
【注】当記事は2017/08にアップしたのですが、2017/11に機能強化や画面変更がありましたので、2017/11月時点の情報でアップデートしました。
- Bluemix→IBM Cloudに呼称を変更しました
- DSXを含め色々なサービスが「Watson Data Platform」の冠の下に統合されました。それに伴い画面が変わったので画像を取り直しました。
- WMLの2017/11月の機能拡張の詳細はAutomate the deployment workflow with Watson Machine Learningをご参照ください。当記事では分量の関係もあり、全てを網羅していませんが、要は下記です。
- 継続的な学習( Continuous Learning )
- 機械学習モデルのバージョン管理
- xgboost モデルのサポート
- Python clientの提供
- 以前の記事との差分として新機能に言及した箇所は
 で表記します。
で表記します。
はじめに
こんにちわ!以前「IBM Cloud上のLiteプラン(ずっと無料)でData Science Experience(DSX)が使えるようになったので、触ってみた ★2017/11 Update」の最後で少しだけご紹介した**Watson Machine Learning(以下WML)**が2017/08/01付でIBM Cloud上でGA(正式提供開始)になりました。 無料のLiteプランでもご利用頂けます。触ってみたので、どんなサービスなのか簡単にご紹介しますね。
(以下は記事執筆時点(2017/11月)のものです。Flowなど一部機能がベータなので先々、画面が変わっていたり機能が強化されていたらすいません。)
Watson Machine Learningとは?
昨今流行の機械学習の「モデル作成」から「性能評価~デプロイ~利用(スコア)~フィードバック」までのフル・ライフサイクルの生産性向上を目指した製品/サービスです。データサイエンティストの方はDSX上のUIから迅速・簡単に使うこともできますし、デベロッパーの方はAPIを使ってアプリに組み込むこともできます。

- 昨年、SPSSベースのスコアリングサービス「Predictive Analytics」が「Watson Machine Learning」と改名しました。今回は同サービスにSpark/Scikit-Learnベースのサービス群が追加になったものです
- Watsonという名前が付いていますが、Watson Developer Cloud(WDC)上のWatson API群とは違うものです。WDC上のAPI群はチャットボットに代表されるような言語や画像など非構造化データの処理が得意ですが、Watson Machine Learningはもっとデータ・サイエンス寄りで、機械学習モデルを使って顧客の離反や融資可否の判断などの「予測」を行うモノです
- 分野としては(身もふたもない言い方をすれば)「Amazon Machine Learning」や「Azure Machine Learning」と同じカテゴリーのもの、と思っていただいてよいかと思います
WMLの目指す姿と現状(2017/11月時点)
WMLは最終的に「チームでのデータ分析プロジェクトの全ライフサイクルをカバーする」ことを目指しています。つまり単に機械学習モデルを作るだけではなく、モデルを評価/デプロイ/スコアリングし、モデルの品質を監視し、劣化があればモデルにフィードバックするまでを視野に入れています。(カッコ良く言うと「Self-Learning」でしょうか)![]() 2017/11の機能強化でモデルの品質を裏でモニタリングし、所定のしきい値以上に劣化した場合には通知したり再トレーニングしてくれる機能が追加されました。(ご興味あれば記事Watson Machine Learningの継続的学習システム( Continuous Learning System )を試してみたをご参照ください)またDSX上で簡単にモデルを構築できるUIやウイザードが提供されていますが、これらはベータとの位置づけです。
2017/11の機能強化でモデルの品質を裏でモニタリングし、所定のしきい値以上に劣化した場合には通知したり再トレーニングしてくれる機能が追加されました。(ご興味あれば記事Watson Machine Learningの継続的学習システム( Continuous Learning System )を試してみたをご参照ください)またDSX上で簡単にモデルを構築できるUIやウイザードが提供されていますが、これらはベータとの位置づけです。
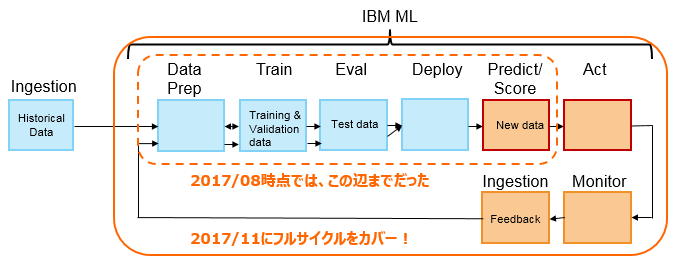
以下、現時点利用可能な機能の前提環境や制約の主なものをSupported Frameworksから抜粋・列挙します
- Spark 2.0 MLlib(※1) / Anaconda 4.2.x for Python 3.5 Runtime with scikit-learn 0.17 / XGBoost 0.6 with Python 3.5
- 現在利用できる機械学習モデルは**「クラス分類(Classification)」と「回帰(Regression)」**のみ。つまり「教師あり学習」として様々な「予測」(例. 離反可能性の予測や購入代金の推定)はできますが、「クラスタリング」(例. 似ている顧客をグループ化する) や、「パターン発見」(例. おむつとビールの関係を見つける)はできません
- スコアリングのモードと利用可能な環境
2017/11の強化で自動モデル構築でバッチやストリーミングも指定できるようになってました!
| モード | 自動モデル構築 | フロー | API | ドキュメント |
|---|---|---|---|---|
| リアルタイム | ○ | ○ | ○ | Deploying online models |
| バッチ |
|
× | ○ | Deploying batch models |
| ストリーミング |
|
× | ○ | Deploying streaming models |
※Spark 2.0 MLlibにはRDDベースのSpark MLlib(古い)とDataFrameベースのSpark ML(新しい)の両方が含まれますが、新しいSpark MLも当然利用できます
で何がいい?
- 品質・性能の高いモデルを迅速に作成できます
- データに最もフィットしたアルゴリズムを迅速に最適化(Cognitive Assistant for Data Scientists (CADS) )
- モデルに最適なパラメーターを自動的に提示(Hyper Parameter Optimization (HPO) )
- 専門家でなくとも簡単にモデルを作れます
- DSXからウイザード形式でモデルを簡単に作成・トレーニング(Model Builder)
-
継続的にモデルをモニターし、改善します(2017/11機能強化)
- モデルの正確さを継続的にモニターし、過去の実績からデータをフィードバック
- モデルを既存のアプリやツールと簡単に統合できます
- データ・サイエンティストやデベロッパーなど、分析チームでのコラボを簡単に行えます(DSX / REST API )
- モデルの管理プロセスをシンプルに行えます
- エンタープライズ環境での多数のモデルの簡単なデプロイ( UIから1クリック、または REST API)
具体的にどんな環境?
DSXと同様に「役割・好みに応じた適切なツール」をご提供します。データサイエンティストの方向けには自動モデル構築のウイザードやSPSSのような感じのフローがあり、デベロッパーの方向けはJupyter Notebookなどでガンガンとコーディングしていただくことが可能です。
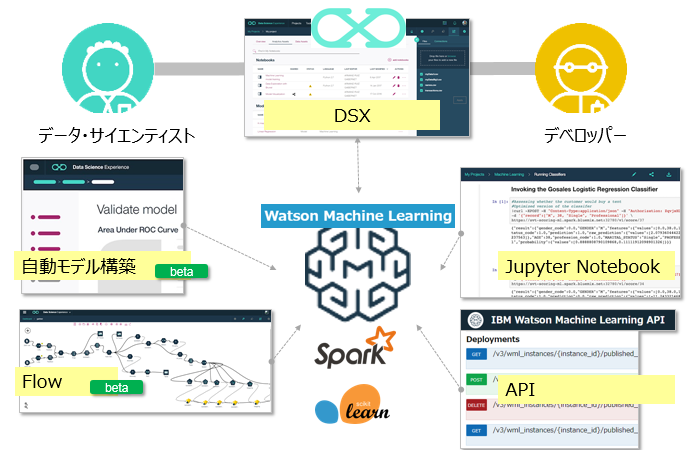
プログラミングについての補足
現状、WMLが独自にご提供するのはプラットフォーム上にモデルを公開・デプロイするためのREST API群やモデル最適化のためのライブラリー群であり、業務に直結する機械学習モデルの作成自体はSparkならSpark MLの、SKLearnならSKLearnの標準のAPIを使ってコーディングすればよいだけです。つまり、業務に関わるロジックについてはオープンであり、プロプラエタリな環境にロックインされるような懸念はありません。(このあたりはDSX上に公開されている各種のNotebookのコードを見ていただけばご理解いただけるかと思います)
以下は整理のための絵ですが
①機械学習モデルの構築時に利用可能な言語
②機械学習モデルの本番デプロイや管理を行う際に利用可能な言語(=WMLのREST APIをたたく言語)
③デプロイした機械学習モデルを使ってRESTでスコアリング要求を出す言語
は異なります。
①は環境に依存しますのでSparkならScalaかPython, Scikit-learnならpythonを使う必要がありますが、②③はREST APIであり任意の言語を使えます。(まあJupyter Notebook上でコーディングする場合は①②は一連のものとして同じ言語になることが多いでしょうが)
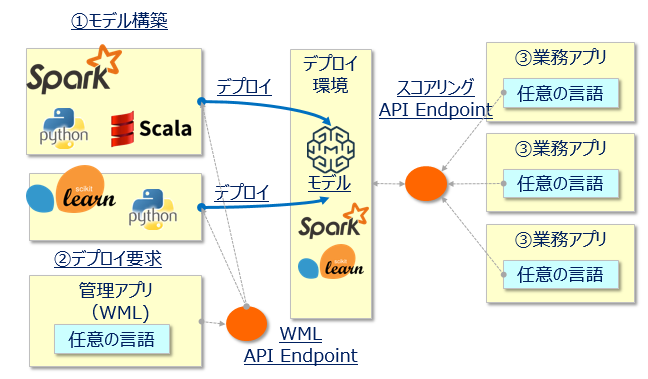
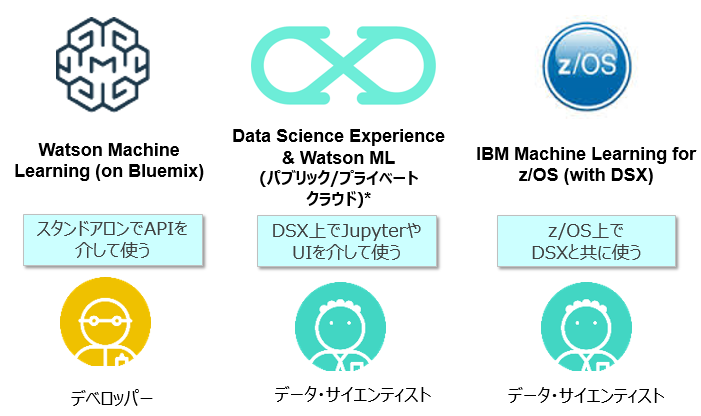
ご提供形態
WMLはパブリック・クラウド上のSaaSだけでなく、プライベート・クラウドも含めた様々な形態でご利用頂けるが特長です
プランや価格は?
以下は記事執筆時点でのプランをカタログから抜粋しますが、先日発表された**「ずっと無料」のライト・プランでもモデルを5つまでデプロイできる**のでお試しには十分でしょう。DSXもライトプランの対象ですので、両方使って無料で色々試せます。ただライトプランでの予測が5000件/月までなので、本格的なスコアリングを業務で使うには足りなそうですね。

ということでやってみる
一番皆様がご興味あるであろう、自動モデル構築(Model Builder)をやってみます。
ネタ: Tutorial: Build a logistic regression model with Watson Machine Learning
1. シナリオ
アウトドア商品を販売している会社が、ロジスティック回帰のモデルを使って顧客がテントを買うか/買わないか、その期待度を予測します。
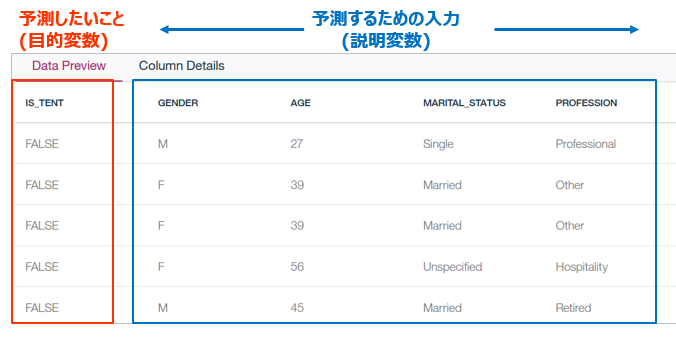
データは以下のような簡単なもので、①性別(GENDER) ②年齢(AGE) ③婚姻状況(MARIAL_STATUS) ④職業(PROFESSION)から 買うか・買わないか( IS_TENT)を予測します。
2. IBM Cloud上でWMLサービスを作成する
まずIBM CloudのカタログからMachine LearningのLite Planを選択してサービスを作成します。(DSX内で新規作成もできますが、まあ一応先に)
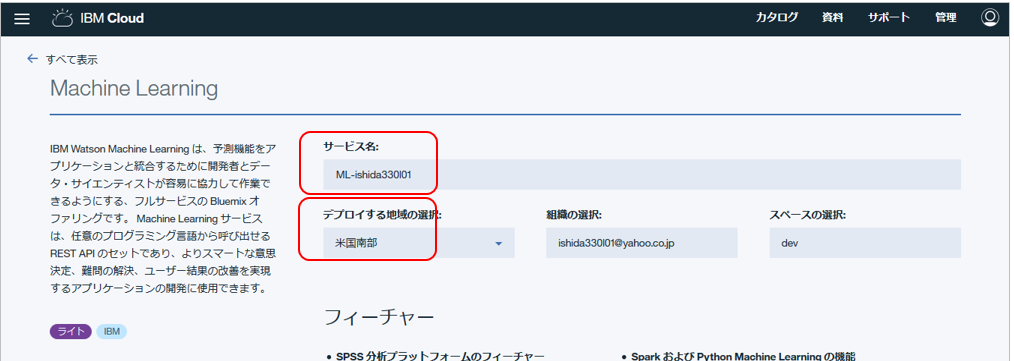
サービスの名前はお好みで。
![]() Liteプランの時は「デプロイする地域」は「米国南部」にしてください。2017/11月時点ではLiteプランで利用できるのは「米国南部」のみです。
Liteプランの時は「デプロイする地域」は「米国南部」にしてください。2017/11月時点ではLiteプランで利用できるのは「米国南部」のみです。
3. サンプルデータを準備する
ここからGoSales_Tx_LogisticRegression.csvをPCにダウンロードします( ログインするとダウンロードのボタンが出てきます)
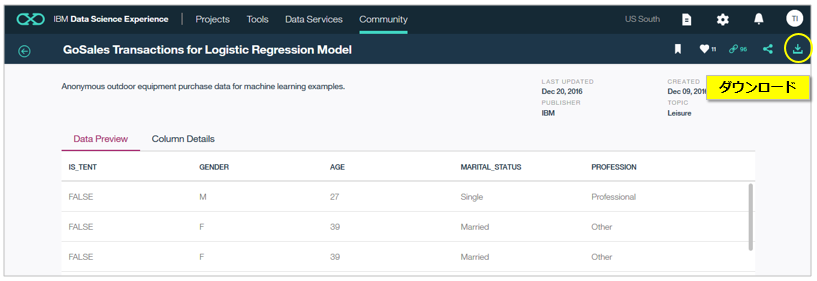
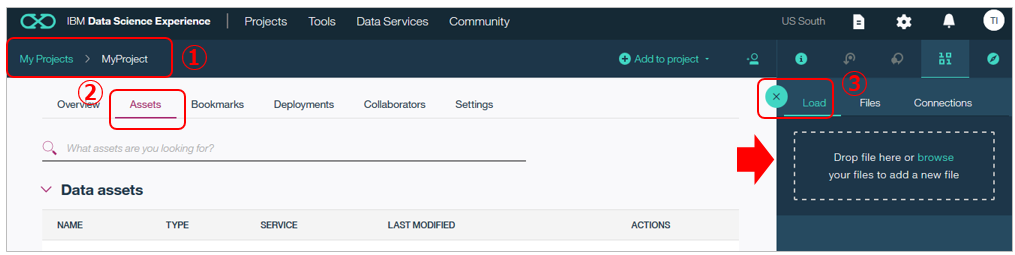
ダウンロードしたファイルをDSXのプロジェクトに追加しましょう。DSXで①プロジェクトを開き ②「Asset」タブを選択し ③右側で「Load」タブ を選んだら、今ダウンロードしたファイルを(Object Storageに)アップロードできます。
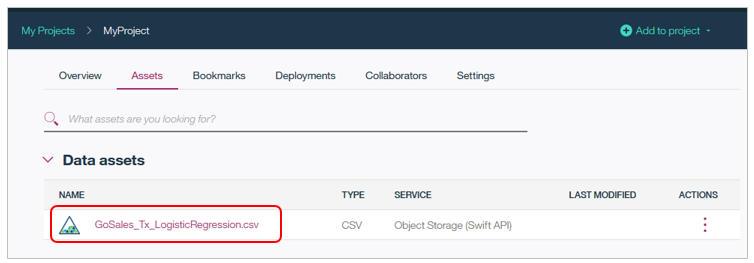
プロジェクトにデータが追加できました。
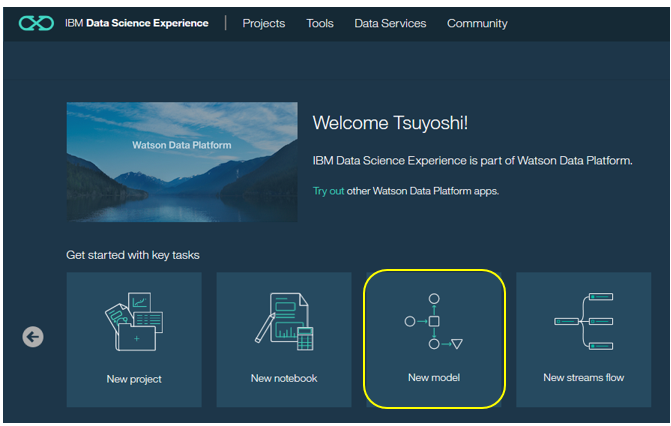
4. DSXのプロジェクトでWMLを使えるようにする
IBM Cloud上のData Science Experienceにログインしてコンソールを開きます。(サービスを未作成の場合はこの記事など参考にDSXのサービス・インスタンスを作成してください)
その後、「New Model」をクリック。
お好きなモデル名とモデルを格納するプロジェクトを選びます。(プロジェクトが無ければ作成します)
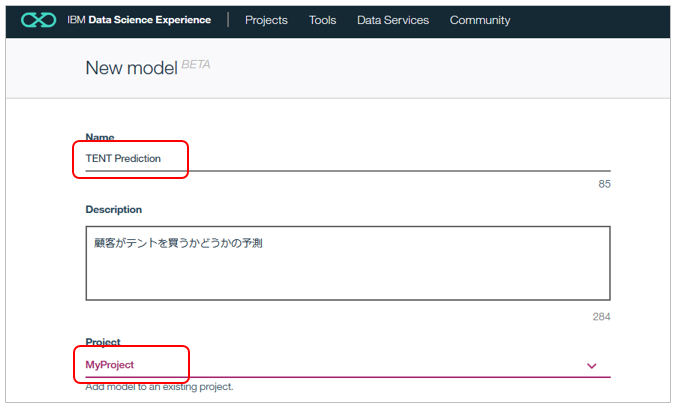
初回はプロジェクトにWMLのインスタンスが関連付けられていませんので、「Associate a Machine Learning service instance」のリンクをクリック。
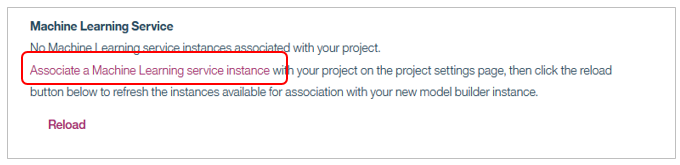
WMLのインスタンスを指定する別パネルが開きます。既にインスタンスは作成済なので「Exsisting」を選択し、先程作成したインスタンスを指定して「Select」ボタン。
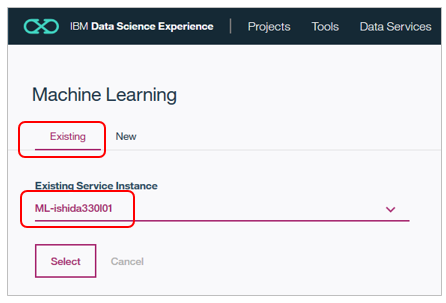
パネルが閉じ、元の画面に戻るので「Reload」すると指定が反映します。
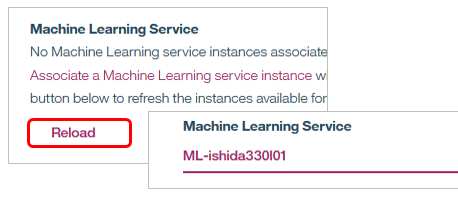
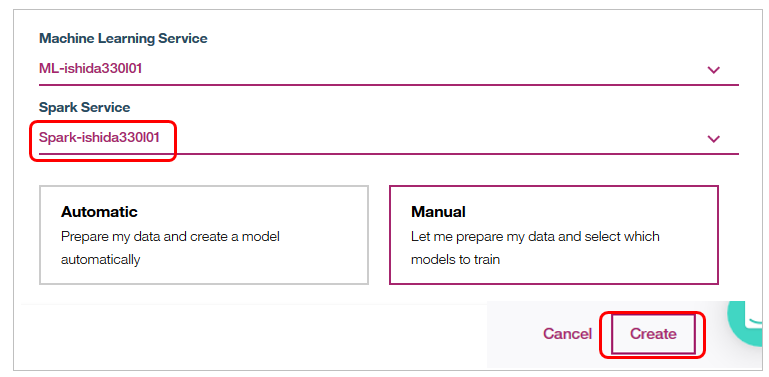
DSXで定義されているSparkのインスタンスを選択し、モデルの構築方法として今回は「Manual」を選択して「Create」ボタン。
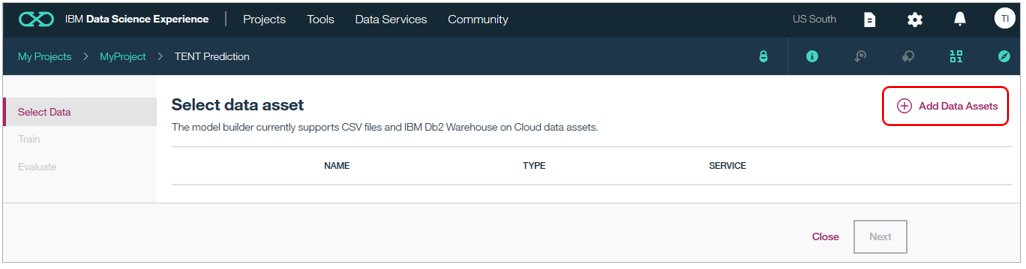
5. モデルを作り評価する
ここからは実際にモデルを作ります。まずは右上「Add Data Assets」
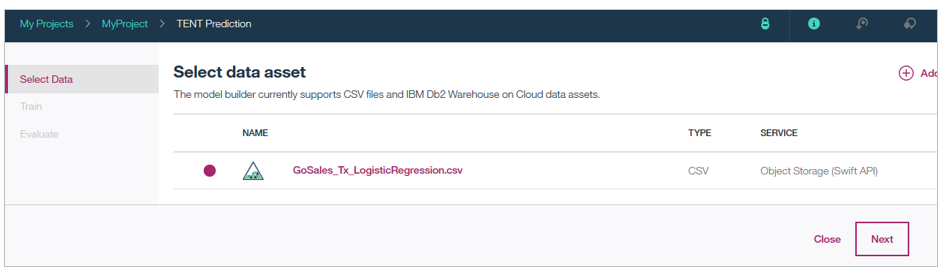
先程アップロードしたファイルを選択して「Next」ボタン。
しばしお待ちください。内部的にはここでAutomatic Data Preparationが行われます。
次のパネルでトレーニング内容を指定します。① 予測したいフィールドの指定で「IS_TENT」を選択します。②は入力となるフィールド群で、そのままにします。すると③で自動的に「Suggested technique」として「Binary Classification」がお勧めされます。WMLはAutomatic Data Preparationで各フィールドの値や傾向をサンプリングでチェックし、IS_TENTフィールドは「TRUE/FALSE」の2値しかないことを知っています。なので「二値の予測ならBinary Classificationがいいんじゃね?」と推奨できるわけです。これでいいので、このまま進みます。④右上の「Add Estimators」をクリック。
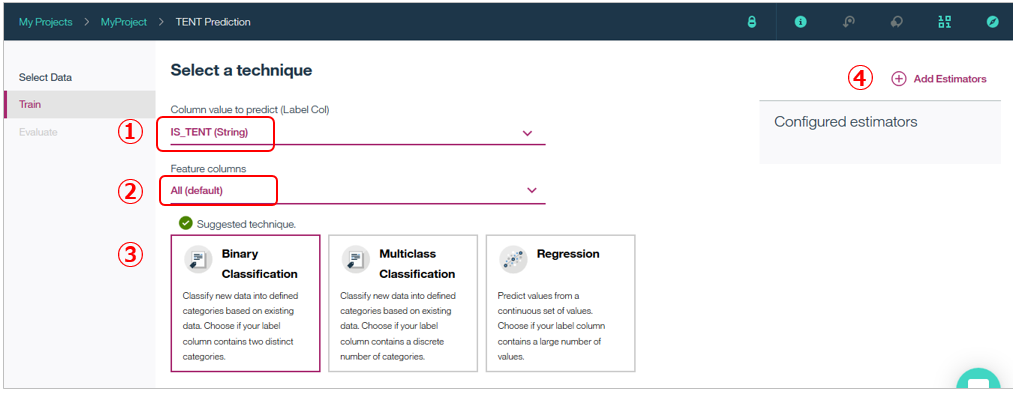
次のパネルではEstimatorを選択します。Estimatorとは実際のモデル構築手法です。WMLは様々なEstimatorを提供していますが、今は「Logistic Regression」を選択して「Add」します。ここで複数のEstimatorを選択することもでき、その場合はそれぞれについてモデルの評価が行われますので「一番成績のいいモデル」を選ぶこともできます。とりあえず今は1つだけとします。
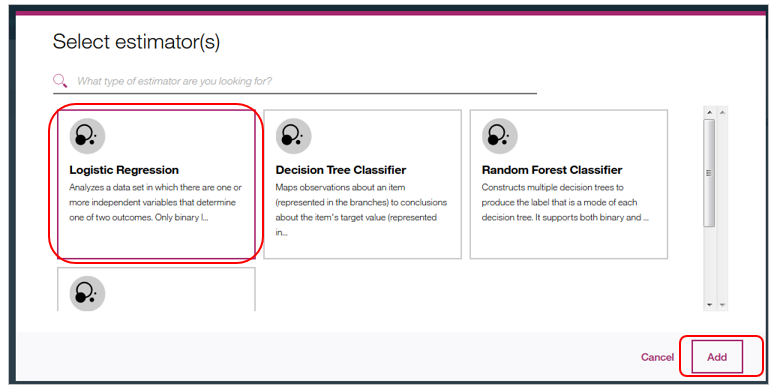
ご参考) 以下が手法とEsitimatorのサマリーです。色々ありますね。
Estimatorが選択されると下部にValidation Splitが表示されます。入力データを自動的に①モデル構築用②モデル品質評価用(Holdout)③テスト用に分割してくれます。
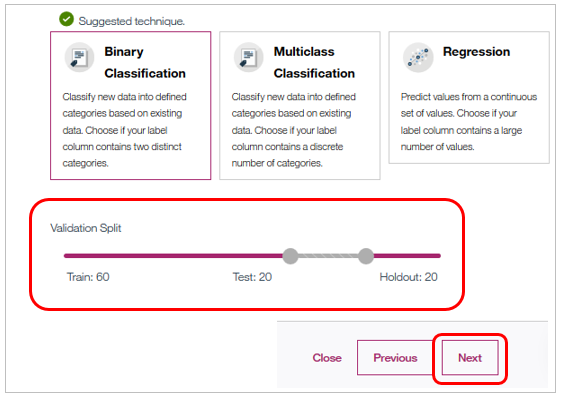
「Next」ボタンでパネルが切り替わりモデルの構築と評価が行われます。
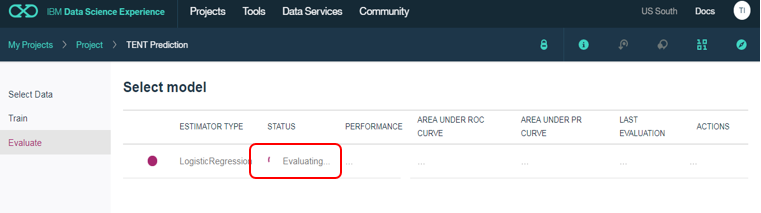
できました。PERFORMANCE欄は「Fair」になっています。これは「モデルの品質がまあ、いい」ということを意味しています。「Poor(いまいち)」「Fail(ダメダメ」などの値が表示されることもあります。これらはモデルの品質に関する指標であり、いずれにせよデプロイは可能です。(特に「Fail」は「処理が失敗した」のではなく「品質が良くない」ことを示しているだけで処理は完了していますので誤解なきよう!)他にもROCやPRなどモデル品質に関する評価結果が見られます。このまま、「Save」します。
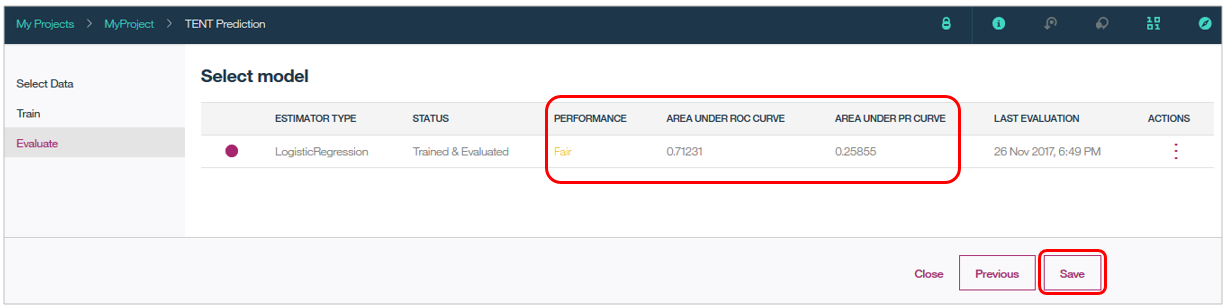
6. モデルをデプロイする
Saveできたら以下の画面になります。モデルの評価やデプロイメントのタブがありますね。
「Deployments」で「Add Deployment」
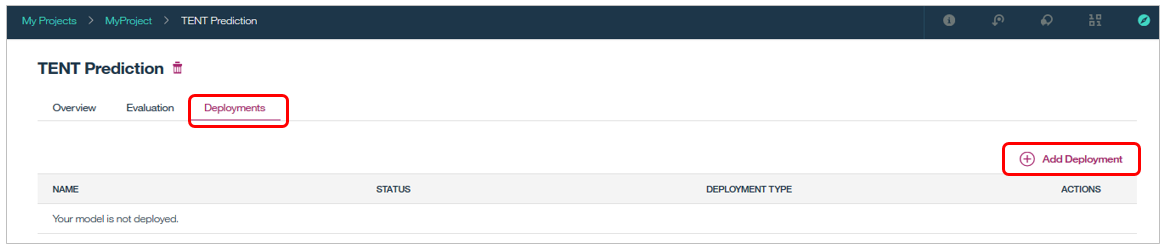
2017/11の拡張でデプロイメントの形式として①WebService ②Batch Prediction ③Real-time Streaming Predictionsの3種類が選べるようになりました。今回はRESTのWebサービスにしましょう。「WebService」タブでサービスにお好みの名前をつけて「Save」ボタン。
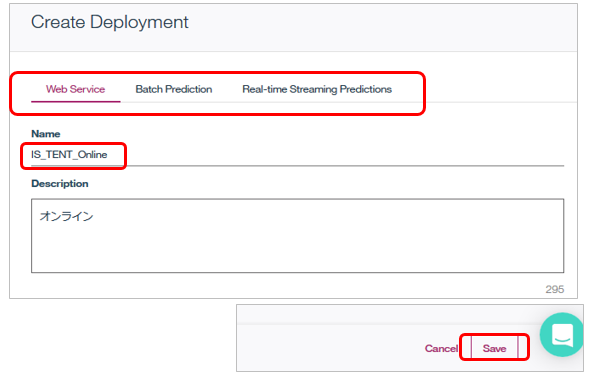
これで実行環境へのモデルのDeployが成功しました。マジで1クリックですね。
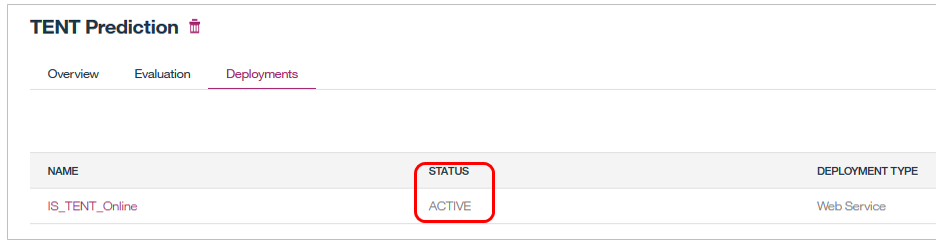
7. モデルを使う(スコアリングを行う)
すでにモデルは本番環境に反映していますので、任意のアプリケーションからのREST呼び出しでスコアリングを行うことができます。DSXではAPIをテストする機能がありますので、これでスコアリングをしてみます。
デプロイされたモデル名をクリックします
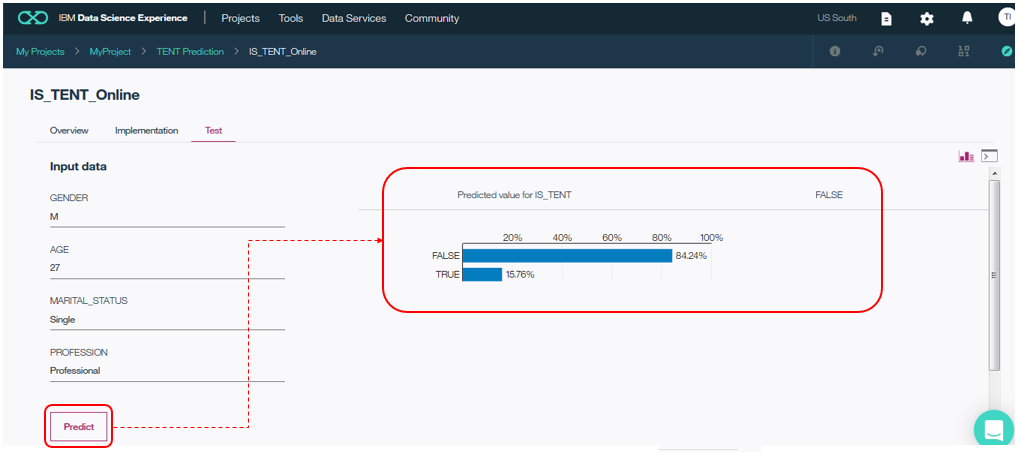
次のパネルで「Test」タブを選択するとIS_TENTの値を予測するための入力データが指定できるようになるので、適当なデータを入力して「Predict」ボタンを押します。
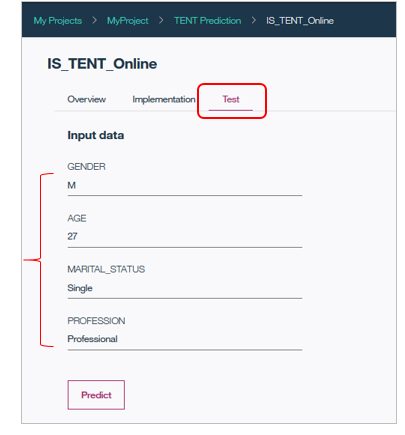
すると右側に予測結果と確信度が表示されます。この例では、予測結果は「FALSE(買わない)」で、その確信度は84.24%です。よろしければフィールドの値を変えて、色々試してみてください。
【ご参考】
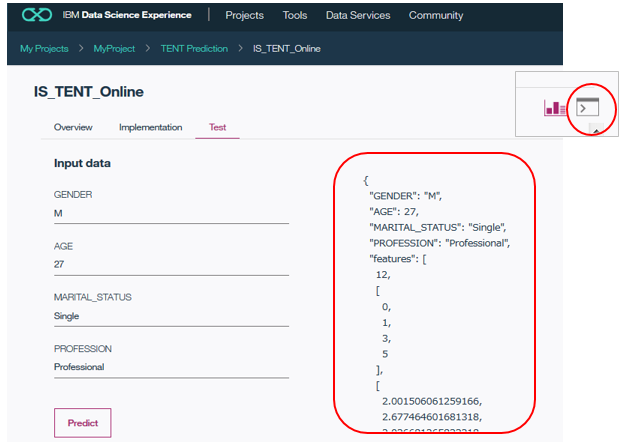
右上のマークで右側をクリックするとチャートではなく実際のjsonのレスポンスが表示されます。
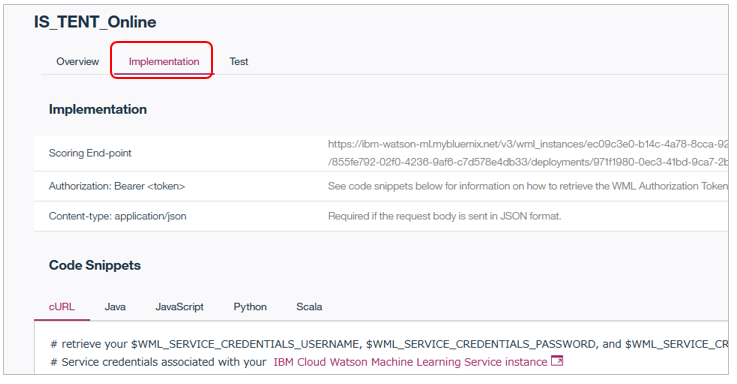
当該サービスをプログラムから呼び出したい場合は「Implementation」タブを見ればAPIのエンドポイントや言語別のコードスニペットが見られます。
以上、簡単ですが自動モデル構築の例でした。
(「フロー」もご紹介したかったんですが、長くなったので別の記事にて公開しました。)
デベロッパーの方向けには? (Jupyter環境でのプログラミングによるモデル作成やAPIの使いかたなど)
このBlogの「Integration with Data Science Experience」のところに以下のNotebookへのリンクがあります。DSXにアップロードして実際に動かすことももちろんできますよ。特に上の2つは題材が今回の「テントの予測」と同じものなので、今回の操作をプログラム的にどうやるか、を知るにはもってこいの教材です。
- Scala Jupyter Notebook end-to-end tutorial: Train, Save and Deploy a SparkML model
- Python Jupyter Notebook end-to-end tutorial: Train, Save and Deploy a SparkML model
- Scala Jupyter Notebook Auto-Modeling with Cognitive Assistance (CADS)
- Building Predictive Apps on Bluemix Sample application “Customer interest in sport products prediction using Spark MLlib
新機能Continuous Learning Systemについて
2017/11に強化された注目機能「継続的学習」についてはWatson Machine Learningの継続的学習システム( Continuous Learning System )を試してみたで書きましたが、以下URLだけご紹介しときます。特に「ドキュメント」については具体的な使いかたが書いてある唯一のページにもかかわらず、なぜかWMLのドキュメントの左側の目次からは辿れず、ページが埋もれています! (=この直のURLを知らないとアクセスできないんです。![]() )ので、とりあえずここに書いておこうと思った次第です。
)ので、とりあえずここに書いておこうと思った次第です。
![]() あ、あと日本語の文書は更新日が古いことがあるので、必ず本文の下にある言語選択では英語を選んでから読んでくださいね!
あ、あと日本語の文書は更新日が古いことがあるので、必ず本文の下にある言語選択では英語を選んでから読んでくださいね!
ブログ:Lifelong (machine) learning: how automation can help your models get smarter over time
ドキュメント:Continuous learning system
プログラミング:Use of Continuous Learning System to select the best heart drug with IBM Watson Machine Learning
あ、ちなみにIBM Cloud(Bluemix)の全ドキュメントはGitHubにも公開されているんで、そっちを見る、って手もありますよ。こんなの、です。
ご参考) ドキュメントやURL
-
Getting started with Machine Learning
- 英語ドキュメント~日本語版は古いようなので英語を見たほうがよさそうです
-
IBM CloudカタログのWatson Machine Learning
- プランや価格など
-
Service API
- APIについてのドキュメント
-
Watson Machine Learning overview
- DSXでのWMLのドキュメント
以上です。