なんの記事?
これまでPaperSpaceで自然言語処理の実験用に使用していたのですが、
- 高い
- 安く何度も実験したい。
- 自分が行った実験を、他の人でも手軽に再現できるようにしたい。
などの理由から、Colabを使ってみようと思い、この記事を書きました。
本記事では、メイン実験とサブ実験をColab-Proで再現することを目標にします。(本記事を通して、より多くの人にエンティティ・リンキングの面白さを手軽に体感してもらえたら、とても嬉しいです。)
【注】Colab-Proが契約してあることが本記事の前提になります。契約状態であれば、ここにアクセスした場合、左上のアイコンがPro使用になっています。

gitを用いたDeepLearningの実験再現
実際に、実験リポジトリをColab環境に落とし、sshでColab-Pro(GPU)にログインして実験を完了させることを目的とします。
Colab-Proのセッション開始
Colab-Proの使用には月額1,000円程度が必要です。事前に契約してあることを前提にします。
-
ここにアクセスし、左上からノートブックの新規作成をクリック

-
ランタイム→セッションの管理をクリック

-
「他のセッションをすべて終了」をクリック。
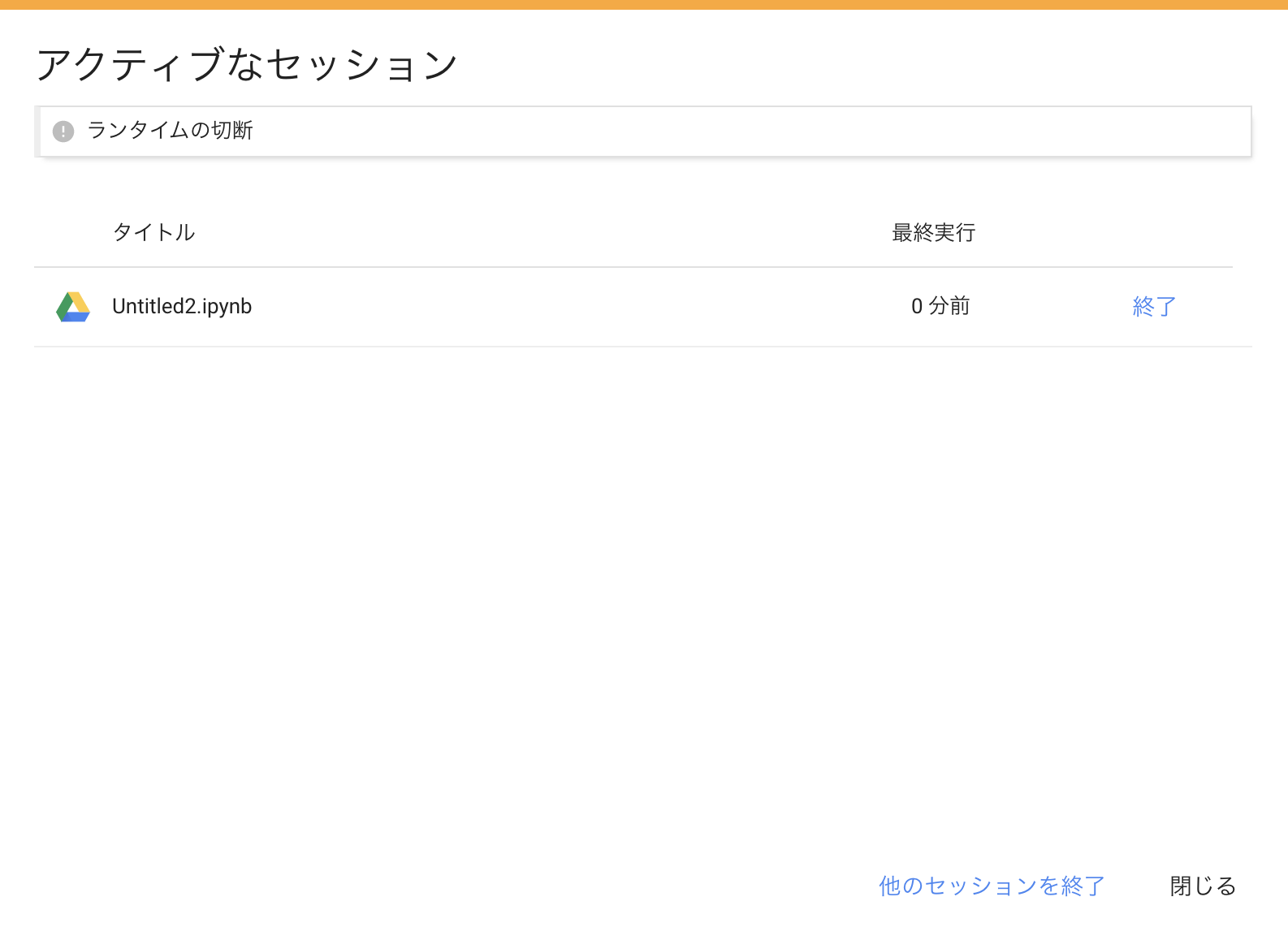
他のセッションが生きている場合、本記事はエラーが出る可能性が高いです。事前に他のセッションをすべて終了させて下さい。
GPUランタイムへの変更
-
ランタイム→ランタイムのタイプを変更 をクリック
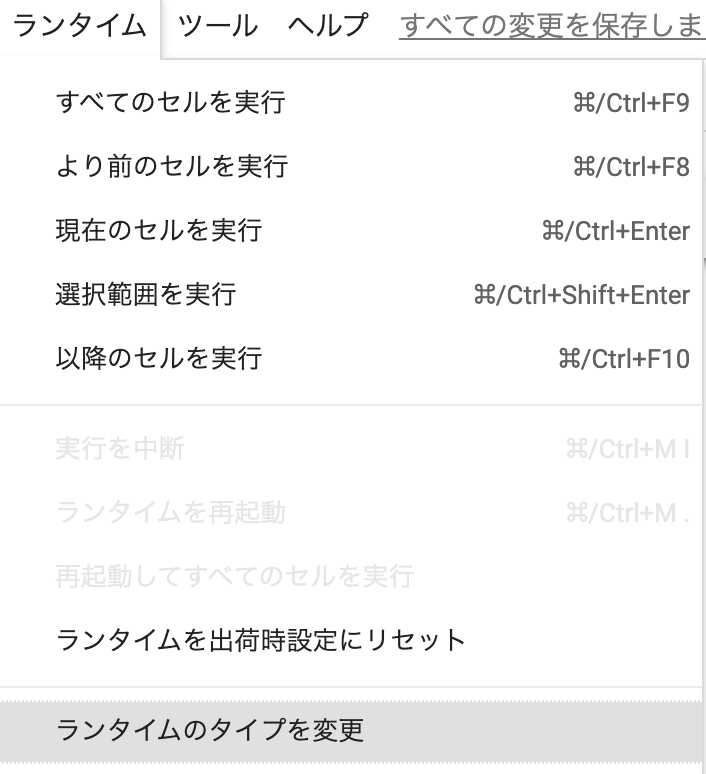
-
ハードウェアアクセラレータをGPUに変更→保存

作製したノートブックセッションへのsshログイン
-
https://dashboard.ngrok.com/get-started/your-authtoken にアクセスし、トークンをコピーします

-
sshのポートを開ける。
以下をセッションに貼り付け実行します。
!pip install colab_ssh --upgrade
from colab_ssh import launch_ssh
ngrokToken = "your_authtoken" # 先にコピーしたトークン
launch_ssh(ngrokToken, password="your_password")
成功した場合、以下のようなsshログイン情報が与えられます。

-
先程の情報を元に、ローカルのターミナルからssh ログイン
ssh root@8.tcp.ngrok.io -p 14082Are you sure you want to continue connecting? -> yes でOK.
パスワードを聞かれるので、先程記入した
your_passwordを使用します。 -
ログインして
nvidia-smiしてみる。
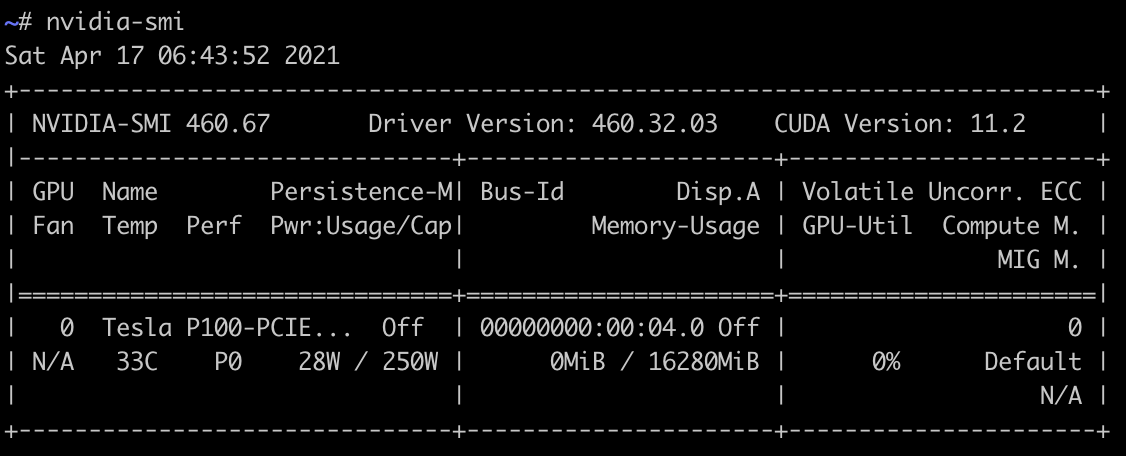
ここまででログインが確認できました。
GitHubからのリポジトリクローンと環境構築
今回は、P100を用いて以下のリポジトリの実験を行います。
本実験についての解説は、以下のページからシリーズになっているので、当記事では説明は省略します。
$ git clone https://github.com/izuna385/Entity-Linking-Tutorial
$ cd https://github.com/izuna385/Entity-Linking-Tutorial
$ pip3 install -r requirements.txt
特に問題なく進めば、以下のようにライブラリのインストールが完了する。
前処理ファイルの配置(本実験のみに必要)
今回使用するリポジトリでは、いくつか前処理ファイルの配置が事前に必要です。
README に従いファイルを配置します。
ローカルで解凍して scp -P 14082 -r hogehoge root@8.tcp.ngrok.io:/root/Entity-Linking-Tutorial/ などとして転送しましょう。
実験
python3 main.py
- 精度を無視し、実験完了のみを一度通したい人は
python3 main.py -debug True

実験が走ります。自動でevaluationまで完了します。
dev evaluation result
recall@50 ** %
detail recall@1, @5, @10, @50 ** % ** % ** % ** %
accuracy: **
test evaluation result
recall@50 ** %
detail recall@1, @5, @10, @50 ** % ** % ** % ** %
本記事を書いたもう一つの背景
本記事を書いたもう一つの背景としては、In-batch trainingにおけるバッチサイズの増加で、実験の精度改善を狙いたかったからです。
P100を用いることで、訓練時のバッチサイズを16(GPU 8GB~時)から48まで増やすことが可能になります。
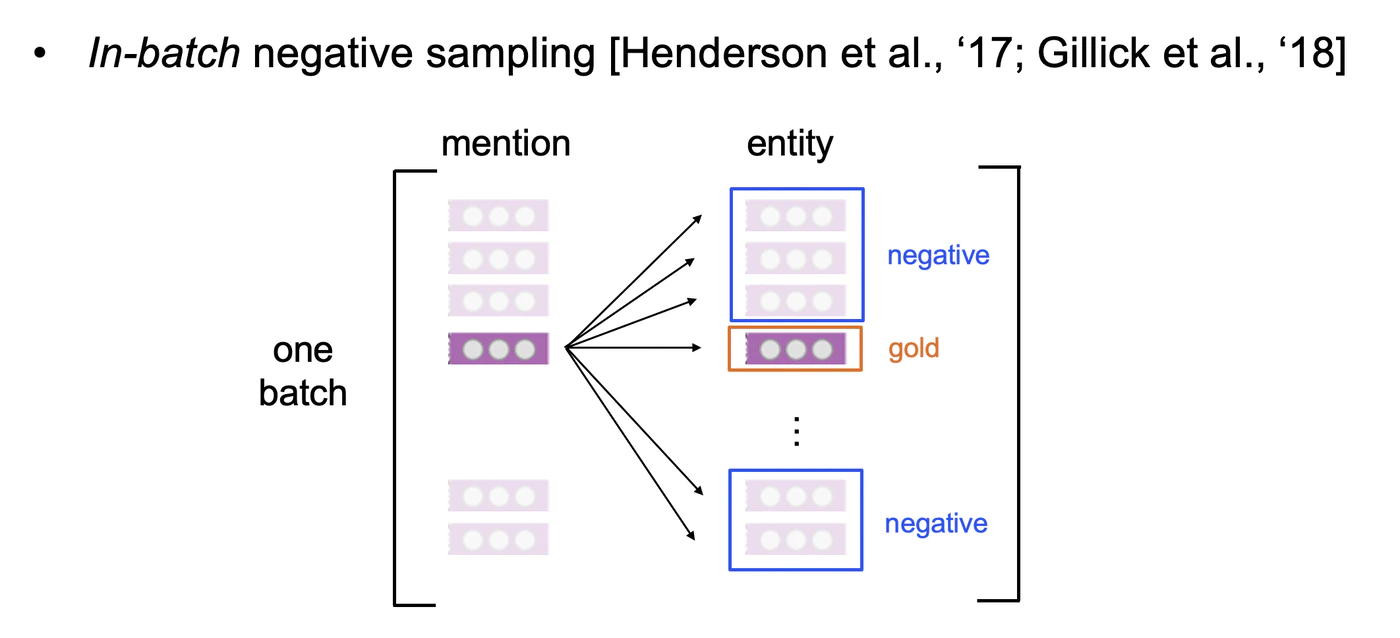
In-batch trainingではバッチサイズを増加させることで、それがそのまま負例の増加につながります。結果として、より多くの負例から一つだけの正解を予測できるように、よりモデルを厳しく訓練させることになります。本実験でなぜIn-batch trainingを用いるかについては、下記を御覧ください。
実際にバッチサイズを16 -> 48 とすることにより、本実験では大幅に精度が向上することが確認できます。
nohup python3 main.py -num_epochs 10 -batch_size_for_train 48 > b48.log &
などとすることで、手軽に実験から評価までが完了します。
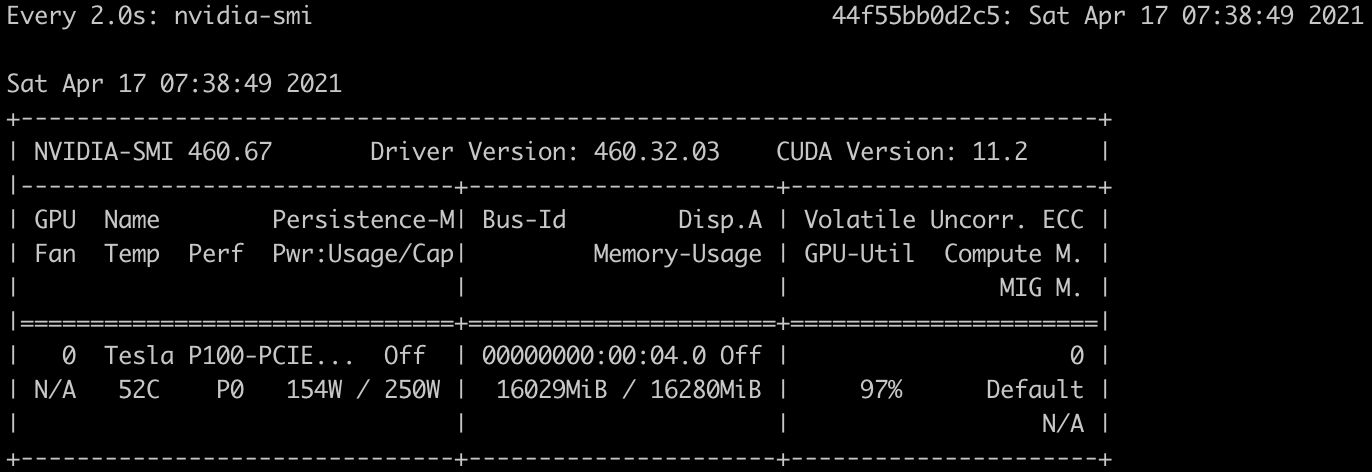
P100をフルに使っていますね。
まとめ
Colab-Pro を用いてsshで自然言語処理の実験を行うチュートリアルについて書きました。requirements.txt から環境を手軽に再現し、P100を用いた実験を行うことが出来ました。