関連
https://qiita.com/ilovegalois/items/cf4b11899bc6cd76f607
PowerQuery上ではエラーじゃないのに読み込むとエラーになる?
PowerQueryでクエリ定義をしたあと、PowerBI(もしくはExcel)にデータを読み込もうとすると、次のようなエラーが出ることがあります。
今回エラーが出たのは、「フォルダからの読み込み」で出てきたファイル一覧をそのままテーブルとして読み込んだ場合です。
(ファイル名とフォルダパスは秘匿情報のため列ごと削除しました)
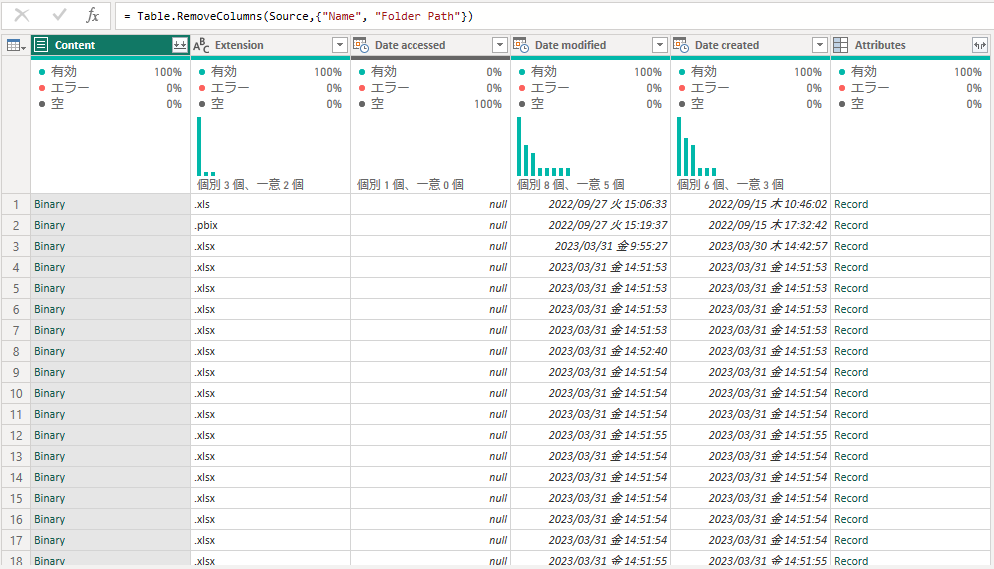
PowerQuery上では何もエラーが出ていませんが、このクエリを適用する(読み込む)と、次のようにエラーと表示されました。(エラーが表示されないこともあります。)
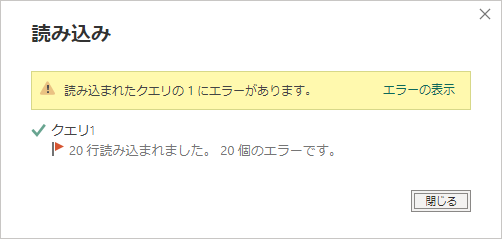
このまま「閉じる」にするとエラーでとまってしまって読み込めないので、「エラーの表示」を押すことになりますが、すると次のようなクエリが作られます。
再度PowerQueryを開いて、「クエリ1のエラー」を削除してから適用すると、エラーなく読み込むことができますが、クエリを更新するとやはり同じエラーが出てしまいます。
また、この謎のエラーは、PowerQuery上では確認ができず、PowerQueryからPowerBI(もしくはExcel)にデータを読み込んだり、読み込んだデータをPowerBI(もしくはExcel)上で更新したりすると発生します。
そのため、具体的にどこでエラーが出ているのか特定するのが難しいのが実情です。
これは何のエラーなのか、今回どう対処したのか、という内容です。
PowerQueryのエラーの種類について
PowerQueryのエラーについて、公式ドキュメント、および下記サイトがわかりやすくまとまっています。
まず、PowerQueryで起こるエラーには、いくつか種類がありますが、大きく分類すると次の2種類に分類できます。
- ステップレベルのエラー
- セルレベルのエラー
ステップレベルのエラー
ステップレベルのエラーは、エラーが発生するとクエリがPowerQueryでプレビューできず、摘要(読み込み)もできなくなります。
このエラーが発生した場合は、エラーが発生したステップで黄色ペインが出て、エラーの理由が表示されます。
PowerQuery上でエラーを確認できるため、わかりやすいエラーと言えます。
セルレベルのエラー
セルレベルのエラーは、エラーが発生していてもクエリを適用(読み込む)ことが可能です。
さらにPowerQuery上でもプレビューができてしまうため、比較的わかりにくいエラーと言えます。
セルレベルのエラーは、どこかのセルが何らかの理由によりError値になっていることが原因であることが多いです。事前の対処としては、データプロファイリングツールを利用してエラーが出ている列がないか探す方法が有力です。
エラーが見つかった列については、エラーの削除やエラーの置換などの対処をすることにより、セルレベルのエラーが解決されることになります。
また、セルレベルのエラーは、読み込むと「クエリのエラー」というクエリが自動的に作られます。このクエリの中身を調べることでも、エラー原因特定に繋がると思われます。
今回の事例では
以上がPowerQueryのエラーについての一般論で、ここまでは前置きです。
今回のエラーはクエリの適用(読み込み)時に出てきたエラーなので、セルレベルのエラーということになります。
セルレベルのエラーなので、セオリー通りに進めると、エラー値が出ている列を探してエラー値を削除もしくは置換する、ということになるのですが…
今回はどこにもエラー値が見つかりません。
では一体何のエラーが出ているのか、どう対処したらいいのか、というのが今回の本論です。
「クエリ1のエラー」というクエリを見てみる
読み込み時に発生したエラーが原因で、「クエリ1のエラー」というクエリが作られています。この中を調べると原因が特定できるかもしれませんので中身を見てみましょう。
let
ソース = クエリ1,
型の不一致が検出されました = let
tableWithOnlyPrimitiveTypes = Table.SelectColumns(ソース, Table.ColumnsOfType(ソース, {type nullable number, type nullable text, type nullable logical, type nullable date, type nullable datetime, type nullable datetimezone, type nullable time, type nullable duration})),
recordTypeFields = Type.RecordFields(Type.TableRow(Value.Type(tableWithOnlyPrimitiveTypes))),
fieldNames = Record.FieldNames(recordTypeFields),
fieldTypes = List.Transform(Record.ToList(recordTypeFields), each [Type]),
pairs = List.Transform(List.Positions(fieldNames), (i) => {fieldNames{i}, (v) => if v = null or Value.Is(v, fieldTypes{i}) then v else error [Message = "値の型が列の型と一致しません。", Detail = v], fieldTypes{i}})
in
Table.TransformColumns(ソース, pairs),
追加されたインデックス = Table.AddIndexColumn(型の不一致が検出されました, "行番号" ,1),
保存されたエラー = Table.SelectRowsWithErrors(追加されたインデックス, {"Content", "Name", "Extension", "Date accessed", "Date modified", "Date created", "Attributes", "Folder Path"}),
並べ替えられた列 = Table.ReorderColumns(保存されたエラー, {"行番号", "Content", "Name", "Extension", "Date accessed", "Date modified", "Date created", "Attributes", "Folder Path"})
in
並べ替えられた列
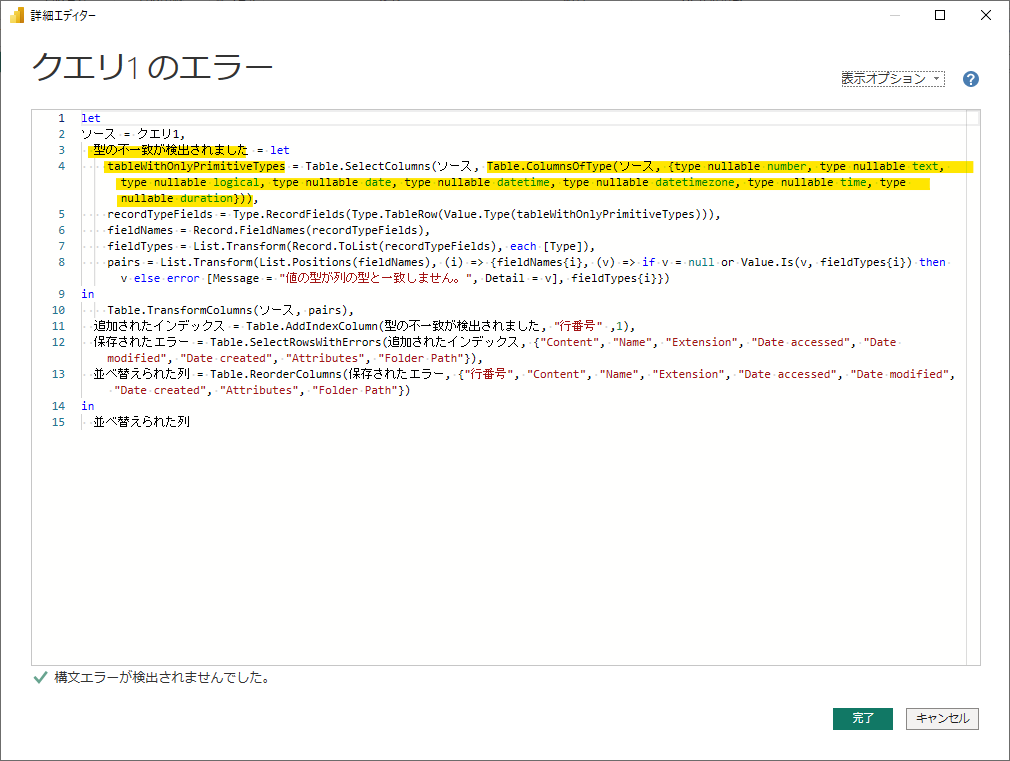
まず、エラーの症状ですが、「型の不一致が検出されました」とあります。
さらにその中身を見てみると、tableWithOnlyPrimitiveTypesというステップがあり、何やら「プリミティブ型のみからなるテーブル」にしようとしているようです。
公式ドキュメントにも以下の記載がありました。
データ型で定義された列にAnyスカラー以外の値が含まれている場合、このような値は読み込み中にエラーとして報告されます (Excel のブックやPower BI Desktopのデータ モデルなど)。
考えられる解決策:
エラーを含む列を削除するか、そのような列に非Any データ型を設定します。
結合を実行する前にテーブルをフラット化して、入れ子になった構造化値 (テーブル、レコード、リストなど) を含む列を排除します。
ここで、今回はフォルダからの読み込みをしているので、Contentという列にbinary型のデータがあることを思い出します。
このbinaryが悪さをしているのではないか、と推測しました。
このContent列を削除してしまえば話は早いのですが、今回の案件ではこのContent列も使用しているため、削除はできません。
そこで、あまり意味はないような気はしましたが、列の型を明示的にバイナリに変換してから読み込んでみました。
(既に「データ型:バイナリ」になっていましたが、GUIで明示的にバイナリ型を選択し直すと、binary型に変換するステップが追加されました)

この状態で適用・更新すると、セルレベルのエラーは起こらず、「クエリのエラー」というクエリも作られることはなくなりました。
まとめ
PowerQueryのエラーには、ステップレベルのエラーとセルレベルのエラーがあり、セルレベルのエラーだと今回のように原因の特定が少し厄介です。
セルレベルのエラーが出た時は、まずはセオリーに従って、エラー値を探して対処、「クエリのエラー」が作られた場合はその中身を調べる、というのがデバッグ手順になりそうです。
また、今回「テーブルがプリミティブ型以外の列を含む場合、PowerQuery上で問題なく型指定できているように見えても、場合によっては型を明示的に指定する(明示的に変換する)必要がある」ということがわかりました。