
![]() 当記事は2017/6月に初投稿しましたが、現時点(【2019/2月】)では既に古くなっています。記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。代替の記事としては下記などがございます。
当記事は2017/6月に初投稿しましたが、現時点(【2019/2月】)では既に古くなっています。記事自体はアーカイブの目的でこのまま残しますが、当記事の内容を参考になさらないようにお願いいたします。代替の記事としては下記などがございます。
【注】当記事は「Bluemix上でData Science Experience(DSX)のFree版が使えるようになったので、触ってみた」とのタイトルで2017/06にアップしたのですが、2017/11にLiteアカウントの開始やDSX/WML関連でUIの変更がありましたので記述見直し&画面ショットを撮り直しました。記事の内容は以前とほぼ同じです。変えたところは  で表記します。
で表記します。
はじめに
こんにちわ!2017/06/01にIBM Cloud上にData Science Experienceのアイコンが登場しました! と興奮しても、殆どの方は「Data Science Experienceって何よ、それ」というクールな反応かと思います。(ガックリ.. ) Qiita上にもData Science Experience(以下DSX)の記事はちらほらありますが、IBM Cloudのカタログに登録されたのを機に、改めて「何それ?」を簡単にご紹介しようと思いました。
Data Science Experience(DSX)とは?
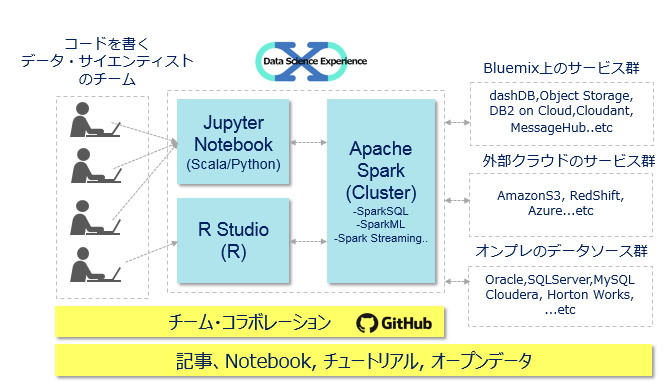
( スキルフルなQiita読者の皆様には以下の表現が話が早いと思いますが) 要は、最近盛り上がってる以下のようなオープンなデータ・サイエンス系分析の開発・実行環境を一式まとめて提供するSaaSサービスです。利用者としてはコーディングができるデータサイエンティストのチームを想定しています。(コーディング嫌いな方は![]() SPSSもDSX上で使えるようになってますよ! :-) )
SPSSもDSX上で使えるようになってますよ! :-) )
- Jupyter Notebook(※)上のScala/Python
- R Studio上のR
- Spark Cluster
- Brunel(Visualization)/Apache Toree(SparkとJupyterの統合)など
更に
- お勉強のための記事・Tutotialやオープンデータ
- 分析チームのためのコラボ機能
- NotebookのGitHub連携
もついてます。
※実際はチームで開発できるのでJupyter Hubなのかな?何を使っているかまではわかりません。
で何がいい?
まあ現状は要はオープンソースものを統合したSaaSサービスなわけで、似たような環境は自力でも作れるといえば作れるんでしょうが、以下の利点があると思います。
- (SaaSなので)そもそもインフラの手配や環境設定の必要が無い
- JupyterとSparkの連携など、基盤設定の知識も不要
- ゆえにすぐコードの開発に入れる(またはすぐお試し・お勉強できる)
- 多言語環境(Polyglot)なので分析チームが「ツールや環境を統一する」必要が無い
- 特にSpark Clusterの環境構築と運用が不要(結構大変ですよ、これ)
- dashDBやObject StorageなどIBM Cloud上のサービスと簡単に連携できる
- 作ったNotebookをgithub上に簡単にデプロイできる
なおDSXは特に**「分析チームの生産性を上げること」に力点を置いているようです。データ・サイエンティストの方ってそれぞれ自分の好きな言語や得意なツールがあって、「僕はRでやりたい」「え、これからはAIだからPythonだろ」とか色々でしょう。個人単位で分析をする場合は好きなものを使えばよいのでしょうが、「分析作業」を「チーム」で「お仕事」でやる場合はそうもいきません。言語やツール環境を統一しないと分析結果をチームで評価したりシェアしたりする際に何かと不便です。かといって「この分析仕事はxxxで」と強制的に決められるのも、結構つらいしモラルダウン。。。DSXはこのあたりをチームの皆様はお好きな言語・ツールで** 分析して、成果物はコラボできるような環境を目指しているようです。(価格の体系が1ユーザーの価格ではなくて、5名でいくら、のような感じになっていることからも推し量れます)
DSXのIBM Cloud上での変遷
Data Science Experience自体は2016年にBluemixから独立した形でSaaS上のサービスとして提供されていたのですが、30日間のトライアルが提供されているのみ、でした。(つまりトライアル期限が過ぎたら使えなかった。)![]() その後2017/06にBluemixのカタログに掲載&Free版が提供され、2017/11にはBluemix→IBM Cloudへの名称変更を機に、ずっと無料のLiteプランが提供されましたが、DSXとWMLはLiteプランでも利用できます。要は(リソースに制限はあるものの)Liteプランなら期限なし&無料で気軽に試せるようになってますので、「Jupyter/Python/Scala + Sparkのお勉強」を始めるのにいいんじゃないかと思います。(お勉強のためのTutotialやサンプルのNotebookも豊富に準備されていますしね)
その後2017/06にBluemixのカタログに掲載&Free版が提供され、2017/11にはBluemix→IBM Cloudへの名称変更を機に、ずっと無料のLiteプランが提供されましたが、DSXとWMLはLiteプランでも利用できます。要は(リソースに制限はあるものの)Liteプランなら期限なし&無料で気軽に試せるようになってますので、「Jupyter/Python/Scala + Sparkのお勉強」を始めるのにいいんじゃないかと思います。(お勉強のためのTutotialやサンプルのNotebookも豊富に準備されていますしね)
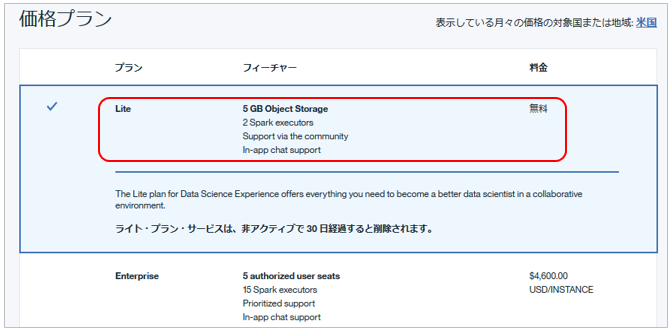
ちなみにLiteプランで使えるリソースは下記です。小規模ですが「お勉強」レベルなら十分かと思います。(Liteプランは有償のEnterprise版と機能は同じで、利用できるマシンのリソースやSpark Clusterの数が違うだけ、です。)
Data Science Experience
ということでやってみる
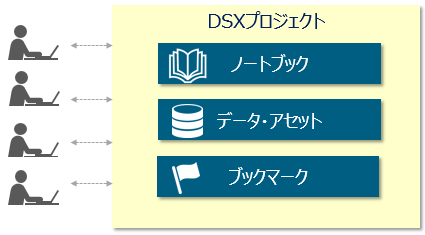
以下、入門編としてFreeの環境でDSXの機能をご紹介しながら、プロジェクトの作成から既存のPython/Sparkの解説付きNotebookを動かすところまでやってみます。なお、DSXでは「プロジェクト」という管理単位を用いて様々なノートブックやデータなどのリソースを取りまとめ、管理・シェアします。
まずIBM Cloud上でDSXのサービス・インスタンスを作成
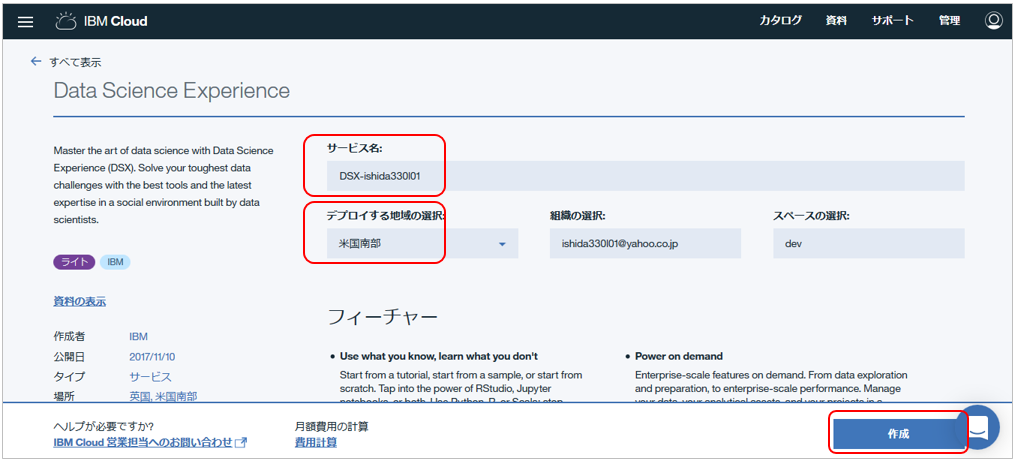
IBM CloudにログインしてカタログからData Science Experienceを選択します。

次画面でサービス名にお好みの名前を付け、Lite Planを選択の上「作成」します。
![]() Liteプランの時は**「デプロイする地域」は「米国南部」**にしてください。2017/11月時点ではLiteプランで利用できるのは「米国南部」のみです。(サービスの品揃えが一番多いのは「米国南部」なので妥当かと)
Liteプランの時は**「デプロイする地域」は「米国南部」**にしてください。2017/11月時点ではLiteプランで利用できるのは「米国南部」のみです。(サービスの品揃えが一番多いのは「米国南部」なので妥当かと)
画面が切り替わったら「Get Started」
DSXで利用するIBM Cloudの組織とスペースを選択して「Continue」(デフォルトでいいかと)
しばし待ち、Doneになったら「Get Started」
メニューのご紹介
下記がDSXの初期画面です。![]() 2017/11の更新でカッコよくなりましたね。
2017/11の更新でカッコよくなりましたね。
- このパネルは右上の「Get Started」をクリックすると表示されます。
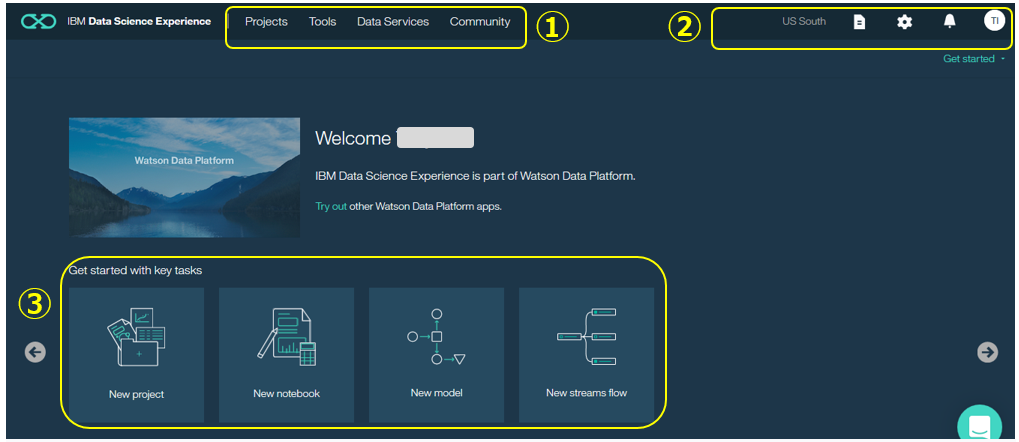
- ① ここが操作の中心で、プロジェクトの作成やデータソースの設定などを行います
- ② ドキュメントへのリンクや様々な設定
- ③ ショートカット的なアイコン
①のメニューは以下のようなものになっています。
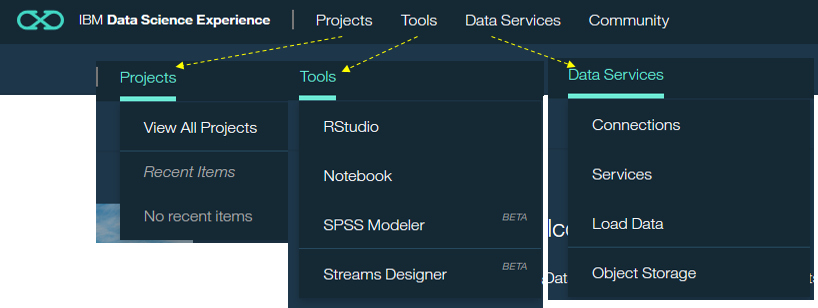
- Projects - 作成したプロジェクトやノートブックへのアクセス
- Tools - JupyterとRStudioへのアクセス
- Data Services - データベースやストレージなど様々なデータソースの定義
![]() ベータですがSPSS ModelerやStream Designerも追加されました
ベータですがSPSS ModelerやStream Designerも追加されました
画面の下部は
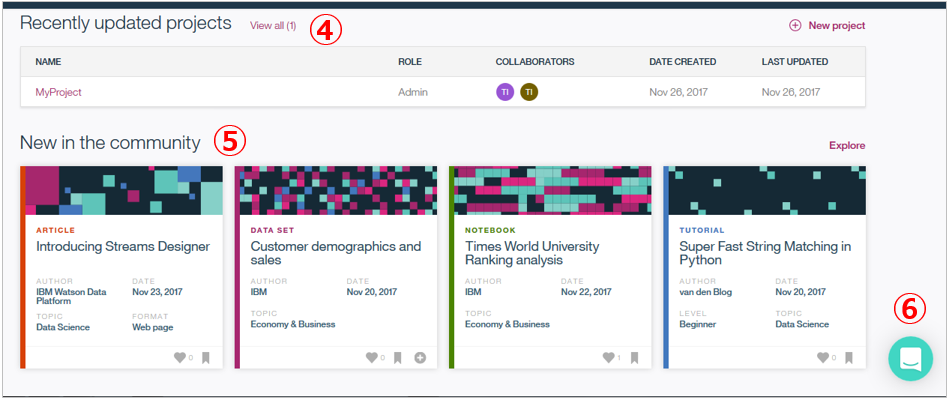
- ④ 最近使ったプロジェクト
- ⑤ コミュニティのリソースで、ブログ記事やチュートリアルがたくさん並んでいますので、ここから直ぐに勉強を始められます。
- ⑥をクリックするとDSXのサポートに質問ができます。(私はやったことありませんが)
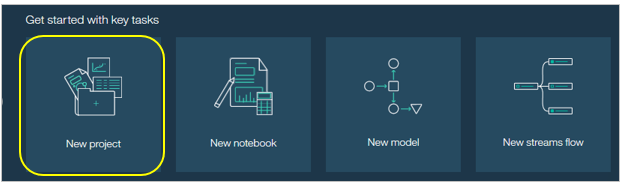
プロジェクトを作ってみる
③のショートカットで「Create Project」
Name欄にお好きなのプロジェクト名を入力します
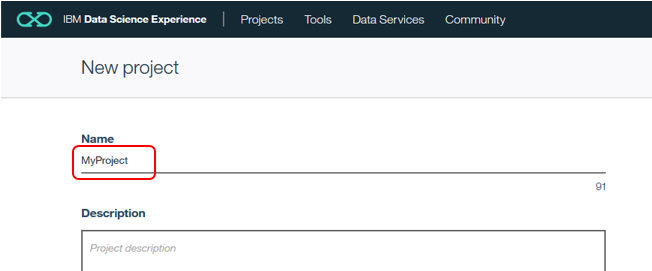
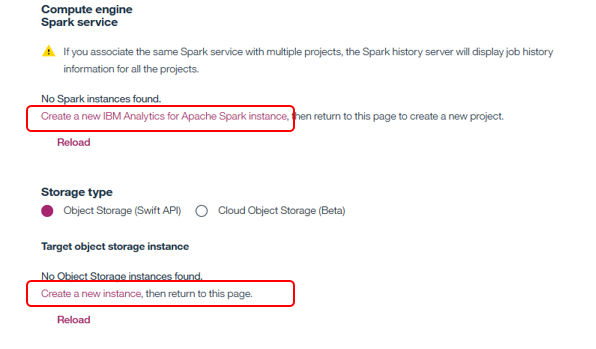
DSXを利用する際は①Spark ②Object Storage のインスタンスが必要です。これらもLiteプランで無料で作れます。もし未定義の場合はこのパネルから下記をクリックしてすぐ定義できますので、作成してから改めて「Reload」して使うインスタンスを指定してください。(既に定義済であれば、選択するだけ)
【当該アカウントにインスタンスが無い場合】
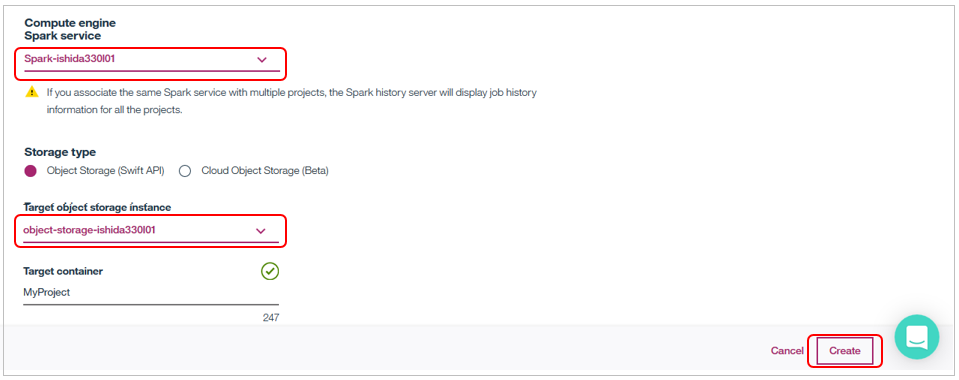
インスタンスを指定したら「Create」
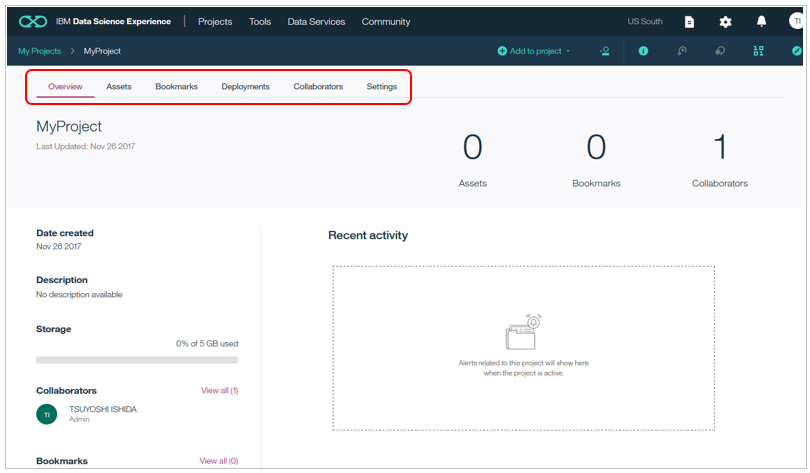
プロジェクトができました。まだまっさらですが、プロジェクトの中にノートブックやデータアセットが格納される構造になっていることがわかります。ここから新規にノートブックや機械学習モデルを作れます。
新規にNotebookを作ってみる
新しいNotebookを作ります。右上の「add notebooks」
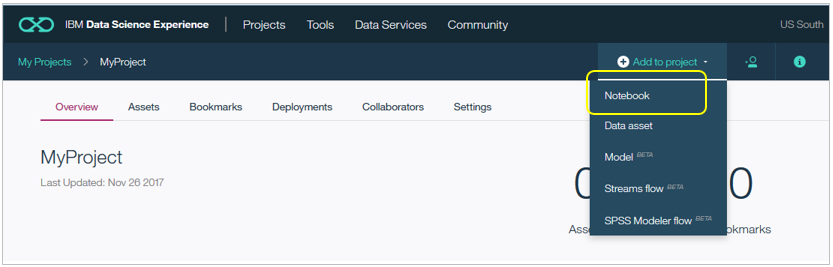
Nameにお好きな名前を設定し、言語とSparkのバージョンを選択の上、「Create Notebook」。ここでは最新のPython 3.5/Spark 2.1を選びました。
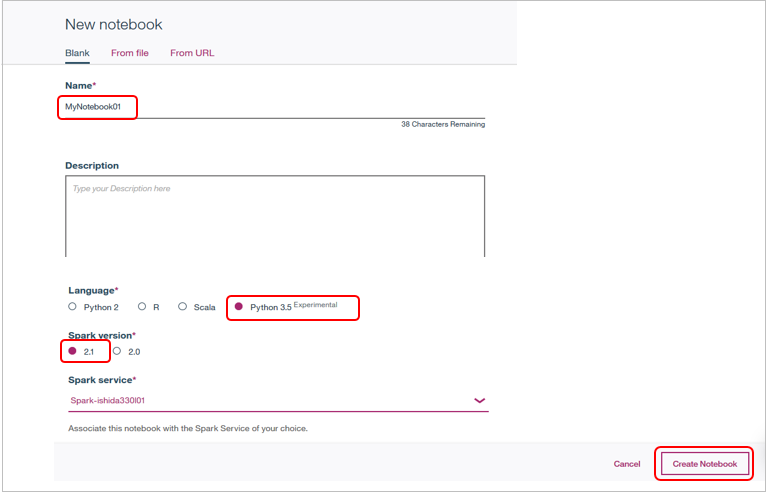
結果、下記のように見慣れたJupyter Notebookの環境ができました。最上部のメニューや配色がオープンソースのJupyter Notebookと違いますが、実体はJupyterそのものなので、既にJupyterのご経験がある方が操作に迷うことは無いでしょう。
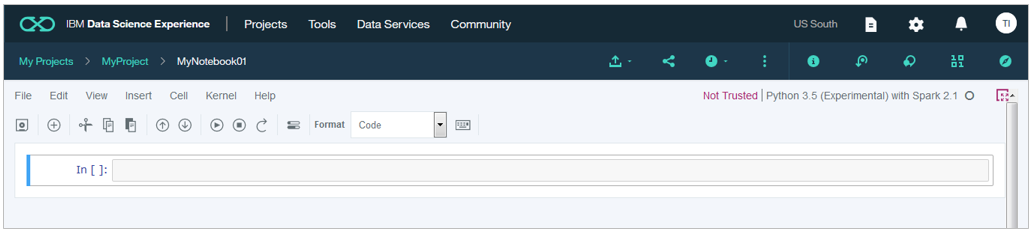
ちなみに右上の以下のメニュー群はDSXの機能です

| # | ご説明 |
|---|---|
| ① | ノートブックのgithubへのPublish |
| ② | 直リンク、twitter、LinkedInでのノートブックのシェア |
| ③ | ノートブックの定期実行スケジューリング |
| ④ | プロジェクト・トークン(※)の挿入 |
| ⑤ | 環境、作成日など、このノートブックに関する情報 |
| ⑥ | ノートブックのバージョン保管(10まで) |
| ⑦ | コメントの追加 |
| ⑧ | ファイルやデータソース接続 |
| ⑨ | ブックマークやコミュニティ・リソースの検索 |
※プロジェクト・トークンとはデータへアクセスする際の認証情報。詳細はここを。
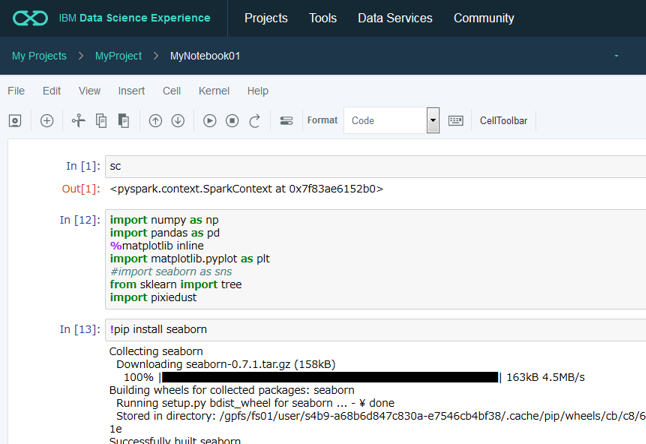
ノートブックが開いたら、あとはコーディングを開始するだけ、です。以下のようにSpark Contextは既に初期化済ですし、Pythonでのデータサイエンスの定番ライブラリーである numpy, pandas, matplotlib等も使えるようになっています。ちなみにseabornは入ってませんでしたが、!pip install seabornでインストールできました。このように「無いライブラリーは追加」することも簡単です。
事前に準備されているNotebookの利用
「これからお勉強」の方は何もないところから始めるのはつらいですが、DSXでは(英語ですが)「解説を読み実際に動かしながら、勉強できる」Notebookが多数揃っています。ためしに既存の「PythonでSparkを使うためのNotebook」を動かしてみましょう。
CommunityのNotebooksで「Apache Spark Lab」と検索すると以下の3部構成のNotebookが見つかります。そのパート1をダブルクリックで開きます。
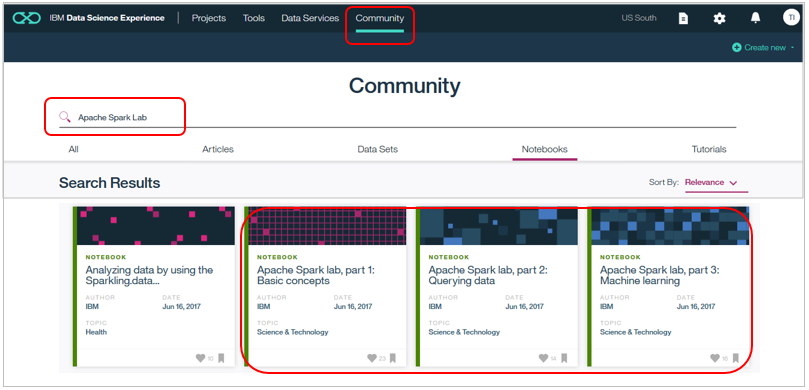
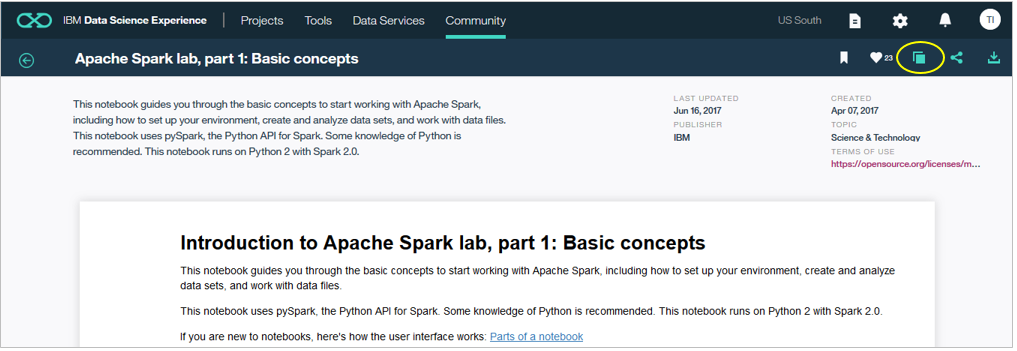
以下のように解説付きのNotebookが開きますので右上のアイコンから「Copy」を選択します。
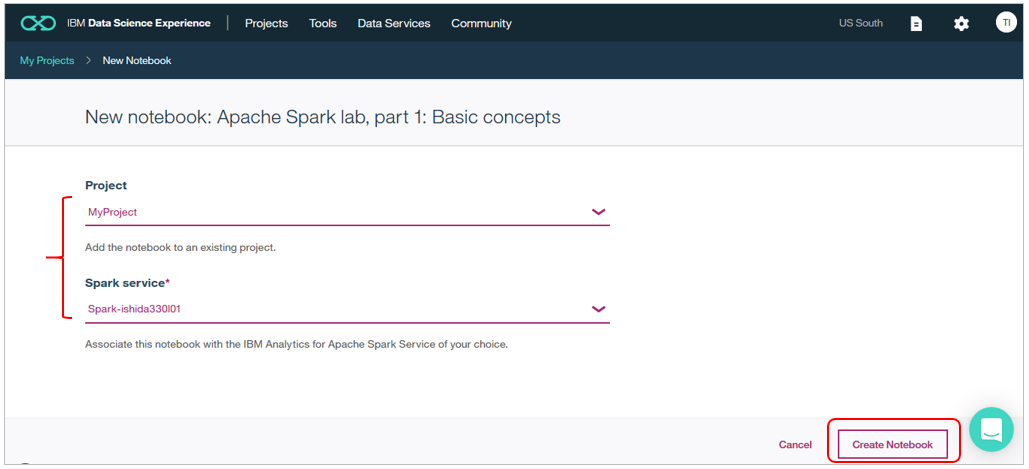
プロジェクト名と利用するSparkの環境を選んで「Create Notebook」
しばらく待つと下記のようにNotebookが自分の環境にコピーされ、動くようになります。
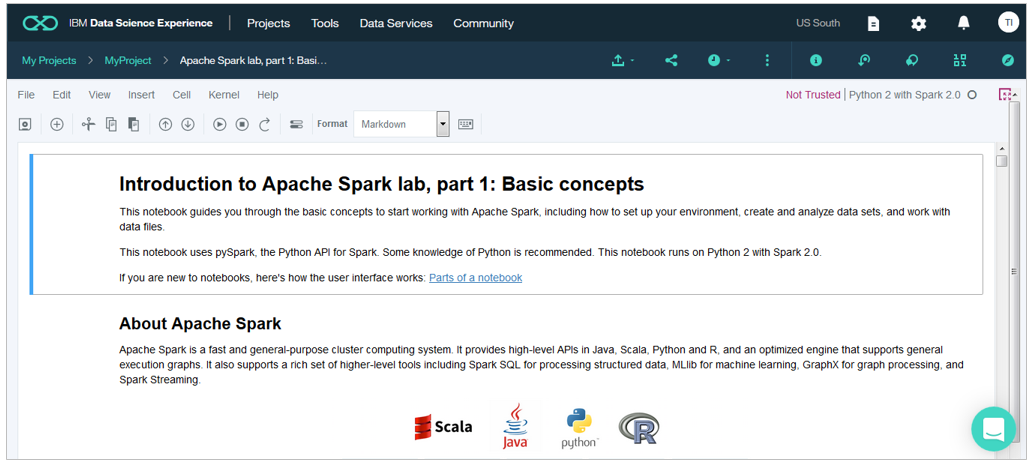
実行前の準備として、以前の出力が残っている場合はクリアしておきましょう。
「Cell」-「All Output」-「Clear」
あとは解説を読みつつ、実際にセルを実行していけばいいだけです。解説で学んだことをすぐに試せるので、お勉強に良いかと思います。
( ちなみにセルのステップ実行は以下のボタンまたは「Shift+Enter」で)

このNotebookの内容については当記事の範囲外なので割愛しますが、他にもいろいろなNotebookがあるので、ご興味のテーマを選んで同様に勉強できますよ。
以上、「触ってみた」でした。
チームでコラボるには
複数のメンバーがひとつのプロジェクト上でコラボするには、以下の手順を踏みます。やってみた限りでは、Liteアカウント同士でもできるようです。
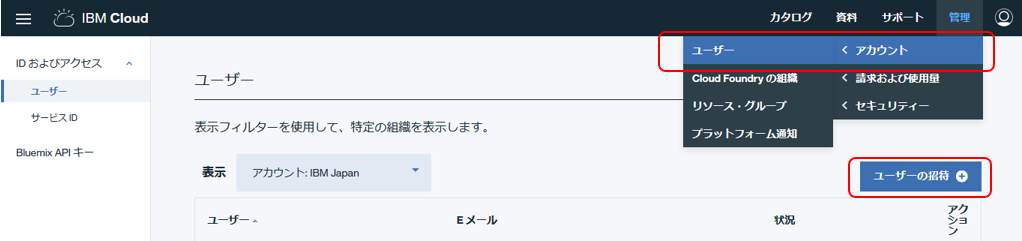
- IBM Coudの右上メニューで「管理」-「アカウント」-「ユーザー」のパネルで「ユーザーの招待」をクリック
-
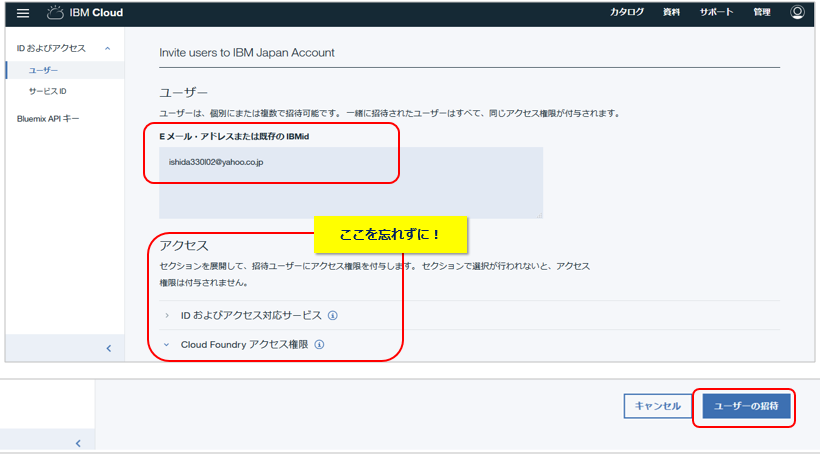
招待したいユーザーのメアドを入力し、適切なアクセス権限を設定してから「ユーザーの招待」ボタン
-
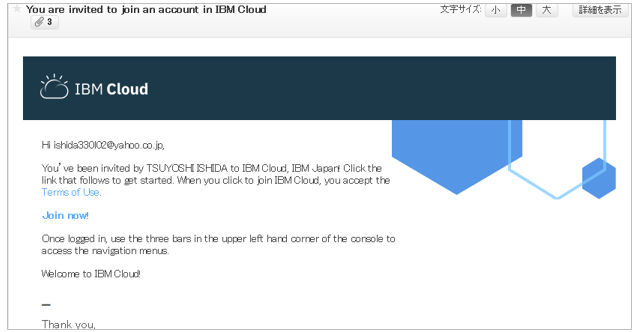
招待されたメンバーには以下のようなメールが飛ぶので、「Join Now」で招待を受け入れIBM Cloudにサインアップします。
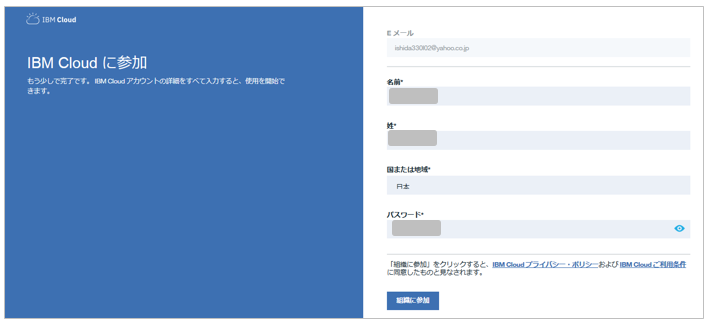

- 招待されたメンバーがIBM Cloudにログインすると、以下のように招待した側のDSX関連のサービスが利用可能になっています。(ただしまだプロジェクトは使えません)
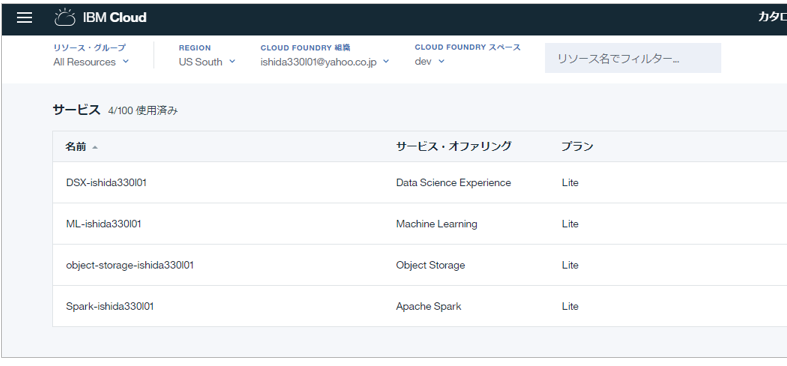
- 招待されたメンバーはDSXのサイトで新規にサインアップします。この操作により、IBM CloudのアカウントとDSXのアカウントが関連付けされます。
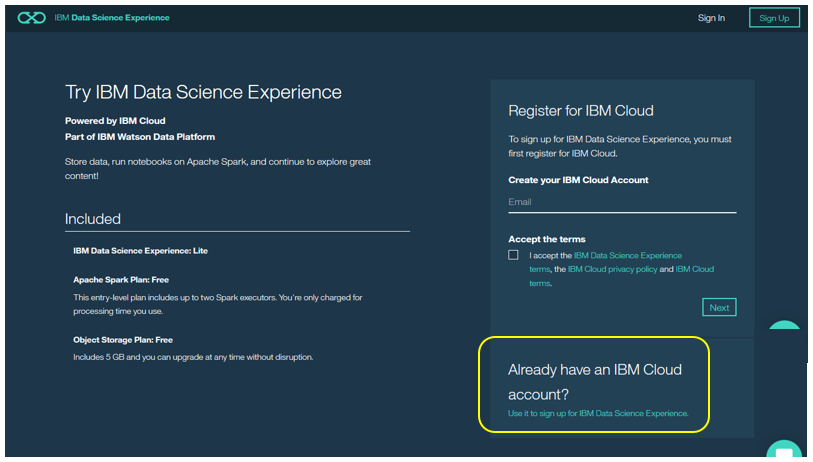
すでにIBM CloudにログインするIDを持っているので、右下の「Already hace an IBM Cloud account?」でサインアップします。ただし、この時点では招待した側がまだプロジェクトがシェアしていないので、何も見えません。
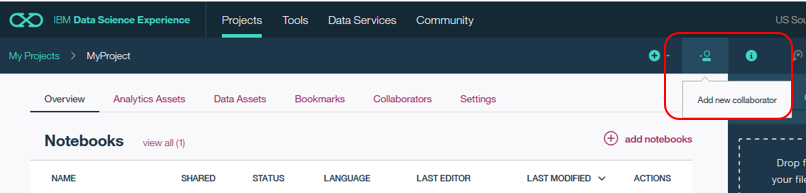
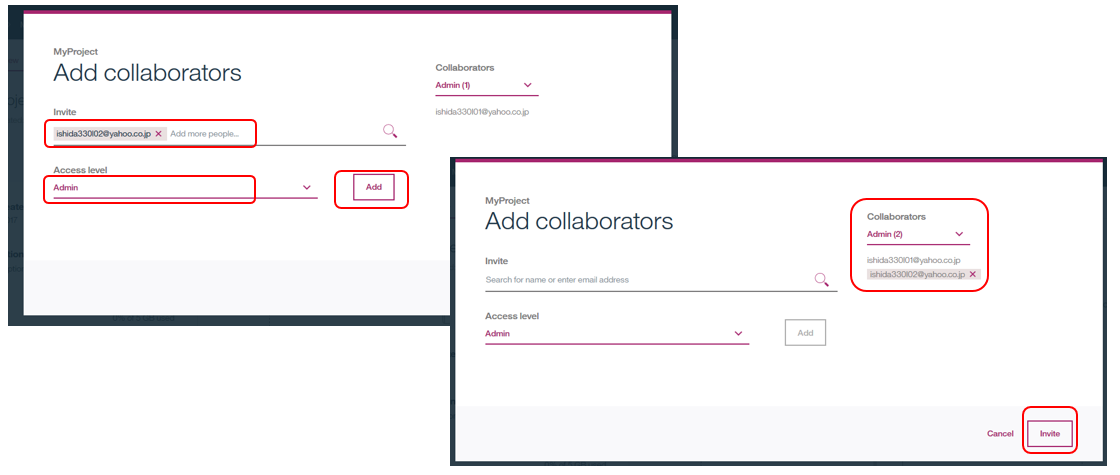
- 招待する側の管理者はシェアしたいプロジェクトを開き「Add new collaborators」で招待したメンバーを適切な権限と共に「Add」します。Collaboratorにidが追加されたら「Invite」ボタン
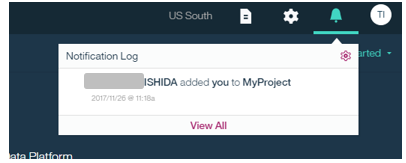
- 上記操作により、新規メンバーに通知がなされ、プロジェクトが見えるようになります。
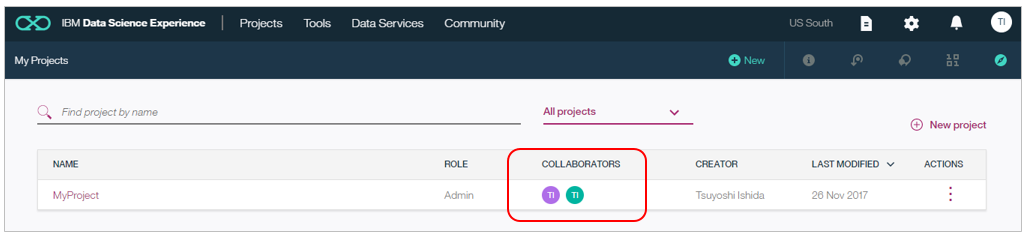
このあたり、IBM CloudのアカウントとDSXのアカウントの両方があり、ちとややこしいので詳しくはドキュメントSet up an enterprise accountをご参照ください。
なお複数人で同一のノートブックを更新することが無いよう、誰かが編集中はノートブックはロックされています。
実はDSXはオンプレ版も
当記事ではご紹介しませんでしたが、DSXにはプライベート・クラウドで動くDSX Localやデスクトップで使えるDSX Desktop(2017/6月現在オープンβ中)もあります。ご興味があればDSXのDocumentやインターネットを検索してみてください。
Watson Machine Learingとの連携も進んでます
なお、DSXとWMLはIBM Cloud上では別々のサービスですが、両者の連携もどんどん進んでいます。IBM Cloud上でデータサイエンス/予測分析的なことをやる場合、おそらく両方とも使うことになるでしょう。Lite プランではWatson Machine Learningも無料で使えますので、ぜひ使ってみてください。