この記事では
U-netについて説明した後、 tensorflow2.0でU-Net実装する方法について紹介します。
1. U-netとは
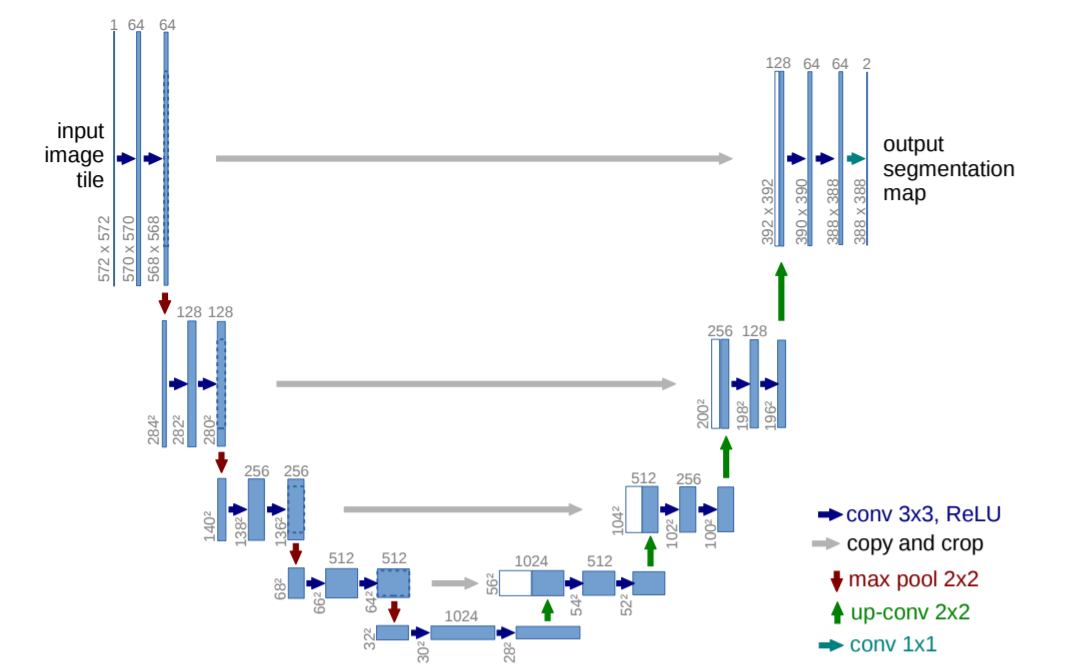
U-netは全層畳み込みネットワーク(Fully Convolution Network,以下 FCN)の1つであり、画像のセグメンテーション(物体がどこにあるか)を推定するためのネットワークです。
上のイメージのように「U字のネットワーク」になっているからU-Netと呼ばれます。イメージの各要素の意味は下記の通りです。
| ボックス | 矢印 |
|---|---|
| 青ボックス:画像、特徴マップ | 青矢印:kernel size 3×3, padding0の畳み込み、ReLU |
| 白ボックス:コピーされた特徴マップ | グレー矢印:特徴マップのコピーをクロップ |
| ボックスの上の数字:チャンネル数 | 赤矢印:kernel size 2×2のmax-pooling |
| ボックスの左下の数字:縦横のサイズ | 青緑矢印:kernel size 1×1の畳み込み |
U-NetはVGG16等のCNNモデルとは異なり、以下の3つの特徴があります。
① Upサンプリング
- Upサンプリング 画像の解像度を上げる意味があります。
- 画像の解像度を下げるプーリング(ダウンプーリング)処理と逆の効果を持つため「アンプーリング」とも呼ばれます。
② Merge(マージ)
- 文字通り情報を統合する意味があります。
- U-Netの下向きパスは、深い層ほど、特徴が局所的で位置情報が曖昧に、浅い層ほど、特徴は全体的で位置情報は正確になります。
- 上向きパスは、特徴を保持したまま、画像を大きく復元することができるので、両方のパスにおいて、画像サイズが同じものを深い層から段階的にマージすることによって、局所的特徴を保持したまま全体的位置情報の復元を行うことができます。
③ 全結合層がない
- 全結合層がない VGG16等のCNNモデルに見られるような全結合層がありません。
- クラス分類や回帰では、全結合層が必要ですが、領域抽出では画像が出力になるため、全結合層が必要ありません。
- そのため、畳み込み層だけのネットワーク = Fully Convolutional Network(FCN)と呼ばれます。
- 出力層では、シグモイド関数を使用することにより、出力は0~1の値となるため、推論の際は閾値を設けて、白黒の二値画像として出力させます。
(※このネットワーク図では具体例として入力画像と特徴マップのサイズも記載されているが、U-Netは全結合層を持たないため、入力画像サイズを固定する必要はありません。) - U-netはオートエンコーダー(AE:Auto Encoder)としての側面もあります。
- なぜなら、オートエンコーダーは出力画像が入力画像が等しくなるように訓練を行うからです。
- U-NetはEncoderのpoolingを経てダウンサンプリングされた特徴マップをDecoderでアップサンプリングしていきます。
しかし、U-Netが一般的なオートエンコーダー(AE:Auto Encoder)と異なる点は、EncoderとDecoderの間にはしごのように配線があるということです。
2. U-netの実装
U-Netの実装は、Encoderの各層では前の層の特徴マップと統合を行い、出力される特徴マップを、Decoderの対応する層の特徴マップに直接連結することでpixelのディティールを補う流れになります。
tf.kerasのSubclassing APIによるU-netモデルを実装してみました。これは私が実装したU-netの全体のコードです。以降でコードを少し詳しく説明します。
import os
import numpy as np
import random
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, Activation, BatchNormalization, Dropout, Flatten, Dense
class UNet(Model):
def __init__(self, config):
super().__init__()
# Network
self.enc = Encoder(config)
self.dec = Decoder(config)
# Optimizer
self.optimizer = tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
# loss
self.loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
self.train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
self.valid_loss = tf.keras.metrics.Mean('valid_loss', dtype=tf.float32)
def call(self, x):
z1, z2, z3, z4_dropout, z5_dropout = self.enc(x)
y = self.dec(z1, z2, z3, z4_dropout, z5_dropout)
return y
@tf.function
def train_step(self, x, t):
with tf.GradientTape() as tape:
y = self.call(x)
loss = self.loss_object(t, y)
gradients = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
self.train_loss(loss)
@tf.function
def valid_step(self, x, t):
y = self.call(x)
v_loss = self.loss_object(t, y)
self.valid_loss(v_loss)
return y
class Encoder(Model):
def __init__(self, config):
super().__init__()
# Network
self.block1_conv1 = tf.keras.layers.Conv2D(64, (3, 3) , name='block1_conv1', activation = 'relu', padding = 'same')
self.block1_conv2 = tf.keras.layers.Conv2D(64, (3, 3) , name='block1_conv2', padding = 'same')
self.block1_bn = tf.keras.layers.BatchNormalization()
self.block1_act = tf.keras.layers.ReLU()
self.block1_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block1_pool')
self.block2_conv1 = tf.keras.layers.Conv2D(128, (3, 3) , name='block2_conv1', activation = 'relu', padding = 'same')
self.block2_conv2 = tf.keras.layers.Conv2D(128, (3, 3) , name='block2_conv2', padding = 'same')
self.block2_bn = tf.keras.layers.BatchNormalization()
self.block2_act = tf.keras.layers.ReLU()
self.block2_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block2_pool')
self.block3_conv1 = tf.keras.layers.Conv2D(256, (3, 3) , name='block3_conv1', activation = 'relu', padding = 'same')
self.block3_conv2 = tf.keras.layers.Conv2D(256, (3, 3) , name='block3_conv2', padding = 'same')
self.block3_bn = tf.keras.layers.BatchNormalization()
self.block3_act = tf.keras.layers.ReLU()
self.block3_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block3_pool')
self.block4_conv1 = tf.keras.layers.Conv2D(512, (3, 3) , name='block4_conv1', activation = 'relu', padding = 'same')
self.block4_conv2 = tf.keras.layers.Conv2D(512, (3, 3) , name='block4_conv2', padding = 'same')
self.block4_bn = tf.keras.layers.BatchNormalization()
self.block4_act = tf.keras.layers.ReLU()
self.block4_dropout = tf.keras.layers.Dropout(0.5)
self.block4_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block4_pool')
self.block5_conv1 = tf.keras.layers.Conv2D(1024, (3, 3) , name='block5_conv1', activation = 'relu', padding = 'same')
self.block5_conv2 = tf.keras.layers.Conv2D(1024, (3, 3) , name='block5_conv2', padding = 'same')
self.block5_bn = tf.keras.layers.BatchNormalization()
self.block5_act = tf.keras.layers.ReLU()
self.block5_dropout = tf.keras.layers.Dropout(0.5)
def call(self, x):
z1 = self.block1_conv1(x)
z1 = self.block1_conv2(z1)
z1 = self.block1_bn(z1)
z1 = self.block1_act(z1)
z1_pool = self.block1_pool(z1)
z2 = self.block2_conv1(z1_pool)
z2 = self.block2_conv2(z2)
z2 = self.block2_bn(z2)
z2 = self.block2_act(z2)
z2_pool = self.block2_pool(z2)
z3 = self.block3_conv1(z2_pool)
z3 = self.block3_conv2(z3)
z3 = self.block3_bn(z3)
z3 = self.block3_act(z3)
z3_pool = self.block3_pool(z3)
z4 = self.block4_conv1(z3_pool)
z4 = self.block4_conv2(z4)
z4 = self.block4_bn(z4)
z4 = self.block4_act(z4)
z4_dropout = self.block4_dropout(z4)
z4_pool = self.block4_pool(z4_dropout)
z5 = self.block5_conv1(z4_pool)
z5 = self.block5_conv2(z5)
z5 = self.block5_bn(z5)
z5 = self.block5_act(z5)
z5_dropout = self.block5_dropout(z5)
return z1, z2, z3, z4_dropout, z5_dropout
class Decoder(Model):
def __init__(self, config):
super().__init__()
# Network
self.block6_up = tf.keras.layers.UpSampling2D(size = (2,2))
self.block6_conv1 = tf.keras.layers.Conv2D(512, (2, 2) , name='block6_conv1', activation = 'relu', padding = 'same')
self.block6_conv2 = tf.keras.layers.Conv2D(512, (3, 3) , name='block6_conv2', activation = 'relu', padding = 'same')
self.block6_conv3 = tf.keras.layers.Conv2D(512, (3, 3) , name='block6_conv3', padding = 'same')
self.block6_bn = tf.keras.layers.BatchNormalization()
self.block6_act = tf.keras.layers.ReLU()
self.block7_up = tf.keras.layers.UpSampling2D(size = (2,2))
self.block7_conv1 = tf.keras.layers.Conv2D(256, (2, 2) , name='block7_conv1', activation = 'relu', padding = 'same')
self.block7_conv2 = tf.keras.layers.Conv2D(256, (3, 3) , name='block7_conv2', activation = 'relu', padding = 'same')
self.block7_conv3 = tf.keras.layers.Conv2D(256, (3, 3) , name='block7_conv3', padding = 'same')
self.block7_bn = tf.keras.layers.BatchNormalization()
self.block7_act = tf.keras.layers.ReLU()
self.block8_up = tf.keras.layers.UpSampling2D(size = (2,2))
self.block8_conv1 = tf.keras.layers.Conv2D(128, (2, 2) , name='block8_conv1', activation = 'relu', padding = 'same')
self.block8_conv2 = tf.keras.layers.Conv2D(128, (3, 3) , name='block8_conv2', activation = 'relu', padding = 'same')
self.block8_conv3 = tf.keras.layers.Conv2D(128, (3, 3) , name='block8_conv3', padding = 'same')
self.block8_bn = tf.keras.layers.BatchNormalization()
self.block8_act = tf.keras.layers.ReLU()
self.block9_up = tf.keras.layers.UpSampling2D(size = (2,2))
self.block9_conv1 = tf.keras.layers.Conv2D(64, (2, 2) , name='block9_conv1', activation = 'relu', padding = 'same')
self.block9_conv2 = tf.keras.layers.Conv2D(64, (3, 3) , name='block9_conv2', activation = 'relu', padding = 'same')
self.block9_conv3 = tf.keras.layers.Conv2D(64, (3, 3) , name='block9_conv3', padding = 'same')
self.block9_bn = tf.keras.layers.BatchNormalization()
self.block9_act = tf.keras.layers.ReLU()
self.output_conv = tf.keras.layers.Conv2D(config.model.num_class, (1, 1), name='output_conv', activation = 'sigmoid')
def call(self, z1, z2, z3, z4_dropout, z5_dropout):
z6_up = self.block6_up(z5_dropout)
z6 = self.block6_conv1(z6_up)
z6 = tf.keras.layers.concatenate([z4_dropout,z6], axis = 3)
z6 = self.block6_conv2(z6)
z6 = self.block6_conv3(z6)
z6 = self.block6_bn(z6)
z6 = self.block6_act(z6)
z7_up = self.block7_up(z6)
z7 = self.block7_conv1(z7_up)
z7 = tf.keras.layers.concatenate([z3, z7], axis = 3)
z7 = self.block7_conv2(z7)
z7 = self.block7_conv3(z7)
z7 = self.block7_bn(z7)
z7 = self.block7_act(z7)
z8_up = self.block8_up(z7)
z8 = self.block8_conv1(z8_up)
z8 = tf.keras.layers.concatenate([z2, z8], axis = 3)
z8 = self.block8_conv2(z8)
z8 = self.block8_conv3(z8)
z8 = self.block8_bn(z8)
z8 = self.block8_act(z8)
z9_up = self.block9_up(z8)
z9 = self.block9_conv1(z9_up)
z9 = tf.keras.layers.concatenate([z1, z9], axis = 3)
z9 = self.block9_conv2(z9)
z9 = self.block9_conv3(z9)
z9 = self.block9_bn(z9)
z9 = self.block9_act(z9)
y = self.output_conv(z9)
return y
2-1)ライブラリのインポート
まず、必要なライブラリをインポートしましょう。
import os
import numpy as np
import random
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, Activation, BatchNormalization, Dropout, Flatten, Dense
2-2) モデル・損失関数・オプティマイザの設定
イメージセグメンテーションでは損失関数としてDice係数、SparseCategoricalCrossentropy等を利用することができます。
私は損失関数でBinaryCrossentropyを使用し、オプティマイザはAdamを使いました。
class UNet(Model):
def __init__(self, config):
super().__init__()
# Network
self.enc = Encoder(config)
self.dec = Decoder(config)
# Optimizer
self.optimizer = tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
# loss
self.loss_object = tf.keras.losses.BinaryCrossentropy()
self.train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
self.valid_loss = tf.keras.metrics.Mean('valid_loss', dtype=tf.float32)
def call(self, x):
z1, z2, z3, z4_dropout, z5_dropout = self.enc(x)
y = self.dec(z1, z2, z3, z4_dropout, z5_dropout)
return y
@tf.function
def train_step(self, x, t):
with tf.GradientTape() as tape:
y = self.call(x)
loss = self.loss_object(t, y)
gradients = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
self.train_loss(loss)
@tf.function
def valid_step(self, x, t):
y = self.call(x)
v_loss = self.loss_object(t, y)
self.valid_loss(v_loss)
return y
2-3)Encoderの定義
U-NetのEncoderの特徴は下記の通りです。
- 典型的なConvolution network
- 3X3 convolutionを二回反復して行う
- 活性化関数でReLUを使う
- 2X2 max pooling と stride 2を使う
- downsampling時、 2倍のfeature channelを利用する
これらの特徴を元に実装して行くとこのようになります。
class Encoder(Model):
def __init__(self, config):
super().__init__()
# Network
# 3X3 convolutionを二回反復します。
self.block1_conv1 = tf.keras.layers.Conv2D(64, (3, 3) , name='block1_conv1', activation = 'relu', padding = 'same')
self.block1_conv2 = tf.keras.layers.Conv2D(64, (3, 3) , name='block1_conv2', padding = 'same')
self.block1_bn = tf.keras.layers.BatchNormalization()
# 活性化関数でReLUを使います。
self.block1_act = tf.keras.layers.ReLU()
# 2X2 max pooling と stride 2を使います。
self.block1_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block1_pool')
self.block2_conv1 = tf.keras.layers.Conv2D(128, (3, 3) , name='block2_conv1', activation = 'relu', padding = 'same')
self.block2_conv2 = tf.keras.layers.Conv2D(128, (3, 3) , name='block2_conv2', padding = 'same')
self.block2_bn = tf.keras.layers.BatchNormalization()
self.block2_act = tf.keras.layers.ReLU()
self.block2_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block2_pool')
self.block3_conv1 = tf.keras.layers.Conv2D(256, (3, 3) , name='block3_conv1', activation = 'relu', padding = 'same')
self.block3_conv2 = tf.keras.layers.Conv2D(256, (3, 3) , name='block3_conv2', padding = 'same')
self.block3_bn = tf.keras.layers.BatchNormalization()
self.block3_act = tf.keras.layers.ReLU()
self.block3_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block3_pool')
self.block4_conv1 = tf.keras.layers.Conv2D(512, (3, 3) , name='block4_conv1', activation = 'relu', padding = 'same')
self.block4_conv2 = tf.keras.layers.Conv2D(512, (3, 3) , name='block4_conv2', padding = 'same')
self.block4_bn = tf.keras.layers.BatchNormalization()
self.block4_act = tf.keras.layers.ReLU()
self.block4_dropout = tf.keras.layers.Dropout(0.5)
self.block4_pool = tf.keras.layers.MaxPooling2D((2, 2), strides=None, name='block4_pool')
self.block5_conv1 = tf.keras.layers.Conv2D(1024, (3, 3) , name='block5_conv1', activation = 'relu', padding = 'same')
self.block5_conv2 = tf.keras.layers.Conv2D(1024, (3, 3) , name='block5_conv2', padding = 'same')
self.block5_bn = tf.keras.layers.BatchNormalization()
self.block5_act = tf.keras.layers.ReLU()
self.block5_dropout = tf.keras.layers.Dropout(0.5)
def call(self, x):
z1 = self.block1_conv1(x)
z1 = self.block1_conv2(z1)
z1 = self.block1_bn(z1)
z1 = self.block1_act(z1)
z1_pool = self.block1_pool(z1)
z2 = self.block2_conv1(z1_pool)
z2 = self.block2_conv2(z2)
z2 = self.block2_bn(z2)
z2 = self.block2_act(z2)
z2_pool = self.block2_pool(z2)
z3 = self.block3_conv1(z2_pool)
z3 = self.block3_conv2(z3)
z3 = self.block3_bn(z3)
z3 = self.block3_act(z3)
z3_pool = self.block3_pool(z3)
z4 = self.block4_conv1(z3_pool)
z4 = self.block4_conv2(z4)
z4 = self.block4_bn(z4)
z4 = self.block4_act(z4)
z4_dropout = self.block4_dropout(z4)
z4_pool = self.block4_pool(z4_dropout)
z5 = self.block5_conv1(z4_pool)
z5 = self.block5_conv2(z5)
z5 = self.block5_bn(z5)
z5 = self.block5_act(z5)
z5_dropout = self.block5_dropout(z5)
return z1, z2, z3, z4_dropout, z5_dropout
2-4)Decoderの定義
U-NetのDecoderの特徴は下記の通りです。
- 2X2 convolution (up-convolution)を使う
- feature channelは半分で 減らして使用する
- EncoderでMax-Poolingする前のfeature mapをCropして、Up-Convolutionする時concatenationする
- 3X3 convolutionを二回反復して行う
- 活性化関数でReLUを使う
- 最後のレイヤーでは 1X1 convolutionを使って2個のクラスで分類する
これらの特徴を元に実装して行くとこのようになります。
class Decoder(Model):
def __init__(self, config):
super().__init__()
# Network
self.block6_up = tf.keras.layers.UpSampling2D(size = (2,2))
# 2X2 convolution (up-convolution)を使います。
self.block6_conv1 = tf.keras.layers.Conv2D(512, (2, 2) , name='block6_conv1', activation = 'relu', padding = 'same')
# 3X3 convolutionを二回反復して行います。
self.block6_conv2 = tf.keras.layers.Conv2D(512, (3, 3) , name='block6_conv2', activation = 'relu', padding = 'same')
self.block6_conv3 = tf.keras.layers.Conv2D(512, (3, 3) , name='block6_conv3', padding = 'same')
self.block6_bn = tf.keras.layers.BatchNormalization()
# 活性化関数でReLUを使います。
self.block6_act = tf.keras.layers.ReLU()
self.block7_up = tf.keras.layers.UpSampling2D(size = (2,2))
# feature channelは前の層より半分で 減らして使用します。
self.block7_conv1 = tf.keras.layers.Conv2D(256, (2, 2) , name='block7_conv1', activation = 'relu', padding = 'same')
self.block7_conv2 = tf.keras.layers.Conv2D(256, (3, 3) , name='block7_conv2', activation = 'relu', padding = 'same')
self.block7_conv3 = tf.keras.layers.Conv2D(256, (3, 3) , name='block7_conv3', padding = 'same')
self.block7_bn = tf.keras.layers.BatchNormalization()
self.block7_act = tf.keras.layers.ReLU()
self.block8_up = tf.keras.layers.UpSampling2D(size = (2,2))
self.block8_conv1 = tf.keras.layers.Conv2D(128, (2, 2) , name='block8_conv1', activation = 'relu', padding = 'same')
self.block8_conv2 = tf.keras.layers.Conv2D(128, (3, 3) , name='block8_conv2', activation = 'relu', padding = 'same')
self.block8_conv3 = tf.keras.layers.Conv2D(128, (3, 3) , name='block8_conv3', padding = 'same')
self.block8_bn = tf.keras.layers.BatchNormalization()
self.block8_act = tf.keras.layers.ReLU()
self.block9_up = tf.keras.layers.UpSampling2D(size = (2,2))
self.block9_conv1 = tf.keras.layers.Conv2D(64, (2, 2) , name='block9_conv1', activation = 'relu', padding = 'same')
self.block9_conv2 = tf.keras.layers.Conv2D(64, (3, 3) , name='block9_conv2', activation = 'relu', padding = 'same')
self.block9_conv3 = tf.keras.layers.Conv2D(64, (3, 3) , name='block9_conv3', padding = 'same')
self.block9_bn = tf.keras.layers.BatchNormalization()
self.block9_act = tf.keras.layers.ReLU()
# 最後のレイヤーでは 1X1 convolutionを使って2個のクラスで分類します。
self.output_conv = tf.keras.layers.Conv2D(config.model.num_class, (1, 1), name='output_conv', activation = 'sigmoid')
def call(self, z1, z2, z3, z4_dropout, z5_dropout):
z6_up = self.block6_up(z5_dropout)
z6 = self.block6_conv1(z6_up)
# EncoderでMax-Poolingする前のfeature mapをCropして、Up-Convolutionする時concatenationします。
z6 = tf.keras.layers.concatenate([z4_dropout,z6], axis = 3)
z6 = self.block6_conv2(z6)
z6 = self.block6_conv3(z6)
z6 = self.block6_bn(z6)
z6 = self.block6_act(z6)
z7_up = self.block7_up(z6)
z7 = self.block7_conv1(z7_up)
z7 = tf.keras.layers.concatenate([z3, z7], axis = 3)
z7 = self.block7_conv2(z7)
z7 = self.block7_conv3(z7)
z7 = self.block7_bn(z7)
z7 = self.block7_act(z7)
z8_up = self.block8_up(z7)
z8 = self.block8_conv1(z8_up)
z8 = tf.keras.layers.concatenate([z2, z8], axis = 3)
z8 = self.block8_conv2(z8)
z8 = self.block8_conv3(z8)
z8 = self.block8_bn(z8)
z8 = self.block8_act(z8)
z9_up = self.block9_up(z8)
z9 = self.block9_conv1(z9_up)
z9 = tf.keras.layers.concatenate([z1, z9], axis = 3)
z9 = self.block9_conv2(z9)
z9 = self.block9_conv3(z9)
z9 = self.block9_bn(z9)
z9 = self.block9_act(z9)
y = self.output_conv(z9)
return y
3. まとめ
U-netの説明からU-netの実装まで一つの記事でまとめてみました。
特徴マップのサイズやチャンネル数の把握で混乱しましたが、前の層の構成を反復する典型的なConvolution networkの為、すぐに慣れる事ができました。
誤り等ありましたら、ご指摘ください。