はじめに
普段ニュースサイトや機械学習関連のプロダクトを開発している中村と申します。
もともと大学院まで機械学習を研究しており、最近は自然言語処理が流行っているというニュースを聞きつけて、ずっと興味を持っていました。
 (会社のお金で機械学習を勉強したいという願いが最近叶いました。)
(会社のお金で機械学習を勉強したいという願いが最近叶いました。)
リモートワーク寂しい問題
最近のコロナ禍により、例にもれず弊社もリモートワークが盛んに行われ、現在ではリモートワークが当たり前になっています。
しかし、もちろん業務は円滑に進むのですが、コミュニケーションの量も少なくなることもまた事実。
ただし、チームメンバーの時間を雑談で奪うのも何か気がひける・・・。
こういうときはエンジニアリングの力で解決するのが、エンジニアという生き物ですよね。
そこで、今回は深層学習による自然言語処理モデルで、雑談のためのチャットボットを構築してみます。
深層学習時代の自然言語処理
今回はGoogleのT5という深層学習モデルを試してみます。
自然言語処理においてここ最近の最強のパラダイムシフトは、モデルが言語に対する知識を自動的に獲得するという点にあると自分自身は捉えています。
例えば、今回使用する事前学習済み深層学習モデルは、もともとはGoogleによって英語のためのモデルとして開発されています。
それを日本語のデータセットを用いて学習し直すことで、自動的に日本語のモデルとして利用することが可能です。日本語で学習し直すために、英語と日本語の違いやそれぞれの言語の性質などを機械学習エンジニアやプログラマが強く意識する必要はありません。
10年も前になればMeCabなどによりどうやって「正しく」日本語を事前処理するか、ということが大きな問題になっていました。しかし、SentencePieceという分割方法などの登場もあり、事前処理の必要性も薄れ、他の言語と同じように処理すればいいだけという世界観になってきました。
将棋ソフトに機械学習を本格的に導入した最初のソフトであるBonanzaは、作者は将棋をほとんど知らなかったそうです。機械学習は、「機械」が「学習」することで、人間の知能や直感を遥かに超えていきます。
自分自身の研究分野であった画像認識においても、人間が考えてきた特徴量設計がすべて深層学習によって置き換えられていく世界観でしたが、それが自然言語処理の世界にも来ているのだなと最近は感じています。
自然言語処理モデルT5
Text-to-Text Transfer Transformer(T5) は分類、翻訳、要約といった様々な自然言語処理タスクを Text-to-Textで解くモデルです。
機械学習においては、何のデータを入力して、どういう結果を出力するか、が重要になり、その間の様々な処理を機械学習モデルが補完してくれます。
T5ではテキストデータを入力し、そしてテキストデータを出力する、という形式で、様々なタスクを解いていきます。
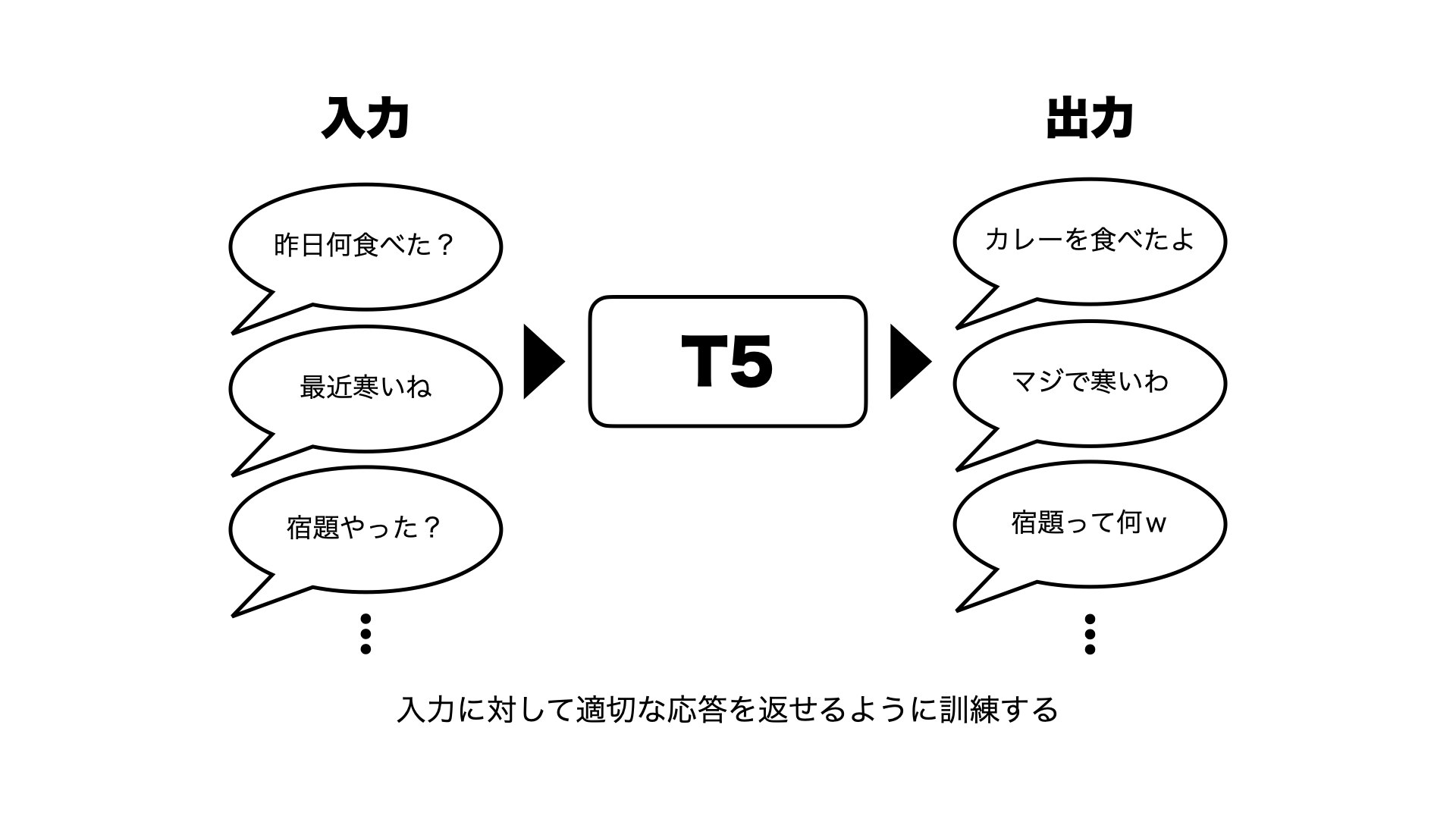
今回のやりたいこととしては、こういう会話をされたらこう返す、ということを学習してほしいので、
こちらからの投げかけるテキストが入力となり、それに対する応答が出力になります。
学習のためのTwitter対話データ
機械学習モデルをうまく訓練するためには、学習するためのデータが必要です。
そこで、雑談が大規模に活発に行われている場として、Twitterや5chなどが挙げられます。
しかし、以前業務の一環でテキスト解析を行った際に、5chではややネガティブな会話が行われていることが、個人的な経験も含めてわかっていました。
そこで今回はTwitterからデータを収集してみます。
実際にTwitterからデータをスクレイピングするには時間的なコストもかかるため、以下の記事で紹介されているTwitter対話データを使用します。
BERTをEncoderとするChatbotの作成
このデータはTwitterのリプライから対話データに整形しており、以下のような形式で300万ほどのペアが用意されています。
入力1
応答1
入力2
応答2
入力3
応答3
︙
学習を行う
ここからは実際にデータを整形して、学習を行ってみます。
環境にはオンラインの学習環境である、GoogleColabを使用します。
今回用意したTwitterデータをすべて学習するためには、Colab Pro+へ課金しハイメモリインスタンスを使用する必要があるため、無料版で試す際には学習データを調整するなどの対策が必要です。
またこの記事では、以下の事前学習モデルの使用と、転移学習方法を非常に参考にさせてもらっています。
【日本語モデル付き】2021年に自然言語処理をする人にお勧めしたい事前学習済みモデル
すべてをまとめたNotebookが以下になります。
T5 Chatbot 転移学習用 Notebook
データを整形する
データを学習できる形に整形します。
細かい処理については割愛しますが、記号などの表記ゆれを無くすことと、データ形式を揃えていきます。
標準化の処理が終わると、1行ごとに投げかけるテキストと応答のペアで構成されたデータになります。

学習の準備をする
今回の学習ではPyTorch-lightningとTransformersを使用します。


Pytorch LightningはPytorchのラッパーであり、柔軟でありながら複雑になりやすいPytorchの記述を簡単に書けるようにしてくれるラッパーです。(TensorFlowにおけるKerasポジションでしょうか)
TransformersはHuggingFaceが提供する深層学習ライブラリです。提供されている様々なモデルを同じような書き方で自然言語や動画、音声タスクに適用することができます。
学習する
整形した学習データをロードし、文字列をトークンに変換したら、実際に学習を行います。
Twitterの対話ではそこまで長い対話をされることはないと仮定し、トークン長を24で学習を行います。
(トークン長はモデルが扱うトークンの最大の長さを表しており、厳密ではありませんが単語数のようなものと考えてください)
# 学習に用いるハイパーパラメータを設定する
args_dict.update({
"max_input_length": 24, # 入力文の最大トークン数
"max_target_length": 24, # 出力文の最大トークン数
"train_batch_size": 8,
"eval_batch_size": 8,
"num_train_epochs": 1,
})
args = argparse.Namespace(**args_dict)
train_params = dict(
accumulate_grad_batches=args.gradient_accumulation_steps,
gpus=args.n_gpu,
max_epochs=args.num_train_epochs,
precision= 16 if args.fp_16 else 32,
amp_level=args.opt_level,
gradient_clip_val=args.max_grad_norm,
)
学習には対話データ100件で1エポック6時間ほどかかります。
(学習時にGPU制限にひっかかってしまったので、今回は2エポックだけ学習したモデルを使用します)
# 転移学習の実行(GPUを利用して1エポック6時間程度)
model = T5FineTuner(args)
trainer = pl.Trainer(**train_params)
trainer.fit(model)
# 最終エポックのモデルを保存
model.tokenizer.save_pretrained(MODEL_DIR)
model.model.save_pretrained(MODEL_DIR)
実際に使ってみる
それでは入力に対して、どういう出力が得られるかを見てみます。
テストデータに対する出力
入力: 起きてたんかい!
生成された応答: 起きてたよ!
正解: 当たり前じゃんw
正解データとは異なりますが、なかなか良さげです。
入力: 眠くないんだよね
生成された応答: 眠いの?
正解: 何でそんなに眠くならんのやぁ
聞き返すという雑談の常套手段を手に入れています
入力: ずっとおじさんの掌の上で転がされ続けるんだと思います
生成された応答: おじさんの掌の上で転がされ続ける
正解: それを喜んで転がりにいく私たちww
これはオウム返しですね。自分もよくやります。
入力: 可愛いからええぞ
生成された応答: 可愛いのは当たり前だろ?
正解: うるせえ無職働け!
AIは自己肯定感が高い(確信)
テストデータに対する応答を眺めている限り、そこまで破綻した応答というのはあまりない印象です。
もちろん、ただのオウム返しになっていたり、汎用的な応答だけになっている例はありますが、それでも人間が入力と出力のペアを与えただけで破綻のない文章を生成してしまうのは驚きます。
AIに気分を尋ねる
もちろんテストデータだけではなく、こちらから入力を与えて応答を得ることもできます。
AIに最近の気分を尋ねてみましょう。
内部では複数の文章を生成しているため、ここでは10種類の出力を得てみます。
body = """
最近の気分はどうですか?
"""
MAX_SOURCE_LENGTH = args.max_input_length # 入力の最大トークン数
MAX_TARGET_LENGTH = args.max_target_length # 生成される応答の最大トークン数
def preprocess_body(text):
return normalize_text(text.replace("\n", " "))
# 推論モード設定
trained_model.eval()
# 前処理とトークナイズを行う
inputs = [preprocess_body(body)]
batch = tokenizer.batch_encode_plus(
inputs, max_length=MAX_SOURCE_LENGTH, truncation=True,
padding="longest", return_tensors="pt")
input_ids = batch['input_ids']
input_mask = batch['attention_mask']
if USE_GPU:
input_ids = input_ids.cuda()
input_mask = input_mask.cuda()
# 生成処理を行う
outputs = trained_model.generate(
input_ids=input_ids, attention_mask=input_mask,
max_length=MAX_TARGET_LENGTH,
temperature=1.0, # 生成にランダム性を入れる温度パラメータ
num_beams=10, # ビームサーチの探索幅
diversity_penalty=1.0, # 生成結果の多様性を生み出すためのペナルティ
num_beam_groups=10, # ビームサーチのグループ数
num_return_sequences=10, # 生成する文の数
repetition_penalty=1.5, # 同じ文の繰り返し(モード崩壊)へのペナルティ
)
# 生成されたトークン列を文字列に変換する
generated_response = [tokenizer.decode(ids, skip_special_tokens=True,
clean_up_tokenization_spaces=False)
for ids in outputs]
# 生成された応答を表示する
for i, response in enumerate(generated_response):
print(f"{i+1:2}. {response}")
1. 最近はどうですか?
2. お疲れ様です。
3. 最近はどうですか??
4. 今の気分はどうですか?
5. おはようございます。
6. 今日はお休みです。
7. 今日はお休みです
8. 今はもう寝る時間です
9. 気分はどうですか?
10. それな。

質問に質問で返すか、どことなく汎用的な言葉を返しがちですね・・・
まとめ
今回はT5という深層学習モデルを使用してチャットボットを作成してみました。
実際に使えるか?はおいておくとしても、学習データさえ用意してしまえば、あとはエンジニアのドメイン知識に関係なく自動的に学習が行われ、そして破綻のない文章を作れている点に関しては、機械学習の凄さを改めて感じました。
機会があればさらに高性能なチャットボットを作成していきたいと思います。