
![]() (2019/2) AI OpenScaleはWatson OpenScaleに名前が変わりました
(2019/2) AI OpenScaleはWatson OpenScaleに名前が変わりました
 改定履歴
改定履歴
当記事は今後も気付きがあったら追加しようと思うので改定履歴をつけます。初版から記述を追加/変更した箇所には![]() マークを付けておきますね。
マークを付けておきますね。
| 版 | 日付 | 変更内容 |
|---|---|---|
| 1.0 | 2019-02-12 | 初版公開 |
| 1.1 | 2019-04-22 | ・構成時に1件要求が不要になる場合あり ・Explain時のPeturbationでは課金に注意 ・Training Dataについて |
|
はじめに
先日、以下の2つの記事でWatson OpenScaleって何? (できること・できないこと)をご紹介しました。
-
 「AIへの信頼」や「説明可能なAI」に絡み、一部で話題の「IBM Watson OpenScale」をザクッとご紹介します
「AIへの信頼」や「説明可能なAI」に絡み、一部で話題の「IBM Watson OpenScale」をザクッとご紹介します
-
Watson OpenScaleをもう少し「キチッ」とご紹介します(A.K.A.「麗しき誤解」を解く)
正直申しましてWOSって、「できること(解決できる課題)」を理解すること自体が結構難易度高いので、上の記事ではしくみや技術の説明(How)は避けて「できること(What)」のみにフォーカスしました。ただ、あれこれ触ってみて、しくみ面でドキュメントを読むだけではわかりずらい( or きちんと書いてない)「しっといたらいいかも」という点があれこれあるように感じたので、これから入門チュートリアルをやる技術者の方向けに、あれこれを記事にします。皆様のご理解の一助になればと思います。
1. 環境やセットアップ
Watson OpenScaleへの入力データは大きく2種類~ペイロードとフィードバック・データ( +トレーニング・データも必要です)
+トレーニング・データも必要です)
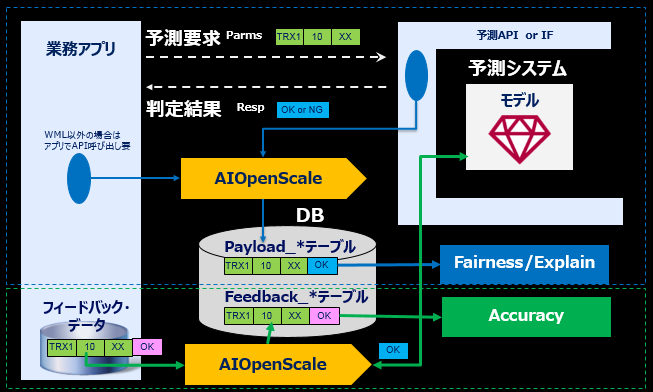
まずはおさらいから。
- 業務アプリが予測システムにスコアリング要求を出すと(WMLの場合は裏で自動的に/他社ランタイムの場合は別途APIを呼んで)PayloadがAIOSのデータベースに書き込まれます。このPayloadデータはFairness監視および予測のExplainに使われます。
- スコアリング要求とは別に、DB2データベース等に格納された事実ベースのフィードバックデータをWatson OpenScaleに入力するとAIOSのデータベースにFeedbackデータがコピー/格納されます。このFeedbackデータはAccuracy監視に使われます。
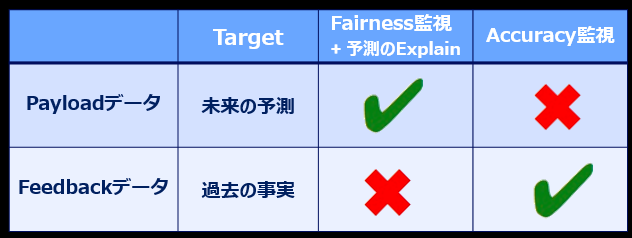
ここで重要なのは、Fairness監視/ExplainでFeedbackデータを使うことは無く、Accuracy監視でPayloadデータを使うことは無い、両者は独立した別のものだ、という点です。詳しくは次にご説明します。
両者の違いは時制=将来の予測 or 過去の事実=「正解」の有無
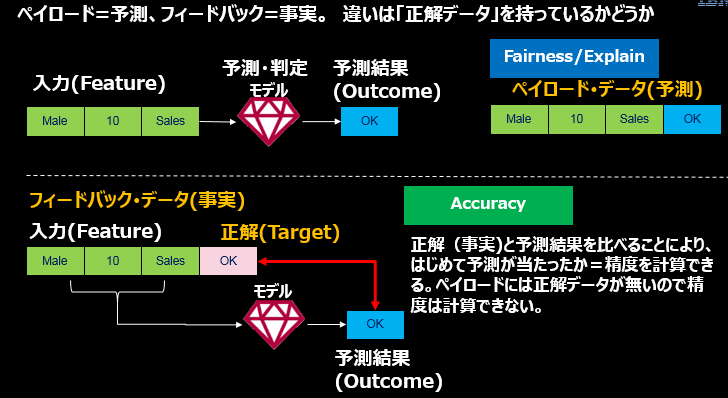
**ペイロードとは将来の予測のデータです。フィードバックは過去の実績・事実のデータです。**両者の時勢は異なっています。(例えるならば、天気予報はペイロード、「昨日は雨だった」はフィードバックです)
- 「Fairness」は予測における「望ましい結果」(ex. ローンOK/NG)が「特定の軸」(ex. 男/女)で著しく偏ってないかどうかを見るだけ、です。Fairnessの視点では「予測が当たったかどうか」はどっちでもいいのです。よって「過去の事実(正解データ)」は不要であり、予測のデータだけあればバイアスを評価できます。(ちなみに「Explain」も「予測モデルが結論に至る道筋」を説明するものであり、その予測が当たったかどうかは見ませんので、「過去の事実(正解データ)」は不要です)
- 翻って「Accuracy」は「予測が当たってるか?」を評価する指標ですから、「過去の事実(正解データ)」が不可欠です。入力データを現在のモデルに投入した「予測の結果」が、「過去の事実(正解データ)」とあってるか?を比較することで「あたり・はずれ」を判断するわけですから、「過去の事実(正解データ)」が必要です。
上記の理由より、Watson OpenScaleでは各々のデータをFairness/Accuracyで別々に扱っているわけです。
(2019/04/19) 構成定義時には該当モデルを作った時のトレーニング・データも必要です
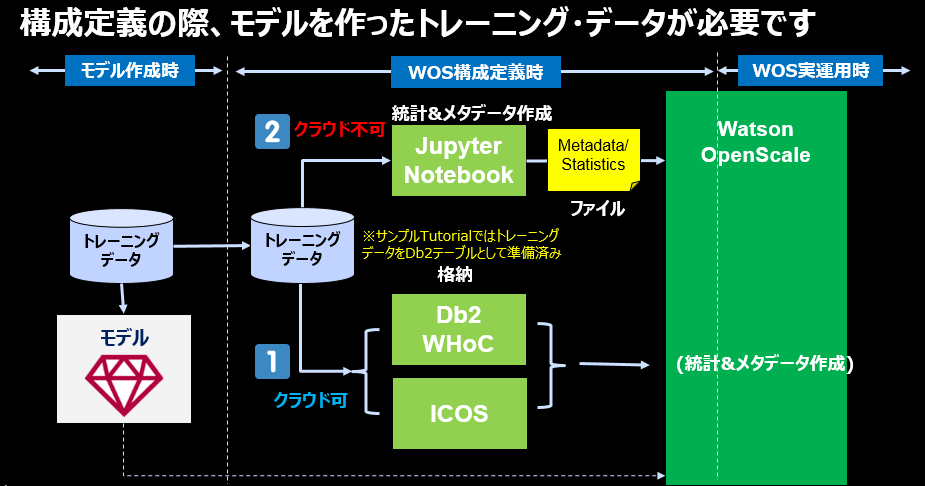
前述のとおり、①ペイロードと②フィードバック・データがWOSの重要な2種類のデータですが、実はもう一種類、「モデルを作った時のトレーニング・データ」もご用意いただく必要があります。
何に使うのか
トレーニング・データは本番の予測で使われるわけではなく、モデルの統計情報/メタデータを得るためにのみ使います。統計情報とは例えば ①各フィールドの実際の値 ②値毎の件数や分布 ③数値の場合の最大/最小/分布などです。具体的にはこのような情報です。このメタデータはフェアネス監視においてトレーニング時と実際の運用時(ペイロード)での結果の比較やExplainのContrastive Explanations等で使われます。
具体的な指定方法
トレーニング・データはモニター定義の際に以下のパネルから指定します。

-
 トレーニング・データをクラウドにアップしてもいい場合に選択します。格納先はIBM Cloud上のDb2WoCかICOSのいずれかです。この場合はデータをスキャンしてメタデータを作成する作業はWOS側で自動的に行われます
トレーニング・データをクラウドにアップしてもいい場合に選択します。格納先はIBM Cloud上のDb2WoCかICOSのいずれかです。この場合はデータをスキャンしてメタデータを作成する作業はWOS側で自動的に行われます -
 トレーニング・データをクラウドにアップしたくない場合です。その場合は提供されるJupyter Notebookを使って統計情報の生成を自社環境で実施いただき、出力結果のメタデータファイルをアップロードします。(前述のサンプルはこの方法で作ったもの)
トレーニング・データをクラウドにアップしたくない場合です。その場合は提供されるJupyter Notebookを使って統計情報の生成を自社環境で実施いただき、出力結果のメタデータファイルをアップロードします。(前述のサンプルはこの方法で作ったもの)
 チュートリアルのトレーニング・データはデフォルト提供
チュートリアルのトレーニング・データはデフォルト提供
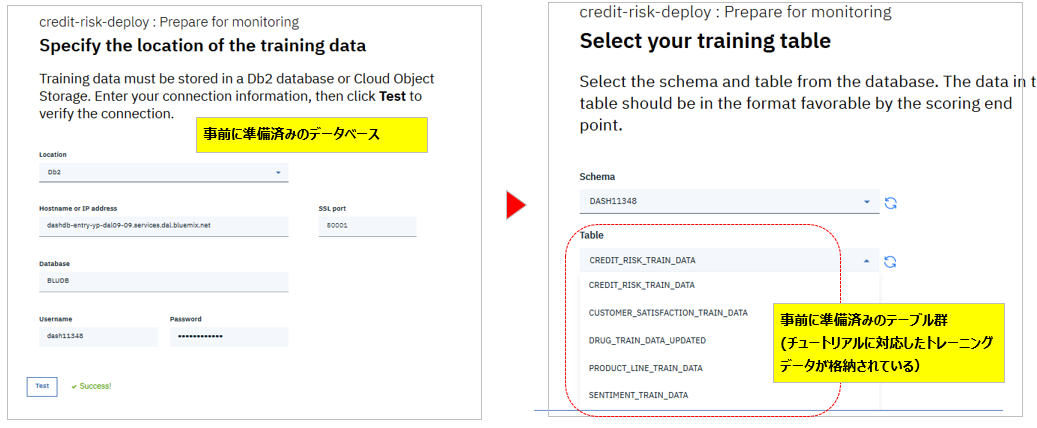
OpenScaleのドキュメントに掲載されているチュートリアルでは、モデルだけでなくトレーニング・データを格納するデータベースやテーブルも提供されています。Monitoring構成のパネルでいうと以下の箇所です。よって、チュートリアルを実行している限り、トレーニングデータの必要性を意識しない場合が多いかと思います。とはいえ実際にご自身のモデルを監視する際は、元のトレーニングデータが無いとWOSのモニタリングの構成ができませんので、ご注意ください。
ICOSの場合の指定方法
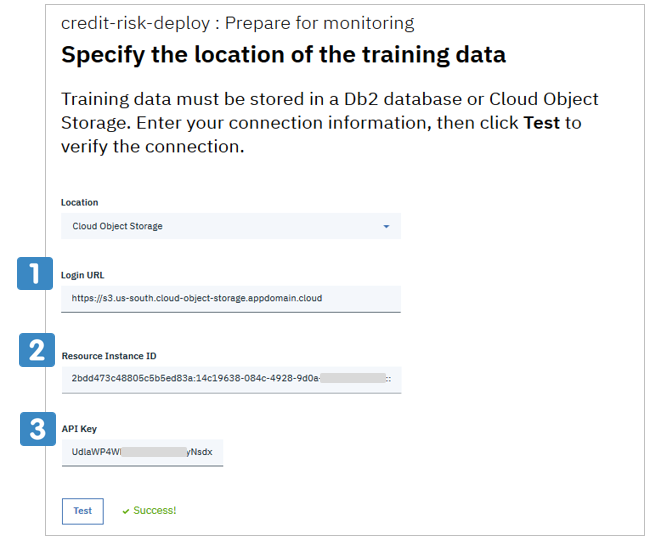
当節冒頭のチャートの![]() クラウド可の場合でトレーニングデータをDb2ではなくてICOSに置きたい場合の指定の仕方ですが、正規のドキュメントが説明不足なので、具体的にお示しします。
クラウド可の場合でトレーニングデータをDb2ではなくてICOSに置きたい場合の指定の仕方ですが、正規のドキュメントが説明不足なので、具体的にお示しします。
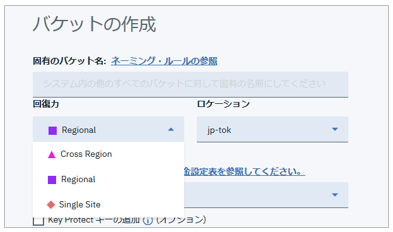
![]() LoginURL - ICOSではバケット作成時に以下のように回復力やロケーションを指定します
LoginURL - ICOSではバケット作成時に以下のように回復力やロケーションを指定します
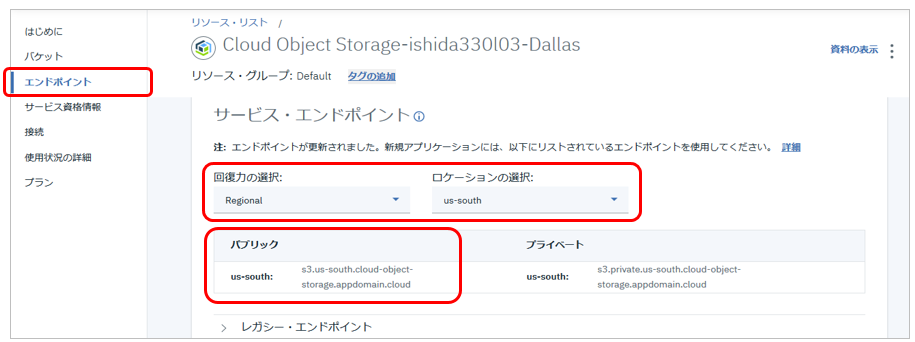
「LoginURL」とはICOSの「サービス・エンドポイント」のことです。ご自身のパケット定義時の属性によりエンドポイントは違いますのでICOSのパネルの「エンドポイント」から参照してください。なおLoginURLに記入する際は**先頭にhttps://を追加**するのをお忘れなく。
![]() Resource Instance ID と
Resource Instance ID と ![]() API Key
API Key
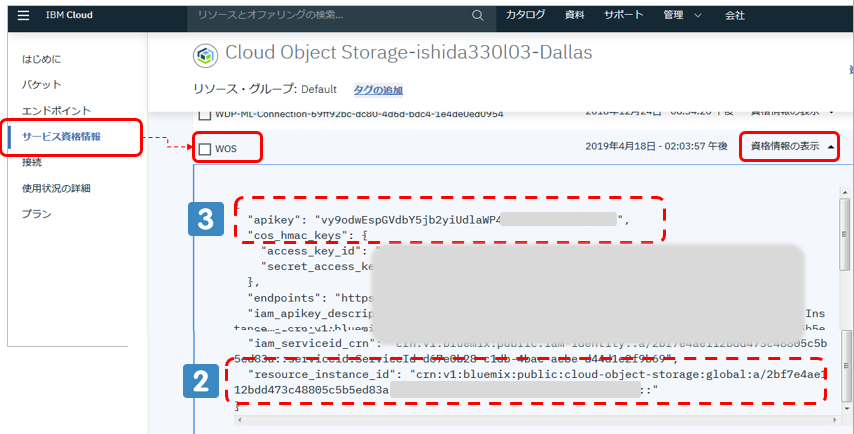
上記のようにICOSパネルの「サービス資格情報」からエントリーを選んで、そこに記載されている値を転記します。(エントリーが無ければ新規に作れます)
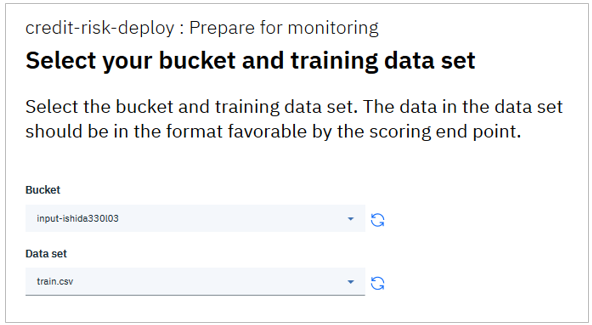
「Test」ボタンを押してSuccess!であれば、認証が通ったので次のパネルでバケットとトレーニング・データのファイルを指定できます。
Watson OpenScaleのテーブル群
![]() InternalDBの中身を見る方法は記事「小ネタ: Watson OpenScaleのInternalDBの中身を見る」をご参照ください。
InternalDBの中身を見る方法は記事「小ネタ: Watson OpenScaleのInternalDBの中身を見る」をご参照ください。
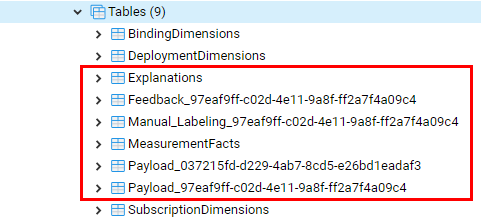
上記がpgadminで見たAIOSのInternalDBのテーブル群の例です。赤い枠のものは該当する操作毎に行が追加更新されます。それ以外は定義を格納するものです。Watson OpenScaleは1インスタンスで複数のモデルを管理できます。AIOSのデータベースはインスタンス毎に1つですが各々のモデルはSubscription_IDで識別できます。上の画面コピーの場合はモデル2つを監視対称にしているので、Payloadテーブルが2つあり、各々はPayload_Subscription_IDの名前で区別できます。
| テーブル名 | 説明 |
|---|---|
| SubscriptionDemensions | 【構成定義】Watson OpenScaleの監視対象モデルのリスト |
| DeploymentDimensions | 【構成定義】Subscriptionがデプロイされた状況のリスト(定義) |
| BindingDimensions | 【構成定義】Deploymentに更なる区別がある場合(テスト、本番など) |
| MeasurementFacts | FairnessやAccuracy、Debias等の評価の結果(Facts)を格納 |
| Explanations | Explain機能を実行した結果ログを格納 |
| Feedback_(subid) | フィードバック・データのコピーとAIOSでの処理日時を格納 |
| Manual_Labeling_(subid) | Perturbationの結果を格納 |
| Payload_(subid) | スコアリングの結果のペイロードを格納 |
_(subid)..サブスクリプションID
この辺を知っておくと、何か問題判別が必要になった際に「どこを見るといいか」の当たりがつくので便利です。
環境設定は大きく3段階。途中で予測を1件実行する必要があるのは出力のスキーマを確認するため。
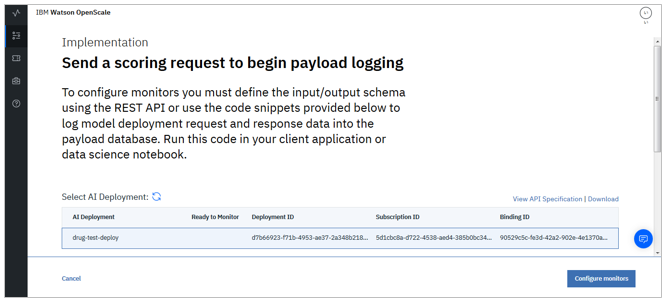
![]() (2019/04/19)
(2019/04/19) ![]() 最近すこしですが振る舞いに変更(改善)があって、以下の両条件を満たせば「予測を一件実行する」必要がなくなっています。
最近すこしですが振る舞いに変更(改善)があって、以下の両条件を満たせば「予測を一件実行する」必要がなくなっています。
- 監視対象のモデルがWML上にデプロイされたものであること
- WMLにデプロイされたモデルのメタデータにOUTPUT_DATA_SCHEMAを含んでいること(WMLにデプロイする側が指定してるかどうか、の話です)
とはいえ、
- Watson Builderではモデルのデプロイ時にoutput_data_schemaは生成していないので、Watson Builderで作ったモデルの場合は結局1件投げろといわれます
- Jupyter NotebookなどでWMLのAPIを駆使してモデルをデプロイする場合は、そこでoutput_data_schemaを指定すれば、この恩恵にあずかれます
- Drug SelectionやCredit Riskのようなサンプル・チュートリアルでは手順的に書いてあるものの、実際は1件投げなくても次に進めるようです
↑(2019/04/19追加ここまで)
当初、自分が迷ったので同じような方がおられるかもしれないので書いておきます。Watson OpenScaleを使い始めるための構成作業は大きく3段階あります。Watson OpenScaleのUIパネルのウイザードの指示とおりに進めればいいだけなのですが、Setupのウイザードが完了した後にImplementationとして「一件でいいからスコアリング要求投げて」と言われます。1 ここで、きちんと一件投げないと次のモニタリングの構成に進めないようになっています。「あれ、モニターの構成に進めない。。」と思ったら「2. Implementation」の1件スコアリングを実行する手順をもらしていないかどうか、ご確認ください。なお、同パネルの下部にはPayloadテーブルに1件データを追加するためのサンプルコードがありますが、中身を見ずにこのまま実行してはいけません。これ、チュートリアルのDrug Selectionの場合の「例」にすぎず、自分のモデルに合わせてレイアウトとかを書き換えなくてはいけないのです。AmazonやAzureなどの場合はランタイムから裏で自動的にPayloadをキャプチャーできないのでこのAPIの方法をとらざるを得ませんが、WMLの場合は単にスコアリングさえすれば自動的にキャプチャーしてPayloadを記録してくれます。よってわざわざこの例のようなAPIによるPayload登録作業は不要です。
![]() 具体的には、最低1件ペイロードが無いとMonitorの構成時に下記の警告が出ます
具体的には、最低1件ペイロードが無いとMonitorの構成時に下記の警告が出ます
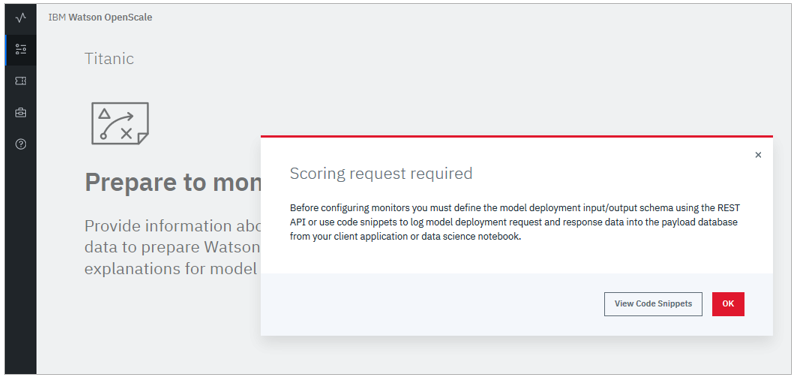
(以前はパネルの「Begin」ボタンがグレイアウトされて進めませんでした)
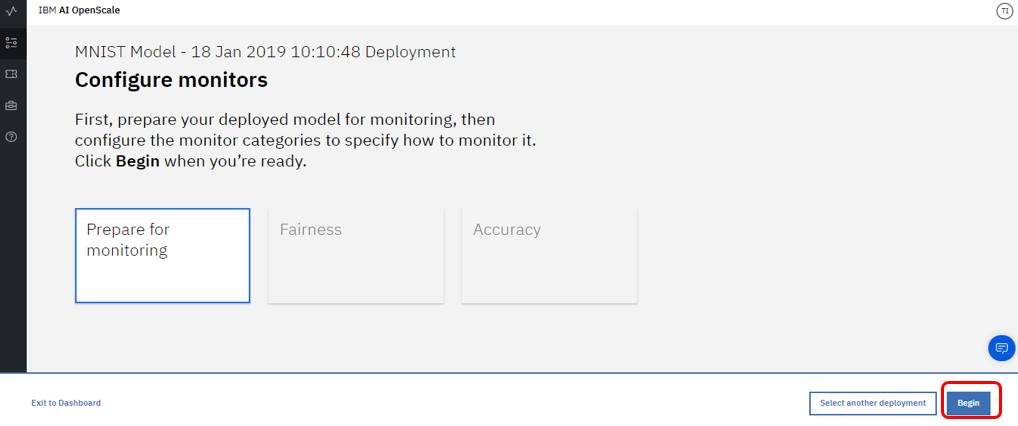
うまくいけばパネルを進めることができ、最終的に下記のように「Ready to Monitor」の欄にチェックマークが付きます。
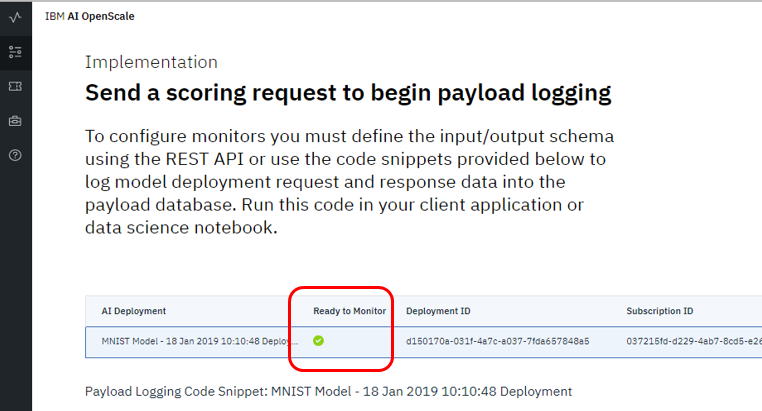
- (WML以外のケース) 進めない場合の問題判別としては「該当サブスクリプションのPayloadテーブルのカラム構成(レイアウト)が実際のリクエストと合ってるか?最低1件、行があるか?」を確認されるとよろしいかと。WMLの場合はテーブルは自動的に定義され、ペイロードは自動的にキャプチャーされるはずなので「レイアウトが違ってる」ようなケースは起こりづらいですが、他社環境などではAPIの呼び出しがもれている、レイアウトなどのメタデータが誤っている、などあるやもしれませんので。
- 他の環境は試していませんが、少なくともWMLの環境では「1.Setup」環境時点で既にPayloadテーブル等は定義されています2ので、なんでここで更に1件スコアリングさせるかなあ(面倒くさい)、そのままモニタリングの構成に進ませてよ、と思っていたのですが、どうもここでスコアリング要求の出力のスキーマをチェックしているらしく、今はスキップできないようです。
2. Fairness
Fairnessでは指標が100%を超えることもある
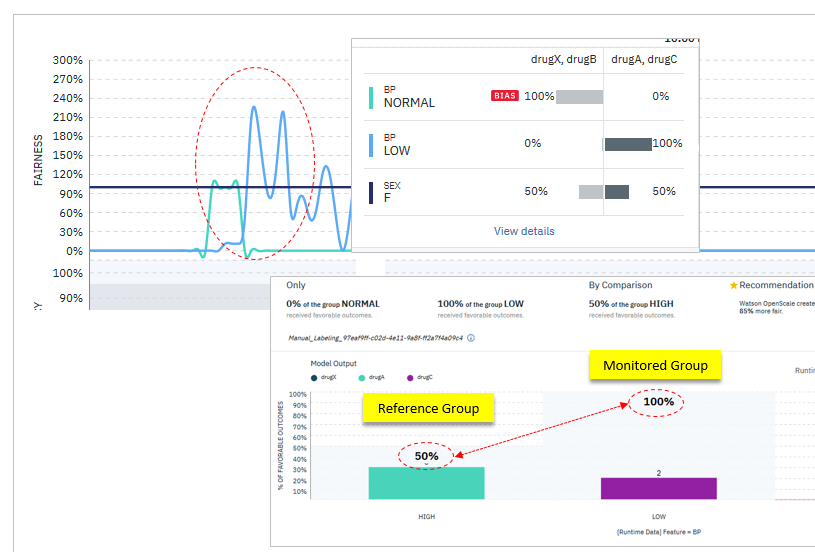
あれこれ触っててダッシュボード上のFairnessの指標が200%を超えました。で「あれ?」と思いましたが、よく考えたら正しい結果でした。Accuracyの指標は「Reference Groupのうち望ましい結果を得た割合」と「Monitored Groupのうち望ましい結果を得た割合」を比べることにより判定します。私はお勉強でDrug Selectionのチュートリアルを使っていましたので、望ましい結果はdrugA/Cです。予測リクエストの入力データはテストなのでランダムに生成していました。その結果、たまたま血圧(BP)=HIGHのグループ(Reference Group)は50%がdrugA/Cの結果を得ました。翻って血圧(BP)=LOWのグループ(Monitored Group)は全部(100%)がdrugA/Cの結果を得ました。この割合をMonitored Group÷Reference Groupと比率で見ると200%を超えますので、正しい結果です。要は通常は(バイアスを監視したいような)Monitored Groupのほうが比率は低いはずなので気がつきませんが、Accuracyの指標が100%を越えるということは「逆バイアス」であり、それは(望ましいかどうかとは別に)理屈としてはありうる、製品のバグというわけではない、ということです。
Pertubation(摂動)でやってること
Pertubation(摂動)の背後にある理論については高度すぎて私は正しく説明できませんが、要は、特徴量=入力データの値をあれこれ変えてモデルに入力してみて、判定結果がどう変わるか(変わらないか)を見ることでモデルの振る舞い・性質を推測するものです。Watson OpenScaleでは「バイアスの比較軸のデータを反転させて結果の変化を見る」ことは最低限やっているようです。
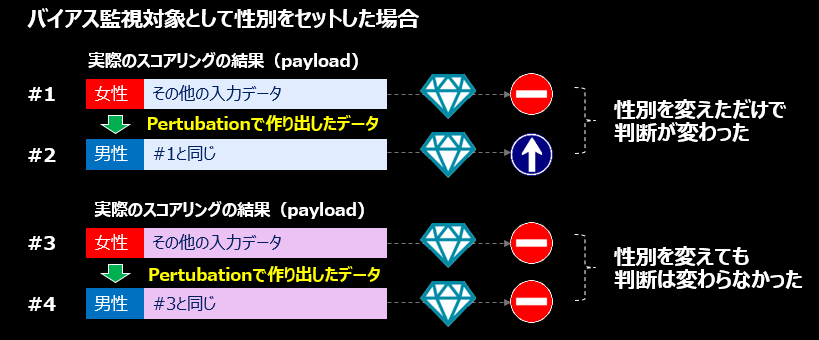
以下、話を単純化してご説明します。
- ローン審査で性別によるバイアスを検知するシナリオで、女性に関して予測をしたら拒否だった(#1)とします。その事実はペイロードテーブルに自動的に記録されます。Watson OpenScaleは一定周期で#1の入力レコードの他の部分は変えずに性別のみを男性に変え(#2)、裏で再び予測を行います。この動きがPertubationです。
- その結果、今度は判断が「承認」に変わったとします。この場合、他のデータはすべて同一なのに性別を変えただけで「結果」が変わったわけですから、モデルは「性別に対してバイアスがかかっている」といえます。
- 別の予測で女性が「拒否」され(#3)、Pertubationで「男性」に変えても「拒否」された(#4)とします。この状態の場合はモデルは性別に対してはバイアスかかかっているとはいえません。
実際は本番では多数の予測が行われており、一定時間に蓄積されたペイロードは多数あることでしょう。またバイアスの監視項目も性別以外にいろいろ設定されていることが多いでしょう。このような環境でWatson OpenScaleは一定時間(一時間毎)で3、自動的に前の時間帯のペイロード群に対してPertubationを行い、多数の結果を入手4した上で総合的にモデルの振る舞いやバイアスの状況を判定します。
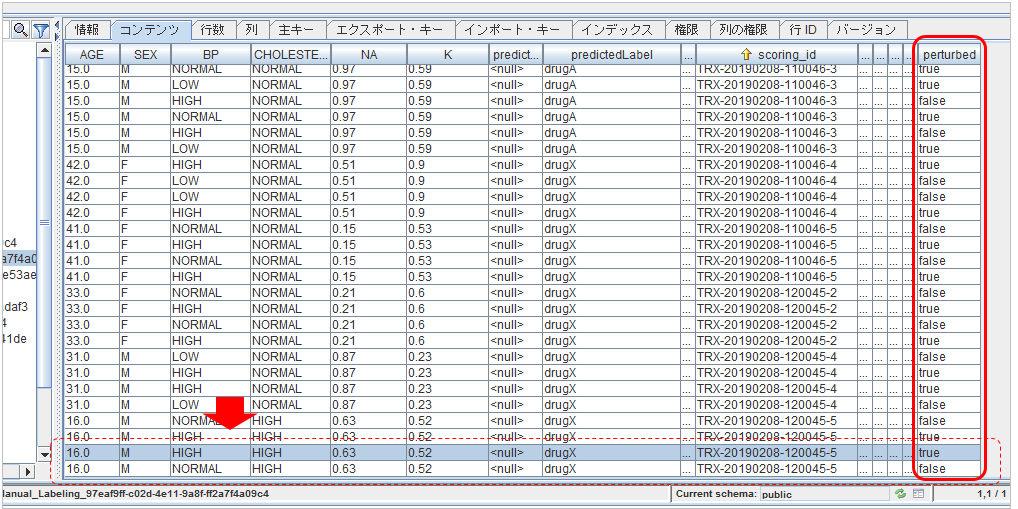
このPertubationの様子はManual_Labelingテーブルに記録されています。カラム perturbedがTrueのものは実際のペイロードではなくperturbationによって作り出された行です。上記の例はチュートリアルのDrug Selectionの例ですが末尾の2行でBP=NORMALのペイロードをBP=HIGHに変更して実行したけれど、結果はいずれもdrugXで変わらなかった、と読みとれます。
え、じゃPertubationの分の予測も課金されるの?
前述のようにPertubationでは裏で実際に予測を実行します。翻って、予測の実行ランタイムであるWatson Machine Learningの課金は「予測リクエスト数」に対して行われます。ここで勘の良い方は「え、じゃ裏で実行するPertubationの予測も課金されるの?」と思われるかもしれません。結論から申しますと
- ランタイムとしてWMLをお使いであれば、課金されません。Watson OpenScaleはモデルのコピーを独自のSandbox環境に作り、そこでPertubationの予測を行いますので、WML本番側での課金は回避できます
- 他社のランタイムの場合は、他社の課金ルールに沿いますが、WMLの場合のような特別な仕掛けがありませんので、基本、課金されると思ってください。 フェアネスやデバイスでのPertubationはたいしことありませんが、後述のExplainの場合には1回のExplainで5000回程度のスコアリング要求が出ますので、課金にご注意ください。5
3. バイアス緩和(De-Bias)
ダッシュボード
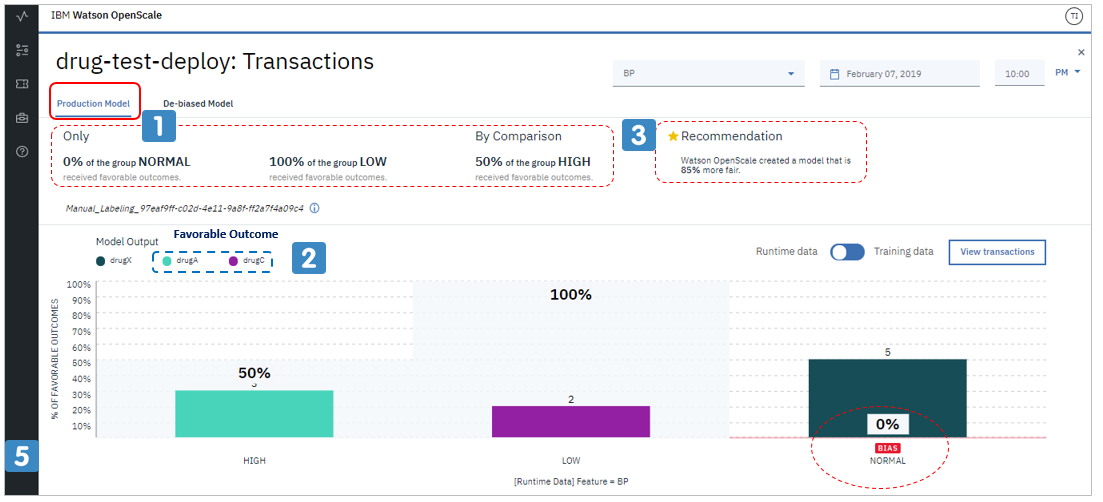
![]() 一時間毎のスコアリングの集計が見られます。この例では
一時間毎のスコアリングの集計が見られます。この例では![]() 「期待される結果(Favorable Outcome)はdrug-Aとdrug-Cです。BP(血圧)=NORMALの場合で5件の予測が行われましたが、結果はすべてdrug-X=期待される結果を得られませんでした。比較対象であるBP=HIGHが50%に対して0%なのでバイアスの警告がされています。
「期待される結果(Favorable Outcome)はdrug-Aとdrug-Cです。BP(血圧)=NORMALの場合で5件の予測が行われましたが、結果はすべてdrug-X=期待される結果を得られませんでした。比較対象であるBP=HIGHが50%に対して0%なのでバイアスの警告がされています。
![]() WOSはフェアネスの指標を85%に緩和できるモデルを使えるよ、と教えてくれています。(ここは常に「よりよいモデル」が提示されるとは限りません。例えば次の一時間でスコアリングが一件もなければ改善のしようもなく「0%改善できるよ」といった価値の無い表示になることもあります。)
WOSはフェアネスの指標を85%に緩和できるモデルを使えるよ、と教えてくれています。(ここは常に「よりよいモデル」が提示されるとは限りません。例えば次の一時間でスコアリングが一件もなければ改善のしようもなく「0%改善できるよ」といった価値の無い表示になることもあります。)
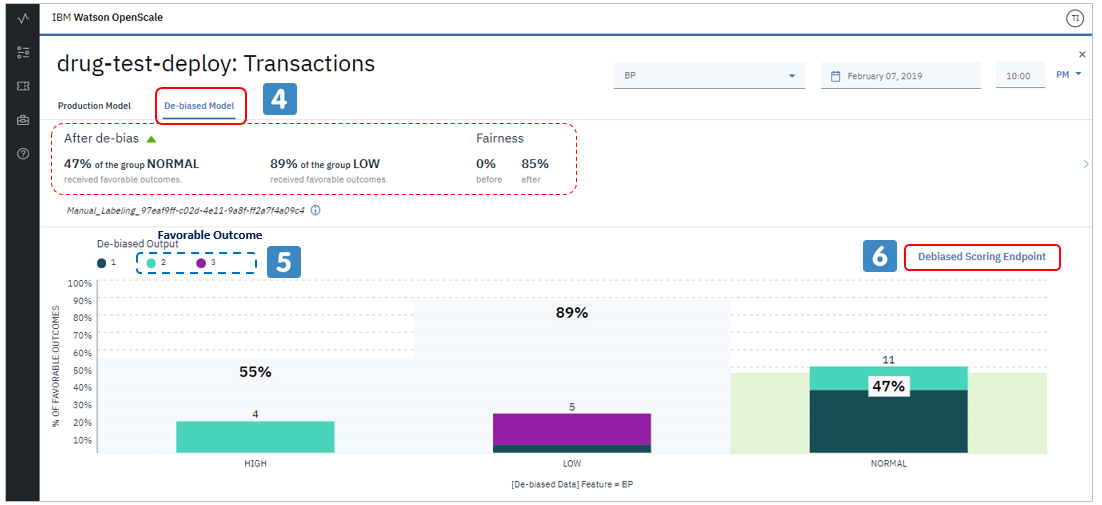
![]() その右の「DeBias Model」のタブを見ると「こんな感じに改善できる」と教えてくれます。ここはPerturbationなどの結果を活用しています。
その右の「DeBias Model」のタブを見ると「こんな感じに改善できる」と教えてくれます。ここはPerturbationなどの結果を活用しています。
![]() この緩和する方向のモデルを使えば、BP=HIGHが55%でBP=NORMALが47%になるのでフェアネス指標を(47%)÷(55%)=85%にまで緩和できる、と言ってます。
この緩和する方向のモデルを使えば、BP=HIGHが55%でBP=NORMALが47%になるのでフェアネス指標を(47%)÷(55%)=85%にまで緩和できる、と言ってます。
![]() そのためにはWMLの元々のエンドポイントではなく、こっちのエンドポイントを使ってね、と言ってます。リンクをクリックしますと
そのためにはWMLの元々のエンドポイントではなく、こっちのエンドポイントを使ってね、と言ってます。リンクをクリックしますと
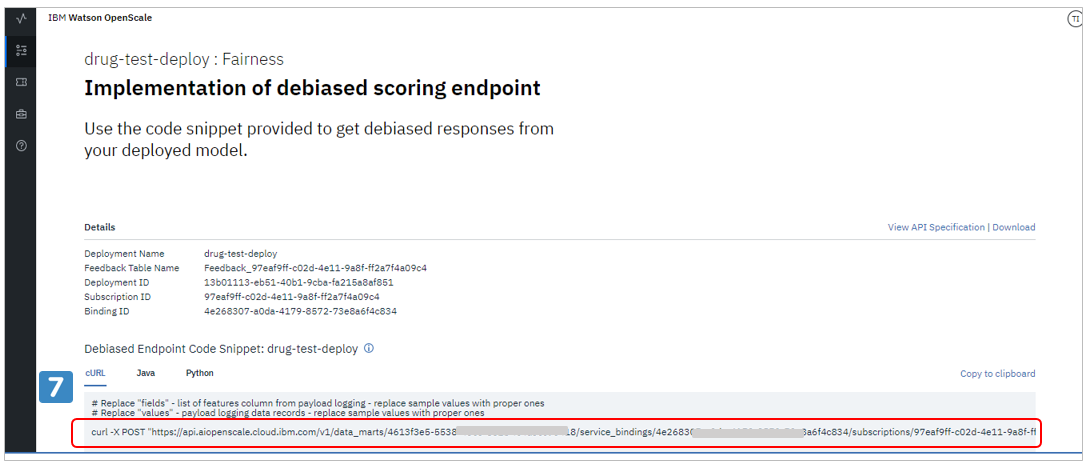
上記のようにDe-Bias用のAPIエンドポイントが示されます。
de-bias Endpointの使い方
Watson OpenScaleでバイアスの自動的な緩和をしたいのであれば、WMLの提供する元のエンドポイントではなく、Watson OpenScaleの提供するDe-Biasエンドポイントを呼び出してください。本番運用中、ある時間帯がバイアスが無い状態であれば元のエンドポイントと同じように振舞いますし、バイアスが生じた時間帯であれば自動的に緩和の方向に振舞ってバイアスをしきい値以下に抑えるように判断を操作します。その結果、しきい値を下回れば「緩和」操作は自動的に停止します。これらの「緩和のためのアクション」はWatson OpenScaleにより自動的に行われますので、運用部門による人手の操作や介入は必要ありません。
De-Biasエンドポイントを使うには、プログラミングでURLを新しいものに書き換えるだけでよいのですが、レスポンスとしては①元の判断結果 ②緩和を適用した時の判断結果の両方が返ります。 ![]() 両方の結果が返りますから、①②のどちらをアプリで採用するかは、お客様が決められます。
両方の結果が返りますから、①②のどちらをアプリで採用するかは、お客様が決められます。
- 業務上、②のバイアス是正後の値を積極的に利用する(この場合、現在はアプリは①の値を使っているでしょうから、②の値を使うようにプログラムの若干の書き換えが必要になります)
- 業務上は引き続き①を採用し、②の値はあとで違いを調べるためにペイロードDBに記録するだけに留める
のいずれでも結構です。
Debiaエンドポイントのレスポンス
以下はDe-biasエンドポイントを呼び出した場合のレスポンスのレイアウトですが、通常のエンドポイントでのレスポンスに加え、4つのフィールド(de-bias欄が○)が追加されます。
| # | de-bias | フィールド | 説明 | 値の例 |
|---|---|---|---|---|
| 1 | Feature(n個) | モデルへの入力となる特徴量 | [43.0,"M","LOW","HIGH", 0.66, 0.05] | |
| 2 | ○ | debiased_prediction | De-Bias(緩和)後の予測(数字で表現) | 0 |
| 3 | ○ | debiased_probability | De-Bias(緩和)後の確信度 | [0.66, 0.0, 0.0, 0.34, 0.0], |
| 4 | ○ | (debiased_decoded_target) | De-Bias(緩和)後の予測(値で表現) | "drugX" |
| 5 | rawPrediction | [2.0, 0.0, 0.0, 1.0, 0.0], | ||
| 6 | predictedLabel | 元々の予測(値で表現) | "drugY" | |
| 7 | features | [43.0, 0.0, 2.0, 0.0, 0.66, 0.05] | ||
| 8 | probability | 予測の確信度 | [0.66, 0.0, 0.0, 0.34, 0.0] | |
| 9 | prediction | 予測(数字で表現) | 0.0 | |
| 10 | xxxx_IX | カテゴリー | [2.0, 0.0, 0.0] | |
| 11 | ○ | scoring_id | スコアリングID | "31e1728e-cd57-45a1-86ac-f2aa2373bae2-1" |
元々の(何もしなかった時の)WMLの予測値とDe-bias適用後の予測値の両方が返るのがおわかりいただけると思います。特に重要な以下の3つを詳しく説明します。
debiased_prediction
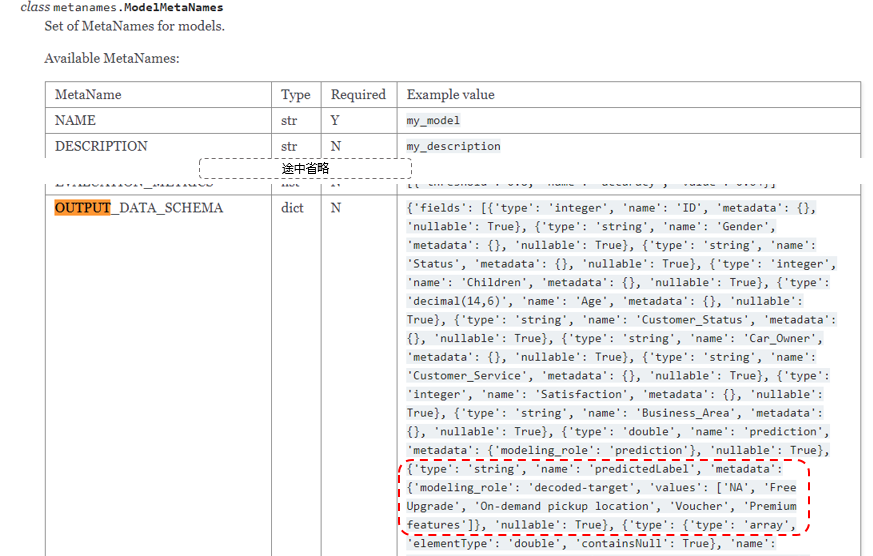
- バイアス緩和後の予測値ですが、カテゴリー値の場合、表現としては数値で返ります。この数字の意味ですが、事前にモデルをWMLに格納する(store_model)際にメタデータ OUTPUT_DATA_SCHEMAで以下のように予測のとりうる値をリストで定義します6が、このリストのN番目(0~)かを示します。たとえば下記の状況でdebiased_predictionに0.0が返れば、0番目="drugX"だということです。
{
"type": "string",
"name": "predictedLabel",
"metadata":
{
"modeling_role": "decoded-target",
"values": ["drugX", "drugY", "drugA", "drugB", "drugC"]
},
"nullable": True
},
debiased_probability
各予測値の確信度です。上のメタデータの"values"リストの順番に対応します。"values": ["drugX", "drugY", "drugA", "drugB", "drugC"]であれば、[0.66, 0.0, 0.0, 0.34, 0.0]とは"drugX"の確信度が66%、"drugB"の確信度が34%ということです。
debiased_decoded_target
上記のように予測結果がリスト中の順序番号で返ると、値への変換(Decode)が面倒です。当フィールドはこの変換をした後の「値」で返してくれます。なお、debiased_predictionとdebiased_probabilityは必ず返りますが、当フィールドは前掲の"modeling_role": "decoded-target"が定義されている場合のみに返ります。(普通はこっち使いますよね。。なんでこんなややこしい仕様にしたのか、ちと意味不明。。)
![]() 2019/2/12時点、debiased_decoded_targetがレスポンスに含まれないバグがあるようです。既に報告&修正済みなので数日中に本番反映すると思いますが、しばらくご辛抱ください。すいません。
2019/2/12時点、debiased_decoded_targetがレスポンスに含まれないバグがあるようです。既に報告&修正済みなので数日中に本番反映すると思いますが、しばらくご辛抱ください。すいません。
なお以下はご参考ですが、Payloadテーブルは実際の予測の結果とDeBiasした場合の予測結果の両方を保持しています。
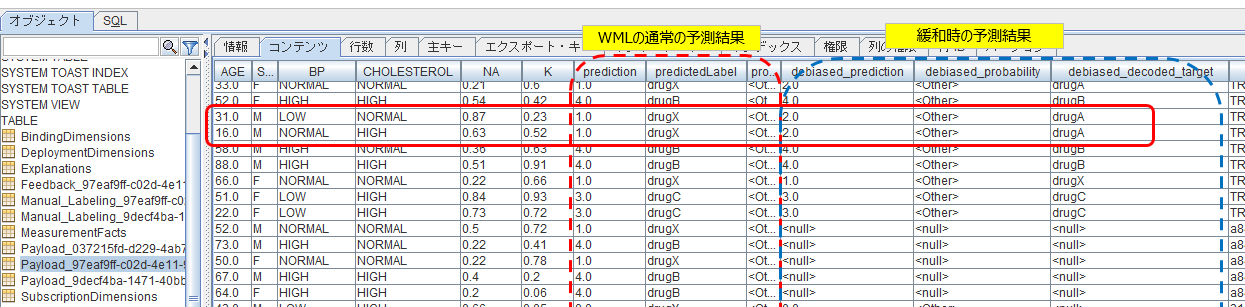
赤い実線の行など見ると、Debiasの結果、"drugX"の判定が望ましい値である"drugA"に変わっています。あと、「Debiasしても結果が変わらないもの」もある点にご注意ください。細かいところは私も存じませんが、Debiasエンドポイントは「呼び出したら、とにかく必ず期待された結果が返る」というような単純なものではなく、もうすこし高度なことをやってるようです。
![]() WMLのAPIの詳細は当記事末尾のご参考)WMLのドキュメントをご参照ください。
WMLのAPIの詳細は当記事末尾のご参考)WMLのドキュメントをご参照ください。
Debias Endpointの呼び出し例
以下はチュートリアルのDrug SelectionのモデルのDe-Biadエンドポイントを呼び出した例です。通常のWMLの呼びだしとURLが違うだけ、です。ただし前掲の通り、レスポンスにフィールドが増えています。
import requests
import json
# IAM Tokenの入手
def getToken(apikey):
url = 'https://iam.bluemix.net/identity/token'
header = {'Content-Type': 'application/x-www-form-urlencoded',
'Accept': 'application/json'}
payload = {'grant_type': 'urn:ibm:params:oauth:grant-type:apikey',
'apikey': apikey}
response = requests.post(url, payload, headers=header).json()
return response['access_token']
# platform_apikey ... IBM Cloudの 管理 - セキュリティ - プラットフォームAPIキー より作成
platform_apikey = "mqsxYZfUMvhO_XXXXXXXXXX-XliEJTDMhlouU8-q-64"
# AIOSのDASHBOARDから
debiased_url = 'https://api.aiopenscale.cloud.ibm.com/v1/data_marts/XXXXXXXXXX-38-43ce-862b-fc4a3cc90418/service_bindings/XXXXXXXX-a0da-4179-8572-73e8a6f4c834/subscriptions/XXXXXXXX-c02d-4e11-9a8f-ff2a7f4a09c4/deployments/XXXXXXXX-eb51-40b1-9cba-fa215a8af851/online'
# 呼出し時のパラメータ
params = {
"fields": ['NA', 'K', 'AGE', 'CHOLESTEROL', 'SEX', 'BP'],
"values": [[0.66, 0.05, 43.0, 'HIGH', 'M', 'LOW']
]
}
header = {'Content-Type': 'application/json', 'Accept': 'application/json',
'Authorization': 'Bearer ' + getToken(platform_apikey)}
response = requests.post(
debiased_url, data=json.dumps(params), headers=header).json()
print(response)
{'fields': ['AGE', 'SEX', 'BP', 'CHOLESTEROL', 'NA', 'K', 'debiased_prediction', 'debiased_probability', 'predictedLabel', 'BP_IX', 'rawPrediction', 'prediction', 'probability', 'SEX_IX', 'CHOL_IX', 'features', 'scoring_id'], 'values': [[43.0, 'M', 'LOW', 'HIGH', 0.66, 0.05, 0.0, [0.6666666666666666, 0.0, 0.0, 0.3333333333333333, 0.0], 'drugY', 2.0, [2.0, 0.0, 0.0, 1.0, 0.0], 0.0, [0.6666666666666666, 0.0, 0.0, 0.3333333333333333, 0.0], 0.0, 0.0, [43.0, 0.0, 2.0, 0.0, 0.66, 0.05], 'XXXXXXXX-0196-4452-9d08-50c7b70d62b6-1']]}
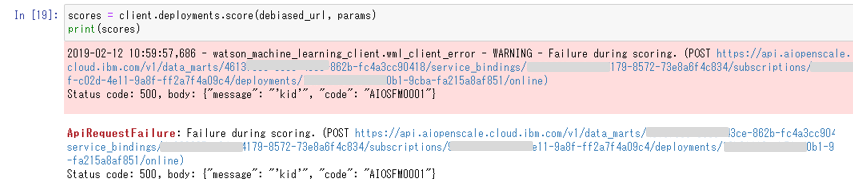
![]() WMLでは上記のREST スタイル以外にPython Clientも提供されています。が、このPython ClientではDe-Bias Endpointはサポートされていないらしいです。(マジか。。)以下のようにエラーになったので問い合わせしていたのですが、「RESTを使う」ことをオススメされました。
WMLでは上記のREST スタイル以外にPython Clientも提供されています。が、このPython ClientではDe-Bias Endpointはサポートされていないらしいです。(マジか。。)以下のようにエラーになったので問い合わせしていたのですが、「RESTを使う」ことをオススメされました。
4. Explain
トランザクションID 設定の必要性
「トランザクションID」とは個々の予測を識別するためにアプリケーションがリクエスト毎に付与するID、キーのようなものです。任意の文字列でよく、お客様は自由に採番ルールを決められます。例えば予測リクエストの「トランザクションID」として顧客番号や日時などを含めた番号体系のIDを付与しておけば、あとでExplain機能で「特定の顧客のローン否認の理由を説明する」場合の検索が楽になります。なお、予測実行時にトランザクションIDを指定しないとランダムな文字列が割り当てられます。
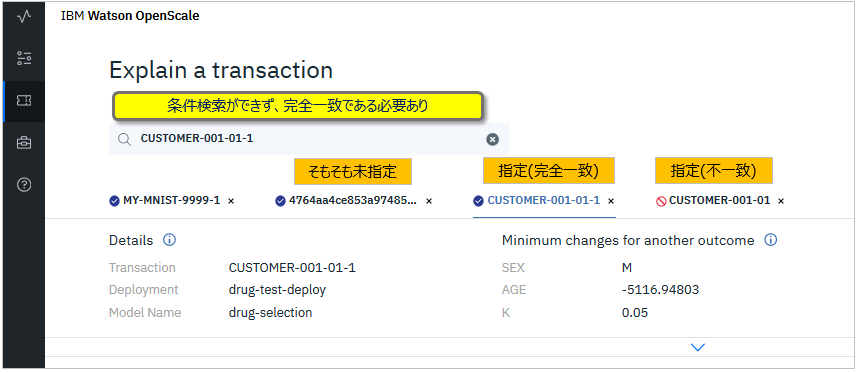
残念ながら現時点のExplainパネルではトランザクションIDは条件検索ができず、**入力したIDと完全一致しないと説明が表示されません。**大量のペイロードの中から目的の予測のエントリーを探し出すのはかなり困難です7。できれば予測の実行時に検索する可能性のあるキーをトランザクションIDとして指定しておくとよいのではないかと思います。
トランザクションIDのセット方法
トランザクションIDはWMLのスコアリング実行時にアプリケーションで指定します。(指定しなければデフォルトのランダムな文字列が割り振られます)
WMLのPythonクライアントを使うとき
Python Clientのドキュメントにありますが、score時にtransaction_id=を指定できます。
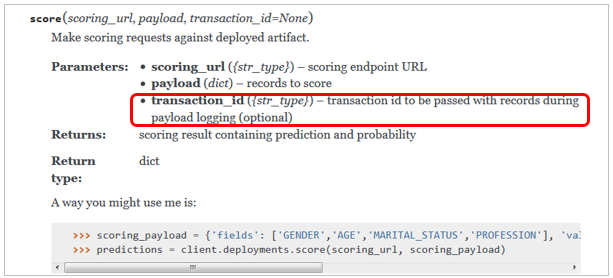
scores = client.deployments.score(scoring_url, params, transaction_id="CUSTOMER-001-01")
WMLのScoring EndpointをRESTでたたく時
AIOS側のドキュメントにありますが、HTTPヘダーのX-Global-Transaction-IdにトランザクションIDを指定できます。
platform_apikey = "xxxxxxxxxx"
header = {'Content-Type': 'application/json', 'Accept':'application/json',
'Authorization': 'Bearer ' + getToken(platform_apikey), 'X-Global-Transaction-Id':'CUSTOMER-002-01'}
response = requests.post(scoring_url, data=json.dumps(params), headers=header).json()
上記コードは抜粋です。このGistに実際に使ったJupyter Notebookを貼ってありますので、ご参照ください。
IDの扱われ方の注意点
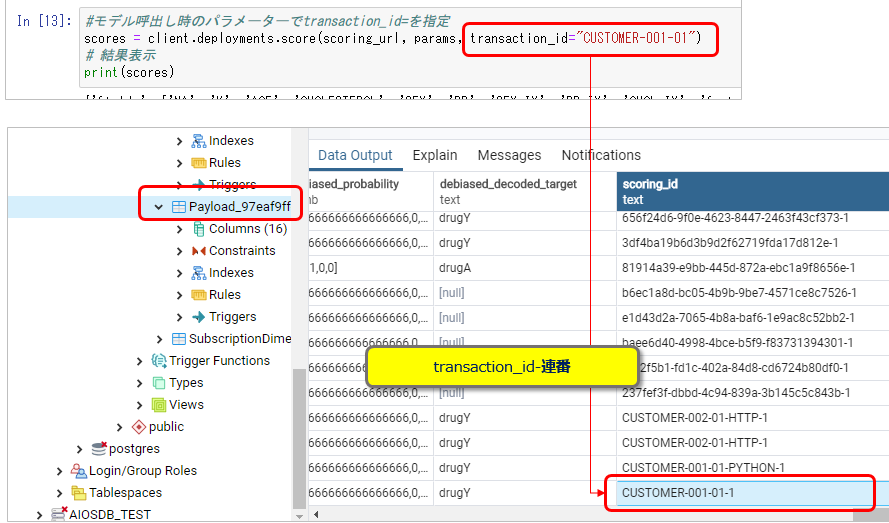
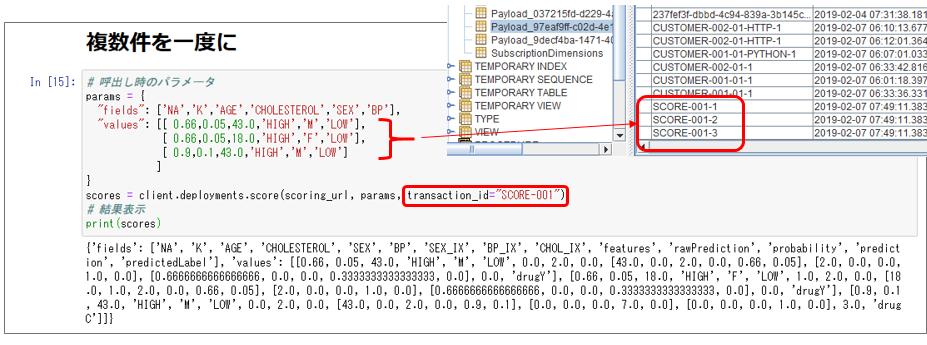
アプリケーションで指定したトランザクションIDはPayloadテーブルでは末尾に「-連番」が付いた形式でscoring_idカラムに格納されます。Explainで完全一致で指定する必要があるのは、このscoring_idです。
絵を再掲しますが、アプリケーションで指定した「CUSTOMER-001-01」だと「見つからない」になり、scoring_idである「CUSTOMER-001-01-1」だと結果が表示されています。
この連番が付く理由ですが、実はWMLでは以下のようにペイロードを配列にして「一回の要求で複数件の予測をまとめて実行する」ことができます。その場合に個々の入力を識別するために連番が付与されているわけです。Payloadテーブル上も3件にわかれて格納されています。
Explainの問題判別
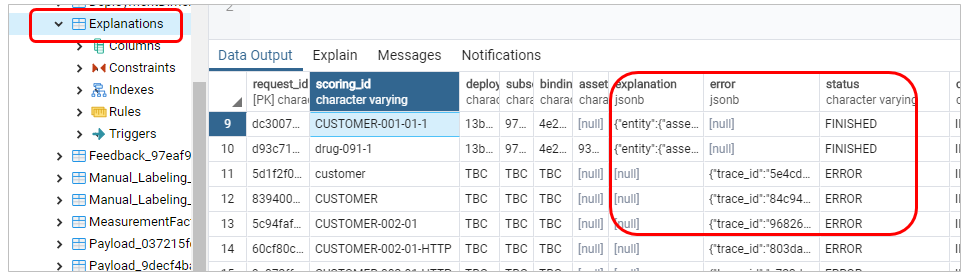
ExplanationsテーブルにはExplainを実行する都度、どのトランザクションIDに対してどういう結果だったか、エラーの場合は何か(「見つからない」など)などが逐一記録されています。何かうまくいかないときにはテーブルを見るのも役に立ちます。
上部のMinimum changes for another outcomeって何?
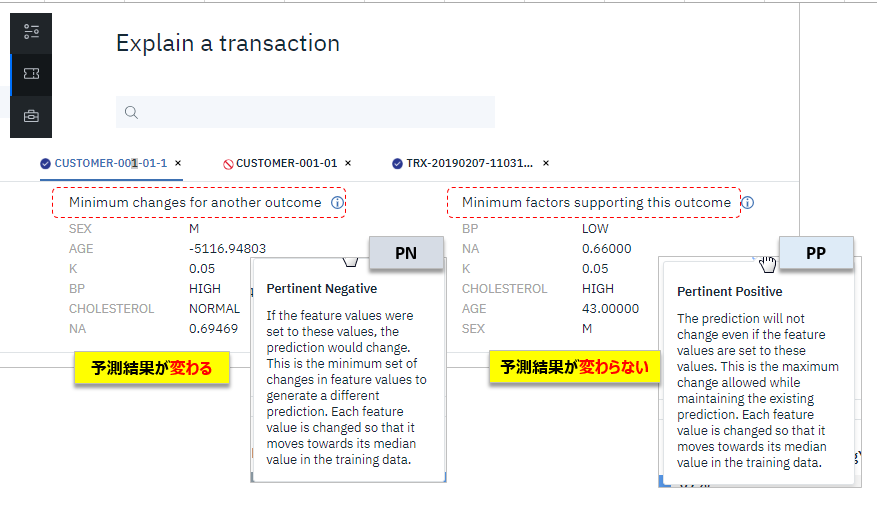
Explain Transactionの上部にはMinimum changes for another outcomeが表示されています。(横のInfoマークの上にカーソルを置くと説明のポップアップが出ます)この意味を簡単にご説明します。
-
Minimum changes for another outcome:(PN)
- モデルの判定結果を変えたいなら、これらの値に近づけるように値をセットするといいよ、という一式の値のセット。表示の順番は上から影響の強い順となっているので場合によって順番が違います。値は中央値なのでこれをそのままセットすれば一番結果が変わりやすくなる、ってことです。
-
Minimum factors supporting this outcome:(PP)
- 上記の逆で、モデルの判定結果を変えたくないなら、これらの値に近づけるように値をセットするといいよ、という一式の値のセット。
これらの値はアプリケーションが使うものではなくWatson OpenScaleが**モデルのDe-Bias(緩和)を行う際に使います。Watson OpenScaleはContrastive Analyticsという手法でこれらの値を導いていますが、このようにモデルの判定結果を変える(変えない)値を知っているからこそ、それらを駆使してモデルのDe-Bias(緩和)**ができるわけですネ。
![]() 「とにかく結果を操作したい」だけであれば、ここに表示されている値を単純に「とにかくこの値をそのままセットすれば結果が変わる(変わらない)よ」という意味で考えてしまっても良いのですが、より正確には「各特徴量の値をこの値の方向に近づけると、変わりやすく(or 変わらなやすく)なるよ」という考えるべきものです。(値を「点」で考えているのではなく、「線・方向」を持って考えているイメージ)
「とにかく結果を操作したい」だけであれば、ここに表示されている値を単純に「とにかくこの値をそのままセットすれば結果が変わる(変わらない)よ」という意味で考えてしまっても良いのですが、より正確には「各特徴量の値をこの値の方向に近づけると、変わりやすく(or 変わらなやすく)なるよ」という考えるべきものです。(値を「点」で考えているのではなく、「線・方向」を持って考えているイメージ)
下部の読み解き方
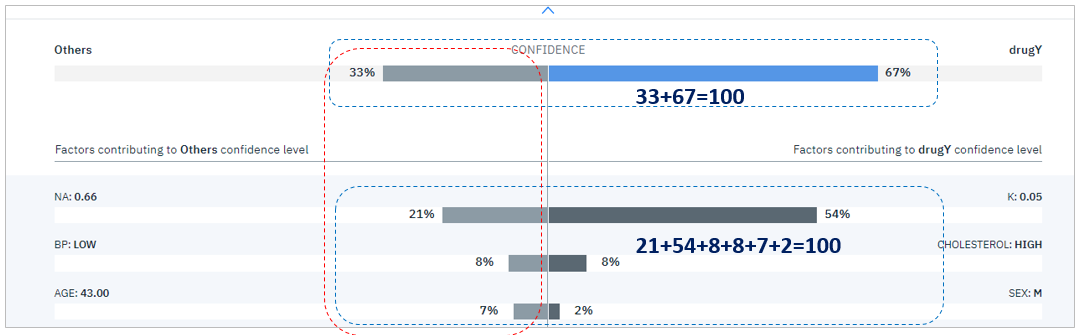
ここではLIMEを用いてモデルが特定の判断に至った要因が重要度と共に示されます。表示上は「Confidence」と「Factors contributing to ~」のセクションに分かれています。ここに記載されている%は各々の構成要素の比率であり、各々の中での合計は100%になります。(上記の青い枠)ただし「Confidence」の内訳が「Factors contributing to ~」であるわけでは**ありません。**両者は別々の方法で算出されていますので、「Factors contributing to ~」の%の合計が「Confidence」の%と一致するわけではありません。(上記の赤い枠)
ご参考) WMLのドキュメント
De-Bias エンドポイントの話はWMLをAPIで触ったことがある方以外には「ナンノコッチャ」と思われるでしょう(私も当初はそうでした)。このドキュメントのあたりにAPIの説明がありますのでご興味あればご参照ください。普段はWMLはWatson StudioのUI等を介して触っていることが多いと思いますが、実際は裏でAPIを呼んでいます。

以上です
-
Getting_StartedのTutorialではWMLのテスト機能で1件投げるシナリオになっています。
しかし振る舞い改善により、実際は投げなくても進めるようになってます。 ↩ -
WMLではスコアリングのために必要なデータ構造はメタデータから入手できるので、それを使ってテーブルを定義しているだろうと想像 ↩
-
ReleaseNoteによると2019/2/7のアップデートで明示的に「評価を今すぐ実行する」ボタンがつきました。 ↩
-
バイアス監視項目が「性別」「国籍」「人種」など複数個セットされていたら、それぞれのデータの「とりうる値」×監視項目の組み合わせ数は膨大になる可能性があり、それを逐一Pertubationしていたら実行時間がかかりすぎる恐れがあります。。この辺をうまくやるためにWatson_OpenScaleは様々な最適化を施していると聞いています。 ↩
-
この動きは開発部門でも課題は認識しており改善策・代替策を検討中とのことです ↩
-
WatsonStudioのウイザード等でデプロイした場合は自動的にメタデータが付与されます ↩
-
PayloadテーブルをSQLで直接検索する手はあるでしょうが、エンドユーザー向きではないでしょう。 ↩