IBMとGroqの提携が発表されました。
IBMがwatsonx OrchestrateからGroqCloud上で高速(リリースには5x fasterという表現がありました)に動作するLLMを利用可能になるようです。AIエージェントを動作させる際には複数のLLM推論ステップが必ず必要となるため、今後、LLMによる推論のパフォーマンスの重要性はますます高まってくると思われ、高速な推論が行うための選択肢が追加されるという事は非常に良いことだと思います。
Groqとは?
GroqはLPU(Language Processing Unit)と呼ばれる言語処理に特化したチップを開発し、GroqCloud上でサービスを提供しています。LPUを利用することで、もともと画像処理のためのものであるGPUを使用した場合と比べ、数倍の速度で動作し、かつ低コストでのサービス提供を可能にしているようです。ちなみに、イーロン・マスク率いるxAI社が提供するGrokとは全く別物なので注意しましょう!
watsonx OrchestrateからGroqを試してみる
今回の発表ではオープンソースのLLMサーバーであるvllmとGroqの統合といった点にも言及しており、今後はwatsonx Orchestrateが正式にGroq対応していくものと思われますが、現時点ではwatsonx OrchestrateはGroqへの正式な対応はしていません。ですが、GroqのAPIはOpenAIと同形式のため、watsonx OrchestrateのAIGateway経由で接続できるのではないかと思い、さっそく試してみました。
なお、今回はPC上で動作するwatsonx OrchestrateのDeveloper Editionでテストしていますが、SaaS版でも同様の構成、動作は可能です。
2025年10月29日にリリースされたADK1.14.0でGroqのサポートが追加されました!
Groq APIKeyの取得
Groqへサイン・インして、Create API KeyからAPI Keyを生成します。

なお、プランとしては、Free/Developer/Enterpriseの3つが用意されており、Freeプランでも、例えばgpt-oss-120bでしたら、1000リクエスト/日と、それなりのリクエストを実行することが可能です。モデルごとに条件が違いますので詳細はこちらを参照してください。
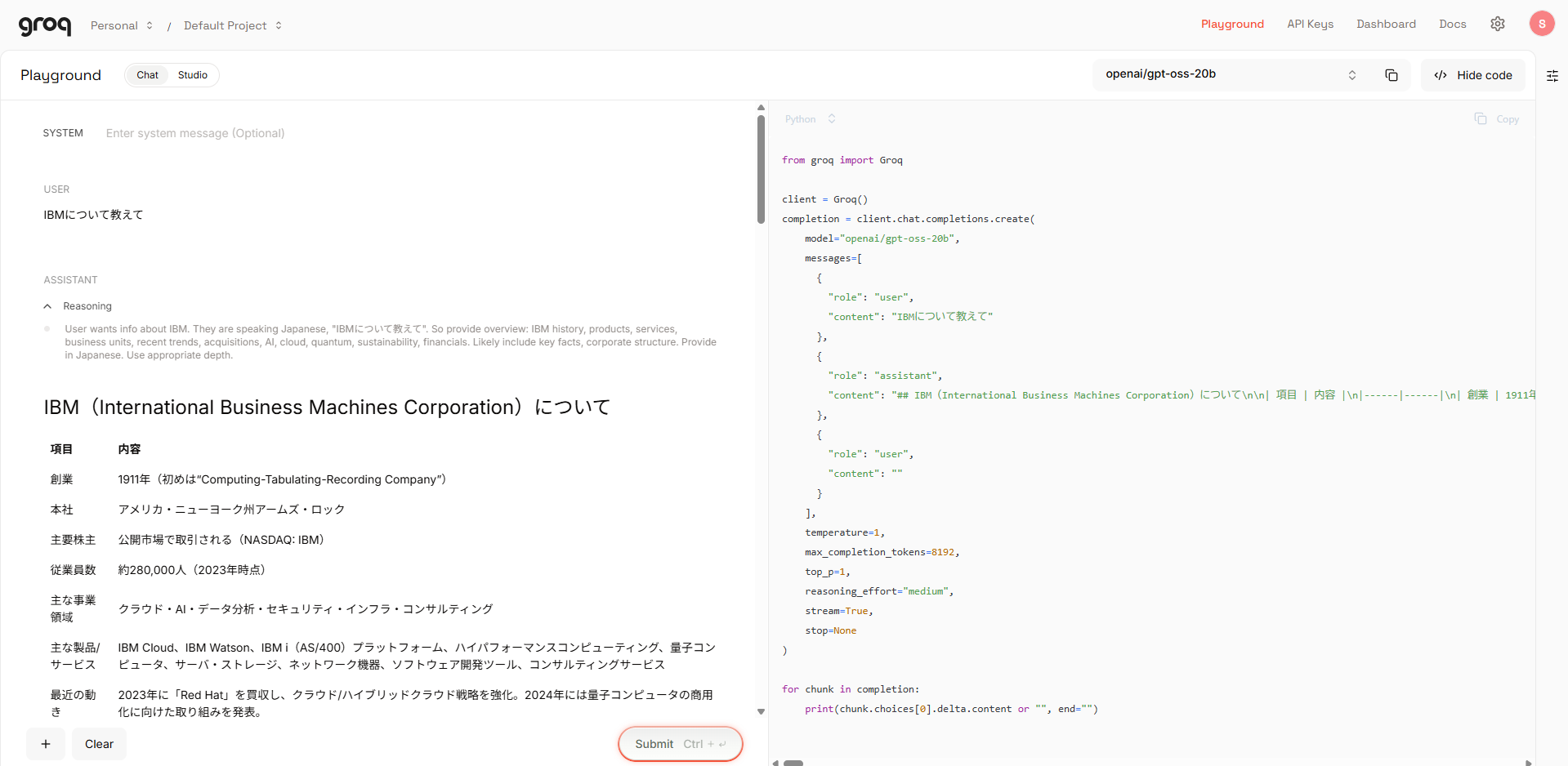
Playgroundという画面から、モデルを指定してチャットからリクエストを送信することも可能です。いくつかのモデルを触ってみましたが、この時点で明らかにレスポンスが速く、期待が持てます。
watsonx Orchestrateの構成
現時点ではwatsonx Orchestrateは正式にはGroqはサポートしていませんので、OpenAIの互換モデルとして登録します。具体的には以下のようなyamlファイルを用意します。
ポイントはnameの指定です。OpenAI互換のモデルとして登録するため openai/の後ろにGroq上のモデル名を指定します。他にもプレビュー版のモデルがありますが、プロダクションとして利用できるLLMは以下の通りです。
- llama-3.1-8b-instant
- llama-3.3-70b-versatile
- meta-llama/llama-guard-4-12b
- openai/gpt-oss-120b
- openai/gpt-oss-20b
今回はwatsonx OrchestrateのデフォルトのLLMに近いllama-3.3-70b-versatileを指定してみました。api_keyに取得したAPIKey、custom_hostにGroqのAPIのエンドポイントを指定します。
spec_version: v1
kind: model
name: openai/llama-3.3-70b-versatile
display_name: Groq(llama-3.3-70b-versatile)
model_type: chat
provider_config: {"api_key":"groq_api_key","custom_host":"https://api.groq.com/openai/v1"}
次に以下のコマンドでモデルをインポートします。
orchestrate models import -f groq_llama.yaml
以上でモデルのインポートは完了です。
ADK1.14.0以降では、以下のように定義が可能です。(こちらの例はapi_keyとしてConnectionを用いて設定していますが、前述のようにyamlファイルに直接api_keyを記述することも可能です。)
spec_version: v1
kind: model
name: virtual-model/groq/openai/gpt-oss-120b
display_name: openai/gpt-oss-120b # Optional
description: Welcome to the gpt-oss series, OpenAI's open-weight models designed for powerful reasoning, agentic tasks, and versatile developer use cases.
tags:
- openai
- gpt-oss-120b
model_type: chat # Optional. Default is "chat". Options: ["chat"|"chat_vision"|"completion"|"embedding"]
app_id: groq_credentials
provider_config:
custom_host: https://api.groq.com/openai/v1
動作確認
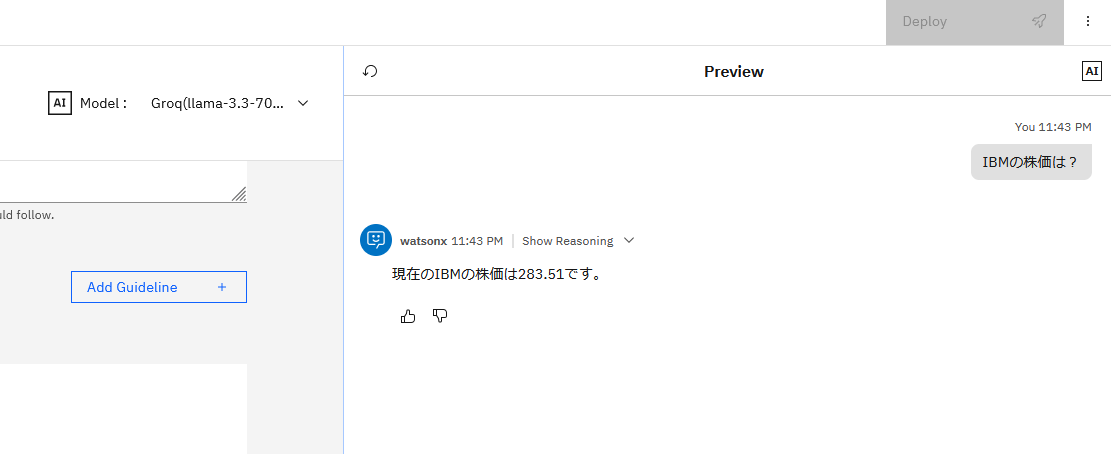
Agent Builderを表示したところ、正しくモデルがリストされていました。yfinanceを用いて株価情報を取得するツールを指定し、IBMの株価を確認したところ、無事に応答が返ってきました。Defaultの設定で、Tool呼び出しも問題無く動作するようです。そして、気になるレスポンス・タイムですが、、、、驚くほど速いです。
Langfuseでの確認
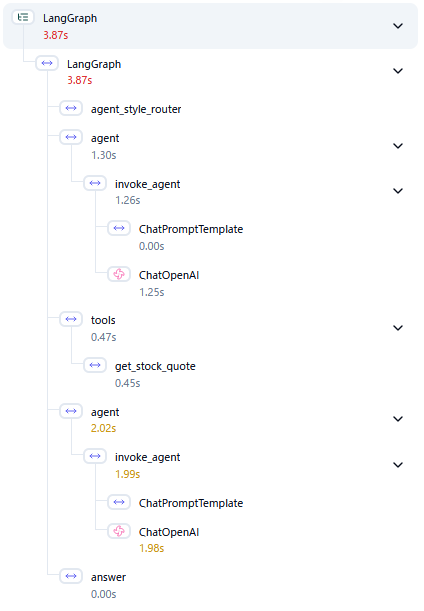
せっかくなので、watsonx Orchestrateに組み込まれているLangfuseを使って詳細を見てみました。まずは製品デフォルトのmeta-llama/llama-3-2-90b-vision-instructを用いた場合です。
ChatOpenAIと表示されている部分がLLMの呼び出しで、株価を取得して回答するという一連の処理の中で、タスクの計画と回答の作成の2回呼び出されています。1回目は1.25、2回目は1.98と合計で3.23秒をLLM部分だけで消費していることになります。
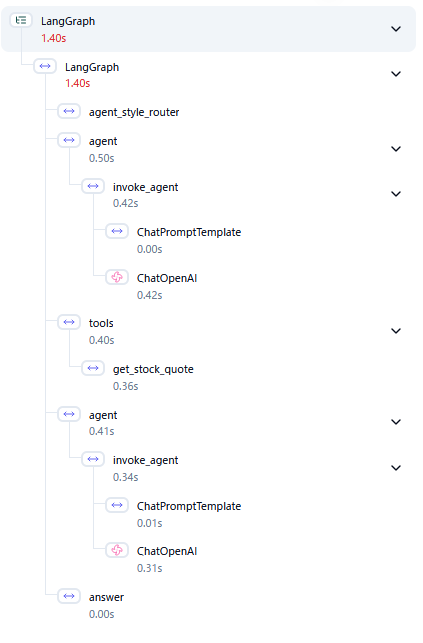
次にGroqを使用した場合です。1回目0.42、2回目0.31で合計0.73秒と、大幅に時間が短縮されており、5x fasterという表現も嘘ではないと言って良いでしょう。トータルのレスポンス・タイムも1.4秒と、ユーザーにストレスを感じさせないレベルの応答を実現しています。
gpt-oss-120bのテスト
watsonx Orchestrateでも提供されているgpt-oss-120bでも動作確認してみました。結果、製品側で6.07秒かかったLLM部分の処理が、1.38秒と、こちらも4倍以上速く動作しました。
なお、現時点ではgpt-oss-120bは製品側もGroq側もReactエージェントとして定義した場合にはTool呼び出しが動作しませんでした。
まとめ
AIエージェントの動作には、基本的に複数回のLLM呼び出しが含まれるため、リアルタイムな応答が求められるユースケースではそのパフォーマンスが大きな課題となります。今回のIBMとGroqの業務提携は、そのような課題に対しての明確なソリューションを提供するという点で大きく期待できるものだと感じました。
現時点では特にGroqのための特別な機能が提供されるわけではなく、OpenAI互換のLLMとしてGateway経由で動作する状況ですが、今後、製品がネイティブ対応することにより、Groq独自の細かいパラメータの設定や、より、小型軽量なgpt-oss-20bのサポートなどが追加されることが望まれます。
なお、今回は製品がネイティブ対応前の段階での簡易的な計測を行っており、今後の統合や機能追加、使用する機能やエージェントの実装によって、利用方法やパフォーマンスが影響を受ける可能性があることにご注意ください。