はじめに
これまで、推理小説家を作るため、seq2seqを使い色々やってきました。(前回、前々回)
seq2seqは、ある1つの文章から次に続く文章を予測します。したがって、一問一答となり、文脈を含む文章を生成することはできませんでした。推理小説ならば、読者を予想を裏切るようなトリックやミスリードなど文脈を考慮した文章が必要不可欠です。そこで、seq2seqに文脈を学習させる機構を追加したら良いのでは?という発想が浮かんでくるかと思います。
どんな機構を追加しようかと悩んでいたところ、the hierarchical recurrent encoder-decoderというもの発見したので、これを参考に文脈を考慮した文章生成を行えるモデルを作って見たいと思います。
論文はこちら
https://arxiv.org/pdf/1507.02221.pdf
https://arxiv.org/pdf/1507.04808.pdf
2つ目の論文は、1つ目のモデルを拡張したもののようです。具体的な処理や数式的がどのように変わったのかいまいち理解できてないので、こちらはもう少し読み進めてみようと思います。
HRED(the hierarchical recurrent encoder-decoder)
HREDとは、その名の通り階層的なRNNです。
これまで使ったseq2seqは、エンコーダーとデコーダーと呼ばれる2つのネットワークから構成されます。ある文章をエンコードし、エンコードされたベクトルをデコードすることで、文章を生成します。(白い四角形はRNNを表してます。)
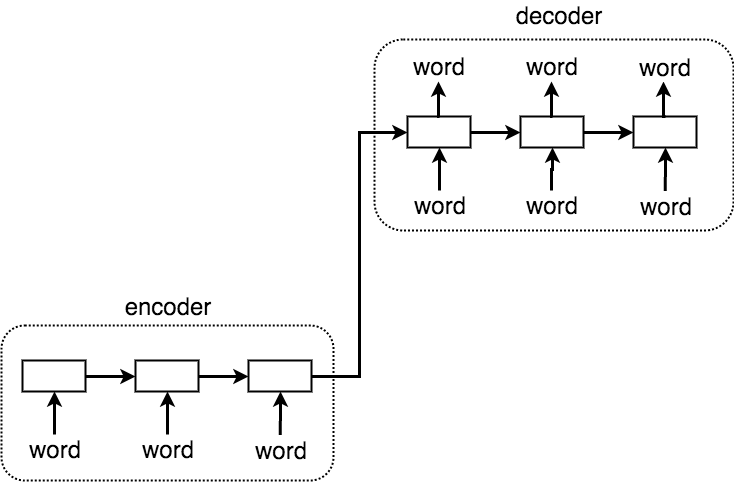
HREDでは、エンコーダーとデコーダーに加えて、文脈を学習するRNNを追加します。つまり、単語の時系列を予測するRNNと、文章の時系列を予測するRNNが階層的な構造になっているということです。
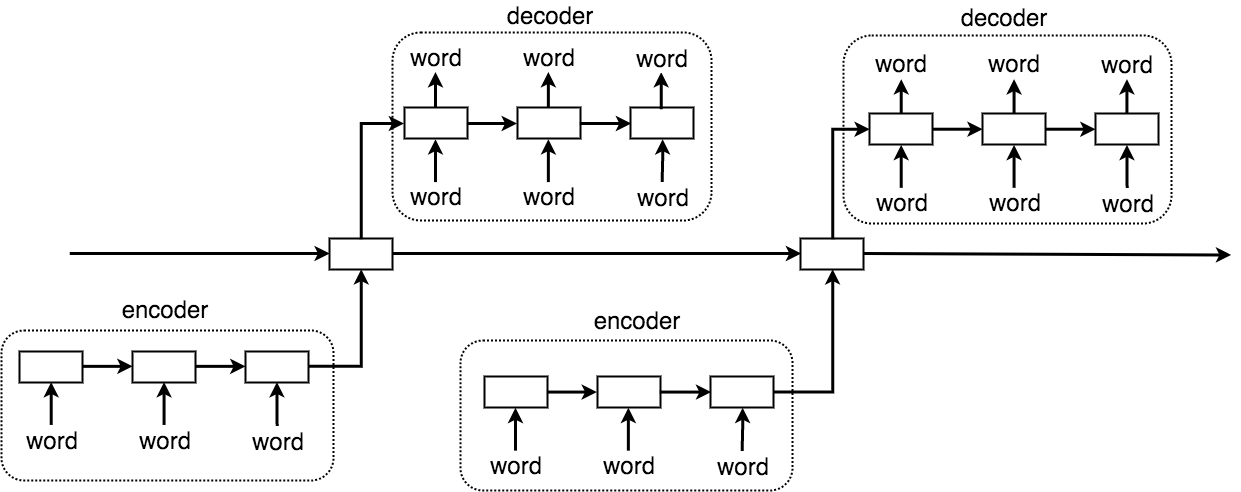
これにより、文脈を考慮した文章が生成できるはずです。
モデル
kreasでモデルを構築します。ひとまず自らの発想を信じて、論文は参考程度にとどめモデルを構築していきます。また、kerasで組む上で、いくつか妥協した点もあるので、論文のモデルを完全再現したものではないのでご注意を。
まずは、エンコーダーのモデルを定義します。ネットワークへの入力は、word2vecで単語をベクトルに直したものを入力としています。論文では、GRUを使っていましたが、ここでは、Bidirectional LSTMを使ってみます。
def build_encoder(self, model):
K.set_learning_phase(1)
encoder_inputs = Input(shape=(None, self.input_dim))
encoder_dense_outputs = Dense(self.input_dim, activation='sigmoid')(encoder_inputs)
encoder_bi_lstm = LSTM(self.latent_dim, return_sequences=True , dropout=0.6, recurrent_dropout=0.6)
encoder_bi_outputs = Bi(encoder_bi_lstm)(encoder_dense_outputs)
_, state_h, state_c = LSTM(self.latent_dim, return_state=True, dropout=0.2, recurrent_dropout=0.2)(encoder_bi_outputs)
return Model(encoder_inputs, [state_h, state_c])
次にデコーダーです。こちらもBidirectional LSTMを使って見ます。
def build_decoder(self):
K.set_learning_phase(1) # set learning phase
encoder_h = Input(shape=(self.latent_dim,))
encoder_c = Input(shape=(self.latent_dim,))
encoder_states = [encoder_h, encoder_c]
decoder_inputs = Input(shape=(None, self.input_dim))
decoder_dense_outputs = Dense(self.input_dim, activation='sigmoid')(decoder_inputs)
decoder_bi_lstm = LSTM(self.latent_dim, return_sequences=True, dropout=0.6, recurrent_dropout=0.6)
decoder_bi_outputs = Bi(decoder_bi_lstm)(decoder_dense_outputs)
decoder_lstm = LSTM(self.latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_bi_outputs, initial_state=encoder_states)
decoder_outputs = Dense(self.output_dim, activation='relu')(decoder_outputs)
decoder_outputs = Dense(self.output_dim, activation='linear')(decoder_outputs)
return Model([decoder_inputs, encoder_h, encoder_c], decoder_outputs)
本来、確率分布を得るため出力層はsoftmaxを用いるのですが、今回は、単語ベクトルを出力して欲しいため線形の全結合を用います。
文脈を学習するネットワークです。
def build_context_model(self):
K.set_learning_phase(1) #set learning phase
inputs = Input(shape=(None, self.latent_dim))
state_h_input = Input(shape=(self.latent_dim,))
state_c_input = Input(shape=(self.latent_dim,))
state_value = [state_h_input, state_c_input]
outputs, state_h, state_c = LSTM(self.latent_dim, return_state=True)(inputs, initial_state=state_value)
return Model([inputs, state_h_input, state_c_input], [outputs, state_h, state_c])
3つのInputlayerは、1つ目がencodeされたベクトル、2、3つ目がcontext_modelのLSTMの隠れ状態であるh、cを入力するものとなります。
エンコーダーとデコーダーとcontext_modelをつなぎ合わせます。
def build_autoencoder(self, encoder, decoder, context_h, context_c):
# encoder
encoder_inputs = Input(shape=(None, self.input_dim))
_, ed, eb, el = encoder.layers
dense_outputs = ed(encoder_inputs)
bi_outputs = eb(dense_outputs)
encoder_output, state_h, state_c = el(bi_outputs)
# context_h
_, _, _, clh = context_h.layers
meta_hh = Input(shape=(self.latent_dim,))
meta_hc = Input(shape=(self.latent_dim,))
meta_h_state = [meta_hh, meta_hc]
state_h = Reshape((1 , self.latent_dim))(state_h)
state_h_output, _, _ = clh(state_h, initial_state=meta_h_state)
# context_c
_, _, _, clc = context_c.layers
meta_ch = Input(shape=(self.latent_dim,))
meta_cc = Input(shape=(self.latent_dim,))
meta_c_state = [meta_ch, meta_cc]
state_c = Reshape((1 , self.latent_dim))(state_c)
state_c_output, _, _ = clc(state_c, initial_state=meta_c_state)
encoder_states = [state_h_output, state_c_output]
# decoder
decoder_inputs = Input(shape=(None, self.input_dim))
_, dd1, db, di2, di3, dl, dd2, dd3 = decoder.layers
decoder_dense_outputs = dd1(decoder_inputs)
decoder_bi_outputs = db(decoder_dense_outputs)
decoder_lstm_outputs, _ , _ = dl(decoder_bi_outputs, initial_state=encoder_states)
decoder_dense2_outputs = dd2(decoder_lstm_outputs)
outputs = dd3(decoder_dense2_outputs)
return Model([encoder_inputs, decoder_inputs, meta_hh, meta_hc, meta_ch, meta_cc], outputs)
encoder = build_encoder()
decoder = build_decoder()
context_h = build_context_model()
context_c = build_context_model()
auto_encoder = build_autoencoder(encoder, decoder, context_h, context_c)
encoder-decoderモデルを作るときは、重みを再利用したかったり、入力のみ別レイヤーを使いたかったりがあるので、毎回Modelに対してlayerを取り出し、再びつなぎ合わせるってことをしてるのですが、割と手間がかかり、コード量も増えるので困ってます。
単語選択
decoderの出力する単語ベクトルをword2vecを用いて単語に復元します。出力される単語ベクトルは、ランダム性のない単語ベクトルとなるため、類似単語5つの中から類似度の比率に応じてランダムに選択します。
学習データ
前回と同様に、word2vecにまず、青空文庫から以下の作家の
江戸川乱歩、夢野久作、大阪圭吉、小栗虫太郎、海野十三
の全小説を学習させます。
HREDには、江戸川乱歩の全小説を学習させます。
これで、推理小説家の語彙を兼ね備えた、江戸川乱歩の文脈、文章構成を学習するはずです。
データ数は、以下のようになります。
|江戸川乱歩|夢野久作|大阪圭吉|小栗虫太郎|海野十三|合計
-------------|--------|-----|------|------|------|------|------
文章数 |71713|56196|4702|14113|125607|272331
ユニーク単語数 |34316|43809|11501|23884|53419|166929
ファイルサイズは合計で38Mでした。
学習
最適化関数はRMSprop、損失関数はmean_squared_errorを用います。
batch size=1で、lossが約0.1になるまで1日ほどほったらかしで学習させました。
batch size=1なのは、連続文章を学習させるため、文章あたりの単語数を揃えることができず、batchを作れなかったためです。このあたりどのように実装しているのかプログラム漁ってみようと思いますが、とりあえず今回はbatch size=1で学習させてみます。
文章生成
いくつか妥協した点もありますが、とりあえず文章を生成させてみましょう。
江戸川乱歩の奇才っぷりが発揮され、文脈を考慮した素晴らしい文章が生成されるはずです。
10個の文章を生成します。
1つの文章は、15単語を超える、もしくは句点か文章の終了を表す記号EOSが出力されると1つの文章とします。
1回目
>> やろてよ申しあげるまそまそまそまアまアまそどうぞまそホホホホまアホホホホどうぞ
>> 嫌嫌アハハハちホホホホハハハハーッこらーッーッアラアラーッアラホホホホ
>> アハハハ嫌アハハハちええアラホホホホえホホホホホホホホーッえホホホホーッ
>> 嫌嫌恥こらアラハハハハえこらこらえーッえアラホホホホアラ
>> アハハハアハハハ嫌ちーッハハハハええこらこらアラアラえホホホホえ
>> アハハハアハハハアハハハちこらアラーッホホホホえアラこらこらホホホホーッえ
>> アハハハ恥アラアラアラアラこらこらアラこらーッホホホホえアラホホホホ
>> 嫌嫌アラちホホホホハハハハこらーッアラーッえアラホホホホホホホホーッ
>> 嫌アラアラちこらえアラホホホホーッホホホホえこらホホホホホホホホアラ
>> 嫌アラアハハハアラアラアラホホホホアラアラアラアラこらーッこら
2回目
>> 抱えよ申しあげるどうぞシラセナサイ嫌ホホホホ嫌まそまそどうぞ蒙るまそまそ嫌蒙る
>> アハハハハハハハアラちアラえーッホホホホーッホホホホホホホホえアラホホホホえ
>> 嫌アラサアサアアラこらええホホホホーッーッーッーッえホホホホーッ
>> そりゃアハハハアラちこらこらーッこらえこらーッアラホホホホアラアラ
>> アハハハハアハハハ嫌こらーッアラホホホホホホホホーッアラアラホホホホこらホホホホーッ
>> アラ恥恥アラこらアラアラこらアラアラホホホホーッこらえーッ
>> アハハハハ恥サアサアえアラハハハハアラこらこらこらーッえアラホホホホえ
>> アハハハアハハハ恥えーッーッこらホホホホーッえーッホホホホーッーッこら
>> そりゃまアアハハハちホホホホこらえホホホホこらホホホホこらこらこらアラアラ
>> アラまア恥アラこらーッホホホホこらえーッーッーッーッえア
笑い狂う奇才を生み出してしまいました.....
笑い続けるという意味では、文脈を考慮しているのでしょうか....
1つの文章を最大25単語までにして、再び文章を生成してみます。
>> 抱えよ申しあげる下さいまそまそホホホホ嫌まアましょまそまそシラセナサイどうぞシラセナサイホホホホシラセナサイまそまそホホホホホホホホシラセナサイまそまそどうぞホホホホ
>> アハハハまア嫌サアサアサアサアえこらこらえホホホホええホホホホえアラアラーッーッアラアラーッこらアラホホホホえ
>> アハハハ恥アラアラ御免なさいーッーッアラえホホホホこらーッホホホホえホホホホーッアラこらえーッこらーッえホホホホホホホホ
>> アラまアサアサア嫌御免なさいこらーッえホホホホホホホホーッこらアラアラーッーッホホホホーッーッホホホホホホホホええーッこら
>> 何もかも嫌サアサアホホホホ御免なさいアラこらアラホホホホホホホホアラえこらこらこらこらホホホホーッホホホホアラーッホホホホホホホホこらーッ
>> アハハハ嫌まアええこらーッこらホホホホこらえアラーッホホホホえーッこらーッえアラホホホホホホホホえホホホホえ
>> アハハハハ何もかもサアサアアラサアサアこらホホホホアラアラこらアラえーッえアラホホホホーッアラーッーッえーッえアラこら
>> 何もかもまアアラサアサア御免なさいアラこらホホホホえーッアラアラホホホホえアラこらえこらアラこらえええこらホホホホ
>> アハハハハ何もかもアハハハアラ御免なさいホホホホアラーッアラホホホホアラこらえこらこらホホホホええーッこらこらこらええーッ
>> 何もかも恥アラサアサアアラホホホホえええーッーッアラホホホホアラこらこらーッアラホホホホえーッアラーッアラこら
依然として笑い狂ってます....
1つの文章を最大5単語までにして、再び文章を生成してみます。
こうなると、もはや推理小説は諦めて、江戸川乱歩っぽいポエムや詩のようなものが生成されることを期待しましょう。
>> まアてよ申しあげるどうぞまア
>> アハハハ嫌アハハハ見やーッ
>> 嫌ーッーッアラハハハハ
>> アラ恥アラーッーッ
>> アラーッ見やーッーッ
>> アハハハハ恥アラ見やハハハハ
>> ハハハハハハハハハ見やえハハハハ
>> アハハハハーッ見やアラハハハハ
>> アハハハハハハハハアハハハハハハハハハハハ
>> アハハハ嫌ハハハハハハハハア
ただただ爆笑するだけの人になってしまいました......
なんでこんな笑ってばっかりなの....
まとめ
文脈を考慮した文章の生成ができる階層的なRNNであるHREDを用いて、推理小説家を作ってみました。
その結果、ただただ爆笑するという奇才が生まれてしまいました。僕の乱歩は何処へ.....
次は、論文を読み込んでモデルの調整を行ってみようと思います。