なんの記事?
Entity Linking チュートリアル 中編 に続く後編です。
今回作るもの
Bi-encoder ベースのモデル部分を実装していきます。 Bi-encoderベースのエンティティリンキングシステムは [Gillick et al., '19] が初出と考えられ、現在はそれのTransformerベースが主流になっています([Wu et al., '20])。
Bi-encoderベースのエンティティ・リンキングでは、メンション側とエンティティ側でそれぞれ独立にベクトルをエンコーディングし、ベクトル同士の近さ(L2距離、コサイン類似度、内積など)を用いてメンションと知識ベース内エンティティを比較し、メンションに紐づくであろうエンティティを予測します。
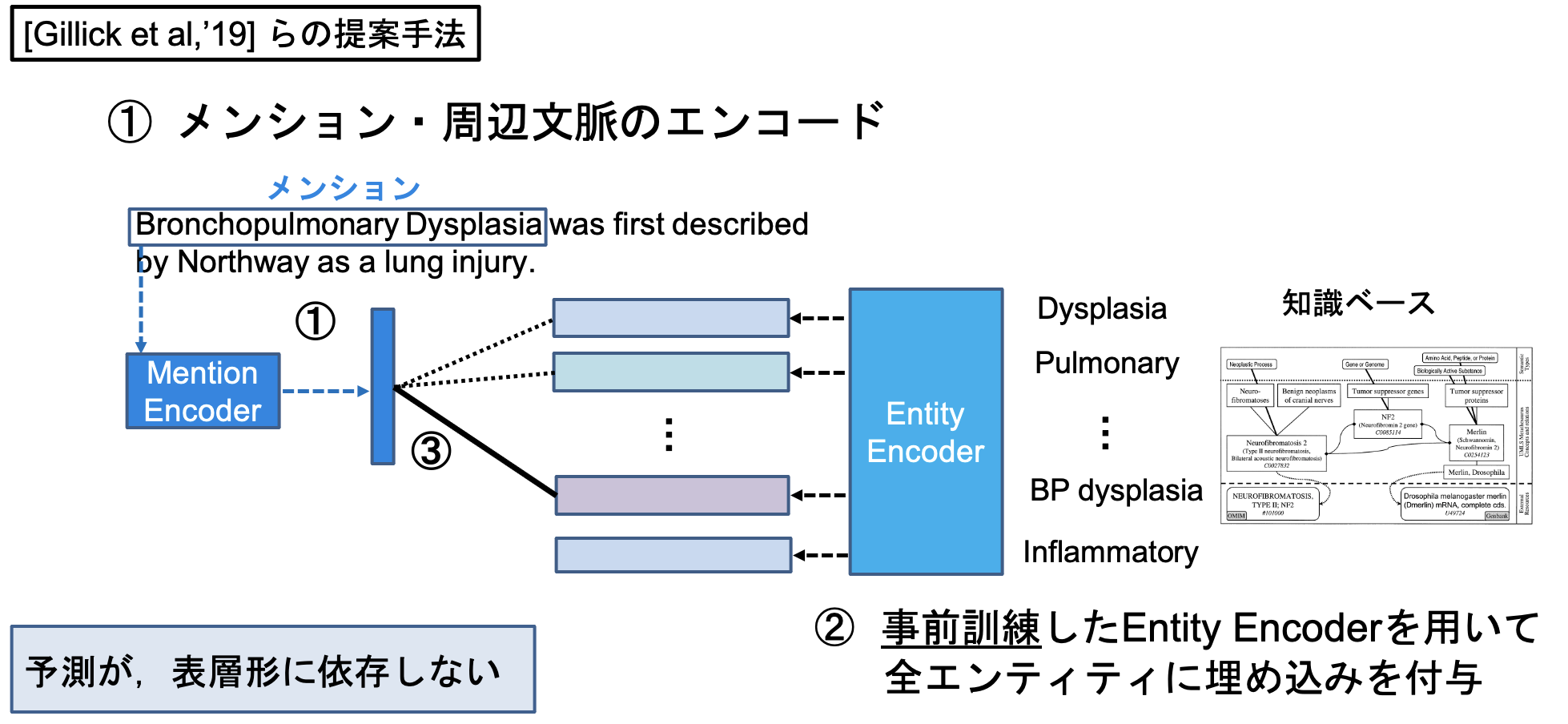
今回はこのシステムの予測モデル部分ならびに実験評価部分を実装していきたいと思います。
変更点として、Gillickらの手法では近似近傍検索を用いて、メンションに紐づくであろうエンティティを予測していますが、今回の実装では予めメンションに対して生成された候補のみを対象として、Bi-encoderモデルによる予測を行っていきます。
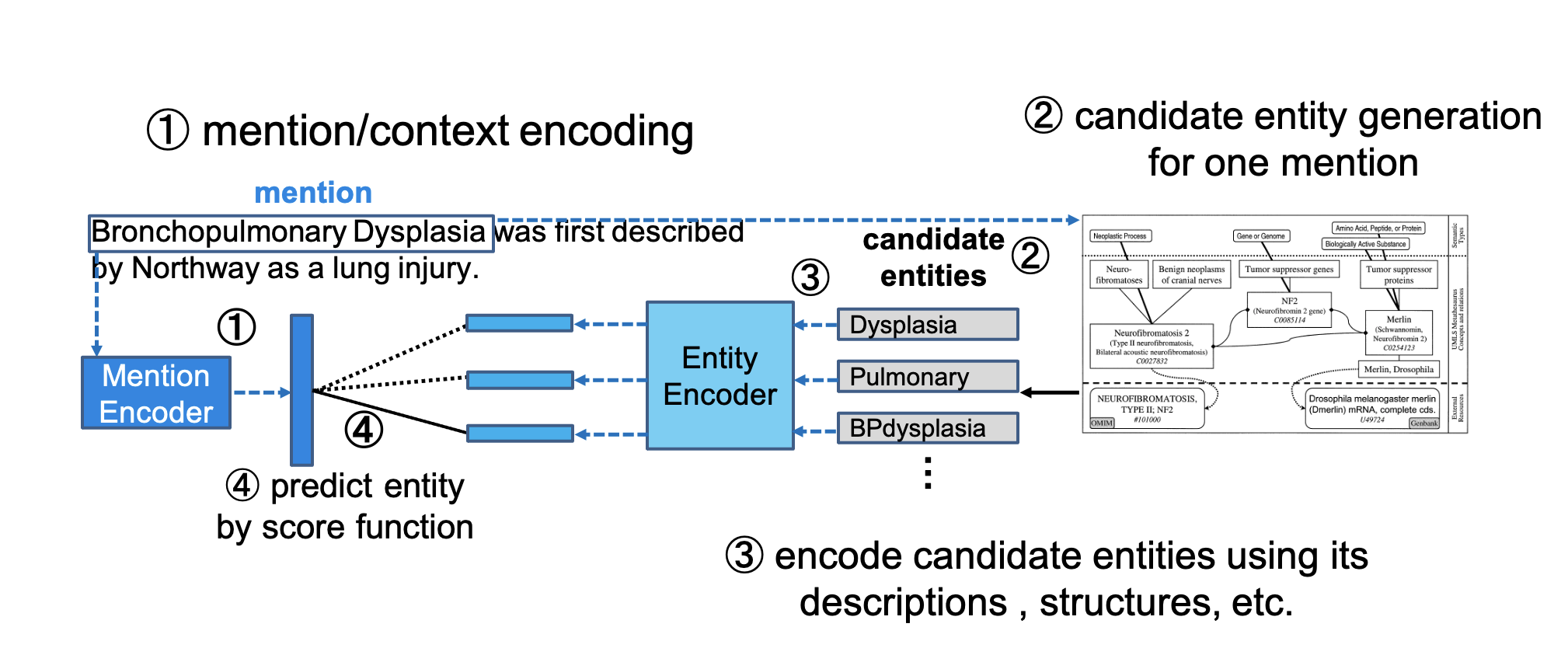
エンコーダ部分
エンコーダ部分の実装は、学習時と評価時で分けます。
学習時にはモデル図のmention encoder 及び entity encoder が学習され、評価時には改めてこれら2つのencoderを引き継いだモデルを使用します。
mention encoder
mention encoder には、mention部分を特別なアンカーで囲み、その周辺コンテキストをencodingするようなエンコーダを用います。
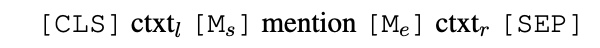
([Wu et al., '20]から引用)
エンコーダには上記のような入力が入り、
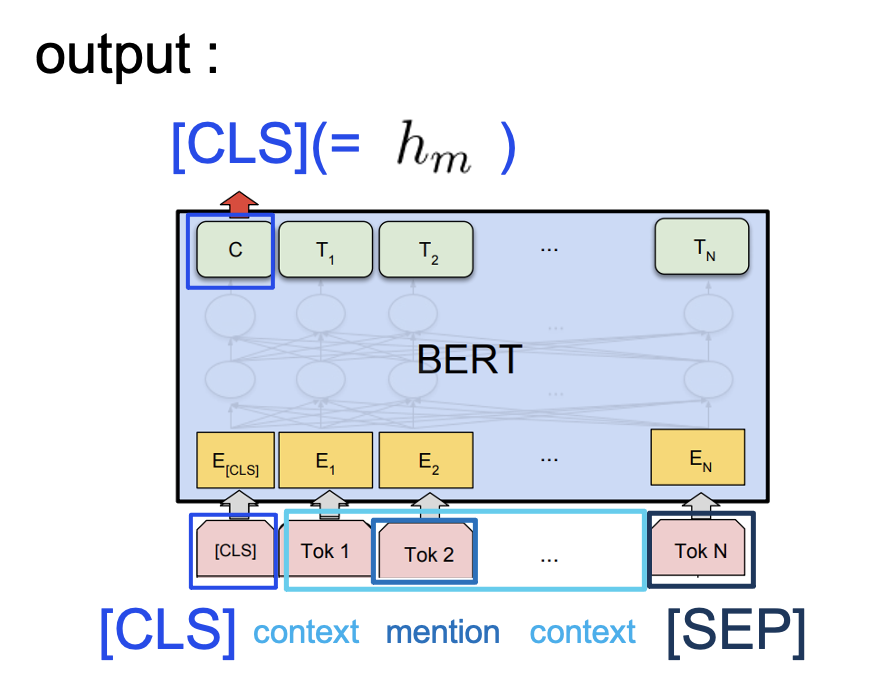
[CLS]トークンがアウトプットになります。
このようなエンコーダは[Logeswaran et al., '18] などで使用されています。
entity encoder
mention encoder と似ていますが、各エンティティの実体名(title)と定義文(description)を考慮するため、以下のような入力を考えます。
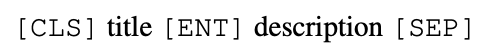
このような入力をTransformerに入れ、先頭の[CLS]トークンに相当するベクトルを、エンティティベクトルとします。
エンコーダ部分の実装
Seq2VecEncoderを継承し、それぞれのエンコーダを作製します。
'''
Seq2VecEncoders for encoding mentions and entities.
'''
import torch.nn as nn
from allennlp.modules.seq2vec_encoders import Seq2VecEncoder, PytorchSeq2VecWrapper, BagOfEmbeddingsEncoder
from allennlp.modules.seq2vec_encoders import BertPooler
from overrides import overrides
from allennlp.nn.util import get_text_field_mask
class Pooler_for_cano_and_def(Seq2VecEncoder):
def __init__(self, args, word_embedder):
super(Pooler_for_cano_and_def, self).__init__()
self.args = args
self.huggingface_nameloader()
self.bertpooler_sec2vec = BertPooler(pretrained_model=self.bert_weight_filepath)
self.word_embedder = word_embedder
self.word_embedding_dropout = nn.Dropout(self.args.word_embedding_dropout)
def huggingface_nameloader(self):
if self.args.bert_name == 'bert-base-uncased':
self.bert_weight_filepath = 'bert-base-uncased'
elif self.args.bert_name == 'biobert':
self.bert_weight_filepath = './biobert/'
else:
self.bert_weight_filepath = 'dummy'
print('Currently not supported', self.args.bert_name)
exit()
def forward(self, cano_and_def_concatnated_text):
mask_sent = get_text_field_mask(cano_and_def_concatnated_text)
entity_emb = self.word_embedder(cano_and_def_concatnated_text)
entity_emb = self.word_embedding_dropout(entity_emb)
entity_emb = self.bertpooler_sec2vec(entity_emb, mask_sent)
return entity_emb
class Pooler_for_mention(Seq2VecEncoder):
def __init__(self, args, word_embedder):
super(Pooler_for_mention, self).__init__()
self.args = args
self.huggingface_nameloader()
self.bertpooler_sec2vec = BertPooler(pretrained_model=self.bert_weight_filepath)
self.word_embedder = word_embedder
self.word_embedding_dropout = nn.Dropout(self.args.word_embedding_dropout)
def huggingface_nameloader(self):
if self.args.bert_name == 'bert-base-uncased':
self.bert_weight_filepath = 'bert-base-uncased'
elif self.args.bert_name == 'biobert':
self.bert_weight_filepath = './biobert/'
else:
self.bert_weight_filepath = 'dummy'
print('Currently not supported', self.args.bert_name)
exit()
def forward(self, contextualized_mention):
mask_sent = get_text_field_mask(contextualized_mention)
mention_emb = self.word_embedder(contextualized_mention)
mention_emb = self.word_embedding_dropout(mention_emb)
mention_emb = self.bertpooler_sec2vec(mention_emb, mask_sent)
return mention_emb
@overrides
def get_output_dim(self):
return 768
モデル部分の実装
一つのメンションに対して正解エンティティは知識ベース内の1エンティティ、という前提を置きモデルを作製していきます。
今回BERTを用いるので、1データに対してnegative samplingを行う場合、batchがGPUに乗り切らないことが多々発生します。
それを回避すべく、In-batch Negative Samplingを利用します。
In-batch Negative Sampling
バッチ内から負例をサンプリングします。"一つのメンションに対して正解エンティティは知識ベース内の1エンティティ"であるので、言い換えればバッチ内の注目するメンションーエンティティ対以外のエンティティを負例として利用できるという事です。
(バッチ内でエンティティが重複する可能性もありますが、今回は無視します。)
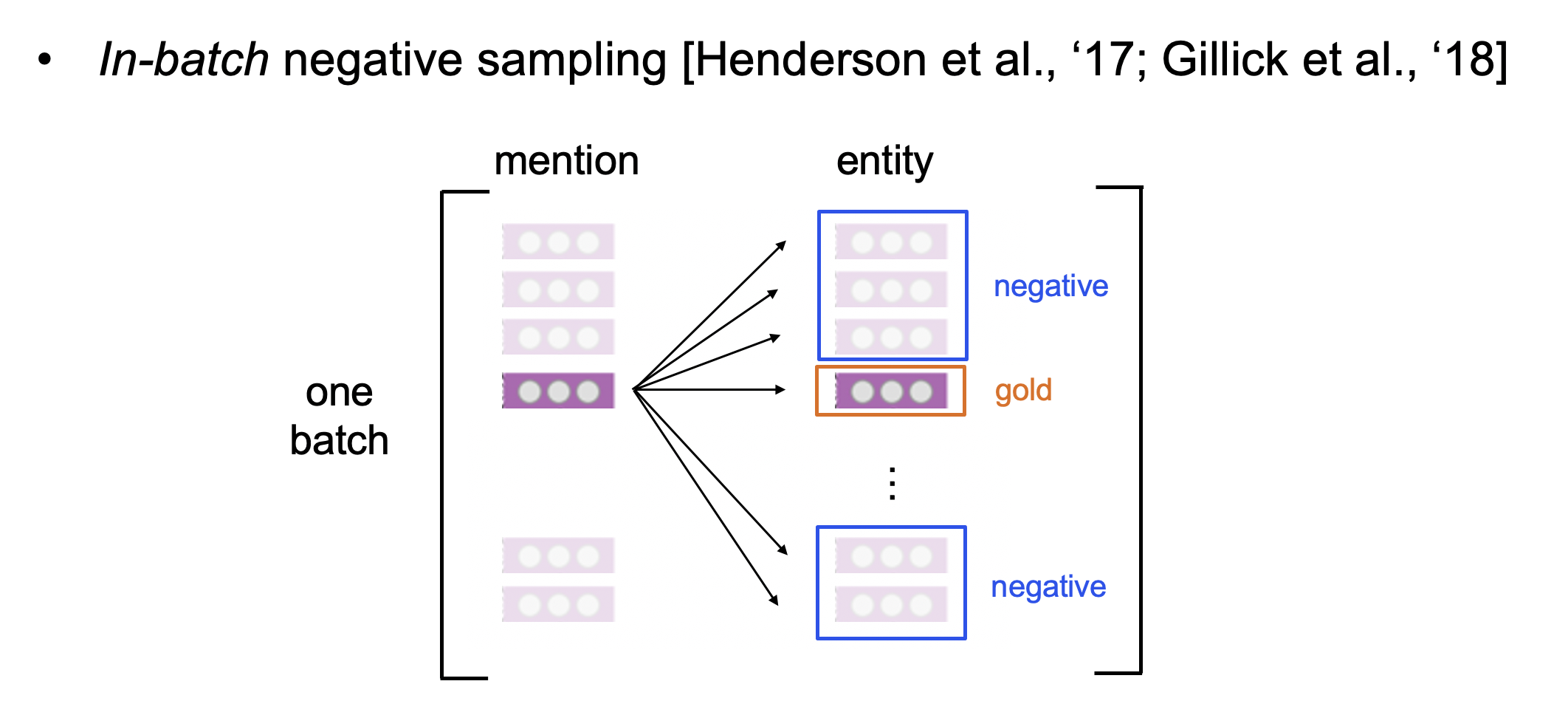
自身のゴールドエンティティ以外を負例とみなすことで、リソースの節約に繋がります。このテクニックは[Humeau et al., '20]などでも利用されています。
各エンティティに対するスコアリング
今回はスコア関数として、コサイン類似度を用います。
各メンションに対して、メンションのコンテキストと、正解エンティティとが近くなるような学習をねらいます。
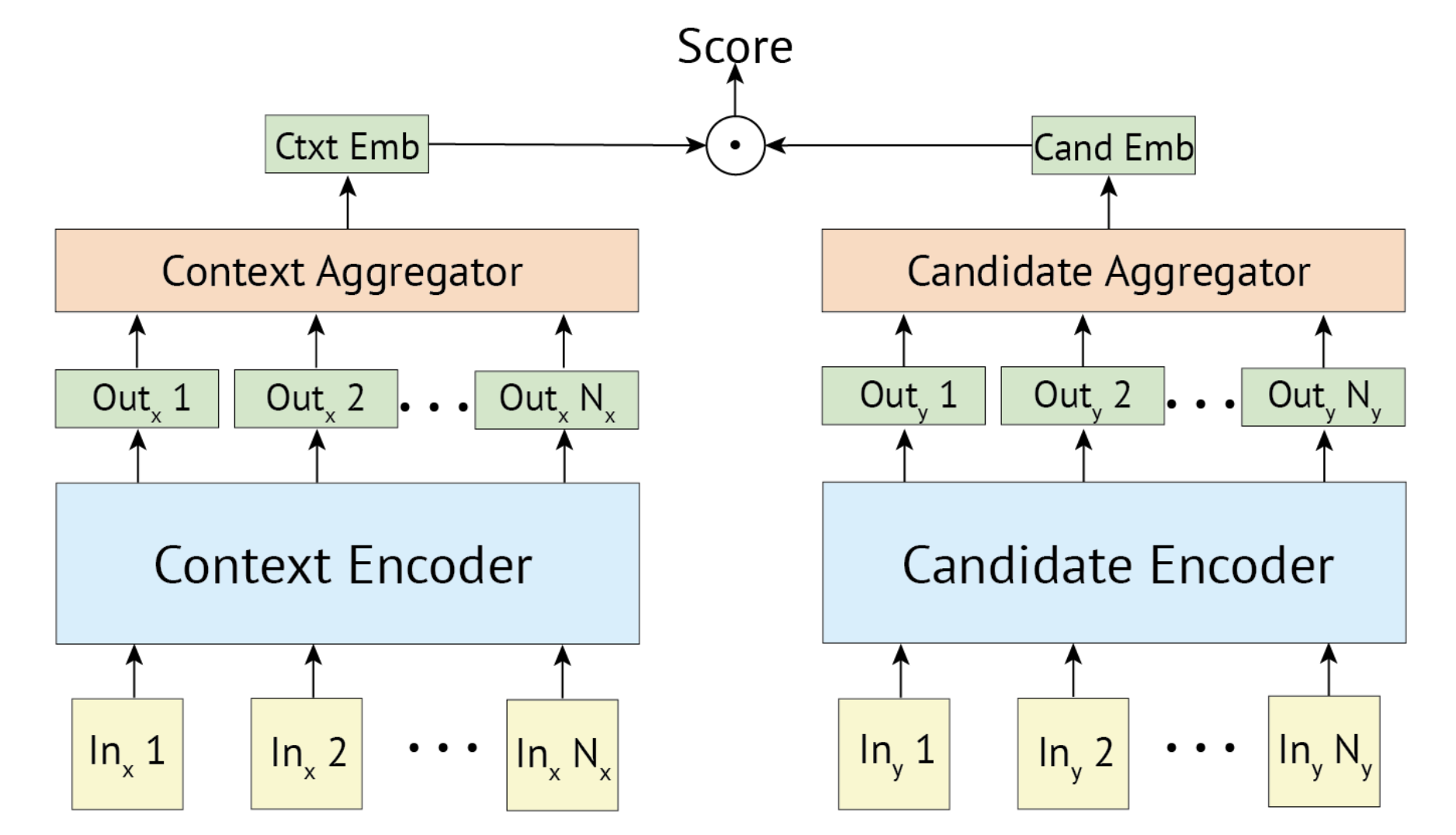
上記の図([Humeau et al., '20]から引用)のように、メンションのエンコーダ出力と各候補エンティティのエンコーダ出力に対してスコア付けを行います。
実装
学習時には In-batch Negative Samplingを用います。
import torch
import torch.nn as nn
from allennlp.modules.seq2vec_encoders import Seq2VecEncoder, PytorchSeq2VecWrapper
from allennlp.models import Model
from overrides import overrides
from allennlp.training.metrics import CategoricalAccuracy, BooleanAccuracy
from torch.nn.functional import normalize
class Biencoder(Model):
def __init__(self, args,
mention_encoder: Seq2VecEncoder,
entity_encoder: Seq2VecEncoder,
vocab):
super().__init__(vocab)
self.args = args
self.mention_encoder = mention_encoder
self.accuracy = CategoricalAccuracy()
self.BCEWloss = nn.BCEWithLogitsLoss()
self.mesloss = nn.MSELoss()
self.entity_encoder = entity_encoder
self.istrainflag = 1
def forward(self, context, gold_dui_canonical_and_def_concatenated, gold_duidx, mention_uniq_id,
candidates_canonical_and_def_concatenated, gold_location_in_candidates):
batch_num = context['tokens']['token_ids'].size(0)
device = torch.get_device(context['tokens']['token_ids']) if torch.cuda.is_available() else torch.device('cpu')
contextualized_mention = self.mention_encoder(context)
encoded_entites = self.entity_encoder(cano_and_def_concatnated_text=gold_dui_canonical_and_def_concatenated)
if self.args.scoring_function_for_model == 'cossim':
contextualized_mention_forcossim = normalize(contextualized_mention, dim=1)
encoded_entites_forcossim = normalize(encoded_entites, dim=1)
scores = contextualized_mention_forcossim.mm(encoded_entites_forcossim.t())
elif self.args.scoring_function_for_model == 'indexflatip':
scores = contextualized_mention.mm(encoded_entites.t())
else:
assert self.args.searchMethodWithFaiss == 'indexflatl2'
raise NotImplementedError
loss = self.BCEWloss(scores, torch.eye(batch_num).to(device))
output = {'loss': loss}
if self.istrainflag:
golds = torch.eye(batch_num).to(device)
self.accuracy(scores, torch.argmax(golds, dim=1))
else:
output['gold_duidx'] = gold_duidx
output['encoded_mentions'] = contextualized_mention
return output
@overrides
def get_metrics(self, reset: bool = False):
return {"accuracy": self.accuracy.get_metric(reset)}
def return_entity_encoder(self):
return self.entity_encoder
学習の評価
評価時には、今回は各メンションに対してScispaCyを用いて生成された候補エンティティが存在するので、学習時とは別のモデルを別途作製します。
ただし、学習されたmention encoderおよびentity encoderは利用するものとします。
import torch
import torch.nn as nn
from allennlp.modules.seq2vec_encoders import Seq2VecEncoder, PytorchSeq2VecWrapper
from allennlp.models import Model
from overrides import overrides
from allennlp.training.metrics import CategoricalAccuracy, BooleanAccuracy
from torch.nn.functional import normalize
class BiencoderEvaluator(Model):
def __init__(self, args,
mention_encoder: Seq2VecEncoder,
entity_encoder: Seq2VecEncoder,
vocab):
super().__init__(vocab)
self.args = args
self.mention_encoder = mention_encoder
self.accuracy = CategoricalAccuracy()
self.BCEWloss = nn.BCEWithLogitsLoss()
self.mesloss = nn.MSELoss()
self.entity_encoder = entity_encoder
def forward(self, context, gold_dui_canonical_and_def_concatenated, gold_duidx, mention_uniq_id,
candidates_canonical_and_def_concatenated, gold_location_in_candidates):
batch_num = context['tokens']['token_ids'].size(0)
device = torch.get_device(context['tokens']['token_ids']) if torch.cuda.is_available() else torch.device('cpu')
contextualized_mention = self.mention_encoder(context)
encoded_entites = self._candidate_entities_emb_returner(batch_num, candidates_canonical_and_def_concatenated)
if self.args.scoring_function_for_model == 'cossim':
contextualized_mention_forcossim = normalize(contextualized_mention, dim=1)
encoded_entites_forcossim = normalize(encoded_entites, dim=2)
scores = torch.bmm(encoded_entites_forcossim, contextualized_mention_forcossim.view(batch_num, -1, 1)).squeeze()
elif self.args.scoring_function_for_model == 'indexflatip':
scores = torch.bmm(encoded_entites, contextualized_mention.view(batch_num, -1, 1)).squeeze()
else:
assert self.args.searchMethodWithFaiss == 'indexflatl2'
raise NotImplementedError
loss = self.BCEWloss(scores, gold_location_in_candidates.view(batch_num, -1).float())
output = {'loss': loss}
self.accuracy(scores, torch.argmax(gold_location_in_candidates.view(batch_num, -1), dim=1))
return output
@overrides
def get_metrics(self, reset: bool = False):
return {"accuracy": self.accuracy.get_metric(reset)}
def return_entity_encoder(self):
return self.entity_encoder
def _candidate_entities_emb_returner(self, batch_size, candidates_canonical_and_def_concatenated):
cand_nums = candidates_canonical_and_def_concatenated['tokens']['token_ids'].size(1)
candidates_canonical_and_def_concatenated['tokens']['token_ids'] = \
candidates_canonical_and_def_concatenated['tokens']['token_ids'].view(batch_size * cand_nums, -1)
candidates_canonical_and_def_concatenated['tokens']['mask'] = \
candidates_canonical_and_def_concatenated['tokens']['mask'].view(batch_size * cand_nums, -1)
candidates_canonical_and_def_concatenated['tokens']['type_ids'] = \
candidates_canonical_and_def_concatenated['tokens']['type_ids'].view(batch_size * cand_nums, -1)
candidate_embs = self.entity_encoder(candidates_canonical_and_def_concatenated)
candidate_embs = candidate_embs.view(batch_size, cand_nums, -1)
return candidate_embs
テスト評価時にはTextFieldのリストをListFieldとして格納したので、_candidate_entities_emb_returner内でentity encoderに食わせられる形に変換した後、各候補エンティティの埋め込みを返却するようにしています。
実際の評価の実装法
Modelを継承したモデル内でaccuracyをタスクに適当なものに設定しておきます。
@overrides
def get_metrics(self, reset: bool = False):
return {"accuracy": self.accuracy.get_metric(reset)}
今回はCategoricalAccuracyを使用します。
実際にドキュメントを見てみましょう。
Assumes integer labels, with each item to be classified having a single correct class.
となっており、候補エンティティの中からただ一つの正解エンティティが存在すれば、それを当てに行く今回のタスクに適した評価指標になります。
評価指標を上記のように設定しておけば、評価部分はほんの数行で終わります。
from allennlp.training.util import evaluate
'''
中略
'''
evaluator_model = BiencoderEvaluator(params, mention_encoder, entity_encoder, vocab)
evaluator_model.eval()
eval_result = evaluate(model=evaluator_model,
data_loader=test_loader,
cuda_device=0,
batch_weight_key="")
print(eval_result)
訓練したmention_encoder, entity_encoderを用いた評価モデルを別途作成することで、評価コードを簡易にすることが出来ました。
実験方法
この記事は以下の記事の続編になっています。
上記の記事に沿って前処理を行うと、以下のようなファイル配置になっているかと思います。
.
├── README.md
├── __init__.py
├── candidate_generator.py
├── candidates.pkl
├── commons.py
├── dataset
│ ├── BioCreative-V-CDR-Corpus
...
├── dataset_reader.py
├── encoder.py
├── evaluator.py
├── main.py
├── mesh
│ ├── dui2canonical.json
│ ├── dui2definition.json
│ ├── dui2idx.json
│ └── idx2dui.json
│
├── mesh_2020.jsonl
├── model.py
├── parameteres.py
├── preprocess_mesh.py
├── preprocessed_doc_dir
│ ├── 10027919.json
│ ├── 10074612.json
... ...
│ ├── 9931093.json
│ └── 9952311.json
├── requirements.txt
├── tokenizer.py
└── utils.py
./preprocessed_doc_dirとcandidates.pklは前回の記事によって得られた前処理ディレクトリとファイルです。
mesh_2020.jsonlおよび./mesh/は、preprocess_mesh.py を走らせることで得られます。これについても前回の記事で記載しました。
この状態でpython3 main.py により実験が走ります。
実験ログ
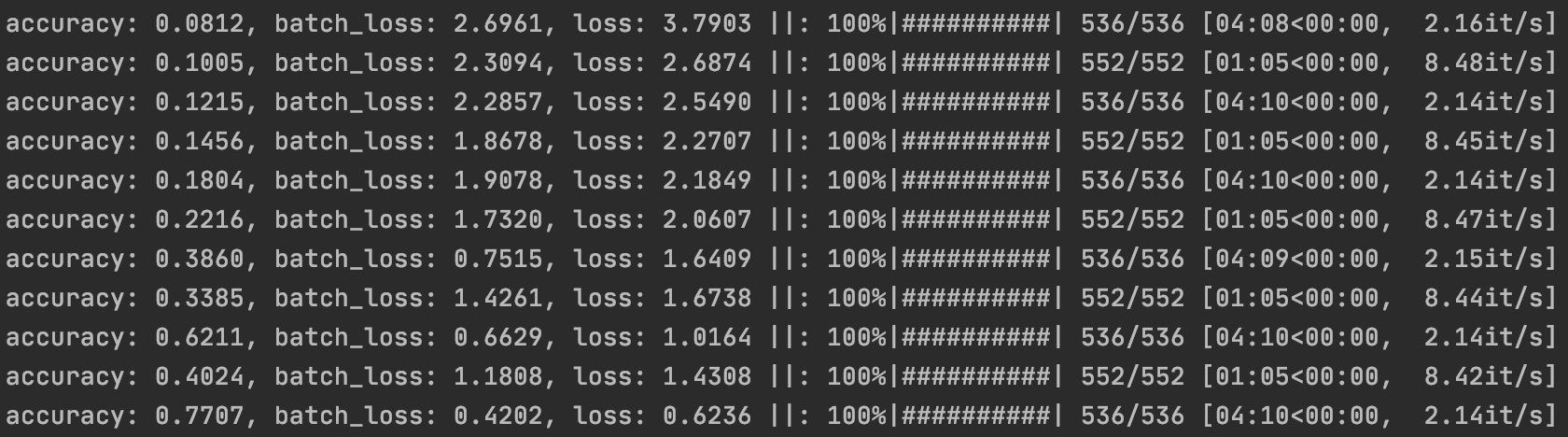
メトリクスに従って、allennlpは自動でそのメトリクスの計算を行ってくれます。また、今回は開発データ(dev)もtrainerに渡したので、学習とdevデータでのバリデーションが交互に走っています。
trainer部分は以下の実装になります。
def build_trainer(
config,
model: Model,
train_loader: DataLoader,
dev_loader: DataLoader,
) -> Trainer:
parameters = [(n, p) for n, p in model.named_parameters() if p.requires_grad]
optimizer = AdamOptimizer(parameters, lr=config.lr)
if torch.cuda.is_available():
model.cuda()
trainer = GradientDescentTrainer(
model=model,
data_loader=train_loader,
validation_data_loader=dev_loader,
num_epochs=config.num_epochs,
patience=config.patience,
optimizer=optimizer,
cuda_device=0 if torch.cuda.is_available() else -1
)
return trainer
テストデータでの実験結果
>> {'accuracy': 0.6851956252114105, 'loss': 275.96289144979943}
となりました。今回の実験では、各メンションに対する候補は5つに絞り、表層形を一切考慮せず、メンションのコンテキストとエンティティの情報のみに注目しています。うまくBiencoderモデルが学習できていることが分かります。
実装の改良点
Hard Negative Miningの実装
今回はBi-encoderの概念理解と実装に重きを置きました。しかし、実際の研究では、各メンションに対してより識別困難な負例をエンティティ集合全体からサンプリングする、Hard Negative Miningが行われているものが多いです。([Gillick et al., '19]や[Wu et al., '20])
Hard negative miningの実装を行ったリポジトリもあるので、もし気になる方はそちらも御覧ください。
Hard Negative Miningの実装については、別の記事でまたまとめたいと思います。
知識ベース全体を対象とした候補生成
今回はあらかじめ候補を事前に絞り込んだ後にリンギングを行いました。この手法は[Gillick et al., '19]で主に行われていたものです。
faissを用いた全エンティティ探索についても、記事を別途書きたいと思います。
(追記2021-03-26: この記事になります。)
エンティティ候補数のdevデータによる調整
各メンションに対するエンティティ生成候補数を増やすと、リコールは増えるが、予測正解率が下がるというジレンマがあります。
今回は特にパラメータチューニングについては行いませんでした。
devデータを用いて、最適なエンティティ候補数を調整し、再現率を上げた分正解率が上がる可能性があります。
まとめ
本シリーズを通して、エンティティ・リンキングに少しでも興味を持っていただけたなら大変幸いです。
もし、更にこのタスクについて知りたい!という方は、以下でもこれまでの歴史から最新の論文までまとめてあります。参考になれば幸いです。
本記事のソースコード
になります。もし不明な点がありましたら、issueを建てていただくか、こちらの記事にコメントして頂ければ幸いです。
次の記事