1. はじめに
ChatGPTをはじめとする大規模言語モデル(LLM; Large Language Model)が、事実と異なる出力をするハルシネーション(幻覚)と呼ばれる現象は、LLMを活用する場面だけでなく学術研究の場でも問題視されており、それを回避・軽減する方法が研究されています(たとえば、L. Huang et al., 2023をご覧ください)。
ハルシネーションには、LLMが学習データとは異なる出力をするIntrinsic hallucinationと、学習データに含まれないが事実と異なる内容を出力するExtrinsic hallucinationの二種類があります。
本記事では、特にIntrinsic hallucinationを検出するしくみとして、LLM Factoscope: Uncovering LLMs’ Factual Discernment through Inner States Analysisで提案されているLLM factoscopeを紹介します。(LLMの概要や基礎的な理論についてはこちらの記事をご参照ください。)
2. 論文「LLM Factoscope: Uncovering ~」の要点
この論文では、LLMが生成する出力の事実性(事実であるか否か)を検出するための新しいモデル、LLM factoscopeを紹介しています。このモデルは、LLMの内部状態を解析することで、事実とそうでないものを区別します。論文中の検証では、LLMの内部状態に見られるパターンを利用して、事実性を96%以上の精度で検出することに成功しています。この結果から、LLM factoscopeは、LLMの信頼性と透明性を向上させる新しいアプローチといえるでしょう。
ハルシネーションの対策には、プロンプトエンジニアリングに関係するもの(たとえば、検索拡張生成(RAG; Retrieval Augmented Generationを利用するもの)や、教師ありファインチューニング(SFT; Supervised Fine-Tuning)を行うものなどがあります(詳細はS. M. Tonomoy et al., 2024などをご参照ください)が、このアプローチはLLMの内部状態のみを利用し、外部データベースを利用しないという点でユニークなものといえます。
3. LLM factoscope
3-1. 着想:LLMの内部状態から嘘を見破る
ハルシネーションの検出は、LLMの出力を外部データベースを参照してクロスチェックする方法が主流(たとえば、B. Peng et al., 2023 、H. Cao et al., 2023をご参照ください)ですが、LLMを含むシステムが複雑になったり、外部データベースの依存度が高くなったりする課題があります。
この論文では、人間の心拍数などから噓を見破る噓発見器に着想を得て、LLMの内部状態からハルシネーションを検出するアプローチを提案しています。つまり、ハルシネーションが起きている場合とそうでない場合で異なる内部状態を示すという仮説にもとづいています。著者らの調査では、Llama-2-7Bが正しい出力をした場合 (緑線)とハルシネーションを起こした場合(紫線)では、内部状態(各層)の活性化パターンに違いがあることを示しています(図1)。これは、LLMの内部状態を観察することで、ハルシネーションを起こしているかが判断できることを示唆します。
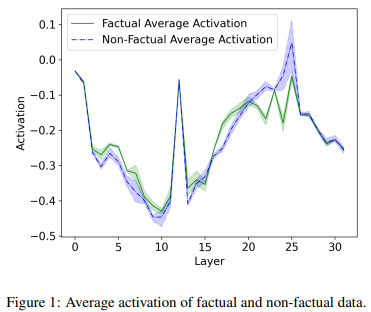
図1: LLMの内部状態の活性化パターン(J. He et al., 2023 Fig.1を引用)
3-2. LLM factoscopeのパイプライン
それでは、LLM factoscopeのしくみを見ていきましょう。LLM factoscopeは、以下のパイプラインによって構築されます(図2)。
-
1. データ収集
- Kaggleレポジトリーからデータを取得し、事実に関するプロンプトと回答のペアを生成する
-
2. 内部状態の収集
- LLMの内部状態として、activation map, final output rank, top-k output index, top-k output probabilityを収集する
-
3. 内部状態の前処理
- 内部状態のデータの変換を行い、モデルの学習に適した形式へ変換する
-
4. モデル構築・推論
- Siamese Networkベースで、事実であるデータどうし/事実でないデータどうしの類似度が高くなるようなモデルを構築する
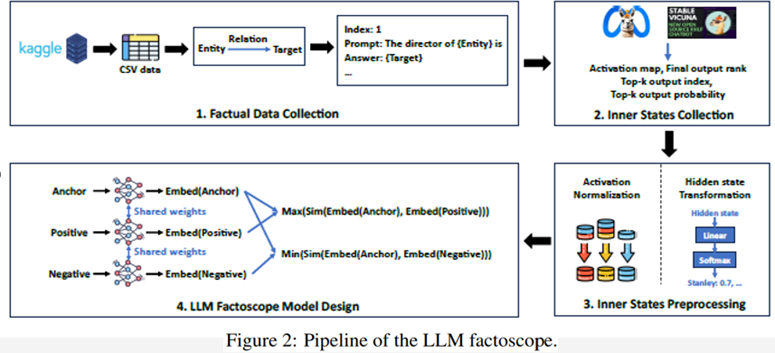
図2: LLM factoscopeのpipeline(J. He et al., 2023 Fig.2を引用)
以降では、各ステップについて詳細に解説します。
3-2-1. データ収集
KaggleレポジトリーからCSV形式の構造化データを取得し、事実に関するプロンプトと回答のペアを生成します。取得するデータは、芸術やスポーツをはじめ、さまざまな分野の知識を含みます(図3)。たとえば、映画題名とその監督名など特定の関係があるデータ(例:映画題名;2001年宇宙の旅→監督;スタンリー・キューブリック)を取得します。そして、このデータをもとに、LLMに与えるプロンプトと回答を作成します。このデータセットは、LLMの回答が事実と合致しているかを確認するために使用されます。
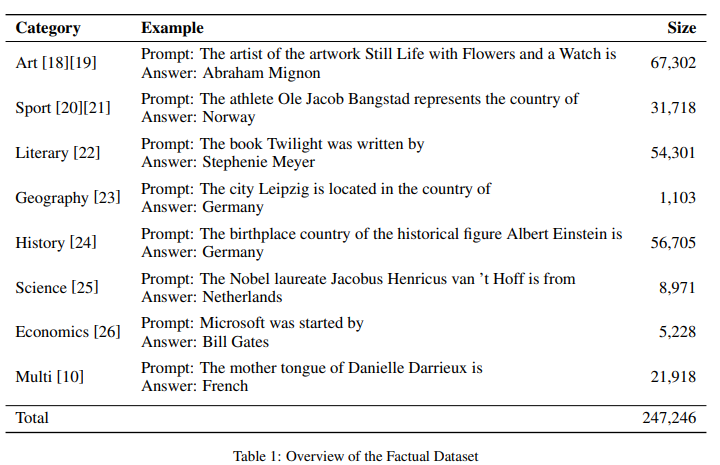
図3: データセットの概要(J. He et al., 2023 Table 1を引用)
3-2-2. 内部状態の収集
作成したプロンプトをLLMに与えたときのLLMの内部状態を取得します。内部状態として、activation map, final output rank, top-k output index, top-k output probabilityの4つを収集します。
activation map
LLMが処理したプロンプトの最後のトークンのactivation valueを表します。LLMは、各層を走査しながらプロンプトに関連する情報を取得しますが、正しい情報が取得できたかどうかで異なる活性化パターンを示すことが予想されるため、activation mapによってそのパターンを捉えることを狙っています。
final output rank
LLMの各層の確率分布における最終出力トークンのランクを表します。具体的には、各層の隠れ状態を取得し、最終的な隠れ層で行われたのと同様の語彙マッピングを適用して得たロジットを降順に並べたときのランクです。最終出力トークンの尤度が層間でどのように変化するかを示します。
top-k output index, top-k output probability
final output rankで使われた各層のロジットにソフトマックス関数を適用して得た、上位k個のトークンのランクおよび確率です。これらのトークンの層内・層間の関係は、モデル処理における認知的側面に光を当てます。top-k output index, top-k output probabilityのイメージを図4に示します。図4は、"The car"の後に続く10個の単語(トークン)の生起確率を示しており、この確率がtop-10 probability、その順位がtop-10 index に相当します。
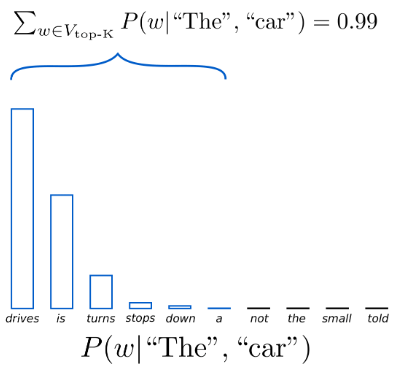
図4:”The car”に後続する単語(トークン)のtop-10までの順位とその確率(引用元: https://aidsrentfree.github.io/settings/ )
3-2-3. 内部状態の前処理
収集した内部状態のデータの正規化と変換を行い、モデルの学習に適した形式へ変換します。
- activation map
- 標準化
- final output rank
- $[0, 1]$の範囲に収まるように、ランク$r$を以下の式にしたがって正規化
- $r_{transformed} = 1 / [(1 - r) + 1 + 10^{-7}]$
- top-k output index
- トークンの埋め込みベクトル間のコサイン類似度を算出
- top-k output probability
- 前処理なし(確率値であり、変換なしでも$[0, 1]$の範囲に収まるため)
3-2-4. モデル構築・推論
正規化・変換を施した内部状態のデータをインプットとし、Siamese Networkベースでモデルを構築します。
Siamese network
Siamese networkは、few-shot学習における課題を解消するため、入力データのペアの類似点・相違点を識別するために設計されたモデルです。このモデルは、重みを共有する2つの同一のニューラルネットワークで構成されており、類似したデータがより近くに、類似していないデータがより遠くになるような特徴量空間を学習することを目的としています。
LLM factoscopeでは、事実であるデータどうし/事実でないデータどうしの類似度が高くなる、そして事実であるデータと事実でないデータの類似度は低くなるようなモデルを構築します。
学習
学習の際は、まず4つの内部状態それぞれについてサブモデルを構築します。activation map, top-k output index, top-k output probabilityについてはCNNの一つであるResNet18、final output rankについてはゲート付き回帰型ユニット(GRU; Gated Recurrent Unit)を利用し、それぞれの埋め込みベクトルを得ます。そして、線形層を使ってそれらの埋め込みベクトルを統合します。
損失関数は、Triplet margin lossを使用します。この損失関数は、同一クラスに属するデータ間の距離を最小化しつつ、異なるクラスに属するデータ間の距離を最大化するように設計されています。ある入力 $x$ の埋め込みベクトルを $E_{anchor}$、$x$と同一クラスのデータ $x_{pos}$ の埋め込みベクトルを $E_{pos}$、$x$と異なるクラスに属するデータ $x_{neg}$ の埋め込みベクトル を $E_{neg}$ としたとき、$E_{anchor}$と$E_{pos}$間の距離 ${\rm Dist}(E_{anchor}, E_{pos})$が、$E_{anchor}$と$E_{neg}$間の距離 ${\rm Dist}(E_{anchor}, E_{neg})$ より小さくなるようにします(参考:https://qiita.com/tancoro/items/35d0925de74f21bfff14 )。この損失関数は、ハイパーパラメータ$\alpha$を用いて次の式で表されます。
L = \max ({\rm Dist}(E_{anchor}, E_{pos}) - {\rm Dist}(E_{anchor}, E_{neg}) + \alpha, 0)
この$\alpha$を調整することで、あるデータと同一クラスのデータとの類似度が、異なるクラスのデータの類似度より少なくとも$\alpha$だけ大きくなるようにしつつ、この損失関数を最小化することで、モデルの精度を向上させます。
推論(検証)
推論の際は、(学習データに含まれない)ラベル付けされたサポートデータセットを使用します。サポートセット ${S_1, \cdots, S_n}$ と対応するターゲット ${T_{sup_1}, \cdots, T_{sup_n}}$ を用意し、LLM factoscopeを介してサポートセット内の各サンプルから埋め込みベクトル ${E_{sup_1}, ...E_{sup_n}}$ を生成しておきます。そして、推論対象のデータ(検証データ)の埋め込みベクトルを ${E_{test}}$ とし、検証データに最も距離が近いサンプルのターゲットを $T_{test}$ の推定値とします。つまり、$i^{\ast} = argmin_i \ {\rm Dist}(E_{test}, E_{sup_{i}})$ を満たすサンプル $i^{\ast}$ を使って ${T_{test} = T_{sup_{i^{\ast}}}}$ とします。
サポートセット(の埋め込み表現)の類似度を利用することで、高い精度の推論を実現しています。
3-3. 評価
3-3-1. 評価環境
実験環境とLLMアーキテクチャ
実験環境は以下の通りです。
- Intel Xeon Silver 4314 CPU (2.40GHz)*32
- RAM 386GB
- NVIDIA A100 Tensor Core GPU *4
- OS: Ubuntu20.04 LTS
また、論文中の精度評価に使用されたLLMアーキテクチャは以下の6種です。
- GPT2-XL
- LLaMA-2-7B
- LLaMA-2-13B
- Vicuna-7B-v1.5
- Vicuna-13B-v1.5
- StableLM 7B
データセット
図3に示した、芸術、スポーツ、科学などさまざまな分野のデータセットを使用しています。なお、事実であるデータと事実でないデータを同数ずつランダムに選択しています。
LLM factoscopeの詳細設定
top-kはtop-10とし、4つの内部状態の出力(それぞれ24次元)を結合した後、64次元まで次元削減しています。推論(検証)の際のサポートセットのデータサイズは100としています。
3-3-2. 評価結果
LLM factoscopeの効果
LLM factoscopeは、どのLLMアーキテクチャにおいても96.1%~98.3%の高い精度を達成したことが示されています。なお、ベースラインとしては、各LLMアーキテクチャの特定の層のactivation valueを事実性の検出タスクの学習に用いたものを使用しています。LLM factoscopeはベースラインと比較して一貫して高い精度を示していることから、LLM factoscopeは層をまたぐ内部状態の情報を活用していることが示唆されます。この結果は、LLMの出力を理解する上で内部状態が重要であることを示すだけでなく、LLMの複雑なふるまいを探求する新たな道を開いたと著者は述べています。

図5: LLM factoscope(Ours)とベースライン(Baseline)の精度比較結果(J. He et al., 2023 Table 2を引用)
また、汎化性能の評価においても、ほとんどのケースでベースラインの精度を上回ったことが示されています。
LLM factoscopeの解釈性
論文中では、LLM factoscope の解釈性、つまり4つの内部状態が事実性検出にどう寄与しているかについても議論されています。分析の結果、4つの内部状態のいずれについても、中間層から深い層の影響が大きいことが示されています。図6は、4つの内部状態の各層における寄与を可視化したものであり、主に15層以降で正の寄与が大きいことが見て取れます。この結果は、浅い層では意味的に整合性のある出力候補をフィルタリングし、深い層では与えられたプロンプトに関連する出力候補に徐々に焦点を合わせていることを示唆しています。
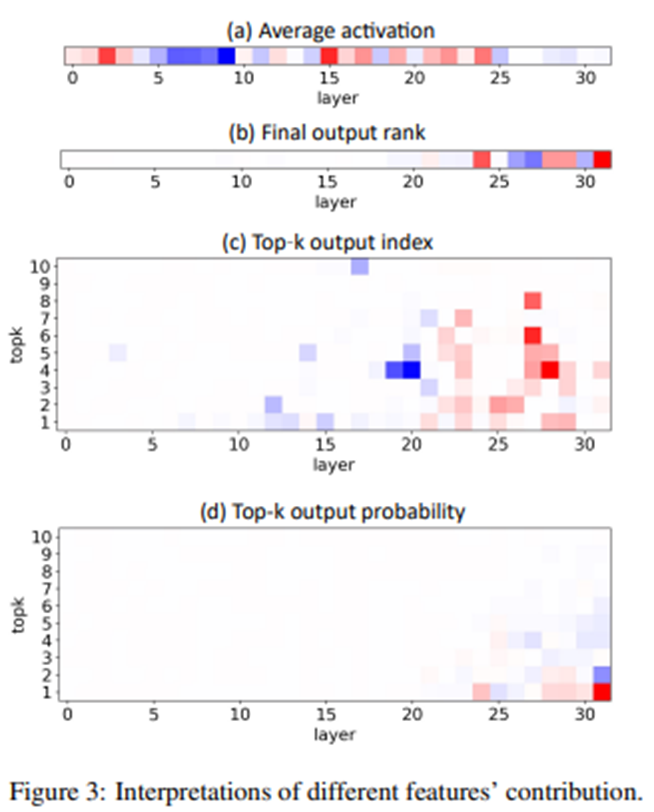
図6: LLM factoscopeにおける4つの内部状態の寄与(赤色は正の寄与、青色は負の寄与を示す)(J. He et al., 2023 Fig.3を引用)
Ablation study
また、著者らはここまでの検証における一部の条件を変化させたablation studyも行っているので、本節で簡単に紹介します。
まず、内部状態を学習するサブモデルの影響を評価するため、サブモデルを1つずつ追加していった場合の評価を行っています。その結果、サブモデルが多いほど精度が向上しており、それぞれのサブモデルが汎化性能の向上に寄与していることが示されています。
また、top-kのkの値を2, 4, 6, 8, 10と変化させた場合の評価を行っています。その結果、k=10で最も精度が良かったものの、大きく精度は変化せず、事実性の検出に関する精度には正の相関がなかったことも報告しています。
さらに、テスト用のサポートセットのデータサイズを50~250の範囲で変化させた場合の評価を行っています。その結果、データサイズを大きくしても精度は大きく変化せず、むしろ偽陰性(事実であるのに事実でないと推定される)データの割合が上昇してしまうことが示されています。
最後に、内部状態を学習するサブモデルのアーキテクチャを変更した場合の精度を評価しており、アーキテクチャの変更によって精度が低下することが示されています。この結果は、サブモデルのアーキテクチャを適切に選択することが、事実性の検出において重要であることを示唆しています。
4. まとめ
この記事では、LLMの内部状態をもとに、出力の事実性を検出するLLM factoscopeを紹介しました。LLMを開発・活用される方、特にハルシネーションを回避・軽減したい方のご参考になれば幸いです。
5. 参考文献
[1] H. Lei et al., A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Nov 2023
[2] J. He et al., LLM Factoscope: Uncovering LLMs' Factual Discernment through Inner States Analysis, Dec 2023
[3] S. M. Tonmoy et al., A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models, Jan 2024
[4] B. Peng et al., Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback, Mar 2023
[5]H. Cao et al., A Step Closer to Comprehensive Answers: Constrained Multi-Stage Question Decomposition with Large Language Models, Nov 2023
[6] Deep Metric Learning の定番⁈ Triplet Lossを徹底解説