更新(2020/05/20)
今更ながらgoogle colabで動作するnotebookを追加しました。
訓練用と評価用2つを用意していて、評価用の方で全てのセルを実行していただければ、簡単に訓練済みモデルを実行できるかと思います。
訓練済みモデルはいい出来とは言えませんが、曲がりなりにも作成いたしましたので試していただければと思います。
リンク等はGithubのREADMEに記載しております。
何かエラーがありましたら、issue等で知らせていただければと思います。
はじめに
タイトル通り、BERTをEncoderとするChatbotを作成しました。
本当に作りたかったモデルは会話の流れを考慮できる会話モデルの作成なのですが、リソースとデータの観点から厳しいです。
どうにかデータが集められればいいのですが...。
EncoderにBERTを採用した理由は単純な興味からなります。
そもそもTransformerベースのものでChatbotを作ること自体が間違っているという意見が私の中で出ましたが、RoBERTaやALBERT論文が(プログラム及びこの記事作成時2019/08-2019/09に)でたので使いたいと思い採用しました。
あと、日本語の訓練済みBERTモデルが東北大の研究室から公開され、huggingfaceのtransformersから利用できたためです。
学習と推論のコードはGithubで公開しています。
結果
先に結果を載せます。
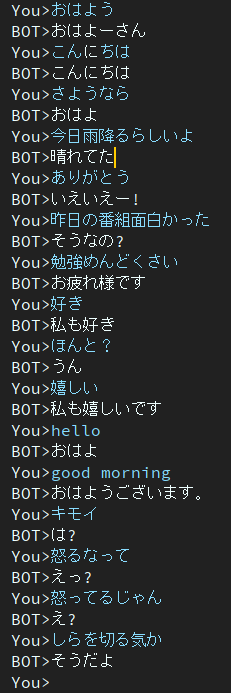
入力はその時に考えた言葉を入れました。
Twitterでデータ収集したので「さようなら」とかあまりデータになかったみたいで、適切な返答が返せてないのがわかります。
また、英語である「hello」や「Good morning」に対して返答してるようにも見えますが、すべての英語に対して「おはよう」系の言葉を返しているのでたまたまこの時成功してるように見えただけでした。
ぱっと見良さそうにも見えますが、「えっ?」とか「は?」のような汎用性の高い返答が多く生成されるように思えます。
この辺は対話生成系の論文で挙げられている多様性の問題そのものだと思います。
頻出トークンが積極的に採用されるためにGreedyで候補を選ぶと当たり障りない返答が返ってくるみたいな。
「Dull Response」と検索かければ色々出てくると思います。
なので、汎用性を追求するなら私の使ってるデータセットでは多くのバイアスがあるので自分のものを用意して使うことをおすすめします。
使用したモデル等
では、ここからTokenizer及びモデルのアーキテクチャについて書いていきます。
Tokenizer
Tokenizerには同時に公開されていたtransformers.BertJapaneseTokenizerを使用しました。
これはBERTのモデルがmecabで学習していたためそのまま流用しました。
公開していただきありがとうございます。
Architecture
モデルのアーキテクチャは単純でtransformersのBERTに、Vanilla TransformerのDecoderを繋げただけです。
これは脳死で決めました。返事を返してくれればいいやくらいの気持ちです。
Decoderの実装に関してFFNの部分だけは、LinearかConv1dかの問題になりましたがConv1dの方がGPUのメモリ食わない気がしたので(気のせいかもしれない)こちらにしました。
内容はGithubを参照してください。
Decoder部分でVanilla Transformerとの違いはembedding_sizeが512->768になっていまる点とactivationにreluではなくgeluを使用している点です。
次元についてはDecoderの頭にLinearをはさんでもよかったですが、BERTに合わせました。
Encoder
import torch
from transformers.modeling_bert import BertModel
def build_encoder(model_name):
encoder = BertEncoder.from_pretrained(model_name).eval()
encoder.freeze()
return encoder
class BertEncoder(BertModel):
def freeze(self):
for p in self.parameters():
p.requires_grad = False
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None,
head_mask=None, inputs_embeds=None, encoder_hidden_states=None, encoder_attention_mask=None):
input_shape = input_ids.size()
device = input_ids.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
if attention_mask.dim() == 3:
extended_attention_mask = attention_mask[:, None, :, :]
elif attention_mask.dim() == 2:
extended_attention_mask = attention_mask[:, None, None, :]
else:
raise ValueError("Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(input_shape,
attention_mask.shape))
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype)
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
encoder_extended_attention_mask = None
head_mask = [None] * self.config.num_hidden_layers
embedding_output = self.embeddings(input_ids=input_ids, position_ids=position_ids,
token_type_ids=token_type_ids, inputs_embeds=inputs_embeds)
encoder_outputs = self.encoder(embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask)
out = encoder_outputs[0]
return out
Decoder
import torch
import torch.nn as nn
from .attention import SourceTargetAttention, SelfAttention
from .ffn import FFN
def build_decoder(N=6, h=8, d_model=512, d_ff=2048, drop_rate=0.1):
decoder_layers = [DecoderLayer(h, d_model, d_ff, drop_rate) for _ in range(N)]
decoder = Decoder(nn.ModuleList(decoder_layers), d_model)
return decoder
class Decoder(nn.Module):
def __init__(self, layers, d_model):
super(Decoder, self).__init__()
# decoder layers
self.layers = layers
self.norm = nn.LayerNorm(d_model)
def forward(self,
x: torch.FloatTensor, memory: torch.FloatTensor,
source_mask: torch.Tensor, target_mask: torch.Tensor
) -> torch.FloatTensor:
source_mask = source_mask.unsqueeze(-2)
# note that memory is passed through encoder
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
def __init__(self, h=8, d_model=512, d_ff=2048, drop_rate=0.1):
super(DecoderLayer, self).__init__()
# Self Attention Layer
# query key and value come from previous layer.
self.self_attn = SelfAttention(h, d_model, drop_rate)
# Source Target Attention Layer
# query comes from encoded space.
# key and value comes from previous self attention layer
self.st_attn = SourceTargetAttention(h, d_model, drop_rate)
self.ff = FFN(d_model, d_ff)
def forward(self, x, mem, source_mask, target_mask):
# self attention
x = self.self_attn(x, target_mask)
# source target attention
x = self.st_attn(mem, x, source_mask)
# pass through feed forward network
return self.ff(x)
学習
LossとかOptimizerの設定などは一般的なものです。
LossはCrossEntropy、Optimizerには目新しさからAdamWを使いました。
Twitterから集めたデータ数百万ペアくらいのデータで5epochくらい回したものが上の結果になります。
上にも書きましたが、詳しいことはGithub見ればわかると思います。
訓練ループ
import torch
from torch.nn.utils import clip_grad_norm_
from tqdm import tqdm
from .batch import Batch
def one_cycle(epoch, config, model, optimizer, criterion, data_loader,
tokenizer, device):
model.train()
with tqdm(total=len(data_loader), desc=f'Epoch: {epoch + 1}') as pbar:
for i, (x, y) in enumerate(data_loader):
optimizer.zero_grad()
batch = Batch(x.to(device), y.to(device), pad=tokenizer.pad_token_id)
out = model(batch.source, batch.source_mask,
batch.target, batch.target_mask)
loss = criterion(out.transpose(1, 2), batch.target_y).mean()
loss.backward()
optimizer.step()
clip_grad_norm_(model.parameters(), config.max_grad_norm)
pbar.update(1)
pbar.set_postfix_str(f'Loss: {loss.item():.5f}')
# always overwrite f'{config.data_dir}/{config.fn}.pth'
torch.save({
'epoch': epoch,
'model': model.state_dict(),
'opt': optimizer.state_dict()
}, f'{config.data_dir}/{config.fn}.pth')
# not overwrite
torch.save({
'epoch': epoch,
'model': model.state_dict(),
'opt': optimizer.state_dict()
}, f'{config.data_dir}/{config.fn}_{epoch}.pth')
print('*** Saved Model ***')
感想
モデルのアーキテクチャを脳死で考えてしまいましたが、まともな(?)返答をしてくれただけで嬉しいです。
しかし、今回の場合はBERT使わなくても通常のTransformerで十分だと思います。
また、Transformerで過去の会話内容参照するためにはメモリなどに保存して、メモリ用にEncodingして入力しないといけないのでそういった面ではRNNの方が扱いやすいように思います。
これに関してはTransformer-xlの再帰機構を応用すれば実現できるのでは?と愚考しています。そう単純な話ではなさそうですけどね。
個人的にTransformerの利点の1つはDecoderの訓練時に時間方向の並列化ができる点だと思っているので、学習速度や学習の安定性からTransformerでのアプローチはしていきたいと考えています。
あと、思い知ったのは学習データの重要性ですね。もっとまともな学習データを集めたいです。いいデータセットがあればコメント欄で教えてください。
今後は生成ではなく用例ベースのモデルも試してみようと思います。
用例ベースで作るなら、データベースに検索かけて一番近い文章を解析して好みの語尾とかに変換って感じですかね。
時間があるときにやろうと思います。
拙い文章ですが読んでいただきありがとうございました。