Zaim Analysis Platform
我が家の家計簿はZaim.netを利用しているのだけど、Zaim.netのオリジナルのデータ描画機能はどうも痒いところに手が届かず、有料会員の描画機能にしてもそこまで家計分析がやりやすいものではなかったので、自分で分析ができるように、Zaim.netの家計簿データを定期的にスクレイプしてきて、elasticsearchに突っ込んで、kibanaで描画するためのdockerプラットフォームを作った。ソースは以下。
https://github.com/inTheRye/zaim-analysis-platform
システム構成
システムの構成は以下のような感じ。
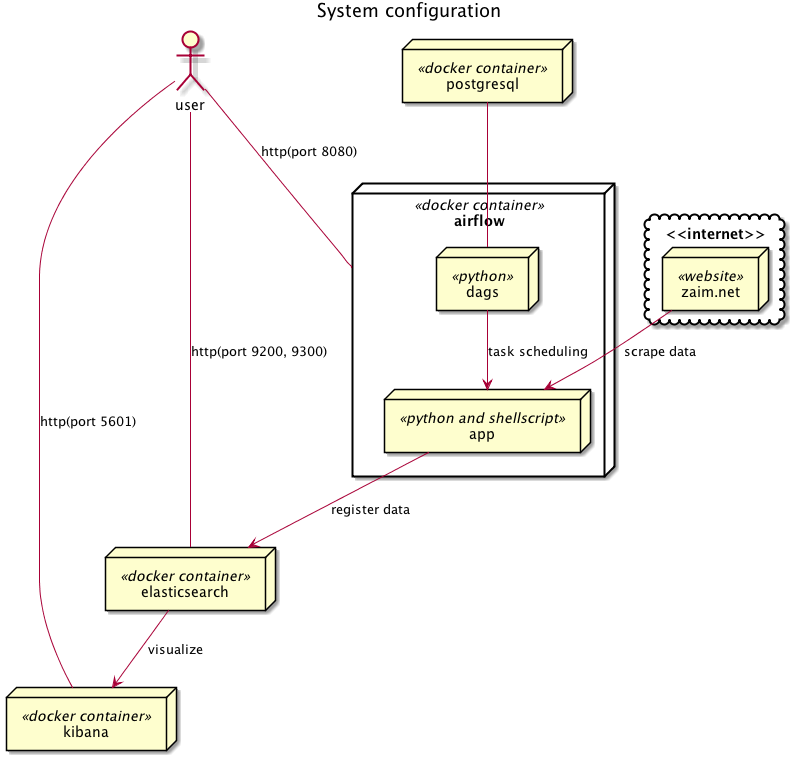
処理の流れ
大まかな処理の流れは以下のような感じ。
- airflowのdagsとして、pythonのクローラー兼スクレイピングスクリプトとelasticsearchへのデータアップロード用のシェルスクリプトを登録。
- これらを定期的に叩いて、以下の処理を実行。
- zaim.netの家計簿データを取得し、取得した家計簿データをelasticsearch登録用に成形したjsonファイルに保存。
- jsonファイルをcurlコマンドでelasticsearchにzaimというインデックスで登録。
- kibanaにzaimインデックスを登録して可視化。
elasticsearchへの登録部分は、全部pythonでやってしまえば良いのだけど、elasticsearchのインデックス作成とか色々試行錯誤やったりするのがやりやすかったので、curlコマンドでの登録内容をそのまま残す形にした。その内全部pythonスクリプトで作り直すかも。
また、データ量的にそれほどでもないので、一旦インデックスを削除して再登録し直すという形にしている。これも登録データ量が増えたら差分登録する必要があるかも。
(参考)
deviantony/docker-elk
puckel/docker-airflow
Getting Started
インストール
dockerが動く環境なら基本的にどこでも動くはず。Docker for mac (Version 17.09.0-ce-mac35)で動作確認済み。
githubからソースコードをcloneしてくる。
$ git clone https://github.com/inTheRye/zaim-analysis-platform.git
自身のZaim.netのID,PASS,スクレイピングしたい家計簿データの開始日を書き込んだconfig.ymlファイルを作る。
$ cd zaim-analysis-platform
$ echo 'ID: "your_user_id"' > py_scraping/app/config.yml
$ echo 'PASS: "your_password"' >> py_scraping/app/config.yml
$ echo 'START_DATE: "2016-1-1"' >> py_scraping/app/config.yml
スケジュールされたdagの開始日(start_date)を本日からに修正する。1
$ date=`date +"%Y, %m, %-d, 00, 00, 00"` && sed -i '' 's/datetime.today()/datetime('$date')/g' py_scraping/dags/zaim.py
dockerコンテナを起動する。
$ docker-compose up -d
コンテナの動作状況のログは下記で確認する。
$ docker-compose logs
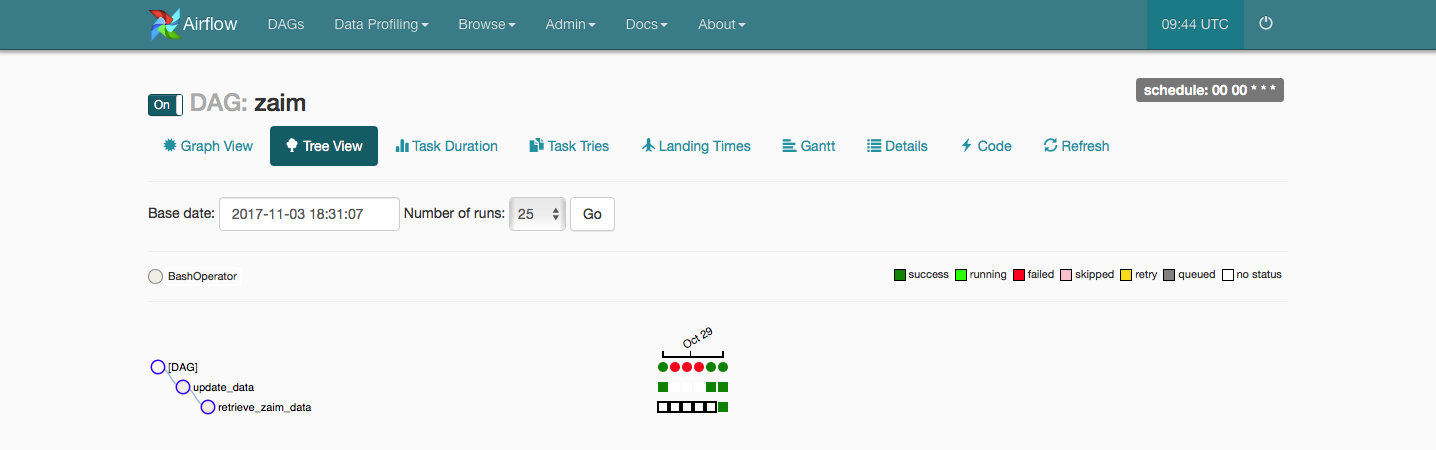
Airflowによる定期ジョブ管理
http://localhost:8080 でairflowにアクセス。
zaimというdagが登録されているので、offの状態であれば、onに変える。
これで毎日、0時に処理が定期的に動く。
あまり見やすいUIとは言えないけど、ジョブの成功、失敗状況もWeb UIで分かるのは嬉しい。
最初は単純にcronで定期起動しようとしていたけど、log出力とか真面目に考えるのも面倒だし、そのあたりを適当にやってもそれなりにlogが見れるのは良い。
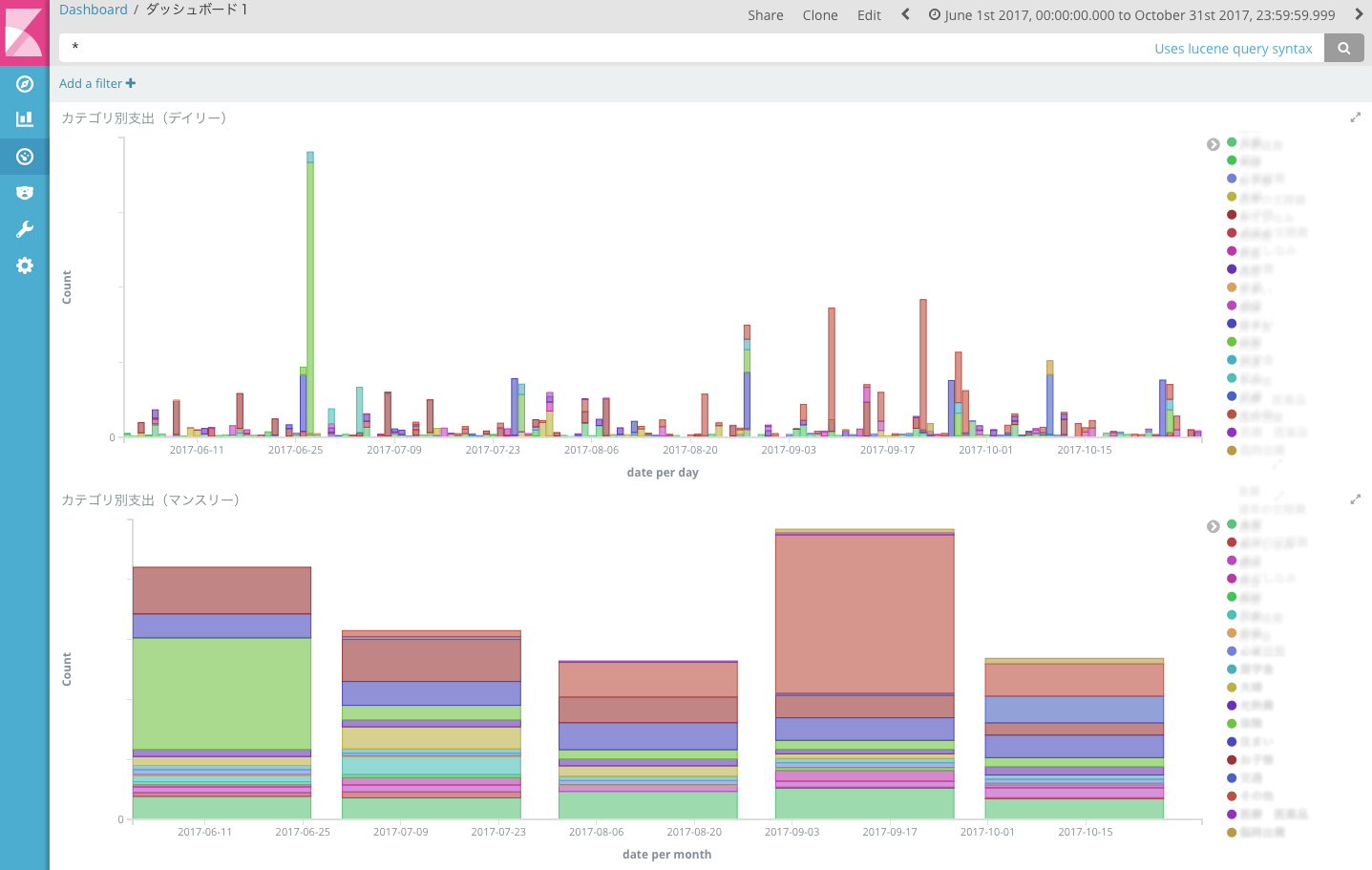
kibanaによる描画
http://localhost:5601 でkibanaにアクセス。
zaim* の Index Pattern を作って、あとは適当にビジュアライズする。
kibanaに関しては、検索すれば詳しい記事がいくらでも見つかると思うのでそのあたりを参考にしてください。
ちゃんとindexは見つかってるのに、「データが無いって言われる!」となる時は大体検索期間が極端に短くなっているので、検索期間をLast 90daysとかにすればOK。
※デフォルトの設定は"now-15m"で15分前までのデータ検索期間になっている。
(参考)
Kibanaで簡単! サクサク ビジュアライズしよう!
elasticsearchへ直接アクセス
$ curl localhost:9200
その他
注意事項等
まあ、昨今クローリングとかスクレイピングの書籍とかも出まくっているので、今更注意することでもないですが、間違った設定で意図せずzaim.netにアクセスしまくって、Dos攻撃をしているように思われないように注意してください。そのあたりは自己責任で。2
あと、パスワードとIDをconfig.ymlにヒラで書いているので、情報管理には気をつけてください。
(※これは自分自身への注意も込めて)
なんで公式APIを使わないのか?
「ZaimはAPIを公開してくれてる(dev.zaim.net)のに、なんでわざわざスクレイピングしてるの?」って思った人へ。
実は当初は、下記の記事とかを見てzaim api使おうと思っていたのだけど、zaim apiで取ってきたデータだと、”金融機関連携のデータが取得できない”という重大な欠陥があることに気がつき、金融機関連携をフル活用している我が家ではこれは使えんなー、ということになったのでした。(Zaim APIは今も更新されてるけど、2017年10月現在まだ金融機関連携のデータは取得できない模様)
- Fluentd + Elasticsearch + Kibanaで遊んでみた(その1) 〜環境構築から簡単な動作確認まで〜
- ZaimのデータをLogstashでAmazon Elasticsearch Serviceへ投入する
作った後に気づいたけど
何か、似たようなことしてる人がいた。
AirflowとDockerで俺々データ分析基盤をつくってみた&Imageを公開してみた #kwskrb
まあ、scrapyとか本格的なスクレイピングフレームワークをこちらは使ってないし、データの保存先がこちらはelasticsearch使ってるので違うっちゃ違うけど、airflowでの管理の部分は恐らく似たような感じと推測。
この記事を先に読んでいたら、多分自分もAirflowは使わなかったなーと思う。結構構築のハマりどころが多かったし、このシンプルなジョブの管理にはAirflowは重い。
今後
とりあえず動くのでまあ家庭用の環境としては良し。せっかくelasticsearch使ってるので、kibanaとは別の描画や分析基盤を作ってみようかと模索中。
-
スケジュールされたジョブが上手く実行されないことがあるため2017/11/5に追記。What’s the deal with start_date?によれば、start_dateをdatetime.now()などで与えるとstart_dateが動的に変わってしまって、永遠にスケジュールされた時刻にたどり着けないらしい。schedule_intervalを時刻指定で与えていれば大丈夫だろうと思っていたけど、どうやらそれでもダメらしい。 ↩ ↩2
-
1にも関連するけど、start_dateの与え方を失敗してすごく過去の日付を与えてしまうと、start_dateから今まで実行されていなかったジョブが並列実行可能な上限値で一気に走って大変なことになる模様。(airflowもうちょっと何とかならんのか。。。)(2017/10/5現在) ↩