前回、SPSSで時系列の予測モデルを作成したので、その続き。
やりたいこと
前回は2つの手法により予測結果を出力した。
1つ目は「レコードの将来への拡張」設定により、予測したい期間の説明変数を与えずに予測結果を出力した。
予測のために使用された変数は以下の斜線部分。

2つ目は「予測したい期間の目的変数をnullにしたcsv」をモデルに入力し、nullを欠損値として予測結果を出力した。
予測のために使用された変数は以下の斜線部分。つまり予測したい期間の目的変数以外のすべての情報を与えた。

今回の手法でモデルに与える説明変数は前回の2つ目と同様。
ただし、工夫次第では以下のように任意の期間の説明変数を使用できる手法を試す。

具体的には、トレーニングデータ自体を加工し、未来のデータを過去の時間にずらした列を用意する。
モデルに与えるデータはトレーニング期間の説明変数のみ。つまり前回の1つ目の手法と同様だが、
未来のデータを含む説明変数が含まれるため、「実質的に予測したい期間の説明変数」もモデルに与えることになる。

データの前準備
前回に使用したトレーニングデータ用のcsvに、列を追加する
======前回のcsvに含まれていたデータ======
・Shop(店舗番号)
・Bumon(部門番号)
・Week(週:トレーニングデータの期間は(2010/3/5~2012/7/27の126週分)
・Uriage(今週の売上=目的変数)
・ShopType(店タイプ)
・ShopSize(店サイズ)
・NationalHoliday(祝日)
・Temperature(気温)
・GasolinePrices(ガソリン値段)
・ConsumerPriceIndex(消費者物価指数)
・UnemploymentRate(失業率)
・ChristmasSale(クリスマスセール)
・BlackFridaySale(BlackFridayセール)
・PresidentsDaySale(PresidentsDayセール)
・IndependenceDaySale(IndependenceDayセール)
・EndOfSummerSale(EndOfSummerセール)
・ISO(ISO週番号)
======ここから今回追加したデータ======
NationalHoliday_after13
Temperature_after13
GasolinePrices_after13
ConsumerPriceIndex_after13
UnemploymentRate_after13
ChristmasSale_after13
BlackFridaySale_after13
PresidentsDaySale_after13
IndependenceDaySale_after13
EndOfSummerSale_after13
ISO_after13
名前からわかるように、追加したデータは、13週間後のデータを予測値として入れているだけ。
時間によって変化しない「ShopType(店タイプ)」と「ShopSize(店サイズ)」は除外した。
SPSSでのモデルづくり
先程作ったcsvをドラッグ・アンド・ドロップ。
「フィールド設定」から「データ型」を配置。csvからデータ型に接続

データ型にて、
・Shop(店舗番号)とBumon(部門番号)を「分割」に設定(各店舗&部門ごとの売上を予測したいので)
「尺度」を「カテゴリ型」に変更(それなりに範囲の広い自然数なので、デフォルトでは連続型に自動設定されてしまっている)
・Uriage(売上)を「対象」(=目的変数)に設定(この変数を予測したい)

「モデル作成」から「時系列」を配置。データ型から「時系列」に接続。「時系列」が「Uriage」(売上)に自動的にリネーム

Uriage(時系列)の「データ指定」-「観測」にて、Weekを日付/時刻フィールドに指定。時間区分を「週」に指定。(これが、今回のデータにおける時間軸の情報ですよと)
「作成オプション」でモデルを選べるようだが、デフォルトで全てのモデルを試してもらえるらしいのでそのままで。
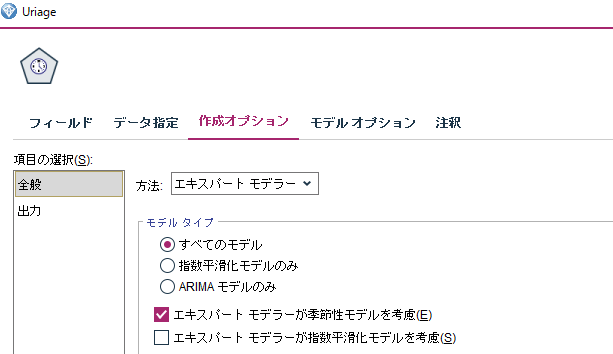
「モデルオプション」にて、「レコードの将来への拡張」にチェックを入れて13を入力。(トレーニングデータのラストから、さらに13週間後までを予測してほしいので)
「データ型」にて「ここから実行」

40分ほどでモデルが出来た。

予測値をcsvで取得
「出力」から「テーブル」を配置。モデルから「テーブル」に接続

「テーブル」にて「実行」

20分ほど待つと表が出てくるのでcsvで保存

生成されたcsvを見ると、トレーニングデータとして与えた2010/3/5~2012/7/27の126週分だけでなく、2012/8/3~2012/10/26までの13週間分についても予測値($TS-Uriage)が入っている。

これを、トレーニングデータから除外した2012/8/3~2012/10/26の実績値と比較して精度を求める。
精度検証
店舗番号と部門番号との組み合わせが2627パターンあるので、2627組x13週間の34151個の予測値をExcelで評価する。
前回、の結果もあわせて検証する。
手法1:前回の1つ目の手法
「レコードの将来への拡張」設定により、モデルに「過去の説明変数のみ与える」
手法2:前回の2つ目の手法
「予測したい期間の目的変数をnullにしたcsv」をモデルに入力して、モデルに「予測したい期間の説明変数も与える」
手法3:今回の手法
「レコードの将来への拡張」設定に加え、時間軸をずらしたトレーニングデータにより「予測したい期間の説明変数も与える」
誤差の統計。

下の方のデータは各週ごとに個別に計算したもの。直近の予測ほど精度が高いのでは?と思って調べてみたが、あまり有意な差には見えない。ただ、予測しやすい(誤差の小さな)週と、予測しづらい週がはっきり別れているのが確認できる。
手法2,3は、いずれも手法1と比べて全体的に改善されているように見える。
誤差絶対値平均では手法2が最も優れていたが、誤差二乗平均では手法3の方が精度が高い。(つまり大きなハズレが少ない。誤差XX%以内の割合からも、その傾向が見える。)
=
各週の売上を、全店舗&全部門で合計し、予測値と実績値を比較する。

手法2はかなりアグレッシブに予測値が上下しているが、手法1、手法3はほぼ平均値付近に見える。
ただ、実績(正解値)の標準偏差が22620なのに対して、どの手法でも誤差二乗平均は5000以下なので、平均に近い無難な値が予測値になっているわけではなく、個別の店舗&部門ではきちんと意味のある予測になっているはず。
=
誤差のばらつきをグラフにする。
横軸の0は、実際には「誤差が-500~0の範囲の予測数」になる。手法3のピークが+500(実際には「誤差が0~+500の範囲の予測数」)にずれているように見えるのはそれが原因。

分解能が500と大きいために形が歪に見えるが、だいたい正規分布っぽい。
今後の予定
トレーニングデータにちょっとした加工を加えることで精度を上げてみる
SPSSを使用して時系列データの予測モデルを作成する3
別の機械学習ソフトでも同様のデータを使ってモデルを作成し、比較したい。
DriverlessAIと比較してみた:DriverlessAIを使用して時系列データの予測モデルを作成する