1. はじめに
この記事では、機械学習を用いて画像認識を実践するために必要な基本知識を紹介します。
2. 機械学習を用いた画像認識
ここでは、そもそも画像認識とは何か、そして機械学習を用いた画像認識にはどのようなタスクがあるのかを述べます。
2-1. 画像認識とは
画像認識とは、「画像データから、画像にある物体やその位置などの特徴を抽出・識別すること」 です。画像認識の例として、カメラに映った製品の画像から傷などの異常を検出することが挙げられます。製品の画像を対象として異常を検出する場合、単に製品の画像に異常がみられるかどうかを見分けるだけでなく、異常の種類や異常箇所の特定も行うことがあります。また、異常検知を行う場合は、精度だけでなく処理速度などの性能が実務上で運用可能なレベルにある必要があります。つまり、画像認識として行いたいタスクおよび要求される機能要件/非機能要件を整理し明確にしたうえで、機械学習モデルの構築を検討する必要があります。
2-2. 機械学習を用いた画像認識のタスク
機械学習を用いた画像認識の主要なタスクとして、画像分類・物体検出・セグメンテーション(分割)の3つが挙げられます1。
画像分類は、画像がどのカテゴリに属するか分類するタスクです。先程の例だと、画像に写った製品に異常があるか否かを分類する、といったタスクです。
物体検出は、画像に映っている物体の位置や範囲を特定するタスクです。先程の例だと、製品の画像にある異常箇所を特定し長方形の枠で囲む、といったタスクです。画像分類と異なり、画像全体ではなく画像の一部領域を抽出したうえで分類を行う必要があります。
セグメンテーション(分割)は、画像に映っている物体ごとに色分け(ラベル付与)を行うタスクです。タスクをより細かく分解すると、同じ種類の物体はまとめて同じ色とするセマンティックセグメンテーション、特定の物体(人や自動車など)のみ抽出したうえで同じ種類の物体でも1つずつ色分けをするインスタンスセグメンテーションに分けられます2。先程の例だと、セマンティックセグメンテーションでは製品の画像に対し異常箇所と異常でない箇所を2色に色分けします。一方、インスタンスセグメンテーションでは異常箇所のみ抽出し、異常箇所が複数ある場合は別々に色を割り当てます。
以上を踏まえると、画像分類、物探検出、セグメンテーション(セマンティックセグメンテーション、インスタンスセグメーション)の順にタスクの難度が上がると言えます。
3. 機械学習を用いた画像認識におけるモデル構築
ここでは、機械学習を用いた画像認識におけるモデル構築の流れとして、前処理(画像処理)、特徴抽出、モデリング、性能評価を順に説明します。大まかなモデル構築の流れを図1に示します。

図1:機械学習を用いた画像認識モデル構築フロー
画像認識で扱う画像データは何らかの方法で収集済みであることを想定していますが、学習に必要なデータ量が確保できていない場合は、追加のデータ収集やXu et al.(2023)等を参考に画像データの拡張(Image Augmentation)も視野に入れてモデル構築を行います。
3-1. 前処理:画像処理
ここでは前処理として行う画像処理について、画像のサイズ変更・幾何的変換(回転・平行移動・反転)3・スケーリングを紹介します。
3-1-1. 画像のサイズ変更
機械学習モデルの入力で想定するサイズと画像のサイズが合っていない場合、先に画像のサイズを変更しておきます。基本的には、画像の横幅や縦幅を拡大・縮小します。ただし、画像を拡大する場合、横幅や縦幅を拡大する代わりに、サイズに合うように元の画像データの周りを0で穴埋め(zero-padding)することがあります。
3-1-2. 幾何的変換
画像認識における幾何的変換として、回転(rotation)、平行移動(translation)、反転(flip)の3つがあります。特に回転・平行移動を行う場合、機械学習モデルの入力として想定しているサイズに合うよう、画像のサイズ変更も同時に行うことがあります。また、反転の場合、デジタル表示の2と5のように意味が変わってしまう場合がある4ため注意が必要です。
3-1-3. スケーリング
画像データは、例えばRGB値(0~255)のように離散値をとることが多いですが、機械学習モデルで扱いやすくするため、データがとりうる値の範囲を変換するスケーリングを行います5。特に、最小値が0かつ最大値が1になるような変換を正規化(normalization)、平均が0かつ分散が1になるような変換を標準化(standardization)と呼ぶことがあります。
3-2. 特徴抽出
画像認識タスクにおいては、画像を識別するのに有効な特徴を抽出できるように、特徴量を適切に設計することが重要です。
ここでは、原田(2017)における特徴抽出の流れを簡単に説明します。
まず、画像のうち輪郭など特徴のある点を検出したうえで、その点の周辺情報をまとめた特徴量を作成します。次に、特徴量にノイズが残っている場合は、線形変換や主成分分析などの統計的手法にもとづきノイズを低減した特徴量に変換する統計的特徴抽出を行います。そして、得られた特徴ベクトルを、画像認識に有効な次元数のベクトルに変換(コーディング)します。最後に、複数の特徴ベクトルを一つのベクトルにまとめるプーリングを行います。
特に、最初の特徴のある点の検出と周辺情報をまとめた特徴量の作成のみで有効な特徴量が得られる場合は、得られた特徴ベクトルをそのままモデル構築に使用する場合もあります。例としては、Dalal & Triggs(2005)のHOG (Histograms of Oriented Gradient) があります。
HOGの詳細はこちらをご確認ください。
HOGは、人の検出を目的に提案された特徴量であり、藤吉(2019)では「物体の形状を表現する」特徴量とされています。HOGは画像の輝度に対する勾配(gradient)・強度(magnitude)を計算したうえで、画像の分割(セル)および勾配の方向ごと6に輝度の強度のヒストグラムを作成し、分割よりも大きいブロック単位で正規化を行うことで計算されます(Dalal & Triggs(2005), 山崎(2010))。HOGの計算イメージを図2に示します。
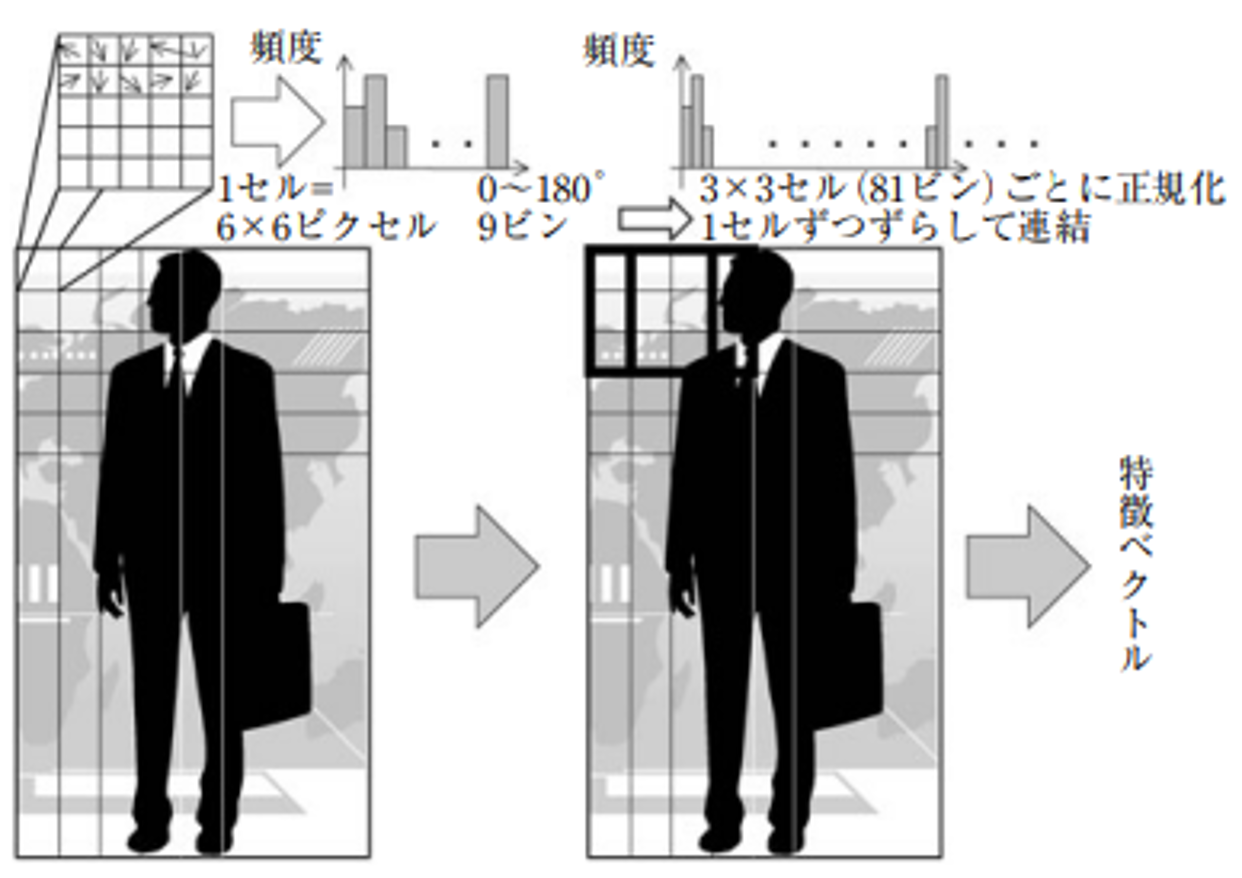
図2:HOGの計算イメージ(山崎(2010)より引用)
具体的なHOGの実装方法などの詳細は割愛しますが、例えば山崎(2010)における実装7を踏まえた解説や原田(2017)における説明が参考になると思います。
なお、CNNなど深層学習ベースのモデルを扱う場合は、モデリングと同時に特徴抽出をすることも考えられます。それでも十分な性能のモデルが構築できる場合は、明示的に特徴量を作成しない場合もあります。
3-3. 画像識別モデルの構築
ここではモデリングの方針として、分類器ベース、CNNベース、Transformerベースを紹介します。
3-3-1. 分類器ベース
分類器ベースのモデリングでは、SVMやAdaBoostなど機械学習モデルの中でも従来から分類器として用いられてきたものを活用します。この場合、先述の特徴抽出を行い、HOGなどの特徴量を事前に作成する必要があります。
分類器ベースのメリットとしては、CNNなど深層学習ベースに比べ実装・学習・推論のコストを抑えやすいことが挙げられます。一方、デメリットとしては、事前に適切な特徴抽出を実施していることが前提となるため、特徴量をうまく作成しないと性能が上がりにくい8、つまり特徴量エンジニアリングが必須であることや、特に多クラス分類を扱う場合はCNNなど深層学習ベースよりも精度の観点で劣るという点が挙げられます。
3-3-2. CNNベース
CNNベースのモデリングでは、CNNの特徴である畳み込みとプーリングを用います。
畳み込み・プーリングの詳細はこちらをご確認ください。
畳み込みとは、画像データの一部(例えば3×3ピクセル)を、畳み込みカーネル(フィルター)を通して1つの特徴量にまとめることです。例えば図3に示すように、5×5ピクセルのデータに対し3×3の畳み込みカーネルを(上下左右1ピクセルずつずらす形で)適用すると、(5-3+1)×(5-3+1)=3×3の特徴量が得られます。
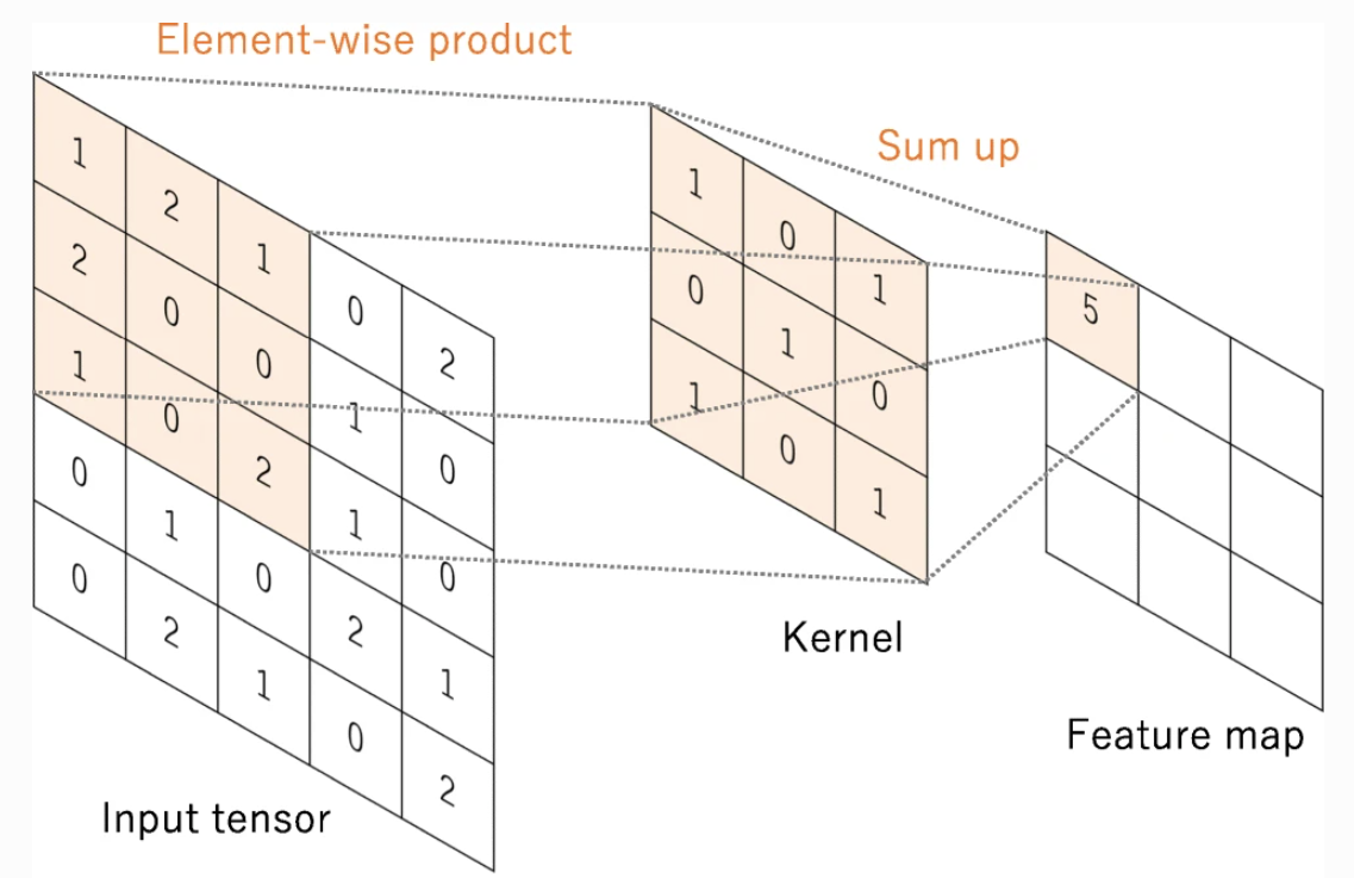
図3:畳み込みのイメージ(Yamashita et al.(2018)より引用)
畳み込みにより、画像の1点(ピクセル)の周辺にある情報を取り込んだ特徴量を作成できます。また、回転や平行移動といった幾何的変換に対して頑健な学習ができます。なお、畳み込みの前後で特徴量の次元を統一する場合は、同じ次元になるように畳み込み前のデータの周辺領域を0で穴埋め(zero padding)、もしくは畳み込みカーネルを1×1にする方法があります。また、特徴量の次元をさらに小さくする場合は、ストライド(畳み込みカーネル適用時に上下左右にずらす幅)を1ではなく2以上にすることがあります。
プーリングとは、特徴量の一部(例えば2×2ピクセル)のデータを、(重み付き)平均値や最大値などの代表値で置き換えることです。例として、最大値によるプーリング(Max Pooling)のイメージを図4に示します。プーリングにより、特徴量およびパラメータを削減し、過学習の抑制につなげることができます。
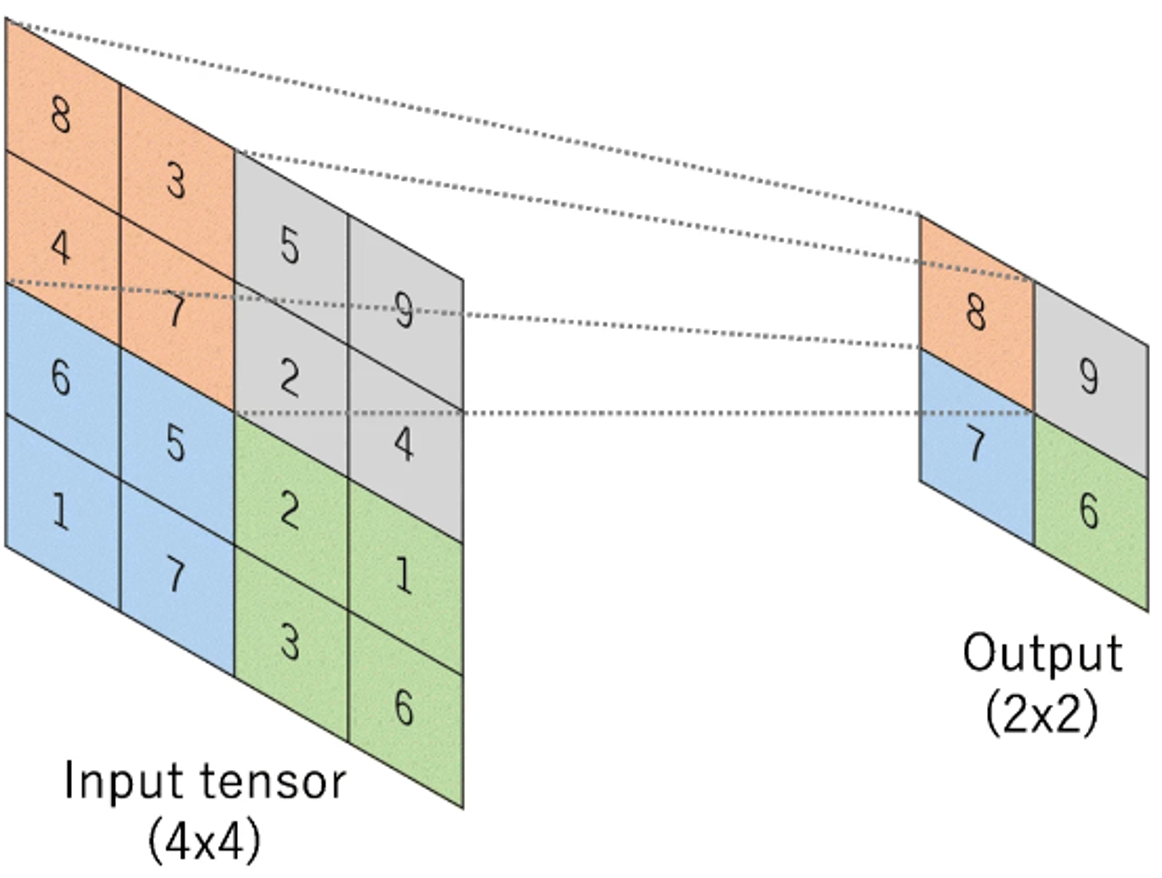
図4:最大値によるプーリング(Max Pooling)のイメージ(Yamashita et al.(2018)より引用)
CNNベースのメリットとしては、画像の各ピクセルの近辺情報をうまく学習できるため、画像を精度よく認識することが期待できるという点が挙げられます。一方、デメリットとしては、離れた位置にあるピクセルの情報同士をうまく結びつけるのが難しいことや、分類器ベースに比べ学習・推論のコストが大きくなりやすいことが挙げられます。
代表的なCNNベースのモデルは様々ありますが、例えば画像分類だとResNet、物体検出だとSSDがあります。
ResNet・SSDの詳細はこちらをご確認ください。
ResNet (Residual Network)は、既存の特徴量では表現しきれない部分であるResidualを学習することで分類精度を上げるCNNです。具体的には、畳み込みやプーリング等を経て作成した特徴量 $X$、$X$ に対しさらに畳み込み等を行い特徴量を作成する操作(を関数として表したもの)を $F(X)$ としたとき、特徴量として $F(X)+X$ を採用します9。つまり、$F(X)$ を「$X$ で捉えられていない特徴を近似的に表現できる関数」とみなした学習(Residual Learning)を行います。このResidual Learningにより、より精度が上がる方向に学習を進められます。
SSD (Single Shot MultiBox Detector)は、物体の領域抽出とその領域に対する分類の両方をCNNベースで行うモデルです。SSDによる物体検出のイメージを図5に示します。図5右におけるlocはbox(物体の枠)の位置と大きさ、confは分類クラスごとの信頼度(もしくはあるクラスに分類される確率)を指します。SSDは、畳み込みを行った(複数のスケールの)特徴量マップの各地に、予め設定したdefault boxes10を生成し、各boxで分類カテゴリの信頼度および形状のオフセットを予測します。物体の領域抽出と分類を並行して行える上、複数の層の特徴量を効率的に扱えます。
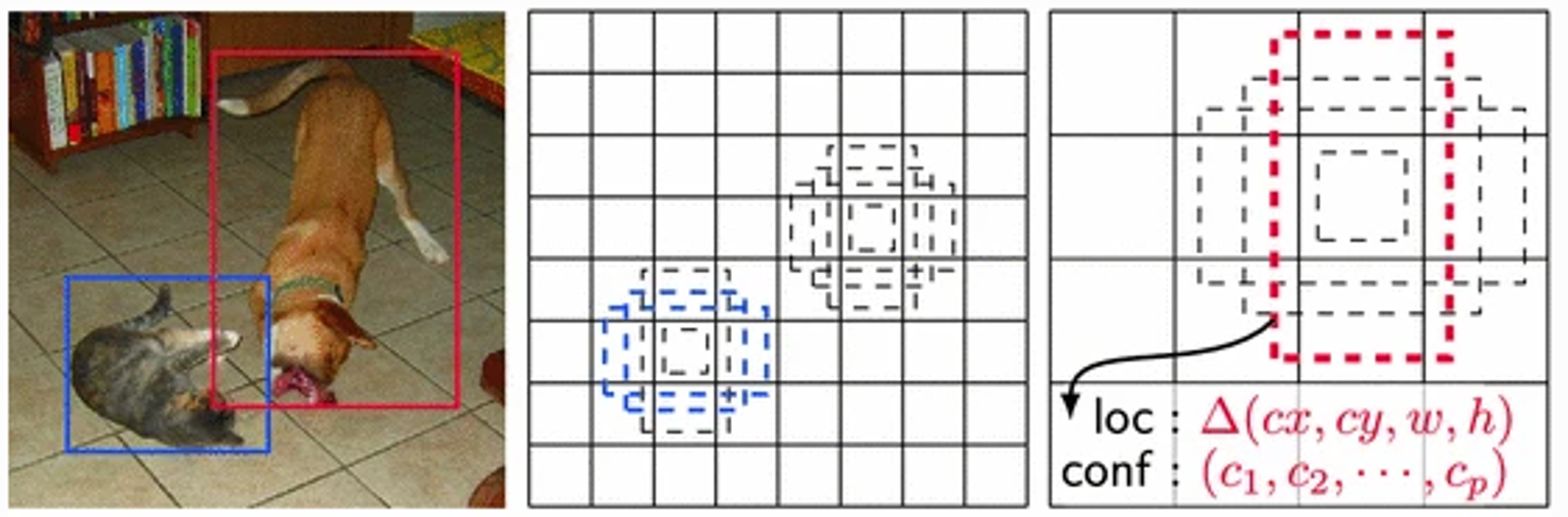
図5:SSDによる物体検出のイメージ(Liu et al.(2017)より引用)
左:真の枠(Ground Truth Boxes)
中央:8×8の特徴量マップ上のDefaul Boxes(点線)
右:4×4の特徴量マップ上のDefaul Boxes(点線)
3-3-3. Transformerベース
Transformerベースでは、Vision Transformer (ViT)に代表されるようにSelf AttentionおよびTransformerを用います。
Self Attention・Transformerの詳細はこちらをご確認ください。
Self Attentionとは、特徴量の行列 $X$ およびクエリ行列 $Q (=XU_q)$ とキー行列 $K (=XU_k)$ を用いて計算されたスコアをもとに、バリュー行列 $V (=XU_v)$ を用いて特徴量を計算する仕組みを指します11。具体的には、行ごとにsoftmax関数による変換を行う関数を $\operatorname{softmax}()$、$Q, K$ の次元数を $d$ としたとき、Self Attentionにより計算される特徴量 $Z$ は、
Z=\operatorname{softmax}\big(\frac{QK^T}{\sqrt{d}}\big)V
と表されます。Self Attentionにより、離れた位置にあるピクセルの情報同士を結び付けながら学習を進めることができます。
Transformerとは、Self Attentionを複数扱うMulti-head Attention、ResNet同様のResidual Learning、多層パーセプトロン(MLP: Multi-Layer Perceptron)を組み合わせたモデル構造です。Transformerのモデル構造のイメージを図6に示します12。図6におけるEmbedded Patchesは特徴量、Normは正規化、$+$はResidual Learningを指します。
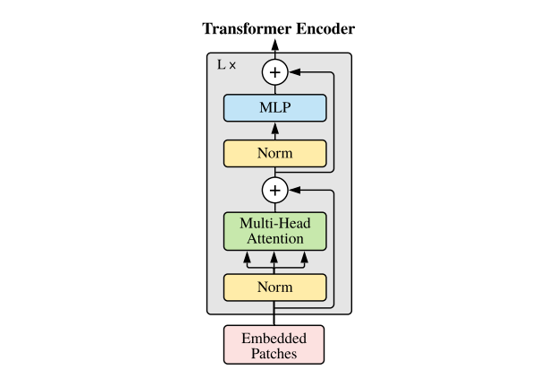
図6:Transformerのイメージ(Dosovitskiy et al.(2021)より引用)
Multi-head Attention(またはMultiheaded self-attention)とは、Self Attentionにもとづき複数の特徴量を(クエリ・キー・バリュー行列を複数用意することで)作成したうえで、それらを1つの特徴量にまとめることで計算する仕組みです。具体的には、$M$ 個のSelf Attentionから作成した特徴量(head)を $Z_m~(m=1, 2, ..., M)$、$Z_m$ をまとめるための $(M\cdot d)\times d$ 行列を $U$ としたとき、Multi-head Attentionで計算される特徴量 $Z_{MA}$は、
Z_{MA}=[Z_m, Z_m, ..., Z_M]U
と表されます。
多層パーセプトロンは、隠れ層(中間層)が2層以上ある階層型ニューラルネットワークのことです。ただしTransformerでは、多層パーセプトロンにおける活性化関数は一般的なReLUではなく、Hendrycks & Gimpel(2016)のGELU(Gaussian Error Linear Unit)を使用することを想定しています。
Transformerベースのメリットとして、CNNベースに比べて離れた位置にあるピクセルの情報も考慮した学習が可能という点が挙げられます。一方、デメリットとして、精度を高めるためにはCNNベース以上に大量の画像データが必要となることがあります(堀田(2022))。
代表的なTransformerベースのモデルとして、Vision Transformer (ViT)があります。
ViTの詳細はこちらをご確認ください。
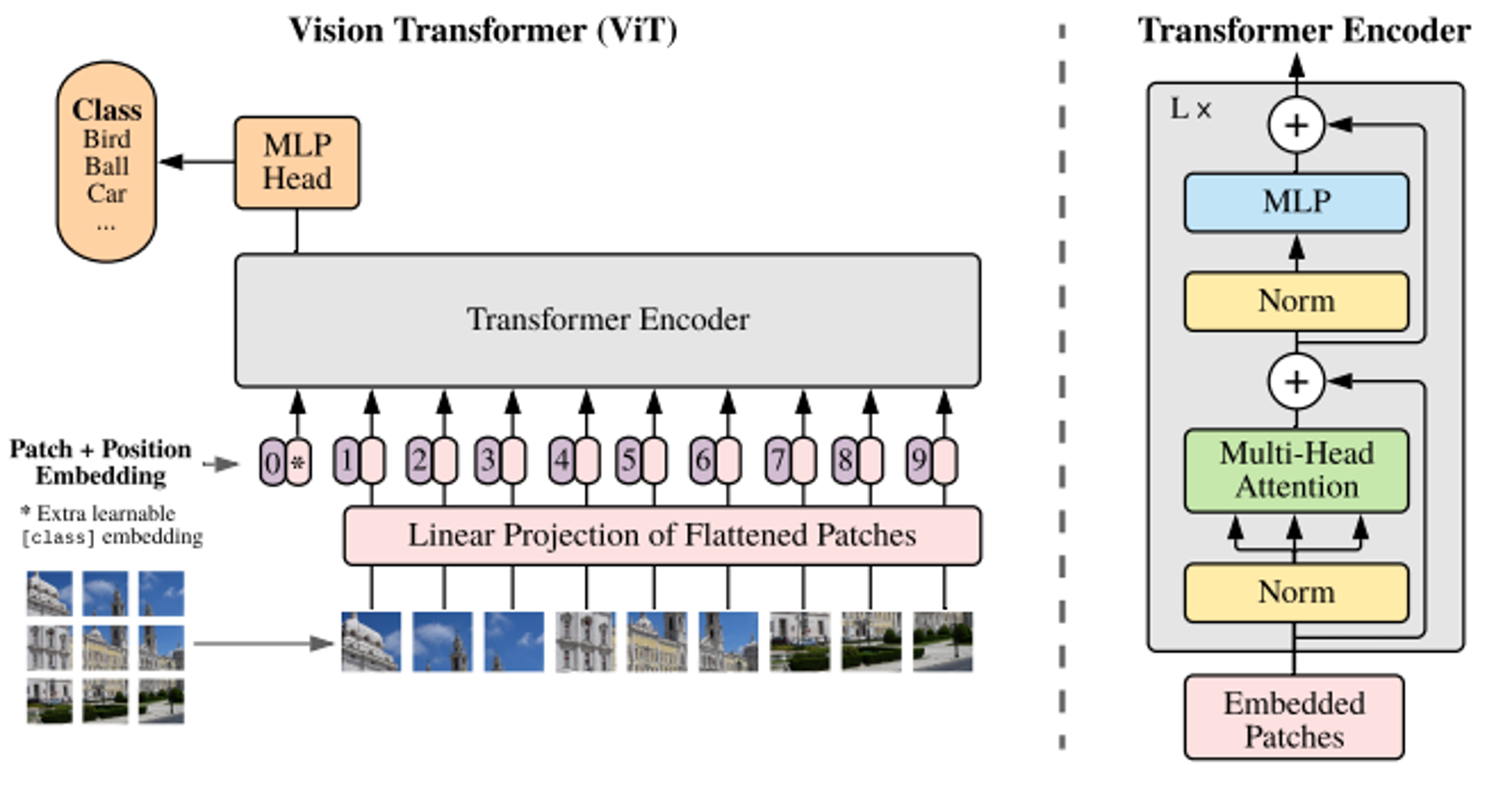
図7:ViTのモデル構造(Dosovitskiy et al.(2021)より引用)
3-3-4. その他のモデル
これまで紹介したモデル以外にも、CNNとSVMを組み合わせたR-CNN(Girshick et al. (2014))、CNNとself-attentionを組み合わせたAA-ResNet(Bello et al. (2019))など様々なモデルがあります。ここでは代表的なモデルを紹介しましたが、やりたい画像認識タスクに合わせて柔軟にモデル構築を行うことが重要です。
3-4. 性能評価
ここでは、性能評価の方向性として、分類精度・処理速度の2種類を紹介します。
3-4-1. 分類精度
分類精度を評価する際に使われる指標として、画像認識に限らず使用されるPrecision・Recall・ROC-AUCのほかに、mAP(mean average precision:分類クラスごとに計算したAP(average precision)の平均値)があります(原田(2017))。特に、物体検出の研究分野ではmAPが報告されるケースが多い印象です。
3-4-2. 処理速度
分類精度が十分でも、リアルタイムでの画像認識が要求されるケースなど、画像認識の活用場面によっては処理速度が不十分である場合があります。そのため、処理速度として画像1枚あたりの推論時間や1秒あたりの処理可能枚数(FPS:frame per second)などを指標とすることがあります。ただし、モデルの処理で消費する計算資源(メモリー等)の量や使用するデバイスのスペック(CPU・GPU等)によって処理速度は変わるため、正確にモデル同士を比較したい場合は実行環境を統一しておく必要があります。
4. まとめ
この記事では、機械学習を用いた画像認識におけるモデル構築の基礎知識を、構築フローとともに紹介しました。画像認識にチャレンジしたい方の参考になれば幸いです。
5. 参考文献
・AA-ResNetに関する文献:Bello, I., Zoph, B., Vaswani, A., Shlens, J., & Le, Q. V. (2019). Attention augmented convolutional networks. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 3286-3295).
・HOG推定量に関する文献:Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. In 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05) (Vol. 1, pp. 886-893). Ieee.
・Vision Transformerに関する文献:Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations.
・R-CNNに関する文献:Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587).
・ResNetに関する文献:He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
・GELUに関する文献:Hendrycks, D., & Gimpel, K. (2016). Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415.
・セグメンテーションに関する文献:Kirillov, A., He, K., Girshick, R., Rother, C., & Dollár, P. (2019). Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9404-9413).
・SSDに関する文献:Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016). Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14 (pp. 21-37). Springer International Publishing.
・Self-AttentionおよびTransformerに関する文献:Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
・画像データの拡張に関するサーベイ論文:Xu, M., Yoon, S., Fuentes, A., & Park, D. S. (2023). A comprehensive survey of image augmentation techniques for deep learning. Pattern Recognition, 109347.
・画像認識を含めたデータサイエンスの応用基礎に関する書籍:赤穂昭太郎, 今泉允聡, 内田誠一, 清智也, 高野渉, 辻真吾, 原尚幸, 久野遼平, 松原仁, 宮地充子, 森畑明昌, 宿久洋. (2023). 応用基礎としてのデータサイエンス-AI×データ活用の実践. データサイエンス入門シリーズ, 講談社サイエンティフィック.
・画像認識に関する書籍:原田達也. (2017). 画像認識. 機械学習プロフェッショナルシリーズ, 講談社.
・深層学習に関する書籍:平井有三. (2022). はじめてのパターン認識 -ディープラーニング編. 森北出版
・深層学習を用いた画像認識に関する解説論文:藤吉弘亘, & 山下隆義. (2017). 深層学習による画像認識. 日本ロボット学会誌, 35(3), 180-185.
・画像認識における教師なし学習およびTransformerの解説論文:堀田一弘. (2022). ディープラーニングに基づく画像認識の更なる進展―教師なし表現学習と Transformer を中心として―. 電子情報通信学会 基礎・境界ソサイエティ Fundamentals Review, 15(4), 258-267.
・HOGに関する解説記事:山崎俊彦. (2010). 画像の特徴抽出: Histogram of Oriented Gradients (HOG). 映像情報メディア学会誌, 64(3), 322-329.
-
ほかのタスクとしては、画像照合や特定物体認証・姿勢推定・画像検索・画像生成・画像キャプション生成などが挙げられます(赤穂 et al.(2023)、原田(2017)、藤吉(2019))。 ↩
-
近年ではセマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせたパノプティックセグメンテーション(Kirillov et al.(2019))というタスクもあります。本文中の例だと、「製品の正常箇所と異常箇所およびその他(背景など)で色分けし、かつ異常箇所が複数ある場合は各異常箇所に別の色を割り当てる」といったタスクです。 ↩
-
画像のサイズ変更(拡大・縮小)も厳密にはアフィン変換として扱えるという意味で幾何的変換ではありますが、便宜上分けています。 ↩
-
回転の場合でも、デジタル表示の6と9を180度回転させると意味が変わってしまいます。つまるところ、線対称や点対称など幾何的特徴のある物体を画像認識として扱う場合は、幾何的変換によって情報が極端に変わり推論に悪影響が出る可能性がないか確認する必要があります。 ↩
-
画像認識の分野では、「画像を拡大・縮小してスケールを変える」という意味でスケーリングという言葉を使うこともあるため、どういう意味でスケーリングという用語を使っているかご注意ください。 ↩
-
Dalal & Triggs(2005)では、勾配の方向ごとの計算は、0~180°の方向を均等に9分割したbinごとに行います。 ↩
-
こちらの実装例は、MATLABとC言語を知っている前提で書かれています。手軽に試したい場合は、例えばPythonのOpenCVパッケージに実装されているHOGDescriptor関数やSVMと組み合わせるためのチュートリアルを活用されるといいと思います。 ↩
-
特徴抽出の代替手段として、深層学習ベースで事前学習済みのモデルから特徴量生成を行っている箇所を取り出し、画像識別の部分のみSVMなど従来の分類器ベースに置き換える方法があります。このように学習済みのモデルをもとにモデル構築を行うことを転移学習といいます。 ↩
-
$X$ と $F(X)$ で次元が異なる場合は、重み行列 $W$ を用いて次元を合わせた $F(X)+WX$ を特徴量として採用します。 ↩
-
物体を囲む(アスペクト比の異なる複数の)枠を指します。 ↩
-
ここでは、堀田(2022)と同様にScaled Dot-Product Attention(Vaswani et al.(2017))のことをSelf-Attentionとして紹介しています。なお、自然言語処理の分野でCheng et al.(2016)により提案されたintra-attentionが厳密にはSelf-Attentionの原型とされており、この記事では異なる定式化を扱っている点にご注意ください。 ↩
-
ここではVision TransformerにおけるTransformer encoderのことをTransformerとして紹介しています。通常、Transformerは自然言語処理の分野で提案されたもの(Vaswani et al. (2017)を指すことにご注意ください。 ↩