2020/01/05 追記:
Python 3.8 / Elasticsearch Service 6.8 対応版はこちらです。
【注意!】(2019/04/17 追記)
私の観測範囲では、2019/04/17 朝より、Lambda 環境上の AWS SDK for Python のバージョンが上がり、Pyhthon 2.7(および 3.6)環境のbotocoreが 1.10 系から 1.12 系に変更されました。
それにより、**「BotocoreHTTPSessionがない」**というエラーが発生するようになりました。
そこで、一部補足を入れ、botocore-1.12を直接使わない形に変更しています。
完全に「他人のふんどしでなんとやら」な記事ですが、クラスメソッドさんの、
を、Elasticsearch Service の Elasticsearch 6.0 環境に取り込む形でチャレンジしてみましたので、メモを残しておきます。
2018/04/08追記:
Elasticsearch 6.2 環境でも同じ方法で取り込むことができることを確認しました。
気を付けること
これも、クラスメソッドさんの、
に書いてありますが、Elasticsearch 6.0 にリクエストを送信するときには**Content-Type: application/json**をリクエストヘッダに指定する必要があります。
基本的には、ここだけです。
2018/03/16追記:
ログの量が多い場合、Lambda の割り当てメモリサイズを増やす必要があります(後述)。
手順
1. Amazon Elasticsearch Service の起動
基本的には元記事のままですので、手順は省略します(バージョンの選択を変えるだけ)。
なお、VPC 内にクラスタを作成する場合、セキュリティグループでは**HTTPS(TCP:443)**のインバウンドアクセスを有効にしておく必要があります。
2. Ingest Pipeline の設定
実行するcurlコマンドに、前述のリクエストヘッダの指定を加えるだけです。
$ curl -H "Content-Type: application/json" -XPUT 'https://XXXXX-XXXXXXXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.es.amazonaws.com/_ingest/pipeline/elblog' -d '{
(以下、略)
※ALB 独自のログ項目を取得する必要がなければ、ログフォーマット・項目の設定は元記事のままで ALB でも利用できるようです。
3. AWS Lambda ファンクションの作成
元記事の説明がかなり省略されているので、一部、画面キャプチャで補っておきます。
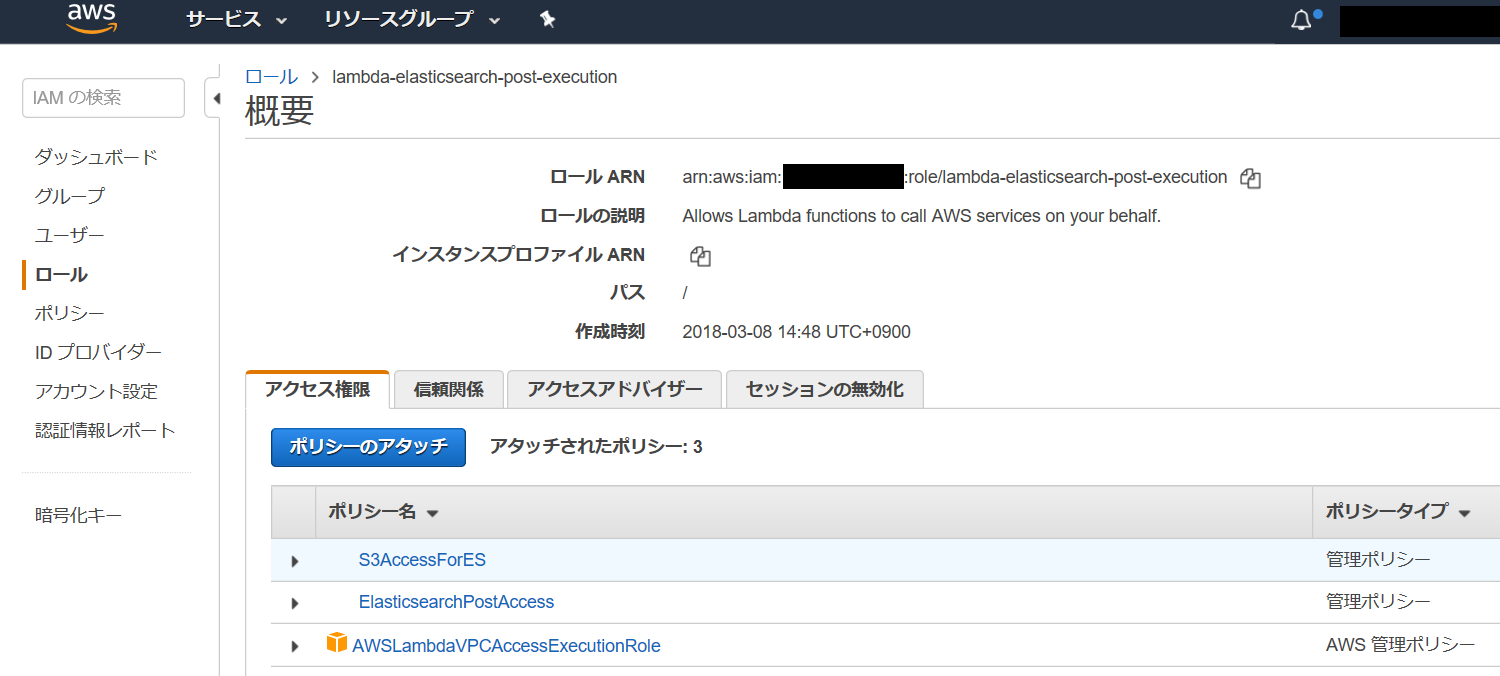
IAM Role の作成
以下は、Elasticsearch Service クラスタを VPC 内に作成する場合の設定です。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets",
"s3:ListBucket",
"s3:GetObject*",
"s3:GetBucketLocation"
],
"Resource": "*"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"es:ESHttpPost",
"es:ESHttpPut"
],
"Resource": "*"
}
]
}
Lambda ファンクションの作成
元記事のコードに対して、リクエストヘッダでContent-Type: application/x-ndjsonを加える処理を追加します。
2018/03/30追記:
_bulkでデータ投入する場合は(Content-Type: application/jsonでも動きますが)Content-Type: application/x-ndjsonが正しいようですので訂正しました(画面キャプチャは直っていませんが)。
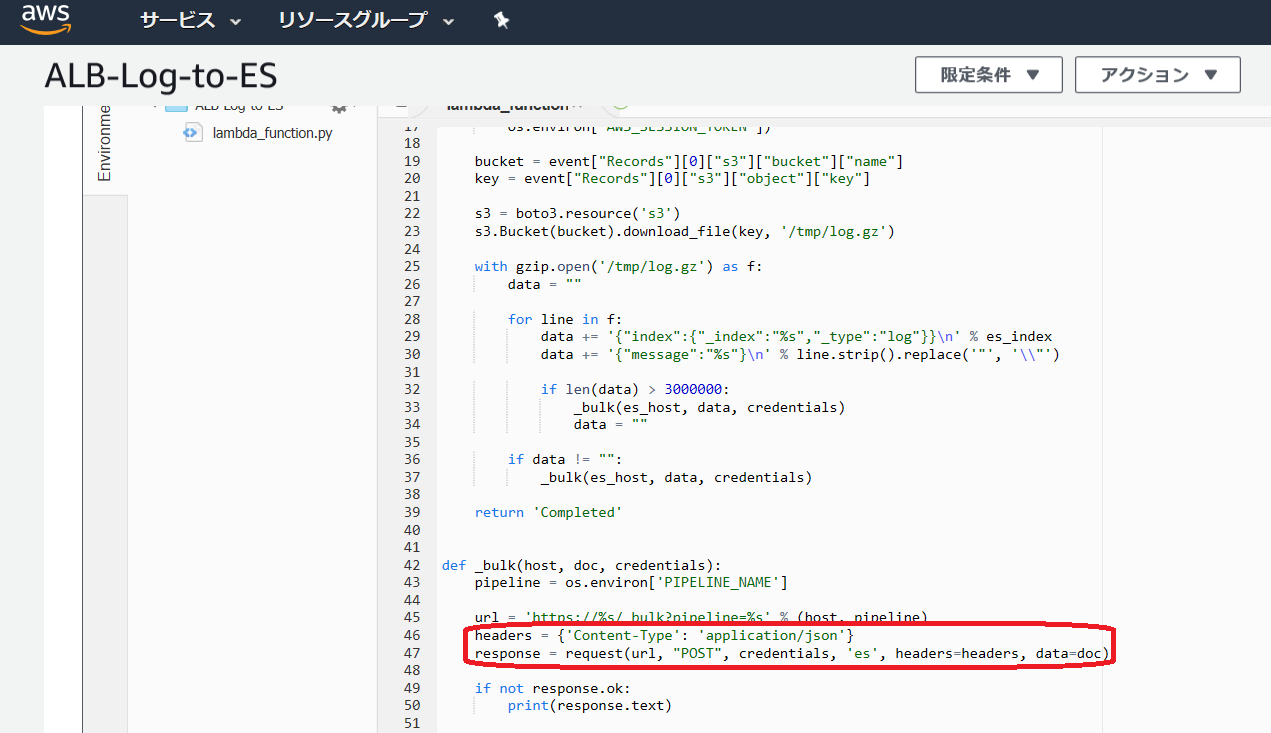
headers = {'Content-Type': 'application/x-ndjson'}
response = request(url, "POST", credentials, 'es', headers=headers, data=doc)
※うまく動かないときは、この変更箇所の直下にprint(response.text)を加えると、CloudWatch Logs のログにエラー等の内容が書き出され、原因究明の手掛かりになりますので試してみてください。
2019/04/17 追記:
冒頭に記した通り、元のコードがbotocore-1.12系で使えなくなったのでbotocoreを直接操作しないコードに書き換えます。
但し、Python Lambda 環境には
requestsrequests_aws4auth- これらの依存モジュール
が足りませんので、手元の環境でこれらを含む .zip ファイルを作成します(**こちら**を参照。但しpymysqlは不要)。
なお、Lambda ファンクション本体のファイル名は**「lambda_function.py」**にして .zip ファイルに入れます。
import boto3
import os
import gzip
import requests
from datetime import datetime
from requests_aws4auth import AWS4Auth
def lambda_handler(event, context):
print('Started')
es_index = os.environ['ES_INDEX_PREFIX'] + "-" + datetime.strftime(datetime.now(), "%Y%m%d")
region = os.environ["AWS_REGION"]
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = event["Records"][0]["s3"]["object"]["key"]
s3 = boto3.resource('s3')
s3.Bucket(bucket).download_file(key, '/tmp/log.gz')
with gzip.open('/tmp/log.gz') as f:
data = ""
for line in f:
data += '{"index":{"_index":"%s","_type":"log"}}\n' % es_index
data += '{"message":"%s"}\n' % line.strip().replace('"', '\\"')
if len(data) > 3000000:
_bulk(data, awsauth)
data = ""
if data != "":
_bulk(data, awsauth)
return 'Completed'
def _bulk(data, awsauth):
es_host = os.environ['ES_HOST']
pipeline = os.environ['PIPELINE_NAME']
url = 'https://%s/_bulk?pipeline=%s' % (es_host, pipeline)
headers = {'Content-Type': 'application/x-ndjson'}
response = request(url, awsauth, headers=headers, data=data)
if response.status_code != requests.codes.ok:
print(response.text)
def request(url, awsauth, headers=None, data=None):
return requests.post(url, auth=awsauth, headers=headers, data=data)
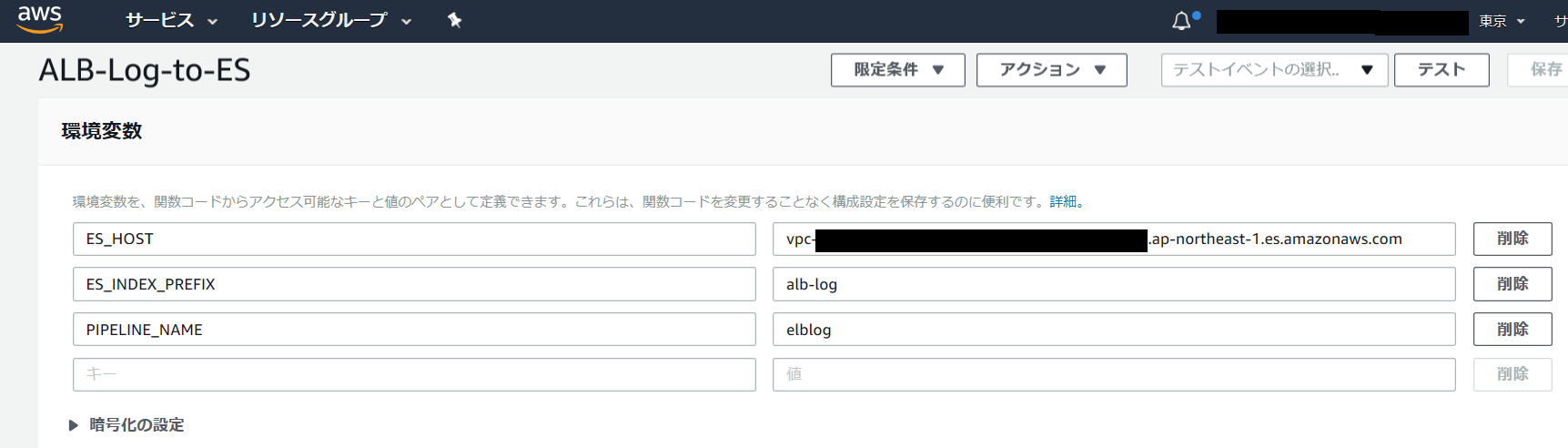
環境変数は以下のように指定します。
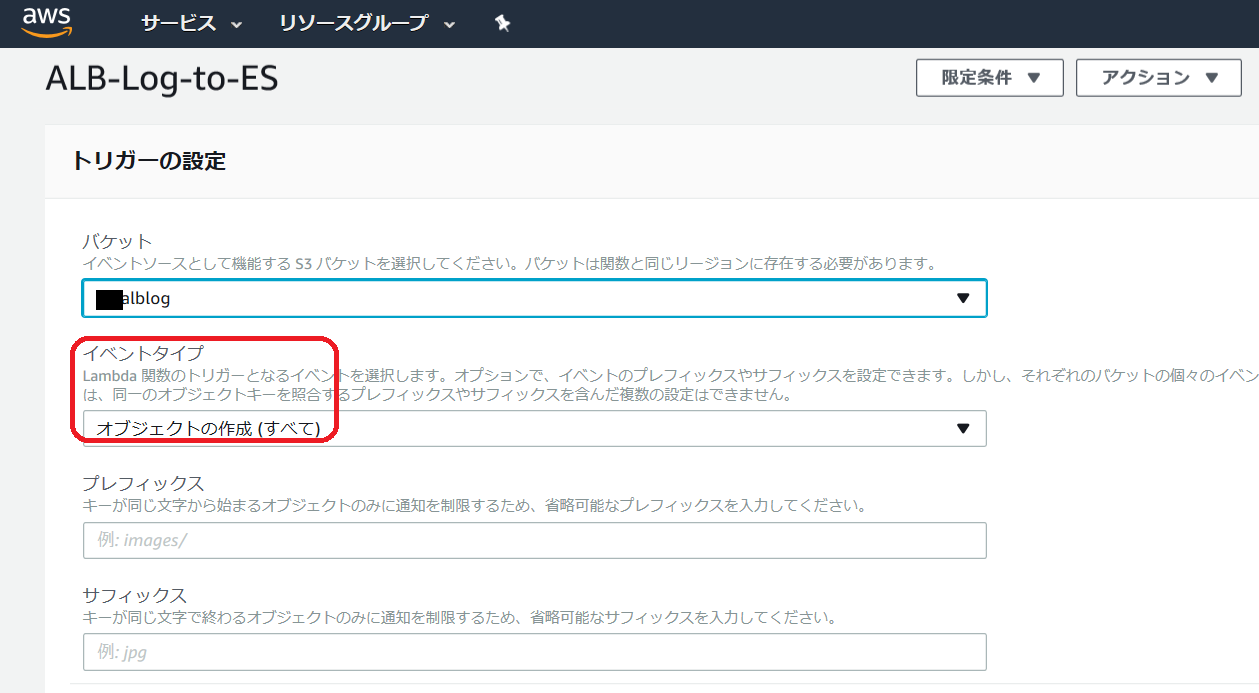
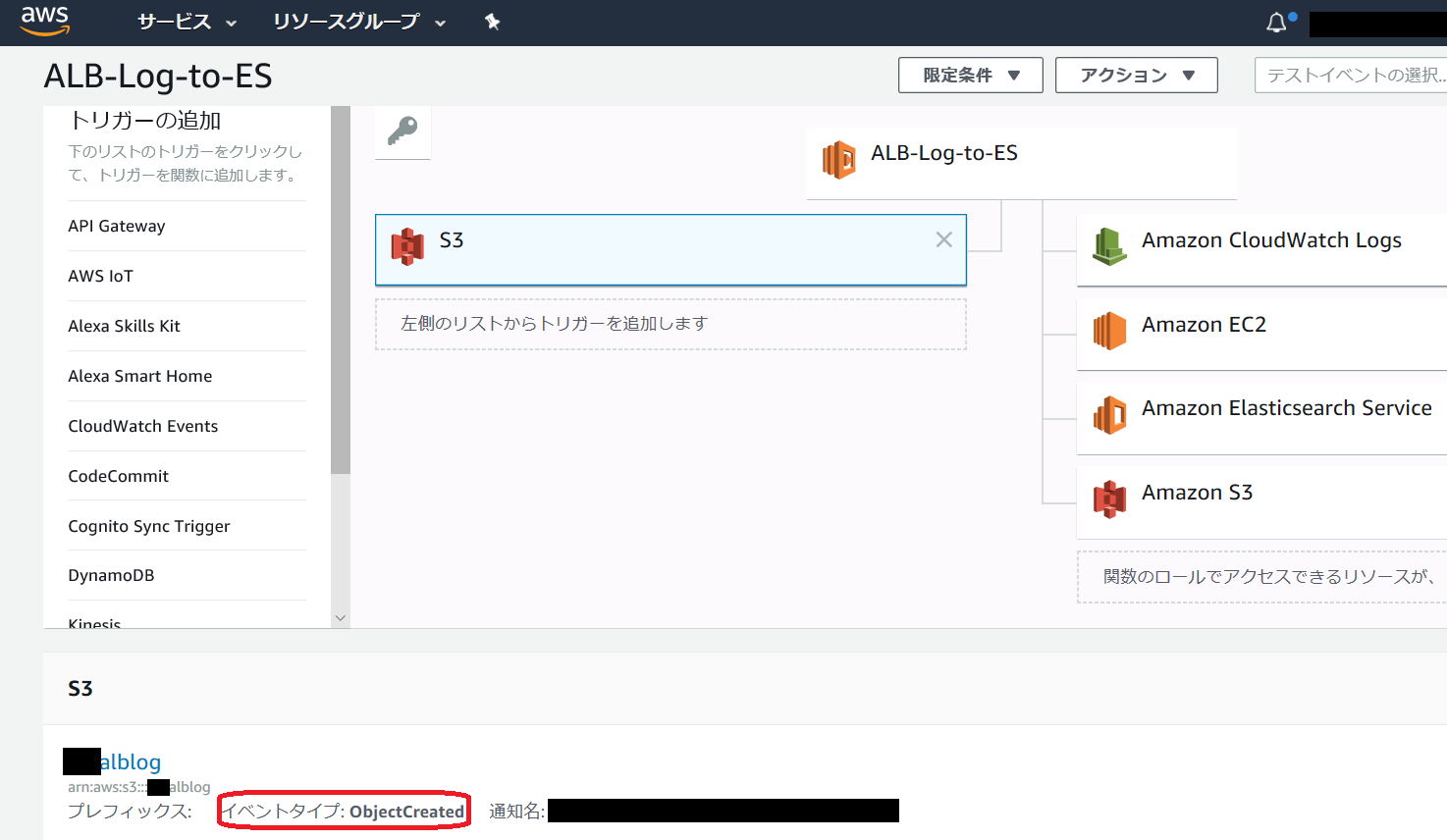
なお、アクセスログが保存されている S3 バケットのトリガーの設定は以下のように行います。
↓保存後
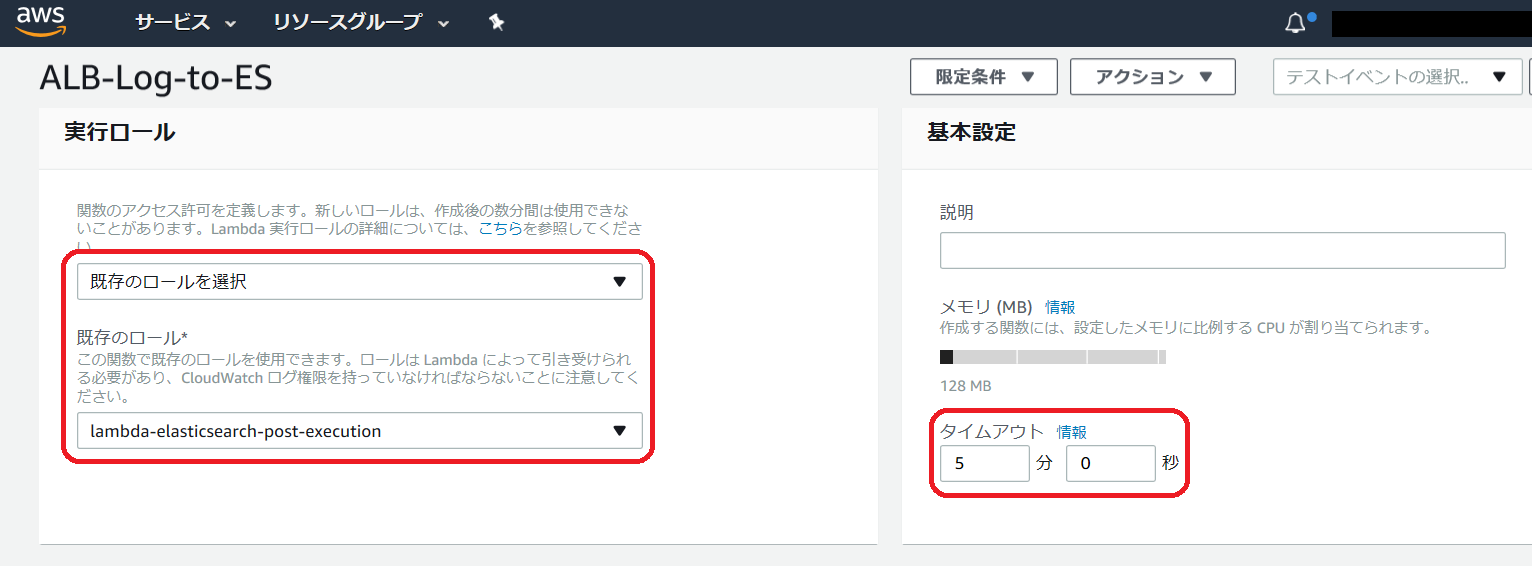
先に作成したロールの指定は以下の通りです。タイムアウト時間も適宜変更しておきます。
2018/03/16追記:
ALB/CLB のログサイズが大きい場合、Lambda に割り当てるメモリサイズが 128MB では不足します。
URL/パスの長さなどにもよりますが、私が試した環境では、分間 40,000 リクエスト程度で最大 160MB 程度必要になったため、Lambda への割り当てを 192MB に増やしました。
なお、メモリが足りない場合、解凍後のログをまとめて転送する途中でエラーになり、最大3回リトライされて同じログが3つ記録されることがあります(その一方で、記録されないログも存在する可能性あり)。
以下は、VPC 内に作成する場合のネットワーク設定の例です。
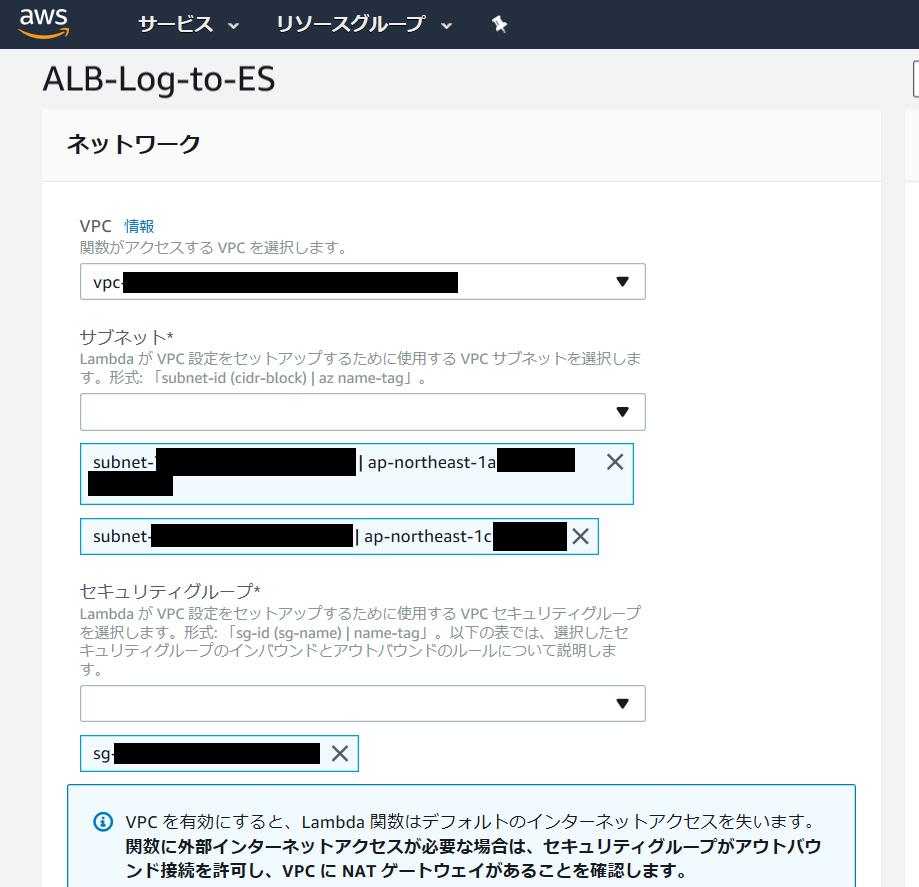
※セキュリティグループでアウトバウンド接続を許可しておきます。
設定後、5~10分程度経過すると、ログが Elasticsearch Service に取り込まれ、Kibana で確認できるようになります。
2018/03/16追記:
早速 6.2 が出たので、近いうちに試すことになりそうです。→04/08 試しました。
2018/03/21追記:
CloudFront アクセスログ用の変更点を書きました。