
![]() (2019/2) AI OpenScaleはWatson OpenScaleに名前が変わりました
(2019/2) AI OpenScaleはWatson OpenScaleに名前が変わりました
要は(TL;DR)
- Watson OpenScaleは「AIの運用をキチッと行う(AIOps)」ためのIBMの商用製品・サービスです
- 大きくは以下の4つの機能があります
- Fairness - 本番での予測の公平さの問題(バイアス)の検知
- De-Bias - 自動的に予測バイアスを緩和(再トレーニング不要)
- Explain - AIの予測の根拠・道筋の提示
- Accuracy - 本番でのモデル性能劣化の検知と自動的な対処
- 「決定木」のような人間にとってわかりやすい手法だけでなく、ニューラル・ネットワークのような**「中身がわからない=ブラックボックス」な手法で作られたAIモデルであっても、問題ありません。**1 AIモデルの実装を問わないので、AWS/Azureなど他社製のAIもサポートします。
- 「本番運用」で使うことを想定しています。一部のオープンソース・ライブラリーのように「モデルの開発時」に「専門家」が「プログラミング」して使う類のものとは統合の度合いや利用するフェーズが異なります
- クラウドとオンプレ(ICP)の両方で稼動する=ハイブリッドです
- Watson OpenScaleはIBM Cloud上で既に利用可能で、Liteプランで無料お試しができます
はじめに
こんにちわ!石田です。昨今、「AIのブラックボックス化」「説明可能なAI(XAI..Explainable AI)」「AIのバイアス」などの話題を良く聞きますよね。先日(2018/11/27)も日経に「AIの判断、企業に説明責任 ルール作りへ政府7原則 」なんて記事が出ました。(ネット上では「ディープラーニングのモデルの説明なんて、できねーよ!」的なコメントも散見されましたね)これらの課題に対応すべく、IBMでは2018/10/15にWatson OpenScaleという製品を発表しました。世間でもニュースになったので名前くらいは知っておられる方も多いかと思います。
-
 日経新聞 米IBM、人工知能の採用と透明性を促進するための「Watson OpenScale」を発表
日経新聞 米IBM、人工知能の採用と透明性を促進するための「Watson OpenScale」を発表
-
Tech Republic Japan IBM「Watson OpenScale」--AWSやAzureに対応のAI向けオープンプラットフォーム
以下、当記事では「要はWatson OpenScaleって何なん?何してくれんの?」(What)だけをザクッと駆け足でご紹介します。「AIのブラックボックス化」「説明可能なAI」などの業界事情や背景(Why)は賢明なるQiita読者の皆様には釈迦説だと思いますし、ネットに情報はたくさんあるのでご説明しません。また「やってみた」系の話(How)も割愛します。
![]() (2019/02/05追加) 当記事読んだ上で、さらに細かく知りたいな、という方は
(2019/02/05追加) 当記事読んだ上で、さらに細かく知りたいな、という方は ![]() 記事「 Watson OpenScaleをもう少し「キチッ」とご紹介します(A.K.A.「麗しき誤解」を解く)」もどうぞ~。
記事「 Watson OpenScaleをもう少し「キチッ」とご紹介します(A.K.A.「麗しき誤解」を解く)」もどうぞ~。
![]() (2019/02/16追加) しくみなど技術面のお話を
(2019/02/16追加) しくみなど技術面のお話を![]() 記事「Watson OpenScaleを触る前に知っておきたかったこと」にまとめました。
記事「Watson OpenScaleを触る前に知っておきたかったこと」にまとめました。
Watson OpenScaleって何?
どういうお客様のためのものか
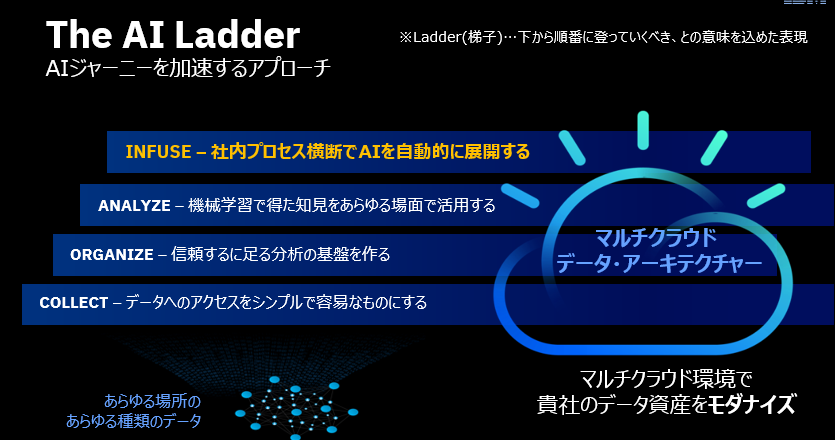
上記「AIのはしご」をご覧になったことのある方も多いかと思います。要は「成熟度」的なものですが、「はしご」なんで下から順番に昇りましょう、と言ってます。ここでWatson OpenScaleは一番上の「INFUSE」の段階をサポートする製品です。つまり「既にAIやってる」お客様の運用面のお悩みを解く製品です。「AIで何ができるのか」とか「AIをやりたいがデータが無い」とかの段階の課題を解く製品ではありません。

名は体を表す、と申しますがOpenの部分は、対象のAI(モデル実行環境)を問わないことを意味しています。Scaleの部分は日本語で言う「横展開」、すなわちAIを多数の業務に適用していく過程で生じる運用面の課題を解決することを目指しています。
適用フェーズ・利用場面
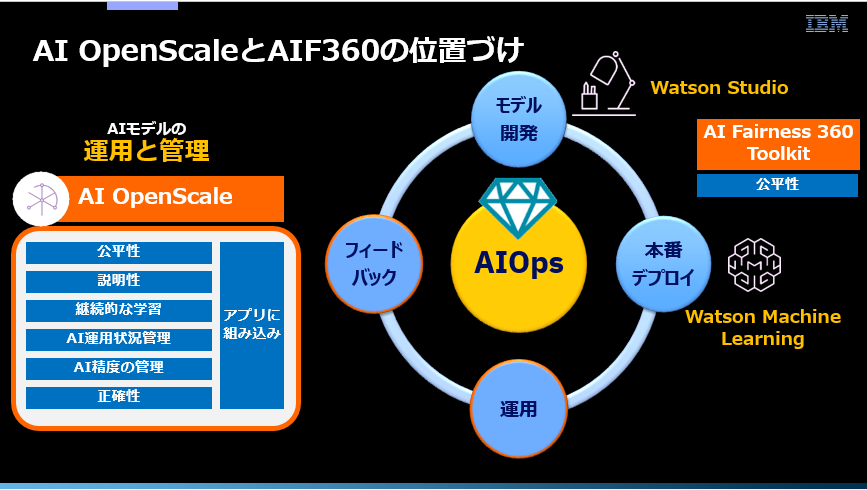
上記をAIのライフサイクルとすると、Watson OpenScaleは「運用」と「フィードバック」のフェーズのための製品です。IBM製品で言えばAIモデルの開発はWatson Studioで行えます。当然ながらモデルは開発中に様々な観点でチェック2され、本番利用に耐えうるレベルになっているはずです。完成したモデルは実行環境(スコアリング環境)であるWatson Machine Learningに本番デプロイして、業務アプリが予測のために利用を開始します。ここで「めでたし、めでたし」で話が終わればいいのですが、AIシステムの場合はそうはいきません。本番開始後も様々な運用上の課題が発生します。
- モデル性能(精度)の劣化有無の監視/検知と対応
- フィードバック・データを用いたモデルの洗いがえと本番反映、版管理
- モデル判断のバイアス3 (特定のセグメントに有利/不利に働いていること)有無の監視/検知と対応
- AIモデルが増えることによる、人手対応の限界(または破綻)
- 顧客始め、関係者からモデルの判断根拠を求められた場合の説明責任
- 本番でのトレーサビリティと監査対応
これら運用上の異なる課題に対し個別のソリューションで対応すると、各々が統合されていないため連携や運用が複雑になります。Watson OpenScaleは様々な課題への対応を「一つの統合したソリューション」として、UI始め使い勝手の良い形でご提供するものです。
なお、モデル開発の際にFairnessを判定しバイアスを緩和するために、IBMは**AI Fainess 360 Toolkitをオープンソース**として提供しています。2 モデル開発時はAI Fainess 360 Toolkitでバイアス有無をチェックし、運用時はWatson OpenScaleを使う、という組み合わせもありますね3。
ご提供形態
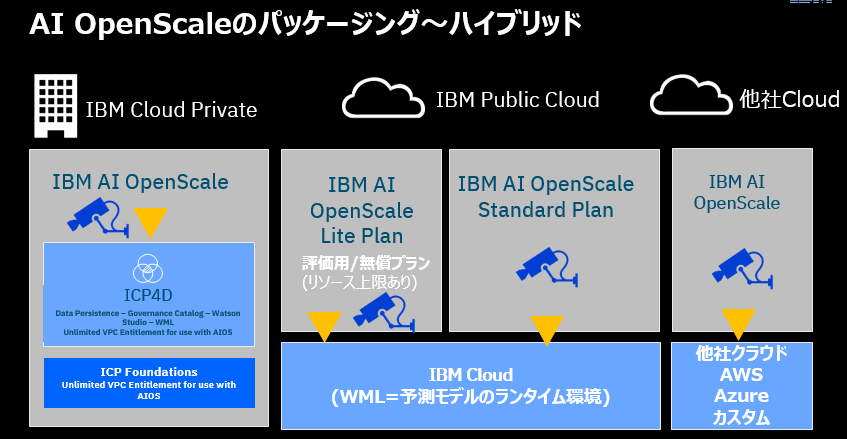
- パブリック・クラウドとプライベート・クラウド(ICP)の両方でハイブリッドにご利用頂けます
- パブリック・クラウドではIBM Cloud上で既に利用可能です。無料のライト・アカウントですぐにお試しいただけます

- 「監視する対象AI」はIBMのWatson Machine Learning以外にもAWSのSageMaker, Azure ML、カスタムAIなどを扱えます。説明可能性はモデルの実装に依存しない方式なので、AIの実装を選びません。

主な機能

上記が主な機能です。![]() ~
~![]() がお客様から見た場合のメインの機能ですが、それ以外にも様々な機能が搭載されています。一点、重要なのがPayload Loggingの仕組み(インフラ)です。平たく申せば、本番での予測モデルへのすべての入出力を記録・蓄積するしくみで、これが
がお客様から見た場合のメインの機能ですが、それ以外にも様々な機能が搭載されています。一点、重要なのがPayload Loggingの仕組み(インフラ)です。平たく申せば、本番での予測モデルへのすべての入出力を記録・蓄積するしくみで、これが![]() ~
~![]() のベースになります。
のベースになります。
AIの運用って、モデル性能(精度)の監視だけではだめなのか
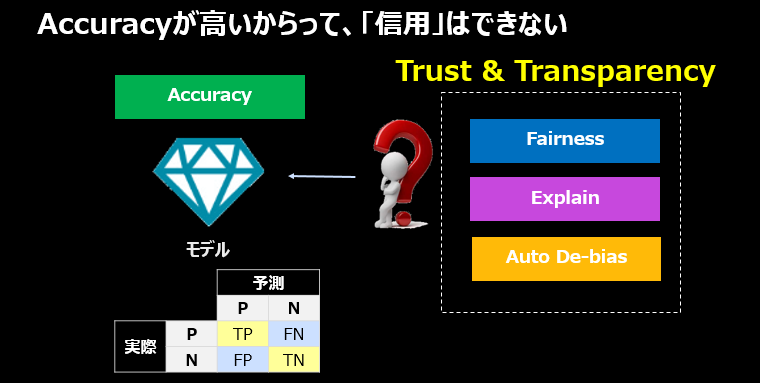
いまさら/釈迦に説法かもしれませんが、いちおう。Accuracyは「精度」=「予測の当たる確率」です。Accuracyがモデルを評価する重要な指標であることは当然ですし、モデルのAccuracyは高いほうがいいに決まってます。しかし、AIモデルの判断を「信頼できるか」という観点では、Accuracyが唯一の指標とはいえません。
- Accuracyは「予測が当たってるかどうか」であってFairnessのような「予測が偏っているのではないか」を見る指標にはなりません
- モデルのAccuracyを改善しても、Fairness(バイアス)は改善しません
- ディープラーニングのような「説明できない」モデルでも、Accuracyは算出できます。Accuracyだけでモデル判断の「説明」はできません
- 「予測」は結論だけです。Accuracyはこの「予測」が当たってるかどうか、の指標です。この結論に至った理由は一切示してくれません。(ローン申請で「可否」の結論は示せても、「なんで?」は示してくれません)
要は業務担当者から「このAIモデルの判断を信頼していいのか?」と問われた際に、IT目線で**「このモデルの精度は99%だから大丈夫です」と答えても現場の納得感が無い**、ということです。だからWatson OpenScaleのようなものが必要なのです。
機能のご紹介
以降、上でお示しした機能をひとつずつ簡単にご紹介していきます。
FairnessとAccuracyの関係
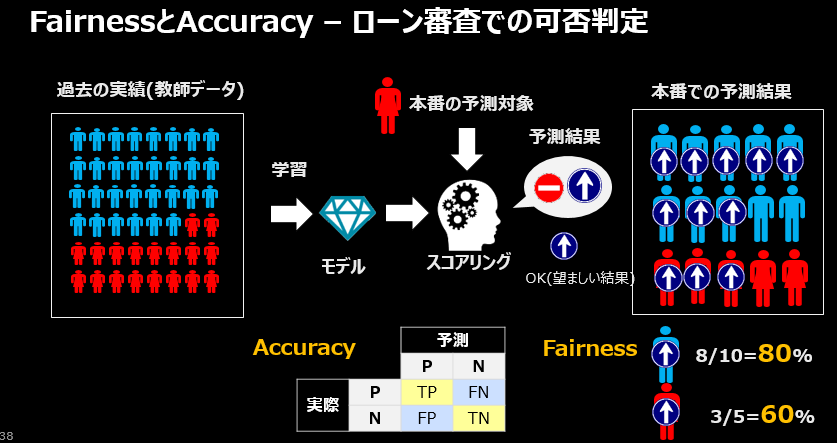
まずはローン審査業務を例に重要な2つの指標、FairnessとAccuracyをご説明します。顧客のローン申し込みを「承認」するか「否認」するかを判定するモデルを作り、本番で判断に使うシナリオとします。
- Accuracyは日本語では「精度」です。機械学習で交差検証をして作られる混合行列で示される精度=「予測が当たる度合い」の指標です。皆様にはおなじみかと思いますので説明は割愛しますが、本番にデプロイされたモデルのAccuracyは一般的に次第に劣化しますので、本番でも継続的な監視が必要な指標です。
- Fairnessは「公平さ」です。「バイアス(差別や偏り)が無い状態」ともいえますが、価値観としては機会の平等 vs 結果の平等など、様々な考え方や意見がありえます。Watson OpenScaleでは「(差別する意図の有無に関わらず)結果的に予測に公平さが保たれているかどうか」を評価します。「意図」ではなく「結果」を重視する考え方で、「間接差別(Disparate Impact)」と呼ばれます。米国では意図的・直接的な差別(Disparate Treatment)は論外として、たとえ意図されたものでなくても結果的に人種・宗教・民族などのグループ間での扱いに著しい差異や不平等が生じている場合は、法律違反として雇用機会均等委員会(EEOC)による摘発の対象になりえます。具体的な評価指標としては、特定のグループ(モニタリング・グループ)と別のグループ(リファレンス・グループ)間で、望ましい結果(Desired Outcome)を得られた比率にどの程度の違いがあったかを評価するものです。上の例では、女性より男性の方がローンの申し込みには有利なようです。つまり、「性別」軸でみると、「ローンの承認」という「望ましい結果」が「男性」に偏っており、結果的に「女性」は損をしている、と見ることができます。
| 比較軸 | 申し込み | 承認 | 承認率 |
|---|---|---|---|
| 男性 | 10 | 8 | 8÷10=0.8(80%) |
| 女性 | 5 | 3 | 3÷5=0.6(60%) |
男女間の承認率の違い(Impact Ratio) = 0.6÷0.8=0.75(75%)4
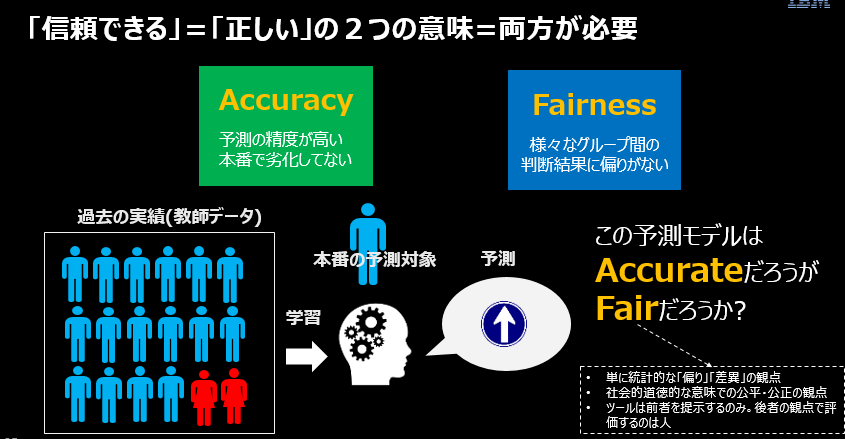
FairnessとAccuracyはまったく別の指標です。モデルのAccuracyが高いからといって、モデルがFairだとはいえません。 ローンの審査を例に取りますと、過去の実績が「男性の方がローンを承認される割合が高い」のであれば、その事実を教師データとして作成された判定アルゴリズムは男性の申し込みなら承認する確率が高いはずです。なぜなら、予測モデルとは過去のパターンを未来の予測に適用するものにすぎないからです。つまり「Accuracy=正解率」の観点からは「女性」より「男性」に対して「承認」を多くするのが道理にかなった判断と言えます。でもこの判定での「望ましい結果(ローンの承認)」は「性別」軸で見ると「男性」側に非常に偏っている=バイアスがかかっています5。このように、Accuracyだけ見ていてもFairnessは評価できません。両者は別の指標ですので、本番運用ではFairnessとAccuracyは両方を監視する必要があります。
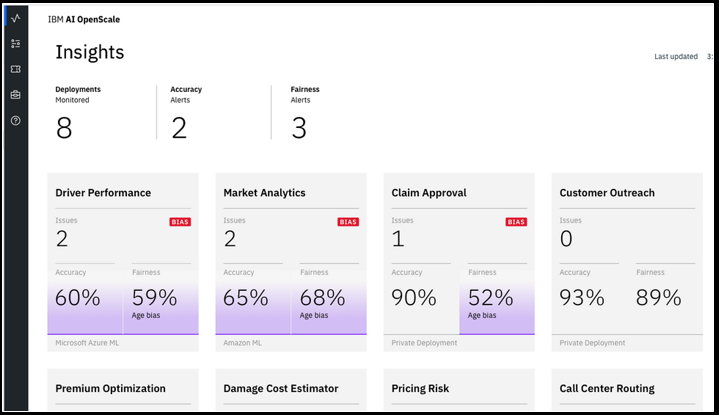
上記はWatson OpenScaleのメインのダッシュボードですが、モデルの監視指標は大きくは①Fairnessと②Accuracyの2つになってます。
Fairness(公正さ)
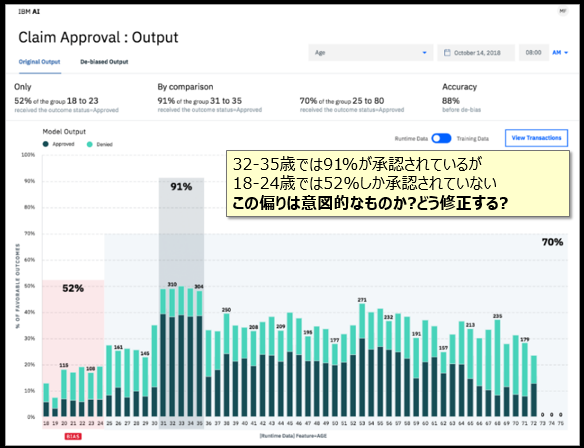
Watson OpenScaleでは、特定の時間帯の公平さ(バイアスの有無)を監視できます。たとえば上記の例は何らかの申請(Claim)の許可・拒否の状況を示しています。これらを年齢別の分布で見ると、18-24才の若年層の申請は、許可される率が他と比べて非常に低いことがわかります。これは意図した結果でしょうか、問題でしょうか?公平といえるでしょうか?それは人間の判断になりますが、「偏り(バイアス)」が可視化されなければ、そもそもの「偏っている」ことを気付くことができません。
![]() 「どんな項目のバイアスを監視すべきか」は利用者が事前にUIで定義しておきます。Watson OpenScaleが自動的に項目を選ぶわけではありません。
「どんな項目のバイアスを監視すべきか」は利用者が事前にUIで定義しておきます。Watson OpenScaleが自動的に項目を選ぶわけではありません。
De-bias/Bias Mitigation(バイアスの緩和)
Passive De-biasing(受身のバイアス緩和)
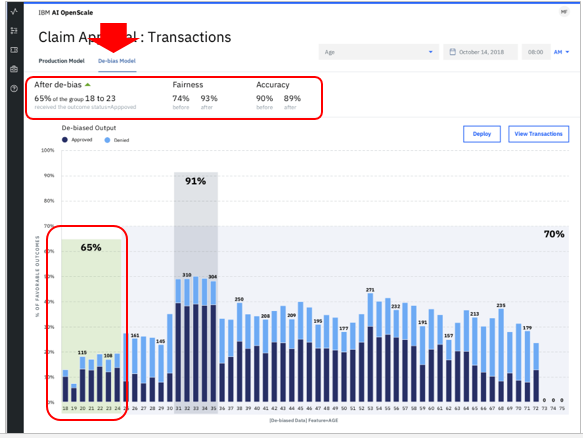
Watson OpenScaleのFairness機能は「偏っているよ」と警告してくれるだけでなく、「この偏った状況を是正する場合、AccuracyをX%犠牲にすればFairnessをY%改善・緩和できますよ」という推奨を提示してくれます。ここでの「緩和」とは、「グループ間での判定に差異がある状況を、慣らす」ことです。例えばローン審査の判定で女性に不利な状況がある場合、「女性の承認を増やす」方向にモデルの振る舞いを変更することです。上記の例ではAccuracyを1%犠牲にすれば(90%→89%)、Fairnessは19%改善(74%→93%)しますよ、と言っています。実は、Watson OpenScaleは本番環境のすべてのスコアリング要求を補足し、データベースに記録しています。(ペイロード・ロギング)そして一時間毎に直近のFairnessの状況を様々な手法で評価し、ダッシュボードに表示してくれます。
Active De-biasing(積極的なバイアスの緩和)
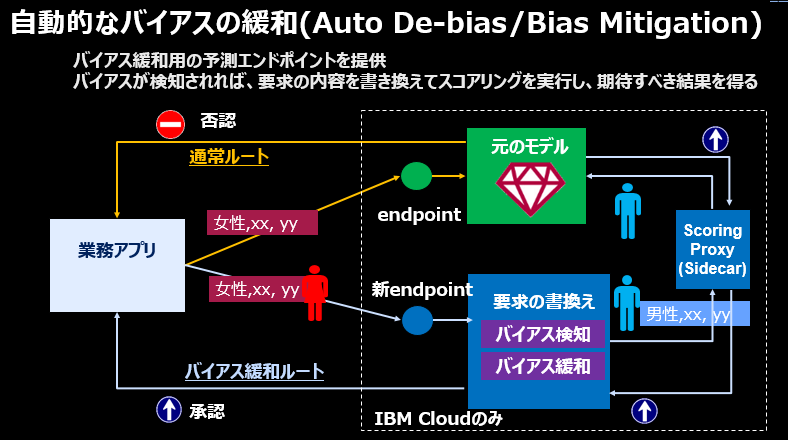
モデルが偏った判断をしている状況を見るだけでなく、動的/積極的に緩和することもできます。~~IBMクラウド(=WML)のみ6の機能になりますが、~~スコアリング要求の入力パラメーターを自動的に書き換えて「期待すべき結果」を得ることで予測結果の偏りをリアルタイムで緩和していくことが可能です。Watson OpenScaleは前述のPassive De-biasingを通じて「今、どのように偏っているか、それを直して期待すべき結果を得るにはどうすればいいのか」を既に知っているので、要求のリアルタイムの書き換えが可能なわけです。通常はモデルのバイアスを補正・緩和するなら改めてモデルをトレーニングしなおす必要がありますが、それには手間も時間も高いスキルも必要になります。Watson OpenScaleならモデルの再トレーニングをせずに、リアルタイムで/動的に/自動的にバイアスを緩和できます。
(2019/02/06追記) アプリは本来のスコアリングのエンドポイントではなくAIOSが提供するDe-Bias用のエンドポイントを呼び出すように変更すれば、あとはWatson OpenScaleに「お任せ」できます。具体的にはスコアリング時点でモデルにバイアスがあり警告されていればバイアスを緩和する方向に判定結果を変更してアプリに返しますし、バイアスが無ければ介入しません。その積み重ねで次第にバイアスが解消して、しきい値の範囲に収まれば、そこで緩和の動きは停止します。
Explain - 予測の説明(Explain Prediction )
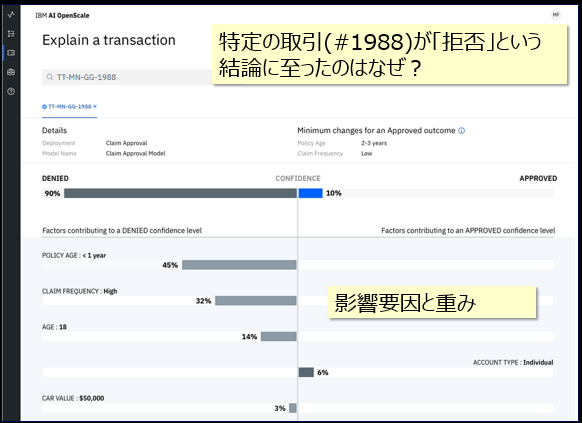
「このローン申し込みはなぜ拒否(または承認)されたのですか?」という顧客や監査部門からの問いかけに答える機能です。アンサンブルやニューラル・ネットワークのような**「ブラックボックス」モデルに関しても、個別の予測結果の根拠・主な要因と重みを示せます。**説明のための手法はLIME+αであり、モデルの実装に依存しませんので、IBMのAIだけでなく、他社含めどんなAIでも対応できます。上記の例では結果的に「拒否」となりましたが、その結論に与える主な要因と重みとしては加入年数(POLICY AGE)が一年未満であること、申請の頻度が多いことが拒否の方向に90%の影響を与えています。顧客種別が「個人」であることは「承認」の方向に10%の影響を与えてはいますが、最終的には「拒否」の結論になった、とわかります。この事実を顧客にそのまま提示することは無いでしょうが、業務担当者は「説明する根拠」を手に入れられます。
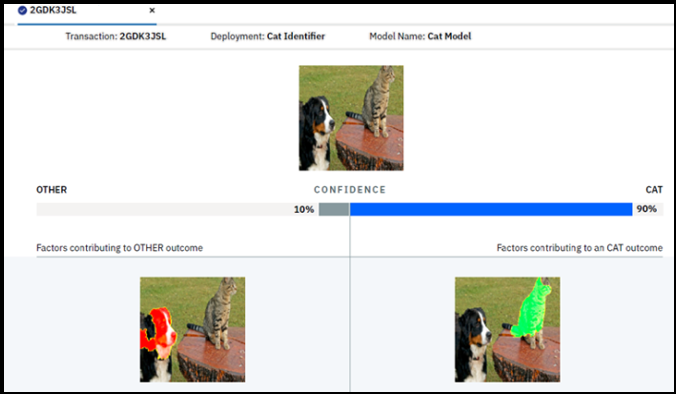
イメージの説明もできます。AIはこのイメージを「猫」と判定しましたが、「イメージのどこを見て猫と判断したか」「どこは犬と思ったか」「各々の重み付けは」などが一目でわかりますね?
 <質問> なんでブラックボックスのモデルの振る舞いがわかるんですか?
<質問> なんでブラックボックスのモデルの振る舞いがわかるんですか?
一般にperturbations(摂動)と呼ばれる手法を使っています。ごく簡単に言うと、パラメータの値を変化させながらモデルに何度もスコアリングを要求し、応答の変化を記録・把握します。それらの結果を元にモデルの特徴・振る舞いを導くものです。有名な実装はLIME(Local Interpretable Model-agnostic Explanations)ですが、Watson OpenScaleではContrastive Explanations7という手法も併用し、精度と効率を改善しています。
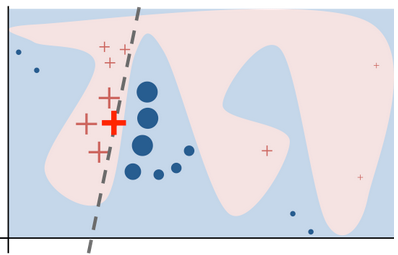
※上図はLIME - Local Interpretable Model-Agnostic Explanationsからの引用。ある判定の入力パラメータをすこしずつ変えることで、モデルの振る舞い=判定の境界を外部から明らかにする手法
Accuracy - 本番でのモデル性能劣化検知と自動対応
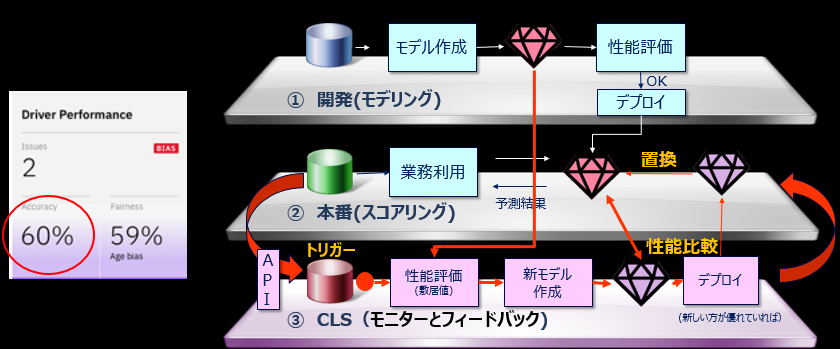
平たく言えば、「放っておいても本番でのモデルの性能劣化を検知・警告してくれて、必要なら新しいデータで洗い替えして勝手に本番反映してくれる=本番モデル性能の維持管理を楽にする」機能です。
ここでいう「性能」とは、いわゆる交差検証した結果、混合マトリックスで表現されるようなモデルの精度・性能のことです。ご存知のとおり、モデルは時間経過と共に様々な理由で性能劣化する宿命にあります。Watson Studio/WMLでは以前から以前から**継続的学習システム( Continuous Learning System )**として本番モデルの性能劣化検知と自動洗い替えのしくみをご提供8してきました。それが今回、装いも新しくWatson OpenScaleに搭載されました。仕組み的には
①モデル開発時点でトレーニングデータでの精度がX%だったとする
②モデルが本番に反映され、本番データで予測が実行される
③CLSはAPIエンドポイントを介して明示的に与えられた6本番データを①のモデルに投入し、最新データでのモデルの精度を算出する(Y%)
④Y%が指定した基準を下回っていれば、CLSは改めて裏で本番データを使って新しいモデルを作成し、精度を算出する(Z%)。結果、Z% > Y%であれば、新しいモデルのほうが性能がよいということなので、本番のモデルを自動的に入れ替える
![]() モデル入れ替えの自動化はオプションです。「自動的にできます」が「しない」という選択ももちろん可能です。
モデル入れ替えの自動化はオプションです。「自動的にできます」が「しない」という選択ももちろん可能です。
NeuNet S: AI for AI
「AI for AI」すなわちAIを使ってデータに即したニューラルネットワークを一から組み立ててくれるツールです。IBM Researchの研究成果だそうで、2018/12/14にやっとベータでお披露目されました。まだ機能は限定的ですが、すごく簡単に精度の高いモデルが作れるらしいです。ディープラーニング・モデルの開発に際し、モデルの層の選定やらHPOで悩む日々は近々終わるのかも!?
![]() Using AI to Design Deep Learning Architectures
Using AI to Design Deep Learning Architectures
![]() NeuNetS: Automating Neural Network Model Synthesis for Broader Adoption of AI
NeuNetS: Automating Neural Network Model Synthesis for Broader Adoption of AI
ご興味あればQiita上で@makaishi2さんが入門記事を書いてくれているのでご一読ください。
![]() 「イメージと正解ラベルだけで高精度の画像認識DLモデル作成 - Watsonの最新機能NeuNetSのご紹介 -」
「イメージと正解ラベルだけで高精度の画像認識DLモデル作成 - Watsonの最新機能NeuNetSのご紹介 -」
Model Ops
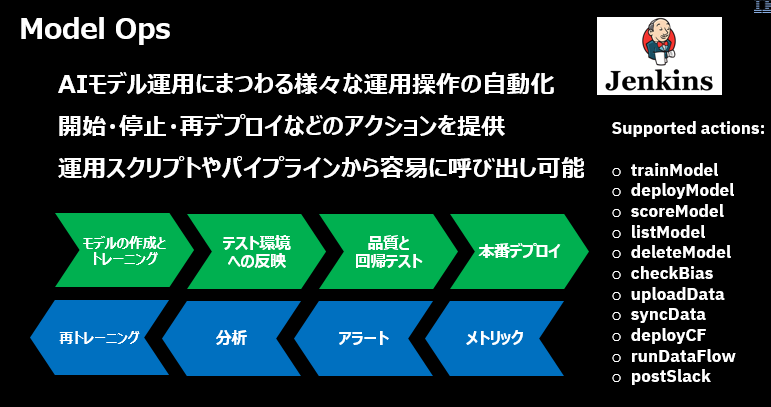
Watson OpenScaleの提供する運用機能は自動化の仕組みに容易に組み込めます。詳しくは下記を(リファレンスなので読むものではありませんが)
![]() API Reference
API Reference
![]() ModelOps CLI
ModelOps CLI
![]() Python Client Reference
Python Client Reference
Payload Logging(ペイロード・ロギング)
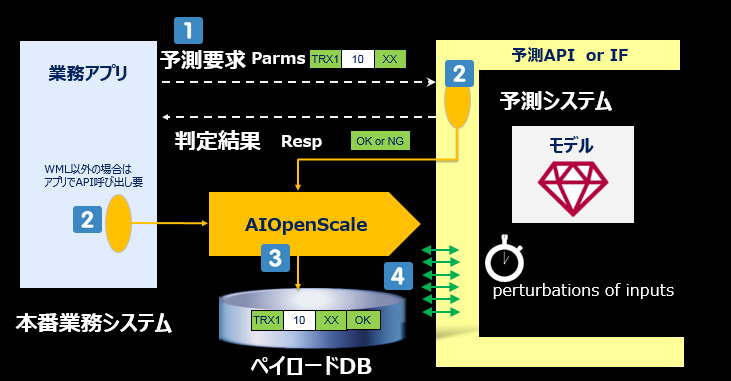
「ペイロード」とは予測(スコアリング)要求の入力(パラメータ)と出力(予測結果)のデータ・ペアのことです。Watson OpenScaleは本番の全スコアリング要求のペイロードをなんらかの手段で入手し、内部DBに記録します。 今まで説明してきたExplainとFairnessはペイロード・ロギングの仕組みに大きく依存しています。(AIの運用に関し色々賢いことができるのは、本番の予測リクエストの入出力を全部記録しているからこそ、できるというわけです)
以下流れをご説明します。
![]() 本番で何らかの予測システムが稼働中で、アプリから呼び出して利用しているものとします。(予測システムはWML/Amazon SageMaker/Azure MLなど色々あるでしょう)
本番で何らかの予測システムが稼働中で、アプリから呼び出して利用しているものとします。(予測システムはWML/Amazon SageMaker/Azure MLなど色々あるでしょう)
![]() Watson OpenScaleは本番環境でのアプリからのすべての予測実行リクエストのInput(パラメータ)とOutput(予測結果)のペア(=これをペイロードと呼びます)を入手し、内部の ペイロードDBに蓄積します。
Watson OpenScaleは本番環境でのアプリからのすべての予測実行リクエストのInput(パラメータ)とOutput(予測結果)のペア(=これをペイロードと呼びます)を入手し、内部の ペイロードDBに蓄積します。
- 予測システムがIBMのWMLの場合は、裏で要求をフックのうえ、内部で動いているKafka経緯で自動的に取り込みますので、アプリの変更は一切不要です
- 予測システムが他社の場合は予測ランタイムの実装に手を入れられないので、アプリから同様の情報をREST APIで通知してもらう必要があります
![]() いずれの場合も、Watson OpenScaleは本番のペイロードをDBに蓄積・記憶します
いずれの場合も、Watson OpenScaleは本番のペイロードをDBに蓄積・記憶します
![]() 一定間隔(デフォルト1時間)で直近のインターバルで溜まった本番のペイロード9を使って、AccuracyやFairnessの評価を行います。評価の結果、特定のしきい値を超えていればダッシュボードに警告が表示されます。ここでのバイアス有無の評価には摂動分析(pertubation analysis)を用います。
一定間隔(デフォルト1時間)で直近のインターバルで溜まった本番のペイロード9を使って、AccuracyやFairnessの評価を行います。評価の結果、特定のしきい値を超えていればダッシュボードに警告が表示されます。ここでのバイアス有無の評価には摂動分析(pertubation analysis)を用います。
最後に
以上、ザクッと「何できんの、ソレ、、」だけお示ししました。Watson OpenScaleはまだ出たばかりです。今後のロードマップでは来年も機能の追加・拡張が予定されていますのでお楽しみに!
ご参考/リソース
できること・できないこと
![]() サポートされるモデル
サポートされるモデル
各々の機能でどんなモデルがサポートされているか、の一覧表です。
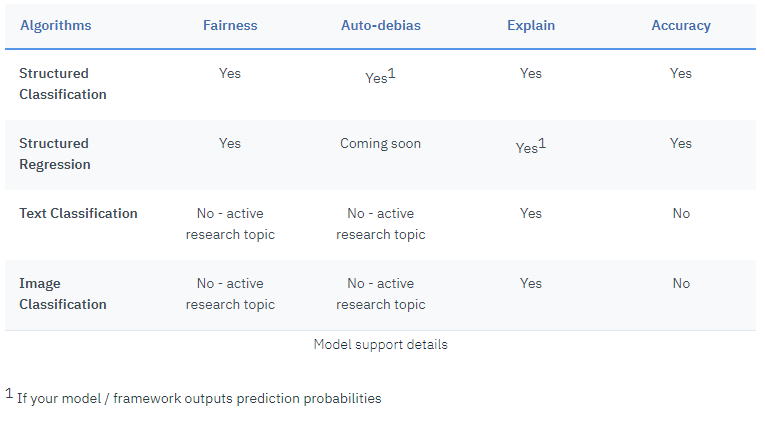
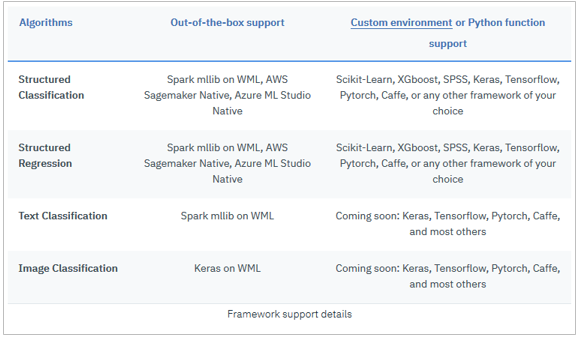
![]() 2019/2月時点では (AssistantやDiscoveryなどの)Watson APIがサポート対象外である点にご注意ください。SPSSも「カスタム環境」を介してのサポートであって、「すぐ使える(Out of Box)」のサポートではありません。
2019/2月時点では (AssistantやDiscoveryなどの)Watson APIがサポート対象外である点にご注意ください。SPSSも「カスタム環境」を介してのサポートであって、「すぐ使える(Out of Box)」のサポートではありません。
お試し
ご興味があればIBM Cloudの無償のLiteプランですぐお試しいただけます。
- Liteプランでは「一度に2つのモデルまで」などリソース上の制約はありますが、機能はすべてお試しいただけます。
- ドキュメントのGetting Startedに紹介ビデオや入門チュートリアルがあり、UIを使った設定などを一通り学べます。
ドキュメント
![]()
![]() Watson OpenScale 製品ページ
Watson OpenScale 製品ページ
![]()
![]() Watson OpenScale 製品ページ
Watson OpenScale 製品ページ
![]()
![]() Watson OpenScale ドキュメント
Watson OpenScale ドキュメント
![]()
![]() NeuNets(ベータ) ドキュメント
NeuNets(ベータ) ドキュメント
![]()
![]() IBM Watson OpenScale: Operate and automate AI with trust - (2018/10/15)製品発表時のお披露目ブログ
IBM Watson OpenScale: Operate and automate AI with trust - (2018/10/15)製品発表時のお披露目ブログ
![]()
![]() IBM Watson OpenScale: Updates to Lite Plan - (2018/12/14) 無償のライトプランの利用可能な上限のお知らせ
IBM Watson OpenScale: Updates to Lite Plan - (2018/12/14) 無償のライトプランの利用可能な上限のお知らせ
![]()
![]() Automate and Operationalize Your AI with Watson OpenScale - (2018/12/14) 各種機能拡張時のの新機能のお披露目記事
Automate and Operationalize Your AI with Watson OpenScale - (2018/12/14) 各種機能拡張時のの新機能のお披露目記事
-
当然ながら、なんでもできるわけではなく「できること・できないこと」があります。最新の状況はドキュメント
 サポートされるモデルをご参照ください。 ↩
サポートされるモデルをご参照ください。 ↩ -
LIMEなどオープンソースのライブラリー群に、IBM独自の機能(たとえばバイアスを検知するだけでなく緩和する方法をアドバイスしてくれます)を加えたものです。Pythonのライブラリーなのでプログラム書ける人が使うものです。 ↩ ↩2
-
AIF360とAI_OpenScaleは別モノです。IBMだからといって「一緒に使わなくてはならない」わけではありませんので念のため。 ↩ ↩2
-
完全にバイアスのない状態ではImpactRatioは100%となる道理ですが、米国での判例では80%以上であれば「フェア」と見なされれ、80%を下回れば「バイアスがある」と判断されるそうです。 ↩
-
ちなみにこの場合、AI_OpenScaleが行うのは「予測が統計的に偏っていますよ!」と警告するだけです。それを社会道徳や「差別をなくす」観点で是正するのは(または是正しないのは)人間の役割です。AI_OpenScaleは価値観や社会道徳を判断しません。 ↩
-
(2019/02/15)すいません。WMLだけでなくAWSやAzure等他社ランタイムでもオーケーでしたので記述を訂正します。 ↩ ↩2
-
ご興味あれば「Watson_Machine_Learningの継続的学習システム(CLS)を試してみた」の記事をご参照ください ↩
-
正確にはさらに「事前に設定した、評価に足るだけの十分な件数のリクエストがあれば」という条件がつきます。 ↩