今回記事として書くのは,エンティティ・リンキングというタスクに対するチュートリアルです.
以下のシリーズになっています。
- Entity Linking チュートリアル 前編 ざっくりとした歴史編 [本記事]
- 中編 前処理・実験準備編
- 後編 実験・評価編
- 発展編 知識ベース全体に対するBi-encoder探索の実装
- 本シリーズの Colab Pro上での実行について
目的
- エンティティ・リンキング (Entity Linking) というタスクについて,より多くの人に知ってもらう.(当記事)
- 実際にBC5CDRデータセットに対して,動くデモを実装しタスクを理解する.
エンティティ・リンキング とは
エンティティ・リンキングとは,文書中に存在する,メンションと呼ばれるテキスト範囲を知識グラフ内に存在するエンティティへとマッピングするタスクであり,自然言語理解及び応用における重要なタスクの一つとされています.

実際にエンティティ・リンキングが実用される例について,例えば対話エンジンが存在します.以下に実用例スライドを用意しました.(画像を押すと、スライドにジャンプします。)
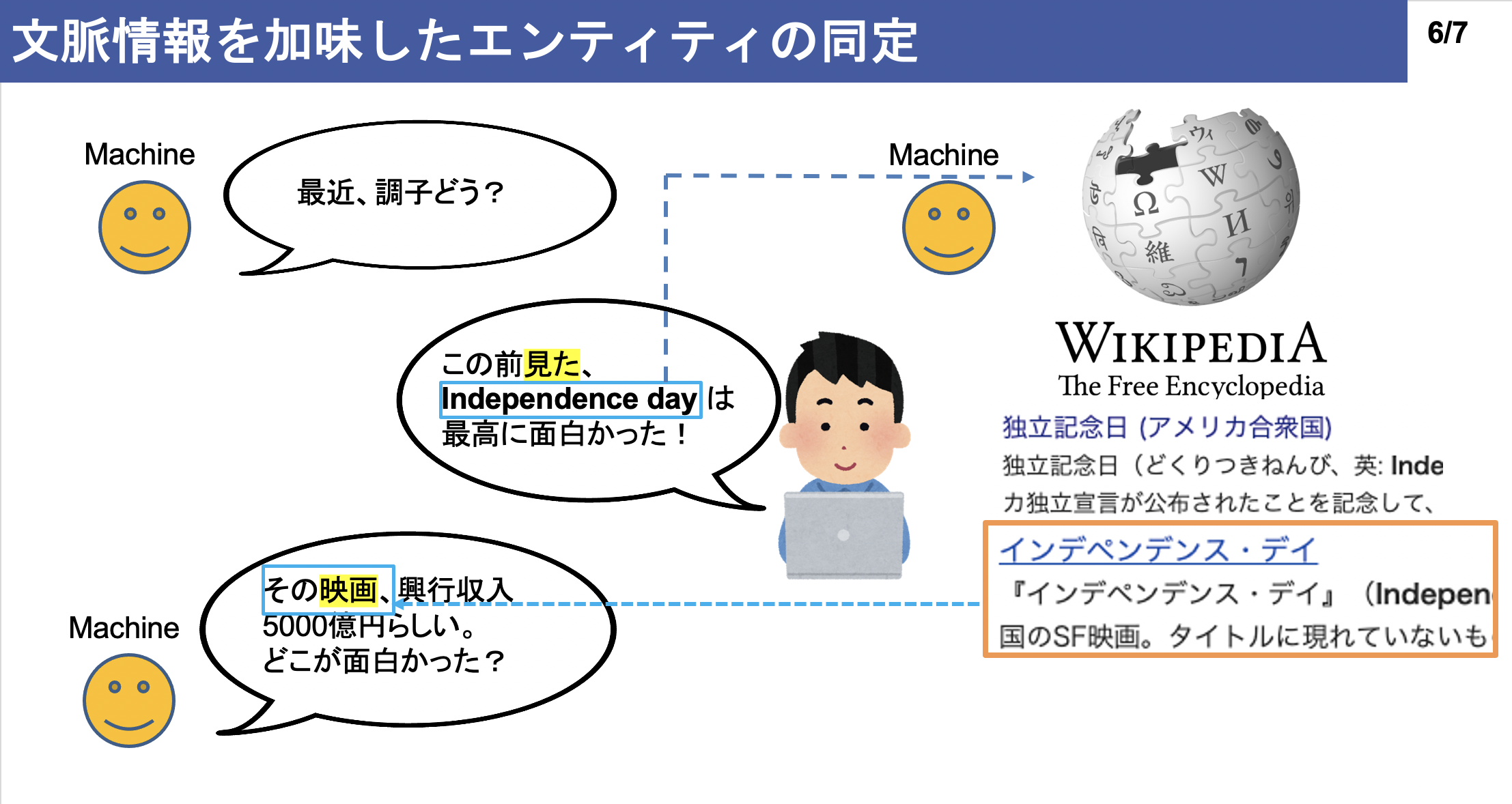
エンティティ・リンキングの応用例
上記はあくまで応用例の一つであり,この他にも当タスクは文書理解,文書要約,検索システム等様々な場面で応用されています.
一つだけ,ここで注意点を挙げます.本記事ではメンションは予めNERモデルによって検出されているものとします.つまり、メンションのスパン同定については扱いません.(メンションのスパン検出までを含めたEnd-to-Endモデルとしては [Kolitsas et al., '19] などが存在します.)
従来のエンティティ・リンキング
後述のBi-Encoderモデルが登場するまでは,エンティティ・リンキングは以下のサブタスクを順に解くことで行われていました.

エンティティ・リンキングを解く際には,メンションの周辺文脈に加えて
- 文書全体のトピック
- 知識ベース内のエンティティが持つ正式名 (Canonical name)
- エンティティの説明文
- エンティティが属するカテゴリ (Type)
等,使用し得る手がかりが数多く存在します.
2018 年後半までは,メンション及びその周辺コンテクストが保有する情報や,エンティティが持つ情報を活用したリンキングの精度向上が主に行われてきました.例えば,[Gupta et al., '17]の提案手法ではメンション周辺の文脈を出力するエンコーダの学習に加えて,エンティティが保持する type や説明文のエンコーダを同時学習させることで,リンキングの精度向上を試みています.
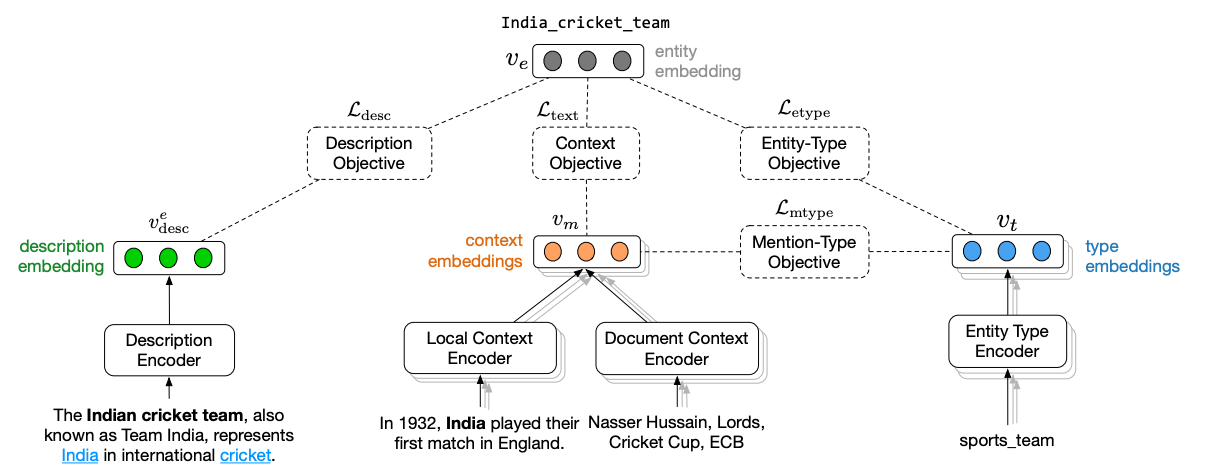
メンションが含まれる1文章のみを考えるモデルは Local modelと呼ばれ,メンション周辺のコンテクストに加えて,メンション同士の一貫性を考慮するモデルを Global model と呼ばれます.後者の場合,同じ文書中に出現するエンティティは全て似たトピックに属するという前提が置かれます.この前提を置くGlobal modelでは,エンティティ同士の文書内一貫性をどのように定義するかがリンキングの精度に関わります.
代表的なGlobal model の例をいくつか挙げると,例えば [Cao et al., '18] は文書内に存在するメンションをノードと見なし,文書内メンションからグラフを構成する手法を提案しました.この時構成したグラフに対し,グラフニューラルネットワークを用いてノード情報を相互に伝播させることで,メンション同士の一貫性を考慮しています.1
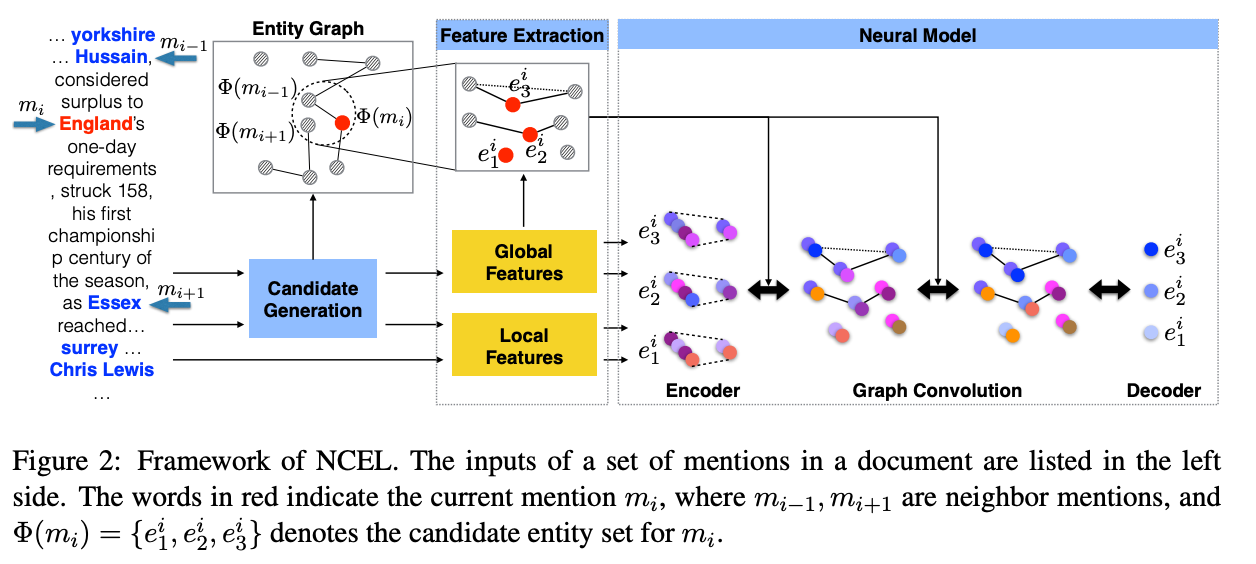
また,[Le and Titov, '18] は,メンション同士が共参照以外の関係でも結ばれているという仮定の下,メンション同士の関係を表現する潜在的関係を学習させることで Global model におけるリンキングの改良を行っています.
Alias Table によるエンティティ候補絞り込み
これらのモデルに一貫して共通する点として,(i) リンキング対象の文書は,Wikipedia の保持するエンティティが出現する分野(一般分野)であること,(ii)メンションに対してエンティティの予測を行う際,Alias Table と呼ばれる同名辞書を用いていること,の 2 点が挙げられます.
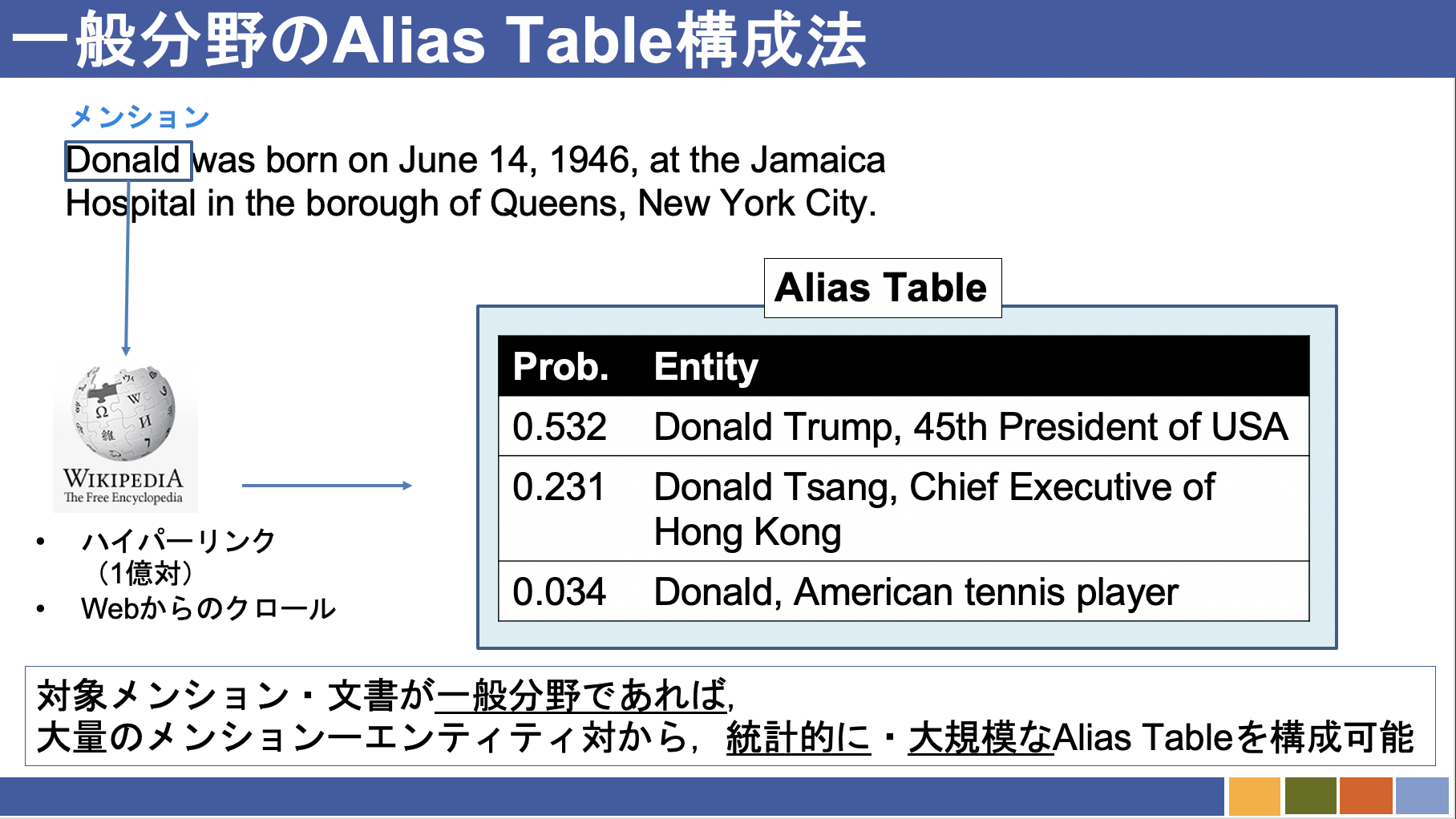
Alias Tableとは,あるエンティティが取りうる文字列表層の集合,またはその逆である,ある文字列が指しうるエンティティについての集合を指します.例えば,文章中に"Donald"という文字列が現れた場合の候補は以下のようになります.(画像はWikipediaより引用)

"Donald"に対して分かりやすい候補を3つ出してみました.(リンキングすべきエンティティは,言うまでもないですが,ドナルドダックになります.)
一部の研究([Eshel et al.,2017]; [Gupta et al., 2017])では,CrossWiki([Spitkovsky and Chang., 2012])や PPRforNED([Pershina et al., 2015])など,事前に構成済みの辞書を Alias Table として用い,知識ベース内に存在する膨大なエンティティからの候補削減を行っています.また他にも有名な Alias Table の構成法としては,Wikipediaなどの大規模なWebコーパスからアンカーテキストを正解エンティティ付きアノテーションコーパスとして使用した例も存在します.([Yamada et al., 2016]; [Ganea and Hofmann., 2017]; [Le and Titov., 2018]; [Cao et al., 2018]).後者のアプローチの利点としては,コーパスから収集された頻度情報 (Prior と呼ばれる) をリンキング時に考慮できる点が挙げられます.実際に今挙げた先行研究のほぼ全てが,Priorも特徴として使用しリンキングモデルを学習させています.
Alias Table によるエンティティ候補絞り込みの欠点
対象文書が一般分野に属す場合,エンティティ・リンキングを行う際,Wikipedia 上のハイパーリンクやウェブ上の文書から構成される Alias Table を候補生成時に使用することが可能です.一方,一般分野とは異なる(例えば生物医学分野や法律分野といった)文書のエンティティ・リンキングを行う場合を考えると,Wikipedia は必ずしも該当分野の Aliasを網羅してるとは限りません.
この場合でも,Alias Table は予め対象ドメインの知識ベースにおいて用意されている場合があります.しかし,メンションが持ちうる表記ゆれすべてを Alias Table 内に用意することは,事実上不可能です.この問題への対応として,[Murty et al., 18]は文字 n-gramから構成された特徴量を用いており,また [Logeswaran et al., '19]は BM25 と呼ばれる特徴量を用いています.しかし,どちらもメンションやエンティティ自身の表層文字列のみを用いて Alias Table を作成しており,表層形のみで Alias Table を完備なものにすることは不可能です.事実,候補辞書による正解エンティティ生成の成功率はそれぞれの文献におけるテストデータで 81.82%及び 76.0%止まりとなっています.Alias Table を用いて生成された候補集合に正解エンティティが含まれない場合,そのメンションはその時点で知識ベース内エンティティとのリンキングが不可能となってしまいます.
まとめると,
(A.)文字列ベースによる候補生成の場合,表層が異なるメンションーエンティティを考慮しにくくなる
(B.)一般ドメインで使用される Alias Table の構成法に倣い候補辞書を作成する場合,膨大な量のメンションーエンティティ教師対応が必要となる.
この2点が欠点になります.

Bi-Encoderモデルによる全探索の高速化
上記のうち,主に(A.)の欠点を克服したモデルを[Gillick et al., '19]は提案しました.
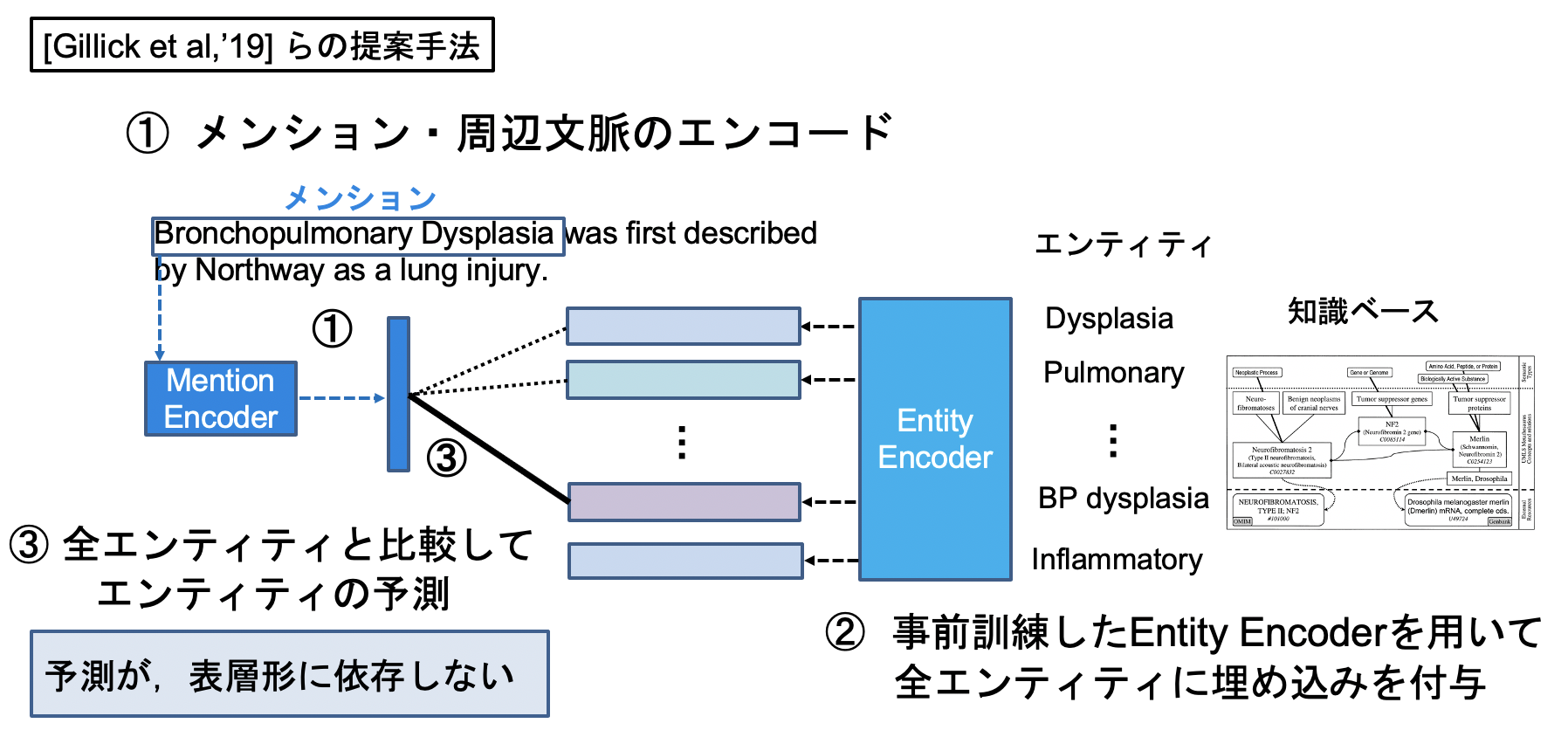
上記図の②,知識ベース内の各エンティティの特徴ベクトルを出力するエンコーダに約1億対の教師対を使用しているものの,この手法により1メンションー全エンティティの比較が可能となりました.③の部分では近似近傍探索をこのタスクに置いて初めて彼らが導入し,高速化を図りました.
各エンコーダのアーキテクチャは,この考え方とBERTとを組み込んだモデル ([Humeau et al., '20]) が現在では主流となっています.
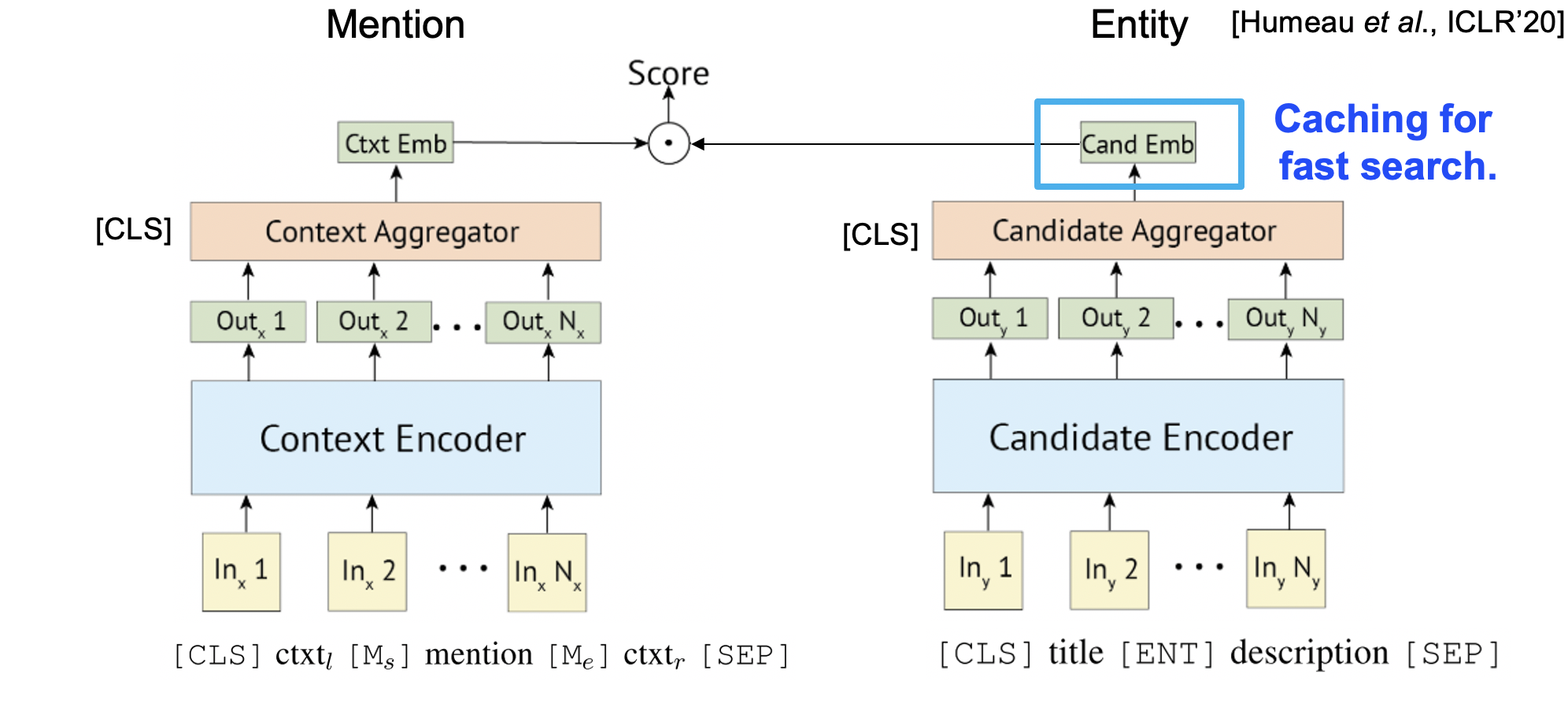
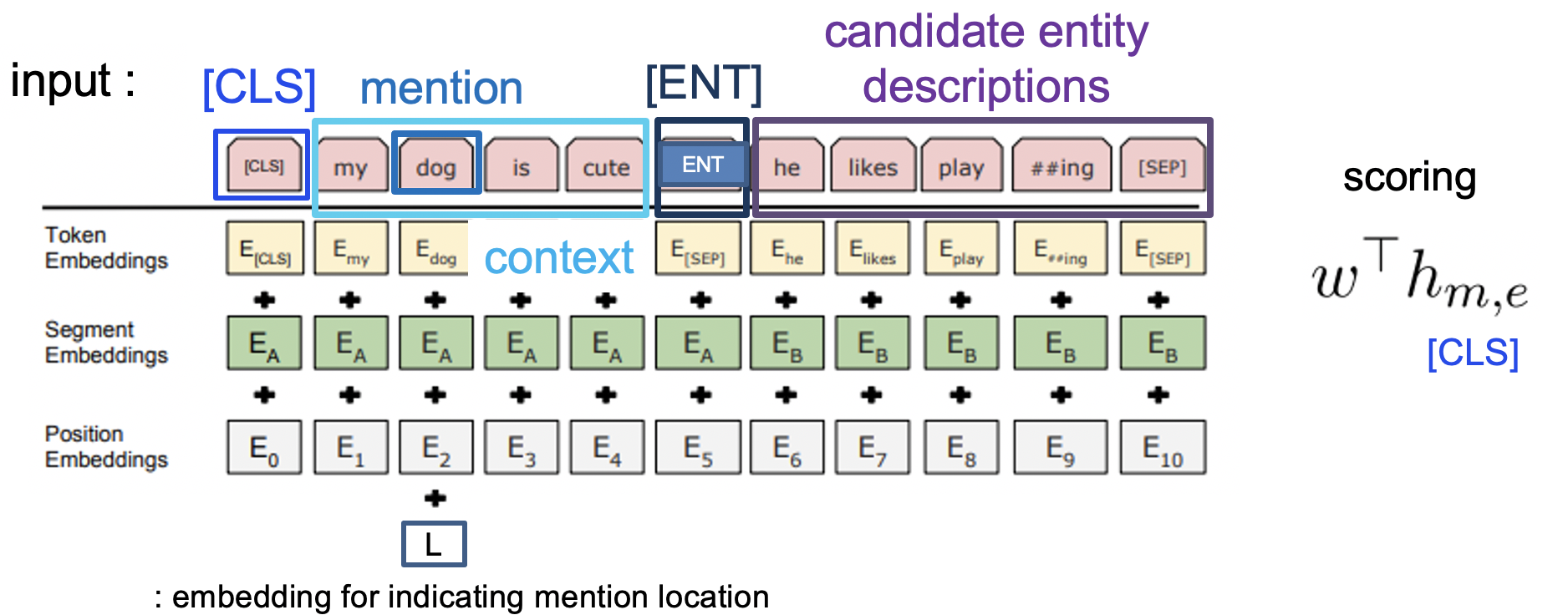
また,Bi-encoderモデルと同時によく比較されるのがCross-encoderモデルです.上記のBi-Encoderモデルの場合,予め与えた教師データによってCandidate-Encoderを訓練した後各エンティティをエンコーディングすることで,一度出力したエンティティ特徴ベクトルを使い回すことが可能になります.
一方,Bi-encoderモデルは結局の所メンション側とエンティティ側の最終出力同士を比較することになるので,例えばメンションが含まれるコンテキストと,候補エンティティの説明文間の密な相互作用を考慮出来てはいません.速度をある程度犠牲にしても良い場合,あるいは候補エンティティ数がある程度限られている場合,メンションーエンティティ説明文間の相互作用も加味できるCross-encoderが使われることもあります.
エンティティ・リンキング周辺における新しい問題
Bi-encoderモデルの登場と同時期に,これまでのIn-domainで豊富なアノテーションコーパスが存在する舞台設定とは異なる問題の定式化も多くされました.例えば訓練時のドメインとは異なるドメインでリンキングの推論を行うZero-shotの設定([Logeswaran et al., '19])や,アノテーションの存在しないドメインにおけるアノテータへの候補推薦([Klie et al., '20]), ラベルなしデータを用いたエンティティ・リンキング([Le and Titov, '20])などが挙げられます.この他にもEMNLP2020等でもエンティティ・リンキングを扱った論文が数本投稿されており,まだまだホットな研究分野であると言えます.
さいごに
今回の記事はここまでです.後半では実際にAllenNLPを用いて,Bi-Encoderモデルの実装と評価を行う予定です.
記事では紹介しきれなかった面白い論文も
https://github.com/izuna385/Entity-Linking-Recent-Trends
にて紹介しております.是非ご一読ください.
次の記事