概要
自分用のメモとして、機械学習に関する情報を浅く ( それなりに ) 広くをモットーに、ざっくり整理してみました。
少しでも、他の方の理解に役立ったら嬉しいです。
機械学習とは
コンピュータプログラムが経験によって自動的に出力結果を改善していく仕組み。
手法
機械学習の代表的な手法について記載します。
1.教師あり学習
2.教師なし学習
3.強化学習
に分けて記載しました。
※概要説明は一例です。
1.教師あり学習
1-1.線形回帰
予測したい値を算出する式を連続する多項式として表し、各係数を最小二乗法や最尤推定法で求めることでモデルとなる式を決定する
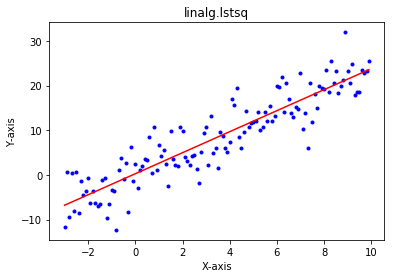
Pythonライブラリ:scikit-learn(sklearn.linear_model.LinearRegression)
参考:最小二乗法による線形回帰のアルゴリズム (自身のQiitaの過去記事です)
1-2.ロジスティック回帰
2択の予測において ( 負け / 勝ち , 売れない / 売れる ) 、ロジスティック曲線を使用して片方 ( 勝ち・売れる ) になる確率を0から1の値で算出する。
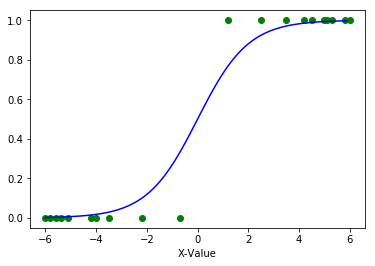
Pythonライブラリ:scikit-learn(sklearn.linear_model.LogisticRegression)
参考:ロジスティック回帰分析(Mr. Masahiko Asano)
1-3.サポートベクターマシーン(SVM)
データを分類するための境界線を決定する際に、境界線から一番近いサンプルデータまでのマージンの和が最大になる線を境界線とする手法。分類も回帰にも利用できる。
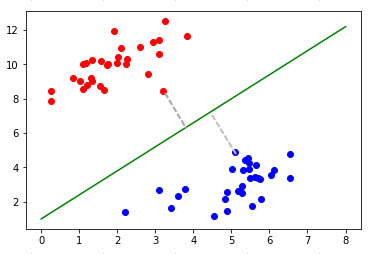
Pythonライブラリ:scikit-learn(sklearn.svm.SVR)
参考:Qiita 機械学習入門~ハードマージンSVM編~
1-4.パーセプトロン
2択の予測において ( 活性 / 非活性 ) 、要因となる入力値に重みを付けて合算し、それが閾値 ( バイアス ) を超えると片方 ( 活性 ) と判定する手法。脳のニューロンの仕組みを模している。
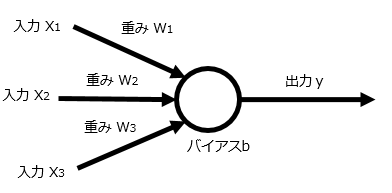
Pythonライブラリ:scikit-learn(sklearn.linear_model.Perceptron)
参考:Qiita 単純パーセプトロンからの機械学習入門
1-5.決定木
分岐処理をツリー状に形成し、トップから再帰的に対象データを分岐させて最終的なクラスを決定する手法。
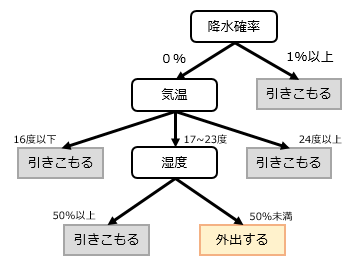
Pythonライブラリ:scikit-learn(sklearn.tree.DecisionTreeClassifier)
参考:Qiita 決定木とランダムフォレスト
1-6.ランダムフォレスト
訓練データからランダムにデータを選んで決定木を複数作り、それぞれの決定木で予測された結果の多数決により、最終的なクラスを判定する手法。回帰で使用する時は各予測の平均をとって数値を算出する。
このように、訓練データの一部を使用してモデルして予測し、それを何度も繰り返して最後に合わせる方法をバギングという。
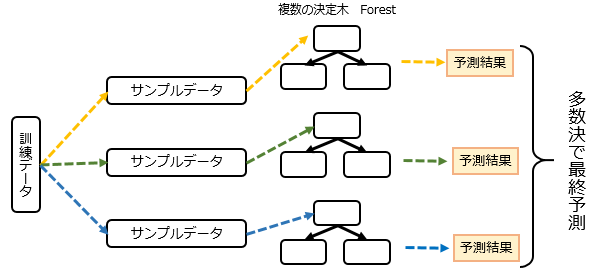
Pythonライブラリ:scikit-learn(sklearn.ensemble.RandomForestRegressor)
1-7.Ada Boost
弱分類器を複数作り、訓練データで1番精度が高いものを第1分類器として選ぶ。第1分類器が誤判断したデータに対して最も精度が高い分類器を第2分類器として1つ選ぶ。これを繰り返し、弱分類器からお互いに補完しあう弱分類器を選別し、最後に合算する手法。
前回の弱分類器の結果を利用して、分類を回繰り返す方法をブースティングという。
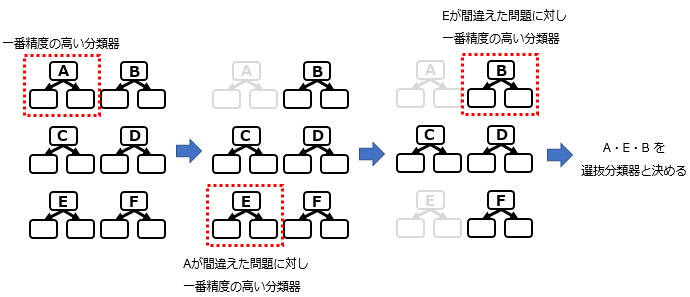
Pythonライブラリ:scikit-learn(sklearn.ensemble.AdaBoostRegressor)
1-8.ナイーブベイズ
対象データを独立的な各要素に区切り、各要素の条件付き確率をベイズの定理に当てはめることで、判定対象がどのクラスへ分類されるかを判定する手法。主に文章の分類で使用される。
Pythonライブラリ:scikit-learn(Naive Bayes)
参考:ナイーブベイズ分類器のアルゴリズム (自身のQiitaの過去記事です)
1-9.k近傍法 ( KNN )
自分から最も近い複数のデータのクラスの多数決で、分類する手法。
単純すぎて怠惰学習という異名を持つ。
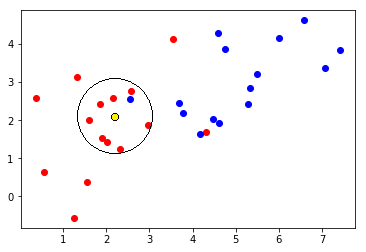
Pythonライブラリ:scikit-learn(sklearn.neighbors.KNeighborsClassifier)
1-10.ニューラルネットワーク ( NN )
パーセプトロンを入力層・隠れ層・出力層と階層型に構築したモデル。
入力層ユニットは予測対象の入力データを受け取り、出力先が隠れ層ユニットと結合している。出力層ユニットは隠れ層ユニットからのデータを元に、最終的な予測を出力する。
入力層・隠れ層・出力が単純な一方向の階層構造になっているものを単純ニューラルネットワークという。
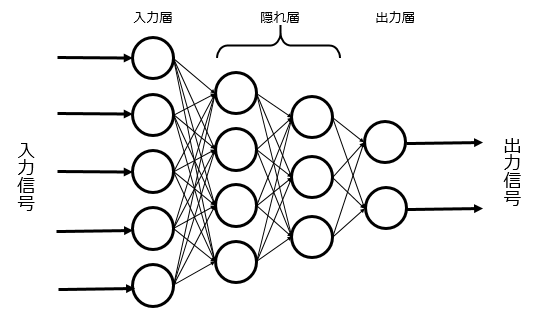
Pythonライブラリ:scikit-learn(sklearn.neural_network.MLPClassifier)
フレームワーク:Chinaer 公式サイト(英語)
1-11.畳み込みニューラルネットワーク ( CNN )
ニューラルネットワークにおいて、隠れ層が、畳み込み層+プーリング層 から形成されているもの。
畳み込み層では、入力層からのデータをあらゆる部分でスキャンして、特徴との適合度を計算する。プーリング層では畳み込み層のデータをあるサイズに縮約する。
畳み込み層とプーリング層を交互に繰り返すことで、隠れ層を形成する。
例えば、ある画像を0~9に判断させたい場合、0との適合用「畳み込み層+プーリング層」が1つ、1との適合用「畳み込み層+プーリング層」が1つ・・・と10の隠れ層を必要とする。
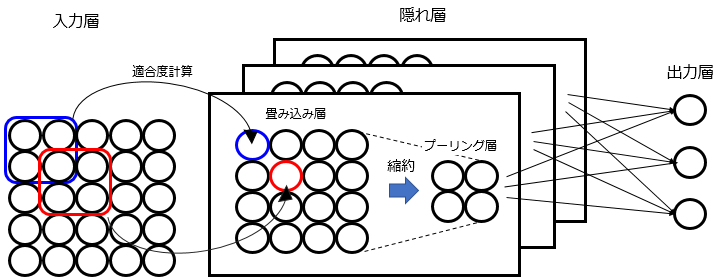
2.教師なし学習
2-1.k平均法 ( k-means )
クラスタの個数を決めておき、訓練データからクラスタ個数分、ランダムなデータを選び、一旦、代表点と定める。他のデータは代表点との距離が1番近いクラスタに属させる。
クラスタにデータが追加された時、その中心点を新しいクラスタの代表点とする。これを、代表点が動かなくなるまで繰り返すことで、クラスタが作られる。
未知のデータに対して、同じく、各代表点との距離が1番近いクラスタに分類する手法。
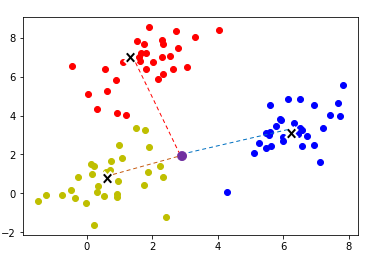
Pythonライブラリ:scikit-learn(sklearn.cluster.KMeans)
2-2.主成分分析 ( PCA )
結果に影響する複数の要因から、どの要因がどのくらい影響を及ぼすか、寄与率を算出して、主な要因を割り出す手法。
モデルの次元を落とすのに用いられる。
Pythonライブラリ:scikit-learn(sklearn.decomposition.PCA)
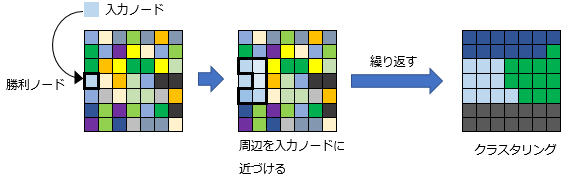
2-3.自己組織化マップ ( SOM )
入力ノードに最も近いノードを勝者ノードとして選び、その周辺ノードを入力ノードに近づける。それを繰り返すことでクラスタが作られる。
大脳皮質の視覚野を模した。
3.強化学習
3-1.Q学習
全ての状態(s)とその時に取りうる全ての行動(a)のセットの行動価値(Q値)を、一旦、ランダムに決める。初期状態からランダムに行動を決めて、得られた即時報酬(r)と遷移先で推測される最大値の行動価値Q値によって、遷移前の状態のQ値を更新する。これを繰り返すことで、全ての状態とその時に取りうる全ての行動の行動価値を決定する。
そして、必ずその状態における行動価値が最大になるような選択をする。
4.手法のあれこれ
4-1.「回帰」と「分類」
回帰は数値を予測する。分類はクラスを判定する。
4-2.「教師あり学習」と「教師なし学習」
教師あり学習は入力と出力の関係を学習するもので、人間がラベル付けを行う必要がある。教師なし学習はデータの構造を学習するもので、人間によるラベル付けをしない。
4-3.過学習
訓練データに対して過剰に適用した状態となり、未知のデータに対する予測が正しく測定できなくなること。
4-4.アンサンブル学習
個々にモデリングした複数の学習器を利用し、平均・多数決などで最終的な予測をする方法。
上記のバギングやブースティングはアンサンブル学習の一種。
言語
1. Python
機械学習において、最も支持されている言語。オブジェクト指向が強いが、マルチパラダイムであり手続き型・関数型としても実装可能。習得が容易であり、教育用の言語としても好まれている。科学計算系のライブラリも豊富。
私もPythonで機械学習の勉強をして、アプリを作ってます。なので、贔屓目に書いてます。
Python 公式サイト(英語)
2. R言語
統計学に強く、Pythonに続いて支持されている言語。こちらもマルチパラダイムであるが関数型が強く、また、データをベクトルとして扱うことができる。統計解析系のライブラリが豊富。
R言語 公式サイト(英語)
3. MATLAB
技術計算・数値分析に特化したソフトウェアで、工学および科学分野でよく使用されている。オブジェクト指向で書けて、行列計算が得意。フリーではなく、使用するにはMathWorks社のラセンス認証が必要。
MathWorks社 - MATLAB (日本語)
4. Octave
MATLABと同じ文法で書ける数値計算用のフリーソフト。MATLABよりもパッケージやツールが少ないが、実装が簡単なのでプロトタイプ作成などによく使用される。デジタル信号処理用の関数が豊富で、音声のノイズ除去処理などが得意。
私はCourseraのMachine Learningコースで、初めて使用して知りました。
GNU Octave 公式サイト(英語)
5. Julia
比較的新しい、科学計算用のプログラミング言語。感覚的に書きやすく、処理速度が極めて高速。高速なのは、LLVM ( コンパイラー作成用のライブラリーやツール群 ) を使った実行時コンパイラー ( JIT ) によるもの。
Julia 公式サイト(日本語)
クラウドベースのAPI
1. Google Prediction API
Google Cloud Platform ベースの機械学習API。東京リージョンが2016年冬にできて注目をあびた。
機械学習系技術は他より数歩先を行っている印象。
2. Microsoft Azure Machine Learning
Azureベースの機械学習API
機械学習のアルゴリズムが多数あるのが特徴。
3. Amazon Machine Learning
AWSベースの機械学習API。
クラウドとしては最大手のため、AWS上の既存アプリに機械学習を取り入れるのに便利。
関連情報
1. シンギュラリティ
人工知能が人間の能力を超えること。予想では2045年とされている。
2. 強いAI弱いAI
脳科学や神経科学のアプローチを使用して、人間の脳を模した形で処理を行うAIを強いAIという。
脳の仕組みとは関係なしに、結果的に人間が行うことと同じ結果となるように処理を行うAIを弱いAIという。
3. CourseraのMachine Learningコース
言わずと知れた、Courseraの機械学習の講義。
無料動画で、スタンフォード大学のアンドリュー先生の講義が受けられる。テストやコード提出の課題がある。
修了までの時間制限はなし。
Coursera - Machine Learning
アンドリュー先生は優しいですが、やはり高度なアルゴリズムや公式理解はなかなか簡単にはいきません。
私も頑張って修了を目指してますが、なかなか終わりません。
4. arXivTimes
機械学習関係の論文を調査し、日本語によって一言でまとめているチーム。
TwitterのBotをフォローしています。
初心者の私には難易度が高いなぁ~、と思いながら読んでます。
[Qiita まだ機械学習の論文を追うのに消耗してるの?それBotで解決したよ] (http://qiita.com/Hironsan/items/ca0b176fd859490dde08)
おわり
手法や関連情報について、随時、追加していきたいです。
また、手法の参考リンクを自身のQiita記事に置き換えられるように、本格的なアルゴリズム理解を進めていきたいです。
誤った記載がありましたら、指摘いただけたら嬉しいです。