watsonx Orchestrateのknowledge-baseとしてAstra DBのサポートが追加されました
Datastax Astra DBはベクトル検索をサポートしているApache CassandraベースのNOSQL DBです。今回、watsonx Orchestrateのknowledge-base(いわゆるRAG的な機能)として利用することが可能になりました。Astra DBの無料アカウントを用いて、実際に構成してみたいと思います。
Astra DBの構成
まず、DBおよび、Collectionを作成します。デフォルトではNVIDIAのEmbedding modelが利用可能ですが、英語のみの対応となるようです。

embedding provider integrationを設定することで外部のプロバイダーと連携できるようですが、残念ながらwatsonx.aiは含まれなかったため、英語前提で進めます。(watsonx.aiを使用する方法は後述します)

データのロード
画面からデータのロードが出来るようなので、ロードします。今回はIBMのAnnualReportをインポートしてみます。
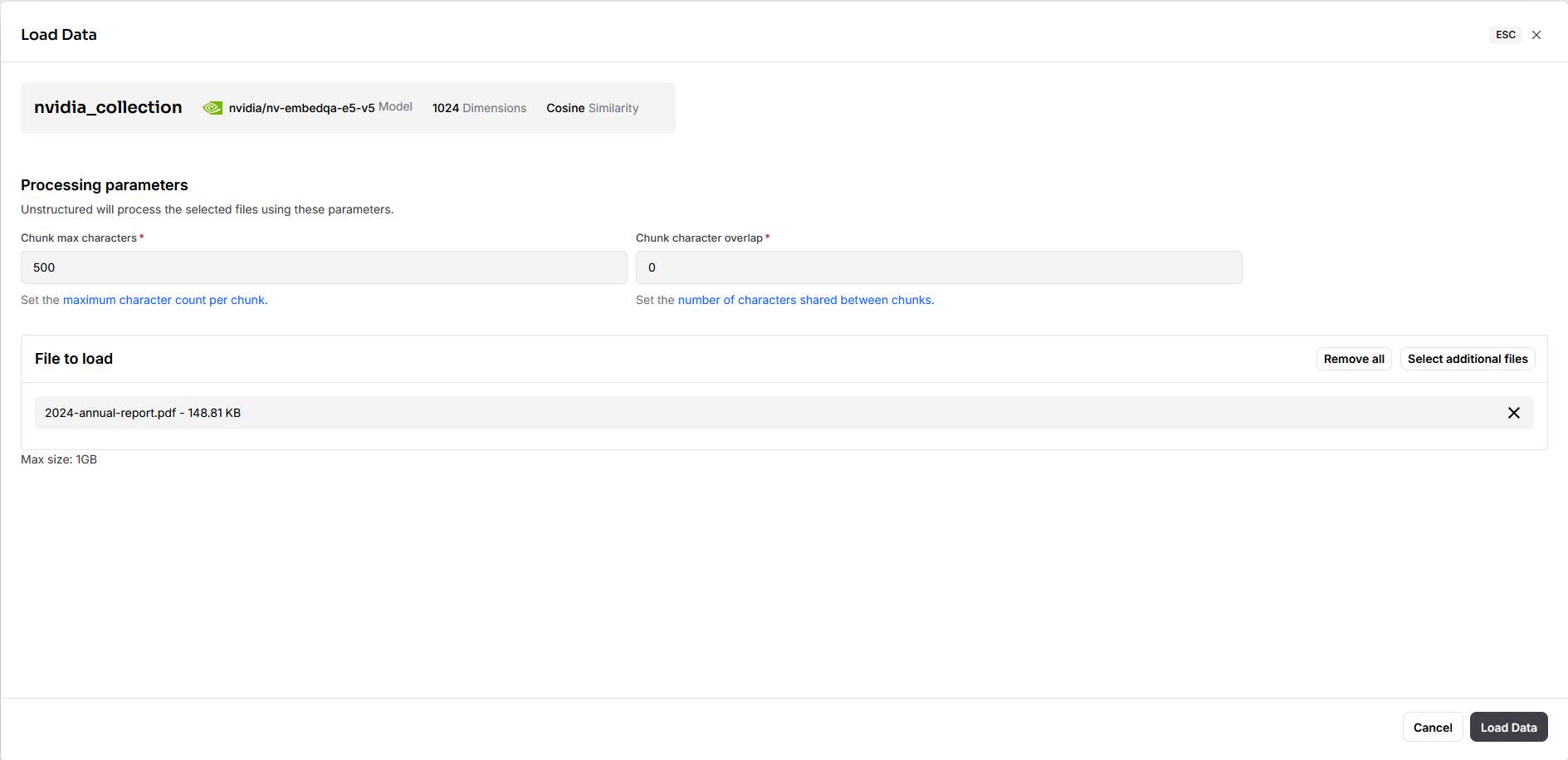
以下の様に、ロードされました。

watsonx Orchestrate側の構成
watsonx Orchestrate側はAgentBuilderのナレッジソースとしてAstra DBを選択することが可能です。
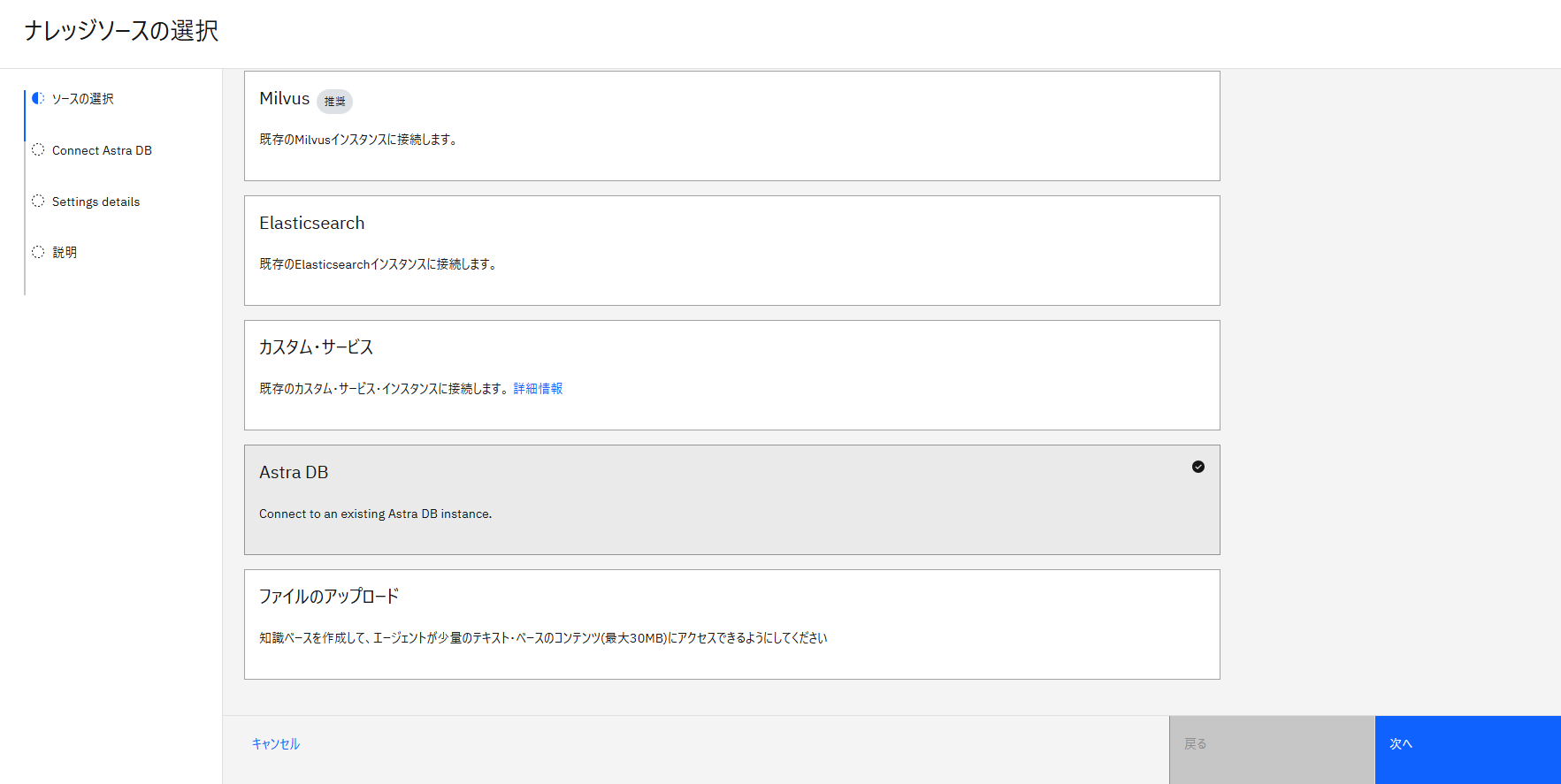
接続情報を入力します。
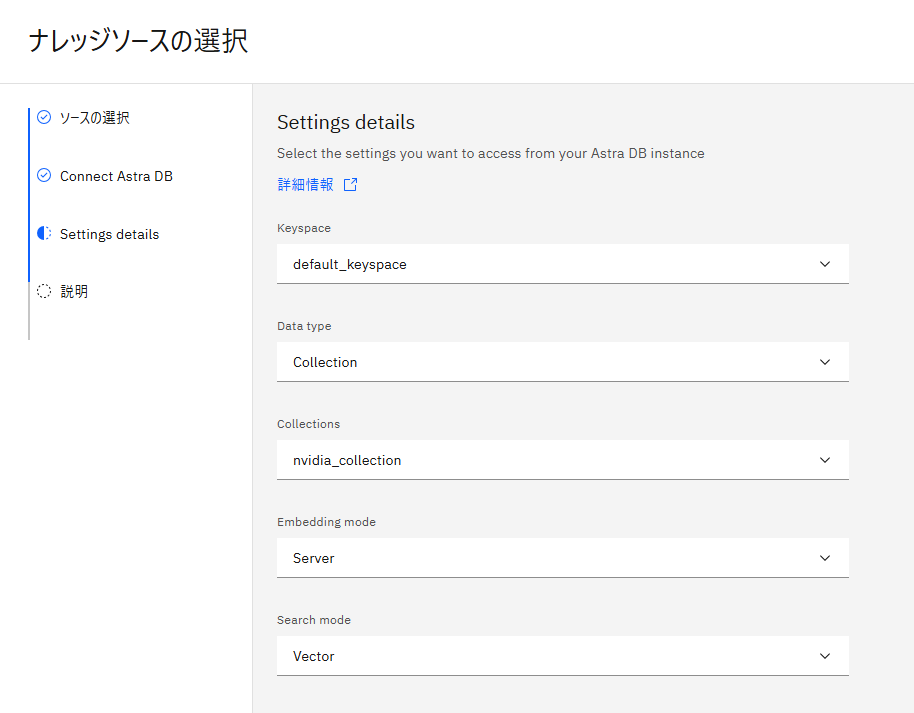
正しく接続できると以下の様に、詳細設定画面が表示されるので、先ほど作成したCollectionを選択します。今回はAstra DB側でベクトル化して検索するので、Embedding modeはServerを選択します。
Knowledge-baseとして使用するには、TitleとBodyをマッピングする必要があります。今回ロードしたCollectionには、_idと$vectorizeというプロパティがあるのでそちらを指定してみます。
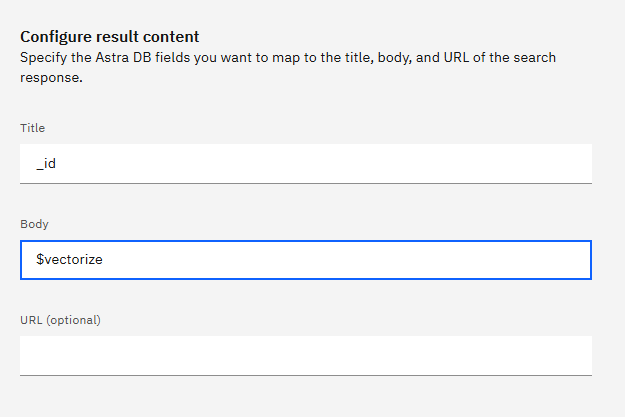
最後に説明を追加します。この説明を見て、エージェントは検索を行うかどうか判断します。

チャット画面から質問してみたところ、以下の様に正しく回答できました。

watsonx.aiのEmbedding Modelを使用したい
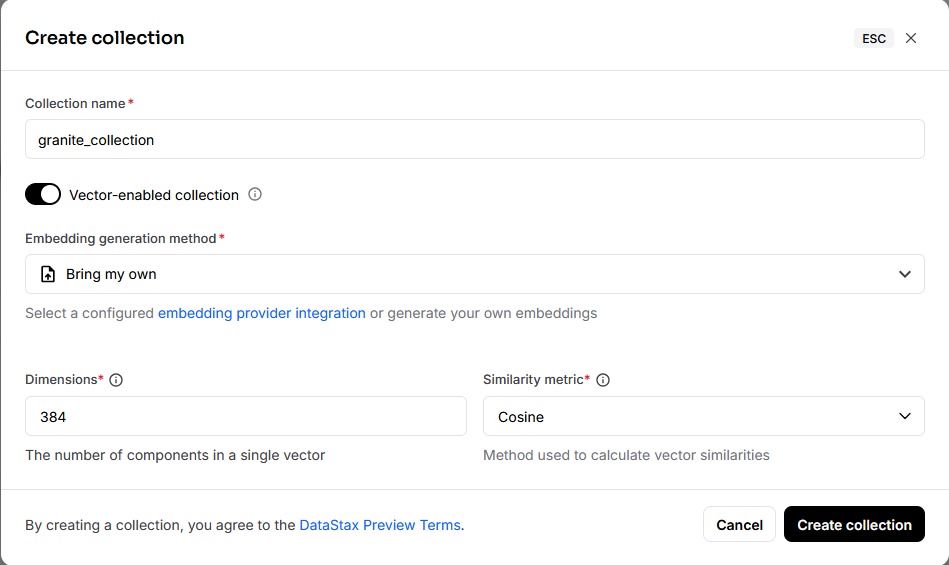
Astra DB標準のEmbedding Modelでは動作させることができましたが、日本語に対応したEmbedding Modelで動作させたいところです。Astra DBではEmbeddingの生成方法として、Bring My Ownという選択を行うことで、Embeddingを自前で行うことが可能です。
今回は、watsonx.aiでサポートされている、granite-embedding-107m-multilingualというモデルを使用してみることにしました。このモデルのDimensionは384なので、384を指定します。
Langflowによる文書のチャンキングとベクトル化
問題は、どうやって文書をチャンキングしてベクトル化するかですが、ちょうど今回watsonx Orchestrateに追加された、Langflowを使うとできそうなことが分かったため、Langflowを使って実行してみることにしました。
watsonx OrchestrateのDeveloper Editionで --with-langflow オプションを付けてサーバーを起動し、http://localhost:7861 にアクセスすることでGUIを利用可能です。
詳細な手順は省略しますが、以下のフローを実装しました。
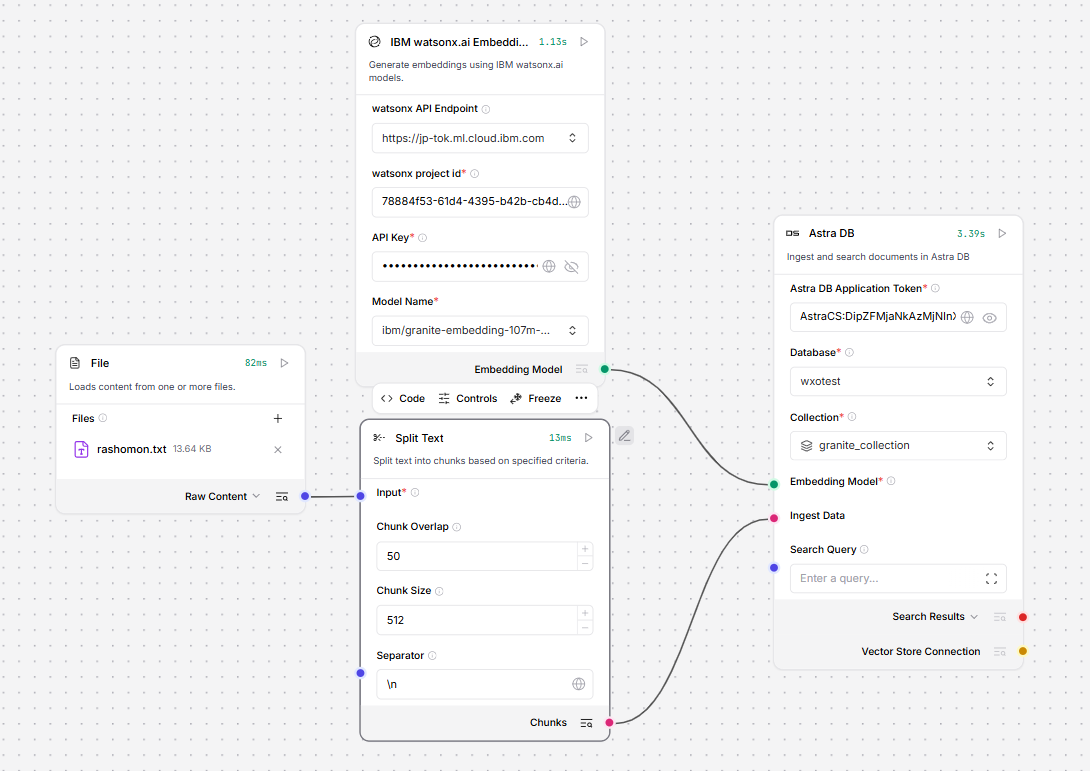
簡単に各ノードの説明をします。
-
File
Langflowのワークスペースにアップロードしたファイルを取得して、データを出力します。今回は青空文庫から取得した芥川龍之介の羅生門のテキストを利用してみました。 -
Split Text
チャンクサイズを指定してテキストを分割可能なノードです。今回は512byteで分割してみました。 -
IBM Watsonx.ai Embeddings
watsonx.ai上で動作するEmbedding Modelを利用するための、接続情報とモデルを指定します。今回はibm/granite-embedding-107m-multilingualを指定しました。 -
Astra DB
AstraのDBにデータをインジェスト可能です。入力として、分割されたテキストと、Embedding Modelのノードを接続し、Astra DB側の接続情報を指定します。
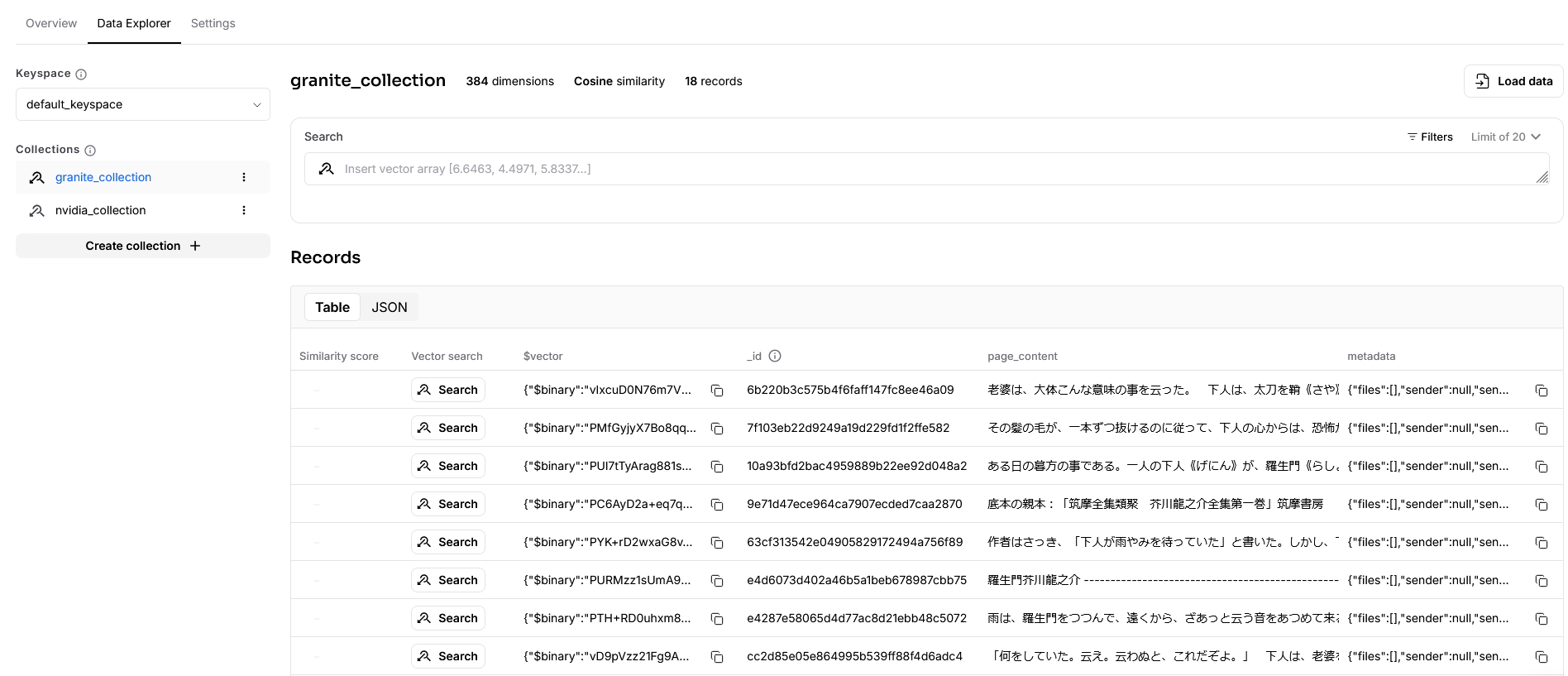
このフローを実行したところ、以下の様に、正しくデータをロードすることができました。Astra DB上でデータをロードした場合と異なり、page_contentというプロパティにコンテンツがロードされています。Langflow側のノードの編集で変更できるのかもしれませんが、今回はこれをそのまま利用します。
watsonx Orchestrate側の設定
先ほどとほぼ同じ設定ですが、今回は、クエリのベクトル化をwatsonx Orchestrate側で実行するため、Embedding modeをClientに指定します。また、モデルとしてibm/granite-embedding-107m-multilingualを選択します。

そして、Bodyとしてpage_contentを指定します。
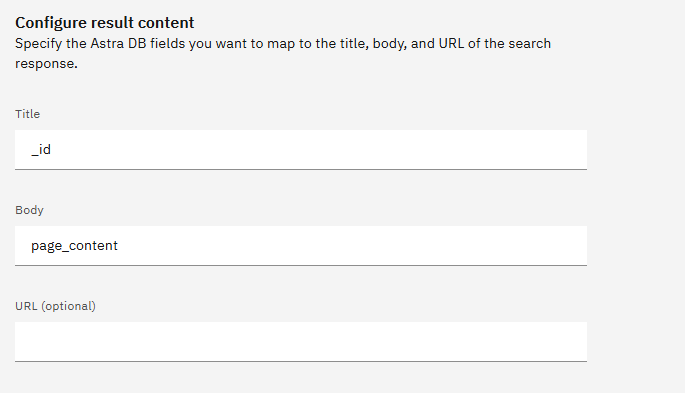
知識の説明として羅生門に関する知識ですと指定することで、羅生門に関する質問を行うと検索が行われます。

正しく動作しているようです!
ADKを使用する場合の設定
knowledge-baseはAgent Development Kit(ADK)でも以下のようなyamlファイルをインポートすることでknowledge-baseを設定できます。
spec_version: v1
kind: knowledge_base
name: rashomon_knowledge
description: >
芥川龍之介の羅生門のテキストです。
prioritize_built_in_index: false
conversational_search_tool:
index_config:
- astradb:
api_endpoint: 'https://xxxxxxxxxxxxxxx.apps.astra.datastax.com'
keyspace: default_keyspace
data_type: collection ## Possible values: `collection` or `table`
collection: granite_collection
embedding_model_id: ibm/graite-embedding-107m-multilingual
embedding_mode: client ## Possible values: `server` or `client`
port: '443'
search_mode: vector ## Possible values: `vector` when `data_type` is `table` OR `vector`, `lexical`, and `hybrid` when `data_type` is `collection`
limit: 5
field_mapping:
title: _id
body: page_content
その際、API-Keyはyamlファイルに含まれないため、Connectionsを用いて指定する必要があります。具体的には以下のようなコマンドを使用します。
orchestrate connections add -a astra
orchestrate connections configure -k api_key -a astra --env draft --type team
orchestrate connections set-credentials -k api_key -a astra --env draft --api-key XXXXX
orchestrate knowledge-bases import -f rashomon_knowledge.yaml -a astra
まとめ
これまでもwatsonx Orchestrateは組み込みのMilvusやElastcSearchといったデータベースをサポートしており、簡単にRAGを構成することが可能でしたが、今回新たにAstra DBが追加され、より選択の幅が広がりました。また、本来の使用目的とは異なりますが、同じタイミングで統合されたLangflowを用いて、チャンキングやembedding modelなどを用いた処理なども容易に行うことが出来ることも確認できました。