※以下、個人的な勉強のためのレポートです。
※間違い多々あると存じますが、現在の理解レベルのスナップショットのようなものです。
※勉強のためWebサイトや書籍からとても参考になったものを引用させていただいております。
http://ai999.careers/rabbit/
CNNの復習
<確認テスト>
サイズ55の入力画像を、サイズ33のフィルタで畳み込んだときの出力画像のサイズを答えよ。なおストライドは2、パディングは1とする。
公式より、
\begin{align}
& OH(Output High)\\
& = \frac{H(hight)+2p(padding)-FH(FilterのHight)}{S(ストライド)}+1\\
& = \frac{5+2*1-3}{2}+1\\
& = 3
\end{align}
\begin{align}
OW(Output Width)\\
& = \frac{W(Width)+2p(padding)-FWidth(FilterのWidth)}{S(ストライド)}+1\\
& = \frac{5+2*1-3}{2}\\
& =3
\end{align}
答え)高さ3 × 幅3
再帰型ニューラルネットワークの概念
RNN
RNN(Recurrent Neural Network)とは、時系列データの予測に対応可能なニューラルネットワークである。時系列に意味を踏まえたまま学習させるニューラルネットワーク。
時系列データとは、時特定の情報について、時間順序を追って取得されたデータのこと。典型的なものとしては、年度ごとのA社の売上高、1時間ごとの東京都の降水量、地球上で発生した地震の時刻と場所、震度などの記録、といったものが挙げられる。音声データや文章データ、株価など、時間的な順序を追って一定時間ごとに観察され、しかも相互に統計的依存関係が認められるようなデータの系列。
画像分類などではCNNが用いられる。しかし、自然言語処理のような問題をニューラルネットワークで扱う場合、単語の意味や単語のつながりは、その前後の文脈(コンテキスト)によって変化する。このようなデータを扱うに当たっては、個々のニューロンの出力が次の層の入力になるだけでなく、同じ層の他のニューロンに伝える必要がある。
例えば、「英語の他動詞の後には目的語が続く」「名詞の前には形容詞を伴う」という性質を用いることを考える。「water」という単語の日本語約を作る場合、drinkという単語を解析したニューロンの「他動詞」と推測された出力をもらうことで、後には名詞が続くことが多いので「水」という名詞の翻訳をすることができ、bedという単語を解析するニューロンの「名詞」と推測された出力をもらうことで、「水の」という形容詞の翻訳をすることができる。
時系列モデルを扱うには、初期の状態と過去の時間t-1の状態を保持し、そこから次の時間でのtを再帰的に求める再帰構造が必要になる。
RNNの概念図
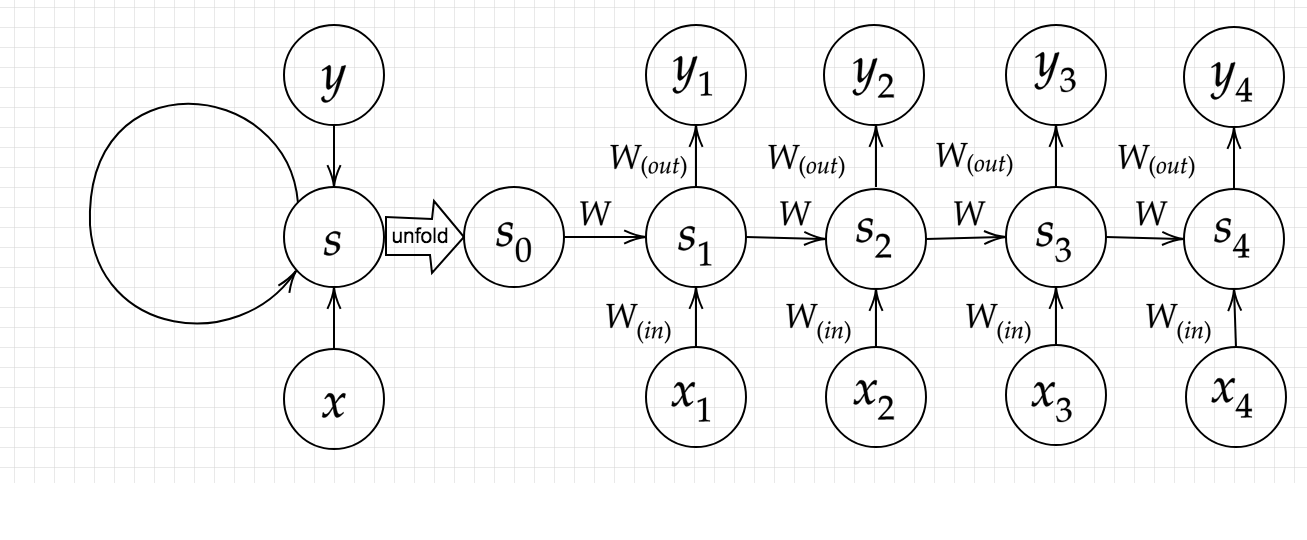
RNNの数式的記述
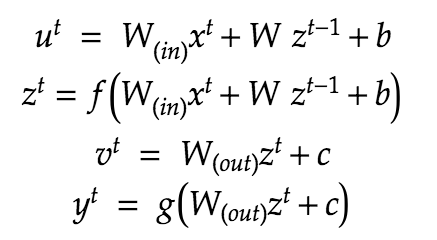
RNNのソースコードでの表現
np.dot(z[:,t+1].reshape(1,-1),W_out)
y[:,t]=functions.sigmoid(np.dot(z[:,t+1].reshape(1,-1),W_out))
<確認テスト>
RNNのネットワークには大きくわけて3つの重みがある。一つは入力から現在の中間層を定義する際にかけられる重み、一つは中間層から出力を定義する際にかけられる重みである。残り一つの重みについて説明せよ。
(答え)Win Wout、そしてW:中間層から次の中間層へわたされる際の重み
<ソースコード演習>
1.weight_init_stdやlearning_rate, hidden_layer_sizeの初期値の変更
ex)中間層の層数の変更
〇16層にして実行したもの
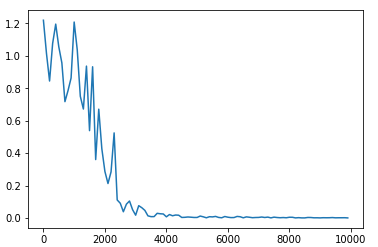
〇100層にして実行したもの
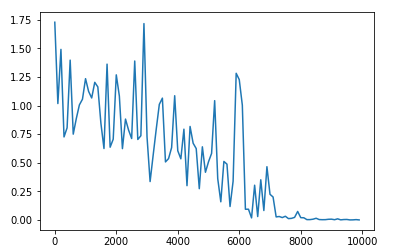
→精度に非常に影響する。単純に層を増やせばよいというわけではないことがわかる。単純に層を増すことは、勾配消失や過学習という問題が生じる。
ウェイト初期化 (バイアスは簡単のため省略)
W_in = weight_init_std * np.random.randn(input_layer_size, hidden_layer_size)
W_out = weight_init_std * np.random.randn(hidden_layer_size, output_layer_size)
W = weight_init_std * np.random.randn(hidden_layer_size, hidden_layer_size)
2.重みの初期化方法を変更
→DNNで用いられる、Xavier,やHeを使用することができる
Xavier
W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size))
W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size))
W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size))
He
W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size)) * np.sqrt(2)
W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
3.中間層の活性化関数を変更
活性化関数にReLU関数を使用
z[:,t+1] = functions.relu(u[:,t+1])
z[:,t+1] = np.tanh(u[:,t+1])
delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * functions.d_relu(u[:,t+1])
delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * d_tanh(u[:,t+1])
tanhの実装
def d_tanh(x):
return 1/(np.cosh(x) ** 2)
※tanhの微分は、1/coshの2乗
def d_tanh(x):
return 1/(np.cosh(x) ** 2)
BPTT:Backpropagation Through Time
https://book.mynavi.jp/manatee/detail/id=76172
RNNにおけるパラメータ調整方法の一種。RNNにおいては、層間だけでなく、時間軸で同じ層のニューロン間での出力のやり取りが発生するため、誤差を求める際には時間軸で展開する必要がある。その誤差を時間をさかのぼって逆伝播するのが、Backpropagation Through Time
→誤差逆転伝播の一種
<誤差逆転伝播法の説明>
計算結果(=誤差)から微分を逆算することで、不要な再帰的計算を避けて微分を算出できる。
**<確認テスト>
連鎖律の原理を使い、dz/dxを求めよ。
z=t^{2} \\
t=x+y \\
\frac{dz}{dx}=\frac{dz}{dt}\frac{dt}{dx}\\
\frac{dz}{dt}=2t\\
\frac{dt}{dx}=1\\
よって、\\
\frac{dz}{dx}=2t*1=2t=2(x+y)
BPTTの数学的記述
Win
Wout
W
バイアスb
バイアスc
の各々について誤差を重みで微分する。
数学的記述
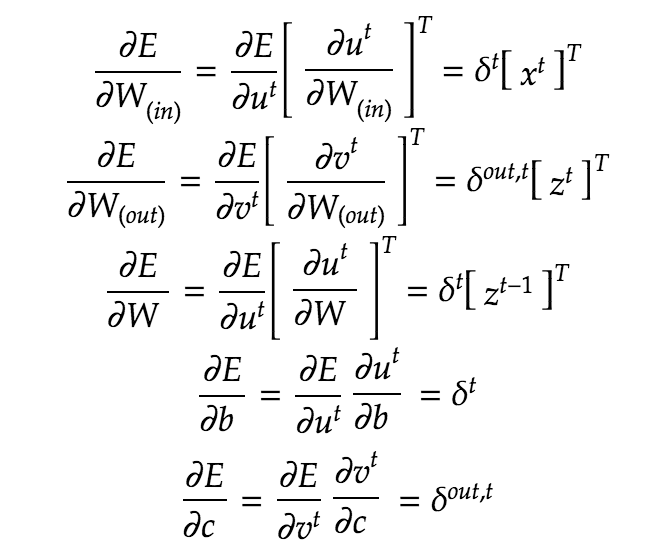
コードによる表現
Win
W_in_grad += np.dot(X.T, delta[:,t].reshape(1,-1))
Wout
W_out_grad += np.dot(z[:,t+1].reshape(-1,1), delta_out[:,t].reshape(-1,1))
W
W_grad += np.dot(z[:,t].reshape(-1,1), delta[:,t].reshape(1,-1))
※バイアスについては簡略
u u^t
u[:,t+1] = np.dot(X, W_in) + np.dot(z[:,t].reshape(1, -1), W)
z z^t
z[:,t+1] = functions.sigmoid(u[:,t+1])
v^t
np.dot(z[:,t+1].reshape(1, -1), W_out)
y^t
y[:,t] = functions.sigmoid(np.dot(z[:,t+1].reshape(1, -1), W_out))
<確認テスト>
下図のy1をx/s0/s1/win/wwoutを用いて数式で表せ。
※バイアスはに似の文字で定義せよ。
※また中間層の出力にシグモイド関数g(x)を作用させよ。
答え)
Z1=sigmoid(S0W+X1Win+b)
Y1=sigmoid(Z1Wout+C)
deltaが分かればすべて芋づる式にわかる
delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * functions.d_sigmoid(u[:,t+1])
パラメータ更新
W_in -= learning_rate * W_in_grad
W_out -= learning_rate * W_out_grad
W -= learning_rate * W_grad
BPTTの全体像
<コード演習問題>
下の図はBPTTを行うプログラムである。なお簡単化のため、活性化関数は恒等関数であるとする。またcalcurate_dout関数は損失関数を出力に関して偏微分した値を返す関数であるとする。(お)にあてまるのは何か?
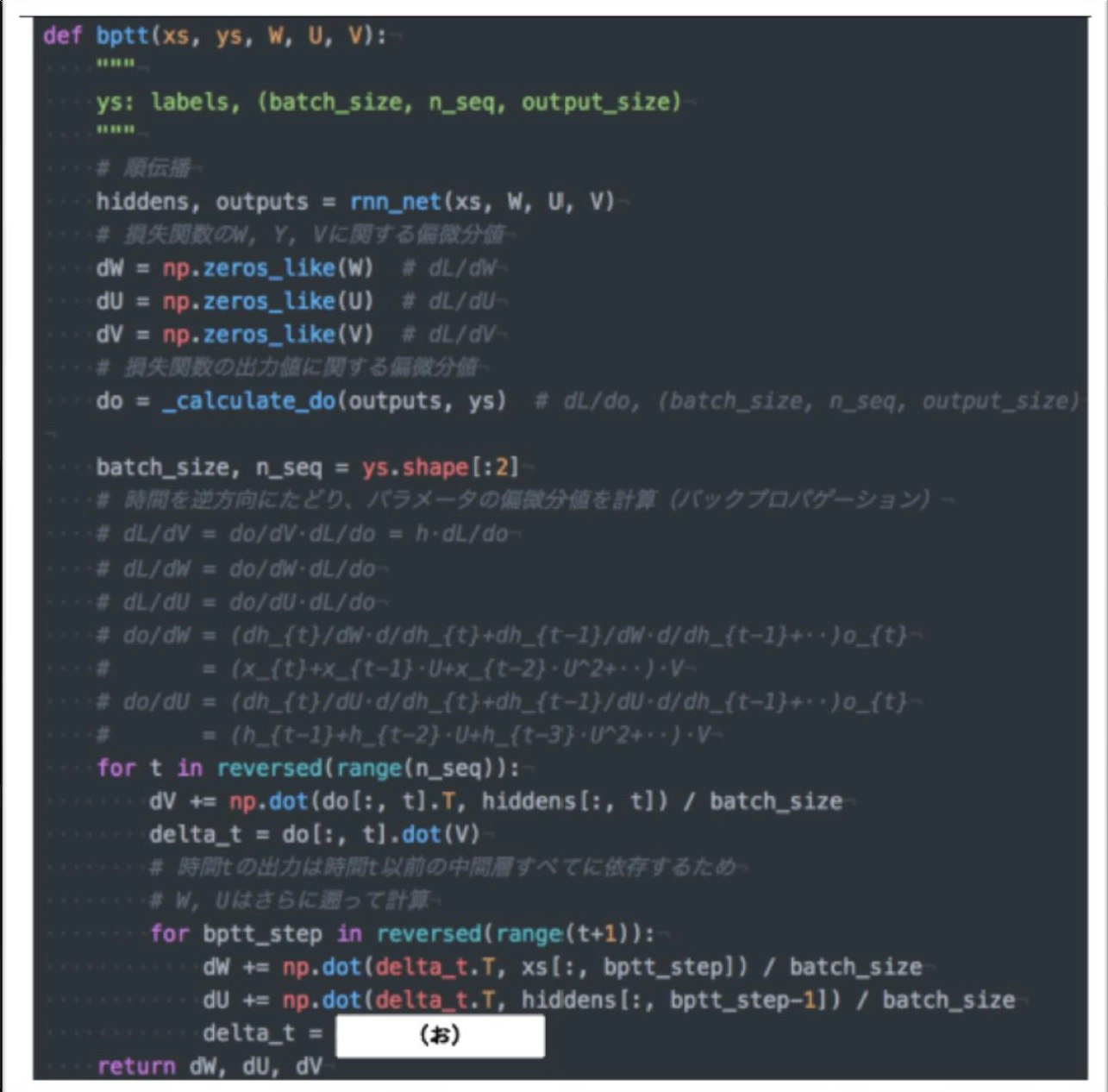
(答え)delta_t.dot(U)
RNNにおいては、過去の中間層の出力に依存性を持っている。
RNNにおいて損失関数を重みWやUに関して偏微分するときは、それを考慮する必要があり、dh_{t}/dh_{t-1}=Uであることに注意すると、過去にさかのぼるためびにUが乗算される。つまり、delt_t.out(U)となる。
LSTM:Long short-term memory
RNNの課題:時系列をさかのぼるほど、勾配が消失していく。つまり、長い時系列の学習が困難という問題があった。従来のニューラルネットワークにも同様の問題がり、活性化関数の変更や正則化で対応する方法があったが、LSTMではそれらの方法を採らず、RNNの構造自体を変えて解決を図ったもの。
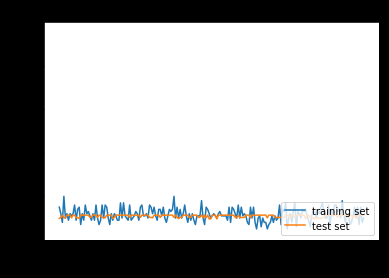
<勾配消失問題とは>
誤差逆伝播法が下位層に進んでいくに連れて、勾配はだんだん緩やかになっていく。そのため勾配降下法による更新では、下位層のパラメータはほとんど変わらず、訓練は最適値に収束しなくなってしまうこと。
〇収束しないパターン
〇うまく収束するパターン
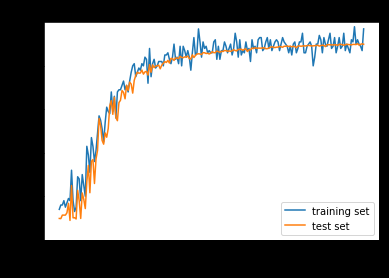
原因の一つとして、活性化関数でも用いられるsigmoid関数には「大きな値では出力の変化が微小」という特徴があり、勾配消失問題を発生させる。
<確認テスト>
シグモイド関数を微分したとき、入力値が0のときに最大値をとる。その値として正しいものは?
(答え)0.25
f(u)'=(1-sigmoid(u))(sigmoid(u))
前の項0.5、後ろの項0.5
よって、0.5 × 0.5 = 0.25
<勾配爆発問題とは>
勾配消失とは逆に、勾配爆発という事象もある。勾配が層を逆伝播するごとに指数関数的に大きくなってしまい、最適値に収束しなくなるという問題。
<演習チャレンジ>
RNNや深いモデルでは勾配の消失または爆発が起こる傾向がある。勾配爆発を防ぐために勾配のクリッピングを行うという手法がある。具体的には勾配のノルムがしいき値を超えたら、勾配のノルムをしきい値に正規化するというものである。以下は勾配のクリッピングを行う関数である。(さ)にあてはまるものはどれか?
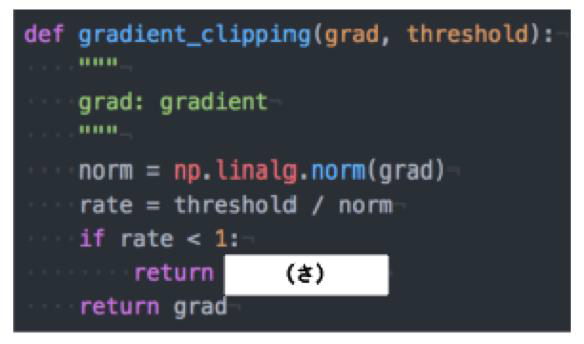
(答え)gradient * rate
→勾配のノルムがしきい値より大きいときは、勾配のノルムをしきい値に正規化するので、クリッピングした勾配は、勾配×(しきい値/勾配ノルム)と計算される。
LSTMの全体図
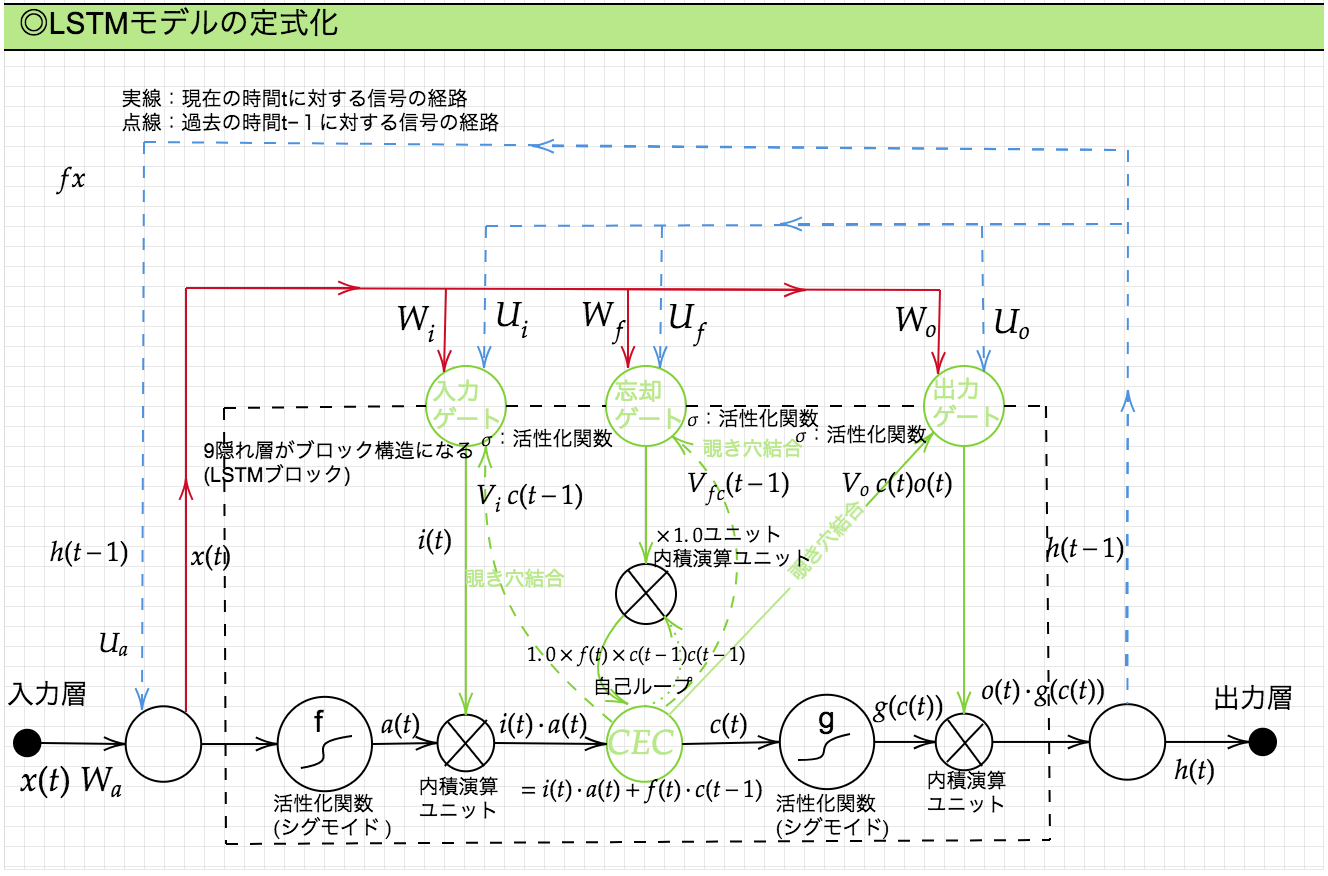
CEC:Constant Error Carousel
勾配消失および勾配爆発の解決方法として、勾配が「1」であれば解決できるという点に着目した手法。
しかしCECには課題がある。単純にCECを導入すると、入力データについて、時間依存度に関係なく重みが一律になってしまい、ニューラルネットワークの学習特性が無くなってしまう。(入力重み衝突、出力重み衝突)
これを解決するために、入力ゲート/出力ゲートの仕組みを用いる。
入出力ゲート
入出力ゲートを追加することで、それぞれのゲートへの入力値の重みを、重み行列W/Uで可変なものとして扱うことができるようになる。
忘却ゲート
LSTMブロックに登場するCECには過去の情報がすべて保存されている。これは、過去の情報が不要になったときでも削除できず保存され、影響を与え続けるという問題を含んでしまう。よって、過去の情報が不要になった場合には、そのタイミングで情報を忘却する機能が必要になる。それが忘却ゲートである。
<確認テスト>
以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測においてなくなっても影響を及びさないと考えられる。このような場合、どのゲートが作用すると考えられるか。
「映画おもしろかったね。ところで、とてもおなかがすいたから何か_____。」
(答え)忘却ゲート
<演習チャレンジ>
以下のプログラムはLSTMの順伝播を行うプログラムである。ただしシグモイド関数は要素ごとにシグモイド関数を作用させる関数である。(け)にあてはまるのは何か?
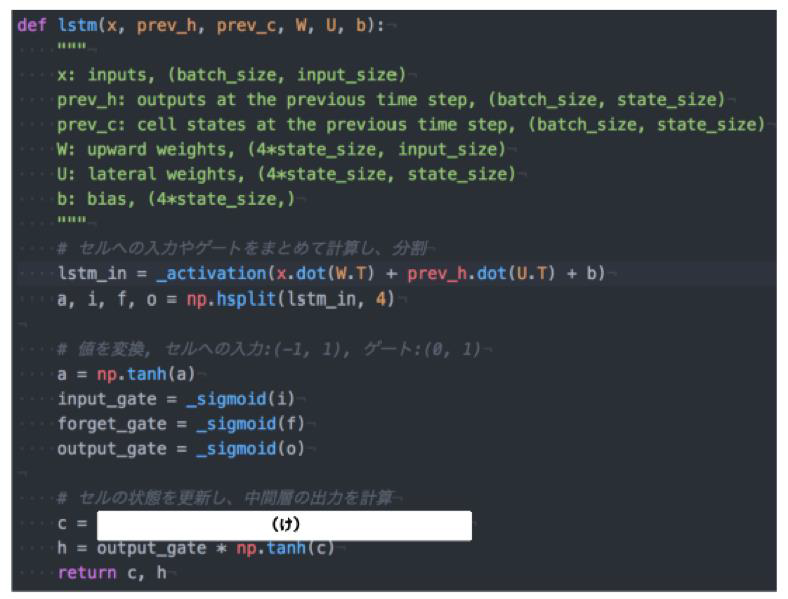
(答え)input_gate * a + forget_gate * c
新しいセルの状態は、計算されたセルへの入力と1ステップ前のセルの状態に入力ゲート、忘却ゲートをかけて足し合わせたものと表現される。
のぞき穴結合
https://teratail.com/questions/177871
https://mrsekut.site/?p=889
CECに保存されている過去の情報を、任意のタイミングで他のノードに伝播させたり、あるいは任意のタイミングで忘却させたいという要求があった場合、そのアクセス手段がない。のぞき穴結合とは、CEC自身の値に、重み行列を介して伝播可能にしたインタフェース構造。
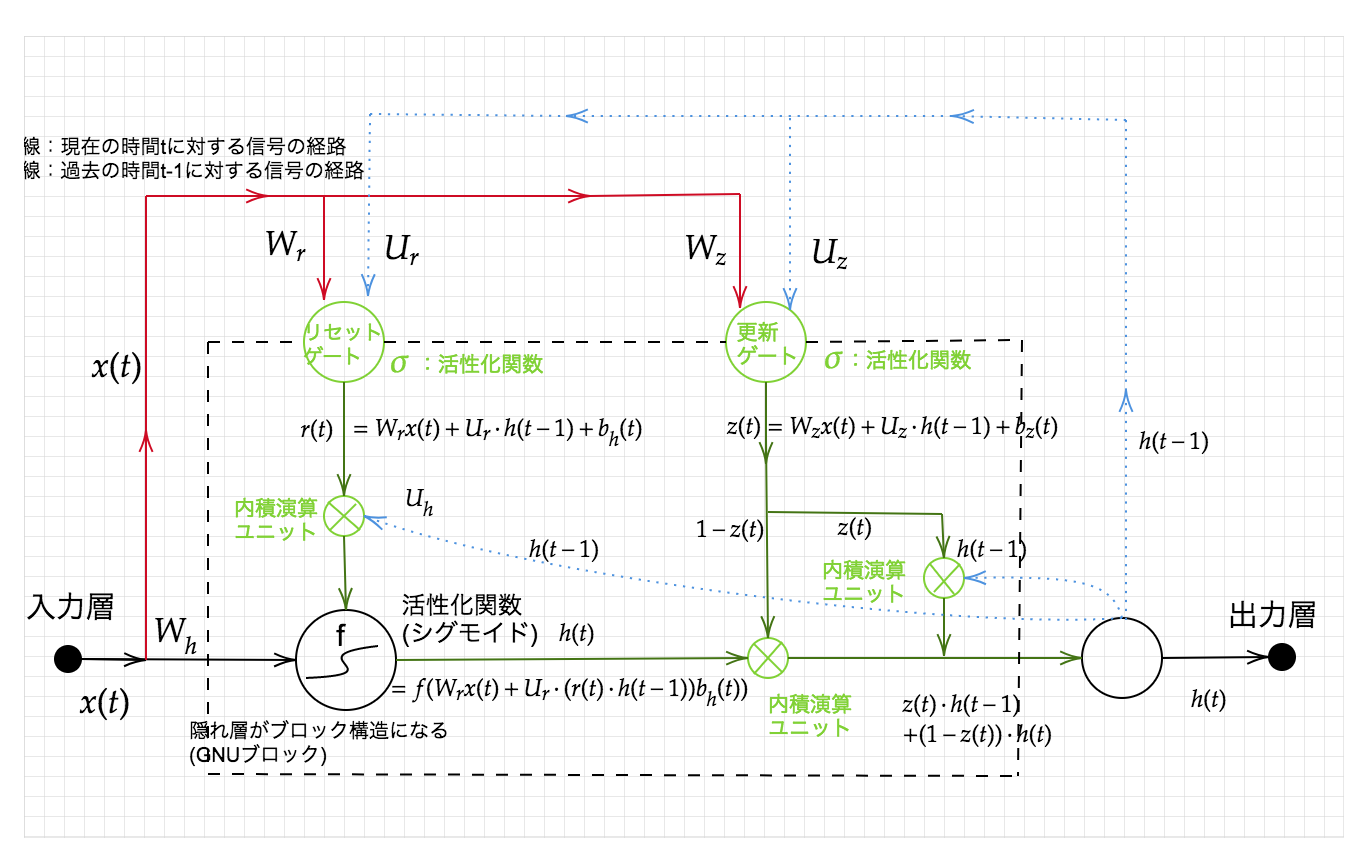
GRU:Gated recurrent unit
RNNの課題を克服するために考案されたLSTMであるが、LSTMは非常に複雑な構造をしており、ゆえにパラメータが多く、計算不可が増大する問題がある。そこで、パラメータを大幅に削減し、計算不可を低下させ、それでいて精度はLSTMと同等またはそれ以上を期待できる構造として考えられたのがGRU(ゲート付き回帰型ユニット)。
※実際問題としては、GRUが必ず勝るというわけではない。
GRUの全体像
<確認テスト>
LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
(答え)
LSTMはパラメータが多く計算負荷が大きい。CECには重みの概念が画一化されてしまい、ニューラルネットワークの特徴である学習の概念がなくなってしまう。
<演習チャレンジ>
GRU(Gated recurrent unit)もLSTMとと同様に RNN の一種であり、単純な RNN において問題となる勾配消失
問題を解決し、長期的な依存関係を学習することができる。 LSTM に比べ変数の数やゲートの数が少なく、より単純
なモデルであるが、タスクによっては LSTM より良い性能を発揮する。以下のプログラムは GRU の順伝播を行うプログラムである。ただし _sigmoid 関数は要素ごとにシグモイド関数を作用させる関数である。(こ)にあてはまるものは何か?
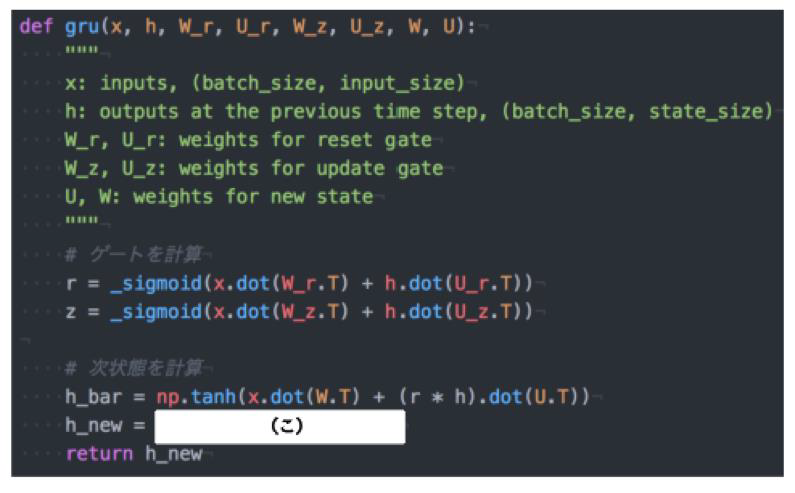
(答え)(1 z) * h + z * h_bar
新しい中間状態は、 1 ステップ前の中間表現と計算された中間表現の線形和で表現される。つまり更新ゲート z を用
いて、 (1 z) * h + z * h_bar と書ける。
<確認テスト>
LSTMとGRUの違いを簡潔に述べよ 。
(答え)https://ja.wikipedia.org/wiki/%E3%82%B2%E3%83%BC%E3%83%88%E4%BB%98%E3%81%8D%E5%9B%9E%E5%B8%B0%E5%9E%8B%E3%83%A6%E3%83%8B%E3%83%83%E3%83%88
LSTMは忘却ゲートを持つが、それに比べシンプルな構造であるGRUは出力ゲートを欠くためLSTMよりもパラメータが少なく、よって計算負荷も低くなる。タスクに応じてLSTMとGRUでどちらが精度が出るかは異なる。
双方向RNN
https://qiita.com/icoxfog417/items/2791ee878deee0d0fd9c
データの中には、「x」が出たら「y」が来る可能性が高い、というように前のデータが次のデータに対し相関を持つものがある。これがいわゆる時系列データであり、具体的には、言葉や音声といったものである。こうした時系列で相関を持つデータでは、当然、事後だけでなく、前に発生したデータを考慮に入れた前後関係の推測が有用になる。これが実現できれば精度をより高めることができる。
上で扱ってきたRNNは時系列データに対応したニューラルネットワークであったが、事後だけでなく、前に発生したデータを考慮に入れた前後関係の推測、つまり「前→後」(未来)と「後→前」(過去)の双方向(Bi-directional)の時系列についても学習を行うことで精度を高められる構造が双方向RNNである。機械翻訳や文書校正などの応用がある。
双方向RNNの構造
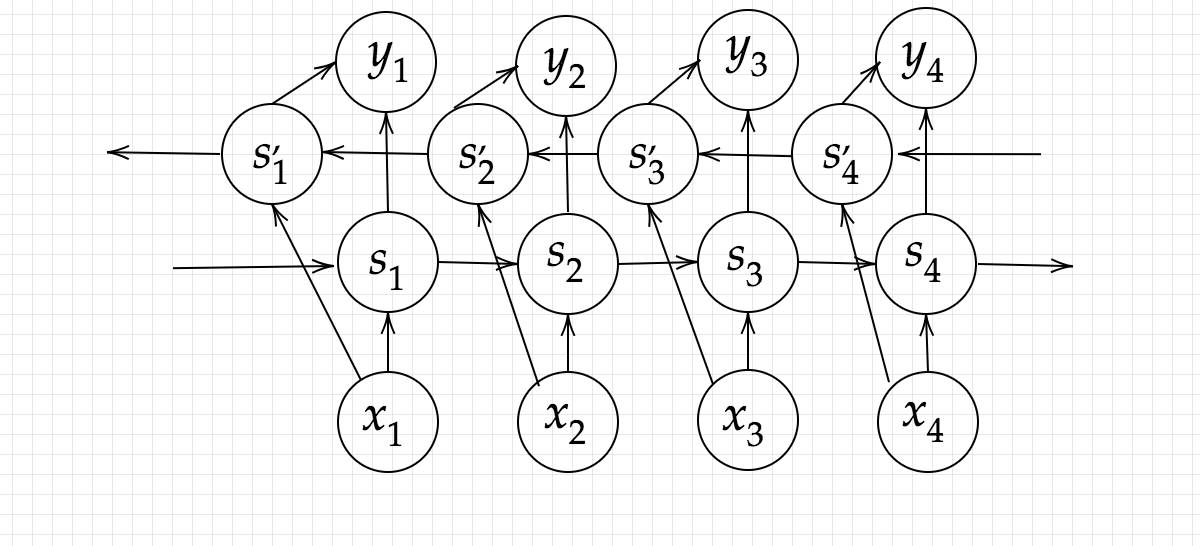
NNに、前に発生したデータを投入できるようにはできないか。その答えが、RNNとなります。
時刻ttの隠れ層の内容が、次の時刻t+1t+1の時の入力として扱われます。t+1t+1の隠れ層がt+2t+2の・・・と続くわけですが、要は前回の隠れ層が次の隠れ層の学習にも使用される、というイメージです。
Long short term memory network (LSTM) と Bi-directional RNN (BRNN) は結合方法に関する制約は特にありません。
<演習チャレンジ>
以下は双方向RNN の順伝播を行うプログラムである。順方向については、入力から中間層への重み W_f , 一ステップ前の中間層出力から中間層への重みを U_f 、 逆方向に関しては同様にパラメータ W_b , U_b を持ち、両者の中間層表現を合わせた特徴から出力層への重みは V である。rnn関数はRNNの順伝播を表し中間層の系列を返す関数であるとする。(か)にあてはまるの何か?
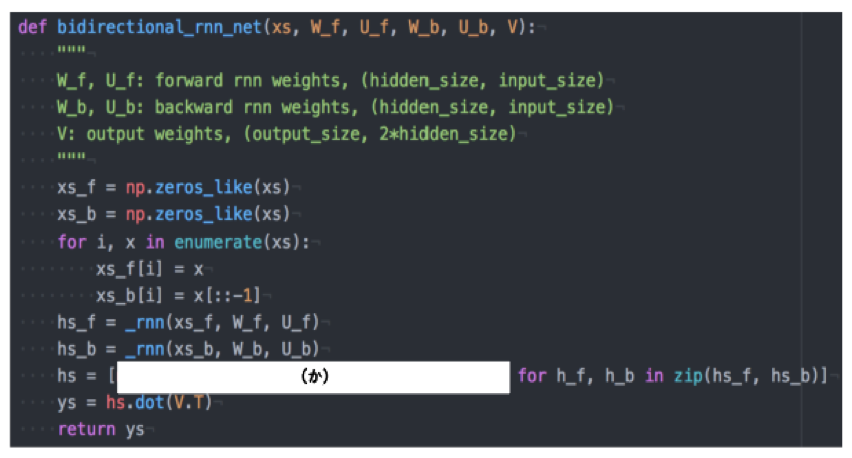
(答え)np.concatenate([h_f, h_b[:: 1]], axis=1)
双方向 RNN では、順方向と逆方向に伝播したときの中間層表現をあわせたものが特徴量となるので、
np.concatenate([h_f , h_b 1]], axis=1) である。
Seq2Seq:Sequence to Sequence
https://qiita.com/kenchin110100/items/b34f5106d5a211f4c004
https://qiita.com/halhorn/items/646d323ac457715866d4
Seq2Seqとは、RNNを用いたEncoderDecoderモデルの一種であり、機械対話や機械翻訳などのモデルとして使用することができる。入力を日本語の文章とし、出力を英語の文章とする「機械翻訳」、入力を人間の言語入力とし、応答をロボットの言語出力とする「チャットボット」これらは入力/出力のシーケンスをペアで学習させることで精度向上の実現が期待できる。構造はLSTMなどのRNN系を用いたニューラルネットワーク二つの部分から構成される。その二つとはEncoder RNNとDecoder RNNである。
Seq2Seqの構造
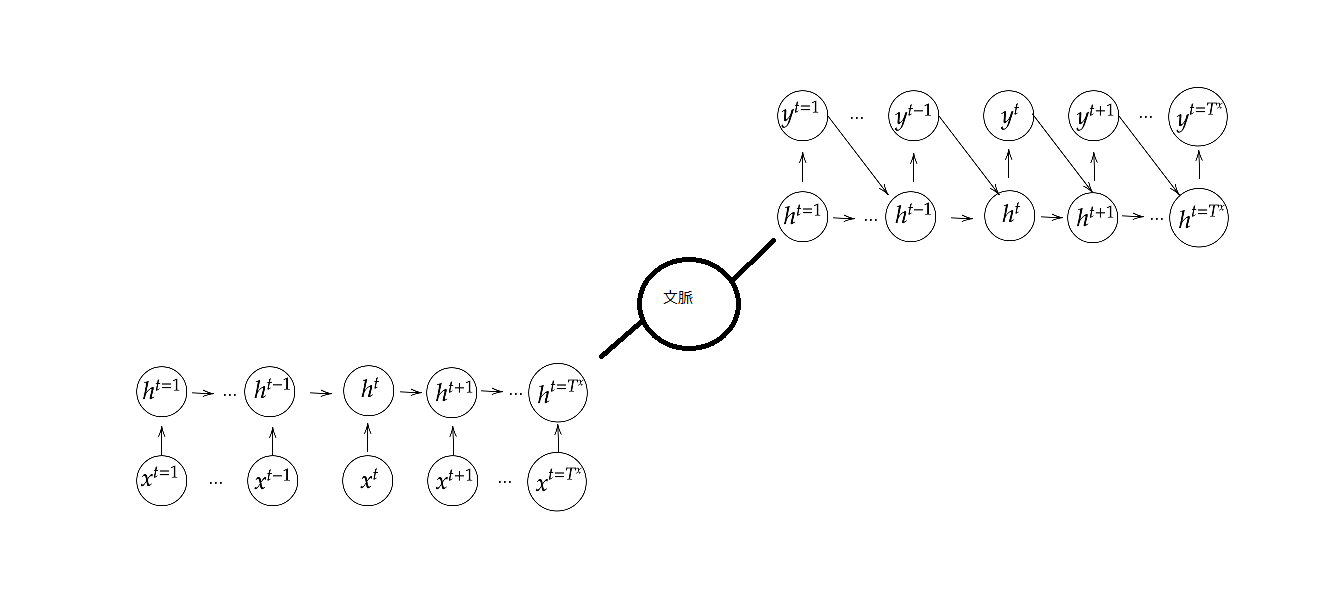
以下、自然言語処理の例でSeq2Seqの構造と処理を説明。
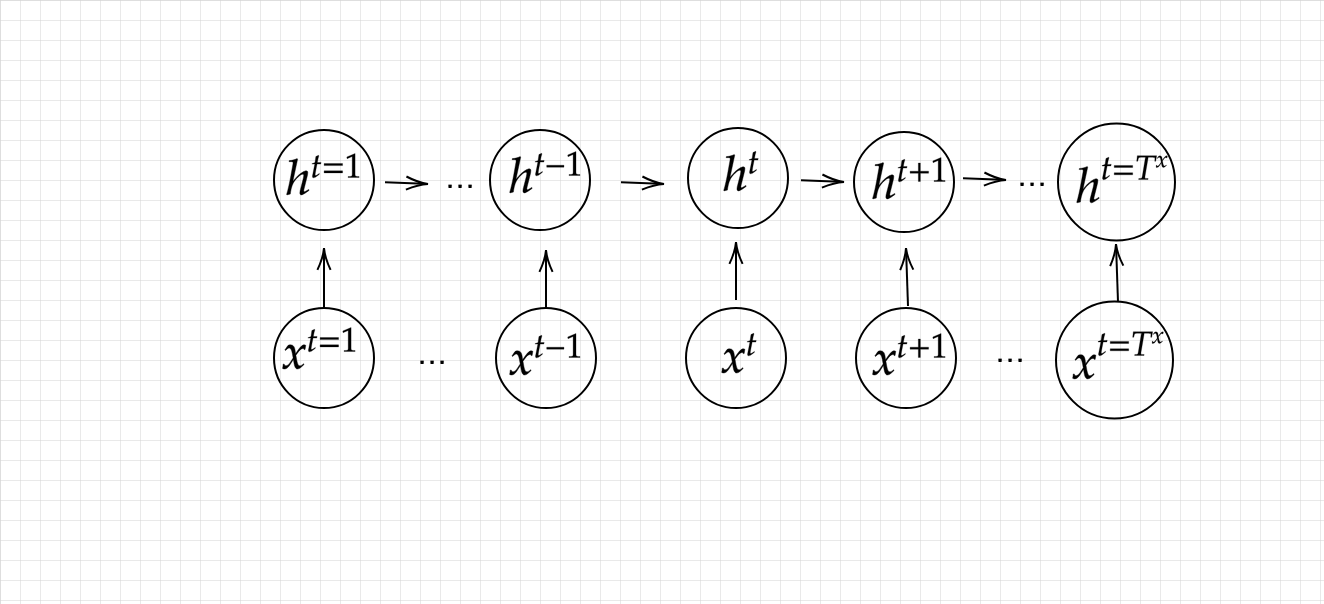
Encoder RNN
ユーザーがインプットしたテキストデータを単語等のトークンに区切って渡す構造(Tokenizer)。Taking(文章を単語等のトークン毎に分割し、トークンごとの ID に分割する)、Embedding(IDから、そのトークンを表す分散表現ベクトル[言語の数値化]に変換)、Encoder RNN(ベクトルを順番に RNN に入力)から成る。
vec1をRNNに入力し、hidden state を出力 。このhidden state と次の入力 vec2 をまた RNN に入力してき
た hidden state を出力という流れを繰り返す 。
最後の vec を入れたときの hidden state を final state としてとっておく。この final state が thought vector と呼ばれ、入力した文の意味を表すベクトルとなる 。
Encoder RNNの構造
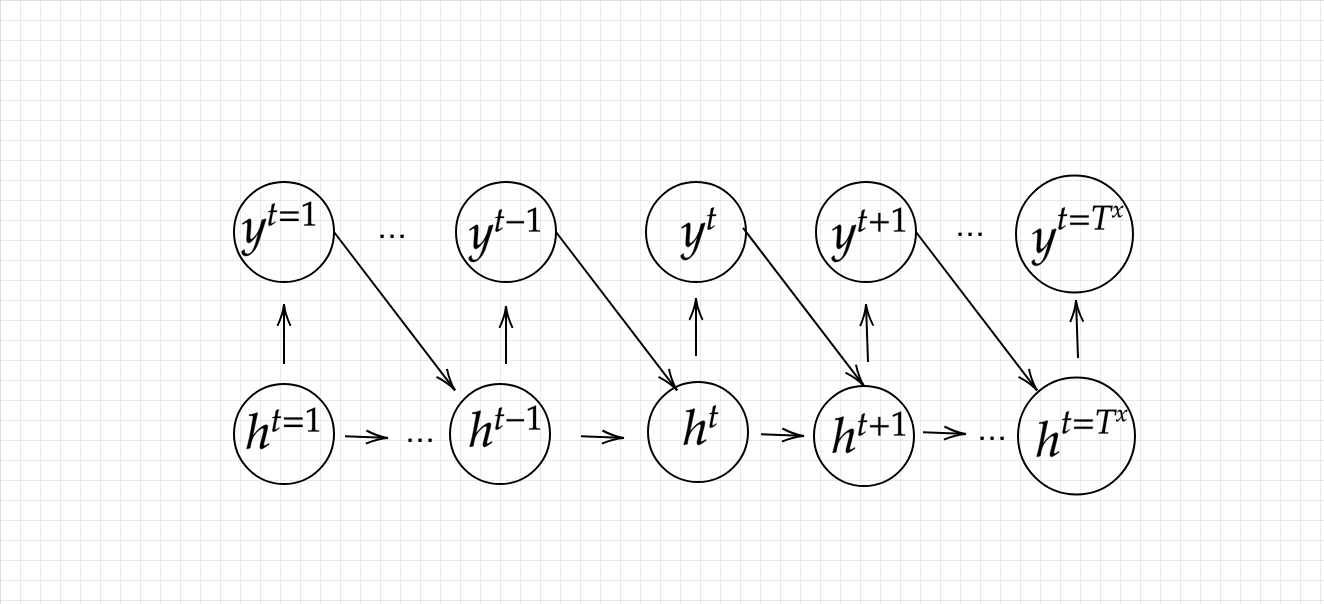
Decoder RNN
システムがアウトプットデータを単語等のトークンごとに生成する構造。
Decoder RNN: Encoder RNNの final state (thought vector) から、各token の生成確率を出力していく。final state を Decoder RNN のinitial state ととして設定し、 Embedding を入力。Sampling(生成確率にもとづいて token をランダムに選択)、Embedding(token を Embedding して Decoder RNN への次の入力)、Detokenize(この処理を繰り返しで得られたtokenを文字列に直す)から成る。
Decoder RNNの構造
<確認テスト>
下記の選択肢から、seq2seq について説明しているものを選べ。
1 時刻に関して順方向と逆方向の RNN を構成し、それら 2 つの中間層表現を特徴量として利用するものである。
2 RNN を用いた Encoder Decoder モデルの一種であり、機械翻訳などのモデルに使われる。
3 構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
4 RNN の一種であり、単純な RNN において問題となる勾配消失問題を CEC とゲートの概念を導入することで解決したものである。
(答え)2
<演習チャレンジ>
機械翻訳タスクにおいて、入力は複数の単語から成る文(文章)であり、それぞれの単語はone hotベクトルで表現されている。 Encoder において、それらの単語は単語埋め込みにより特徴量に変換され、そこから RNN によって(一般には LSTM を使うことが多い)時系列の情報をもつ特徴へとエンコードされる。以下は、入力である文(文章)を時系列の情報をもつ特徴量へとエンコードする関数である。ただし _activation 関数はなんらかの活性化関数を表すとする。(き)にあてはまるのは何か。
※one hotベクトル:一つの要素だけ「1」で残りは「0」のベクトル
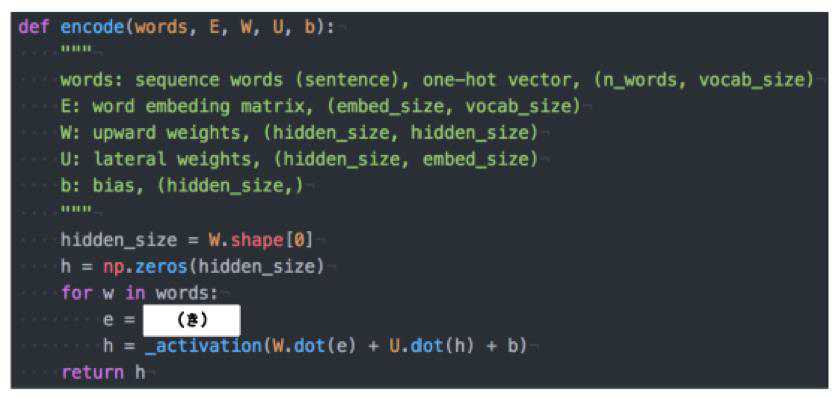
(答え)E.dot(w)
単語 w は one hot ベクトルであり、それを単語埋め込みにより別の特徴量に変換する。これは埋め込み行列Eを用いて、E.dot(w) と書ける。
HRED:Hierarchical Recurrent Encoder Decoder
https://qiita.com/iss-f/items/0b5a2766e789213b42c1
Seq2Seqには課題として、一問一答にしか対応できないという、コンテキストアウェアな対応ができないという問題がある。HREDでは、過去n-1個の発話から次の発話を生成する。Seq2seqでは、会話の文脈等を考慮しないで、応答がなされたが、HREDでは前の単語の流れに即して応答されるためより人間らしい文章が生成される。
HREDの構造
HREDでは、エンコーダーとデコーダーに加えて、文脈を学習するRNNを追加する。つまり、単語の時系列を予測するRNNと、文章の時系列を予測するRNNが階層的な構造になっている。HREDではSeq2SeqにEncoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造を持つContext RNNを組み合わせることで、過去の発話の履歴を加味した返答をできる階層的なRNNである。
HREDの課題
HREDには確率的な多様性が字面にしかなく、会話の「流れ」のような多様性が無い。同じコンテキスト(発話リスト)を与えられた場合、答えの内容が毎回会話の流れとしては同じものしか出せない。HREDは短く情報量に乏しい答えをしがちである。
VHRED
https://qiita.com/halhorn/items/646d323ac457715866d4
HREDに、 VAE(Variational Autoencoder)の潜在変数の概念を追加したもの。VAEとは標準正規分布からサンプリングした潜在変数zからデータを生成することのできるモデルである。標準正規分布から適当な潜在変数zをサンプリングしてVAEに入力することで、学習データをうまく補完したようなデータを生成可能。先に挙げたHREDの課題を、VAEの潜在変数の概念を追加することで解決した構造である。
<確認テスト>
https://qiita.com/halhorn/items/646d323ac457715866d4
seq2seqと HRED 、 HRED と VHRED の違いを簡潔に述べよ。
(答え)
〇seq2seqと HRED
Seq2Seqは一問一答しかできなかった。それを解決したのがHREDであり、n-1の過去状態を取り入れ、文脈に即した応答ができるようにした。
〇HREDとVHRED
同じ質問については同じ応答しかできなかった。VHREDではこれにVAEによるランダム性を取り入れ、会話の流れを表すContext RNN にノイズを乗せることで、同じコンテキストに対しても字面だけではない多様な返答ができるようにしたモデル。VHRED はコンテキストに対する返答のばらつきを Context RNN の確率的な幅で吸収することでそれらをうまく学習できる。
AE(Autoencoder:自己符号化器)
https://deepage.net/deep_learning/2016/10/09/deeplearning_autoencoder.html
教師なし学習の一つ。そのため学習時の入力データは訓練データのみで教師データは利用しない。入力データから潜在変数zに変換するニューラルネットワークをEncoderという。Encorderは入力を低次元に表現する。逆に潜在変数zをインプットとして元画像を復元するニューラルネットワークをDecoderという。Decorderは低次元から復元する能力を持つ。
入力と出力を同じデータにして学習することを考える。各層の入力データが同じ次元になるとしたら、データはただ単に出力層に向かってコピーされるだけである。しかし中間層の次元が入出力層より小さくなっていた場合、同様のデータを小さな情報量に圧縮する何らかの方法をニューラルネットワークは学習しないといけない。これこそがAutoencoderの処理であり、核となる次元削減である。
AIの牽引企業
Amazon:AWSの使いやすさ、価格面で現在一日の長がある。学習を回すときだけ、AIサーバを使えばよいので費用も抑えられる。
Google:tesorflowの開発元。ライブラリも充実。TPU等のハードウェアの開発も継続している。
PFN:Chainer、日本製。
TOYOTA:自動運転。
VAE
通常のオートエンコーダーの場合、何かしら潜在変数zにデータを押し込めているものの 、それはいわばブラックボックスでその構造がどのような状態かわからない。VAEはこの潜在変数zに確率分布z~N(0,1)を仮定している。VAEは、データを潜在変数zの確率分布という構造に押し込めることを可能にしている 。構造の詳細がわからないことは変わらないが、確率変数の中で、文脈に即してはいるが、違う応答が返ってくるという特性を持たせることができる。
※z~N(0,1):平均0、分散1の正規分布。標準正規分布を表すさいはzを使用する。
http://lbm.ab.a.u-tokyo.ac.jp/~omori/kokusai11/koku7b/koku11_0620.html
<確認テスト>
VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。自己符号化器の潜在変数に____を導入したもの。
(答え)確率分布
Word2vec
RNNでは、単語のような可変長の文字列をNNに与えることができない。よって固定長形式で単語を表現する必要がある。
https://www.randpy.tokyo/entry/word2vec_skip_gram_model
↑(非常にわかりやすいページです)
word2vecは、大量のテキストデータを解析し、各単語の意味をベクトル表現化する手法。ボキャブラリ数×任意の単語ベクトルの次元数の重み行列で表現。単語をベクトル化することで、単語同士の意味の近さを計算単語同士の意味を足したり引いたりということが可能になる。実際のword2vecの仕組みには大きく分けて「CBOW」「Skip-Gram Model」という2つの手法がある。
以下は、Skip-Gram Modelの例。
単語ベクトルを直接求めることは困難であるので、word2vecでは、ある偽のタスクを解くことを考え、その過程で間接的に計算していく。意味が近い(≒単語ベクトルの距離が近い)言葉は周辺語も似ていることが予想される。ということは、この二つの単語は比較的近い属性なのではないかということが予測可能である。「各単語はその周辺語と何らかの関係性がある」という考えを元に、「ある単語を与えた時にその周辺語を予測する」というタスクが前述した偽のタスクである。
Attention Mechanism
https://qiita.com/halhorn/items/614f8fe1ec7663e04bea
seq2seqの課題としては長い文章への対応が難しいという問題があった。seq2seqでは、2単語でも、100単語でも、固定次元ベクトルの中で表現しなければならない。文章が長くなるほどそのシーケンスの内部表現しなければならない情報が大きくなっていくので、何らかの仕組みが必要になる。Attention Mechanism ではこの問題に対して、「入力と出力のどの単語が関連しているのか」を学習させることで対応する。例えば機械翻訳の場合、ネットワークは翻訳前後の単語の対応関係を学習し、単語列の出力時に対応する入力の単語を引っ張ってくることで長い文書でも翻訳の精度をあげる。これが「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組み「Attention Mechanism」である。
<確認テスト>
RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ。
(答え)
〇RNNとword2vec
RNNではボキャブラリ数×ボキャブラリ数の重みを算出していたが、word2vecではボキャブラリ数×任意の単語ベクトルの次元数の重みベクトルで表現されており、重み生成軸が現実的な計算速度になっている。
〇seq2seqとAttention
seq2seqでは固定長の入力を対象としていたのに対し、Attention Mechanismを加えたものでは重要度・関連度という概念を取り入れることで、長い文章を入れた場合でも翻訳が成り立つ。