1. はじめに
この記事では、2022年に発表されたConvNeXtというアルゴリズムを用いて画像認識モデルを実装し、他アルゴリズムとの精度を比較検証を行います。
本記事では、まず画像認識(2章)について述べ、ConvNeXtと関係の深い画像認識モデルについて紹介(3章)します。4章でConvNeXtの概要と特徴について述べた後、5章で実際に実装を行い精度検証を行っています。
5章にて実際の実装コードを紹介していますので、ConvNeXtを実装して使ってみたいという方の参考になれば幸いです。なお本記事はConvolutional Neural Networks(CNN)やTensorFlowの知識があると読みやすいかと思います。
2. 画像認識と画像分類の概要
本章ではConvNeXtの適用領域である画像認識と、今回精度検証で用いるタスクである画像分類について簡単に纏めます。
2-1. 画像認識とは
画像認識とは、画像に写っている物が何か、どこに写っているかなどを機械的に識別する技術のことを指します。現在では、自動運転や顔認証技術など多くの場面で用いられており、重要な要素技術となっています。画像認識は様々な技術の総称であり、後述する画像分類のほかにも代表的なものとして次のような技術があります。
-
物体検出
画像の中から、対象物の種類特定と位置、個数を検出する技術のことです。SNSで画像から顔や物を検出してタグ付けする、といったことにも活用されています。 -
セグメンテーション
セグメンテーションは画像から様々な情報を抽出する技術のことです。ピクセル単位でラベル付けをするため、画像分類や物体検出よりも詳細な予測を必要とする(対象の形状など)場合に適しています。
医療現場での病変検出や自動車の自動運転などに活用されています。
画像認識に関しては以前投稿した記事も参考になるかと思いますので、ご興味あればご覧いただければと思います。
機械学習・深層学習による画像認識入門
2-2. 画像分類とは
画像分類は画像認識の1つであり、画像に映っている物が何かを識別する技術です。
画像分類は機械学習・深層学習技術を用いる以前から研究の盛んな分野であり、すでに多くのビジネスでも活用されています。主な活用例としては以下ようなものがあります。
- 顔認証
- 文字認識
- 異常検知
3. 既存の画像認識モデル
2000年代では画像認識を機械学習で行う場合、画像の特徴量を人が設計してから機械学習を行っていました。2012年になり初めてディープラーニングが画像認識で用いられるようになってからは、このような特徴量作成も機械学習側で実施されるようになり、それまであった画像認識をはるかに上回る性能のモデルが多く登場しています。
ここでは、ConvNeXtと関係の深いモデルをご紹介します。
-
AlexNet
2012年のILSVRにて優勝した、初のCNNを用いた画像認識モデルです。3つの畳み込み層と2層のプーリング層、そして3層の全結合層からなるモデルです。発表当時は他モデルに比べ高い精度を達成したモデルでよく使われていましたが、より精度の良いモデルが多数提案されている現在ではあまり使われないモデルです。ただ、現在の画像認識モデルの主流の一つであるCNN系列の元祖とも呼ぶべきモデルであり、歴史的に非常に重要なモデルとなります。 -
ResNet
ConvNeXtのベースとなっているモデルです。CNNでは各層が特徴量抽出の役割を果たすため、一般的に層を深くするほど複雑な特徴を抽出出来ると考えられます。しかしながら、従来のCNNモデルでは層を深くすると勾配消失が起きてしまう問題があり、深い層を用いたモデルが構築が困難でした。ResNetでは残差ブロックと呼ばれる機構を導入したことで、層を深くしても勾配消失を発生させることなく学習できるようなり、非常に深い層を持つCNNの実装を可能としました。(ResNet以前のCNNは数十程度の層でしたが、ResNetは152もの層を実現しています。) -
Vision Transformer(ViT)
こちらのモデルは今までご紹介したモデルとは異なり、CNNではなくTransformerとSelf Attentionと呼ばれる技術をベースとしています。TransformerとSelf Attentionは自然言語処理分野で発展した技術ですが、それらを画像認識分野に持ち込んだモデルとなります。画像を複数のパッチに分割し、パッチ間での関連度を考慮した上で、パッチごとの特徴抽出をしています。CNNと比較して学習にかかる時間を削減しつつ高い精度を出したことで注目されています。 -
Swin Transformer
こちらもTransformerを用いたモデルです。先のVision Transformerでは、画像をパッチに分割し、パッチ間の関連度を考慮してパッチごとの特徴量を計算しています。そのため、画像サイズが大きくなると計算量も比例して増大するというデメリットがありました。そのデメリットの解決を目指して提案されたのがSwin Transformerです。Vision Transformerでは全てのパッチの関連度を考慮していましたが、Swin Transformerでは複数のパッチをwindowというグループ(図1の赤枠)に分割し、そのwindow内のみでパッチ間の関連度を考慮した特徴抽出をすることで計算量を削減しています。このとき、隣り合うパッチがWindowによって分割されることで、そのパッチ間の関連度が考慮されない可能性があるため、図1のようにずらしたWindowに対しても特徴抽出をしています。
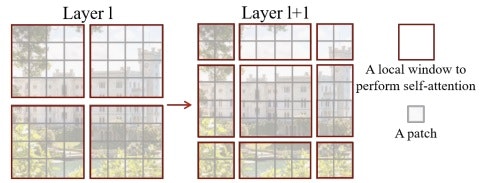
図1:Swin TransformerのShifted Windowの処理(引用元:参考文献 7)
4. ConvNeXtの概要と特徴
ConvNeXtは2022年に発表された、CNNを用いたモデルです。ConvNeXtの利点は、他のモデルよりも高い精度と大幅な計算量の削減により、タスクやデータに応じてスケールアップ、スケールダウンが容易であることです。画像分類だけでなく物体検出や様々な画像認識タスクに用いることができます。
ResNet50をベースとして最新のCNNモデルの手法やTransformerモデルの手法を取り入れることで、代表的な精度検証用のデータセットであるImageNetに対して他モデルよりも高い精度を出したモデルとなっています。
取り入れられた手法としては以下の一覧のとおりです。
-
学習手法の変更
- 最適化関数としてAdamWを採用
AdamWは標準的に使用されるAdamのWeight Decayに関して変更された関数です。Weight Decayは過学習を抑制するために用いられる手法で、AdamWでは通常のAdamより適切なWeight Decayを得ることが出来ると考えられています。 - Stochastic Depthの追加
ランダムで残差ブロックの出力をショートカットのみとする手法です。汎化性能を高め、学習時間を短縮することができます。
- 最適化関数としてAdamWを採用
-
モデルのマクロ構造変更
-
階層構造の変更
ResNetにおいて、ステージごとの残差ブロックは(3, 4, 6, 3)でしたが、Swin Transformerの構造と同じ(3, 3, 9, 3)に変更します。 -
STEMの変更
STEMとはモデル構造において、入力された画像を一番最初に処理する部分です。
Transformerモデルでは、このSTEMで入力された画像をPatchにする処理が行われています。これに倣い、ConvNeXtでは画像に対して4×4 Conv Stride = 4でフィルタする処理が行われています。 -
Conv層⇒Depthwise Conv層へ変更
入力チャンネルごとにフィルタを用意して畳み込みをする手法です。通常のconvと比較してパラメータ数を大幅に削減できるのが特徴です。 -
Bottleneck構造⇒Inverted Bottleneck構造へ変更
従来のBottleneck構造は図2(a)の構造をとっていますが、ConvNeXtではInverted Bottleneck構造図2(b)が用いられています。Inverted Bottleneck構造はTransformerでも使用されている構造です。この構造の特徴は入力と出力のチャンネル数は同じで、中間層の次元が入出力チャンネルの4倍大きくなるという点です。そのため、ショートカットによって渡される情報量がBottleneck構造より削減されており、全体の計算量が削減されています。 -
カーネルサイズを7×7に変更
従来のCNNでは小さいカーネルサイズを使用していましたが、Swin Transformerのwindowサイズに倣って7×7のカーネルサイズに変更しています。また、Swin Transformerの構造に倣い、7×7のカーネルサイズをInverted Bottleneck構造の先頭に移動しています(図2(c))。
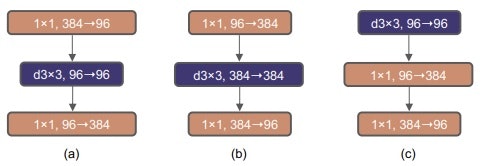
図2:Bottleneck構造とInverted Bottleneck構造(引用元:参考文献 1)
-
-
モデルのミクロ構造変更
-
Relu⇒GELUへ変更
従来では活性化関数にReLUが頻繁に用いられていましたが、GPTやViTなどの最新モデルでよく用いられているGELUに変更しています。また、Transformerに倣って使用する箇所も減らしています。 -
Batch Normalization⇒Layer Normalization(LN)へ変更
こちらもTransformer系モデルに倣ってLNに変更し、使用する箇所を制限しています。
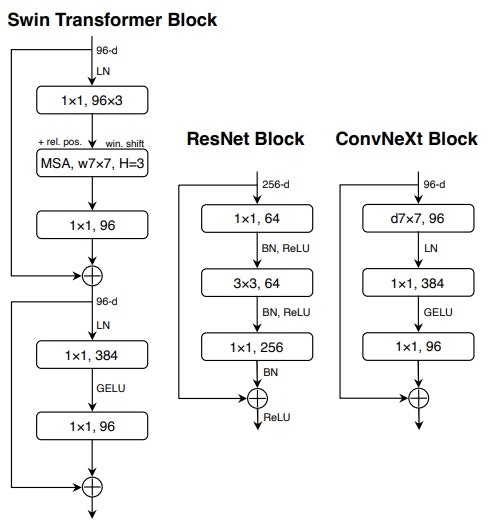
図3:Swin Transformer, ResNet, ConvNeXtそれぞれの構造(引用元:参考文献 1) -
ダウンサンプリング変更
ResNetでは各ステージの最初の残差ブロックでダウンサンプリングを行っています。Swin Transformerでは、各ステージ間にダウンサンプリングを行っているため、ConvNeXtでもダウンサンプリングを各ステージ間としています。
-
以上の内容を変更することによりConvNeXtモデルが構築されます。これらの構造変更がおのおのどの程度精度への影響するかが原論文で調べられており、図4のような結果が得られています。
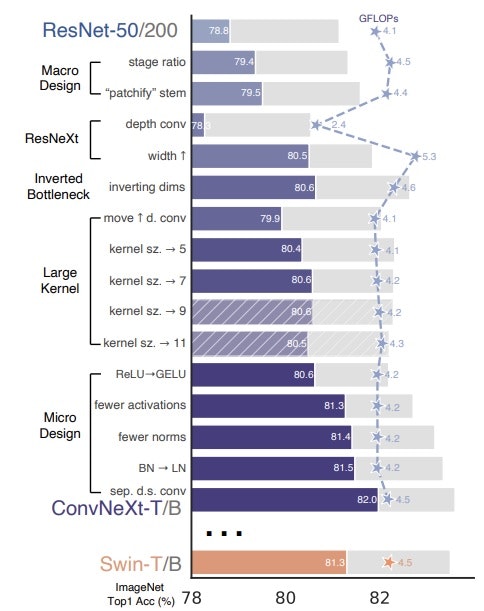
図4:ConvNeXtの各構造変更と精度の変遷(引用元:参考文献 1)
5. ConvNeXtの実装
本章では、実際にConvNeXtモデルを実装していきます。
また実装したモデルの精度と、他モデルの精度を比較します。
今回の画像認識タスクの設定
今回行う画像認識タスクは、多クラスの画像分類タスクとします。つまり、入力した画像に映る物体が何であるかを適切に分類出来ることを目指します。
実装環境
- OS:Ubuntu-18.04(AWS EC2)
- Python:3.8
- Tensorflow:2.6.2
使用するデータセット
今回はCIFAR-10と呼ばれる、10種類のクラスに分かれた画像セットを用います。
CIFAR-10の詳細は以下の通りです。
- データ数:6万枚の画像
- 訓練データ用: 5万枚
- テストデータ用: 1万枚
- 画素情報
- 24git RGBフルカラー
- 幅32×高32ピクセル
- クラス数:10
クラスの内容は以下となっています。- ラベル「0」: airplane
- ラベル「1」: automobile
- ラベル「2」: bird
- ラベル「3」: cat
- ラベル「4」: deer
- ラベル「5」: dog
- ラベル「6」: frog
- ラベル「7」: horse
- ラベル「8」: ship
- ラベル「9」: truck
- データセットリンク:The CIFAR-10 dataset
実際の画像例がこちらです。

図5:CIFAR-10の画像例(引用元:The CIFAR-10 dataset)
モデルの実装
それでは、ConvNeXtを実際に実装していきます。
ここでは下記サイトを参考にしてコードを実装しています。
まずは必要なライブラリをImportします。
import tensorflow as tf
import os
from tensorflow.keras import layers
from tensorflow.keras.layers import DepthwiseConv2D, Conv2D, LayerNormalization, Activation, GlobalAveragePooling2D, Dense
import tensorflow_addons as tfa
from tensorflow.keras.datasets import cifar10
#TensorflowのInfoとWarningを非表示
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
次にデータセットを準備します。画像データは1-255の数値データとなっているので、ここで正規化を行います。ラベルデータはtf.keras.utils.to_categoricalを用いてOne-Hot Encodingしておきます。
# データのロード
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# 正規化
train_images = train_images / 255.0
test_images = test_images / 255.0
# One-Hot Encoding
train_labels = tf.keras.utils.to_categorical(train_labels, num_classes = 10)
test_labels = tf.keras.utils.to_categorical(test_labels, num_classes = 10)
取得した画像データに対してデータ拡張処理を行います。データ拡張処理とは画像認識タスクの際によく行われる学習データ水増し手法であり、回転変換や鏡映変換などを各画像に作用させ変換後の画像も学習データとして用います。これらはデータ数増加だけではなく、過学習抑制等にも寄与します。
データ拡張後の画像データとラベルデータを1つのデータセットにまとめ、学習データはtrain_data、テストデータはtest_dataとします。
AUTOTUNE = tf.data.AUTOTUNE
BATCH_SIZE = 256
# 前処理
def preprocess(image, label):
image = tf.image.convert_image_dtype(image, tf.float32)
label = tf.cast(label, tf.int32)
return image, label
# データ拡張
def augmentation(image, label):
image = tf.image.resize_with_crop_or_pad(image, 40, 40)
image = tf.image.random_crop(image, size = [32, 32, 3])
image = tf.image.random_brightness(image, max_delta = 0.5)
image = tf.clip_by_value(image, 0.0, 1.0)
return image, label
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_data = train_data.shuffle(1024)
train_data = train_data.map(preprocess, num_parallel_calls = AUTOTUNE)
train_data = train_data.map(augmentation, num_parallel_calls = AUTOTUNE)
train_data = train_data.batch(BATCH_SIZE)
train_data = train_data.prefetch(AUTOTUNE)
test_data = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_data = test_data.map(preprocess, num_parallel_calls = AUTOTUNE)
test_data = test_data.batch(BATCH_SIZE)
test_data = test_data.prefetch(AUTOTUNE)
augmentationで行っているデータ拡張によって画像は下図のように変化します。
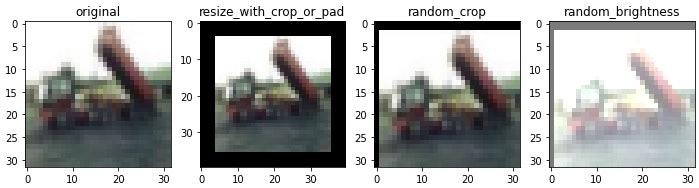
図6:augmentationによる画像処理
それぞれ以下の処理が実行されています。
- resize_with_crop_or_pad:画像のサイズをクロップとパディングによって指定サイズに変更します。
- random_crop:画像を指定サイズまでランダムにクロップします。
- random_brightness:画像の明るさをランダムに変化させます。
- clip_by_value:画像データを正規化します。
次にResNetの残差ブロックに相当するブロックを実装します。
ConvNeXtでは、ResNetのBottleneck構造からInverted Bottleneck構造へ変更します。また、活性化関数の変更やDepthwise Convolutionへの変更などを行っています。
class ConvNeXt_Block(tf.keras.Layer):
def __init__(self, in_channels, out_channels, factor):
super().__init__()
#ConvNeXtブロック1層目
#ConvからDepthwiseConvへ変更しています。
self.layer_1 = DepthwiseConv2D(kernel_size = (7, 7), strides = (1, 1), padding = 'same', use_bias = False)
#ConvNeXtブロック2層目
#正規化をBatchNormalizationからLayerNormalizationへ変更しています。
self.layer_2 = LayerNormalization(epsion = 1e-6)
#チャンネル数が4倍大きくなるInverted Bottleneck構造に変更しています。
self.layer_3 = Conv2D(4 * out_channels, kernel_size = 1, strides = 1, padding = 'valid', use_bias = False)
#ConvNeXtブロック3層目
#活性化関数をReLUからGELUに変更しています。
self.layer_4 = Activation(tf.nn.gelu)
self.layer_5 = Conv2D(out_channels, kernel_size = 1, strides = 1, padding = 'valid', use_bias = False)
self.layer_6 = LayerNormalization(epsilon = 1e-6)
self.layer_7 = Activation('linear')
self.shortcut = self.short_cut(in_channels, out_channels)
#StochasticDepthでランダムにショートカットのみとしています。
self.stochastic = tfa.layers.StochasticDepth(factor)
def short_cut(self, in_channels, out_channels):
#ショートカットとの残差出力の際にチャンネル数が異なる場合は、ショートカットと合わせます。
if in_channels != out_channels:
self.ln_sc = LayerNormalization()
self.conv_sc = Conv2D(out_channels, kernel_size = 1, strides = 1, padding = 'same', use_bias = False)
return self.conv_sc
else:
return lambda x: x
def call(self, x):
shortcut = self.shortcut(x)
x = self.layer_1(x)
x = self.layer_2(x)
x = self.layer_3(x)
x = self.layer_4(x)
x = self.layer_5(x)
x = self.layer_6(x)
x = self.layer_7(x)
x = self.stochastic([x, shortcut])
return x
最後に、ConvNeXt Blockを用いてConvNeXtモデルを構築します。ConvNeXtの階層構造は、ステージごとにConvNeXt Blockが(3, 3, 9, 3)となります。また、各ステージ間にダウンサンプリング層を追加しています。
class ConvNeXt(tf.keras.Model):
def __init__(self, input_shape, output_dim):
super().__init__()
#STEM
self.ln_pre = LayerNormalization(epsilon = 1e-6)
self.stem = Conv2D(96, kernel_size = 4, strides = 4, use_bias = False, input_shape = input_shape)
#ステージ1
self.stage_1 = [ConvNeXt_Block(96, 96, 0.1) for _ in range(3)]
#ダウンサンプリング層
self.ln_1 = LayerNormalization(epsilon = 1e-6)
self.ds_1 = Conv2D(192, kernel_size = 2, strides = 2, use_bias = False)
#ステージ2
self.stage_2 = [ConvNeXt_Block(192, 192, 0.1) for _ in range(3)]
#ダウンサンプリング層
self.ln_2 = LayerNormalization(epsilon = 1e-6)
self.ds_2 = Conv2D(384, kernel_size = 2, strides = 2, use_bias = False)
#ステージ3
self.stage_3 = [ConvNeXt_Block(384, 384, 0.2) for _ in range(9)]
#ダウンサンプリング層
self.ln_3 = LayerNormalization(epsilon = 1e-6)
self.ds_3 = Conv2D(768, kernel_size = 2, strides = 2, use_bias = False)
#ステージ4
self.stage_4 = [ConvNeXt_Block(768, 768, 0.3) for _ in range(3)]
self.pooling = GlobalAveragePooling2D()
self.ln_4 = LayerNormalization(epsilon = 1e-6)
self.activation = Dense(output_dim, activation = 'softmax')
def call(self, x):
x = self.stem(self.ln_pre(x))
for layer in self.stage_1:
x = layer(x)
x = self.ds_1(self.ln_1(x))
for layer in self.stage_2:
x = layer(x)
x = self.ds_2(self.ln_2(x))
for layer in self.stage_3:
x = layer(x)
x = self.ds_3(self.ln_3(x))
for layer in self.stage_4:
x = layer(x)
x = self.activation(self.ln_4(self.pooling(x)))
return x
以上で、ConvNeXtモデルが構築できました。
それでは、ConvNeXtのインスタンスを作成していきます。引数は
ConvNeXt((入力画像の幅, 入力画像の高さ, チャンネル数), クラス数)、
OptimizerにはAdamWを用います。
model = ConvNeXt((32, 32, 3), 10)
model.build(input_shape = (None, 32, 32, 3))
model.compile(
optimizer = AdamW(learning_rate = 0.001, weight_decay = 0.004),
loss = tf.keras.losses.CategoricalCrossentropy(label_smoothing = 0.1),
metrics = ['accuracy']
)
学習
それでは、CIFAR-10のデータセットを用いて学習を行います。今回はepochsを200に設定しています。
model.fit(
train_data,
epochs = 200
)
ConvNeXtモデルの精度
学習によって得られたモデル精度を求めます。画像分類タスクの精度指標には多くの種類がありますが、今回はAccuracyを用いています。
result = model.evaluate(test_data)
print('test accuracy:{}%'.format(round(result[1] * 100,2)))
40/40 [==============================] - 2s 38ms/step - loss: 1.1040 - accuracy: 0.7326
test accuracy:73.26%
結果は73.26%でした。ConvNeXtは元々画像サイズが224×224であるImageNetに適したモデルとして提案されたため、画像サイズが32×32のデータであるCIFAR-10ではあまり精度が出なかったと考えられます。
そこでConvNeXtのSTEMのカーネルサイズとストライドを2に変更し再度モデル学習を行いました。
| STEM | カーネルサイズ | ストライド |
|---|---|---|
| 変更前 | 4×4 | 4×4 |
| 変更後 | 2×2 | 2×2 |
その結果、精度は83.72%まで向上しました。
| STEM | 精度 |
|---|---|
| 変更前 | 73.25% |
| 変更後 | 83.72% |
このように、使用するデータセットやタスクによってカーネルサイズなどを調整することで更なる精度向上が見込めそうです。
他モデルとの精度比較
他モデルでもCIFAR-10に対して学習しましたので、ConvNeXtと精度を比較をします。結果は表のとおりです。ResNet50はTensorflowの組み込みモデル、Vision TransformerとSwin TransformerはKerasに掲載されているドキュメントを参考にして実装しました。
| モデル名 | 精度 |
|---|---|
| ConvNeXt(STEM変更前) | 73.25% |
| ConvNeXt(STEM変更後) | 83.72% |
| ResNet50 | 77.07% |
| Vision Transformer | 69.03% |
| Swin Transformer | 73.18% |
ConvNeXtのSTEM変更後は今回検証したモデルの中で最も精度が出ていることが分かりました。また変更前でもResNet50には劣りますが、それでもTransfomer系より高い値が出ていることが分かります。
以上から、画像分類タスクにおいてConvNeXtを使用することは有効な選択肢の一つとなると考えられます。
今回は画像データの拡張はいくつかシンプルなものだけでしたが、MixupやCutmix等のデータ拡張で更に学習データ数を増やすことや、他にもハイパーパラメータを調整することでさらに高い精度が期待できます。
6. まとめ
この記事では、CNNの新しいモデルであるConvNeXtの概要と実装、学習結果の精度に関して紹介しました。
画像認識モデルは古くから研究されており現在も発展し続けています。新たな画像認識技術に触れたい、実際に実装してみたいという方のご参考になれば幸いです。
参考文献
- A ConvNet for the 2020s
- DECOUPLED WEIGHT DECAY REGULARIZATION
- Deep Networks with Stochastic Depth
- ImageNet Classification with Deep Convolutional Neural Networks
- Deep Residual Learning for Image Recognition
- AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- The CIFAR-10 dataset
- Image classification with Vision Transformer
- Image classification with Swin Transformers
- keras Github
- Tensorflow公式チュートリアル データ増強
- Tensorflow公式チュートリアル 画像分類
- Tensorflow公式チュートリアル カスタムレイヤー