chainerでsequence to sequenceの実装をしたので、そのコードと検証
はじめに
RNN系のニューラルネットワークを使った文の生成モデルとして、有名なものにsequence to sequence(Seq2Seq)というものがあります。
今回はこのSeq2Seqをchainerを使って実装した際の方法と検証に結果についてまとめます。
Sequence to Sequence(Seq2Seq)
Seq2Seqとは、RNNを用いたEncoderDecoderモデルの一種であり、機械対話や機械翻訳などのモデルとして使用することができます。
元論文はこれ
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems. 2014.
Seq2Seqのフローの概略は以下のような感じ
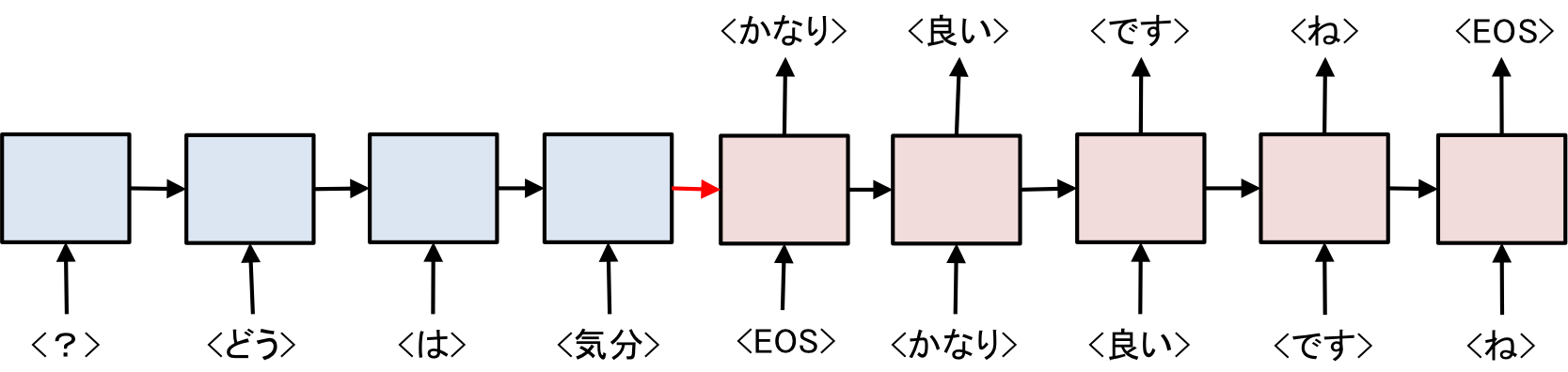
例えば、「気分はどう?」、「かなり良いですね」と言った発話と応答があった場合、Encoder(図中の青色)側で、発話をベクトル化し、Decoder(図中の赤色)側で、応答を生成するようにRNNの学習を行います。
「<'EOS'>」はEnd Of Statementの略で、文がここで終わりですよという合図。
Seq2Seqのポイントは発話を逆向きから入力することであり、「気分はどう?」という発話なら、「>、<どう>、<は>、<気分>」という順にEncoderに入力します。
Encoder側とDecoder側ではそれぞれ別々のEmbedを使い、生成された中間層(図中の赤線)のみを共有します。
Seq2SeqはRNN系のニューラルネットワークと書きましたが、今回はLong Short Term Memory(LSTM)を用いて実装しました。
LSTMの詳しい説明は、
http://qiita.com/t_Signull/items/21b82be280b46f467d1b
http://qiita.com/KojiOhki/items/89cd7b69a8a6239d67ca
あたりがわかりやすい。
LSTMのポイントはLSTM自体がメモリセル(記憶の集積みたいなもの)をもち、新たな入力がされた際に、メモリセルを、忘れる(Forget Gate)、覚える(Input Gate)、出す(Output Gate)という操作をする点です。
実装
今回はchainerを使ってSeq2Seqの実装した。
Seq2Seqをchainerで実装しているサンプルコードはたくさんあるが、今回はなるべくシンプルに書くように心がけた(つもりである)。
参考にしたコードは
https://github.com/odashi/chainer_examples
です。
oda様、いつもありがとうございます。
chainerでは、NNのモデルをクラスとして記述します。
Encoder
まず、発話をベクトルに変換するためのEncoder
class LSTM_Encoder(Chain):
def __init__(self, vocab_size, embed_size, hidden_size):
"""
クラスの初期化
:param vocab_size: 使われる単語の種類数(語彙数)
:param embed_size: 単語をベクトル表現した際のサイズ
:param hidden_size: 中間層のサイズ
"""
super(LSTM_Encoder, self).__init__(
# 単語を単語ベクトルに変換する層
xe = links.EmbedID(vocab_size, embed_size, ignore_label=-1),
# 単語ベクトルを隠れ層の4倍のサイズのベクトルに変換する層
eh = links.Linear(embed_size, 4 * hidden_size),
# 出力された中間層を4倍のサイズに変換するための層
hh = links.Linear(hidden_size, 4 * hidden_size)
)
def __call__(self, x, c, h):
"""
Encoderの動作
:param x: one-hotなベクトル
:param c: 内部メモリ
:param h: 隠れ層
:return: 次の内部メモリ、次の隠れ層
"""
# xeで単語ベクトルに変換して、そのベクトルをtanhにかける
e = functions.tanh(self.xe(x))
# 前の内部メモリの値と単語ベクトルの4倍サイズ、中間層の4倍サイズを足し合わせて入力
return functions.lstm(c, self.eh(e) + self.hh(h))
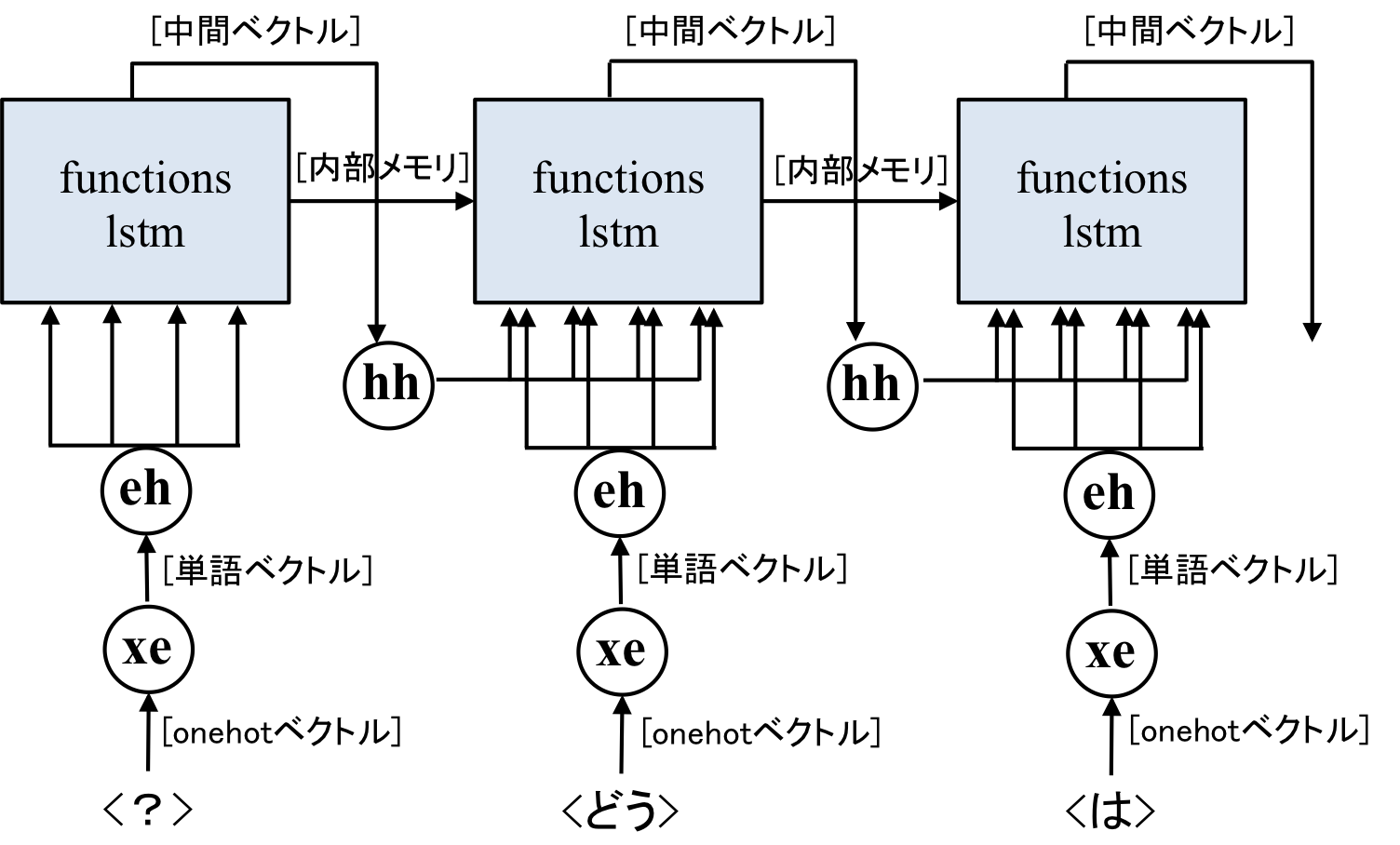
Encoderのポイントは、なぜ指定した隠れ層の4倍のサイズにベクトルを変換しているのかという点にある。
chainerの公式ドキュメントに記載では、

とある。
つまり、「入力されたベクトルをforget用、input用、output用、cell用に分けるから4倍のサイズにしてね」ということである。
chainerのfunctions.lstmでは、関数の計算を行ってくれるだけで、ネットワークの学習は行ってくれない。そこで、コード中のehやhhが代わりにその役割をしています。
実はこんなめんどくさいことしなくてもchainerにはlinks.LSTMという、入力さえ入れれば、出力だけを出して、学習までしてくれる便利なクラスが存在するのだが、今回は使用しませんでした。
なぜなら隠れ層の値をEncoderとDecoderで共有させたいから(それでもlinks.LSTMが使えるとは思うが、今回は今後のためということで・・・)。
なので計算のイメージはこんな感じ、線が重なって見にくいですが・・・
Decoder
次にDecoderについて、
class LSTM_Decoder(Chain):
def __init__(self, vocab_size, embed_size, hidden_size):
"""
クラスの初期化
:param vocab_size: 使われる単語の種類数(語彙数)
:param embed_size: 単語をベクトル表現した際のサイズ
:param hidden_size: 中間ベクトルのサイズ
"""
super(LSTM_Decoder, self).__init__(
# 入力された単語を単語ベクトルに変換する層
ye = links.EmbedID(vocab_size, embed_size, ignore_label=-1),
# 単語ベクトルを中間ベクトルの4倍のサイズのベクトルに変換する層
eh = links.Linear(embed_size, 4 * hidden_size),
# 中間ベクトルを中間ベクトルの4倍のサイズのベクトルに変換する層
hh = links.Linear(hidden_size, 4 * hidden_size),
# 出力されたベクトルを単語ベクトルのサイズに変換する層
he = links.Linear(hidden_size, embed_size),
# 単語ベクトルを語彙サイズのベクトル(one-hotなベクトル)に変換する層
ey = links.Linear(embed_size, vocab_size)
)
def __call__(self, y, c, h):
"""
:param y: one-hotなベクトル
:param c: 内部メモリ
:param h: 中間ベクトル
:return: 予測単語、次の内部メモリ、次の中間ベクトル
"""
# 入力された単語を単語ベクトルに変換し、tanhにかける
e = functions.tanh(self.ye(y))
# 内部メモリ、単語ベクトルの4倍+中間ベクトルの4倍をLSTMにかける
c, h = functions.lstm(c, self.eh(e) + self.hh(h))
# 出力された中間ベクトルを単語ベクトルに、単語ベクトルを語彙サイズの出力ベクトルに変換
t = self.ey(functions.tanh(self.he(h)))
return t, c, h
Decoderでも同じくベクトルを4倍のサイズにします。違う点は、出力された中間ベクトルを語彙数のサイズのベクトルに変換する点。
したがって、Encoderにはなかった、he、eyという層が必要になります。
この計算のイメージを図にすると以下の感じ
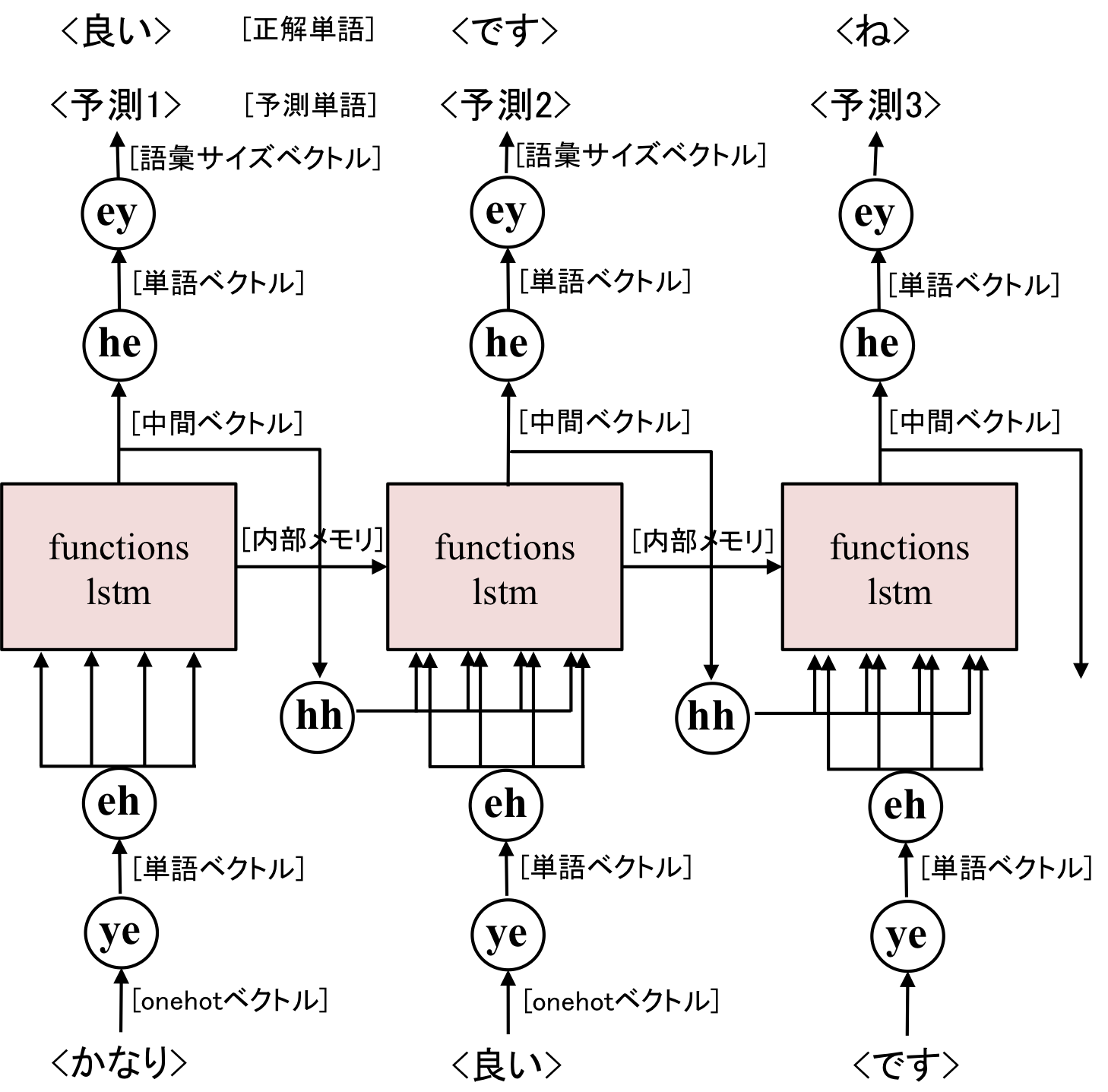
Decorderで、出力されたベクトルを使ってバックプロパゲーションを行います。
Seq2Seq
これらのEncoder, Decoderを組み合わせて作成したSeq2Seqが以下のコードになります。
class Seq2Seq(Chain):
def __init__(self, vocab_size, embed_size, hidden_size, batch_size, flag_gpu=True):
"""
Seq2Seqの初期化
:param vocab_size: 語彙サイズ
:param embed_size: 単語ベクトルのサイズ
:param hidden_size: 中間ベクトルのサイズ
:param batch_size: ミニバッチのサイズ
:param flag_gpu: GPUを使うかどうか
"""
super(Seq2Seq, self).__init__(
# Encoderのインスタンス化
encoder = LSTM_Encoder(vocab_size, embed_size, hidden_size),
# Decoderのインスタンス化
decoder = LSTM_Decoder(vocab_size, embed_size, hidden_size)
)
self.vocab_size = vocab_size
self.embed_size = embed_size
self.hidden_size = hidden_size
self.batch_size = batch_size
# GPUで計算する場合はcupyをCPUで計算する場合はnumpyを使う
if flag_gpu:
self.ARR = cuda.cupy
else:
self.ARR = np
def encode(self, words):
"""
Encoderを計算する部分
:param words: 単語が記録されたリスト
:return:
"""
# 内部メモリ、中間ベクトルの初期化
c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
# エンコーダーに単語を順番に読み込ませる
for w in words:
c, h = self.encoder(w, c, h)
# 計算した中間ベクトルをデコーダーに引き継ぐためにインスタンス変数にする
self.h = h
# 内部メモリは引き継がないので、初期化
self.c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
def decode(self, w):
"""
デコーダーを計算する部分
:param w: 単語
:return: 単語数サイズのベクトルを出力する
"""
t, self.c, self.h = self.decoder(w, self.c, self.h)
return t
def reset(self):
"""
中間ベクトル、内部メモリ、勾配の初期化
:return:
"""
self.h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
self.c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
self.zerograds()
Seq2Seqクラスを使った順伝播の計算は以下のように行う。
def forward(enc_words, dec_words, model, ARR):
"""
順伝播の計算を行う関数
:param enc_words: 発話文の単語を記録したリスト
:param dec_words: 応答文の単語を記録したリスト
:param model: Seq2Seqのインスタンス
:param ARR: cuda.cupyかnumpyか
:return: 計算した損失の合計
"""
# バッチサイズを記録
batch_size = len(enc_words[0])
# model内に保存されている勾配をリセット
model.reset()
# 発話リスト内の単語を、chainerの型であるVariable型に変更
enc_words = [Variable(ARR.array(row, dtype='int32')) for row in enc_words]
# エンコードの計算 ⑴
model.encode(enc_words)
# 損失の初期化
loss = Variable(ARR.zeros((), dtype='float32'))
# <eos>をデコーダーに読み込ませる (2)
t = Variable(ARR.array([0 for _ in range(batch_size)], dtype='int32'))
# デコーダーの計算
for w in dec_words:
# 1単語ずつデコードする (3)
y = model.decode(t)
# 正解単語をVariable型に変換
t = Variable(ARR.array(w, dtype='int32'))
# 正解単語と予測単語を照らし合わせて損失を計算 (4)
loss += functions.softmax_cross_entropy(y, t)
return loss
この計算の流れを図示するとこんな感じ
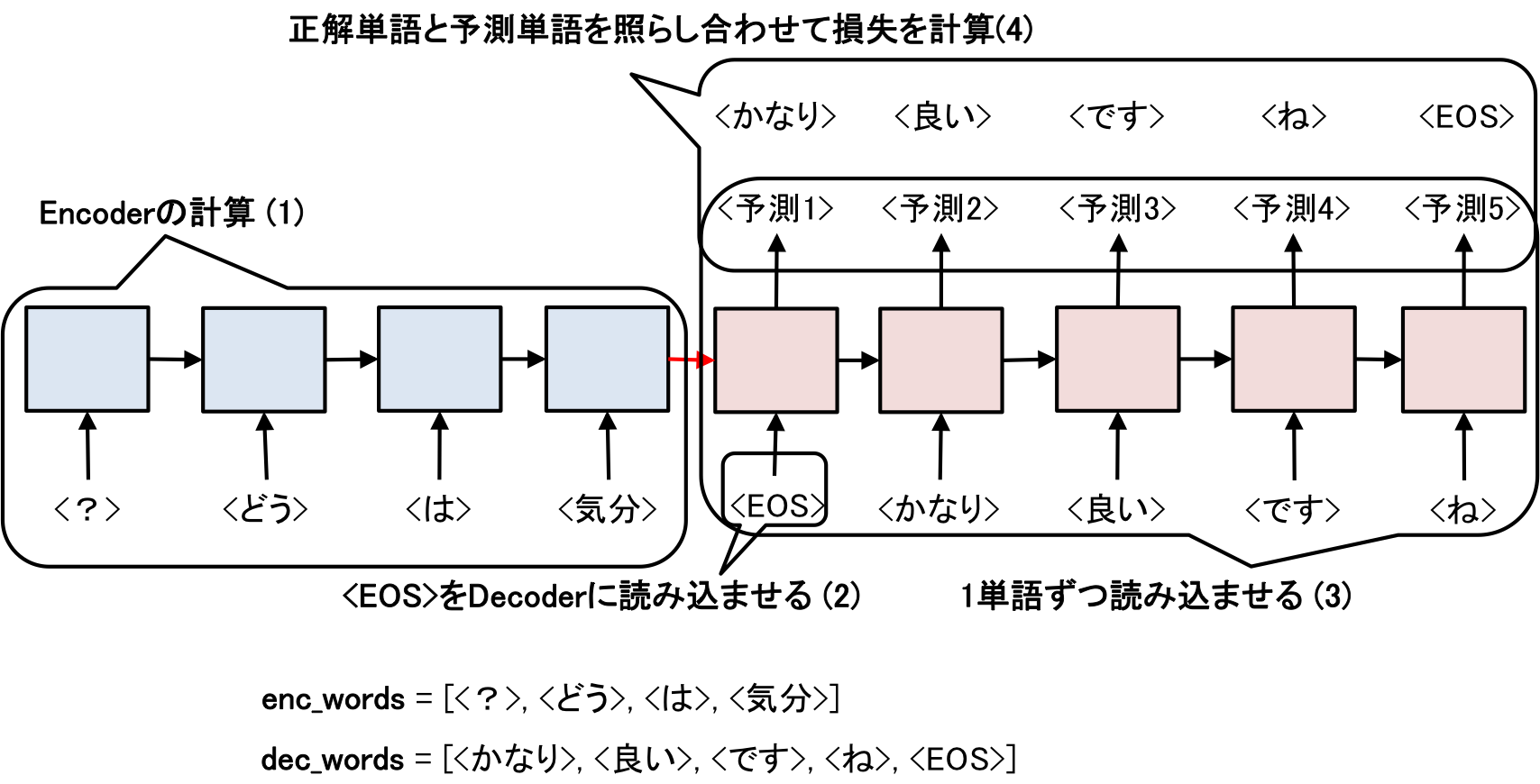
学習させるenc_words、dec_words内の単語はあらかじめID化(数字に直す)する必要があります。
損失の計算にはsoftmax関数を使ってます。
あとはforwardで計算した損失をchainerに学習させて、ネットワークを更新、という繰り返しを行うだけ。
学習のメインのコードを記述すると以下のようになります。
def train():
# 語彙数の確認
vocab_size = len(word_to_id)
# モデルのインスタンス化
model = Seq2Seq(vocab_size=vocab_size,
embed_size=EMBED_SIZE,
hidden_size=HIDDEN_SIZE,
batch_size=BATCH_SIZE,
flag_gpu=FLAG_GPU)
# モデルの初期化
model.reset()
# GPUを使うかどうか決める
if FLAG_GPU:
ARR = cuda.cupy
# モデルをGPUのメモリに入れる
cuda.get_device(0).use()
model.to_gpu(0)
else:
ARR = np
# 学習開始
for epoch in range(EPOCH_NUM):
# エポックごとにoptimizerの初期化
# 無難にAdamを使います
opt = optimizers.Adam()
# モデルをoptimizerにセット
opt.setup(model)
# 勾配が大きすぎる場合に調整する
opt.add_hook(optimizer.GradientClipping(5))
# あらかじめ作っておいた学習データの読み込み
data = Filer.read_pkl(path)
# データのシャッフル
random.shuffle(data)
# バッチ学習のスタート
for num in range(len(data)//BATCH_SIZE):
# 任意のサイズのミニバッチを作成
minibatch = data[num*BATCH_SIZE: (num+1)*BATCH_SIZE]
# 読み込み用のデータ作成
enc_words, dec_words = make_minibatch(minibatch)
# 順伝播で損失の計算
total_loss = forward(enc_words=enc_words,
dec_words=dec_words,
model=model,
ARR=ARR)
# 誤差逆伝播で勾配の計算
total_loss.backward()
# 計算した勾配を使ってネットワークを更新
opt.update()
# 記録された勾配を初期化する
opt.zero_grads()
# エポックごとにモデルの保存
serializers.save_hdf5(outputpath, model)
かなり長かったですがコードの説明は以上。
ちなみに作成したコードは
https://github.com/kenchin110100/machine_learning/blob/master/sampleSeq2Sep.py
にあります。
実験
コーパス
対話破綻コーパス
https://sites.google.com/site/dialoguebreakdowndetection/chat-dialogue-corpus
を使用しました。
ほんとはもっと長いコーパスで学習したかったんですが、学習に時間がかかりすぎて諦めました・・・
実験結果
発話内容は以下の4つ
- token1 = 'おはよう'
- token2 = '調子はどうですか?'
- token3 = 'お腹が空きました'
- token4 = '今日は暑いです'
Epochごとにモデルの精度を見ていきましょう
まず1 Epoch
発話: おはよう => 応答: ['はい', '</s>']
発話: 調子はどうですか? => 応答: ['退屈', 'は', '好き', 'です', 'ね', '</s>']
発話: お腹が空きました => 応答: ['そう', 'です', '</s>']
発話: 今日は暑いです => 応答: ['そう', 'です', '</s>']
哲学者ですか?
次に3 Epoch
発話: おはよう => 応答: ['おはよう', 'ござい', 'ます', '</s>']
発話: 調子はどうですか? => 応答: ['スイカ', 'は', '大好き', 'です', 'ね', '</s>']
発話: お腹が空きました => 応答: ['そう', 'な', 'ん', 'です', 'か', '?', '</s>']
発話: 今日は暑いです => 応答: ['何', 'か', 'に', '行っ', 'て', 'ます', 'か', '?', '</s>']
どこにも行ってません・・・
5 Epoch
発話: おはよう => 応答: ['おはよう', 'ござい', 'ます', '</s>']
発話: 調子はどうですか? => 応答: ['海', 'は', '一', '人', 'で', '行っ', 'て', 'ます', 'か', '?', '</s>']
発話: お腹が空きました => 応答: ['うん', '</s>']
発話: 今日は暑いです => 応答: ['何', 'を', '食べ', 'まし', 'た', 'か', '?', '</s>']
海にも行ってません・・・
8 Epochなら・・・
発話: おはよう => 応答: ['おはよう', 'ござい', 'ます', '</s>']
発話: 調子はどうですか? => 応答: ['クラゲ', 'は', 'いい', 'です', 'ね', '</s>']
発話: お腹が空きました => 応答: ['同じく', '</s>']
発話: 今日は暑いです => 応答: ['熱中症', 'に', '気', 'を', 'つけ', 'ない', 'ん', 'です', 'か', '?', '</s>']
だいぶ惜しくなってきましたが、このくらいが限界でしょうか・・・
これ以上のEpochも試して見ましたが、あんまり精度は変わらなかったです。
結論
chainerを使って今更Seq2Seqの実装をしました。
もっと大きいコーパスを使えば精度が良くなりそうですが、計算量が大きくなりすぎるとなかなか収束しません・・・
ちなみにタイトルに(1)とつけたのは第2弾、第3弾を考えているからです!!
次は、このSeq2SeqにAttentionをつけたいと思います。