以前、クエリを実行後にエラーが出たときの対処法の一つを記事に書きました。
そのときは、セルレベルのエラーのときに作られる「クエリのエラー」というクエリの意味がよくわからず、デバッグが完了したかどうかを「読み込んだときにエラーが出るかどうか」で判断していました。
この「クエリのエラー」というクエリについて、ネットで調べてもあまり情報が見当たらないようなのですが、意味と使い方がわかったので、今回はそれについて説明します。
結論から言うと、「PowerQueryの機能を使ってデバッグするためのクエリ」でした。
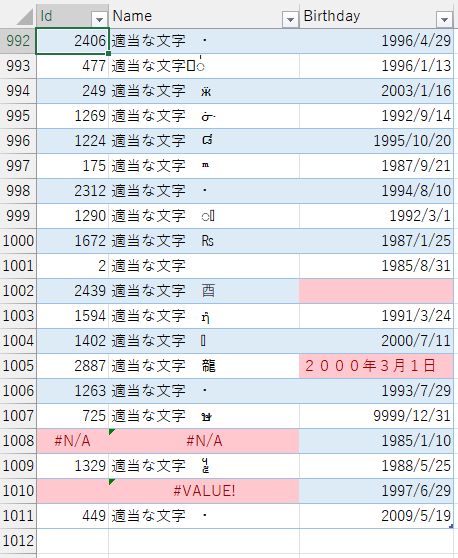
説明用のデータとして、下記のテーブルを使うことにします。
全部で1010行あり、赤く目立たせているのはエラーが出そうなセルです。
上位1000行では特にエラーは出ていません。
次節で説明するように、「上位1000行」というのが重要なファクターとなります。
PowerQueryの仕様と、セルレベルエラーがクエリ編集時にわからない理由
PowerQueryはデータを高速に読み込むための特化したツールです。
そのための工夫として、PowerQueryは「上位1000行を代表値として扱い、それ以降の値はクエリ編集時には無視する、もしくは推測値として扱う」という仕様になっています。
もし上位1000行以降の値も必要な場合は、別途指定しなければなりません。
たとえば列のプロファイリングについて、デフォルトでは左下に「上位1000行に基づく列のプロファイリング」と表示されています。この設定では、列の型検出やエラー値の検出などは上位1000行のみがサンプル値として使われるため、上位1000行以降に型が合わない値やエラー値があったりしても検出されません。
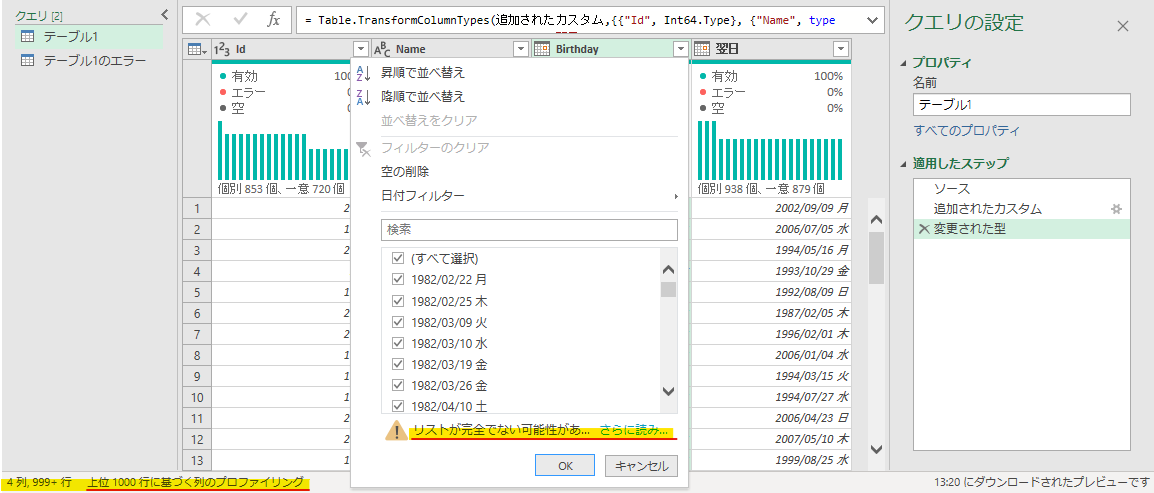
列全体に対してプロファイリングしたい場合はクリックして「データセット全体に基づく列のプロファイリング」に設定変更しなければなりません。
データセット全体でプロファイリングすると、列毎に表示されている分布と品質グラフが変わったのがわかります。(なお、分布と品質グラフはどちらも表示タブでオンオフを切り替えられます)
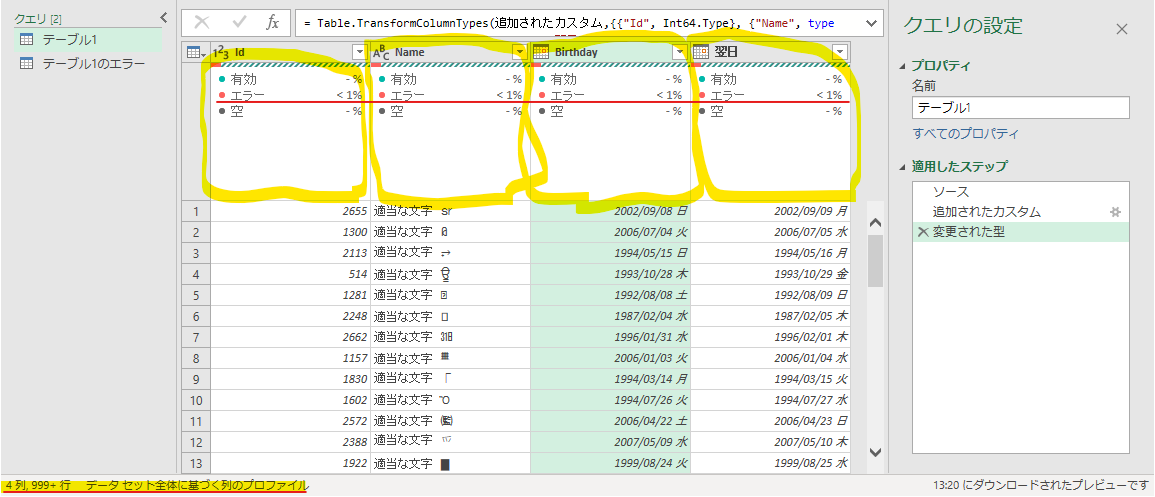
また、列をフィルターしたりソートしようとしたりするとき、ビックリマークで「リストが完全でない場合があります。」と表示されることがあります。これも同じで、デフォルトでは上位1000行の値しか見ていないためです。「さらに表示する」を押せば全ての値を拾うことができますが、これは設定ではないためプルダウンを開くたび毎回確認されます。
(20230520追記 Kagataさんによると「このプルダウンに表示されるのは上位3000行の一意な値」とのこと。)
PowerQueryがこのような仕様になっているため、セルレベルのエラーの多くは読み込んだときに初めて見つかるわけです。
「クエリのエラー」クエリでセルレベルエラーをデバッグする
PowerQueryがクエリ編集時には上位1000行しか見ないために、読み込み時に初めてセルレベルエラーが見つかるという理由はわかりました。
問題はどのようにデバッグするかです。
ここで「クエリのエラー」クエリの出番です。今回はもとのクエリがテーブル1という名前のため、テーブル1のエラーという名前になっています。
(「クエリのエラー」クエリって呼び方がめっちゃややこしいんですけど、なんか正式な呼び名はないんでしょうか)
「クエリのエラー」クエリとは、セルレベルのエラーが見つかった時に作られるクエリです。
これの見方がめちゃくちゃわかりにくいんですが、このクエリは「PowerQueryの機能を使ってデバッグするためのクエリ」です。
ヘルパークエリ(PowerQueryが自動で生成してくれるクエリ)の一種と言えます。
それでは以下でこのクエリの見方と、それを使ったデバッグ方法を説明していきます。
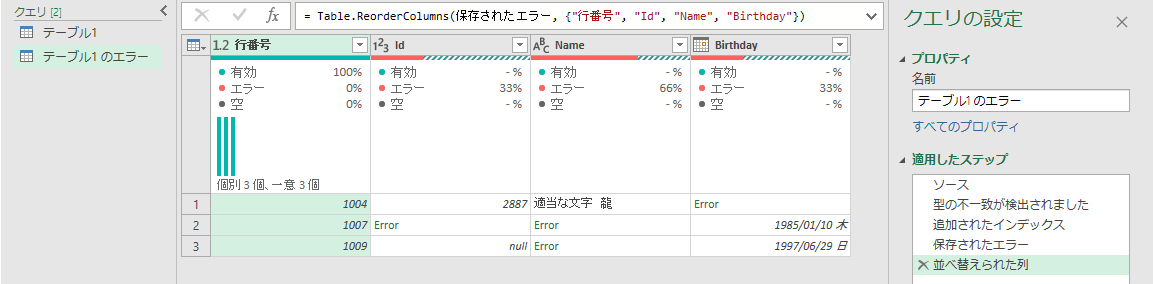
「クエリのエラー」クエリの見方
ソースのステップ
読み込み時にセルレベルエラーが発生したクエリ(通常はテーブル)をそのままソースとして呼び出すステップです。
セルレベルのエラーなので、このステップではエラーは見つかりません。
「型の不一致が検出されました」のステップ
かなりわかりにくいステップ名ですが、テーブルの各列の型をプリミティブ型に変換するステップのようです。
詳細エディターで見ると、tableWithOnlyPrimitiveTypesと書かれており、このステップでプリミティブ型に変換できない列が見つかった場合「値の型が列の型と一致しません。」というエラーが出るように定義されているようです。
PowerQueryからPowerBIやExcelにテーブルを読み込むとき、プリミティブ型でしか読み込めないため、このステップが入れてあるようです。
このステップについてはまだよくわかっていないので、今回はスルーすることにします。
追加されたインデックス
このステップではデバッグ用のインデックス列を追加します。
セルレベルのエラーは、セルの値毎に出るエラーなので、セル毎に見ないとエラーが出ているかどうかの判断ができません。
「セルレベルエラーが何行目で出ているのか」を調べるために、インデックス列を追加しているのがこのステップです。
保存されたエラー
これが最後のステップです。(この後に「並び替えられた列」というステップも追加されてますが、行番号列を一番左に持ってきているだけのステップなので無視していいです)
このステップでは、Table.SelectRowsWithErrorsという関数を使ってセルレベルエラーが発生した行だけにフィルターします。GUIの「行数の保持 > エラーの保持」という操作に相当します。
セルレベルエラーが出ている列は、列ヘッダの下に赤色バーが出ます。ちなみに黒色バーはnullの列、青色バーは値が有効な列です。
「クエリのエラー」クエリを使ったデバッグ方法
使い方は簡単です。
- 「クエリのエラー」クエリの最後の結果を見て、セルレベルエラーが出ている列とその行番号を確認する
- 列と行番号を確認したら、もとのソースに戻って、行の保持または行の削除をして、セルレベルエラーが出ている行が表示されるように調整する(列数が多いとき、デバッグ中だけ関係のない列を削除しておくと、デバッグ効率があがります)
- セルレベルエラーが発生しているはずなので、セルレベルエラーの原因を調査してエラーを対処する(必要ならステップを辿って行く)
この作業を「クエリのエラー」クエリが空テーブルになるまで繰り返せば、デバッグ終了です。
意味がわかれば、「クエリのエラー」クエリの生成手順(インデックス列を追加してエラーのみにフィルターする)を真似して自分でデバッグすることもできますね。
追記:
少しだけ効率よくデバッグする方法があるのに気づきました。
手順
- デバッグしたいクエリ(テーブル)の最後で「エラーの保持」をする
- 上位行にエラーが出てきているはずなので、エラーの出ている列を探して全て選択(Ctrl押しながらクリック)する
- 「他の列の削除」をする
- Table.RowCount関数で行数を取得する
- 各エラーの原因を特定して対処し、対処できたら削除した列をもとに戻す
- 以上をエラーが出なくなる(=エラーの行数が0になる、あるいは同じことだけど「エラーの保持」でテーブルが空になる)まで繰り返す
つまり、デバッグも同じクエリ内でやってしまえば、インデックス列を追加する必要がない(もともとインデックス列を追加したのはエラーの出ている行まで辿るためだったけど、「エラーの保持」はそもそもエラーの出ている行だけを抽出してくれる)ということです。
また、デバッグのときは基本的にエラーの出ていない列についてはあまり興味がないわけですが、エラーの列の選択もGUIでやってしまえばよかったのです。
最後の評価も、テーブルそのものを出力せずに行数だけ出力すると、テーブルの中身を評価しなくていいのでちょっとだけ早いんじゃないかなと(列数が多いときは特に)。
で、この手順で支障があるときに初めて、インデックス列を追加したりすればいいわけです。
補足:オーバーフローについて
オーバーフロー(処理できる許容範囲を越えているような値が発生している状況)も、各セルを評価して初めて発生するエラーなので、ある意味でセルレベルエラーと言えます。
ただしオーバーフローが発生するとクエリの評価が完全にとまってしまい、どこでエラーが発生したのかもわかりません。
たとえば次の例は、Birthday列にBirthdayの翌日という列を追加しています。
Birthday列に9999年12月31日という値があり、その翌日をPowerQueryで処理できないため、オーバーフローになっています。
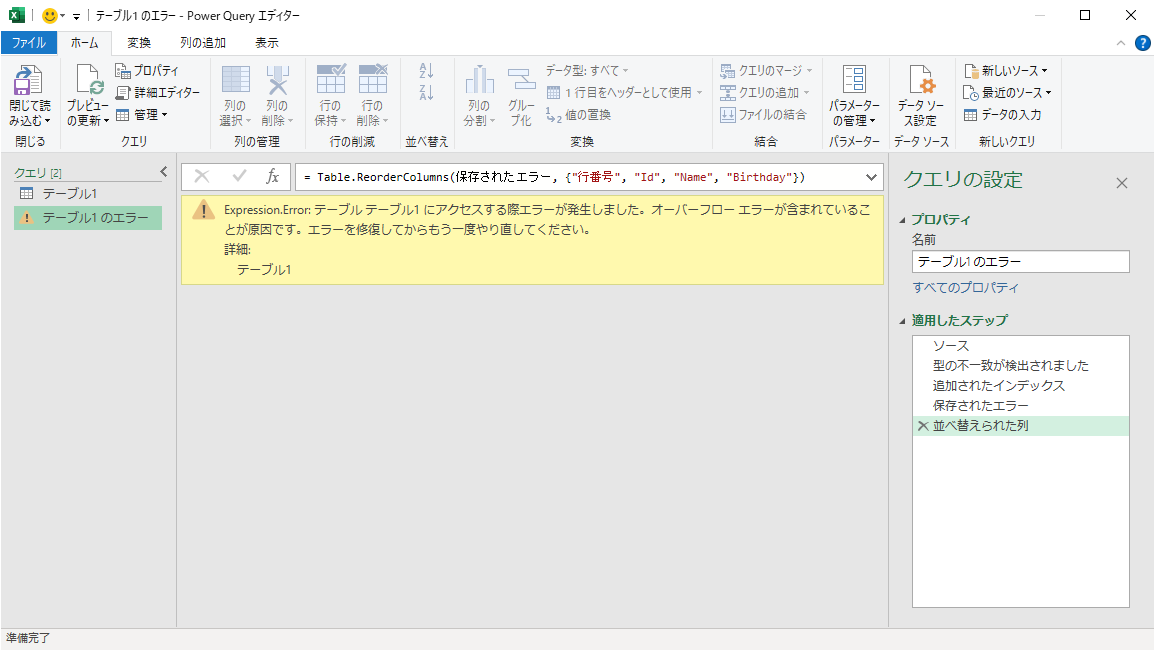
オーバーフローしないように気を付けましょう。
おわりに
今回はセルレベルエラーについて、クエリ編集時にエラーがすぐに見つからない理由と、対処法の一般論を説明しました。
わかってみれば簡単なことですが、あんまりこのことについての解説を見たことがないのは何なんでしょう、検索が下手なだけ…?