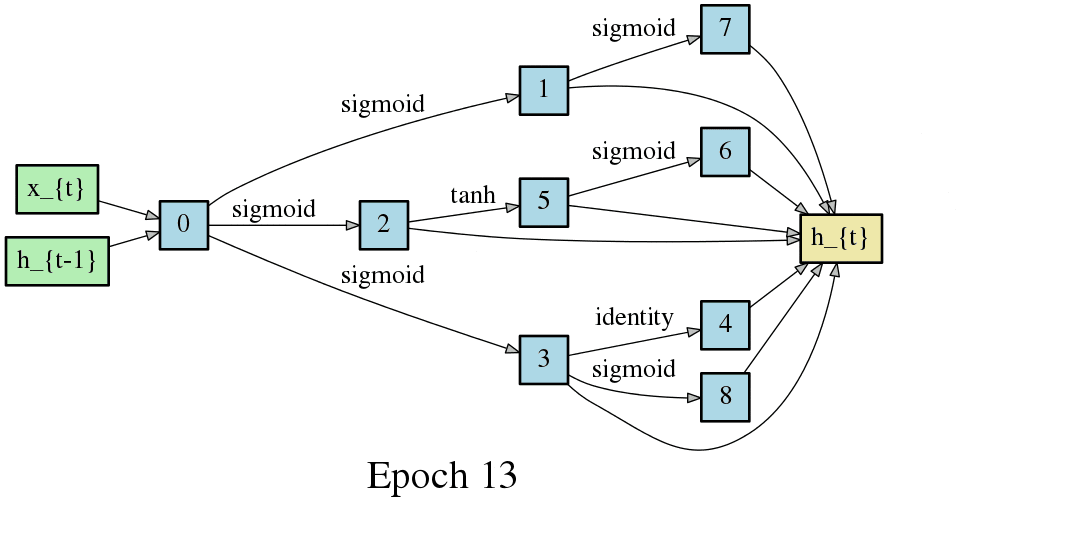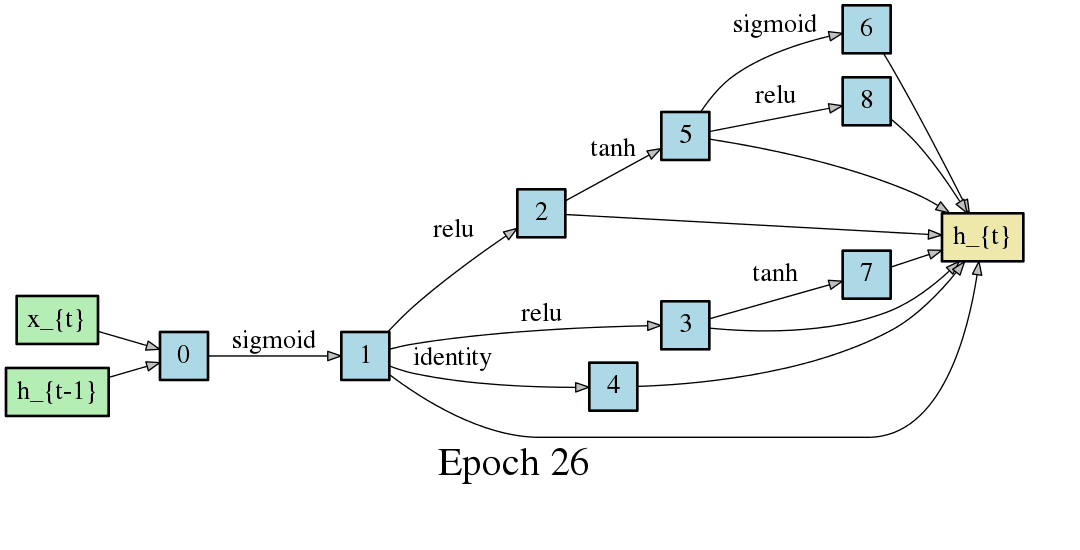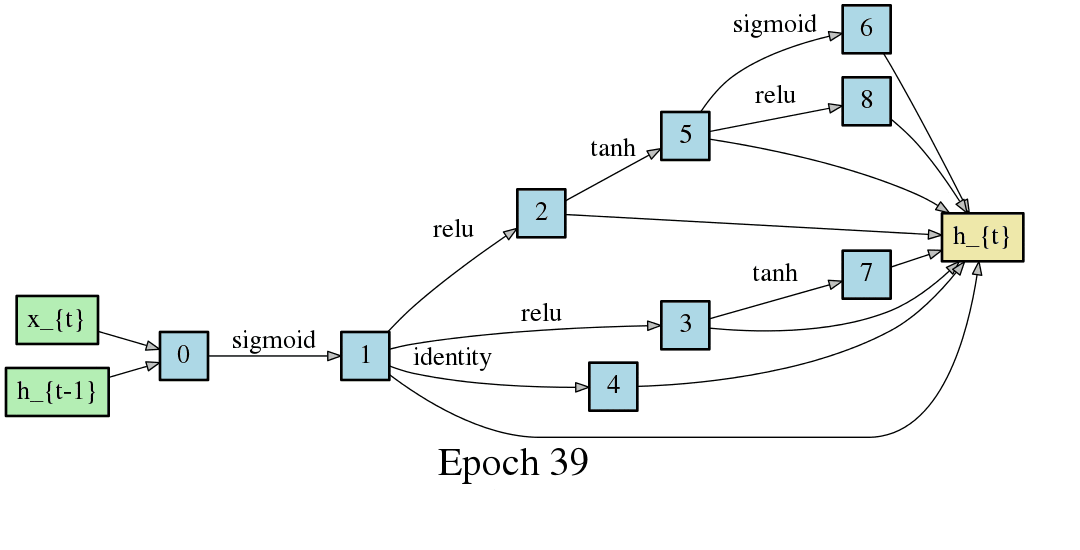
DARTSでは1つのニューラルネットワークでメタ的なアーキテクチャの探索とニューラルネットワーク自体の重み最適化(学習)を実現します。これは従来のNAS(Controller RNNとChild Networkで分離している)ではできなかったことでして、DARTSは探索対象を連続的な空間に緩和することで、オペレーションの選択、引いてはアーキテクチャの探索を微分と勾配降下法に落とし込むことを可能にしました。以降のニューラルネットワークのアーキテクチャ探索では非連続な最適化を連続化することで勾配降下法を用いる手法が主流になっていきます(といってもDARTSの搭乗が2018年なので、2019年にはまた違う最適化手法が主流になるかもしれませんが・・・)。
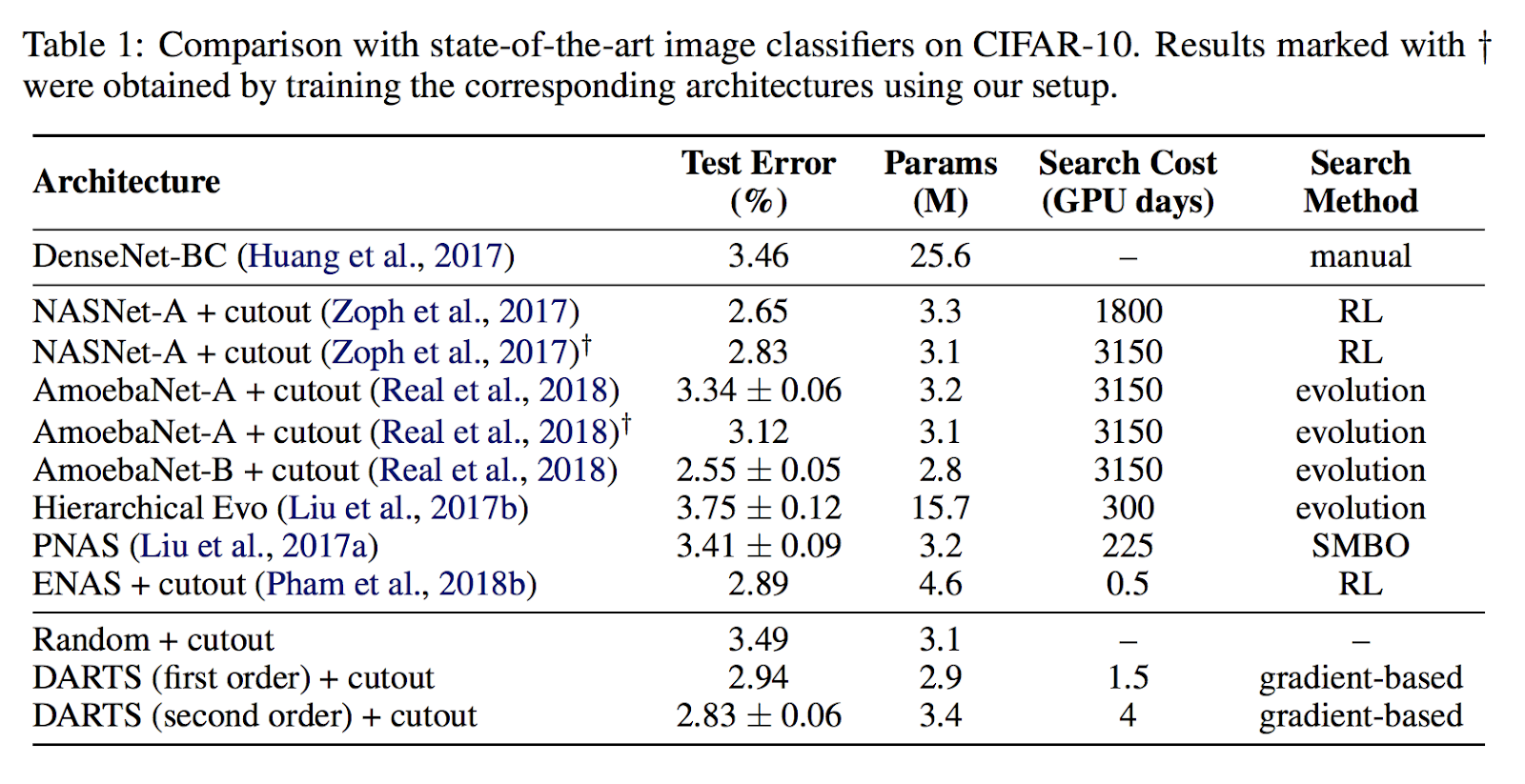
課題
DARTSにより、NAS並みのAccuracyをENAS並みの探索時間(1~4日程度)でニューラルネットワークを最適化することができるようになりました。更には探索対象のニューラルネットワークが一つに限られることで、これまでのNASのように2つのニューラルネットワーク(Controller RNNとChild Network)は不要になります。
しかしこれでニューラルネットワーク・アーキテクチャ探索は終わりではありません。DARTSを含めたNASはAccuracyの最適化を行いましたが、ニューラルネットワークを実用する際に考慮すべきもう一つの重要な課題として、推論時のスピードが挙げられます。
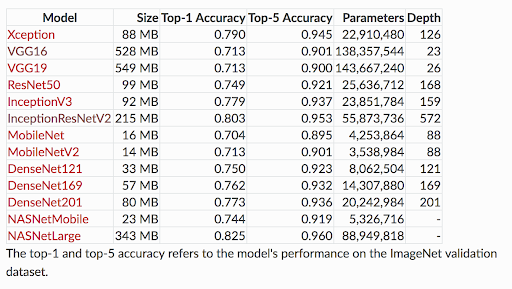
Kerasの学習済みモデルにおけるパラメータ数。NASNetLargeはMobilenetV2の20倍以上のパラメータ数(容量)を持ちます。
FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
前置き
ニューラルネットワークの学習はリッチなGPUとCPUが揃ったサーバで実行されることが主ですが、推論環境が同じようにリッチであるとは限りません。学習は一時的に実行されるものであるため、クラウドを使って必要なときのみGPUサーバを配備することが可能ですが、(バッチ処理でない限り)推論は常に実行可能状態である必要があります。更にはモバイル端末(スマホやデバイス)で推論する場合、数コアのCPUやDSPのみということがほとんどです。
NASやDARTSの課題は、複雑なニューラルネットワークによってパラメータ数が増大し、モバイル端末で実践的に推論するためにはモバイル側のリソースが足りない(遅い・不可能)という点です。FBNetではニューラルネットワークのアーキテクチャ探索の最適化対象を、Accuracyのみならずモバイル端末における推論スピードにまで広げることで、NASの持つ推論の課題に挑みます。
DNAS
FBNetではDNAS(Differentiable neural architecture search)という手法が提案されています。日本語に訳すと「微分可能なニューラルネットワークアーキテクチャ探索」となり、DARTSの目指す方法と類似しています。
FBNetの工夫は最適化の対象をAccuracyとLatency(推論スピード)の両方に広げた点です。そのため、DNASの構造は以下のようになっています。
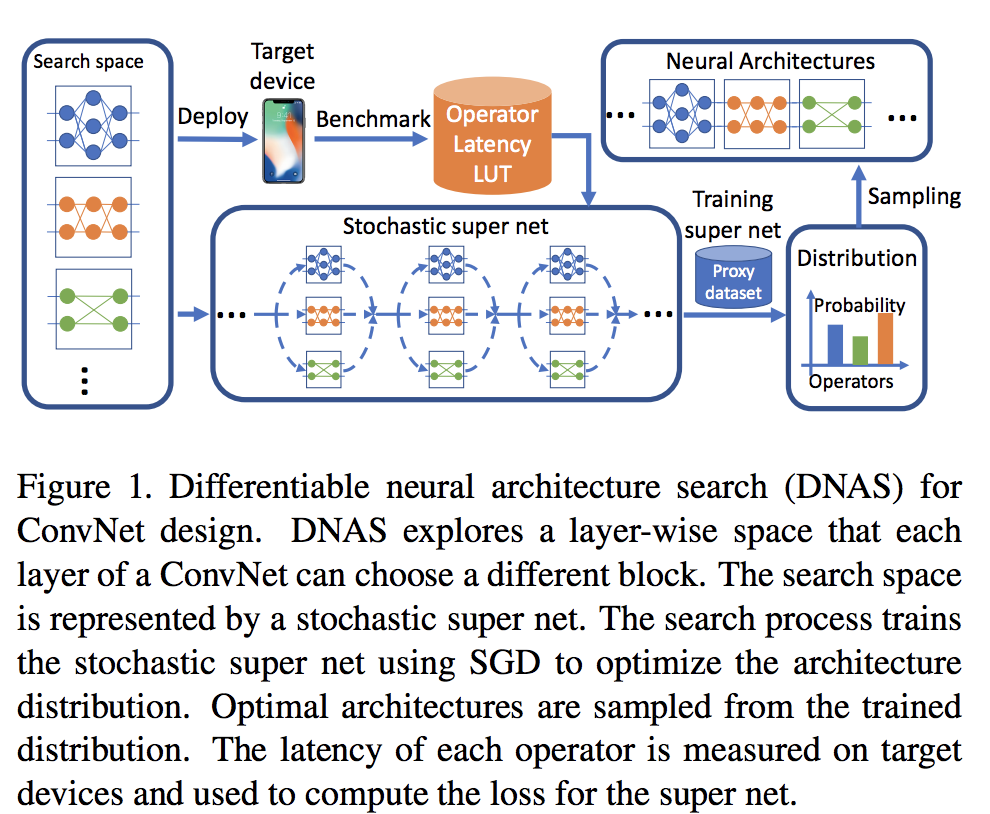
ここで注目すべきはOperator Latency LUTです。LUTはLook up tableの略で、対象デバイス(IPhoneX、SamsungS8等々)での特定の処理の所要時間(スピード)を記録したものになります。LUTを事前に用意しておくことで、ニューラルネットワークの最適化時にスピードを加味してAccuracy*Latencyの最適化を可能にしているのがFBNetの特徴になります(実はFBNetより先にこちらですでにDNASによるデバイス推論含めた最適化は発表されていたりします)。
DNAS自体はDARTSをベースにして探索空間を連続的にすることで微分と勾配降下法による最適化を実践しています。そのため、DARTSの方式を念頭に置いていれば理解することが容易です。DARTSとの最も大きな違いはデバイス推論による遅延を加味した損失関数になります。
FBNetによる遅延を加味した損失関数(Latencuy-Aware Loss Function)
FBNetの損失関数はデバイス推論による遅延(Latency)を加味します。損失関数の具体的な数式は以下になります。
L_{(a,w_{a})} = CE\bigl(a,w_a\bigr)*\alpha\log\bigl(LAT\bigl(a\bigr)\bigr)^\beta
$ CE\bigl(a,w_a\bigr) $はアーキテクチャ$ \alpha $におけるクロスエントロピーロスでして、従来のニューラルネットワークにおける損失関数と動揺です。違いはその後の$ \alpha\log\bigl(LAT\bigl(a\bigr)\bigr)^\beta $でして、$ LAT\bigl(a\bigr) $で、これがデバイス推論における遅延(ミクロ秒)になります。$ \alpha $と$ \beta $は係数になります。
$ LAT\bigl(a\bigr) $は以下の式で表せます。
LAT\bigl(a\bigr) = \sum_{t}LAT\bigl(b^{(a)}_l\bigr)
$ b^{(a)}_l $は$ a $アーキテクチャの$ l $層におけるブロックを意味します。
これはつまり、デバイス推論の遅延は、DNASが選択した$ a $アーキテクチャの$ l $層におけるブロックの処理時間の和とイコールであることを意味します。ニューラルネットワークの各レイヤーの処理時間の合計がFBNetの推論所要時間になる、という意味です。そして各レイヤーの各オペレーションの所要時間はLUTで事前に計測しておくものになります。
更に重要なのは、この所要時間がLUTをベースにした「固定値」であることです。
探索対象のオペレーション
FBNetではニューラルネットワークのレイヤー数11層で固定にし、そのうち7層のオペレーションを探索対象とします。
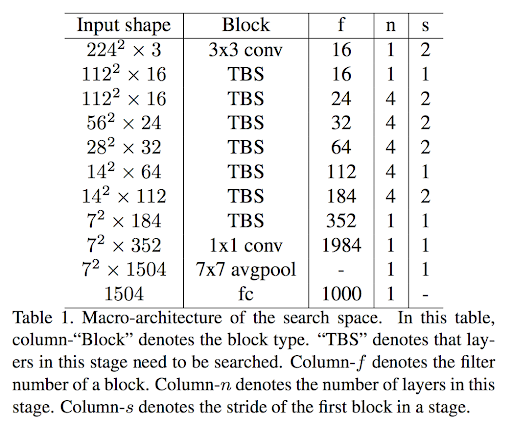
探索の選択肢となるオペレーションは以下で、ブロックと呼称されています。
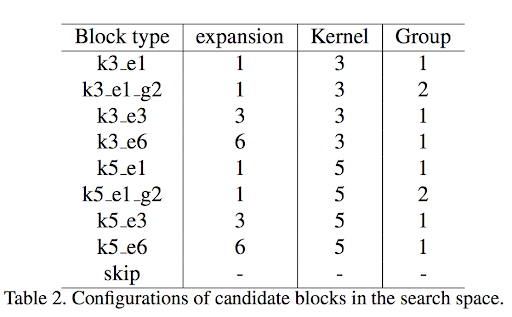
上記テーブルのうち、kはカーネルサイズ、eは拡大比率、gはグループコンヴォリューション(group convolution)のグループ数になります。これらの前後に1x1畳み込みを実行します。なお、skipはスキップ(処理を飛ばす)選択肢です。全体像は以下ようになります。
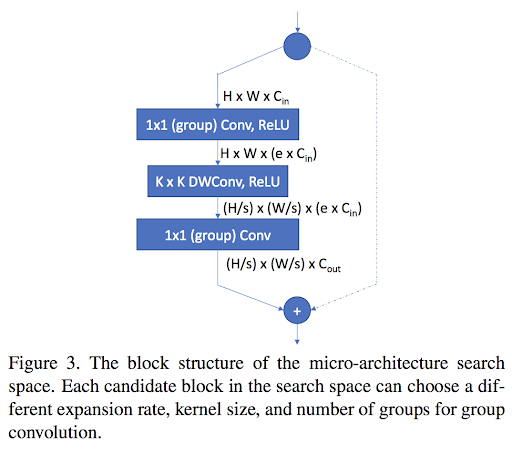
最適化手法
オペレーション選択はDARTS同様にSoftmaxをベースにしていますが、DNASではGumbel Softmaxという強化学習の行動選択で使われる関数を使用しています(詳しくは以下論文参照)。
- Categorical Reparameterization with Gumbel-Softmax
- The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
オペレーション選択は以下の式で定義されます。
m_{l,i}\:=\:GumbelSoftmax\bigl(\theta_{l,i}|\theta_l\bigr)\:=\:\frac{exp[\bigl(\theta_{l,i}+g_{l,i}/\tau\bigr)]}{\sum_{i}exp[\bigl(\theta_{l,i}+g_{l,i}/\tau\bigr)]}
$ \theta_{l,i} $がレイヤー$ l $におけるブロック$ i $の選択になります。
$ g_{l,i} \sim Gumbel\bigl(0,1\bigr) $はGumbel分布に従うランダムノイズです。$ \tau $はTemperature(温度)で、$ \tau $が0に近づくと離散的に、$ \tau $が大きくなると$ m_{l,i} $は連続的になります。それ以外は基本的にSoftmax関数でして、最大値を選択されたオペレーションとします。
この$ m_{l,i} $が$ \theta_{l,i} $を元にしたレイヤー$ l $におけるブロック$ i $の微分可能な選択になります。微分可能であるため、勾配降下法で探索可能です。この数式を元にAccuracyの最適化を勾配降下法で実行します。更に処理時間はLUTベースの「固定値」になるため、微分に影響はありません。
結果として、FBNetではAccuracyとLatencyのバランスをとった最適化を実現しています。
探索結果
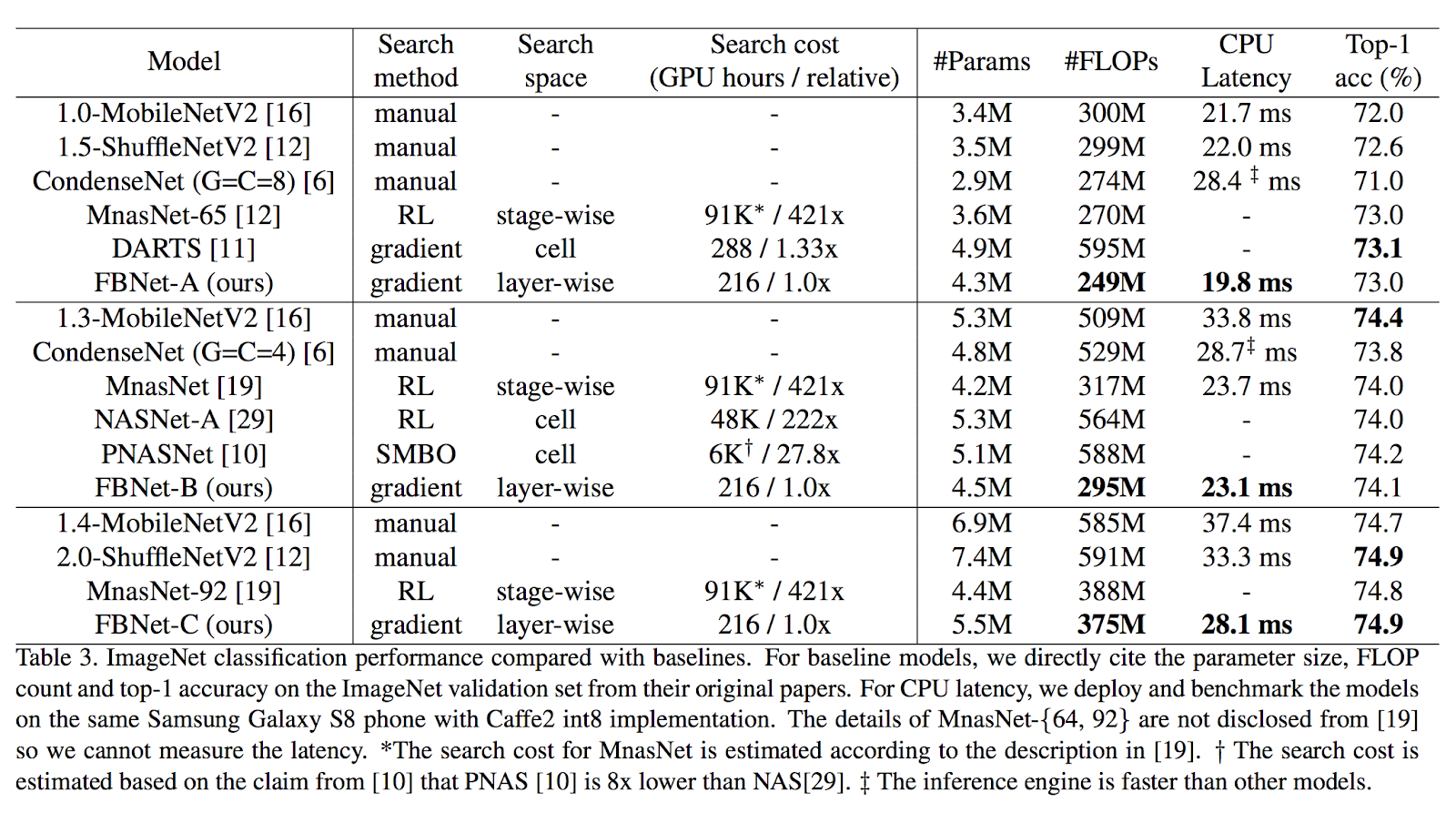
探索結果は以下のとおりです。
FBNetの目的は推論Accuracyとスピードのバランスなので、表の比較対象にはNAS以外にもMobilenetが入っています。注目すべきはFLOPsやCPU Latencyで、Top-1 Accuracyを保ちつつスピード(処理量)を軽減できていることが見て取れます。
特定デバイスに特化した探索結果が以下です。
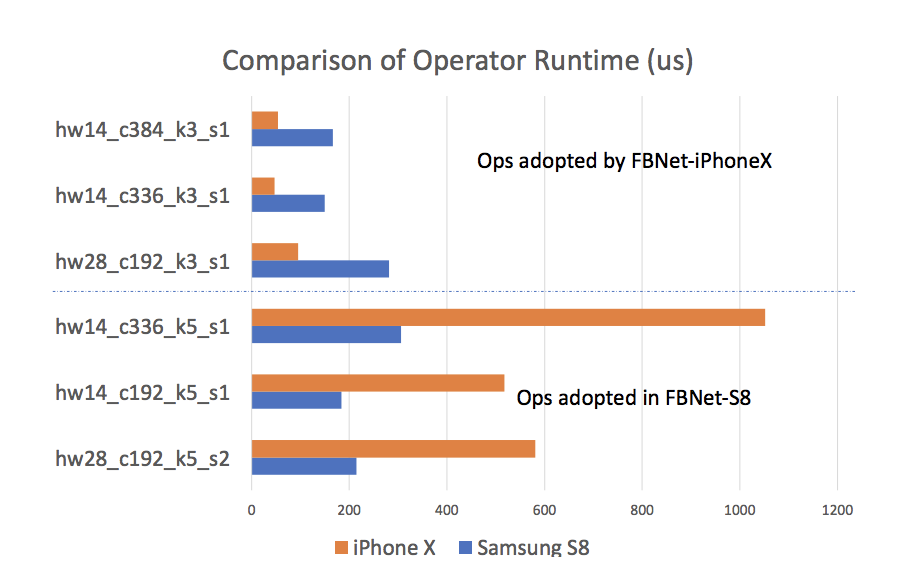
ここではIPhone XとSamsung S8を対象にしていますが、それぞれに特化したニューラルネットワークが出来上がっていることがわかります。興味深いのは、IPhone Xに最適化されたニューラルネットワークはSamsung S8で速いとは限らない(逆も然り)ということです。
これはつまり、これまで探索されてきたニューラルネットワークはあくまで学習と検証で評価された汎用的なものでしかなく、デバイスごとの推論スピードを加味すると、更に最適化する余地があるということを意味しています。従来の高Accuracyを誇るニューラルネットワークは、特定デバイス(CPUアーキテクチャ含めて)で実用的に使うには無駄な計算処理が存在すると言えるかもしれません。
最後に
Neural architecture searchはAccuracyを追い求めるだけのニューラルネットワークではなく、更に実用的にスピードまで考慮したアーキテクチャ設計を実現するようになってきました。
特にモバイルでリアルタイムに物体検知(Object detection)を実行するときを想定すると、スマホを動かしながら物体を検知する場合、求められるのは100%に近いAccuracyではなく、物体にカメラを向けたときにちょうど良く検知することであり、これは正確性とスピードの掛け算になります(うまく検知できなければ、人間がスマホを動かすでしょうし)。
更にVR/ARデバイスやDSP、デバイス、機械でのニューラルネットワーク活用を考えると、汎用的なニューラルネットワークを開発するよりも、特定の機器に特化したニューラルネットワークを効率良くスピーディに生産、実装することが求められる時代になってくると思います。そして多様な機器特化のニューラルネットワークは、人間が開発するよりもアーキテクチャ探索のアルゴリズムを用いるほうが生産的です。DARTSやFBNetの登場は、今後のニューラルネットワーク開発、実用化の主流になっていくると思います。