
![]() (2019/2) AI OpenScaleはWatson OpenScaleに名前が変わりました
(2019/2) AI OpenScaleはWatson OpenScaleに名前が変わりました
 改定履歴
改定履歴
| 版 | 日付 | 変更内容 |
|---|---|---|
| 1.0 | 2019-01-23 | 初版公開 |
| 1.1 | 2019-04-23 | 「ならデータを含めなければ良い」という考えについて記載 |
はじめに
こんにちわ!石田です。昨年末に ![]() 記事「「AIへの信頼」や「説明可能なAI」に絡み、一部で話題の「IBM Watson OpenScale」をザクッとご紹介します 」を書きました。その後、何度かお客様にご紹介したのですが、(当方のご説明の仕方に問題があったのかもしれませんけれど)「とにかく使えばAIのフェアネスや説明可能性の問題はバッチリ解決できて、フェアで判断間違いが無いAIが手に入るんだよね?」的な「麗しき誤解」が生じるケースもありました。Watson OpenScaleはAIモデルの運用で非常に有用なツールですが、万能の「マジック」ではありませんので、できること・できないことをもうすこし細かくご説明したほうがよいな、麗しき誤解があれば解くべきだなと考えまして、上記「ザクッと」記事の「補足」として当記事を書きました。(当記事はWhat(できる・できない)にフォーカス。How(技術寄り)の話は記事
記事「「AIへの信頼」や「説明可能なAI」に絡み、一部で話題の「IBM Watson OpenScale」をザクッとご紹介します 」を書きました。その後、何度かお客様にご紹介したのですが、(当方のご説明の仕方に問題があったのかもしれませんけれど)「とにかく使えばAIのフェアネスや説明可能性の問題はバッチリ解決できて、フェアで判断間違いが無いAIが手に入るんだよね?」的な「麗しき誤解」が生じるケースもありました。Watson OpenScaleはAIモデルの運用で非常に有用なツールですが、万能の「マジック」ではありませんので、できること・できないことをもうすこし細かくご説明したほうがよいな、麗しき誤解があれば解くべきだなと考えまして、上記「ザクッと」記事の「補足」として当記事を書きました。(当記事はWhat(できる・できない)にフォーカス。How(技術寄り)の話は記事![]() 「Watson OpenScaleを触る前に知っておきたかったこと」に書きました)
「Watson OpenScaleを触る前に知っておきたかったこと」に書きました)
![]() 当記事は非公式なものであり、個人的な私見を含みます。
当記事は非公式なものであり、個人的な私見を含みます。
フェアネス(Fairness)
![]() フェアネス機能の簡単なご説明はこちらです。
フェアネス機能の簡単なご説明はこちらです。
AIOSでのフェアネスとは何か(意味/何を監視してるの?)

考え方・概念としては上の説明なのですが、抽象的な言葉でご説明すると、かえってわけがわからなくなりそうですので、具体的な例でご説明します。
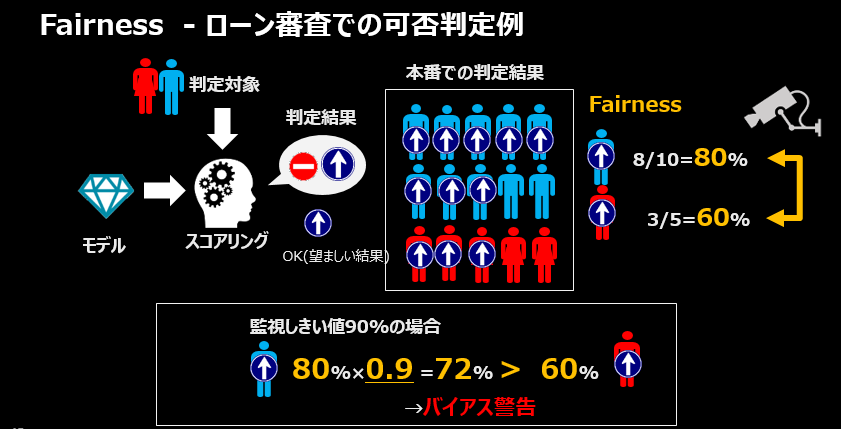
-
本番のローン審査業務において、ローン利用の可否(OK/NG)をAIモデルで判定するものとします
- 「好ましい結果(Favorable Outcome)」は「ローンが承認されること」です
- 「性別」の比較軸(フェアネス属性)で「男性/女性」の各グループによりモデルの判定結果が偏っていないか、公平になっているかを見ることにします。ここでは仮に「女性はローン審査で差別されているのではないか(マイノリティ)」との仮説を設け、「女性」の側から「男性グループの結果と比べてどうか」を見ることにします。この場合の「女性」は監視対象(Monitored)グループと呼び、対比される「男性」を参照(Reference)グループと呼びます。
-
直近の一時間で15人の審査をおこないました。
- 男性は10人中8人がローンOKになりました(80%がOK)
- 女性は5人中3人がローンOKになりました(60%がOK)
-
このモデルの判定傾向を「性別」の観点で見ると、男性より女性のほうがローンOKになる割合が低いようです。
-
本来、ローン審査のOK/NGの判定は申込者の性別によって結果が左右されるべきでしょうか。おそらく、そうではないでしょう。ローンの判定結果を性別の観点でみたら、いずれの性別にも偏らない=ローンOKの割合が男女で同じなのが理想的な姿です。
-
Watson OpenScaleでは本番でモデルのOK/NGの判定状況を監視します。監視しきい値を設定し、男女間での判定結果の違いが許容範囲を超えた場合に警告をします。
- 仮に監視しきい値を90%と設定した場合、「女性のローンOKの割合」が「男性のローンOKの 割合である80%×0.9=72%」以上であるなら、許容範囲なので警告しません。今の状況だと60%であり、基準の72%を下回っているのでバイアス警告の対象になります
つまり、Fairnessの監視とは、以下のことをしているだけです

![]() 厳密には上記のM1/M2などの件数は「アプリが実際に予測を実行した件数」だけでなく、内部的にペイロードを膨らませてPertubationとして実行した予測の結果の件数も含みます。
厳密には上記のM1/M2などの件数は「アプリが実際に予測を実行した件数」だけでなく、内部的にペイロードを膨らませてPertubationとして実行した予測の結果の件数も含みます。
- 比較軸(今は「性別」)において、監視対象グループ(今は「女性」)と参照グループ(今は「男性」)を分ける1
- 異なるグループ間(男性 vs 女性)で、望ましい結果(ローンOK)にどの程度違いがあるのか(バイアスがどの程度か)
- 上記を本番環境で定常的に監視し、一時間単位で許容範囲を超えた違いがあればダッシュボード上に警告する
- この辺は
 ドキュメント Understanding Fairnessにもうすこし詳しい説明があります
ドキュメント Understanding Fairnessにもうすこし詳しい説明があります
Watson OpenScaleが社会的な「公正」や「偏見」の観念を理解しているわけではありません
フェアネス(Fairness)とかバイアス(Bias)って、大きくは2つの意味解釈がありえます。
| フェアネス(Fairness) | バイアス(Bias) | |
|---|---|---|
| 統計 | 釣り合っている感じ | グループ間での分布の偏り |
| 社会正義 | 公平/差別が無い | (差別などの)偏見 |
Watson OpenScaleでの「フェアネス」や「バイアス」は主に上段の統計的な意味合いで使っています。統計的なフェアネスを監視すれば、結果的に下段の「偏見に基づく判定結果での差別」の是正・緩和に結びつく2でしょうが、Watson OpenScale自体が「差別をなくそう!」などの「社会正義・倫理」的な意図を持って何らかの価値判断や推奨をするわけではありません。
よって下記のようなことは、 「できません」
「できません」
Watson OpenScaleを使えば
- 作ったモデルに偏見が無く、社会道義的にフェア(公正)に振舞っていることを判断・保証してくれる
- どのデータに「(社会的)偏見」が混じっているかを教えてくれる
- 何もせずともモデルの振る舞いから「(社会的)偏見」が取り除かれ、公明正大なものになる
Watson OpenScaleでは業務的に見てモデルにどんなバイアスが生じる懸念があるか(=監視しておくべき視点・データは何か)を考えて設定するのは人間(利用者)の役割ですし、業務の文脈により監視すべき内容は異なります。Watson OpenScaleは特定の倫理観に基づいた価値の判断はしません(=できません)
Watson OpenScaleのFairness監視とは、業務面で(本来はあるべきでない)判断の偏りが懸念される項目がある場合に、利用者がそれらを事前に設定しておくと監視・警告(&緩和)してくれる仕組みです。
それって単なる集計BIじゃないの?
ある意味、仰るとおり、です。単にモデルの判定結果(ローンOK/NG)を一定周期で特定の軸(性別)で集計してグラフにしてダッシュボードで見せるだけ、ならBI的なもので十分かと思います。ではWatson OpenScaleは何が価値なのでしょうか。3 それは「迅速にバイアスの緩和ができる(De-Bias)」点だと思います。
仮にBI的な機能を使って本番で「偏り」を検知する仕組みをつくったとします。そして、モデルの判定結果が女性に不利な方向に偏っていることを検知したら、どう対応することになるでしょうか。おそらく、警告を知った運用部からデータサイエンティストに連絡が行き、専門家は状況を調べた上でデータを変えたりモデルのパラメータを調整したり、様々なバイアス低減のツールを使ったりして、モデルの補正に努めるでしょう。そして満足のいく結果が出れば、改めて本番にモデルをデプロイすることになります。このアプローチには以下の課題があります。
- モデルのバイアスを緩和するまでのサイクル/リードタイムがかかりすぎる
- バイアスの緩和は専門家の高度なスキルやノウハウがないと対応できない(=- 単に本番の最新データでモデルを洗い替えればいい、ってもんではない)
Watson OpenScaleはスコアリング要求を裏でキャプチャーして周期的にペイロードを記録・分析しています。結果、モデルの振る舞い=判断の結果を変える為の入力データ(特徴量)の値を知っており、モデルのバイアスを改善するための新しいスコアリング・エンドポイントを提供できます。アプリが新しいエンドポイントを呼び出せば、自動的にバイアスを緩和する方向にモデルを誘導することができます。4
![]() Watson OpenScaleのDe-Bias機能のご紹介はこちらを
Watson OpenScaleのDe-Bias機能のご紹介はこちらを
「本来偏るべきでないものが(意図せず)偏ってる」状態が問題
基本的には「個人の属性(デモグラフィック)」に関するものがバイアス監視の候補になりうる
Fairnessで監視するべき点は、本来は判断・判定に影響を与えるべきでないデータ5が(無意識・意図せずに)判断に影響を与えてしまっているような状態です。たとえばローン審査でいえば、トレーニング・データに性別・国籍・人種・学歴・出身地・居住エリア・病歴・嗜好などが含まれていた場合、それらはおそらく一般的には「お金を貸すか、貸さないか」というローン審査の結果に影響を与えるべきではないデータ項目といえる6でしょう。でも、それらをモデルへの入力とした以上、各項目が判断結果にどの程度影響を与えているのか、与えていないのか、を可視化・理解しておく必要があるでしょう。そういう意味で、フェアネスで監視すべきデータは多くの場合、個人の属性(デモグラフィック)データ、といってもよいかもしれません。
何を監視すべきかは業務の文脈次第
ではローン審査での「収入」はどうでしょうか。多くの民間金融機関では「収入が低い人は返済リスクが高い」と考えるはずです。よって「収入」はローン審査業務での基本的な評価基準であり、「判断・判定に影響を与える」のは当然です。つまり、「収入レベル」で見た場合に、「収入が低い人はローンNG」「収入が高い人はローンOK」のように結果が偏るのは仕方ないことのように思われ、よってこのようなケースで「収入による判定結果の偏り」の「監視」「緩和」を試みるのは意味が無いように思われます。(仮にWatson OpenScaleの機能を使って「収入の低い人でもローンOKにする」方向でモデルの振る舞いを緩和したら、審査がザルになって破綻してしまいますよね.. )
では同じローンの審査でも公共の自治体が社会的弱者の救済などの目的で行う事業の場合はどうでしょう。その場合は「収入」が低い人にこそ積極的に救済措置を適用すべきであり、「収入」軸で目指す方向に偏りが保たれているかどうか(「収入の低い方に、重点的にローンOKが出るよう動いているか」)を監視する意味があるように思われます。
要は(当然ですが)「どのデータ項目を監視すべきか」は一律でいえるものではなく、業務の目標や意図の文脈で個別に考えるべき、ということです。
(2019/04/23)  そんなに面倒なら、モデルを作るときにそのデータを使わなければいいのでは?
そんなに面倒なら、モデルを作るときにそのデータを使わなければいいのでは?
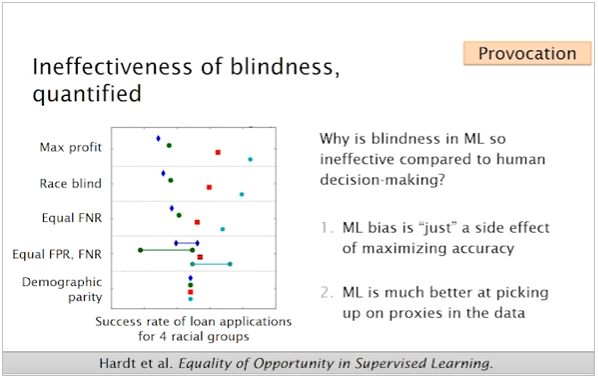
着眼点としては一理あるのですが、データサイエンスの世界では一般的にはあまりおススメではないようです。下記 AI Fairness 360のYouTube説明動画の9:01~で説明していますが、要は「ある特徴量だけ除去しても、代理(Proxy)データによる影響まで完全に除去するのは難しい」ってことで、たとえばモデルの教師データから人種フィールドを除いても、郵便番号や住所が特定の人種の多い地域を示していたりする、ってことを考えるとモデル構築時に「除去」するのではなく「是正・補正」すべき、と言ってます。(AIF360はモデル構築時のバイアス発見・補正ツールキットです。)
![]() 下記イメージをクリックするとYouTubeに飛びます
下記イメージをクリックするとYouTubeに飛びます

以下はご参考だけですが、こんな解説もありました。(「そのデータを無視してしまうこと」をblindnessっていうんですね。知りませんでした) こちらもYouTubeに飛びます。
![]() Tutorial: 21 fairness definitions and their politics
Tutorial: 21 fairness definitions and their politics
事実・実績データ =>バイアス緩和・是正の「必要性」・「可否」?
仮に「過去61ケ月の売上実績から将来の売上を予測する回帰モデル」のような「実績や観測した事実だけから作った予測モデル」を考えてみます。一連の事実からなるトレーニング・データから予測モデルを作っている以上、入力となるトレーニング・データ群の中には「季節変動」や「イベント効果」など、「予測・判定の対象」である「売上」に対しての「偏り」は当然あるでしょう。でも、これらって過去の事実ですから「緩和」できませんし、緩和する意味もありません。 「うーん毎年、12月の売上は他の月より多いなあ」とわかっても、だから何かすべきか、というと何もありません。仮に過去の事実を緩和=捻じ曲げて予測売上=結果を変えたとしても、得るものがありません。数値に代表されるような測定結果や事実データは偏りがあったにせよ「本来は判断・判定に影響を与えるべきでないデータが(無意識・意図せずに)判断に影響を与えてしまっているような状態」とは言えませんので、Watson OpenScaleのFairnessの監視対象としては不適かと思います。
精度(Accuracy)
![]() 精度(Accuracy)機能の簡単なご説明はこちらです。
精度(Accuracy)機能の簡単なご説明はこちらです。
AIOSでの精度(Accuracy)とは具体的に何のことか
マニュアルに記載がありますが、普通の統計解析で使う意味の「精度」(予測のあたる度合い)です。
| 手法 | 評価方法 |
|---|---|
| 複数クラス分類(Multi-Class Classification) | Accuracy = TP/(TP+FP) |
| 二値分類(Binary Classification) | Area Under ROC Curve |
| 回帰(Regression) | 決定係数(Coefficient of Determination (R2)) |
評価のためのデータはキャプチャーしたPayloadではなく、FeedBackデータ(通常は本番データ)を別に与えます。本番のモデル(開発環境でトレーニング・データを使って作られたモデル)に対してFeedBackデータを投入して、精度を評価します。(FeedBackデータの説明変数群をモデルに投入した結果と、正解としての目的変数を比べることでどの程度「当たってるか」=精度を算出する)
Watson OpenScaleはモデルの品質低下があったら通知するだけです。判断の誤りを無くす/自動的に精度を改善するものではありません
前述のとおり、Watson OpenScaleでのAccuracyの監視は「モデルを本番利用してるなら普通にやってること(やるべきこと)」を自動化したもの、と言えます。
- モデルの精度を改善する際に、Watson Studio/WMLの継続的学習システムを使って、よりフレッシュなデータで再度トレーニングするようなプロセスを自動化する=作業の効率化は可能ですが、高度化=「どういうトレーニングをすれば、もっと精度が上がるのか」をガイドしてくれるわけではありません。
よって下記のようなことは、「できません」
Watson OpenScaleを使えば
- モデルの判断間違い(=FP/FN7)が無くなり or 減り、精度が上がる
- モデルの判断結果に間違いが無いことを「保証」「担保」してくれる
- モデルの精度が自動的に高く保たれる
- モデル判断の無謬性をIBMが保証する
説明可能性(Explain)
![]() Explain機能の簡単なご説明はこちらです。
Explain機能の簡単なご説明はこちらです。
「説明」は何を説明してくれるのか

AIモデルの「説明」には大きく2種類あります。
- 「私のローン申し込みが拒否されたのはなぜ?」という問いに答える=個別の予測の根拠・道筋を説明するもの
- 「どのデータをどう変えたらローンNGという判断がOKに変わるのか8」というモデル全体の判断・振る舞いを提示するもの
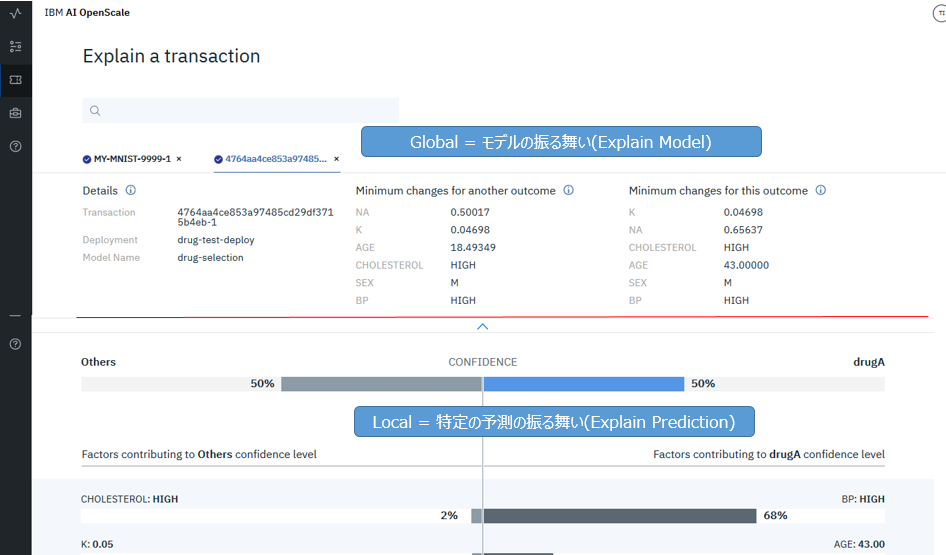
Watson OpenScaleのExplain Transactionパネルでは上記のように両方を提供します。
使っているアルゴリズムはLocal(下段の個別予測の説明)はLIME、Global(上段のモデルの振る舞い)はContrastive Explanationという独自の手法を使っていると聞いています。
モデルの振る舞いの説明(Explain Model)
当機能はモデルの振る舞い・判定を維持または変える値のセットを示してくれますが、「では、モデルをどう直せば精度が上がるか」などは教えてくれません。ましてや「自動的に誤りを直す」ことはできません。
個々の予測の説明(Explain Prediction)
結果として正解(TP/TN)か誤り(FP/FN)かにかかわらず、あるデータをモデルに投入したらこういう判定に至った、その理由・根拠・影響要因はこう、ということは示しますが、「正解(TP/TN)だったか、誤り(FP/FN)だったか」は、ツール上からはわかりません。9
イメージの説明は事前に評価を
以下はおまけです。
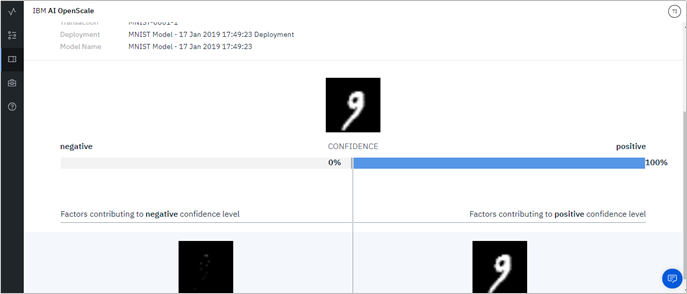
イメージExplainの入門編のつもりでKerasでMNISTのイメージの説明をしてみました。自分的には手書き文字で「このあたりの角の具合から9と判断しているよ」とか出てくれるのかと思っていたのですが、実際は上記のように「そのまんま」で、何の説明にもなってませんでした。。(orx) イメージの分類は単なるラベル付けだけではなく、イメージ中の複数のオブジェクトを位置と共に検出するものなど色々あります。「向き・不向き」があるようなので事前にご評価をおススメします。
![]() (2019/3/27 追記) MNISTはイメージのサイズが小さすぎて差異を検出しづらいことが原因だったようです。もう少し大きいサイズのイメージでやってみるようオススメされました。(まだやってませんが)一応書いておきます。
(2019/3/27 追記) MNISTはイメージのサイズが小さすぎて差異を検出しづらいことが原因だったようです。もう少し大きいサイズのイメージでやってみるようオススメされました。(まだやってませんが)一応書いておきます。
以上です。
-
当然ながらどちらからどちらを見るか、であって定義が逆でも良い。まあ基本的には注意を払って意識的に監視しておくべきグループ=「少数派(マイノリティ)」をMonitored_Groupにするでしょうけど。 ↩
-
「偏見」はモデルを作る際のトレーニング・データに埋め込まれており、トレーニングデータとは過去の「判断」の積み重ねです。例えば過去、採用活動など何らかの業務において「男性偏重」の判断をしてきたなら、それを反映したトレーニングデータは「男性偏重」となり、結果的にモデルも自然に「男性偏重」になるでしょう。これらは過去のトレンドの延長で将来を予測・判断する以上、避けがたいことかとも思います。 ↩
-
すでに製品があるのに、わざわざ同じような機能を一から手組みするのか=車輪の再発明をするのか、という議論は置いておきます。 ↩
-
このアプローチは、モデルの評価/再トレーニングを完全に代替するものではありません。長期的には専門家がモデルのバイアスを見直したり、精度維持のための再トレーニングを行う必要はあると思います。 ↩
-
そこまで明確でなくても「この切り口でAIの判定状況を監視・可視化しておいたほうがいいな」と思うような、気になるデータ項目、程度の決め方でもいいのかもしれませんが ↩
-
もちろん、ローンの性質やビジネス/慣習上のポリシーによります。米国では雇用・住宅・ローンの領域において差別的な扱いをすることは法律で禁止されています。 ↩
-
FP=False_Positive/FN=False_Negative ↩
-
Minimum_changes_for_Approved_outcome=この値にしたらモデルの判断が変わる、Minimum_changes_for_this_outcome=この値ならモデルの判断は変わらない ↩
-
「正解データ=説明変数と目的変数」を持っていれば、モデルへ説明変数を入力して得られた判定結果と手で比較することはできるでしょう ↩