(記事初版 2018年06月25日)
はじめに
こんにちわ!石田です。先般、Watson Studioをザクッとご紹介しましたが、第二弾としてWatson StudioとWatson Knowledge Studio1 の両方に標準搭載されたデータ・プレパレーション・ツール である DataRefinery をザクッとご紹介します。
- 「標準搭載」とは、何もしなくても使えるようになっている=IBM Cloud上で別にサービスをカタログから選んで追加したりする必要なし、ということです
- 以下のように同じ機能が両方のサービスからシームレスに使えるようになっています
![]() (2019/4/3) Data RefineryのProfilingとClassification機能を5/17からWatson Knowledge Catalogに移すとの発表がありました
(2019/4/3) Data RefineryのProfilingとClassification機能を5/17からWatson Knowledge Catalogに移すとの発表がありました
そもそもデータ・プレパレーション(Preparation)・ツールって何 ?
◆皆様は以下のような話をよく聞かれることと思います。
"ビジネス・プロフェッショナルはデータを実際に使う前のデータの修正や検証に40%の時間を費やしている"
"分析作業の時間の80%は分析自体に使われておらず、データの準備に使われている”
◆英語で言うとPreparation=準備ですが、要はデータサイエンスやAIプロジェクトで一番手間と時間を取られるデータの準備作業=クレンジング、整形、エンリッチなどの作業を簡単に行えるようにして、生産性を向上させるツールです。現場/LOBのご担当者の目線で言えば、「いちいちIT部門に依頼せず、自分たちで=セルフサービスでデータの整形ができる」ということです。「百聞は一見に如かず」で、要は以下のような操作感のツールです。

◆「ETLと何が違うのか?」と思われた方、さすがです。最終的に「やりたいこと」はデータの容易な加工であり、その点では同じです。ただ、従来のETLがITの方向けで、きっちり仕様を決めて設計してフローに落とし込み、定例運用でジョブを回すイメージだとすれば、データ・プレパレーション・ツールは「現場/LOB/非ITの方」でもGUIを使って容易に操作できますし、加工の仕方も事前にきっちり仕様を洗い出すのではなく、データ分析者の視点や「その場の発想」を生かして**「コーディングなし」で「対話式」に「トライ&エラー」で結果を見ながら「その場で」加工の仕様を決めていける**点が大きな違いです。
Data Refineryとは
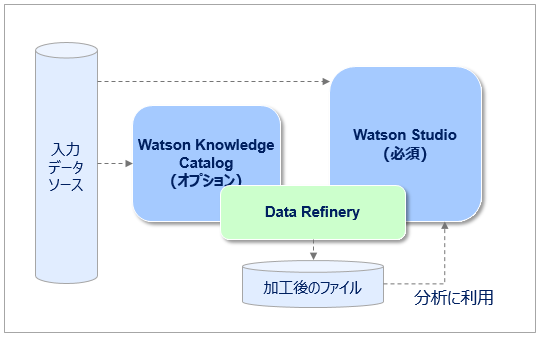
以下はData Refineryの機能を一枚で説明したチャートです。本丸であるデータの対話式な加工は当然として、それ以外にも多様なデータソースとの接続、データのプロファイル、ビジュアライゼーション、ジョブスケジュールなどの機能を持っています。

大きい処理の流れとしては、以下になります。
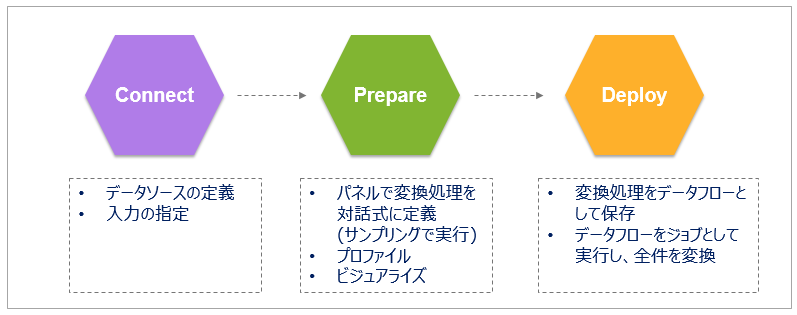
- まずはデータソースや入力ファイルを定義します(① Connect)
- 次にデータの加工内容をビジュアル/対話式に決めていきます。( ② Prepare ) この段階ではサクサクと快適に操作するために、対象とするデータは全件ではなくサンプリングで絞られています。ここはあくまで「加工の内容」を決めるのが目的です。
- 「加工の内容」が決まったら「データフロー」として保存のうえ、ジョブとしてバッチ実行します。(③ Deploy ) ここでは全件が処理対象になります。ジョブの再利用や定期実行のスケジューリングも可能です。
- 分析のデータは非常に大量になる可能性があるので、このように2段階に分けて非同期実行するデザインになっています(世の中のデータ・プレパレーション・ツールは、多くがこの方式ですね。)
以下、① Connect ②Prepare ③Deployの順に特長をご紹介します。
Connect(つなぐ)
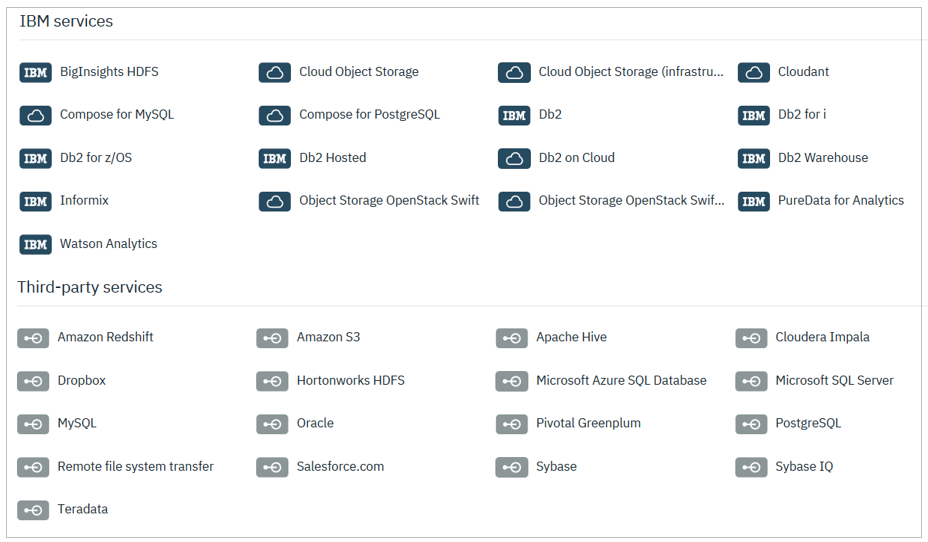
以下はWatson StudioでConnectionを作成するパネルです。以下のようにIBMクラウドのサービスにあるデータだけでなく、他社・サードパーティのクラウド/オンプレミスに存在するサービスもデータソースにできる点が特長です。Data RefineryはこれらのConnection経由でデータ(ファイルやテーブル)を入手して加工します。
たとえば以下の左はAmazon Redshiftの定義パネルですが、URL等の接続情報を記入するだけ。右はOracleの定義パネルですが、オンプレミスならSecure Gatewayを使って接続します。
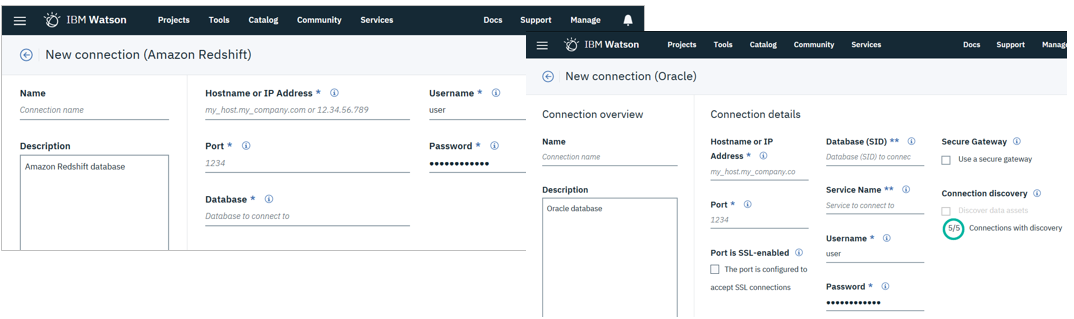
![]() ご参考)
ご参考)
- Watson Studioのドキュメント Connection typesに最新のデータソースのリストがあります
- ファイルのフォーマットとしては AVRO / CSV / EXCEL / JSON / PARQUET をサポートしています
- (ファイルサーバーなどの)「オンプレミスのファイル」に対する直接的なConnectionはサポートされていませんので、念のため。「ファイル」はICOSやS3などネット上のオブジェクト・ストレージに置いておく必要があります。
- CSVの詳細(見出し有無、区切り文字、Stringの囲み文字、エスケープ)は下記からパネルを表示して指定できます。ただし文字コード(Encoding)は**「UTF-8」のみ**ですのでご注意ください。(≒リストボックスでUTF-8以外の選択肢が出てこないんですが..
 )
)

Prepare(データの準備)
プロファイル(Profile)
![]() (2019/4/3) このBlog記事によると当機能は2019/5/17からWatson Knowledge Catalog(WKC)の機能に移ります。よってWatson Studioのみだと使えなくなります。ただしWKCにはFree Planもあるので「お試し」で一定の枠内でご利用いただけます。
(2019/4/3) このBlog記事によると当機能は2019/5/17からWatson Knowledge Catalog(WKC)の機能に移ります。よってWatson Studioのみだと使えなくなります。ただしWKCにはFree Planもあるので「お試し」で一定の枠内でご利用いただけます。
「このファイルに入ってるのはどんなデータなの? きちんとデータ入ってるの?」などをざっくり見るための「プロファイル」機能があります。ファイルから1000件をサンプル抽出して、以下のような感じで見せてくれます。
- データの件数
- 代表的な値と分布
- ユニーク件数、最大・最小・平均などの基礎的な統計値
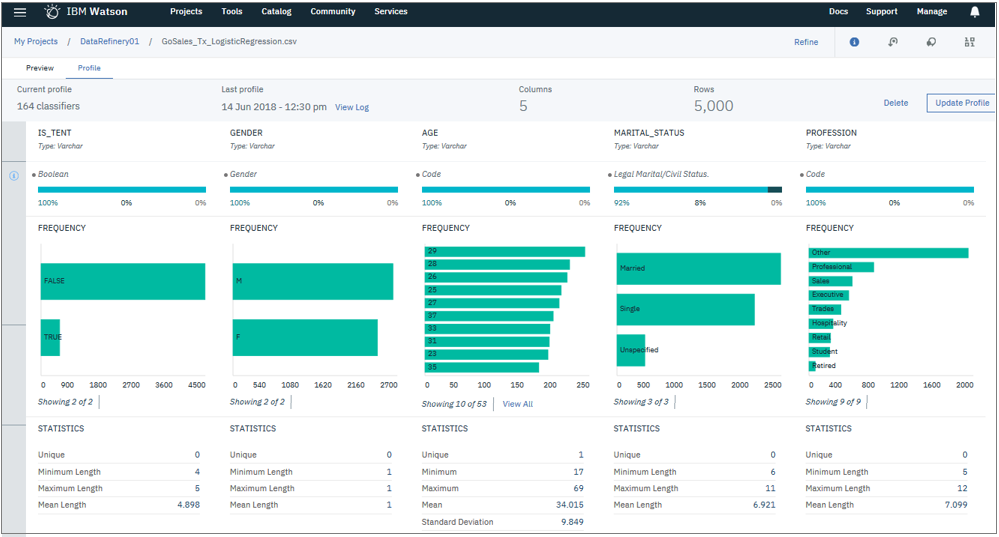
![]() プロファイルはデフォルトはOFFですので、見たければ明示的に作成する必要があります。以下のように数分かかりますがメニューから簡単に作れます。(裏の実装としてはICOS上のファイルにメタデータが格納されるようです。プロファイルの削除や再作成ももちろん可能です)
プロファイルはデフォルトはOFFですので、見たければ明示的に作成する必要があります。以下のように数分かかりますがメニューから簡単に作れます。(裏の実装としてはICOS上のファイルにメタデータが格納されるようです。プロファイルの削除や再作成ももちろん可能です)

![]() 残念ながら現段階ではUS英語
残念ながら現段階ではUS英語![]() のみの機能らしいですが、Watsonを用いてフィールドを自動的に分類してくれる機能( Attribute Classifier )があります。各フィールドの中身を見て「これは人の姓(Lastname)だ」とか「これはメアドだ」とか「町の名前だ」とかを自動的に分類してくれるもので、データの理解や整理が進みます。自動分類の対象は100以上あって、ドキュメントAttribute classifiers for data policiesに一覧があります。(一部はProfessionalでないと使えないそうです)現在はIBM側で事前に定義したカテゴリーしか使えませんが、ユーザー定義のカテゴリーを使えるようにする計画もあるようです。(噂)
のみの機能らしいですが、Watsonを用いてフィールドを自動的に分類してくれる機能( Attribute Classifier )があります。各フィールドの中身を見て「これは人の姓(Lastname)だ」とか「これはメアドだ」とか「町の名前だ」とかを自動的に分類してくれるもので、データの理解や整理が進みます。自動分類の対象は100以上あって、ドキュメントAttribute classifiers for data policiesに一覧があります。(一部はProfessionalでないと使えないそうです)現在はIBM側で事前に定義したカテゴリーしか使えませんが、ユーザー定義のカテゴリーを使えるようにする計画もあるようです。(噂)
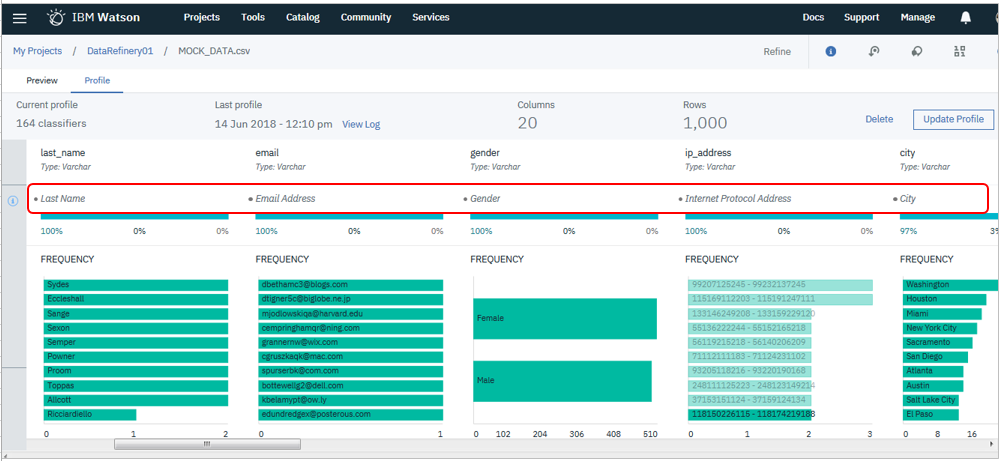
![]() 上記Attribure Classiferの確認のため、英語で色々なダミーデータを作りたかったのですが、MockarooというWebサービスは「クレジットカード番号」や「国の名前」など、定義済みのフィールドの種類が多数あって、すごく便利でした。
上記Attribure Classiferの確認のため、英語で色々なダミーデータを作りたかったのですが、MockarooというWebサービスは「クレジットカード番号」や「国の名前」など、定義済みのフィールドの種類が多数あって、すごく便利でした。
ビジュアライズ(可視化)
IBM提供のオープンソースのグラフ・コンポーネント Brunel Visualizationが組み込まれており、データを対話式に簡単に可視化できますので、データに関する理解が進みます。分析結果の可視化はJupyter上でmatplotlibやseabornを使ってやるのが王道でしょうが、その前段階でデータや業務理解に使う感じ? または「コーディングしない」人向けの簡便な可視化ツールと考えても良いかと。

![]() Brunel Visualizationにご興味があるかたは「こちらのページ」が参考になります。同ページの末尾に各種リソースへのリンクがあります。
Brunel Visualizationにご興味があるかたは「こちらのページ」が参考になります。同ページの末尾に各種リソースへのリンクがあります。
Refine(データ加工)
分析対象データのクレンジングや整形のために、様々な処理をコーディングなしで対話式に行えます。(この部分を英語では「Shaper」と呼んでいるようです。)以下はShaperのパネル・メニューの一覧です。
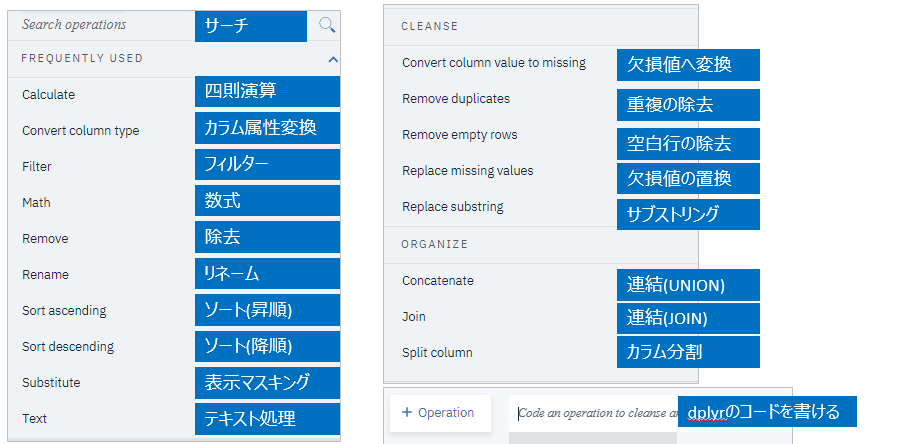
簡単ですが、以下は給与フィールドと手当フィールドを加算する定義の操作例です

集約など複雑な加工が必要なら、データ操作に特化したRのパッケージである dplyrの構文を直接使うこともできます。以下の例では給与を職種別に平均してみました。

Watson Studioのマニュアル: dplyr R library support in Data Refinery
Deploy(本番実行)
対話式に決めた加工の使用はステップ毎に順番に記録されています。上部には「保存」と「実行」のボタンがあります。
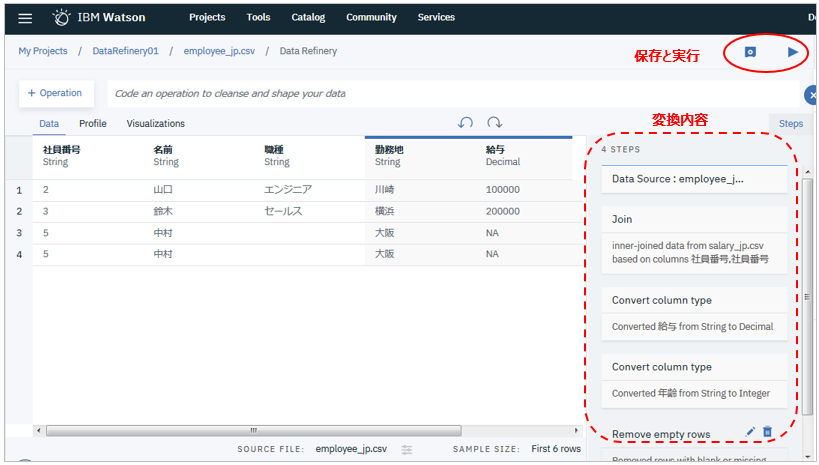
以下は実行の例です。加工内容を記述したデータフローはアセットとしてWatson Studioのプロジェクトに登録されますので、再利用できます。ジョブは定期的なスケジュール実行も可能です。

DataRefineryのコスト
- 冒頭に述べたとおり、Data Refineryは標準で搭載されている機能ですので、Data Refineryとしてのカタログ・エントリーや課金体系はありません。ただし使ったリソースに対する課金がCapacity Unit-Hourベース/Pay As You Goで発生します。
- 「Prepare」のフェーズで加工の仕様を決めるShaperの部分は課金されません。「Deploy」のフェーズでデータフローをジョブ実行する際に使ったリソースに対し課金されます。
- Watson Studioのカタログによると、Data Refineryの実行環境のリソース設定は現時点では6 Capacity Unit-Hourで「決めうち」であり、Jupyter Notebookなどのように「Environments」でのカスタマイズはできません。
- 1 capacity unit-hourは51円ですので 6 capacity unit-hourで一時間使ったら306円となります。要はデータフロー・バッチの実行 一時間あたり306円 と思っておけばよさそうです
- カタログには明確に書いてませんが、Data Refineryの課金は分単位で、最低は10分からと聞いています。ゆえに実行時間1分あたり約5円、ただしジョブが10秒でおわっても最低の10分=51円はかかる、ということですね。
実行時間(性能)について
実行時間の目安については公表されている値が見当たりません。当然ながら性能はデータソースの種類/ロケーション/サイズ、レコード件数やフィールド数、加工の種類や程度によりかなり異なると思いますが、私が「実際にやってみた」結果を以下にシンプルな例としてお示しします。
ICOSに格納した100万件/計211MBのダミー・データのCSVファイルをいくつかのパターンで加工処理してみました。結果は下記です。
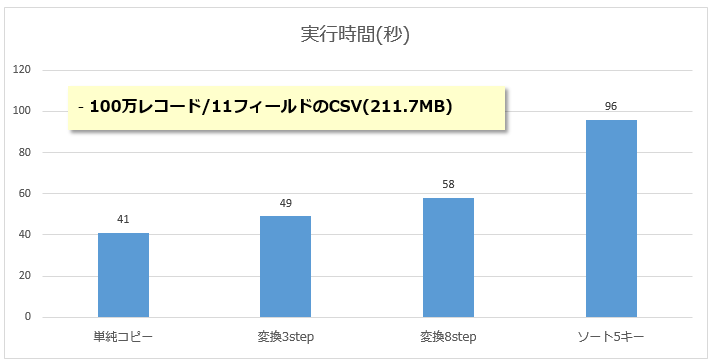
(こんな数字だけで見積もりをするのは無謀であって、皆様はご自身のデータで軽い計測を行ってご評価することをお勧めしますが「何もないよりまし」ってことで)エイヤで「200MBの変換に60秒かかった」とすると、
- 1GB/500万件なら5分、10GB/5000万件なら50分かかる
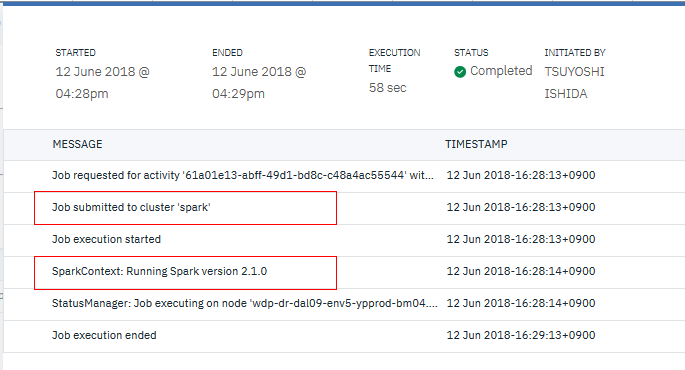
計算になります。くどいですが、あくまで「そういう結果だった」ってだけです。(なおご参考までに、実行ログを見ると内部的にはSparkで処理しているようでした)
![]() (2019/4/3) このBlog記事によると課金単位であるSparkのCUH(Capacity Unit per Hours)は従来は6CUHsでしたが2019/5/13からは1.5CUHsと約1/4で済むようになるそうです。これは朗報。
(2019/4/3) このBlog記事によると課金単位であるSparkのCUH(Capacity Unit per Hours)は従来は6CUHsでしたが2019/5/13からは1.5CUHsと約1/4で済むようになるそうです。これは朗報。
参考文献
![]() Watson Studioのマニュアル該当箇所
Watson Studioのマニュアル該当箇所
![]() ブログ記事
ブログ記事
![]() 動画
動画
改定履歴
| v | 日付 | 内容 |
|---|---|---|
| 1 | 2018/6/14 | 初版 |
| 2 | 2019/4/3 | このBlog記事の内容を追記 |
-
...WKCはデータ・ガバナンスをきちんと実施したい場合の「オプション」機能。要は「あったら便利だが、無くてもいいっちゃ、いい」ものです ↩