SPSSを使用して時系列データの予測モデルを作ってみます。
SPSSの基本的な勉強の結果と疑問点をメモしたものです。
前段:時系列データの予測に使う説明変数の考察
説明変数の中には、未来のデータであっても予測可能なものと、予測が困難なものがある。
理想的には、既知のデータ、および予測可能なすべてのデータを目的変数を予測するために役立ててほしいところ。

しかし、SPSSを含め簡単に機械学習できると謳っているソフトをいくつか試してみたが、単純に時系列に沿ったデータを用意して学習した場合、上記のように思い通りのデータを指定して用いることは簡単ではない様子。
手法としては、以下の2パターンがある。
学習時に「予測したい期間」を数値入力することで予測できるタイプのものは、当然、以下の斜線部分のデータしか予測に使用しない。

予測したい期間の説明変数を入力することで予測できるタイプのものは、以下の斜線部分のデータを使用するため、ツールがこの手法に対応しているのであれば、先のものよりも精度が上がることが期待できる。

SPSSでは両方の手法が可能なので、それぞれ試して比較してみる。
やりたいこと
SPSSのチュートリアルにも時系列のデータを用いたものがいくつかあるが、すべて変数が1つしか無いデータを扱っているような気がする。(つまり、目的変数の過去の値だけを元に、周期的な特性を検出して将来の値を予測する仕組み)
そのため、前述のような問題は考慮する必要がない。
今回は以下のような予測を行いたい
1.時系列データで、それなりに期間が長い
2.説明変数が数値またはカテゴリ化が可能なデータ(自然言語、画像、音声といったデータの処理はスペック的に無理)
3.説明変数がそれなりに多い
4.目的変数は数値(回帰)
使用する(お借りする)データ
前述の「やりたいこと」に合ったデータを探したところ、DataRobotの勉強会で使われていたデータが見つかったので使わせていただく。
https://datarobot.connpass.com/event/64363/
なるべく多くのデータがほしいので、全データが入った「週次売上予測データセット.xlsx」を使用する。
(Kaggleデータセットなども探したが、説明変数が多く、且つ期間も長い時系列データのサンプルはなかなか見つからなかった。)
データの前準備
入手したデータに入っている変数は以下のもの
==基本データ==
・店舗番号
・部門番号
・週(2010/3/5~2012/10/26の日付:139週間分)
・今週の売上(目的変数)
・祝日
・店タイプ
・店サイズ
・気温
・ガソリン値段
・消費者物価指数
・失業率
==イベントフラグデータ==
・クリスマスセール
・BlackFridayセール
・PresidentsDayセール
・IndependenceDayセール
・EndOfSummerセール
・ISO週番号
==ヒストリカル変数/統計==
・1週間前の売上
・2週間前の売上
・3週間前の売上
・4週間前の売上
・過去40週の売上平均値
・過去40週の売上中央値
・1週間前の週次売上絶対値変化
・週次売上変化の過去40週中央値
・週次売上絶対値変化の過去40週中央値
・週次売上変化の過去40週平均値
・週次売上絶対値変化の過去40週平均値
各店舗&部門ごとに、毎週のデータが記録されている。
店舗番号と部門番号との組み合わせが2627パターンあるので、つまり2627組x139週=365153行のデータが存在する(特定日付が抜けているといった欠損は無い様子)
入手したデータを以下のように加工する。(SPSS以外のツールでも使えるように汎用的に加工しておく)
・「ヒストリカル変数/統計」の列は削除する(加工済みのデータが入っていると検証結果が分かりづらいので)
・2バイト文字が入っていると困るかもしれないので英字に置き換える(2バイト文字に対応しないソフトでも使用したいので)
店舗番号→Shop・部門番号→Bumon・週→Week・今週の売上→Uriageみたいな感じに適当に
・xlsx形式は読み込みできないツールが多いのでcsv化する
・2010/3/5~2012/10/26(139週)のデータを2分割する(行数表記はヘッダ1行を除外したもの)
2010/3/5~2012/7/27の126週 (2627x126=331002行) →トレーニング用
2012/8/3~2012/10/26の13週 (2627x13=34151行) →テスト用(予測したい期間)
・テスト用データにおけるUriage列(売上)の内容をすべて0(ゼロ)またはnullにしておく。
仕様上、予測に使われる事は無いと思うが、これが予測に使われてしまうと意図しない予測になるので念の為に消しておく。
トレーニング用データ(2010/3/5~2012/7/27)
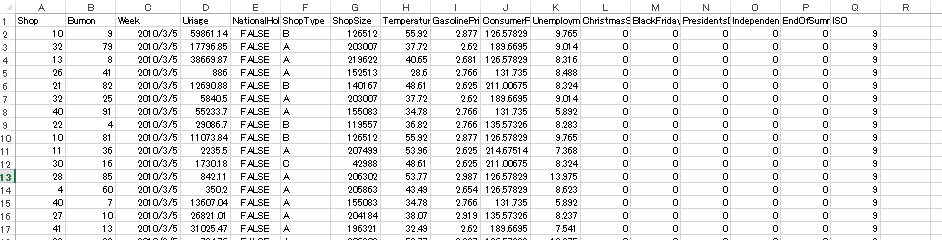
テスト用データ(2012/8/3~2012/10/26)
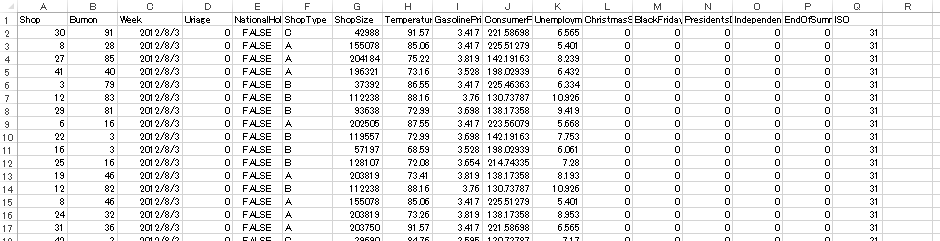
モデル作成
トレーニングデータのcsv(2010/3/5~2012/7/27の126週分のデータ)をドラッグ・アンド・ドロップ。
「フィールド設定」から「データ型」を配置。csvからデータ型に接続
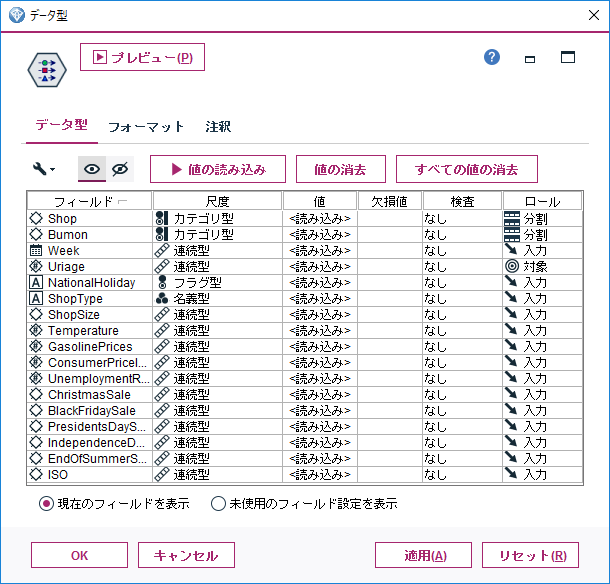
データ型にて、
・Shop(店舗番号)とBumon(部門番号)を「分割」に設定(各店舗&部門ごとの売上を予測したいので)
「尺度」を「カテゴリ型」に変更(それなりに範囲の広い自然数なので、デフォルトでは連続型に自動設定されてしまっている)
・Uriage(売上)を「対象」(=目的変数)に設定(この変数を予測したい)
他のデータの尺度は、自動検出されたもので大丈夫そう(0or1のイベントフラグ系がフラグ型ではなく連続値になっているのがちょっと気になるけど放置)
「モデル作成」から「時系列」を配置。データ型から「時系列」に接続。「時系列」が「Uriage」(売上)に自動的にリネーム
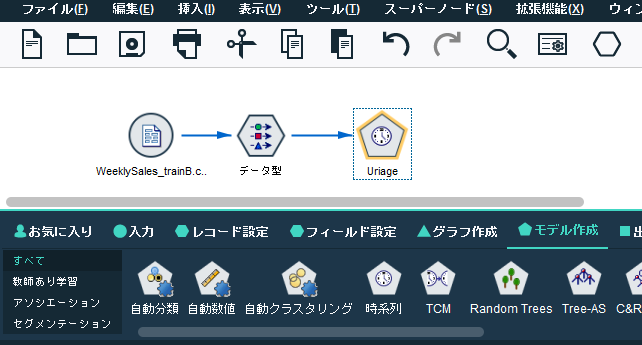
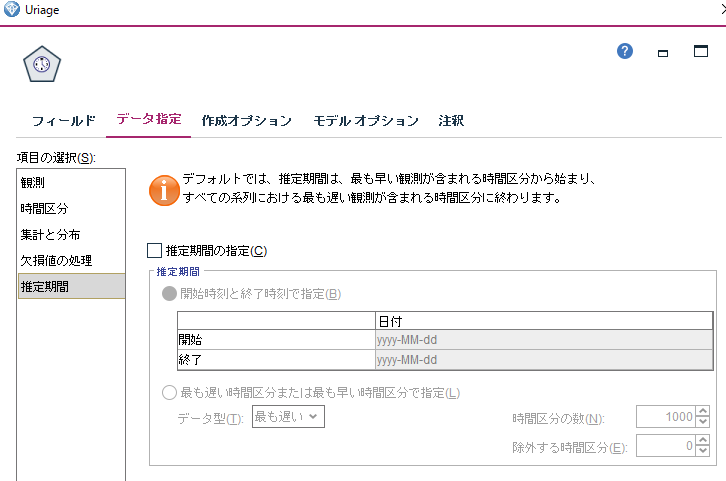
Uriage(時系列)の「データ指定」-「観測」にて、Weekを日付/時刻フィールドに指定。時間区分を「週」に指定。(これが、今回のデータにおける時間軸の情報ですよと)
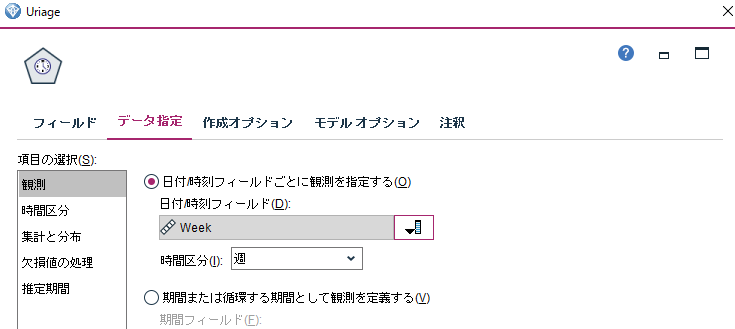
「作成オプション」でモデルを選べるようだが、デフォルトで全てのモデルを試してもらえるらしいのでそのままで。
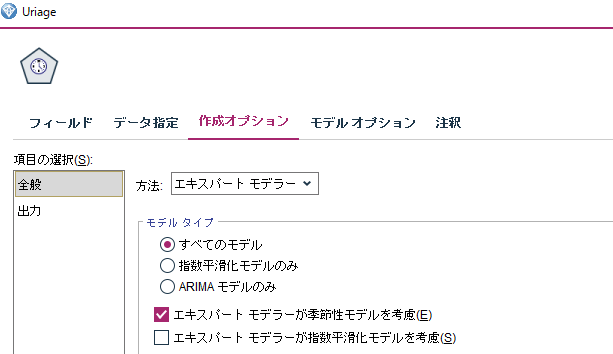
「モデルオプション」にて、「レコードの将来への拡張」にチェックを入れて13を入力。(トレーニングデータのラストから、さらに13週間後までを予測してほしいので)
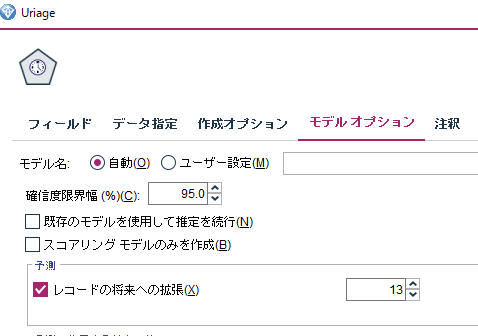
「データ指定」-「推定期間」が重要っぽいが、ヘルプ見てもいまいちわからない。デフォのままにする。
今回みたいに13週間後を予測したい場合、予測に使用する変数として直近13週間分を使わないことで、既知の情報から直接13週間後を予測できるので、そういった設定のようにも見える。(そういった設定がないと、1週間ずつ順番に予測を進めていくことになるので、どんどん精度が下がるのでは?)
「データ型」にて「ここから実行」
なんか流れ始める。
ショボいCPUのVMware仮想マシン環境なので、40分程かかる。
モデルが出来た。
予測値をcsvで取得(手法1)
モデル作成時に「レコードの将来への拡張」を13に指定したので、その指定による予測を出力する。
この予測では、「予測したい期間」の説明変数は与えていないため、予測に使用する変数は以下の斜線部分になる。
「出力」から「テーブル」を配置。モデルから「テーブル」に接続する。
「テーブル」にて「実行」。
また20分ほど待機する。
表が出てくるのでcsvで保存する。
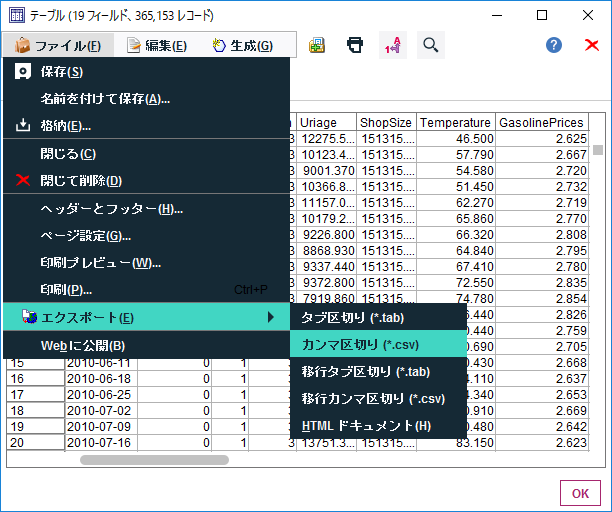
生成されたcsvを見ると、トレーニングデータとして与えた2010/3/5~2012/7/27の126週分だけでなく、2012/8/3~2012/10/26までの13週間分についても予測値($TS-Uriage)が入っている。
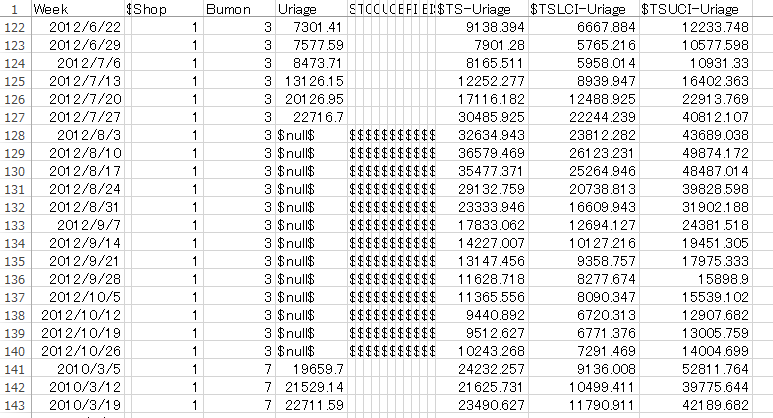
これを、トレーニングデータから除外した2012/8/3~2012/10/26の実績値と比較して精度を求める。
疑問点が2つ
1.
店舗&部門によって、トレーニングデータ期間の最初の数週間の予測値が入っていない(null)ものがあるのは何故だろうか。
過去の実績を元に将来の値を予測するわけだから、過去のデータが少ない最初の期間が予測できない理屈はわかるが、最初の週から予測値が入っている店舗&部門もあれば、7週間もnullになっている店舗&部門もある。違いは何だろうか。
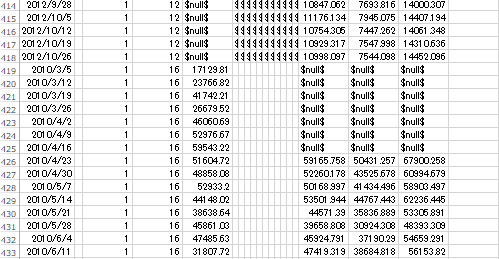
2.一部の店舗&部門では、3,4週目あたりからの予測値が変化していない。今回のモデルでは正確な予測が難しかったということだろうか。
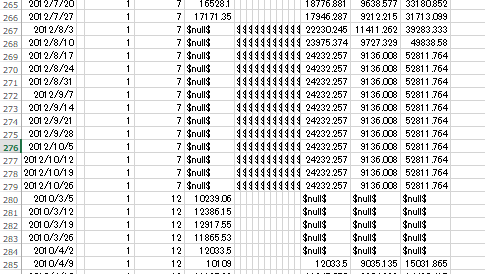
予測値をcsvで取得(手法2)
予測したい期間の説明変数が分かっている場合、つまり以下斜線部分すべての説明変数を使って予測する手法も試してみる。
2010/3/5~2012/7/27のデータ(学習に使用したデータ)と、2012/8/3以降のテストデータ(売上をnullにしたもの)を1つのcsvにまとめたものを用意する。
以下のように、2012/8/3以降のUriageがnullになっている。
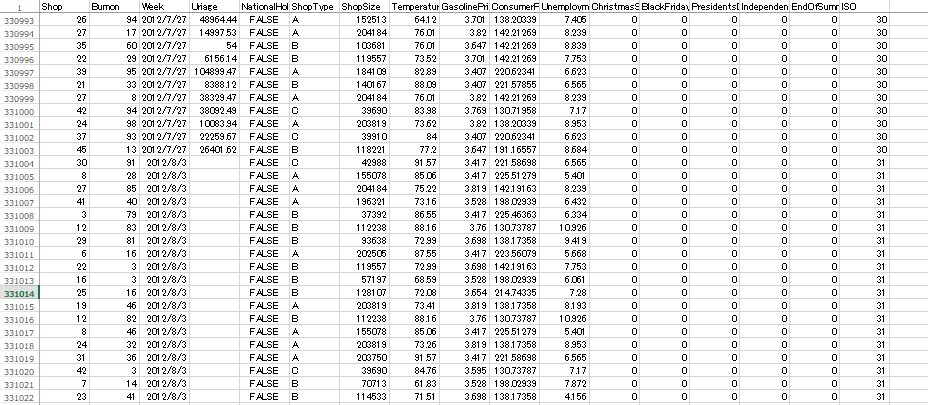
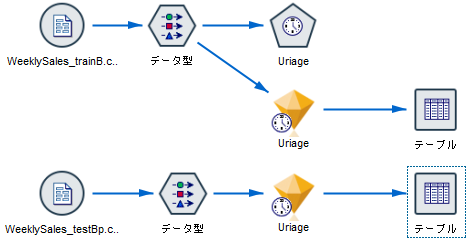
先程作ったモデル「Uriage」をコピペして、新しい「Uriage」を作成する。「データ型」もコピペで複製する。
先程のcsvをドラッグ・アンド・ドロップでインポートし、
「先程のcsv」→「コピーしたデータ型」→「コピーしたUriageモデル」→「テーブル」のように接続する。
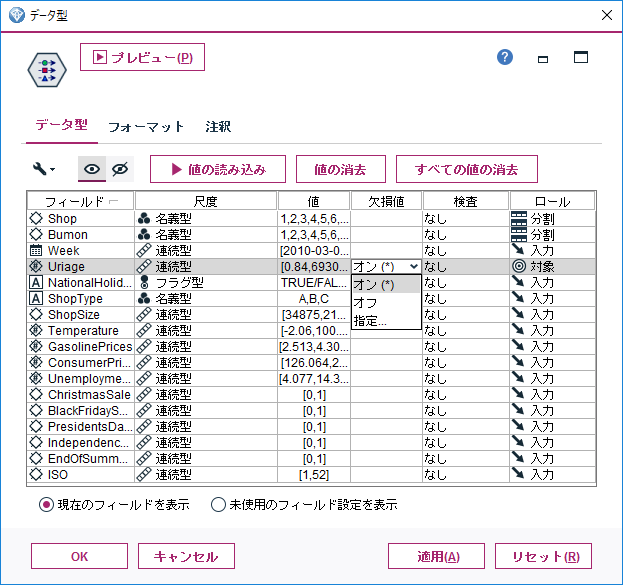
データ型はコピーしたものなので、「尺度」や「ロール」は既に設定済みになっている。
予測したい期間のUriageをnullにしたので、「欠損値」をオンにすることで、過去の既知のデータから、未知のUriageを補完してもらう。
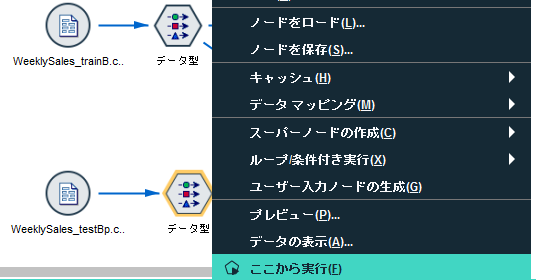
データ型にて「ここから実行」すると、
「テーブル」までまとめて実行されるので、csvで保存。
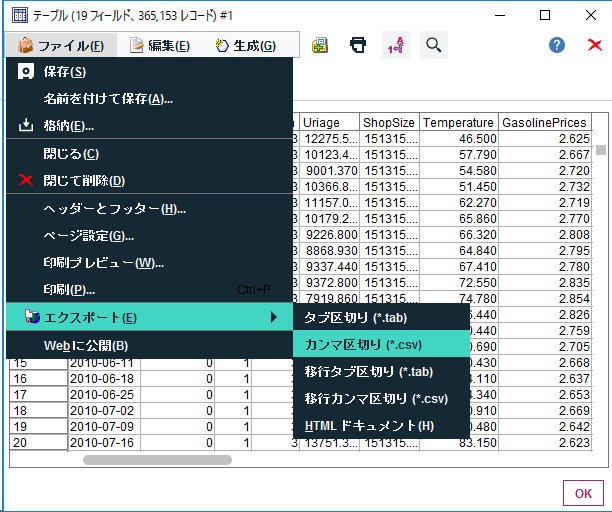
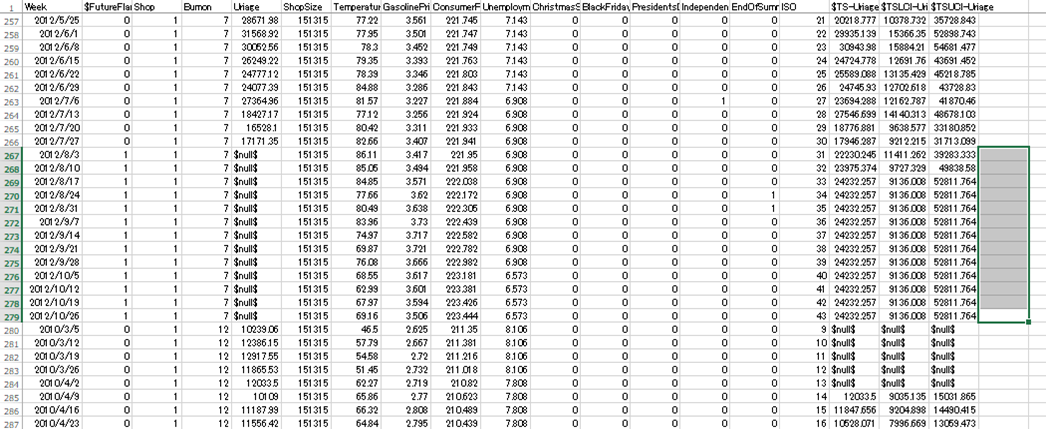
出力されたcsvには、2012/8以降のテストデータ期間中の予測値も含まれるが、
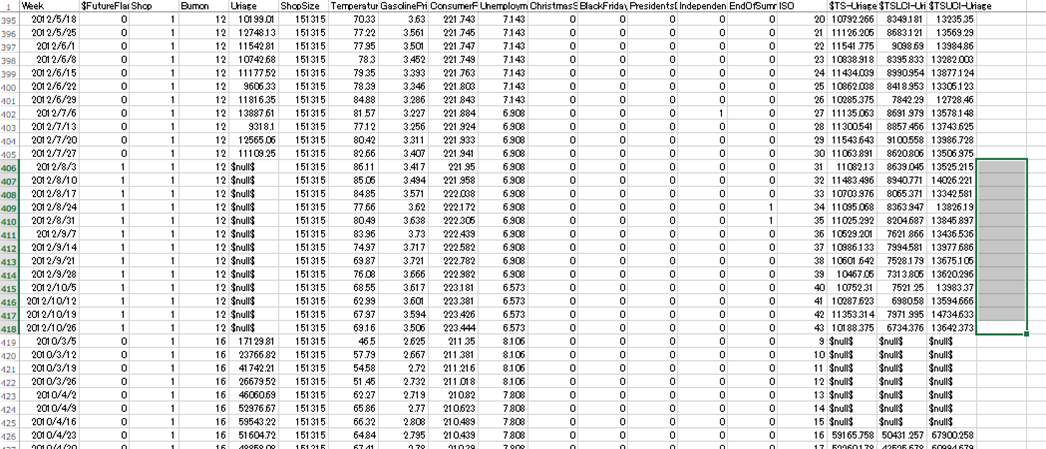
先程の手法と同様に、一部の店舗&部門では、3,4週目あたりからの予測値が変化していない。
精度検証
予測結果の精度検証だが、SPSSによる別の手法も試したので、そちらの結果と合わせて整理する。
SPSSを使用して時系列データの予測モデルを作成する2