はじめに
この3月に発表されたWatson Studioでは、バックエンドのWatson Machine Learningと連携して、時間課金のGPUでKerasをフレームワークとした深層学習モデルを動かすことができます。
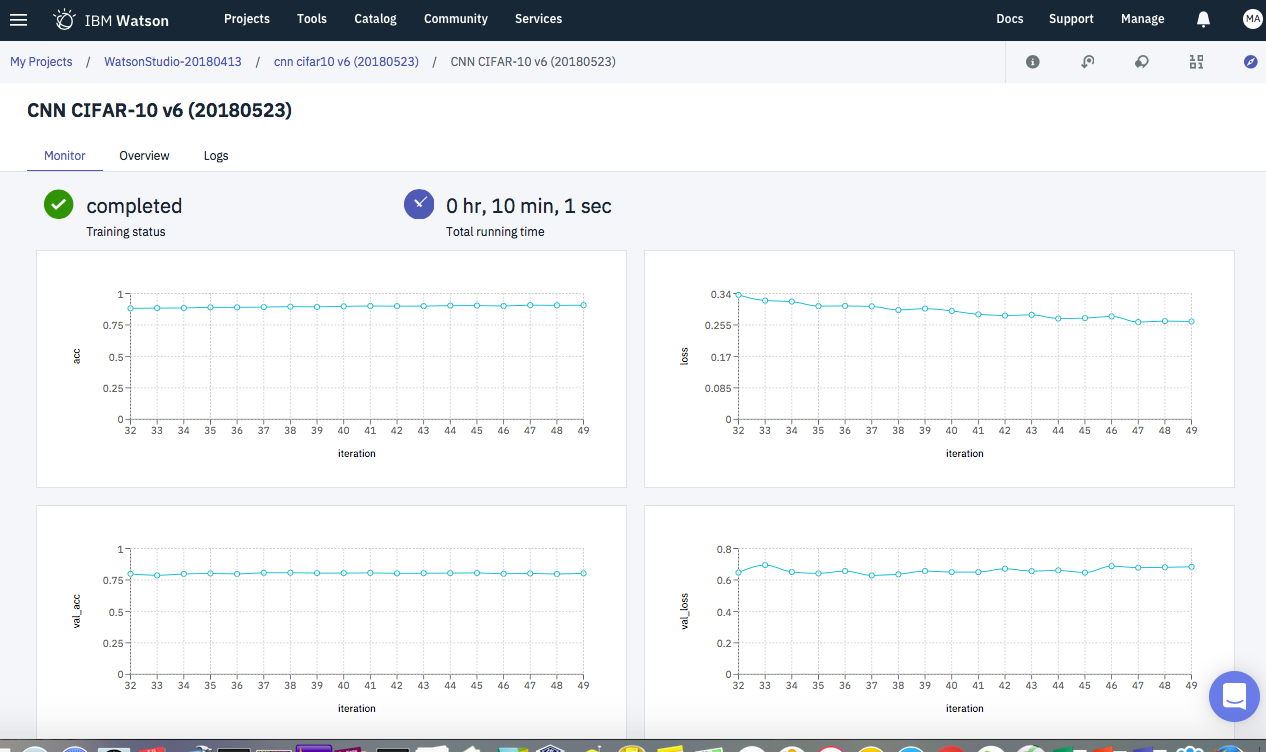
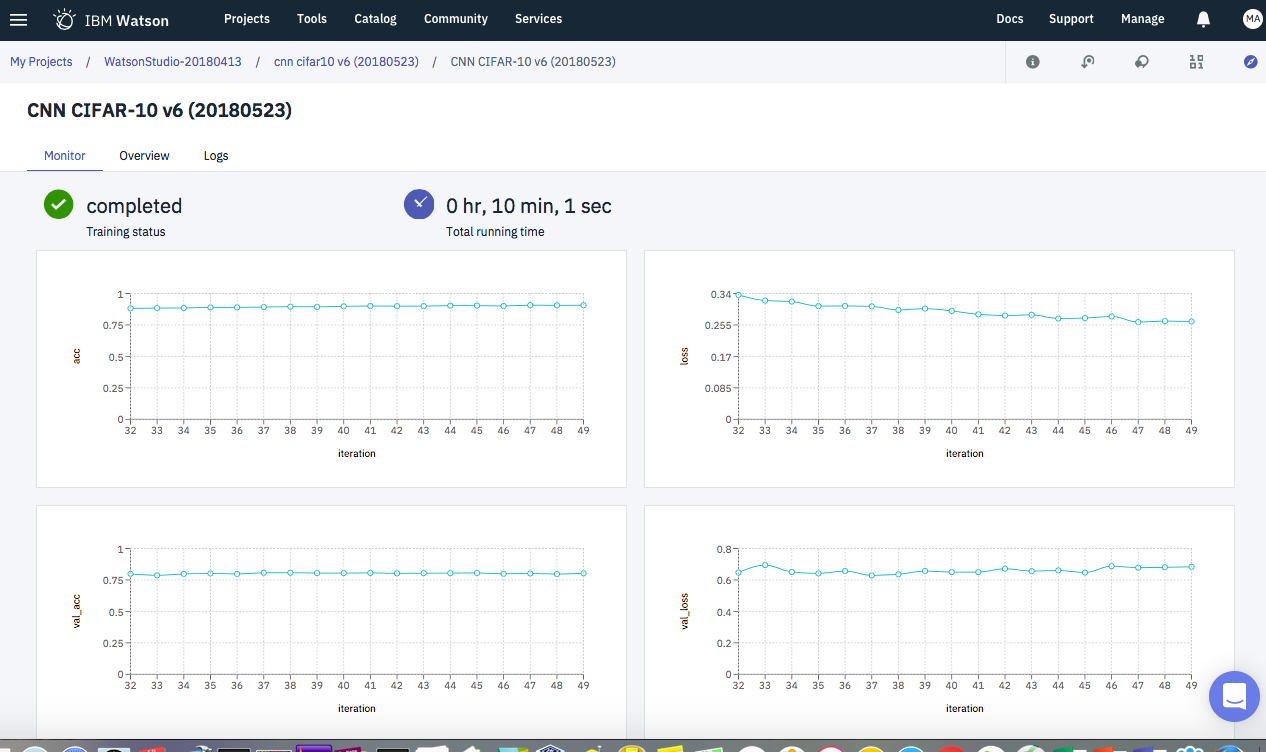
また、学習時の様子はTensorBoardで確認可能です。
実際の実行時の画面サンプルを添付します。
設定手順
Watson Studioの深層学習版はまだベータ版で一部未完成な点があり、上のような結果を得るのには現段階では工夫が必要です。
主なステップは
- バケットの定義、学習用データのアップロード
- コーディング
- Defintionの登録
- Experimentの登録・実行
となります。
このうち「コーディング」と「Defintionの登録」をコマンドで、「バケットの定義、学習用データのアップロード」と「Experimentの登録・実行」をGUIで行う方法をとりました。
以下にその手順の概要を記載します。
パケットの定義、学習用データのアップロード
Object Storageに「入力用バケット」「出力用バケット」の2つを用意し、「入力用バケット」
に対しては、学習に使う3つのファイル(cifar-10-tf-train.pkl, cifar-10-tf-test.pkl, cifar-10-tf-valid.pkl)をアップロードします。
細かい手順はWatson Studioのディープラーニング機能(DLaaS)を使ってみたとまったく同じなので、そちらを参照されて下さい。
ダウンロードするファイルも、この記事で紹介されているbox linkからダウンロードできます。
コーディング
本来は、Watson StudioのNeural Network Editorでソースコード生成をしたいところなのですが、このツールで生成したソースは、まだTensorBoard連携ができていないようなので、コードの雛形だけツールで生成したものを利用し、Kerasのロジック本体はWebで公開されているCNNサンプルアプリを利用する方法をとりました。
ツールで生成したソースは、dlaas_train.pyとtrain_model.pyの2つのプログラムからなり、前者が後者を呼び出す構造になっています。
私は、前者に関してはまったくそのままのソースを利用しました。
具体的なコードは以下のようになっています。
import errno
import os
import sys
from os import path
from runpy import run_path
DATA_DIR = os.environ["DATA_DIR"]
RESULT_DIR = os.environ["RESULT_DIR"]
# Main script
def main(model_script_name, model_result_name):
model_script_path = path.abspath(model_script_name)
model_result_path = path.join(RESULT_DIR, "model", model_result_name) # Model needs to be stored in $RESULTS_DIR/model (#3660)
print("Starting DL model training...")
print("DATA_DIR: %s" % DATA_DIR)
print("RESULT_DIR: %s" % RESULT_DIR)
print("MODEL_SCRIPT_PATH: %s" % model_script_path)
print("MODEL_RESULT_PATH: %s" % model_result_path)
# Prepare ~/.keras dir which is used to store keras config json
keras_user_home = path.expanduser("~/.keras")
keras_json_path = path.join(keras_user_home,"keras.json")
print("Preparing %s..." % keras_user_home)
os.makedirs(keras_user_home, exist_ok=True) # prepare .keras in user's home
if not path.exists(keras_json_path):
with open(keras_json_path, "w") as keras_json:
keras_json.write("{}")
os.chdir(DATA_DIR)
os.makedirs(path.dirname(model_result_path), exist_ok=True)
model_script = run_path(model_script_path, { "model_result_path": model_result_path })
model = model_script["model"]
print("Done!")
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])
このコードには2つポイントがあります。
1つは、「入力用バケット」としてDATA_DIRで渡されるディレクトリの処理で、このディレクトリをカレントディレクトリに変更した状態で子供のプログラムに制御を渡しています。それで、子供側は入力データに関してはパスは気にせず、ファイル名だけ指定して読み込むことができます。
もう1つはmodel_result_pathで子供のプログラムはこの変数で渡させるパスに学習済みの機械学習モデルを保存するプロトコルになっています。
次に改修済みの子供プログラムのソースを添付します。
# Choose the underlying compiler - tensorflow or theano
import json
import os
with open(os.path.expanduser('~') + "/.keras/keras.json","r") as f:
compiler_data = json.load(f)
compiler_data["backend"] = "tensorflow"
compiler_data["image_data_format"] = "channels_last"
with open(os.path.expanduser('~') + '/.keras/keras.json', 'w') as outfile:
json.dump(compiler_data, outfile)
# Global variable intilization
defined_metrics = []
defined_loss = ""
# pickle データの読み込み
# 読み出し元プログラムの下記コーディングにより、当プログラム呼出し時に
# カレントディレクトリは「入力用バケット」になっている
#
# os.chdir(DATA_DIR)
# model_script = run_path(model_script_path, { "model_result_path": model_result_path })
import pickle
from keras.utils import np_utils
with open('cifar-10-tf-train.pkl', 'rb') as f:
train_data, train_label = pickle.load(f)
train_data = train_data.astype('float32') / 255
class_labels_count = len(set(train_label.flatten()))
train_label = np_utils.to_categorical(train_label, class_labels_count)
with open('cifar-10-tf-valid.pkl', 'rb') as f:
val_data, val_label = pickle.load(f)
val_data = val_data.astype('float32') / 255
val_label = np_utils.to_categorical(val_label, class_labels_count)
with open('cifar-10-tf-test.pkl', 'rb') as f:
test_data, test_label = pickle.load(f)
test_data = test_data.astype('float32') / 255
test_label = np_utils.to_categorical(test_label, class_labels_count)
# 学習繰り返し回数
nb_epoch = 50
# 1回の学習で何枚の画像を使うか
batch_size = 128
# TessorBloard初期化
import os
from os import environ
from keras.callbacks import TensorBoard
# writing metrics
if environ.get('JOB_STATE_DIR') is not None:
tb_directory = os.path.join(os.environ["JOB_STATE_DIR"], "logs", "tb", "test")
else:
tb_directory = os.path.join("logs", "tb", "test")
os.makedirs(tb_directory, exist_ok=True)
tensorboard = TensorBoard(log_dir=tb_directory)
# CNNモデル生成
# 必要ライブラリのロード
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense, Activation
def cnn_model(X_train, class_labels_count):
model = Sequential()
model.add(Conv2D(32, (3, 3), padding="same", input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(class_labels_count))
model.add(Activation('softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
return model
# モデル生成
model = cnn_model(train_data, class_labels_count)
# 学習
# コールバック関数にTensorboardを指定する
history = model.fit(
train_data, train_label, batch_size=batch_size, epochs=nb_epoch, verbose=1,
validation_data=(val_data, val_label), shuffle=True, callbacks=[tensorboard]
)
# テストデータで認識率計算
test_scores = model.evaluate(test_data, test_label, verbose=1)
print(test_scores)
# モデルの保存
#
# 呼出し元プログラムによりmodel_result_pathが設定されている
# 設定されていない場合は"./keras_model.hdf5"に保存
#
print('Saving the model...')
if 'model_result_path' not in locals() and 'model_result_path' not in globals():
model_result_path = "./keras_model.hdf5"
model.save(model_result_path)
print("Model saved in file: %s" % model_result_path)
このコードの最初の特徴は入力データの扱いです。前に説明したようにプログラムからは入力バケットがカレントディレクトリとしてアクセス可能になっています。元々、ツールで生成したソースでは入力データにあるpickelファイルをPythonのオブジェクトに変換するプロトコルだったので、この方式はそのまま踏襲しました。
次の特徴はTensorBoardオブジェクトを作っている点です。このオブジェクトを、学習実施時のコールバックパラメータで渡すことにより、Watson StudioとしてのTensorBoard連携が可能になります。
最後の特徴は、model_result_pathで渡されるパスにモデルの保存を行っている点です。
この3つ以外の点は、ごく普通のKerasによるDeep Learningのプログラムであることがサンプルを見てわかると思います。つまり、この部分だけ自分のコードに差し替えれば、自動的にWatson Studioの基盤環境の特徴を使えることになります。
Jupyter Notebook(Watson Studioではこの環境も持っています)などで、子供のプログラムのデバッグが完了したら、次のコマンドで、親プログラムとあわせて一つのzipファイルに圧縮します。
$ zip model-cnn-v5.zip dlaas_train.py cnn-cifar10-v5.py
このzipファイルについては、githubにアップしておきました。
このファイルをWatson Studioの下記の画面から、Data Assetsとしてアップロードしておきます。
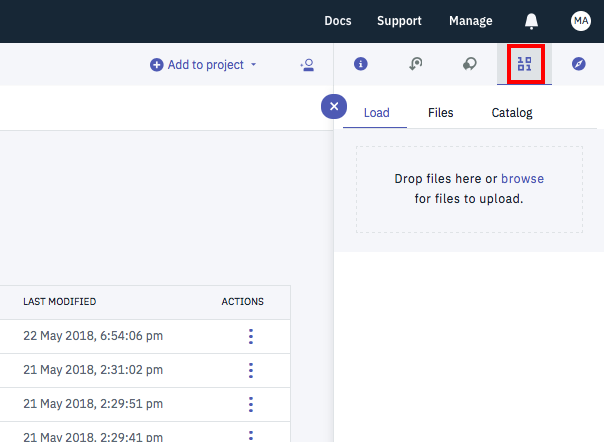
Definitionの登録
zipファイルのアップロードが終わったら、次のステップは、Definitionの登録です。
この登録は、Watson StudioのJupyter Notebookから行います。
そんなに難しい点はないので、ソースをそのままアップしておきます。
Object StorageとWatson Machine Learningの認証情報は人によって違うので伏せ字にしています。各自の設定に置き換えて下さい。
Object Storageの認証情報に関しては、Watson Studioの画面から
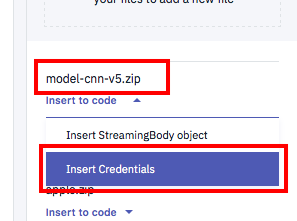
- 下の図のように先ほどアップした
model-cnn-v5.zipをクリック - 更にドロップダウンのメニューから
Insert Credentialsをクリック
とすると、現行のJupyter Notebookセルに認証情報がコピーされるので、それを利用すると効率がいいです。
# COSのcredentaial情報
# 各自の設定に差し替えて下さい
credentials = {
'IBM_API_KEY_ID': 'xxxx',
'IAM_SERVICE_ID': 'xxxx',
'ENDPOINT': 'https://s3-api.us-geo.objectstorage.service.networklayer.com',
'IBM_AUTH_ENDPOINT': 'https://iam.ng.bluemix.net/oidc/token',
'BUCKET': 'xxxx',
'FILE': 'xxxx.xxx'
}
from ibm_botocore.client import Config
import ibm_boto3
cos = ibm_boto3.client(service_name='s3',
ibm_api_key_id=credentials['IBM_API_KEY_ID'],
ibm_service_instance_id=credentials['IAM_SERVICE_ID'],
ibm_auth_endpoint=credentials['IBM_AUTH_ENDPOINT'],
config=Config(signature_version='oauth'),
endpoint_url=credentials['ENDPOINT'])
# download zip file from COS
zipfile = 'model-kit-cnn2.zip'
cos.download_file(Bucket=credentials['BUCKET'],Key=zipfile,Filename=zipfile)
import urllib3, requests, json, base64, time, os, warnings
warnings.filterwarnings('ignore')
# Watson Machine LearningのCredntial情報
# 各自の設定に差し替えて下さい。
wml_credentials = {
"url": "https://ibm-watson-ml.mybluemix.net",
"username": "xxxxx",
"password": "xxxxx",
"instance_id": "xxxxx"
}
from watson_machine_learning_client import WatsonMachineLearningAPIClient
client = WatsonMachineLearningAPIClient(wml_credentials)
print(client.version)
model_definition_metadata = {
client.repository.DefinitionMetaNames.NAME: "CNN CIFAR-10 KIT v3",
client.repository.DefinitionMetaNames.FRAMEWORK_NAME: "tensorflow",
client.repository.DefinitionMetaNames.FRAMEWORK_VERSION: "1.5",
client.repository.DefinitionMetaNames.RUNTIME_NAME: "python",
client.repository.DefinitionMetaNames.RUNTIME_VERSION: "3.5",
client.repository.DefinitionMetaNames.EXECUTION_COMMAND: 'python3 dlaas_train.py train_model_kit2.py CNN-CIFAR10-HPO.h5'
}
# 定義ファイルの登録
definition_details = client.repository.store_definition(zipfile, model_definition_metadata)
# 結果表示
import json
print(json.dumps(definition_details, indent=2))
ここで使ったNotebookはgithubからもダウンロード可能です。
Experimentsの定義
最後のステップはExperimentsの定義です。ここではGUIを利用します。
まずは、下記の画面から「New experiment」をクリックします。
下の画面で、名前を入力したら画面左下のCloud Object Storage設定の「Select」をクリック
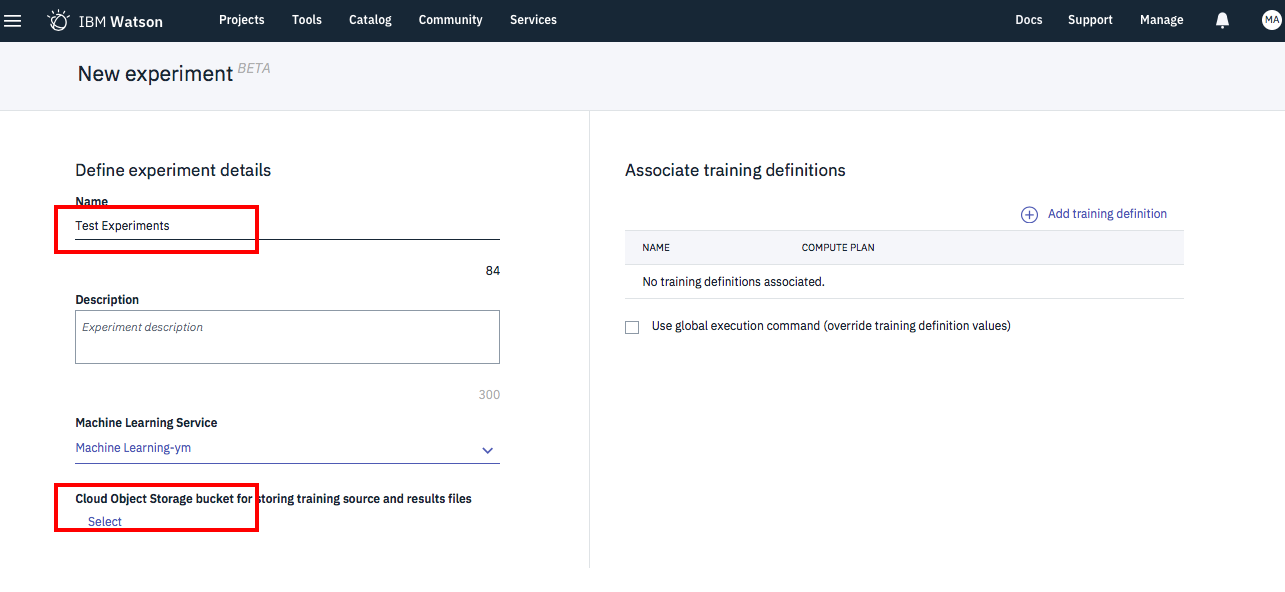
下の画面が出たら、赤枠の3箇所をドロップダウンで順次設定していきます。
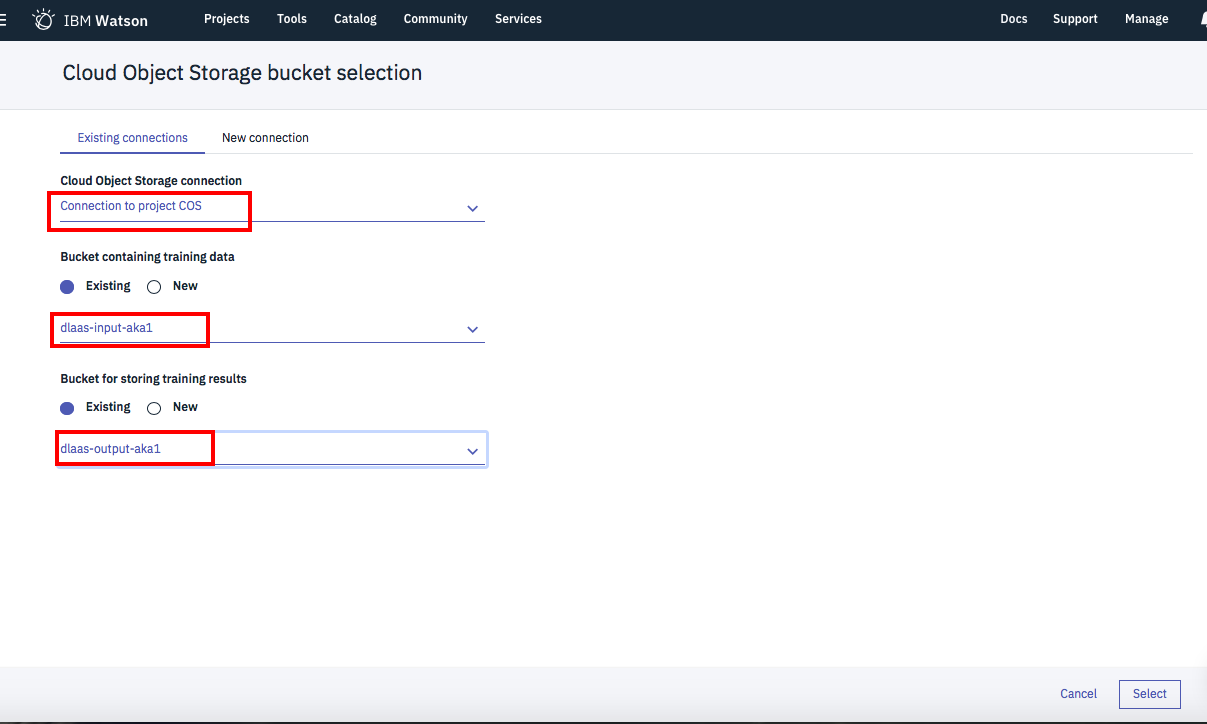
左側の設定が終わったら次は右側です。下記の「Add training definition」をクリック。
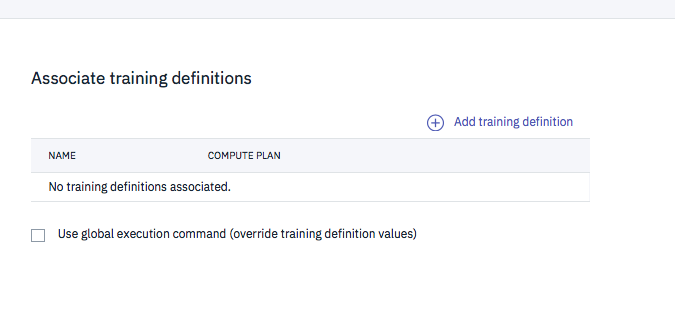
下の画面で、「Existing training defintion」タブを選択、ドロップダウンで先ほど設定した「CNN CIFAR-10 KIT v3」を選択。
赤枠のドロップダウンでGPUの指定を行います。その下のHyperparameter optimizationに関しては、このサンプルアプリでは利用していないので、noneのままでいいです。
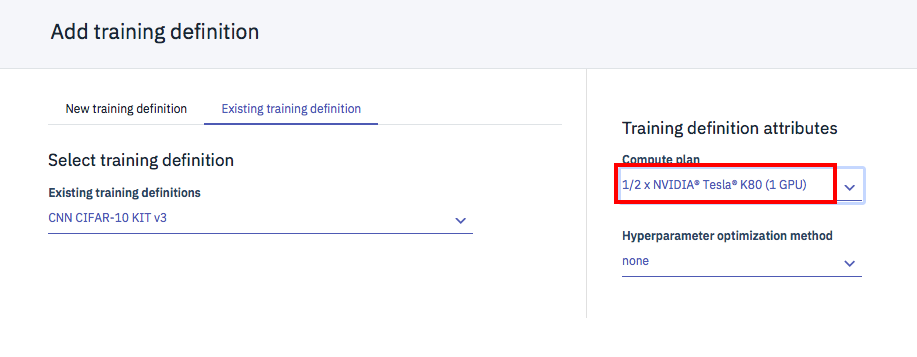
これですべての準備が整いました。
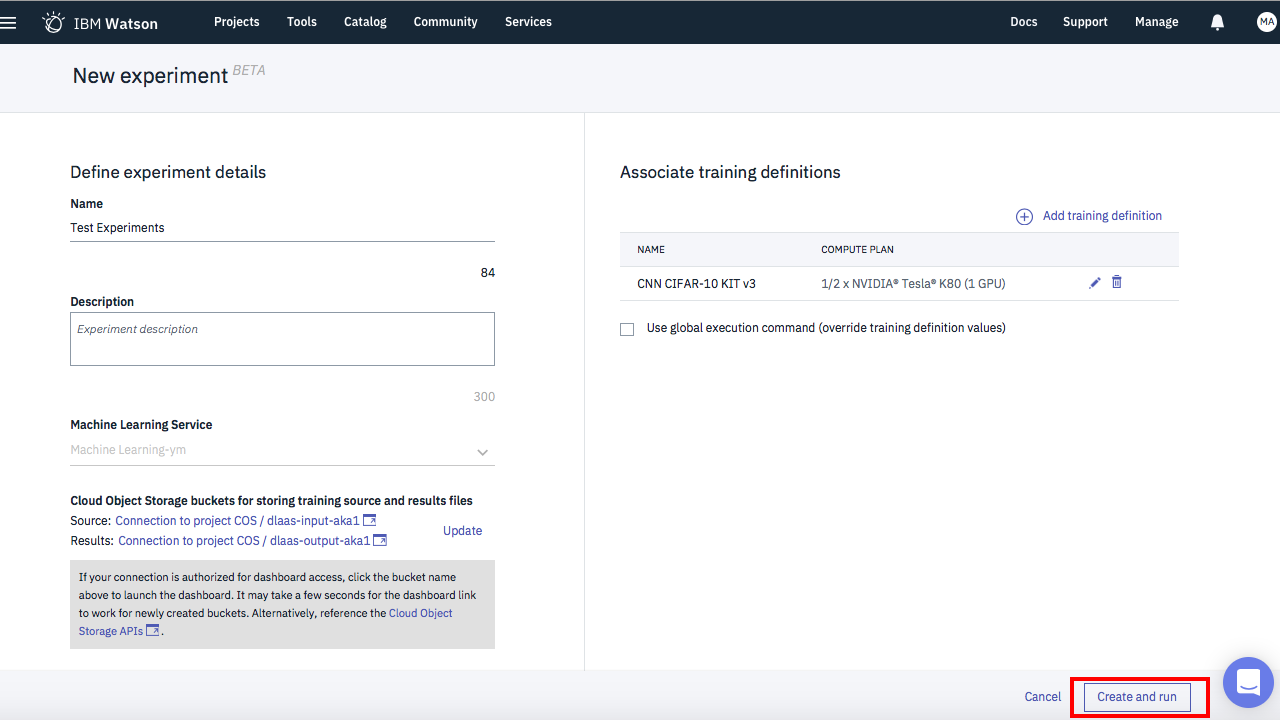
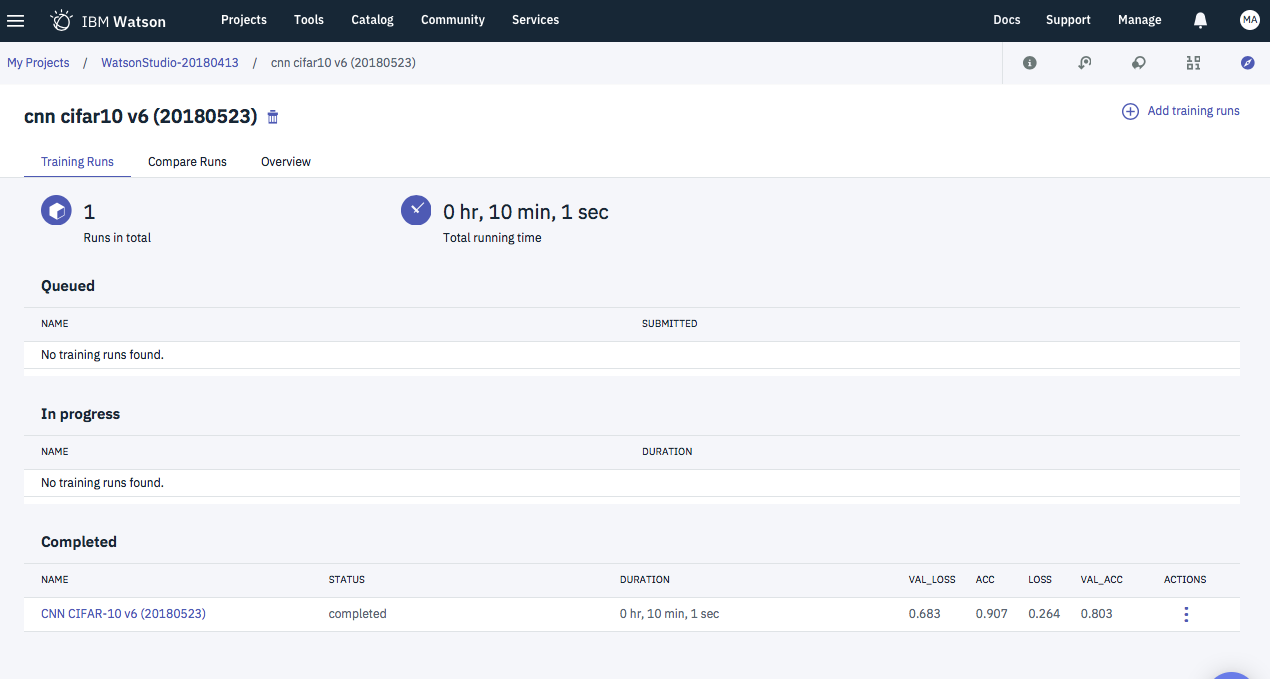
この状態で画面右下の「Create abd run」をクリックすると、「Experiment」の登録と、実行が行われます。
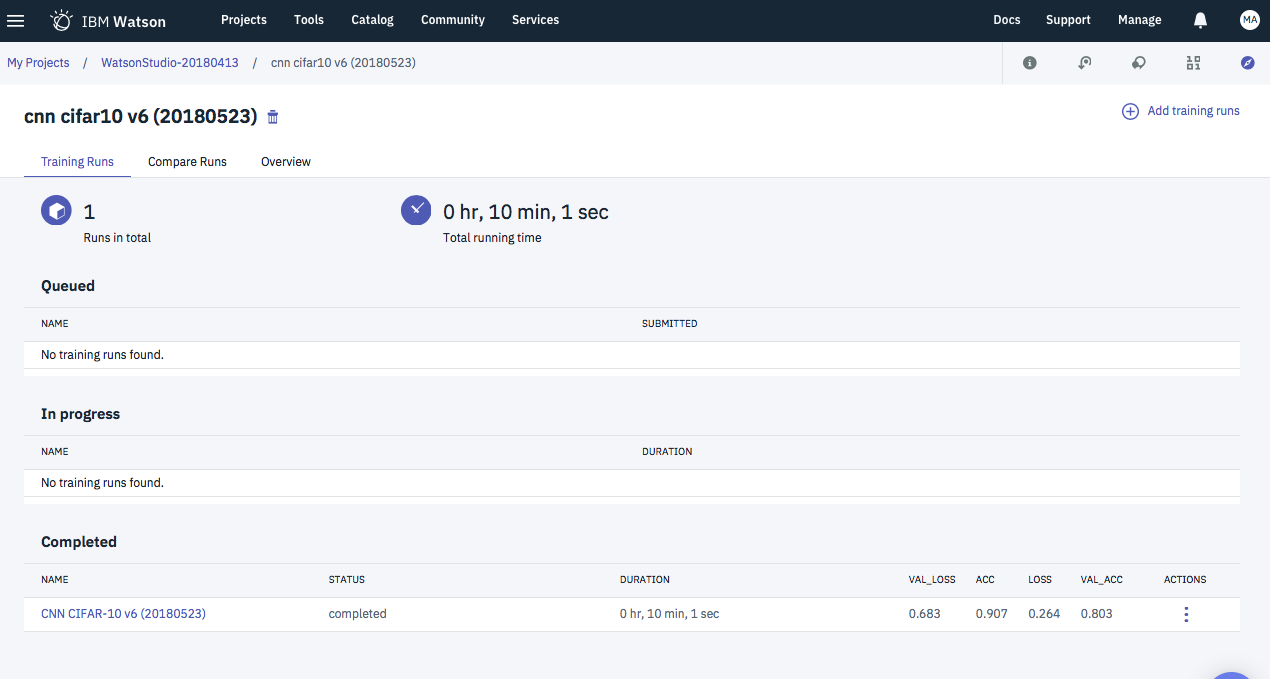
うまくいくと、ジョブ実行後に次のような画面が表示されるはずです。
Webサービス化まで
こうやって学習したモデルは追加の設定を行うことで以下のことが可能となります。
- アプリケーションからモデルを呼び出して利用(Watson MLクライアントのライブラリを利用する前提)
- Webサービスとしての利用
そのための手順の概要は以下のとおりです。
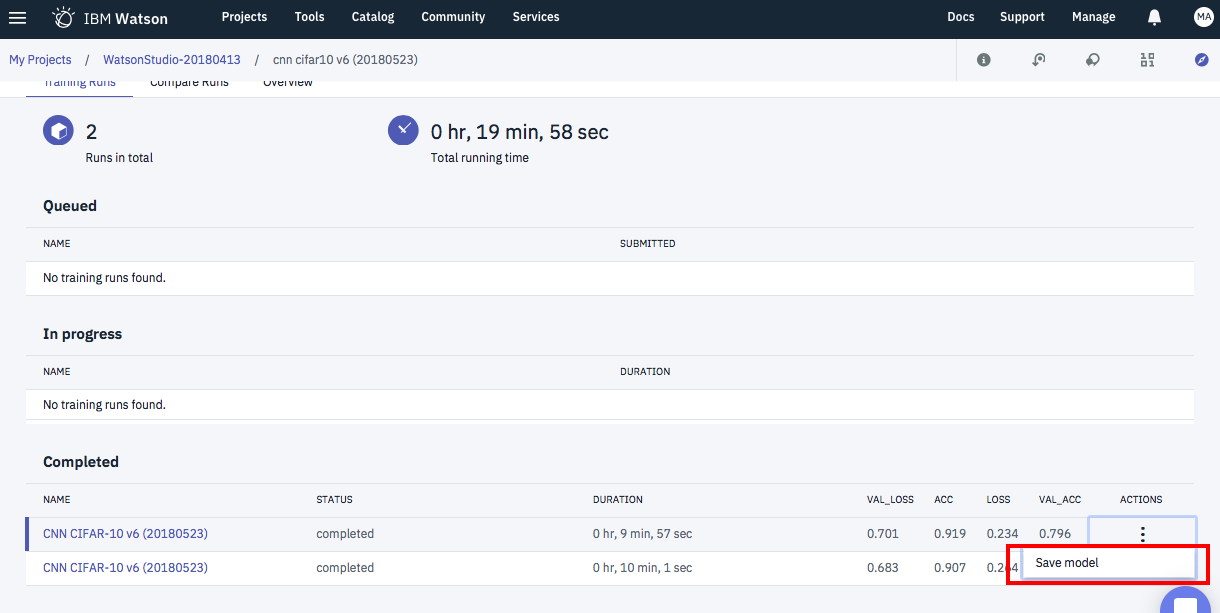
-
学習の終わったモデル(Experimentsの画面)からコンテキストメニューを表示して「Save Model」
-> Modelsとして登録される -
モデル一覧から該当モデルを選択し、Deploymentsタブから「Add Deployment」ボタンをクリック
-> Deploymentsとして登録される
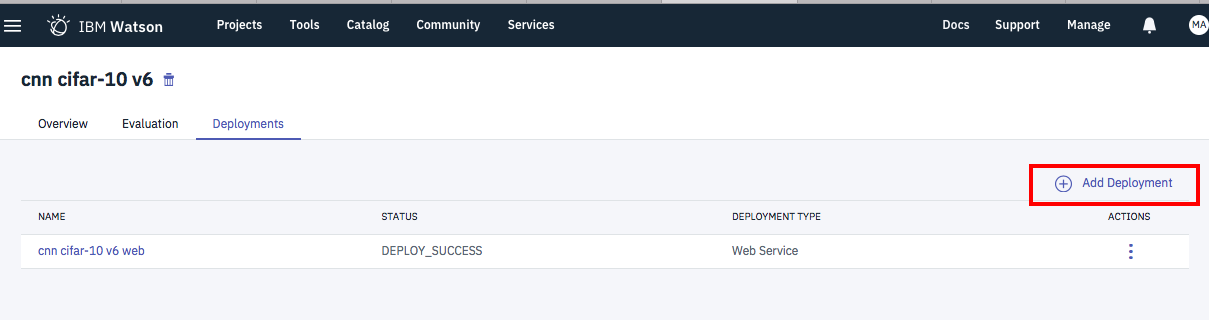
詳細手順に関しては、先ほど紹介したWatson Studioのディープラーニング機能(DLaaS)を使ってみたにに記載がありますのでそちらを参考にされて下さい。
Webサービスのテスト
Deep Learning Webサービスでは、テスト用のデータを作るのも結構面倒だったりします。
特にCIFAR-10に関しては、あまりツールも公開されていないようなので、簡単なデータ作成アプリをJupyter Notebookで作ってみました。
ソースはGithubに公開しておきます。
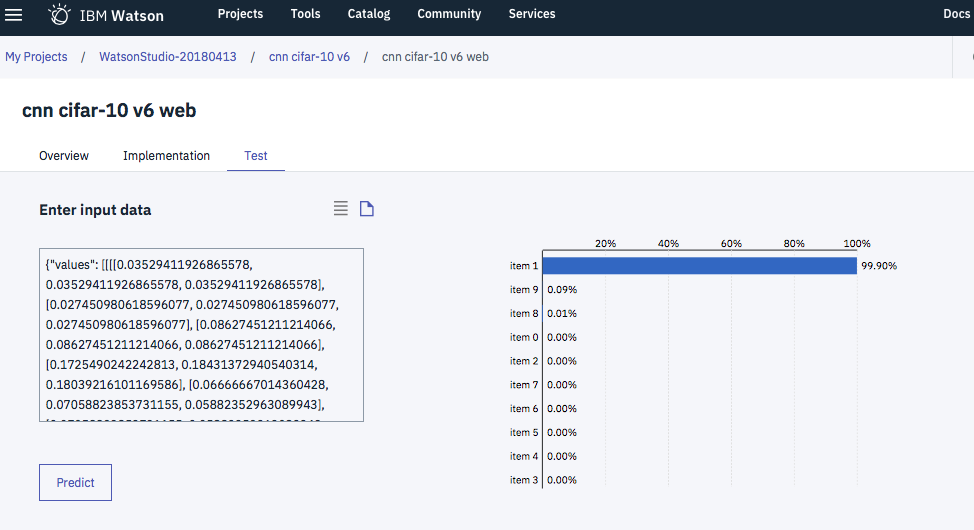
使い方は簡単で、Jupyter Notebookですべてのセルを実行すると、最後のセルの出力が下の図のようになるので、Values以下のテキスト部分をクリップボードにコピーします。(データが長くてコピーするのが大変ですが)
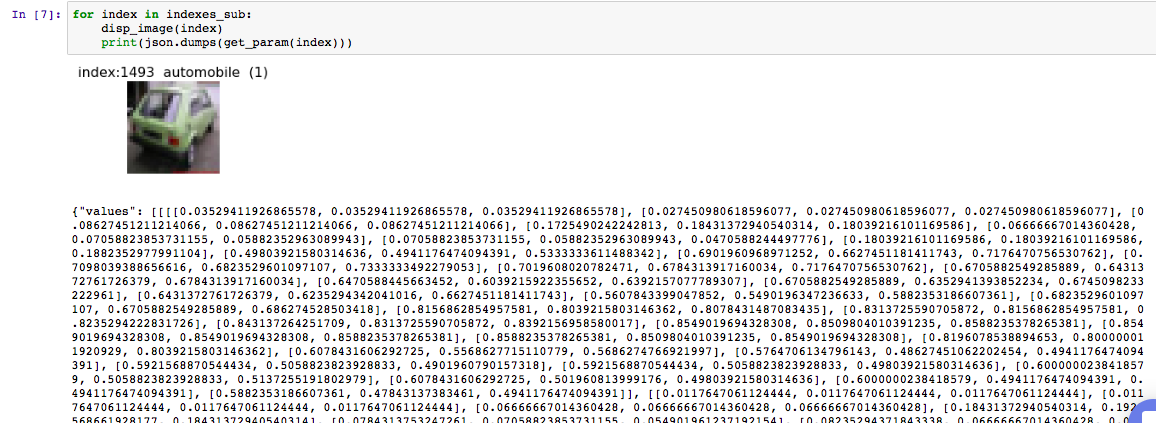
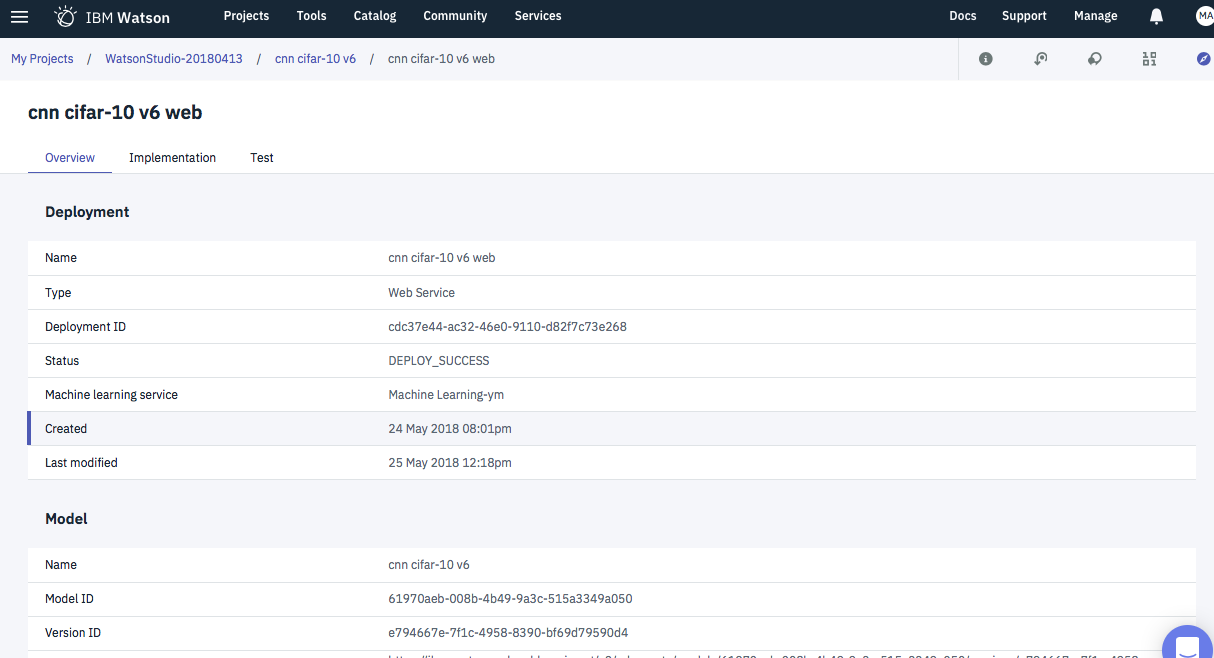
次にWatson Studioの管理画面で
- Deploymentsタブで該当Webサービスを選択
- Deployment詳細画面でTestタブを選択
- クリップボードデータを入力エリアに張り付けてPredictボタンをクリック
とすることで、テストを行うことが可能です。ちなみに、イメージを張り付けているサンプルのデータは上の方を見ると 1 (automobile)となっているので、正しく判断できているようです。