画像の領域検出(セグメンテーション)によくコンペなどで使われるU-Netですが、オートエンコーダー(AE:Auto Encoder)としての側面もあります。今回はU-NetをAEの側面から見て、自己符号化や白黒画像のカラー化といったAEっぽいことをしてみます1。なぜU-Netが強いのかより理解できることを期待します。
全体コード:https://gist.github.com/koshian2/6bcfb03dbc187024da9e86b24c44a5b3
TL;DR
- U-Netが強いのはEncoderとDecoderとの間に「Contracting path(スキップコネクション)」があるから。この効果はResNetと似ている
- U-NetはAEの亜種なので、AEでできることは大抵できそう。AEの一種として捉えるとより理解できそう。
- その応用として、白黒画像のカラー化とかもU-Netをやってみた
オートエンコーダーって何だ?
ざっくりとしたAEの説明をするので、なにか知っている方は飛ばしてください。
画像はKerasの公式ブログからです。
AEにもいくつか種類がありますが、基本的なAEでは、画像なら出力画像が入力画像が等しくなるように訓練を行います。EncoderとDecoderは多層パーセプトロンでもCNNでもいいですが、CNNならEncoderは分類問題で使うような普通のCNN(AlexNetやVGGなど)、Decoderをそれを逆に辿ったようなCNNを作ります。より正確に言えば、Encoderはダウンサンプリングで、Decoderはアップサンプリングです。
「入力画像と出力画像が等しくなるように訓練して何が美味しいんだ?電気代の無駄じゃないか」と思うかもしれませんが、ポイントは中間層の表現、つまり次元削減です。今回はやりませんが、AEの中間層は次元が圧縮された状態になっているので、画像ごとの特徴量をいい感じに取り出せるというわけです。例えば、中間層の値を取り出してk-Meansで分類したら教師なし学習の分類問題ができるわけです。
「次元圧縮ならPCA(主成分分析)やカーネルPCA、t-SNEでいいじゃないか?」と思うかもしれませんが、こちらはニューラルネットワークなので非線形な次元削減がやりたい放題できます。t-SNEは高速に計算できる次元の制約があって任意の次元に使いづらいとかデメリットがあったりするんですよね。
AEの効果は次元圧縮だけではなく、AEの一種としてVAE(Variational Auto Encoder)というのがあります。今回はVAEの記事ではないので、ざっくりだけですが、中間層で乱数を発生させて画像を無限に生成できる、つまり生成モデルとしての使い道もあります。現在はこういうのはGANの天下で、AEは正直日陰者という感は否めませんが、GANの中でAEが使われているケース(例:BEGAN)も結構あるので、AEを知ると結構いろんなものが見えてきたりします。
U-Netの構造
U-Netの論文より。
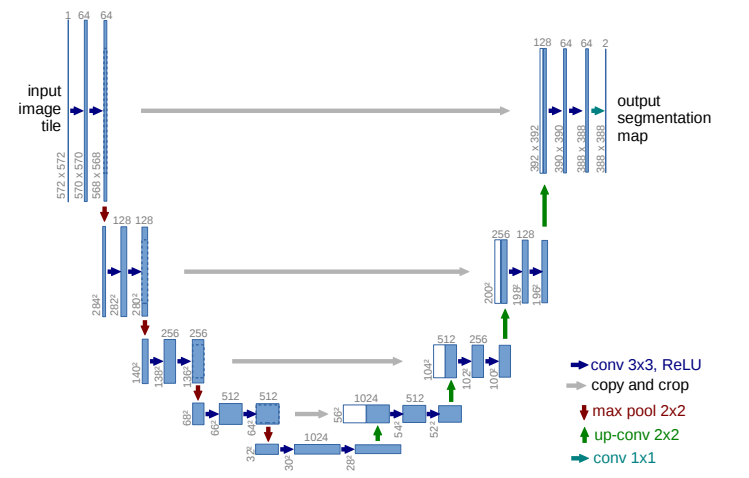
このように「U字のネットワーク」になっているからU-Netと呼ばれます。難しそうに見えますが、普通のCNNが作れれば同じ要領で作れます。ポイントは、「画像を入力して、画像を出力している」ということです。
普段セグメンテーションとして使うときは入力画像と出力画像は異なりますが、もし**入力画像と出力画像を同じように訓練したら、AEのように見えてきませんか?**こんだけ深いネットワーク(後で確認しますがU-Netはかなり計算量多いです)を通って入力画像と出力画像が同じになるって不思議だと思いませんか?
言葉の定義なので、人によって呼び方は異なるかもしれませんが、U-Netのように入力画像と出力画像が異なるケースではAEと呼ばずに「Encoder-Decoderモデル」と呼ぶほうが一般的かもしれません。ただ、この場合でもUの左側をEncoder,右側をDecoderと呼ぶのは変わりないので、AEのEncoder-Decoderとほとんど同じように見てもいいと思います。
しかし、U-Netが一般的なAEと大きく異なる点2は、EncoderとDecoderの間にはしごのように配線があるということです。論文ではこれを「Contracting path」と読んでいます。これがU-Netの大きなポイントです。さて配線といえば、画像分類の「ResNet」のスキップコネクションを思い出します。画像はResNetの論文からです。
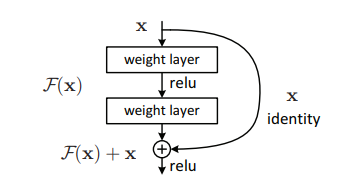
ResNetはDecoderのないシンプルなCNNですが、レイヤーの間にこのような配線(スキップコネクション)を追加することで、勾配消失に強いという特徴があり、このようなスキップコネクションはもはやCNNのデファクトスタンダードとなっています。詳しくは自分が書いたRes-Netsの有効性をCIFAR-10で確認するや、shinmuraさんが書いた畳込みニューラルネットワークの基本技術を比較する ーResnetを題材にーなど結構いろいろあるので、興味があったらぜひ読んでみてください。
ResNetのスキップコネクションと、U-NetのContracting Pathの発想はほとんど同じで、大きな違いはEncoderとDecoderの間に張るということだけです。もっと深いモデルになったらスキップコネクションとContracting Pathの両方を入れるのも全然ありだと思います。オリジナルの実装ではEncoderとDecoderの解像度が違ったりしますが、今回もっと簡略化して同一サイズにするので解像度は同じ(Identity mapping)となります。なので、もうほとんどResNetのスキップコネクションです。
今回は実験の流れは次の通りです。
- 入力画像と出力画像を同一になるように(自己符号化)訓練して、U-NetがAEの側面を持っていることを確認する。そしてContracting Pathの存在により、出力画像がより高画質になることを確認する。
- 入力画像をモノクロ、出力画像をカラーで訓練して、U-Netを使った白黒画像のカラー化を実装してみる。同様にContracting Pathの効果を確認する。
U-NetのKerasの実装
今回はSTL-10を使うので、入力画像も出力画像も96×96サイズにしました。後の白黒画像のカラー化でも使うので、入力がモノクロ(1チャンネル)の場合も定義しています。
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, Input, Concatenate, MaxPool2D, Conv2DTranspose, Add
from tensorflow.keras.models import Model
def create_block(input, chs):
x = input
for i in range(2):
x = Conv2D(chs, 3, padding="same")(x) # オリジナルはpaddingなしだがサイズの調整が面倒なのでPaddingを入れる
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
def create_unet(use_skip_connections, grayscale_inputs=False):
if grayscale_inputs:
input = Input((96,96,1))
else:
input = Input((96,96,3))
# Encoder
block1 = create_block(input, 64)
x = MaxPool2D(2)(block1)
block2 = create_block(x, 128)
x = MaxPool2D(2)(block2)
block3 = create_block(x, 256)
x = MaxPool2D(2)(block3)
block4 = create_block(x, 512)
# Middle
x = MaxPool2D(2)(block4)
x = create_block(x, 1024)
# Decoder
x = Conv2DTranspose(512, kernel_size=2, strides=2)(x) # TPUだとUpsamplingやK.resize_imageが使えない
if use_skip_connections: x = Concatenate()([block4, x])
x = create_block(x, 512)
x = Conv2DTranspose(256, kernel_size=2, strides=2)(x)
if use_skip_connections: x = Concatenate()([block3, x])
x = create_block(x, 256)
x = Conv2DTranspose(128, kernel_size=2, strides=2)(x)
if use_skip_connections: x = Concatenate()([block2, x])
x = create_block(x, 128)
x = Conv2DTranspose(64, kernel_size=2, strides=2)(x)
if use_skip_connections: x = Concatenate()([block1, x])
x = create_block(x, 64)
# output
x = Conv2D(3, 1)(x)
x = Activation("sigmoid")(x)
return Model(input, x)
意外と単純です。今回特に変えた点は以下のとおりです。
- same paddingを入れる(githubを見ると入れている実装も多い)。Contracting PathのAddが同一サイズでないといけないので、paddingを入れるとサイズ調整がやりやすい
- ConvTranspose2Dは格子模様ができやすく、Upsampling2D→Convのほうが品質はいいらしいが、TPUでUpsampling2Dを使おうとするとエラーが出たので、ConvTranspose2Dにした。kernel_size=stridesとする。
パラメーター数は以下の通りです。これはカラー化+Contraciting pathありの例です。
Total params: 31,054,275
Trainable params: 31,042,499
Non-trainable params: 11,776
パラメーター数31Mなので若干多めではないかと思います(Contacting pathなしだと28Mぐらいになります)。エンコーダーだけのResNet50が25.6MなのでResNet以上の計算量はあります。
訓練条件
STL-10とはCIFAR-10に似ているものの、96×96の高画質の画像データセット。全てがラベル付されているわけではなく、訓練データの5000枚とテストデータの8000枚はラベル済み、10万枚の未ラベルの画像があります。これを使います3。

Adam Coates, Honglak Lee, Andrew Y. Ng An Analysis of Single Layer Networks in Unsupervised Feature Learning AISTATS, 2011. (PDF)
- 学習率は1e-3,係数0.9のモメンタムオプティマイザー。バッチサイズは2564。
- ColabのTPUで訓練&推論
- 損失関数はピクセル間のMean squared error(平均2乗誤差)をとり、axis=1,2で和を取る(以下のコード参照)
- 自己符号化では、訓練データ+テストデータの13000枚で訓練。200エポック。
- 自己符号化では、エポックの終わりに固定で選んだ100枚を推論させ、訓練の進みを可視化する。
- 白黒画像のカラー化では、未ラベルの10万枚で訓練。100エポック。
- 白黒画像のカラー化では、以前の猫のランドマーク検出で使った、Cats datasetから、アスペクト比が1のものを100枚選んでカラー化のテストとした。これをエポックの終わりに推論させ、訓練の進みを可視化する。
- 猫画像のモノクロ化は以下のコード。今、コピーした猫画像が「copy_cat」というフォルダにあるものとする。「cats_images.npz」というファイルにパッキングして、Google Driveにあげておく。
from keras.objectives import mean_squared_error
def loss_function(y_true, y_pred):
mses = mean_squared_error(y_true, y_pred)
return K.sum(mses, axis=(1,2))
from PIL import Image
import glob
import numpy as np
def pack_data():
color = np.zeros((128, 96, 96, 3), dtype=np.uint8)
gray = np.zeros((128, 96, 96, 1), dtype=np.uint8)
for i, f in enumerate(glob.glob("copy_cat/*.jpg")):
with Image.open(f) as img:
img_resize = img.resize((96, 96), Image.LANCZOS)
img_color = np.asarray(img_resize.convert("RGB"), dtype=np.uint8)
img_gray = np.asarray(img_resize.convert("L"), dtype=np.uint8)
color[i,:,:,:] = img_color
gray[i,:,:,:] = np.expand_dims(img_gray, -1)
np.savez_compressed("cats_images", color=color, gray=gray)
全体コード:https://gist.github.com/koshian2/6bcfb03dbc187024da9e86b24c44a5b3
結果:自己符号化(入力画像=出力画像)
まずは入力画像=出力画像として訓練し、自己符号化を試してみます。
Contracting Pathなしの場合
訓練経過
1エポック目

白黒の点
10エポック目

輪郭ができてくる
20エポック目

大まかに色が付き始める
30エポック目

色の差が出てくる
50エポック目

かなりいい感じ
200エポック目

50エポック目よりかは鮮明になってる
Ground Truth

よくできているけど、200エポック目でも若干くすんでいる?
Contracting Pathありの場合
訓練経過
1エポック目

いきなり色が付き始めてる。訓練が速い
10エポック目

若干色調がセピアじみてるけど、もう相当いい
20エポック目

Contracting pathなしの200エポックぐらいと見分けがつかない
200エポック目

くっそ鮮やか
Ground Truth(再掲)
もはや本物と見分けがつかない。GANなしでここまでいけるのはかなりすごい。
損失推移
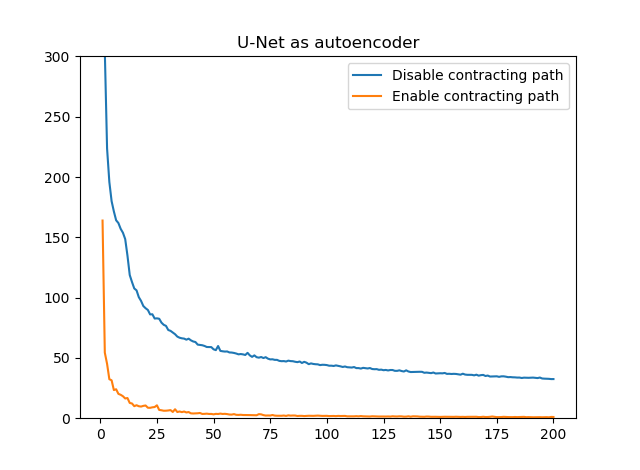
差を見れば歴然。Contracting pathが圧倒的に効いてる。学習がものすごく加速しているのがわかります。
自己符号化まとめ
- U-NetのEncoderとDecoderのスキップコネクション、つまりContracting pathは非常に強力で、学習を加速させるのを確認できた
- U-NetをAutoEncoder(自己符号化)として使うこともできるが、Contracting pathによりGANなしで本物と見分けのつかないレベルの高画質出力ができている
結果:白黒画像のカラー化
でも「これって一番上のContracting Pathが効いてるだけで実質的に画像コピーしてるだけじゃん」というツッコミもきそうなので、応用例として、入力に白黒画像を与え、出力でカラー画像を推定してみます。色の情報は入力では存在しないので当然コピーでは作れません。
白黒画像の色付けの研究としては、例えば早稲田大学の方がやった『ディープネットワークを用いた大域特徴と局所特徴の学習による白黒写真の自動色付け』というのがあります。画像はプロジェクトのHPからです。
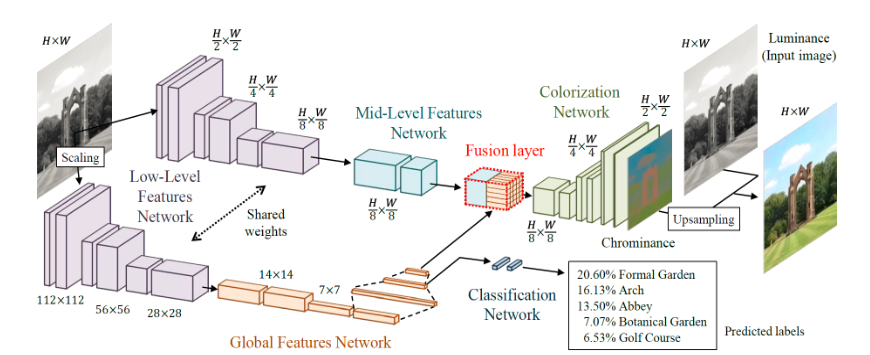
これは分類問題の特徴量を使ってカラー画像の品質を上げるという高度なことをやっていますが、基本的にはEncoder-Decoderモデルです。AEとはかなり異なるかもしれませんが、分類問題の特徴量を使わないように単純化するとAEに近く、U-Netでも同じことはできます。それをやっていきましょう。
これからやるのは、「入力画像にグレー画像を入れ、色を復元したカラー画像を出力として取り出す」ネットワークです。これにより、白黒画像を自動的にカラー化するモデルが出来上がります。実装するだけなら結構簡単で、先程の自己符号化のU-Netの入力のチャンネル数を3から1に変更するだけです。
オリジナルの画像はカラーですが、グレー画像にする際は以下の計算で求めています。luma符号化の式を使いました。
def numpy_to_grayscale(tensor):
# Y = 0.299 R + 0.587 G + 0.114 B
return np.expand_dims(tensor[:,:,:,0]*0.299 + tensor[:,:,:,1]*0.587 + tensor[:,:,:,2]*0.114, axis=-1)
STLの未ラベル10万枚で訓練させ、白黒の猫画像を入力に入れ、カラー化してみます。
入力画像

このグレー画像を自動でカラー化してみます
もとの画像カラー版(Ground Truth)

白黒化前のカラー画像です。この猫画像のカラー情報はネットワークには一切与えません。
Contracting pathなしのカラー化

出てきた画像はオリジナルとはだいぶ違いますがそれっぽく着色されているのがわかります。でも鮮やかさはだいぶ落ちますね。
Contracting pathありのカラー化

鮮明さはContracting pathなしよりはマシになったものの、U-Netをもってしても自動カラー化は若干難しいようです。全般的に猫の種類が少なくなってしまいましたよね。より鮮やかな出力にするにはもうちょっと工夫してあげる必要があります。
エラー推移
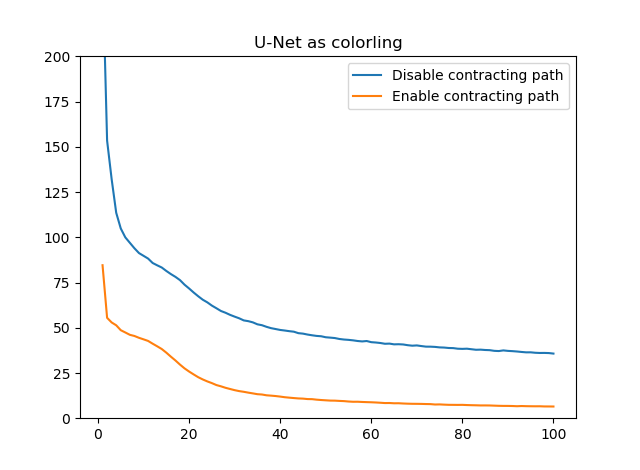
Contracting pathありのほうがずっといいことには変わりないものの、自己符号化よりかは白黒画像のカラー化のほうが、難しいタスクであるということが確認できました。ただ、白黒画像のカラー化もU-Netを使えばそれっぽくできるということを確認できたのは有意義だと思います。
まとめ
- U-Netの強さの秘密は、Contracting PathというEncoderとDecoderの間のスキップコネクション。これにより学習を非常に加速させている。原理はResNetのスキップコネクションとだいたい同じで勾配消失に強い。
- U-NetはAEの亜種とも言われるように、AEでできることは結構できる。自己符号化だけではなく、白黒画像のカラー化もできた。
- 鮮明なカラー化をするにはいろいろ工夫が必要
ということでした。U-Netって簡単にできて楽しいですね。
追加検証:U-Netの自己符号化について
コメントで「U-Netを自己符号化として使うのはあまり意味がないのではないか」という指摘を頂いたので追加検証してみました。
今次の2点の疑問があります。
- Contracting Path(Skip Connection)があると、恒等写像のパスに情報が流れてしまうから、中間層のほうに情報が集積されなくて、特徴量抽出に悪影響が出るのではないか
- AutoEncoderはBottleneckがあると特徴量を抽出できているから、U-NetでもBottleneckを作れば特徴量を抽出できるのではないか
つまり、「Contacting Path」の条件の有無と、「Bottleneck」の条件の有無の計4条件について考えればいいというわけです。
これをMNISTで実験します。はじめCIFARでやってみたらクラスタリングがしょぼすぎてバラバラになってしまったのでMNISTにしました。
どうやって計測する?
「特徴量をうまく抽出する」というはかなり漠然とした概念ですが、これを数値問題に落とし込みます。ここでは中間層の値を取ってきてk-Meansをかけてどのくらいクラスタリングがうまくいくかで考えます。
具体的にはクラスタごとの**純度(purity)**を計測します。純度の計算方法は、スタンフォード大学を参考にしました。この記事は単純平均ですが、クラスタ別のサンプル数が不定なので加重平均の形に落とし込みます。
Ground Truthのラベルの数と、クラスタリングのクラスタ数が同じであるとしましょう。MNISTだったら0~9までの数字なので、どちらも「10」となります。$N$個のサンプルに対して、$1\leq i\leq N$である$X^{(i)}$であるとします。クラスタの数は$K=10$なので、$X^{(i)}$に対応するGround Truthなラベルを$y^{(i)}$、クラスタリングによって割り当てられたクラスを$c^{(i)}$とすると、$0\leq y^{(i)}, c^{(i)}\leq K-1=9$となります。
次に混同行列のような形で$c^{(i)}, y^{(i)}$のサンプル数をK×Kの行列で集計します。混同行列と異なるのは、クラスタリングにおいて1番目のクラスタが「0」という数字を示すという保証がない点です。次のような擬似コードで計算できます。
import numpy as np
matrix = np.zeros((K, K))
for i in range(N):
ground_truth_label = y[i]
cluster_label = c[i]
#行にクラスタ、列にground truthのラベルをとるものとする
matrix[cluster_label, ground_truth_label] += 1
「クラスタ別純度」はこのmatrixを行単位で純度を求めたものです。そしてそのクラスタ別純度を、クラスタごとのサンプル数で加重平均(サンプル数の割合での加重和)を取ったものを「全体の純度」とします。
# クラスタ別純度
cluster_purity = np.max(matrix, axis=-1) / np.sum(matrix, axis=-1)
# 全体に集約する際は、サンプル数の加重平均を取る
weights = np.sum(matrix, axis=-1) / np.sum(matrix)
total_purity = np.sum(row_purity * weights)
直感的な理解では教師あり学習の「精度」と似て非なるものと思えば良いと思います。なぜなら、そのクラスタ内で最大サンプル数のGround Truthのラベルを、そのクラスタのラベルとすれば、クラスタ別純度はそのクラスタにおけるGround Truthのラベルが与えられたときの二値分類の精度となるからです。
全体の純度が1に近いほど、混ざり物のない良いクラスタリング、逆に0に近いほど混ざり物だらけでクラスタリングが意味をなしていないという解釈ができます。
実験の流れ
以下の2つの流れで行います。
- 入力画像=出力画像となるように、AutoeEcoder/U-Netを訓練させる
- 中間層から潜在的な特徴量を取り、k-Meansにかける
- k-Meansのクラスタリングの結果と、Ground Truthなラベルを比較し全体の純度を求める
コードは以下にあります。訓練は各条件1回のみ行い、特徴量を抽出します。
AutoEncoderの訓練と特徴量抽出 : https://gist.github.com/koshian2/1825e5d0f3e5b05dbb612f84ff394045
k-Meansのクラスタリング : https://gist.github.com/koshian2/9075d991c291caf1b2a45b0c3c416c7e
k-Meansは初期の乱数設定により同一のクラスタリングになる保証がないので、同一の特徴量に対してシードを変えて10回やって、全体の純度はその平均を取って比較をします。
U-Netの改造
訓練時間を減らすのと、中間層の値を減らすため大幅にU-Netのチャンネル数を減らしました(中間層のチャンネル数を1024→16)。これでもBottleneckがない場合は、中間層の値は「7×7×16=784」個あり、もとのMNISTの次元の何ら変わらない(=次元削減になっていない)です。この点から考えると、U-Netは次元削減に向いていないというのは確かにそれはそうだよねと言えるのではないでしょうか。
Bottleneckありの場合は、Flatten()で全結合化し、16個の隠れユニットのボトルネックを作り、また784次元に戻します。また、潜在的な特徴量を取る層の活性化関数はスケーリングのためtanhとしました。これは4条件にかかわらずこうしています。モデルの生成コードは以下のようになります。
def create_block(input, chs, latent_flag=False):
x = input
for i in range(2):
x = Conv2D(chs, 3, padding="same")(x)
x = BatchNormalization()(x)
if i == 1 and latent_flag:
x = Activation("tanh", name="latent_features")(x)
else:
x = Activation("relu")(x)
return x
def create_unet(use_skip_connections, bottle_neck=False):
input = Input((28, 28, 1))
# Encoder
block1 = create_block(input, 4)
x = MaxPool2D(2)(block1)
block2 = create_block(x, 8)
x = MaxPool2D(2)(block2)
# Middle
if not bottle_neck:
x = create_block(x, 16, True)
else:
x = create_block(x, 16)
x = Flatten()(x)
x = Dense(16, activation="tanh", name="latent_features")(x)
x = Dense(784, activation="relu")(x)
x = Reshape((7, 7, 16))(x)
# Decoder
x = Conv2DTranspose(8, kernel_size=2, strides=2)(x)
if use_skip_connections: x = Concatenate()([block2, x])
x = create_block(x, 8)
x = Conv2DTranspose(4, kernel_size=2, strides=2)(x)
if use_skip_connections: x = Concatenate()([block1, x])
x = create_block(x, 4)
# output
x = Conv2D(1, 1)(x)
x = Activation("sigmoid")(x)
return Model(input, x)
ちなみに次元削減において、「ならBottleneck入れずに、訓練した『7×7×16』のレイヤーの出力を後でGlobal Average Poolingとればいいんじゃないの?」と思うかもしれませんが、後付けでGlobal Average Poolingを入れたらFlattenと比べて全体の純度が2~3割落ちたので使うのをやめました。『7×7×16』の出力をk-Meansに落とし込むときはFlattenを使います。
したがって、ボトルネックありの場合は16次元のk-Means、ボトルネックなしの場合は784次元のk-Meansとなります。
損失推移
これはAuto Encoderとして訓練したときのReconstruction Lossの推移です。
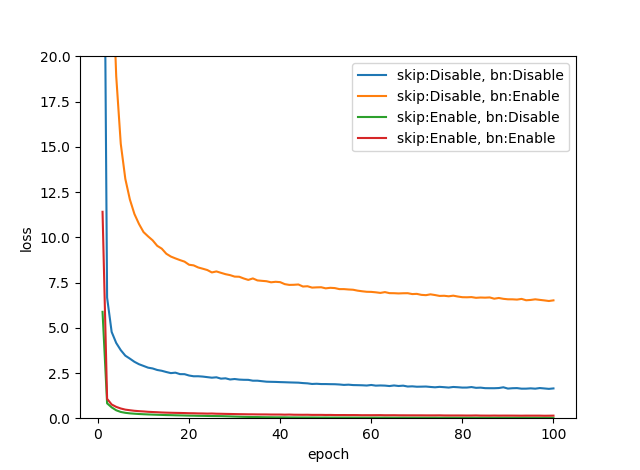
Contracting pathを入れなかったときは、Bottleneckがあるとえらい損失が高めに推移しています。逆にContracting pathがある場合は、Bottleneckの有無にかかわらず損失は低めに推移しています。
純度結果
各条件の同一の特徴量に対して10回k-Meansを行ったときの、条件別の全体の純度の結果です。また、同時にオリジナルのMNISTについてもそのままk-Meansを行っています。
| Contracting Path | Bottleneck | 純度平均 | 純度標準偏差 | 特徴量次元 |
|---|---|---|---|---|
| ☓ | ☓ | 0.5123 | 0.0005 | 784 |
| ☓ | ○ | 0.6998 | 0.0001 | 16 |
| ○ | ☓ | 0.5217 | 0.0001 | 784 |
| ○ | ○ | 0.3752 | 0.0001 | 16 |
| オリジナル | MNIST | 0.5900 | 0.0023 | 784 |
オリジナルのMNISTの純度が59%なので、これより高ければ特徴量がより理想的な状態にマッピングされていると考えることができます。確かに、Contacting Pathなし、ボトルネックありの場合(これは一般的なボトルネックのあるAutoEncoderに相当します)では純度が70%まで上がっているので、確かに特徴量抽出が有効に機能していると言えます。これはご指摘のとおりでした。
しかし、Contracting pathなし、つまり完全にAuto Encoderのような場合でも、ボトルネックを外すと純度はオリジナルのMNISTより下がります。つまり、Contracting pathなしの場合は、Encoder-Decoderの構造そのものではなく、次元をギュッと落とすようなボトルネックが特徴量抽出として機能しているということが確認できます。
しかし、その一方で、U-netの大きな特徴であるContracting pathを入れると、ボトルネックがないケースでは、Contracting pathがないケースよりも純度がわずかに上がるということも同時に確認できます。つまり、Skip connectionを入れようとも、その特徴量のマッピングが有効に機能しているかどうかは別として、Auto Encoder(Skip connection)のとき比べて特徴量の抽出が必ず悪くなるということは確認できませんでした。
これまでの話を総合すると『「AutoEncoderではボトルネックが特徴量抽出に機能している」「Contracting pathを入れてもその機能は損なうことない」→じゃあどっちも入れれば上位互換では?』という発想ができます。つまり、U-Netにボトルネック構造を入れてしまおうということです。これが最後のケースになりますが、これは予想に反して全く機能しませんでした。Reconstruction Lossは下がってはいるものの、特徴量抽出としての機能は最も悪い結果となりました。これの解釈はとても難しいですが、ご指摘のあった通り、情報がContracting Pathのほうで流れていってしまったから中間層のほうのマッピングがうまくいっていないのかもしれません。
まとめ
これまでの内容をまとめましょう。この問題の疑問に答えます。
- Q:「Contracting pathがあると特徴量抽出がうまくいかないのではないか?」→A:今回は確認できなかったが絶対とは言えない。ボトルネックを入れないU-Netを使ったところそれは確認できなかった。しかし、U-Netにボトルネックを入れると明らかに悪くなるので、もしかしたらそういうこともあるのかもしれない。
- Q:「ボトルネックを入れたら特徴量抽出がうまくいくか?」→A:なんともいえない。AutoEncoderでは明らかにうまくいくが、U-Netにボトルネックを入れると明らかに悪くなる。
ただし、コメントでご指摘のあったことも6~7割ぐらい当たっていて、そこは@msrksさんの見識に素直に感服するばかりです。もう少しご指摘の内容を噛み砕いてみます。
- AutoEncoderはBottleneckを作ってそこで特徴抽出させる→正しいし、これはうまくいくのを確認できた
- Bottleneck以外のSkipConnectionのパスを使って情報伝達できちゃうので、reconstruction lossが下がるのは当たり前→これもごもっともだし、ボトルネックの有無にかかわらず、SkipConnectionがあれば損失が下がっているのを確認できた
- U-NetをAutoEncoder(自己符号化)として使うのはあんまり意味がない→これは賛否両論あるのではないか。ボトルネックを入れないAutoEncoderをわずかに上回るぐらいの純度はU-Netでも出せる。少なくとも自分は、U-Netを特徴量抽出の選択肢に入れるのはありだと思う。
そもそもラベルを与えない状態での純度(精度)があまり高くないので、Ground Truthのラベルに直結するような特徴量がほしければ、AutoEncoderではなく分類問題として訓練させたモデルの特徴量を使ったほうが明らかに精度高いし、教師あり学習や半教師あり学習のようなアプローチで学習させたほうが効率がいいのではないか。
ただし向いていないとするなら、あんまり次元削減の効果がないという点ではそれはそう。今回みたいにk-Meansではなく別のCNNにくっつけるとかだったらありかもしれない。
以上です。はっきりとしない結果となってしまいましたがこれでよろしかったでしょうか。
追記:強い人からのコメントがきた
このようなツイートを見つけました。ディープラーニングの研究者の方です。
AutoEncoderはあくまで潜在空間の取得が目的で、(エンコーダーで得られる)高次の特徴をアップサンプリング+Skip-connectionで解像度を上げていくU-Netとは目的が違うような… / “オートエンコーダーとして…” https://t.co/3Fvrx8E9G6
— Yusuke Uchida (@yu4u) November 12, 2018
AutoEncoderがあくまで潜在空間の取得が目的、とのことですが、潜在空間の取得と高次の特徴をアップサンプリングしていくのにどのような違いがあるのでしょうか。そしてAEらしい目的とは何でしょうか。自分が知らないことをまだまだご存知だと思われるので、お時間に余裕があればぜひコメント欄でご教示いただければ幸いです(この方もQiitaやっているそうです)。
ちなみにこの方が最近投稿した『畳み込みニューラルネットワークに関するサーベイ論文』は素晴らしい内容なのでぜひ読むべきです。
-
白黒画像のカラー化はAEっぽくないとかいわないで ↩
-
配線芸自体が、ResNet以降別にそこまで珍しいアイディアではなくなったので、Encoder-Decoderの間に配線を入れたのをAEと呼ぶ人がいてもおかしくはないと思います。ただしこれはVAEで使えないはずです。なぜなら乱数から生成するときにEncoder側のContracting pathの値を取る方法がないので(どうやるのかご存知の方はぜひ教えてください)。 ↩
-
STL-10はPyTorchだとTorchvisionで簡単に扱えますが、Kerasではデフォルトで用意してくれないので自分でローダーを書きます。詳しくはこちらに書きました。 https://blog.shikoan.com/keras-stl10/ ↩
-
HBMメモリ制約がきつくてバッチサイズをあまり大きくできなかった ↩