概要
社内の勉強会用に「機械学習って何?どうやって使うの?」というテーマでまとめたものです。この記事の内容が他の方の役に立てたら嬉しいです。
機械学習 = AI?
機械学習は人工知能の一分野で、ディープラーニングは機械学習の一分野です。

ルールベース
多重If文や探査により多彩なパターンを網羅して、複雑な条件でも適切な出力がされるようにプログラムされているもの
機械学習
データのパターンや特徴を学習し、それをもとに未知のデータに対して何かしらの予測を出力する
ディープラーニング
データの特徴となる要素の取捨選択を自動で行うことができる、機械学習の手法の一つ
強化学習
ある環境において、 エージェントが状況を観測しながら行動することを繰り返し試行し、目的を達成するための最適な意思決定を学習するもの
Point!
ルールベースだと、例外が発生すると人が手でルールを書き換える必要があり、どんどんデータが増えた時に、対応するのが困難
→ 機械学習では、コンピュータにやらせる!
※以下、教師あり学習を前提に記載しています。
機械学習の種類
教師あり学習については、大きく分けて、回帰と分類がある。
回帰:予測の結果が数値のもの。2018年日本のGDPは? → 回帰
分類:予測の結果がクラスであるもの。この花は、菖蒲か杜若か? → 分類
機械学習って何をどうするの?

1. 何をするか決める
何をどの程度の精度で判断させたいかを決めます。
2. データを集める
予測・判断に必要なデータを集めます。
すでにDBに蓄積されたデータを使ったり、WEBから取得したりします。
集めたデータは「学習用データ」と「テストデータ」に分けます。
クローリング
URLを元にWEBページのデータをダウンロードする技術です。
pythonのrequestsを使ったクローリング例:
import requests
r = requests.get('https://ja.wikipedia.org/wiki/Python')
r.text

※Wikipediaにはデータベース・ダンプがあり、こちらを利用したほうが良い旨、コメントにてご教示いただきました。
スクレイピング
ダウンロードしたWEBページから必要な情報を抽出し加工する技術
pythonのBeautifulSoupを使ったスクレイピング例:
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
soup.find(class_='mw-redirect').string
>>> 'マルチパラダイム'

APIで取得
各サービスが公開している RESTful APIを使用して取得
GitHub APIでデータ取得してpandasで加工した例:
import requests
import pandas as pd
git_res = requests.get('https://api.github.com/search/repositories?q=language:python+created:2017-07-28&per_page=3')
pd.DataFrame(git_res.json()['items'])[:][['language', 'stargazers_count', 'git_url', 'updated_at', 'created_at']]

3. データを整形する
集めたデータを整形します。どのように整形をするかは、データの種類とそのあとのモデル作成の作業によって、様々です。
欠損値の補間
特徴量のなかで歯抜けしているデータを、平均値や0で埋めて、データを補間します。
また、カテゴリーとして記載されている文字をフラグに置き換える(ダミー変数変換)処理なども行います。

トリミング
画像データから特定のキャラを判別したい場合など、トリミングを行ったりアノテーションデータを作成します。
形態素解析
文章などは形態素解析によって分かち書きに変換し、さらにベクトル変換する事で数値として扱えるようにします。
janomeの例
インストール
pip install janome
分かち書き
# -*- coding: utf-8 -*-
from janome.tokenizer import Tokenizer
t = Tokenizer()
document = u'これはテストデータです'
tokens = t.tokenize(document)
for token in tokens:
print(token.surface)
出力
これ
は
テスト
データ
です
4. モデルを作って学習
モデルとは、入力データ ( 予測・判断の要因 ) から出力データ ( 予測・判断の結果 ) に変換するためのもの。粗く言うと関数。
手順
取得したデータから、予測結果の要因となりそうなデータの構造や相関などを整理・分析して、一定の自由度を与えたモデルを作成する。学習用データでパラメータを決定して予測モデルを作成する。
イメージ
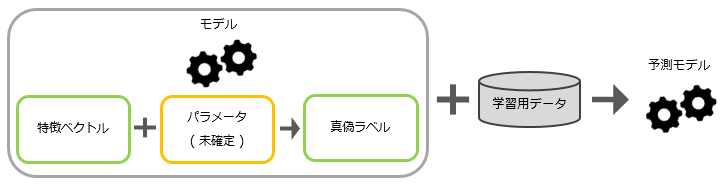
- 特徴ベクトル ( 特徴量 ) :予測の要因となる値
- 真偽ラベル ( ターゲット ) :予測される値
- パラメータ:モデルに自由度を与える値
- 予測モデル:パラメータが確定したモデル
- 予測ラベル:予測モデルを使用した予測結果
ライブラリ
専門知識や経験が必要な部分ですが、ある程度容易に作成できるライブラリがある。
- scikit-learn : python用の機械学習系
- statsmodels : python用の統計学系
- Spark MLlib : ビッグデータの分散処理用の機械学習系ライブラリ提供
- XGBoost : 高精度なアンサンブル学習モデルを作成できるライブラリ
scikit-learnを使用した例:
問題に対してよさげなモデル ( 今回は線形回帰 ) を選び、学習データをモデルにフィットさせて、学習済みモデルを作成。
import numpy as np
from sklearn import linear_model
# 収集したデータと仮定
x_data = np.arange(-3, 10, 0.1).reshape(-1, 1)
y_data = (1/2) * x_data + np.random.normal(0.0, 0.5, len(x_data)).reshape(-1, 1)
# 学習用データとする
x_train = x_data[70:]
y_train = y_data[70:]
# モデルを学習データにフィットさせる
reg = linear_model.LinearRegression()
reg.fit(x_train, y_train)
学習用データとテスト用データを分けるためのtrain_test_splitがあります。
(今回は章ごとに読みやすくするために、使用しませんでした。)
ハイパーパラメータ
モデルによっては、人の手で値を決める必要のあるハイパーパラメータがある。これは学習によって決定しない。 ( 例:DLの層の数、学習回数など )
ハイパーパラメータの決定方法
- グリッドサーチ:ハイパーパラメータの範囲を決め、等間隔に区切って全ての組み合わせを試す方法
- ランダムサーチ:ハイパーパラメータがある分布に従うとし、その中でランダムな組み合わせを試す方法
その他
機械学習の手法をざっくりまとめた記事を以前、投稿しました。モデル構築のヒントになればと思います。
Qiita 機械学習の情報を手法を中心にざっくり整理
5. テストデータで予測
作成したモデルを使用し、テストデータで予測を行います。
scikit-learnを使用した一例 ( 上記コードの続き ) :
# テストデータ
x_test = x_data[:71]
y_test = y_data[:71]
# 予測
pred = reg.predict(x_test)
# 決定係数
print('score:', reg.score(x_test, y_test))
>>> score: 0.714080213722
6. 検証
テストデータでの予測がどのくらいの精度で当たっているかを検証します。
各モデルにあった評価尺度で検証します。
評価尺度
分類
- 正解率 ( accuracy ) : 全体のなかの正解した割合
- 適合率 ( precision ) : hogeクラスと予測した中で実際にhogeクラスであった割合
- 再現率 ( recall ) : 実際にhogeクラスであるデータの中で、hogeクラスと予測した割合
- F値 ( f1-score ) : 適合率と再現率の調和平均
scikit-learnにこれらを出力するaccuracy_scoreやclassification_reportがあります。
回帰
- 平均絶対誤差 ( MAE ) : 予測値と正解値の差の絶対値の平均
- 平均二乗誤差 ( MSE ) : 予測値と正解値の差の2乗の平均
- 平均二乗誤差平方根 ( RMSE ) : 平均二乗誤差の平方根
scikit-learnにこれらを出力するmean_absolute_errorやmean_squared_errorがあります。
検証手法
-
ホールドアウト検証 : データを学習用データとテスト用データにある割合で分割して検証する方法
イメージ

-
K-分割交差検証 : データをK個に分けて、1個をテスト用データとして、それ以外を学習用データとする。テスト用データの選び方はK通りあるので、全組み合わせで検証して精度の平均で評価する方法。
イメージ ( K=3 )

scikit-learnを使用した一例 ( 上記コードの続き ) :
from sklearn.metrics import mean_squared_error
from math import sqrt
# 相関係数
print('corr:', np.corrcoef(y_test.reshape(1, -1), pred.reshape(1, -1))[0, 1])
# RMSE
print('RMSE:', sqrt(mean_squared_error(y_test, pred)))
>>> corr: 0.895912443712
>>> RMSE: 0.6605862235679646
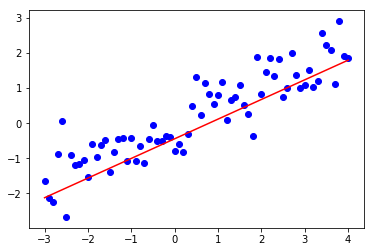
可視化できる場合はグラフ化し、視覚的に確認します。
plt.scatter(x_test, y_test, color='blue')
plt.plot(x_test, pred, color='red')
plt.show()
レポーティング
どのようなモデリングをしたか、テストデータは何を使ったか、どの程度の精度が出たのかを記録しておく。
私はpythonで書いているので、Jupyter notebookにてMarkdownで記載してます。
Qiita : Jupyter Notebookをより便利に使うために、色々まとめ
7. 戻る
検証にて求める精度が出なかった場合は、何がダメだったのかを整理して、手順 「2. データを集める」 or 「3. データを整形する」 or 「4. モデルを作って学習」 に戻ります。このサイクルをぐるぐる回します。
キーワード
過学習
学習データに過度に適応してしまい、未知のデータに対する予測の精度が低くなってしまう事。
特化型AI・汎用型AI
特化型AIとは、ある特定の分野において使用できるAIのこと。
汎用型AIとは、異なる多数の分野において使用できるAIのこと。(鉄腕ア○ムみたいなの)
ほとんどのAIは特化型AIです。
おわり
勉強会では概要のみだったので、少し情報を追加した形でナレッジ共有できたらと思いQiita投稿しました。誤りがありましたらご指摘いただけたら嬉しいです。