
はじめに
(記事執筆時点 2018/03/26) 先週、ラスベガスで開催されたIBMのイベント Think 2018で「Watson Studio」ってのが発表されました。世間的に一番注目されるのは「ディープ・ラーニング」でしょうが、Watson Studioは他にもいろんな要素がいっぱい詰まっていて、全容を理解するのが難しいような気がしたので、自分なりに整理してザクッとご紹介してみます。
要は何が変わったの? ~1分で説明する
「Watson Studio」は突然公開された「真新しいサービス」というわけではなく、従来「Watson Data Platform」の冠の下で提供されてきた「DSX」「WML」などのデータ・サイエンス系のサービス群を発展的に整理統合・機能拡張したものです。従来のサービス群は今回、以下のように強化・再編されました。
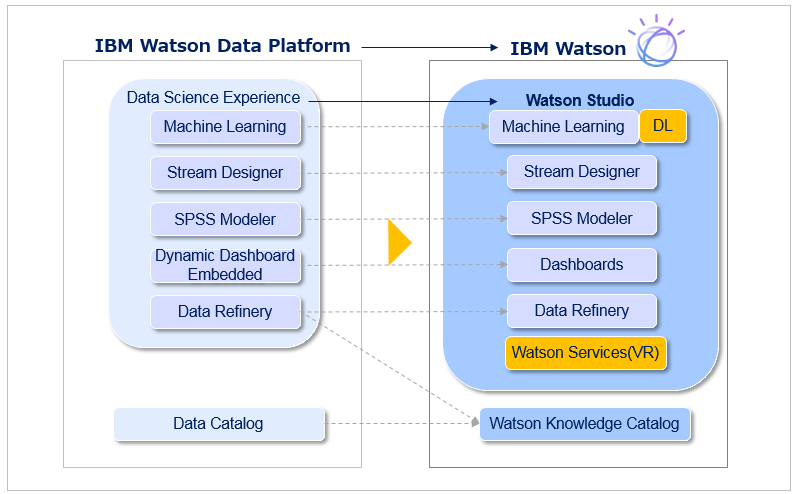
一言で申せば「AIのプラットフォームとして、ディープ・ラーニングやWatsonとの連携を今後さらに進めていきますよ~」ということかと思います。
- 従来の冠(総称)である「Watson Data Platform」は「IBM Watson」に統合されました
- 「DSX」は「Watson Studio」に名称が変わり、従来の「データサイエンス・チームのためのプラットフォーム」が「AI/Watson/ディープ・ラーニングのプラットフォーム」に拡張されました
- 「Machine Learning」にディープ・ラーニングの機能が加わりました
- 「Data Refinery」は単独のサービスではなくなり、「機能」として統合されます
- Watson Studioで様々なWatson APIを使いやすくするUIが提供されます。第一弾としてVisual Recognitionが追加されています
- 「Data Catalog」は「Watson Knowledge Catalog」に名称が変わります
![]() Watson Studioを始め、上記はすでにIBM Cloud上で利用可能です。無料のライト・アカウントでも使えます。上記の名称変更・再編に伴い、カタログのアイコンが新しいものに変更になっていますのでご注意ください。
Watson Studioを始め、上記はすでにIBM Cloud上で利用可能です。無料のライト・アカウントでも使えます。上記の名称変更・再編に伴い、カタログのアイコンが新しいものに変更になっていますのでご注意ください。
![]() 1分終了です。
1分終了です。
ここからはもう少し詳しくご紹介しますので、お時間あればお読みください。
Watson Studioの全体図
以下がWatson Studioの全体図です(日本語に翻訳)

- ①はソリューションやアプリケーションの層ですが、英語の世界の話で日本語はまだ先だと思うので今はスルーします。
- ②のWatson Studioが③のWatson APIを包含しているのは全体で1つのプラットフォームである、との主張でしょうか。実際、今まではWatson API群とWatson Data Platformのサービス群はブランディングとして「Watson」という名前は共通していましたが、「しくみ」面では殆ど関係ないものでした。今後は1つの統合された=使いやすい AIプラットフォームとして育てていくよ、という方向性を示したものと理解しています。
- ④は今までのDSXの領域、⑤は今までのWMLの領域ですね
- ⑥も従来のData Calalog=データガバナンスの領域です。⑥で目新しいものに「Data Kits」というのがあります。これは様々な業界別に事前に整理されたデータのAPI群です。例えば「Watson Data Kit for food menus」は全米21,000の都市の70万のレストランのメニューのデータをAPIでご提供します。(っても、こちらも英語の世界なので当面はスルー、ですが)
- まとめると、大きくは②Watson Studioと⑥Watson Knowledge Catalogの二本柱で進めていく、という感じでしょうか。
Watson Studioのコンセプト
従来のサービスをご存知の方には釈迦に説法でしょうが、初めての方向けに簡単にご紹介します。
- よく「データサイエンティストに求められるスキル」として①業務の知識 ②統計解析の知識 ③ITの知識が挙げられます。とはいえ、この3つをすべて兼ね備えた「スーパーマン」のような人材はそう多くはありません。
- 「AI」という言葉が一般化し、企業がデジタル・イノベーションの手段としてのAI/データサイエンスの可能性に注目するにつれ、AIプロジェクトの数とサイズは飛躍的に増加しています。
- そのような背景で、昨今、AI(≒データサイエンス) プロジェクトは以下のように様々な役割のメンバーからなるチームで推進される「チーム・スポーツ」にならざるを得ません。

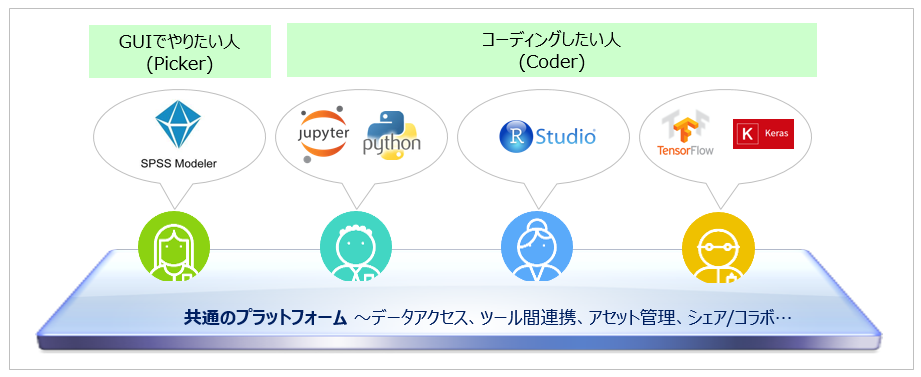
「Watson Studio」はAIプロジェクト・チームの生産性を向上するプラットフォームとして、以下のアプローチを取っています。
① プロジェクトの全ライフサイクルを1つのプラットフォーム上でサポート
② オープンなプログラミング言語/フレームワークを積極的に採用
③ 役割毎に様々なツールの選択肢を用意し、各人は好みのツールを使用可能
④ ツール間連携、成果物/アセットのシェアなどチームのコラボを促進
⑤ 上記一式をクラウド上のサービスとして迅速に提供
要は下記の絵のように、各人はお好みのツールを使いながらも、全体は1つの共通プラットフォーム上でコラボしてプロジェクトを進める感じです。
![]() (2018/7/28追記) Watson Studioのチーム機能って例えばどんなもの?という紹介記事をこちらに書きましたのでよろしければご参照ください。
(2018/7/28追記) Watson Studioのチーム機能って例えばどんなもの?という紹介記事をこちらに書きましたのでよろしければご参照ください。
で、どんなことができるのか?
以下はWatson Studioにログイン直後の画面に表示されるメニューです。このメニューに沿って、「できること」をザクッと簡単にご紹介していきます。

![]() Watson Studioの元になったDSXについてこの記事でご紹介しています
Watson Studioの元になったDSXについてこの記事でご紹介しています
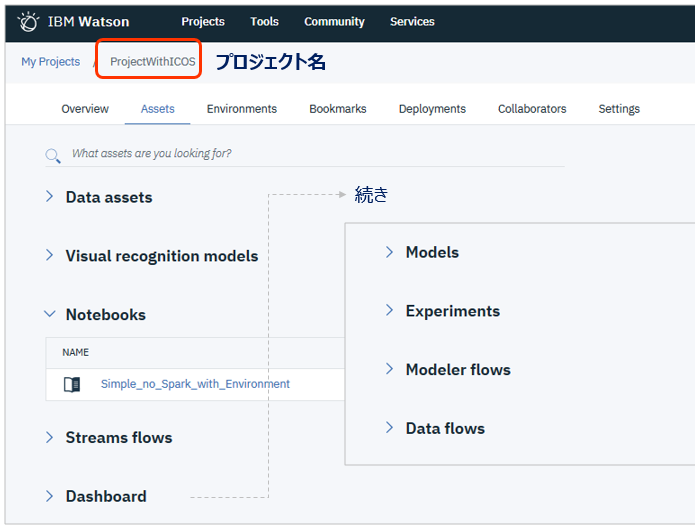
Project(プロジェクト)
Watson Studioでは「プロジェクト」という枠組みでデータサイエンス・チームが分析や開発で使うデータや機械学習モデル、プログラムなどを管理できます。(旧DSXの機能と同じです)
- 「プロジェクト」の下に、様々な分析アセットを格納・管理します
Refine Data(データの準備)
四則演算、フィルタリング、集約、ジョイン等様々な加工・補正が行えます。
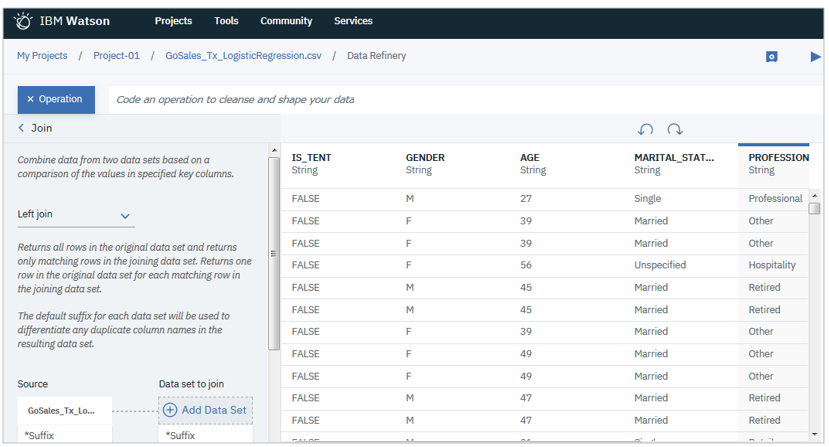
データの品質を確認し、傾向を理解するための可視化もできます。
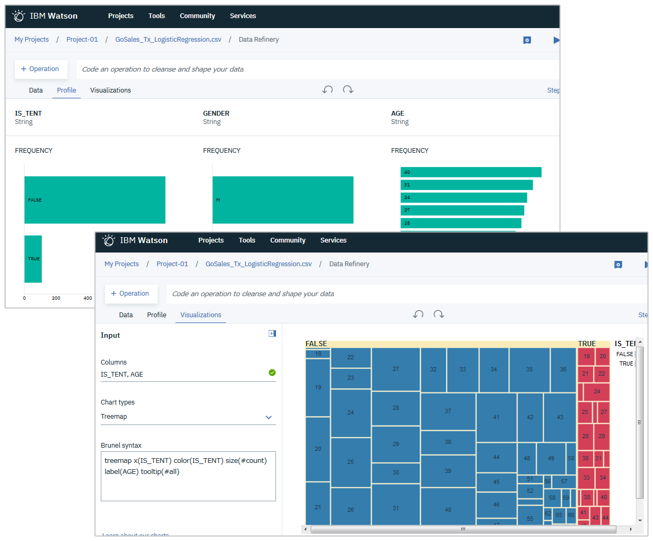
![]() (2018/6/14追記) Data Refineryの紹介記事をこちらに書きましたのでよろしければご参照ください。
(2018/6/14追記) Data Refineryの紹介記事をこちらに書きましたのでよろしければご参照ください。
Notebook
おなじみのJupyter Notebookが使えます。
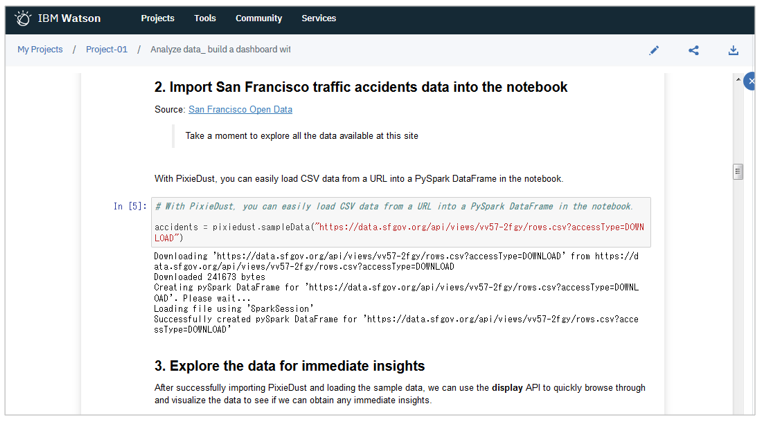
標準で以下のフレームワークをサポートしています。詳しくはSupported Frameworksを。下記以外をご自身でインストールすることも、もちろんできます。

Rがお好きな方はR Studioでどうぞ。
Deep Learning(ディープ・ラーニング)
ここで言う「ディープ・ラーニング」とは、機械学習の一手法である「ニューラル・ネットワーク」のことです。従来もDSXのJupyter Notebook上でTensorFlowやKerasを自分でインストールしてプログラムからAPIをたたいて動かすことは可能でしたが、今回はDeep learning as a Service(DLaaS)として、ニューラルネットワークのモデル作成~トレーニング~デプロイをサポートする新たな機能が追加されています。(2018/04/14追記) 詳しくはWatson Studioのディープラーニング機能(DLaaS)を使ってみたの記事をご参照ください。
ニューラル・ネットワーク・モデルの開発の流れ
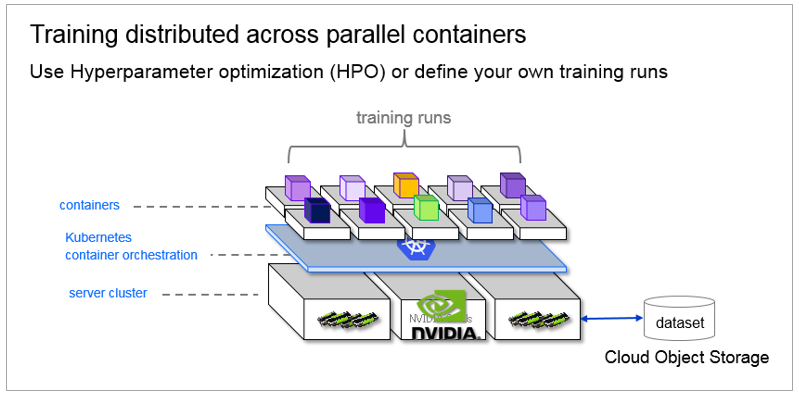
通常、ニューラル・ネットワーク(NN)でのモデル構築では最適な出力を得るため(=最適な特徴量を探すため)にパラメーターの組み合わせを変えて何度も(時には数百・数千回も)トレーニングを実行します。結果、手作業でのトレーニング実行が煩雑であったり、トレーニングの実行時間が数日に及ぶこともあります。Watson Studioではトレーニングの自動実行やGPUの利用&トレーニングの並列実行により、NNのモデル開発を楽に/速く行えます。
Watson StudioでのDLaaS機能
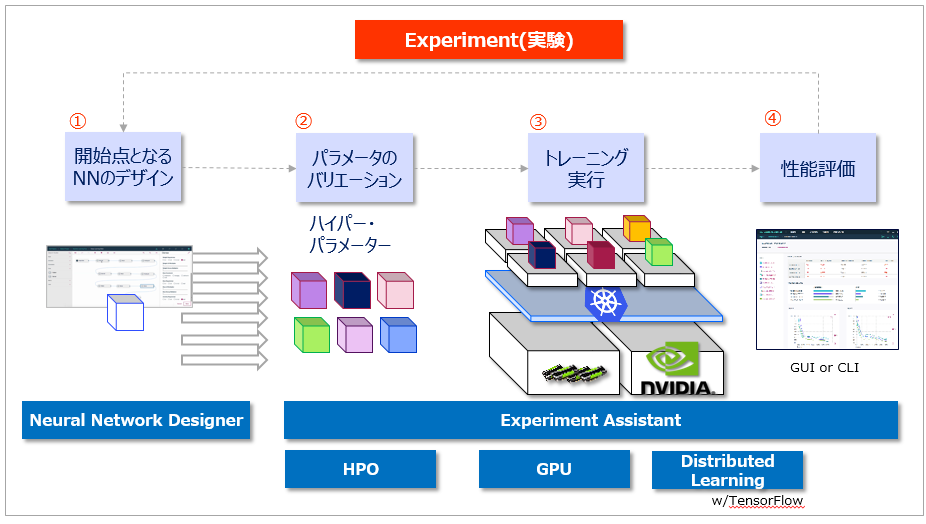
以下が大きな流れです。
![]() 下記のフレームワークをサポートしています。細かい仕様はこちら
下記のフレームワークをサポートしています。細かい仕様はこちら

①ニューラル・ネットワークのデザイン
「Neural Network Designer」を使って、コーディングせずにベースとなるニューラルネットワークのモデルが作れます。
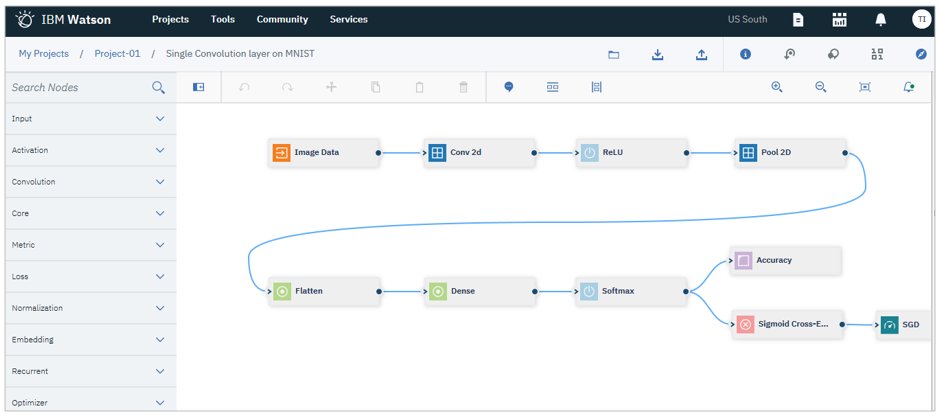
(Neural Network Designerを使わず、コードで対応することも可能です)
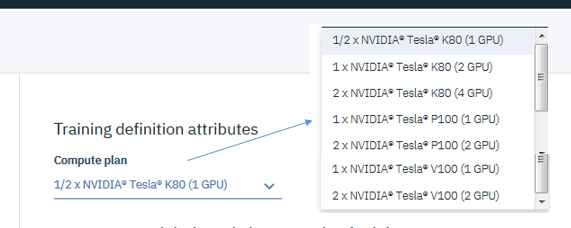
②パラメーターのバリエーション
②~④は「 Experiment Assistant 」が様々な機能を提供します。
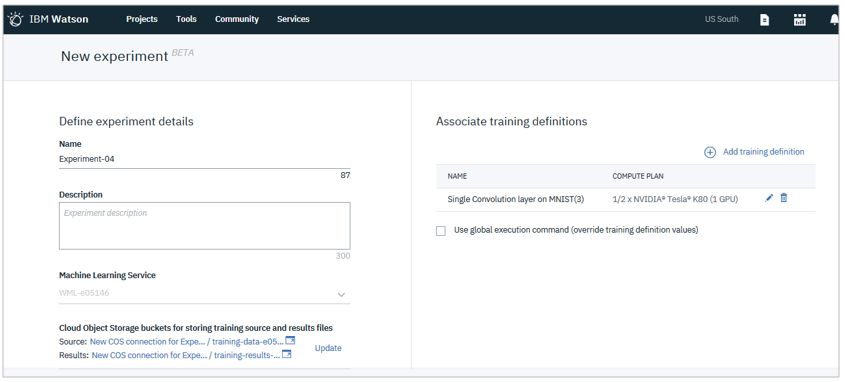
①の結果は「Training Definition」としてデプロイされます。Experiment Assistantでは「Training Definition」を入力にしてモデルのパラメーターの組み合わせを様々に変化させて最適な性能のモデルを作り出すHPO(ハイパー・パラメーター最適化)機能が搭載されていますので、手作業でのパラメーター調整をトライ&エラーで行う必要がありません。(HPOを使わず、ご自身で調整することも可能です)
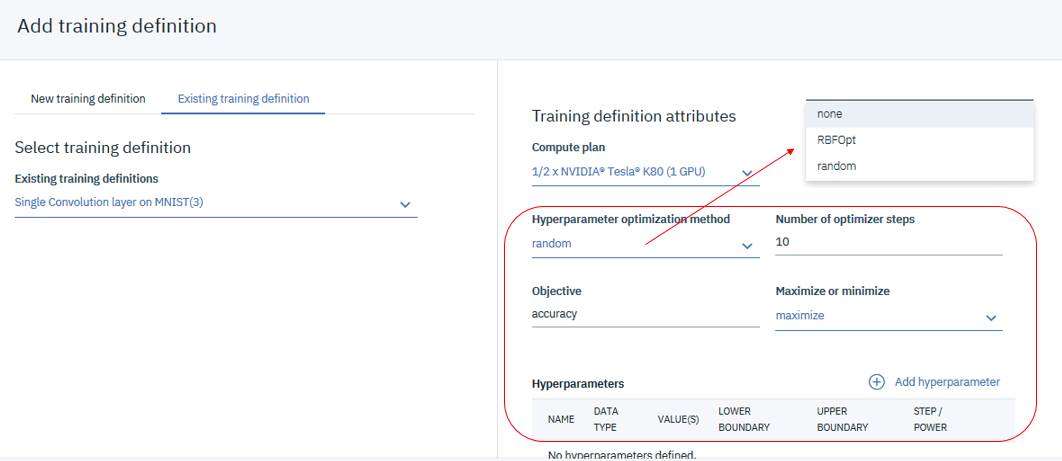
③トレーニングの実行
![]() NVIDIAのGPUをオンデマンドで利用できます。実際にモデル構築などでGPUを使っている時間だけに課金され、データを整備している間などは課金されませんので、お得です。
NVIDIAのGPUをオンデマンドで利用できます。実際にモデル構築などでGPUを使っている時間だけに課金され、データを整備している間などは課金されませんので、お得です。
![]() 一台のマシンのGPUでは能力が不足な場合、Kubernetesクラスター環境で並列にトレーニングを実行することも可能です.(現時点ではTensorFlowのみ)
一台のマシンのGPUでは能力が不足な場合、Kubernetesクラスター環境で並列にトレーニングを実行することも可能です.(現時点ではTensorFlowのみ)
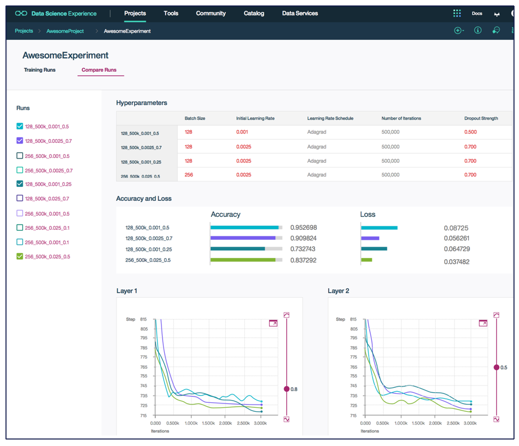
④性能の評価
トレーニングの進行状況の表示、多数のトレーニングの結果の性能比較などをブラウザー上のUIで参照できます。もう実行ログから数字を拾う必要はありません。
以下のMediumの記事も参考になります。
Accelerate Your Deep Learning Experiments with IBM’s Neural Network Modeler
Deep Learning as a service now in IBM Watson Studio
性能が満足いくものであれば、本番に反映です。作ったモデルはMachine Learning上のUIを使って、簡単に本番へデプロイできます。(APIでプログラム的にデプロイすることも可能)
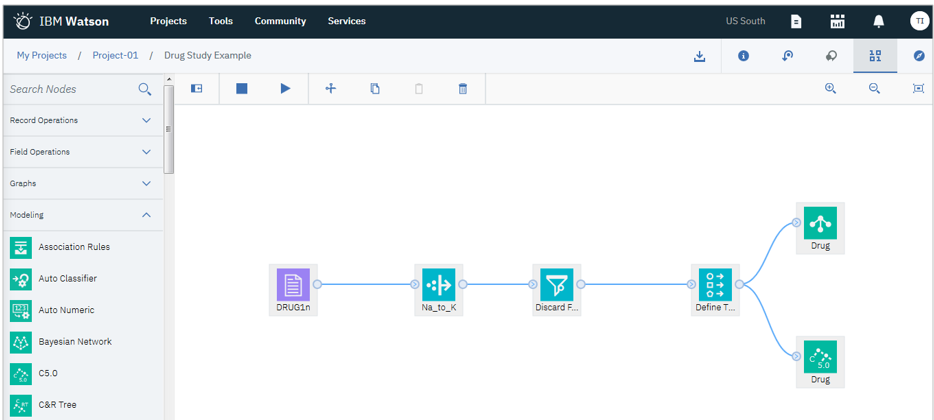
Modeler Flow( モデラー・フロー )
SPSS Modelerがブラウザー上での新しいUIを伴ってWatson Studio上で利用できます。
- 現時点ではPC版のアイコンが全部移植されているわけではありません(6-7割の感じでしょうか)
- PC版のSPSS Modelerのストリーム・ファイル(*.str)をアップロードして利用できます。(逆方向も可)
Model( モデル )
Watson Machine Learingサービスの扱う領域です。機械学習モデルの構築~性能評価~本番デプロイ~監視~再構築のフルサイクル=「継続的な学習」を自動できます。(下記赤い枠がMachine Learningの担当部分)

![]() WMLについてはこの記事でご紹介しています
WMLについてはこの記事でご紹介しています
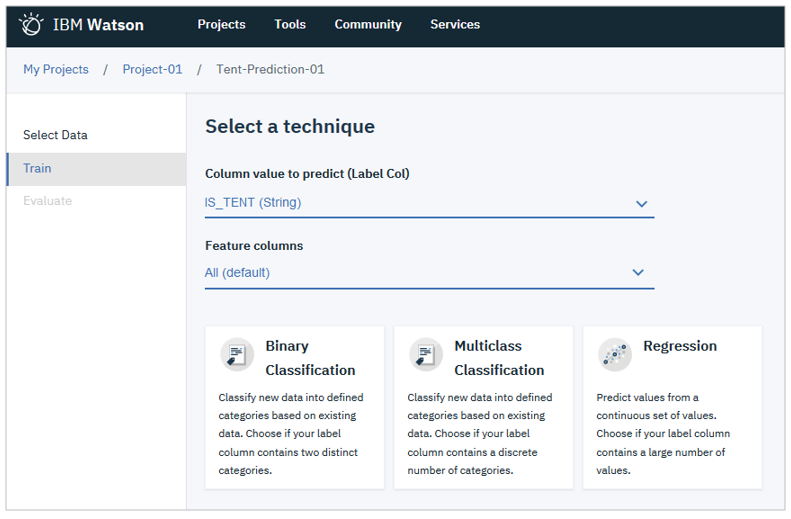
AIモデルの構築とトレーニング
![]() コーディングせずとも、予測モデル(教師あり=分類と回帰)をウイザードで簡単に作ることができます。「予測したいフィールド」と「入力フィールド」を指定するだけです。
コーディングせずとも、予測モデル(教師あり=分類と回帰)をウイザードで簡単に作ることができます。「予測したいフィールド」と「入力フィールド」を指定するだけです。
- データは自動的に「モデル構築用」「評価用」「テスト用」に分割します
![]() トレーニング後のモデル性能も見られます
トレーニング後のモデル性能も見られます
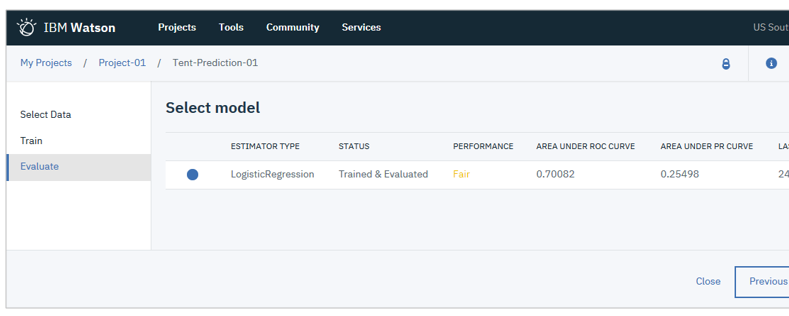
AIモデルのデプロイ
作成したモデルの本番環境へのデプロイもウイザードで簡単に行えます
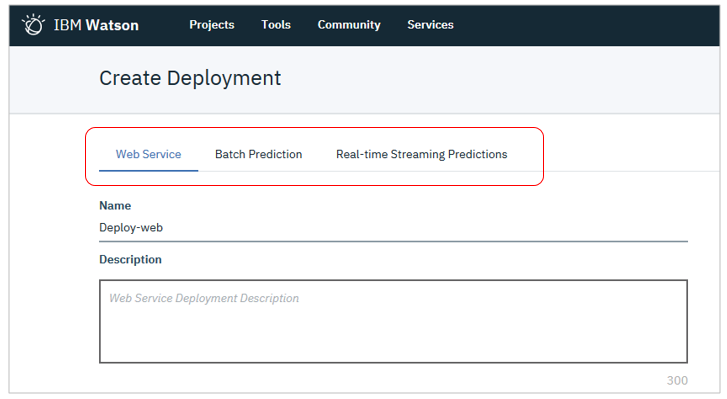
![]() 実行モードは ①オンライン ②バッチ ③ストリーミングから選べます
実行モードは ①オンライン ②バッチ ③ストリーミングから選べます
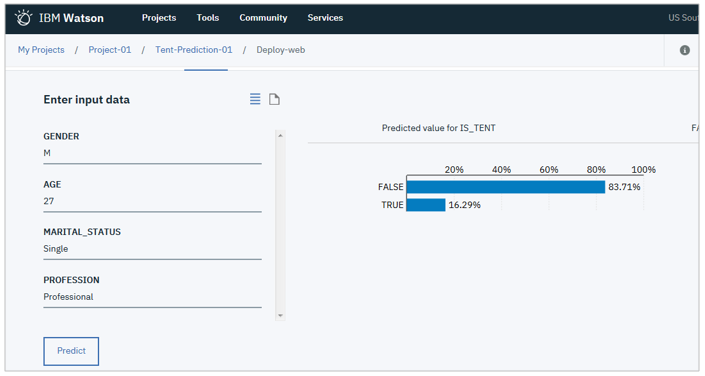
![]() デプロイ後のモデルのテストも行えます
デプロイ後のモデルのテストも行えます
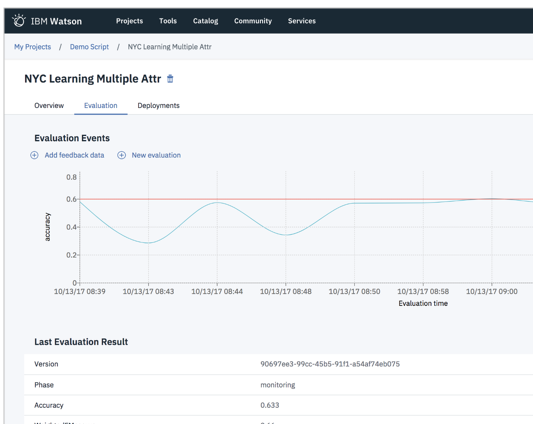
モニター、分析、管理
継続的な本番運用で必要な以下の項目も自動化できます
- 本番での性能モニター
- モデル性能が劣化した場合のモデルの再構築
- 再構築したモデルの自動デプロイ
下記は時系列で本番のモデル性能をモニターしている様子です
![]() WMLの「継続的学習システム」についてはこの記事でご紹介しています
WMLの「継続的学習システム」についてはこの記事でご紹介しています
Streams Flow ( ストリーム・フロー )
IoTのユースケースで、刻一刻と流れてくる大量のストリーミング・データをリアルタイムで分析することもできます。Stream Designerを使えばプログラミングも不要です。
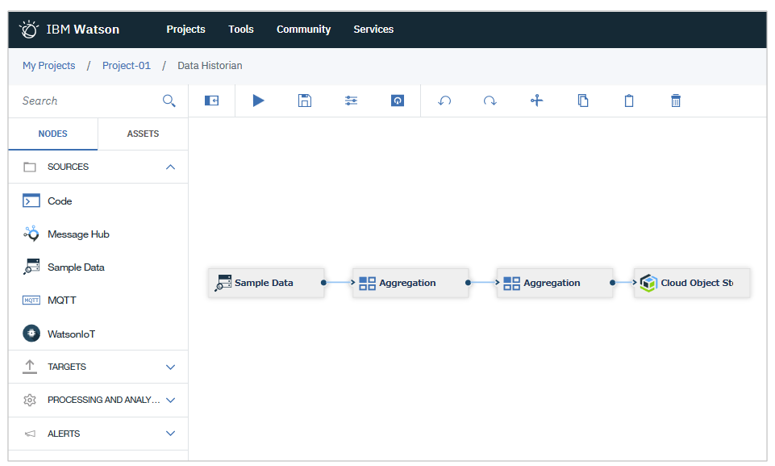
ここまでは基本的なメニューを順番にご紹介してきましたが、他にも以下のようなことができます。
Watson APIとの統合
Watson API向けのUIを提供します。第一弾として、画像認識のサービスであるVisual Recognition API向けのUIが提供されており、カスタマイズした画像の判定/識別モデルを作成できます。2018/08/10にはNLUも正式リリースしました。今後、いろいろな機能が追加されていくのでしょう。
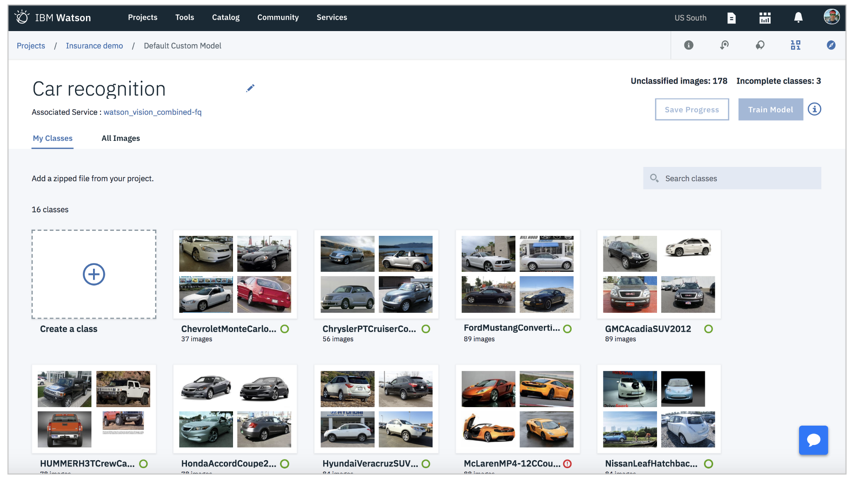
- カスタマイズの可否はWatson API側の機能に依存する話だと思うので、Watson StudioはメニューやUIを統合することで「Watsonを使いやすくする」ことに注力するのかな~、と想像しています
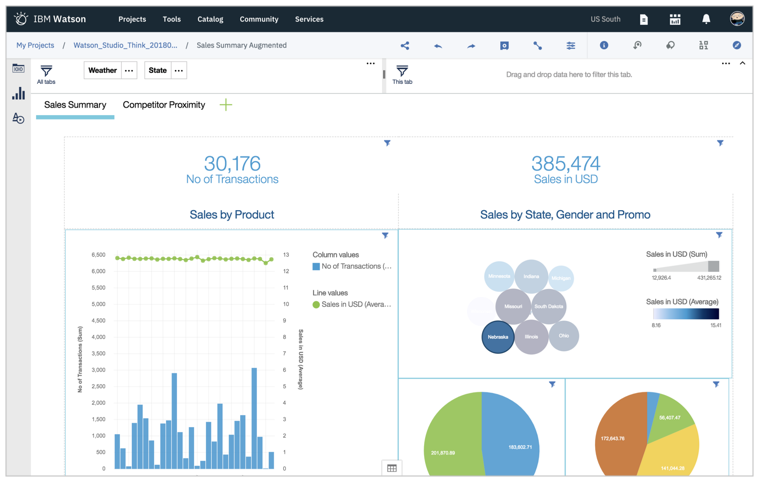
Dashboard
プロジェクトでの分析の結果を簡単にダッシュボード化して、チームにシェアしたり、公開できます。
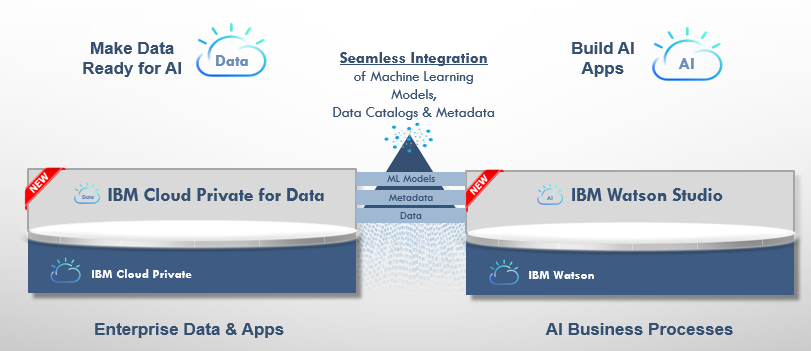
ICP for Dataとの連携
別途、プライベート・クラウド向けのデータサイエンス・プラットフォームとしてIBM Cloud Private for Dataが発表されています。ICP for Dataとは
- Kubernetesベースのプライベート・クラウド・プラットフォームであるICP( IBM Cloud Private)上に追加でデプロイ可能なコンテナ・サービス群です
- プライベート・クラウド上で、データベース/データ統合/ガバナンス/マシンラーニングなどの機能をまとめてご提供します
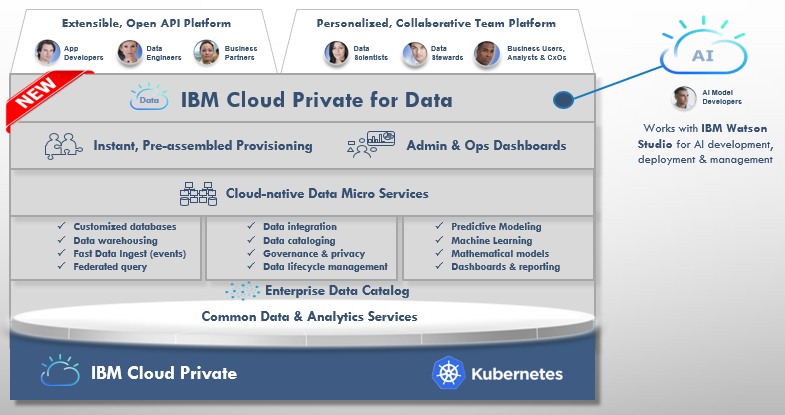
Watson StudioはICP for Dataと連携し、データ、機械学習モデルやメタデータをシームレスに統合できます。たとえば、ディープ・ラーニングでは通常ひとつだけモデルを作ることは無く、パラメーターを変えながら多数のモデルを作り最適な性能のモデルを探ります。その作業は大量のCPUリソースが必要なので、実行はGPUを活用できるクラウド上のWatson Studioが向いています。Watson Studioで最適なモデルができたら、それをダウンロードしてICP for Dataに取り込んで実行する、といったことが可能になります。
Watson Knowledge Catalog
今までData Catalogと呼ばれていたサービスの名称変更&機能強化です。要はデータ・レイクを含む企業内の様々なデータをカタログ化して、すぐに使える状態に管理します。データ・ガバナンスの領域のサービス、といったらわかりやすいですかね。
文献
Introducing IBM Watson Studio - 紹介Blog
Welcome to Watson Studio and Watson Knowledge Catalog - ドキュメント
IBM Watson and Cloud Platform Learning Center - スキル
Learning Center - Watson Studio
MediumのWatson AI&Data系の最新記事ポータル
IBM Watson Studio in 10 videos
独り言
![]() どうでもいい話ですが、最近のIBMは「コグニティブ」ではなく「AI」という言葉を使うようになってきたようですね。昔は「いや、AIではなく専門家の知識を強化・拡張する意味でコグニティブと言ってですね。。」とか話をしてたんですが、世間一般に「AI」という言葉が広く認知・収斂したので、「もう説明すんの面倒くさいからAIでいいや。。」となったのかな~と想像。あ、色々変わったから、今まで書いた記事、またアップデートしないと。。。
どうでもいい話ですが、最近のIBMは「コグニティブ」ではなく「AI」という言葉を使うようになってきたようですね。昔は「いや、AIではなく専門家の知識を強化・拡張する意味でコグニティブと言ってですね。。」とか話をしてたんですが、世間一般に「AI」という言葉が広く認知・収斂したので、「もう説明すんの面倒くさいからAIでいいや。。」となったのかな~と想像。あ、色々変わったから、今まで書いた記事、またアップデートしないと。。。![]()