2020/02/09 追記(変更):
Python 3.8 / Elasticsearch Service 6.8 対応記事はこちらです。
【注意!】(2019/04/17 追記)
私の観測範囲では、2019/04/17 朝より、Lambda 環境上の AWS SDK for Python のバージョンが上がり、Pyhthon 2.7(および 3.6)環境のbotocoreが 1.10 系から 1.12 系に変更されました。
それにより、**「BotocoreHTTPSessionがない」**というエラーが発生するようになりました。
そこで、一部内容を書き換えてbotocore-1.12を直接使わないようにしています。
この記事は、
- ALB/CLBのアクセスログをElasticsearch Service (6.0/6.2) に取り込むメモ
- CloudFrontのアクセスログをElasticsearch Service (6.0/6.2) に取り込むメモ(手抜き編)
に関連して書いたものです。
Aurora(MySQL互換)のスロークエリログは標準ではTABLE形式で出力されます。一方、スロークエリログを Elasticsearch Service に取り込む方法の多くはFILE形式からの取り込みとなっています。
TABLE形式からの取り込みの例としては、
- Aurora のスロークエリログを Fluentd 経由で Amazon Elasticsearch Service に転送する(kakakakakku blog)
がありますが、今回は、
- Elasticsearch Service 6.0/6.2 に取り込む
- Lambda を使って1時間置きに取り込む
- Auroraにあるスロークエリログのローテーションはあえて行わない(他の確認作業で使うため)
- ついでに S3 にもスロークエリログを書き出す
というスタイルで実行してみます。
※3つ目を「ローテーションを行う」運用にする場合は、kakakakakku さんの記事にあるように、CALL mysql.rds_rotate_slow_logでローテーションしてから、mysql.slow_log_backupテーブルの内容をSELECTする形に書き換えると良いでしょう。
手順
1. Elasticsearch Service の起動
内容は省略します。今回は ALB/CLB や CloudFront のアクセスログの取り込みの例と同様、VPC 内にクラスタを作成します。
2. Ingest Pipeline の設定
curlコマンドで設定します。
$ curl -H "Content-Type: application/json" -XPUT 'https://XXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.es.amazonaws.com/_ingest/pipeline/slowlog' -d '{
"processors": [{
"grok": {
"field": "message",
"patterns":[ "%{TIMESTAMP_ISO8601:timestamp} %{NOTSPACE:user_host} %{INT:query_time:int} %{INT:lock_time:int} %{INT:rows_sent:int} %{INT:rows_examined:int} %{NOTSPACE:db} %{GREEDYDATA:sql_test}" ],
"ignore_missing": true
}
},{
"remove":{
"field": "message"
}
}]
}'
3. AWS Lambda ファンクションの作成
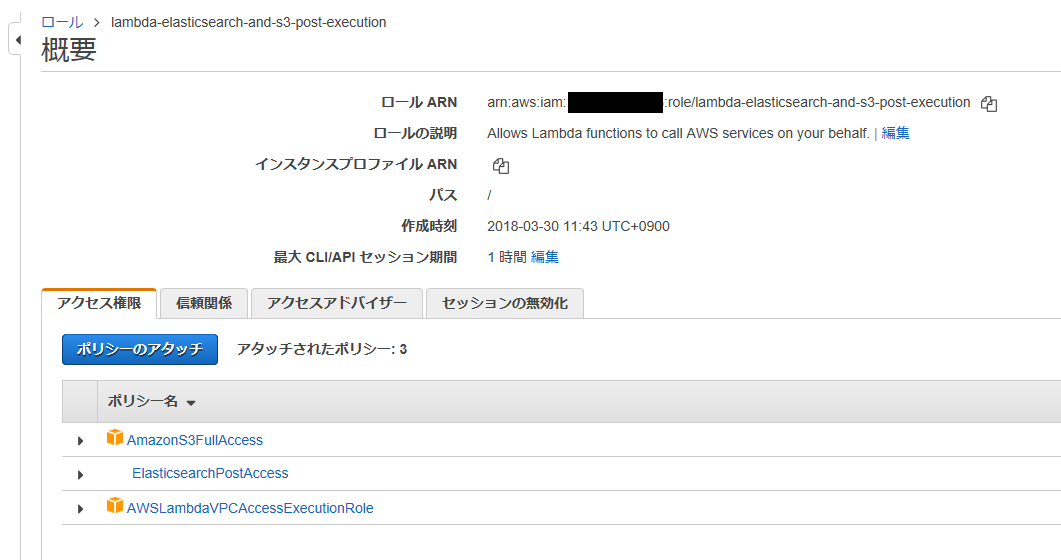
IAM Role の作成
まずリンク先の説明にあるElasticsearchPostAccessポリシーを作っておきます。
- IAM Role の作成(前述の ALB/CLB 取り込みメモより)
続いて、IAM Role を作成します。
Lambda にアップロードする .zip ファイルの作成
今回は、pymysql・requests・requests_aws4auth(および依存モジュール)が必要になるため、.zip ファイルとしてあらかじめ用意します。pymysqlをインストールしたディレクトリに Lambda ファンクションの内容を記述して.zip化します。
$ mkdir ~/auroralog
$ pip2 install pymysql -t ~/auroralog/
$ pip2 install requests -t ~/auroralog/
$ pip2 install requests_aws4auth -t ~/auroralog/
※環境によって「pip」「pip2」など
$ cd ~/auroralog
$ vi auroralog.py
※Lambda ファンクションの内容を記述して保存
$ zip -r ../auroralog.zip *
import boto3
import datetime
import os
import pymysql
import re
import sys
import requests
from requests_aws4auth import AWS4Auth
aurora_host = os.environ["AURORA_HOST"]
aurora_user = os.environ["AURORA_USER"]
aurora_pass = os.environ["AURORA_PASS"]
try:
conn = pymysql.connect(aurora_host, user=aurora_user, passwd=aurora_pass, db="mysql", connect_timeout=10)
except:
print("ERROR: Could not connect to Aurora instance : [%s]." % aurora_host)
sys.exit()
def lambda_handler(event, context):
print("Started")
lasthour = datetime.datetime.today() - datetime.timedelta(hours = (1 - 9))
exportdate1 = lasthour.strftime('%Y%m%d')
exportdate2 = lasthour.strftime('%Y-%m-%d')
exporttime = lasthour.strftime('%H')
es_host = os.environ["ES_HOST"]
es_index = os.environ["ES_INDEX_PREFIX"] + "-" + exportdate1
s3_bucket = os.environ["S3_BUCKET"]
s3_key = os.environ["S3_PREFIX"] + "/" + exportdate2 + "_" + exporttime
region = os.environ["AWS_REGION"]
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
print("Export: " + exportdate1 + "_" + exporttime)
with conn.cursor() as cur:
cur.execute("SELECT CONCAT(DATE(CONVERT_TZ(start_time, '+09:00', 'UTC')), 'T', TIME(CONVERT_TZ(start_time, '+09:00', 'UTC')), 'Z ', REPLACE(user_host, ' ', ''), ' ', TIME_TO_SEC(query_time), ' ', TIME_TO_SEC(lock_time), ' ', rows_sent, ' ', rows_examined, ' ', db, ' ', sql_text) FROM mysql.slow_log WHERE start_time BETWEEN '%s %s:00:00' AND '%s %s:59:59.999'" % (exportdate2, exporttime, exportdate2, exporttime))
file_data = ""
file_count = 1
es_data = ""
for line in cur:
line_data = re.sub(r"(\\t| )+", " ", re.sub(r"\?+", "?", "".join(str(line)).strip()[2:-3].replace('"', '\\"')))
file_data += "%s\n" % line_data
es_data += '{"index":{"_index":"%s","_type":"log"}}\n' % es_index
es_data += '{"message":"%s"}\n' % line_data
if len(file_data) > 3000000:
s3_client = boto3.client("s3")
s3_client.put_object(
Bucket=s3_bucket,
Key=s3_key + "-" + str(file_count),
Body=file_data
)
#print("--- file: %s" % file_count)
#print(file_data)
file_data = ""
file_count += 1
if len(es_data) > 3000000:
_bulk(es_host, es_data, awsauth)
#print("--- es")
#print(es_data)
es_data = ""
if file_data != "":
s3_client = boto3.client("s3")
s3_client.put_object(
Bucket=s3_bucket,
Key=s3_key + "-" + str(file_count),
Body=file_data
)
#print("--- file: %s" % file_count)
#print(file_data)
if es_data != "":
_bulk(es_host, es_data, awsauth)
#print("--- es")
#print(es_data)
return "Completed"
def _bulk(host, doc, awsauth):
pipeline = os.environ["PIPELINE_NAME"]
url = "https://%s/_bulk?pipeline=%s" % (host, pipeline)
headers = {"Content-Type": "application/x-ndjson"}
response = request(url, awsauth, headers=headers, data=doc)
if response.status_code != requests.codes.ok:
print(response.text)
def request(url, awsauth, headers=None, data=None):
return requests.post(url, auth=awsauth, headers=headers, data=data)
Lambda ファンクションの作成
先ほどの.zipファイルをアップロードする形で作成します。
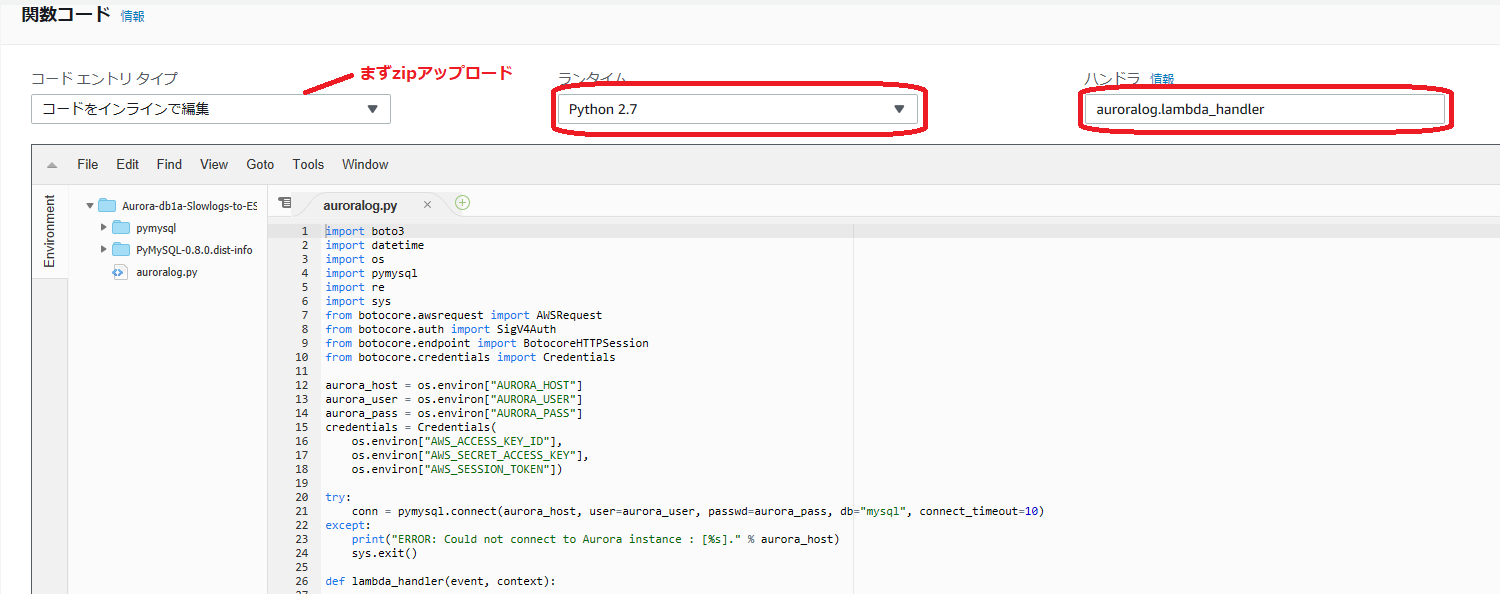
※画面はアップロード後。コードのインライン編集ができる状態になってからのものです。
ランタイムは Python 2.7、ハンドラは【アップロードしたファイル名】.lambda_handlerを指定します。
環境変数の設定は以下の通りです。
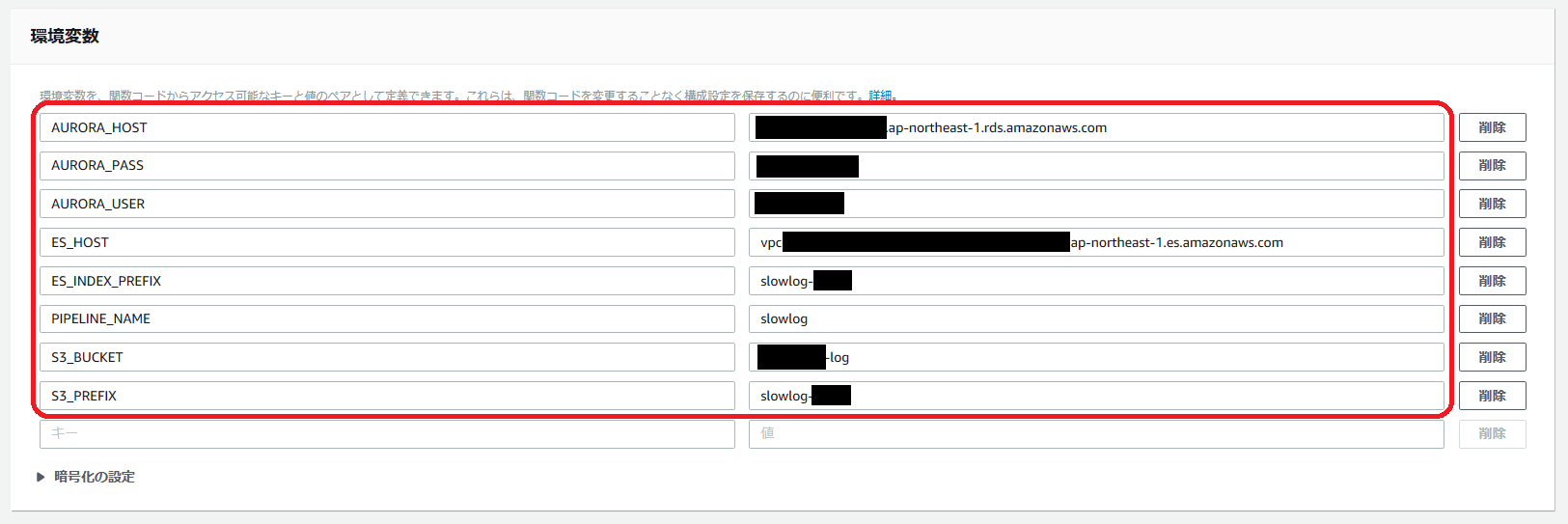
※「AWS Secrets Manager」が発表されましたが、いずれ Aurora の認証情報(AURORA_PASS・AURORA_USER)はそちらで管理するコードにしたほうがよさそうですね。
トリガーは「CloudWatch Events」で cron 式を使って、毎時1分~55分あたりを指定すると良いでしょう(画面は省略)。
実行ロールは先に作成したものを指定します。タイムアウトの時間も延長しておきます。
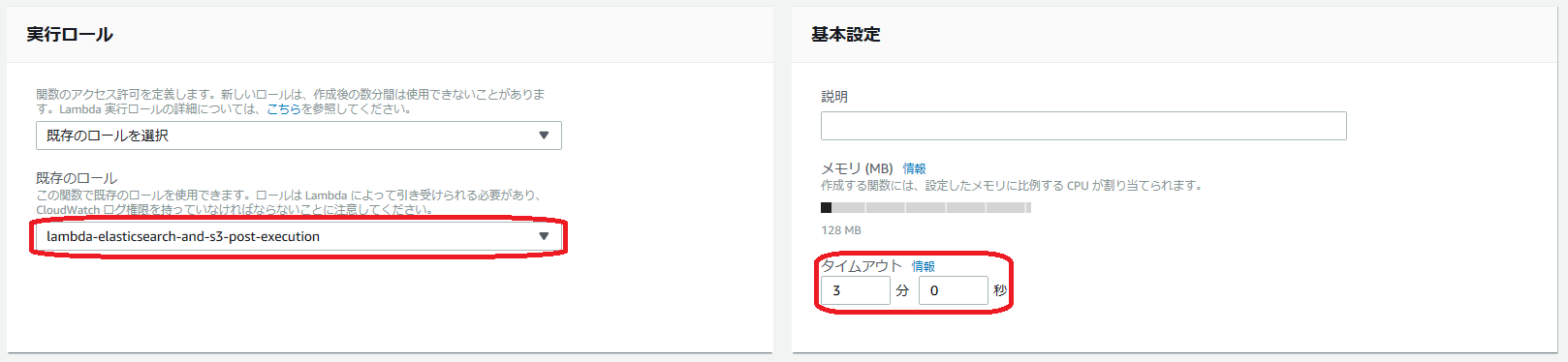
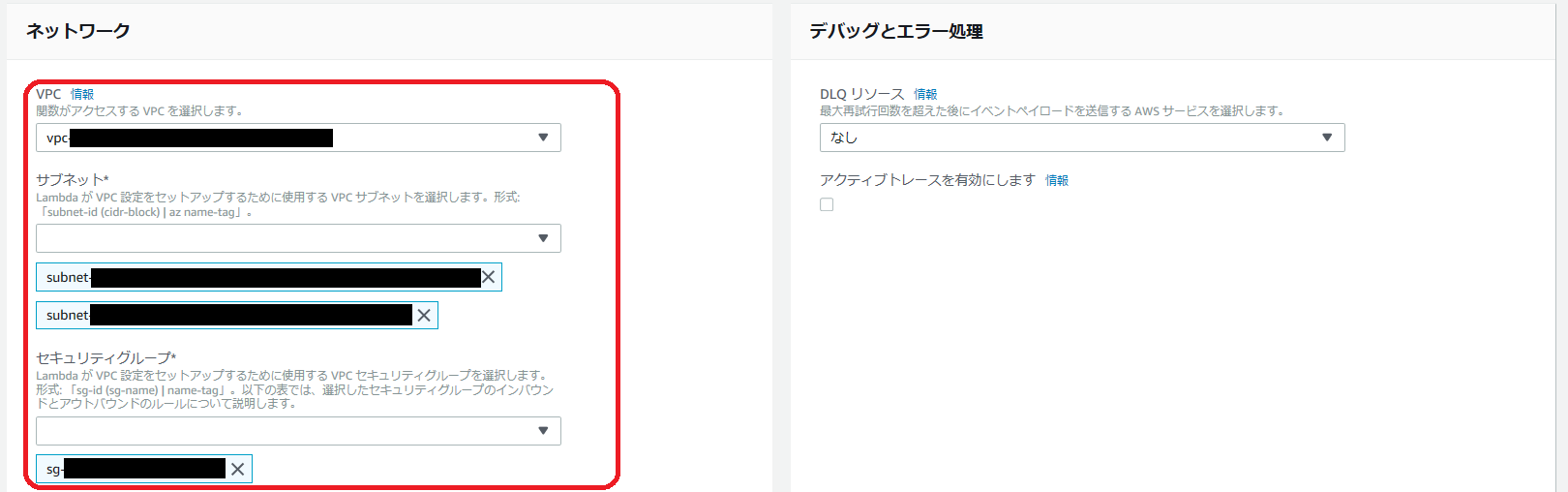
ネットワークの設定は、VPC を使う形で各項目を指定します。
注意点
SQL を発行してスロークエリログを取得しています。その関係で、
- スロークエリログを取得するユーザのアクセス権(できるだけ最小に)
- ↑のユーザ管理
- SQL の実行負荷
に注意しましょう。
スロークエリログが膨大な場合は、以下のような変更を検討してください。
- (前述の)ローテーションを行う方法にする(
WHERE句を使わずに済むように) - 実行間隔や時刻(毎時〇分)を調整する
また、今回はあえて Python 2.7 を使っています。スロークエリログの SQL に含まれる2バイト以上の文字を「?」でマスクして1文字に短縮する処理を行うのにかえって都合がよかったからですが、2バイト以上の文字をそのまま取り込みたい場合は、Python 3.6 環境で UTF-8 を処理するのが良いと思います。
一方、SQL に含まれる(1バイト)英数字等もマスキングしたい場合は、正規表現などを使って変換を加える必要があります。
それから、S3 に書き出す処理では、SQL 負荷を考慮して、書き出すログのstart_timeをあえて UTC・ISO 8601 形式で Elasticsearch へ送るものと合わせています。また、gzip 圧縮もしていません。このあたりは環境と要件に合わせてコードを書き換えてください。
その他
過去2つのコードと違い、今回は実行間隔が短い関係で日時の取得をlambda_handler内で行っています。これは、Lambda の実行間隔が短いと、環境がシャットダウンされず維持され、その結果として起動時の日時が残ってしまう→1~3時間前のログを重ねて出力してしまう(そして当該時刻のログが出力されない)、という問題を避けるためです。