はじめに
Watson Studioで学習した深層学習モデルは、マウスをクリックするだけであっという間にWebサービス化することが可能で、深層学習モデルのオンラインアプリを作る上で大変便利です。
しかし、深層学習モデルの場合、入力データの作り方が難しいこともあり、アプリケーションを作ることそのものが結構大変だったりします。
そこで、対象データをMNIST / CIFAR-10にした典型的な深層学習モデルのWebサービスを呼び出すサンプルアプリケーションを作ってみました。
実装したアプリの画面イメージは下記のようになります。


2つのアプリケーションはソースコードをGithubにも公開しておきました。
そのリンク先は下記になります。
アーキテクチャ
アプリケーションのアーキテクチャーは「ブラウザ」-「Webサーバー」-「Watson ML」の3階層です。
基本的なトポロジーはWatson APIを使ったNode.jsアプリの標準実装パターンで紹介したものと同じなのですが、1点だけ違うのはサーバーサイドの実装をNode.jsでなくPython+Flaskにした点です。
この理由は以下の2つです。
- ブラウザ側でアップした写真データは、解像度を変えたり、Python numpy形式に変換したりと,Webサービスの引数にするまでに加工が必要なのですが、このあたりの実装は明らかにPythonが楽。
- サーバーサイドのAPI呼出しはトークン取得、API起動の2ステップ必要(Watson APIの場合は1ステップでよかった)。API呼出しごとにCallback関数の実装が必要なNode.jsでは実装が大変。
要は、楽をするためにPythonを使ったということになります。
前のNode.jsの時の記事同様に「主要ファイル構成と、実行環境の関係」「実行時のコンポーネント間の呼出し関係」の2つの観点で図を作ると、下記のようになります。
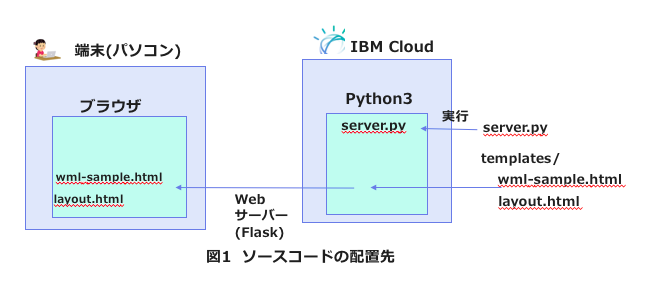

ちなみに、このような構成をIBM Cloud上でデプロイするためのTipsに関しては別記事FlaskアプリをIBM Cloudにデプロイするに書いておきました。
コード解説
それでは、実際のコードの解説をクライアントサイド、サーバーサイドのそれぞれについて行いたいと思います。
クライアントサイド
「分析」ボタンがクリックされると
$(function(){
$('#predict').click(predict)
});
の定義によりpredict関数が起動されます。この関数の実装は下記
function predict() {
call_flask( 'GET', '/predict',
function(XMLHttpRequest,textStatus,errorThrown){alert('error');} );
}
要は、最終的にcall_flask関数が呼ばれることになります。
この関数の実装は次のとおりです。
function call_flask( type, url, error ) {
var elem = document.getElementById("result");
elem.innerHTML = '';
svg.selectAll("g").remove()
var form = $('#fileUploadForm')[0];
var data = new FormData(form);
$("#send").prop("disabled", true);
$.ajax({
type: "POST",
enctype: 'multipart/form-data',
url: "/predict",
data: data,
processData: false,
contentType: false,
cache: false,
timeout: 600000,
success: function (data) {
console.log('predict callback')
ar = JSON.parse(data)
ar.reverse()
ds2 = []
for ( i = 0, j = 9; i < ar.length; i++, j-- ) {
item = {'name' : j + "", 'value' : parseFloat(ar[i]) }
ds2.push(item)
console.log('data' + i + ':' + ar[i]);
}
console.log(data);
console.log(ds2);
draw_graph(ds2);
$('#result').text(data);
}
});
}
イメージデータをenctype: 'multipart/form-data'を使ってファイルアップロードしているだけです。
ファイルアップロード用のHTMLについては、以下のような形で実装しています。
<form action="/send" method="post" enctype="multipart/form-data" id="fileUploadForm">
<br>
<input type="file" id="image" name="image" accept="image/*">
<br>
<br>
<input type="button" name="button" value="分析開始" id="predict"/>
</form>
この他、クライアントサイドの実装でややこしいのはd3jsを使って棒グラフを書くところですが、記事の本題からはそれるので、解説は別の機会でということにします。
サーバーサイド
サーバーサイドの/predictリクエストに対する実装は以下のとおりです。
@app.route('/predict', methods=['POST'])
def predict():
print('/predict')
image = request.files['image']
if image and allowed_file(image.filename):
filename = secure_filename(image.filename)
imagefile = os.path.join(app.config['UPLOAD_FOLDER'], filename)
image.save(imagefile)
img = Image.open(imagefile)
img2 = ImageOps.grayscale(img)
img_resize = img2.resize((28, 28))
ftitle, fext = os.path.splitext(imagefile)
#img_resize.save(ftitle + '_sam' + fext)
im = np.array(img_resize)
im_data = np.uint8(im)
pil_img_gray = Image.fromarray(im_data)
pil_img_gray.save(ftitle + '_mono' + fext)
im_data2 = im_data.reshape(28, 28, 1)
im_data3 = 1- im_data2.astype("float32")/255 # invert image
im_max = im_data3.max()
im_min = im_data3.min()
im_data4 = (im_data3 - im_min) / (im_max - im_min)
im_data5 = im_data4.tolist()
print(im_data5)
# トークン取得
auth = '{username}:{password}'.format(username=wml_credentials['username'], password=wml_credentials['password'])
headers = urllib3.util.make_headers(basic_auth=auth)
url = '{}/v3/identity/token'.format(wml_credentials['url'])
response = requests.get(url, headers=headers)
print(response)
mltoken = json.loads(response.text).get('token')
print('mltoken = ', mltoken)
# API呼出し用ヘッダ
header = {'Content-Type': 'application/json', 'Authorization': 'Bearer ' + mltoken}
payload_scoring = {"values": [im_data5]}
# API呼出し
response_scoring = requests.post(scoring_url, json=payload_scoring, headers=header)
res = json.loads(response_scoring.text)
ret_list = res['values']
ret0 = ret_list[0]
ret1 = [round(n, 3) for n in ret0]
print(json.dumps(ret0, indent=2))
return json.dumps(ret1)
大きくは「File保存」「イメージデータ加工部分」と「Watson ML呼び出し部分」に分けられれます。
ファイル保存部分
ブラウザからアップロードしたファイルをいったんローカルに保存します。
以下のコード部分が該当します。
image = request.files['image']
if image and allowed_file(image.filename):
filename = secure_filename(image.filename)
imagefile = os.path.join(app.config['UPLOAD_FOLDER'], filename)
image.save(imagefile)
イメージデータ加工部分
対象データがNMISTである場合、次のような実装ロジックです。
img = Image.open(imagefile)
img2 = ImageOps.grayscale(img)
img_resize = img2.resize((28, 28))
ftitle, fext = os.path.splitext(imagefile)
im = np.array(img_resize)
im_data = np.uint8(im)
pil_img_gray = Image.fromarray(im_data)
pil_img_gray.save(ftitle + '_mono' + fext)
im_data2 = im_data.reshape(28, 28, 1)
im_data3 = 1- im_data2.astype("float32")/255 # invert image
im_max = im_data3.max()
im_min = im_data3.min()
im_data4 = (im_data3 - im_min) / (im_max - im_min)
im_data5 = im_data4.tolist()
画像のサイズ変更、グレースケール化、白黒反転、コントラスト強調(max=1, min=0)などの加工を行っています。
最終的にはnumpyの関数を使って、(28,28,1)のサイズのものをリスト化しています。
このあたりの加工がPythonでないと難しいところです。
入力データがndarrayの形でできあがったら、最後は``tolist()`関数でリスト化します。
ちなみに、CIFAR-10用の加工処理は次のとおり
img_resize = img.resize((32, 32))
ftitle, fext = os.path.splitext(imagefile)
img_resize.save(ftitle + '_sam' + fext)
im = np.array(img_resize)
print( 'shape1: ', im.shape)
im_data = np.uint8(im)
im_data2 = im_data[:,:,:3]
im_data3 = im_data2.astype("float32")/255
print( 'shape2: ', im_data3.shape)
im_data4 = im_data3.tolist()
こちらは、入力データの方がnumpyの(1,32,32,3)を期待しているので、そのように加工しているのですが、自分でもよくわかっていないのはim_data2 = im_data[:,:,:3]のところ。
その前のim = np.array(img_resize)の処理で(32,32,3)のサイズのarrayができるものと思っていたのですが、どうも最後の次元が4次元になっていて、そのままパラメータで渡すと型が合わないというエラーになってしまうのです。
4番目の要素の値がいつも255になっているみたいだったので、上のようなコーディングで4つめの要素を落としています。これで船とかネコとかちゃんと認識できているので、ロジックはあっているようなのですが、なぜこうなるかはまだわかっていません。
Watson ML呼出し部分
Watson ML呼出し部分の実装は下記のとおりです。
# トークン取得
auth = '{username}:{password}'.format(username=wml_credentials['username'], password=wml_credentials['password'])
headers = urllib3.util.make_headers(basic_auth=auth)
url = '{}/v3/identity/token'.format(wml_credentials['url'])
response = requests.get(url, headers=headers)
print(response)
mltoken = json.loads(response.text).get('token')
print('mltoken = ', mltoken)
# API呼出し用ヘッダ
header = {'Content-Type': 'application/json', 'Authorization': 'Bearer ' + mltoken}
payload_scoring = {"values": [im_data4]}
# API呼出し
response_scoring = requests.post(scoring_url, json=payload_scoring, headers=header)
res = json.loads(response_scoring.text)
一見すると長くて大変そうなのですが、実はそうではありません。
Watson Studioでは実装コードの言語別雛形を自動的に生成する機能を持っていて、それをそのままコピペすれば済むからです。地味ですが、使い慣れるとなかなか便利な機能と思っています。
具体的な画面例は以下のとおりです。
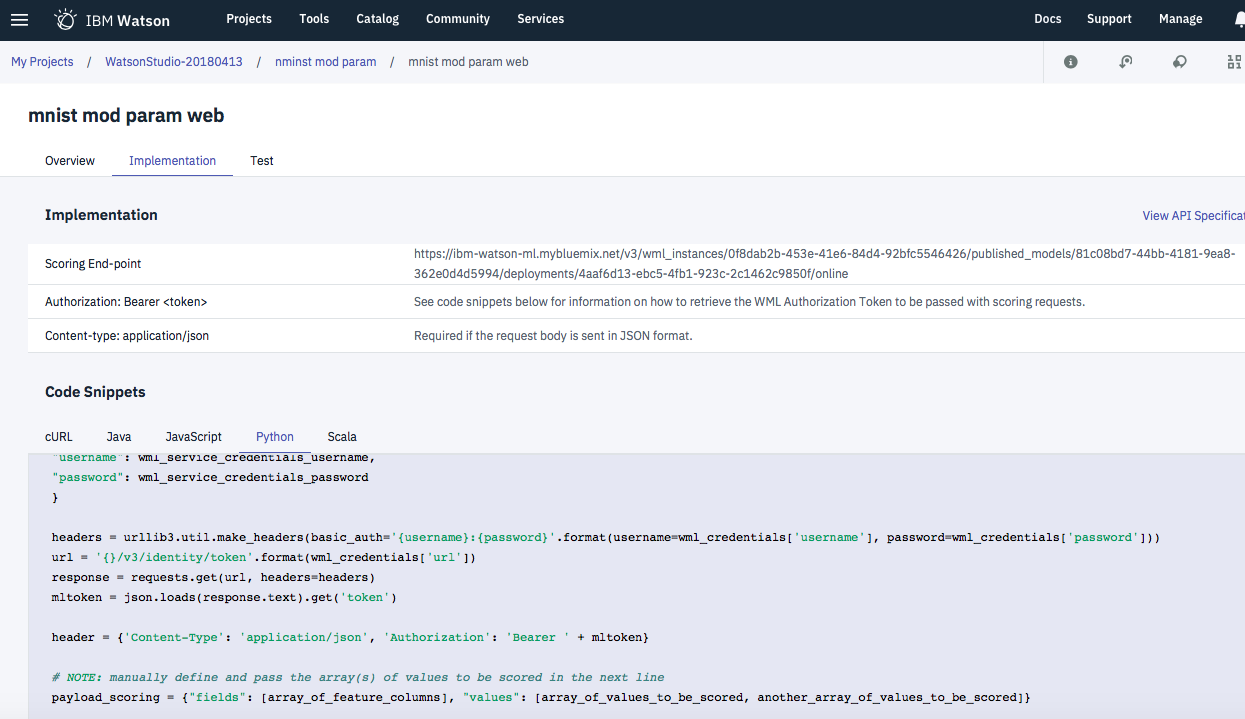
あとは、注意すべき点としては、パラメータデータを作る際に、前のステップで生成したListデータをもう一回(外側に)配列化するところです。(コードでいうとpayload_scoring = {"values": [im_data4]}のところ)。複数の引数を同時に受け付けるようなインターフェイスのため、こういうルールになっているようです。
IBM Cloud環境へのデプロイ手順
IBM Cloud環境へのデプロイ手順に関しては、冒頭で紹介したGithubのReadME.mdに記載しているので、そちらを参照されて下さい。
CFコマンドが使えるようになっていれば、あっという間に動くようになります。
呼出し先のWebサービスを作る手順
MNISTに関しては、Watson Studioのディープラーニング機能(DLaaS)を使ってみたがわかりやすくていいと思います。
CIFAR-10に関してはWatson Studioで深層学習。KerasサンプルアプリをGPU+TensorBoardで動かすを参考とされて下さい。