![]() 当記事は2018/4月に初投稿しましたが、当記事で紹介している**Neural Network Moderは2020/07/31付けで廃止となり、Watson Studioから除去1されました。**記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。
当記事は2018/4月に初投稿しましたが、当記事で紹介している**Neural Network Moderは2020/07/31付けで廃止となり、Watson Studioから除去1されました。**記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。
はじめに
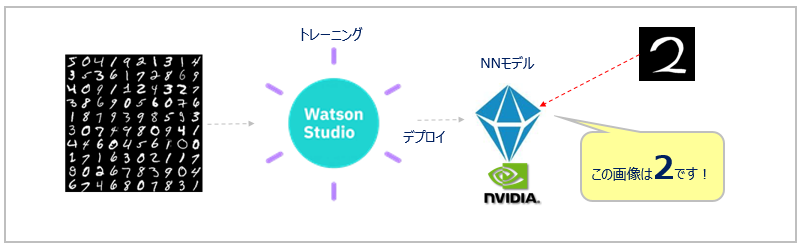
(記事執筆時点: 2018/04/02) 先般、「IBMのThink 2018で発表されたAIプラットフォーム「Watson Studio」をザクッと紹介してみる」という記事を書きました。そこで軽く紹介したWaston StudioのDLaaS(Deep Learning as a Service)機能を使ってみたので、チュートリアルに沿って詳細をご紹介します。
Watson StudioのDLaaS(Deep Learning as a Service)の概要
概要ご紹介は重複するので前掲の記事のここをご参照ください。概要の絵だけ、再掲しますね。
いい話と悪い話
のっけからサゲる話ですいません。以下ぶっちゃけの個人的な所見ですが、現時点でのDLaaS機能にはいい話と悪い話があると思います。
 いい話
いい話
- Watson Stuidoは無償のライトアカウントでも使えます。DLaaSもお試しいただけます。
- 一切コーディングせずに、独自のニューラルネットワークのモデル構築・トレーニングができます
- NNのデザインからデプロイまで、全サイクルがカバーされています
- UIではなく全部APIでプログラミングすることもできます
 わるい話
わるい話
- 上記の利点を享受できるのは、ディープラーニング/ニューラル・ネットワークの基礎知識があり、TensorflowやKerasなどフレームワークのこともそれなりにわかっている方=**「専門家」に限られる**でしょう。
- Watson Studioにはニューラル・ネットワーク・デザイナーなどのUIツールもありますが、パレットの中身は「Conv2D」「シグモイド」「ReLU」「Softmax」など一般の利用者には謎の単語のオンパレードです。UIがあるからといってSPSS的な感覚で「現場の(LOB)ユーザーでも簡単にディープラーニングが」的な理解をすると、足をすくわれます。(残念ながら、それはたぶん無理です)まあ、通常はデータサイエンス領域で現場ユーザーの方がやりたいのは何かの「予測」であって、それは無理にニューラル・ネットワークを使わずとも、SPSSなど従来の予測分析ツールで、できてしまいます。(というか、そのほうが望ましい) 現場の業務ユーザーの方がニューラル・ネットワークの対象領域である「イメージ」や「テキスト」「音声」などの判定器を作るのは異例かと思うので、上記は杞憂かもしれませんが。。
要は、DLaaSは「今までTensorflowとかKeras on Jupyterでプログラムをガリガリ書いて、パラメーター最適化やモデルの管理、本番デプロイなどなどプロジェクト周りで色々とご苦労してきて、難しさ(と楽しさ?)を知っている人」から見ると「えー!こんなに楽になるの?」と思うものなのかな、と思います。
なお、上記は「ツールの機能がプアだから専門家でないと使えない」のではないです。現時点では、ニューラル・ネットワークは他の機械学習の技法に比べ、より実験・探索的(Experimental)です。つまり、層を増やしたり、独自の活性化を試みたり、パラメーターを変えたり、と何度も試行錯誤を繰り返して最適な性能のモデルを導き出すのが通例です。(だからNNになるとGPUが欲しくなる) 要は「テントを買うか・買わないか=購入可能性の予測」のように、「教師データを分割・入力して適切な手法を選べば、(まあ、それなりの)結果が出る」ものよりはるかに手間がかかり、複雑です。先々、なんらかの手法面でのブレイクスルーがあるかもしれませんが、現時点ではこの方式にならざるをえないのだろうなー、と思います。(でなければWatson APIのような「トレーニング済み」のサービスを使うか)
やってみた
ということで、ちと気分を下げましたが、気を取り直してやってみましょう。
シナリオ
Tutorial: Single convolution layer on MNIST dataにチュートリアルがあります。「お約束」の「手書き数字の認識」です。これをエンドTOエンドでやってみます。(githubのIBM Watson Studio Labも似たような内容ですのでご参考まで)
![]() 当記事ではわかりやすさ優先で全部UIでやりますが、同じことはPythonなどのプログラミングでAPIを経由して行ったり、CLIで行うこともできます。「UIは俺の流儀じゃない」という硬派の方はTutorial: CLI with TensorFlowが参考になります。
当記事ではわかりやすさ優先で全部UIでやりますが、同じことはPythonなどのプログラミングでAPIを経由して行ったり、CLIで行うこともできます。「UIは俺の流儀じゃない」という硬派の方はTutorial: CLI with TensorFlowが参考になります。
![]() (2018/5/22) 英語ですが当記事と似たようなことをやってる記事 Deep Learning and Watson Studioがあったのでご紹介します。NNDで生成したソースをPC上でも実行しています。
(2018/5/22) 英語ですが当記事と似たようなことをやってる記事 Deep Learning and Watson Studioがあったのでご紹介します。NNDで生成したソースをPC上でも実行しています。
事前準備
![]() 以下の3つのサービスのインスタンスを「US-Southに」作成(US-Southであれば、既存のものを利用できます)
以下の3つのサービスのインスタンスを「US-Southに」作成(US-Southであれば、既存のものを利用できます)
![]() 2018/4月時点では、ディープラーニング系の新機能は「US-Southのみ」「ベータの位置づけ」で提供されていますので、ご注意ください
2018/4月時点では、ディープラーニング系の新機能は「US-Southのみ」「ベータの位置づけ」で提供されていますので、ご注意ください
- Studio ( アイコンはWatsonカテゴリーにあります)
- Machine Learning( 同上 )
- Object Storage

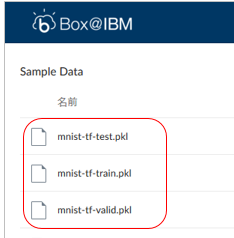
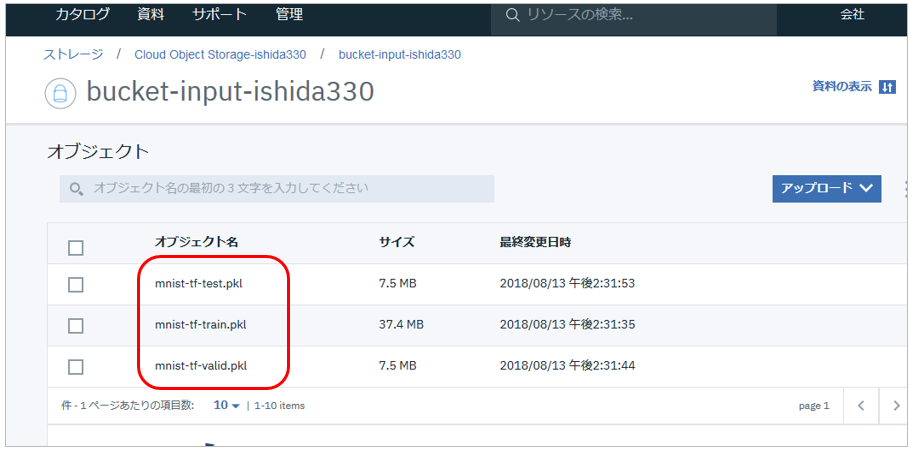
![]() Tutorialで使うデータ(画像)として、以下の3ファイルをここからPCにダウンロードしておきます。(MNISTのトレーニング、テスト、検証用データをpickle形式に保存したものです)
Tutorialで使うデータ(画像)として、以下の3ファイルをここからPCにダウンロードしておきます。(MNISTのトレーニング、テスト、検証用データをpickle形式に保存したものです)
ICOS(IBM Cloud Object Storage)側
以下の手順でICOS上に入出力用にバケットを各1つずつ定義し、上記の3ファイルを入力用のバケットに格納(アップロード)します。
- チュートリアルでは入力/出力ともICOSのバケット上のファイルを使用します
- 操作はAPIでも可能ですが、簡単なので今回はUIでやります
ICOSのBucket準備
ICOSのBucketsタブでバケットを作成します。(以下は「空っぽ」の状態での画面ですので、皆様の表示は多少違うかもしれません)
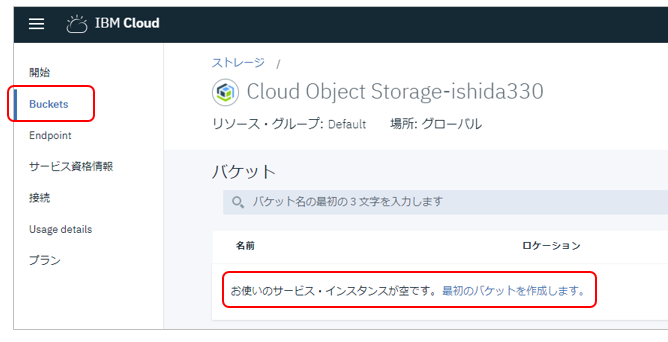
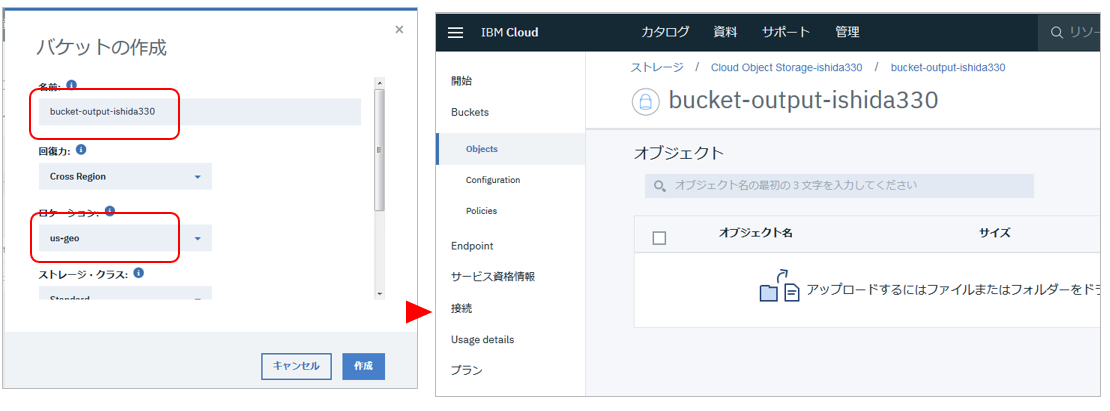
![]() 入力用のバケットに適当な名前を付けて、
入力用のバケットに適当な名前を付けて、![]() ロケーションはus-geoを選んで、残りはデフォルトで「作成」
ロケーションはus-geoを選んで、残りはデフォルトで「作成」
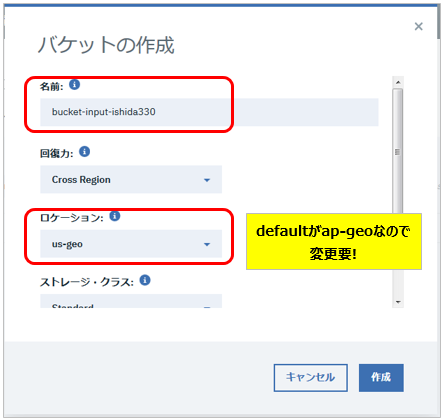
作成したバケットに、先ほどダウンロードした3ファイルをアップロードします
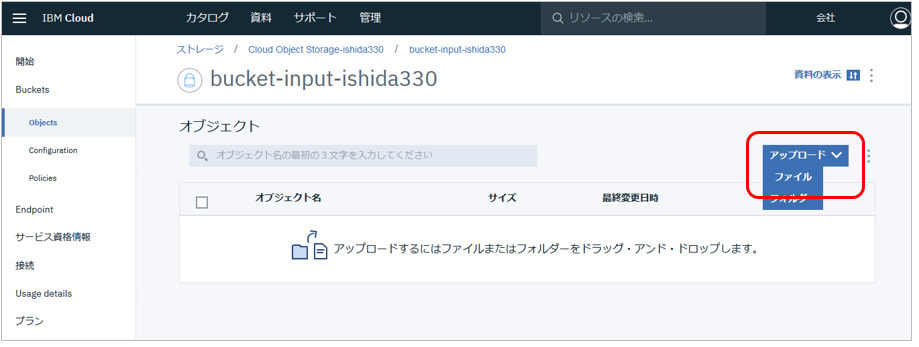
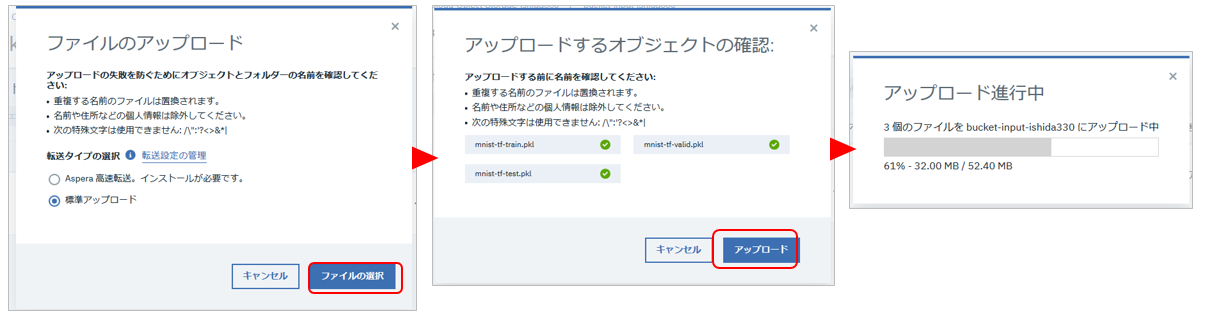
アップロードできました。
![]() 同様に出力用のバケットを作成しておきます.
同様に出力用のバケットを作成しておきます. ![]() ロケーションはus-geoを選んでください
ロケーションはus-geoを選んでください
![]() これで準備ができました!では本筋のWatson Studioに進みましょう
これで準備ができました!では本筋のWatson Studioに進みましょう
Watson Studio側
(なければ) プロジェクトの作成
Watson Studioを起動します。「Get Stated」ボタン
![]() プロジェクトを未作成であれば、以下の作業で作成します。(既存のものも使えます)
プロジェクトを未作成であれば、以下の作業で作成します。(既存のものも使えます)
デフォルトの「Complete(全部いり)」を選んで「OK」
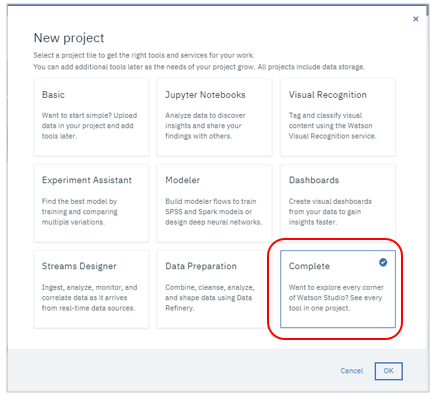
お好みの名前を指定のうえ、既存のICOSのインスタンスと関連付けて「Create」
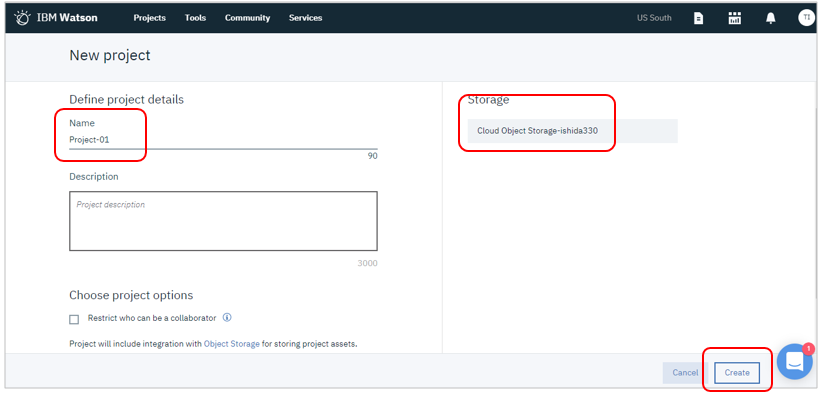
プロジェクトができました。
Machine Learningサービス
プロジェクトに自分のMachine Learningサービスのインスタンスを関連付けます。
![]() 既存のプロジェクトで、すでに関連付けが済んでいるなら、当作業は不要です
既存のプロジェクトで、すでに関連付けが済んでいるなら、当作業は不要です
「Settings」タブ
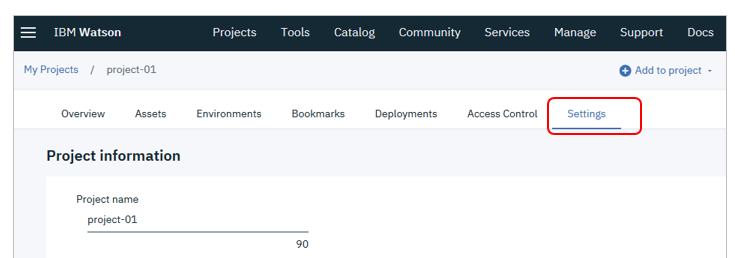
「Associated services」で
- 「Add services」-「Watson」2 をクリック
- Watsonのサービス一覧から「Machine Learning」を選択して「Add」-
- 「Exsisting」からご自身のインスタンスを選択して「Select」
- (未定義なら「New」で作成もできます)
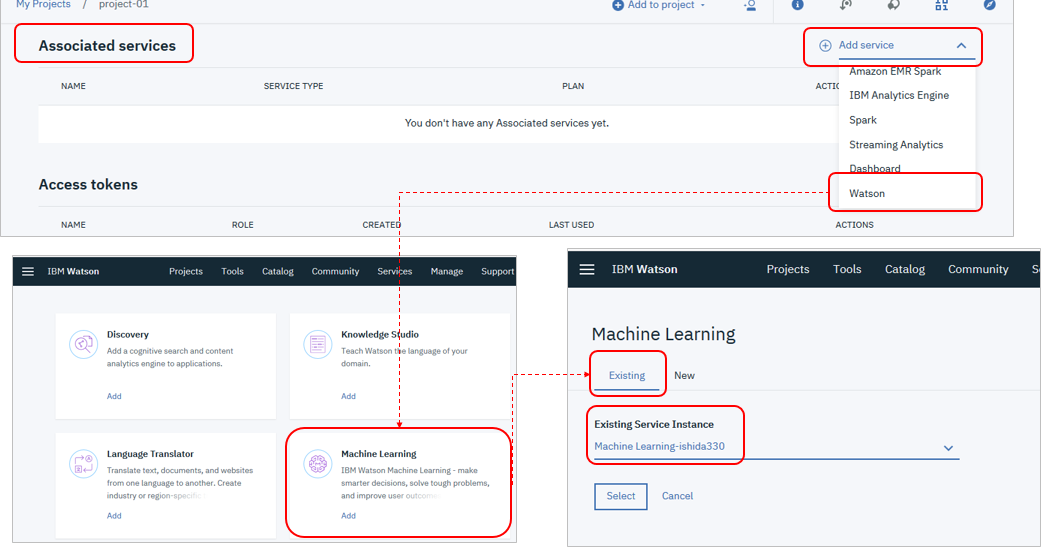
Machine Learningサービスのインスタンスがプロジェクトに関連付けされました

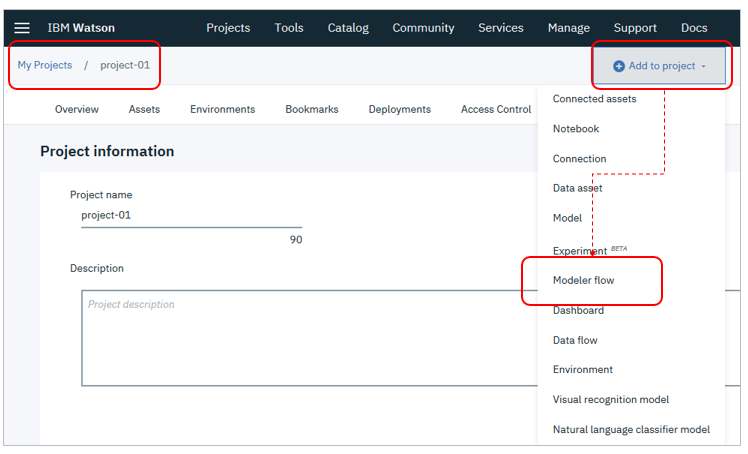
Modeler Flowの作成
プロジェクトのパネルに戻り、右上の「Add to project」ボタンで「Modeler flow」を選択
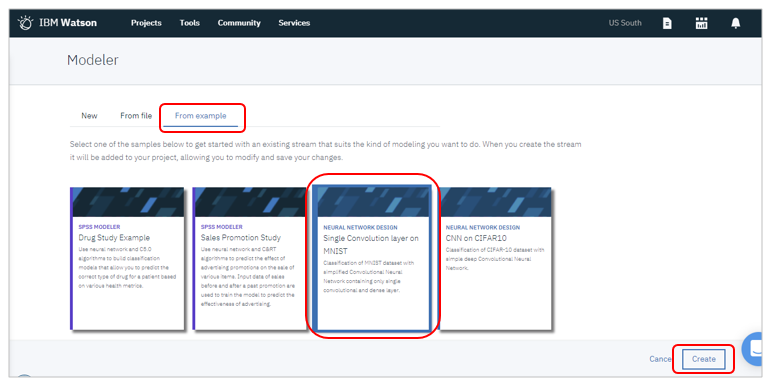
今回は出来合いのチュートリアルで行うので「from example」タブで「Single Convolution layer on MNIST」を選択して「Create」
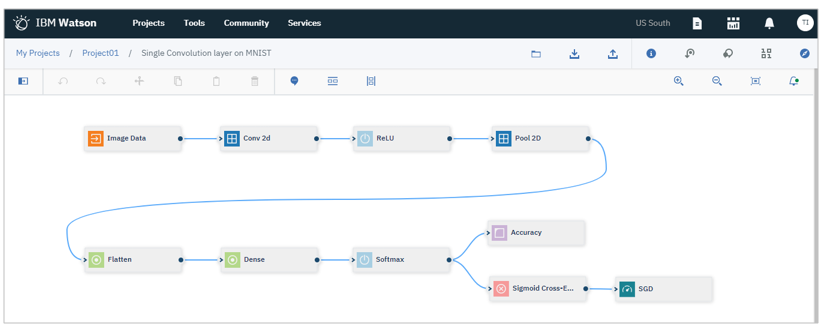
Neural Network Designer
Neural Network Designerが起動してサンプルのフローが表示されます
![]() 今は使いませんが、下記の赤い丸のマークをクリックすると左側にパレットが表示されます。実際はここからドラッグ&ドロップでニューラルネットワークをデザインしていきます。
今は使いませんが、下記の赤い丸のマークをクリックすると左側にパレットが表示されます。実際はここからドラッグ&ドロップでニューラルネットワークをデザインしていきます。
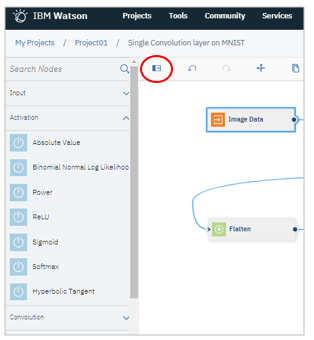
入力となるMNISTの画像ファイルを定義します。開始点の「Image Data」を右クリックして「Open」
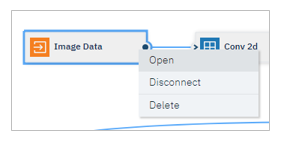
右側にパネルが表示されるので、以下の手順で先ほどICOSにアップしたファイルを指定します
- 先頭の「DATA」セクションを展開
- 「Create a connection」ボタン
- Data Connectionのドロップダウン・リストから「Connection to project COS」を選択
- 「Bucket」は入力ファイル用のBucket
- トレーニング・データ、テスト・データ、検証用データのファイルを各々指定
- 「Save」ボタン
![]() このへん、ちと操作がややこしいので、ご参考動画です。
このへん、ちと操作がややこしいので、ご参考動画です。

このサンプル・フローはデフォルトでも良い精度が出る3はずです。
Training DefinitionのPublish
ではニューラル・ネットワークのトレーニング定義をPublishします。
右上の上向きの矢印のアイコンをクリックし、お好みで名前を指定します。
Select WML InstanceでWatson Machine Learningのインスタンスを指定して「Publish」
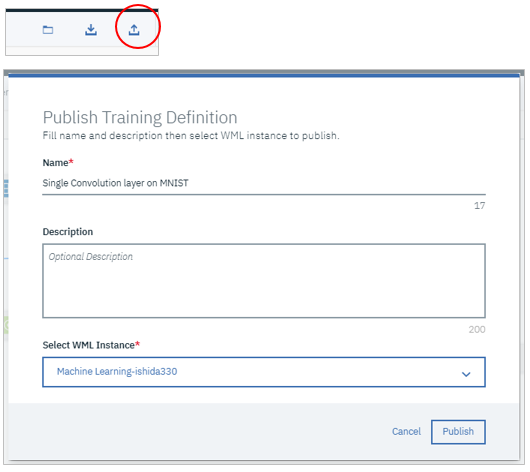
成功しました
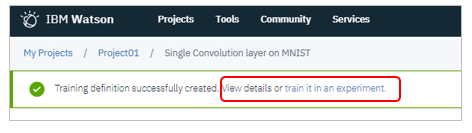
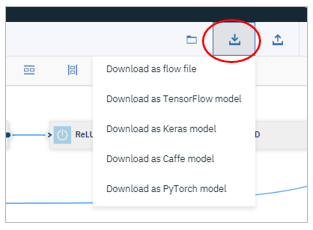
(オプション)Training Definitionのダウンロード
オプションですが、デザイナー上の定義を各フレームワーク用のソースコードに変換した結果をダウンロードできます。中身にご興味がある方は、見てみるとよいかと。
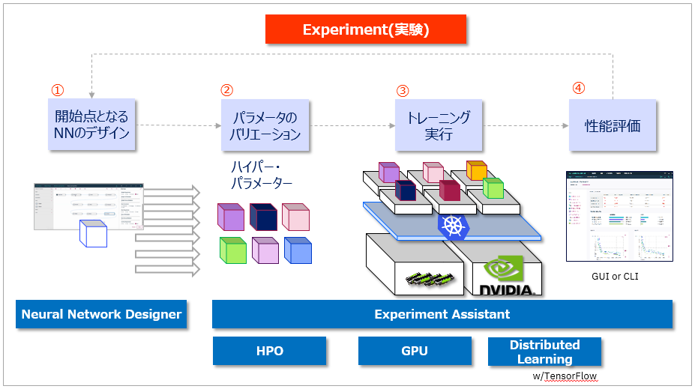
独自のソースコードがあり、前述のGUIベースのNeural Network Modelerを使わない場合は、モデルを定義するフレームワークのソースとトレーニング定義を準備すれば、コマンドやPython Clientを使ってExperiments(実験)を実行できます。トレーニング定義とは、下記のようなJSONファイルです。ドキュメントCreate a Training definitionに説明があります。
Training Definitionの例
Experiment(実験)の定義
トレーニング定義を使ってExperimentを定義します。
Publishが成功したら、「train it in an experiment」のリンクをクリック
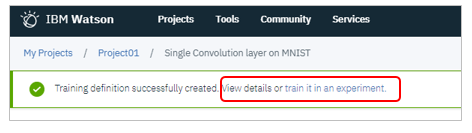
![]() プロジェクトのAssetタブで「Experiments」を追加するのでも結構です。同じです。
プロジェクトのAssetタブで「Experiments」を追加するのでも結構です。同じです。

お好みの名前を指定して①ICOS ②トレーニング定義(さっきPublishしたもの)を各々指定します。以下、順を追ってご紹介します。
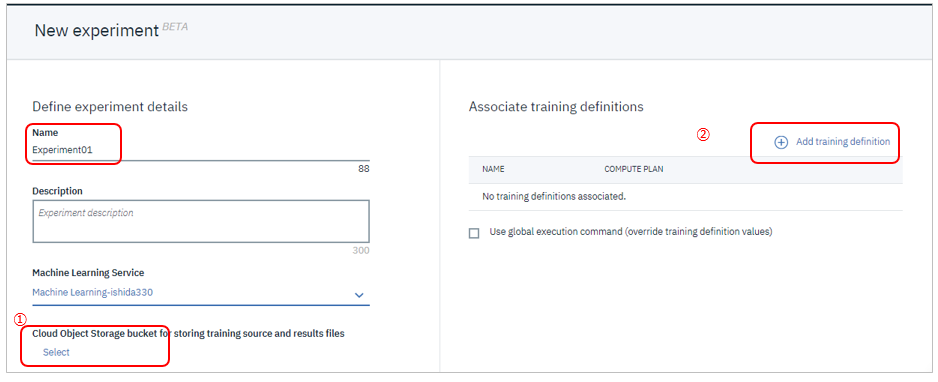
![]() (パネル左側) 入出力に使うオブジェクト・ストレージの指定
(パネル左側) 入出力に使うオブジェクト・ストレージの指定
「Select」でパネルが開くので、「Existing connections」タブから下記を指定して「Select」ボタン
- ICOSへのコネクション
- トレーニング・データの入っているBucket
- 実行結果を出力するBucket
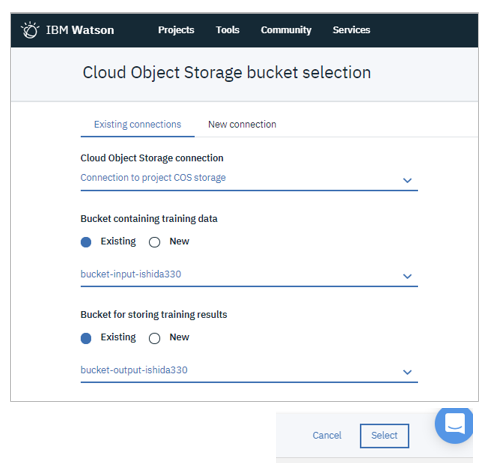
結果、以下のようになります
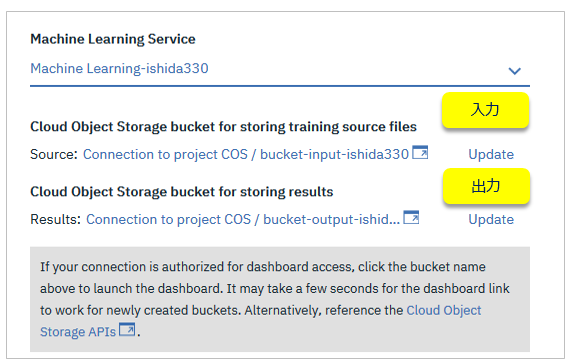
![]() (パネル左側) Training Definition
(パネル左側) Training Definition
右上のAdd training definitionボタンでパネルが開くので、「Existing training definition」タブを選択。ここでGPUの種類やハイパーパラメーター最適化の設定を行います。
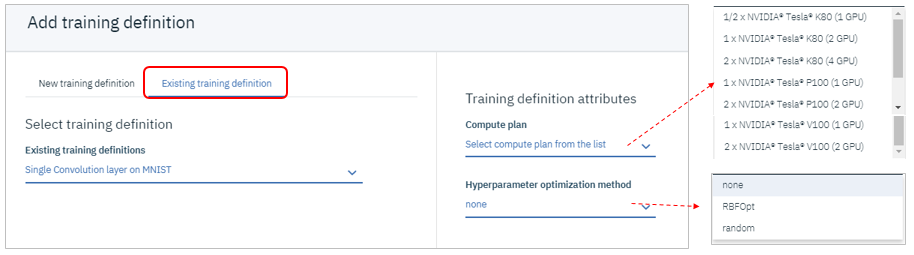
下記を指定して「Select」ボタン
- Compute PLAN - 1/2 x NVIDIA Tesla K80(1GPU)
- Hyperparameter optimization method - none
![]() UIの構造からおわかりの通り、1つのExperimentには複数のTraining Definitionを登録できます
UIの構造からおわかりの通り、1つのExperimentには複数のTraining Definitionを登録できます
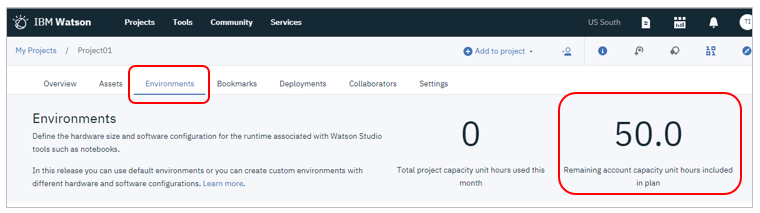
![]() 無償のライトアカウントでは50Capacity Unit Hoursまで使えます。Environmentタブで確認できます
無償のライトアカウントでは50Capacity Unit Hoursまで使えます。Environmentタブで確認できます
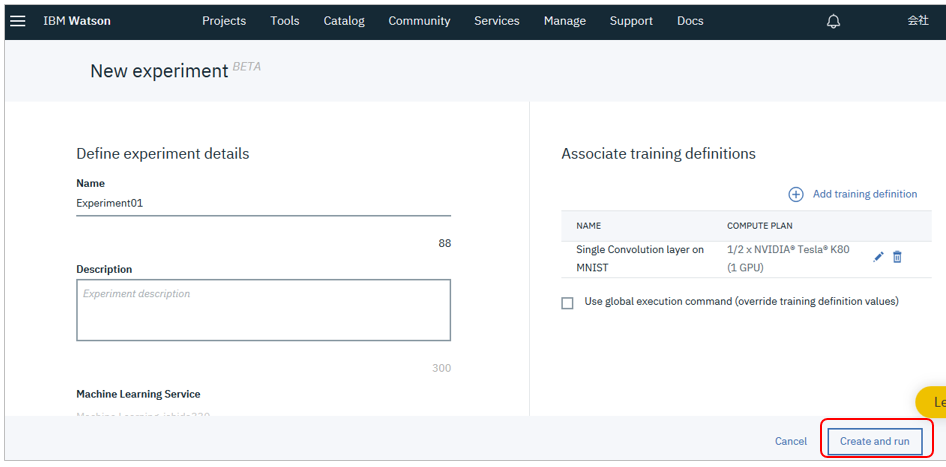
Experiment(実験)の実行
指定が完了したら、モデルのトレーニングを実行しましょう。「Create and Run」ボタン
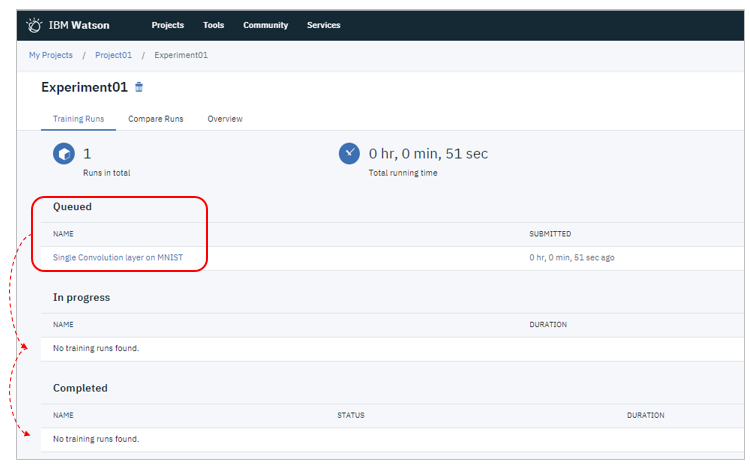
起動直後はキューで実行待ち状態ですが、時間経過と共に状態が変わっていきます
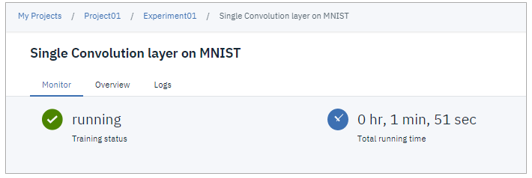
実行中(および完了後)にトレーニングの名前をクリックすると

状況や実行ログを参照できます
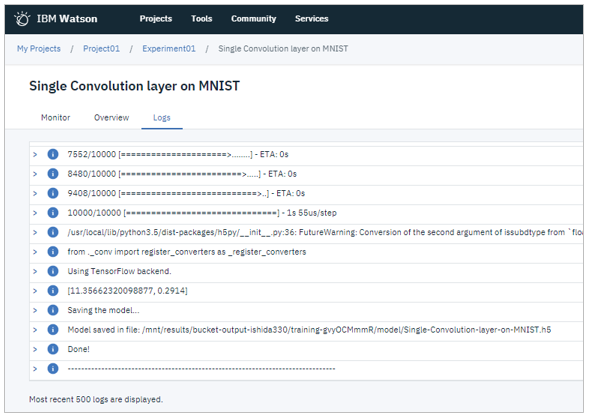
トレーニングは2分半で完了しました。トレーニングの結果がサマリー表示されます。VAL_ACCが97.6%なので良好な結果といえると思います。

| カラム | 意味 |
|---|---|
| ACC | トレーニング・データに対する精度(Accuracy) |
| LOSS | トレーニング・データに対する損失関数の値 |
| VAL_ACC | 検証データに対する精度(Accuracy) |
| VAL_LOSS | 検証データに対する損失関数の値 |
![]() 一般にAccuracyは大きいほうが性能が良く、損失関数の値は小さいほうが性能が良いと解釈4します。
一般にAccuracyは大きいほうが性能が良く、損失関数の値は小さいほうが性能が良いと解釈4します。
トレーニングの名前をクリックすると「Monitor」パネルでトレーニングの精度や進み具合が見られます。実行ログから値を地道に拾わずに済みます。
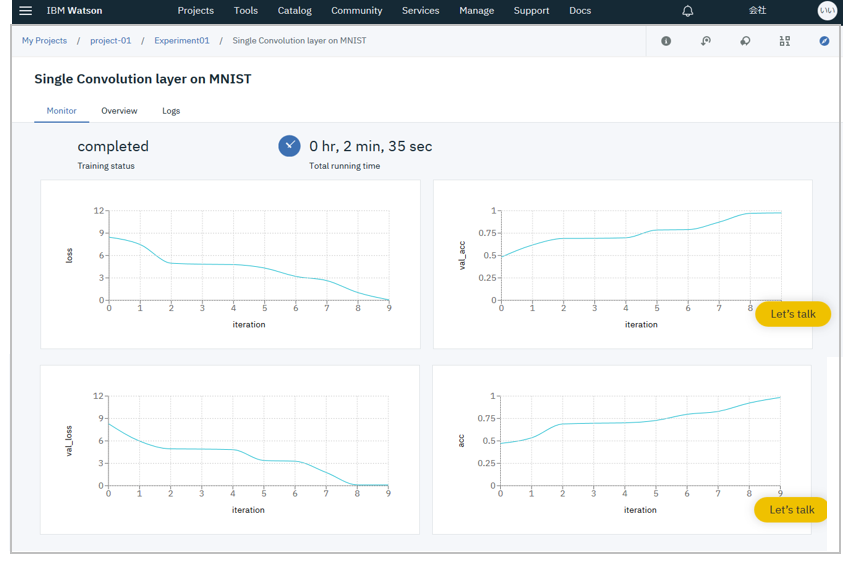
今は1ジョブしかありませんが「Compare」タブでは複数の実行の比較もできます
実行ログや訓練後のモデルはICOSの出力Bucketに保管されています。モデルは.h5の形で永続化されているので再利用もできます。
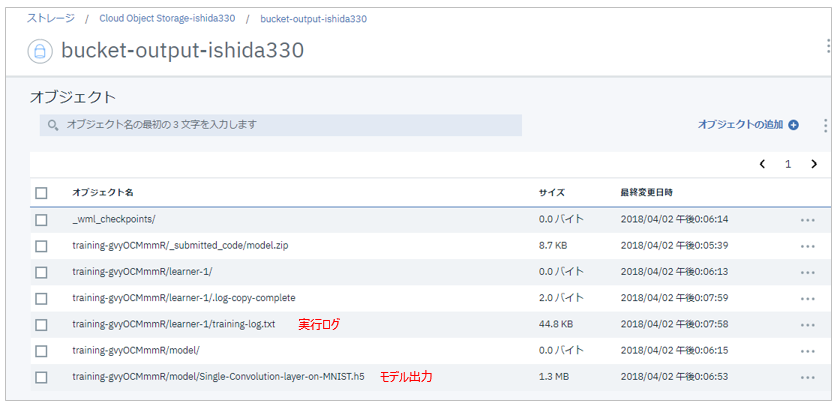
ご参考資料として実行ログをここに掲載しておきますね。10回トレーニングを繰り返している様子が見られると思います。
モデルの保管
本来はニューラル・ネットワーク・モデルのトレーニングは前項のデザインやパラメータを変えて何度も繰り返すプロセスでしょうが、ここでは「満足できる性能が出た」ものとして、モデルを保管します。
モデルの右端の「Action」で「Save Model」

お好きな名前を付けて「Save」
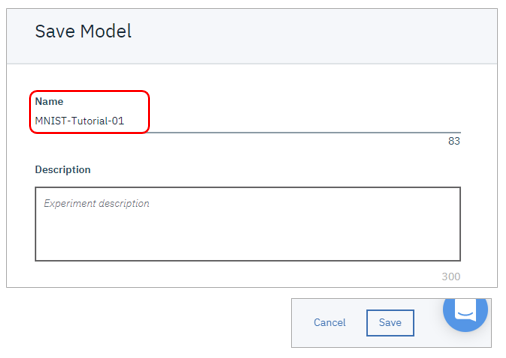
Saveできました
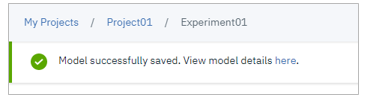
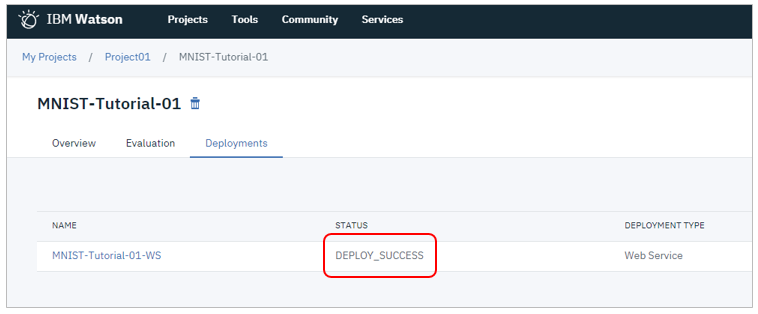
プロジェクトのAssetタブの「Watson Machine Learning models」に登録されています

モデルのデプロイ
ではデプロイです。メッセージの「View model details here」のリンクをクリックするか、またはダッシュボードからModelsの名前をクリックして、モデルを開きます。
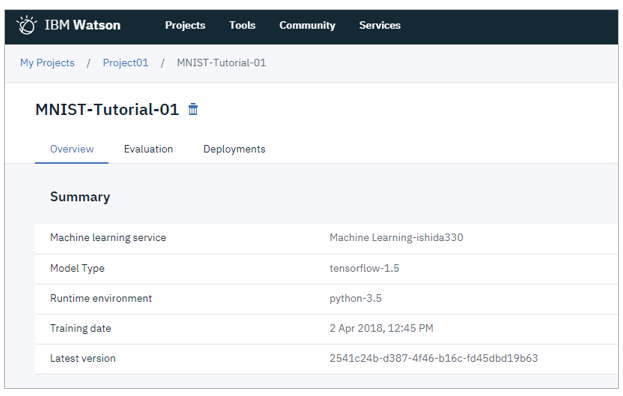
「Deployments」タブで「Add deployent」
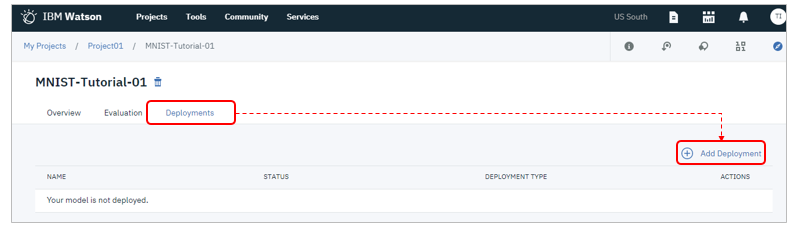
今回はRESTのWebサービスとしてデプロイしましょう。お好みの名前を指定して「Web Service」ボタン5を選んで「Save」
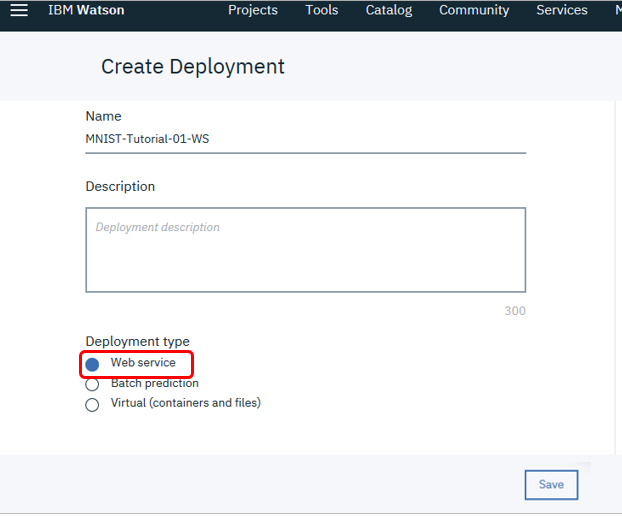
デプロイされました
モデルの利用
では実際にMNISTの手書き文字を認識させてみます。
サービスをクリック
パネルが表示されます
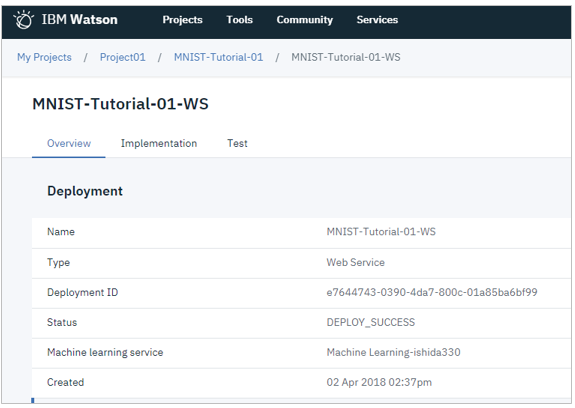
「Test」タブでUIを用いて対話式にテストできます。
![]() 「Implementation」タブではRESTエンドポイントやサービスを呼び出すためのコード・スニペットが表示されます。資格情報だけ書き換えれば、そのままコピペで動くので便利です。
「Implementation」タブではRESTエンドポイントやサービスを呼び出すためのコード・スニペットが表示されます。資格情報だけ書き換えれば、そのままコピペで動くので便利です。
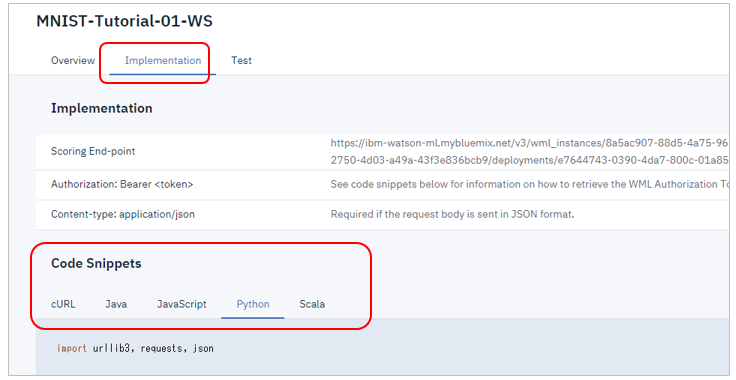
では実際にRESTエンドポイントをUIでテストします。
【Fast Path】~デモなどで、とにかく動かしてみたい方へ
Githubの「ここ」に以下のイメージのjson表現6を置いてあります。
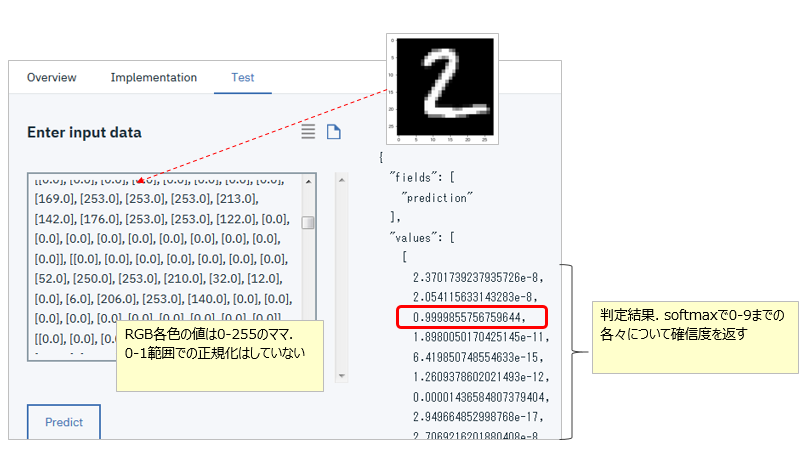
「Enter Input Data」欄に上記ファイルの中身(長いです)を全部コピペして、「Predict」ボタンを押すと、右側に判定結果が表示されます。今回のチュートリアルのフローはsoftmaxを使っているので、イメージが0-9の各々の文字である確信度が10エントリーのリストとして返ってきます。はじめ([2]番目の値が0.9999855756759644で最も大きいので、イメージを「2だ」と判定していることがわかります。
【細かく】~サービスのI/Oをきちんと理解したい方へ
そもそも、今回のチュートリアルのフローをRESTでスコアリングするときの入力と出力はどういう形になるのでしょうか。Machine Learningでは、普通はテキストのjsonデータを投げて予測結果を受け取りますが、今回は入力はイメージです。実は、私もわからなかったのでStackoverflowで聞いてみました。結果、要は下記です。
![]() イメージデータの入力は初めにConv2Dで処理されるので、Tensorflowのtf.nn.conv2dで期待しているinputの形、すなわち [batch, in_height, in_width, in_channels] の4次元の形式になります。
イメージデータの入力は初めにConv2Dで処理されるので、Tensorflowのtf.nn.conv2dで期待しているinputの形、すなわち [batch, in_height, in_width, in_channels] の4次元の形式になります。
Given an input tensor of shape [batch, in_height, in_width, in_channels]
今回はshapeとしては[1,28,28,1]の形式です。(バッチサイズは1枚のイメージなので1、pixelは28x28、in_chanelsは白黒なので1) 上記に沿って作ったjsonが前掲のJSONファイルです。
別のイメージを入力したい方のために、ここにお好きなMNISTデータをJSONに変換するノートブックをおきましたので、よろしければご利用ください。
![]() 同様に出力(判定結果)はSoftmaxを使っているので判定結果は0-9の各々についての確信度がリストで返ります。
同様に出力(判定結果)はSoftmaxを使っているので判定結果は0-9の各々についての確信度がリストで返ります。
(おまけ)作った手書き数字認識モデルを使ってみよう!(node.js)
技術系ブログ まだプログラマーですが何か?とマンホールで有名なきむらさんが、当記事のフォローで「IBM Watson に MNIST の手書き数字を学習させて問い合わせするサンプル」という記事を書いてくれました。当記事で作ったモデルを使って、ブラウザー上で書いた手書きの数字イメージを認識させるアプリを公開してくれています。要はこんなの↓↓
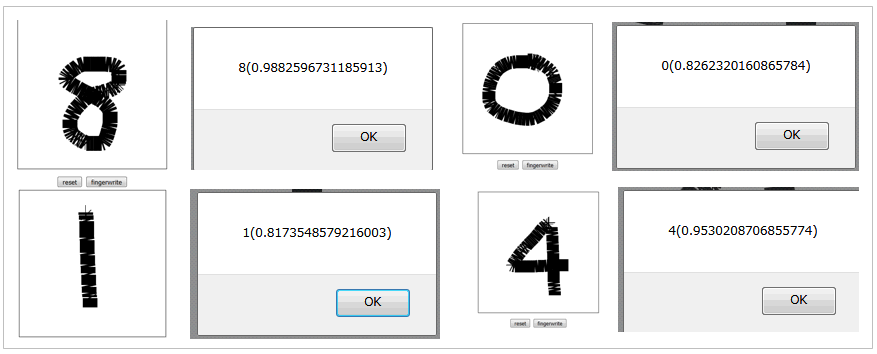
サイト上でサンプルアプリが動いていますし、ソースをgit cloneして自分のPCのnode.jsで動かすのも、bx cf pushでIBM Cloud上で動かすのも簡単です。ご興味あればお試しくださいませ~。きむらさん、あざす!![]()
(おまけ2)作った手書き数字認識モデルを使ってみよう!(Python)
@makaishi2さんも記事「Watson Studioで学習した深層学習モデルをアプリケーションから呼び出す」でモデルをPythonアプリから呼び出すサンプルを公開してくれています。あざす!
以上、MNISTデータセットを入力にして、NNモデルのトレーニング、デプロイ、利用までEnd-to-Endでご紹介しました。ライト・アカウントでもお試しできますし、他にもNeural Network Designのサンプルが揃ってますので、皆様もお試しくださいませ。ではHappy Deep-Learning ! ![]()
改定履歴
(2018/05/10) 以下の誤りを訂正しました
- ICOSのHMACキーを生成しなくてもBucketにアクセスできるので記述削除
- トレーニング定義の例がフロー定義になっていたので訂正
(2018/5/11) 以下を追記しました
- Neural Network Designerのデフォルト・フローでExperimentを実行した際にモデル精度が良くない時の改善方法を追記
- きむらさんの記事をご紹介で追記
(2018/5/22) 以下を追記しました
- 英語のBlog記事 Deep Learning and Watson Studioをご紹介
(2018/8/14) 記事執筆時点以降に各種の変更がされたので、記事内容の更新&画面イメージの取り直しを行いました。サービスの主な変更点は以下です。
- プロジェクトとサービスの関連付けでWatson Machine Learningは「Watson」区分になった(「Machine Learning」という区分が無くなった)
- サンプルMNISTの生成するロジックが一新され①RGB値の標準化(÷255)が行われなくなった② Accuracy, Loss Funcなどの値を返すようになった ③フローのSGDがADAMに変更されデフォルト設定でも良い精度が出るようになった
- Experiment上でAccuracyなどの性能情報を表示できるようになった-
-
先々、AutoAIに旧NeuNetSの流れのディープラーニング系の新機能が搭載されるとの噂あり。時期不明。
 当記事は2018/04に公開したのですが、その後の変更で記事内容や画面コピーが古くなりました。よって2018/08月時点でアップデートしました。
当記事は2018/04に公開したのですが、その後の変更で記事内容や画面コピーが古くなりました。よって2018/08月時点でアップデートしました。 -
以前はMachineLearningというエントリーがありましたが、Watsonに統合されました ↩
-
 4月時点で提供されていたサンプルは、デフォルトだとモデル性能が悪かったので、性能を上げるためのチューニング情報を記載していました。その後サンプルが改善されデフォルトでも97%以上の精度が出るようになったので、以前の記述は削除しました。 ↩
4月時点で提供されていたサンプルは、デフォルトだとモデル性能が悪かったので、性能を上げるためのチューニング情報を記載していました。その後サンプルが改善されデフォルトでも97%以上の精度が出るようになったので、以前の記述は削除しました。 ↩ -
ただしACC>VAL_ACCで、かつ進行に従いVAL_ACCがだんだん小さくなっていく傾向がある場合はトレーニングデータに最適化されている=過学習といえますので、望ましくありません ↩
-
Virtual(containers_and_files)はCoreML用です ↩
-
当初提供されていたサンプルフロー中のロジックでは、RGBの各色の値(0-255)は÷255されて0-1の範囲に標準化されていました。最近の変更でこの標準化が無くなり0-255のままの値で処理するようになっています。よって以前の標準化されたテストデータでテストすると正しい判定結果になりませんのでご注意ください。 ↩