$\def\bm{\boldsymbol}$
概要
- オンラインで開催している『モデルベース深層学習と深層展開』読み会で得られた知見や気づきをメモしていく
- ついでに、中身の理解がてらJuliaサンプルコードをPythonに書き直したコードを晒していく
- 自動微分ライブラリにはJAXを使用する
第4回
大まかな内容
- インクリメンタル学習について
- 一般的な最適化問題を勾配法で解く際に深層展開を利用する例について
議論になったこと
3.2.3節 あたり
- インクリメンタル学習の恩恵について
- 実際これをやると勾配消失が起きにくくなることは経験的に多い
- 勾配法の例においては、一括学習でやると、勾配降下の初期において使われる若い$t$の$\eta^{(t)}$まで誤差がうまく帰ってこないので、大きい$t$の$\eta^{(t)}$の学習はうまくいっても、それを使うところまで勾配降下出来ないみたいなことが起きる?
- インクリメンタルを上げていったとき、若い$t$の方のパラメタは固定にして更新しないって方法の方がいい性能が出るのでは
- その他、勾配消失まわりの議論
- 普通のNNの場合スキップコネクションなどで勾配消失を避ける手法がよく使われるが、モデルベース深層学習の場合は、モデルに縛られる分そのようなテクニックが使えないのではないか
- そもそも普通のNNで勾配消失の原因のひとつとなってる活性化関数の微分のよろしくない挙動は、深層展開の場合は誰が起こしている?
- この節の場合、目的関数の微分$\nabla f(\bm{x})$?
3.2.4節 あたり
- P62の"確率モデルが陽に与えられている場合"とは式(3.29)が観測方程式だとしたら、$\bm{A}$や$\bm{n}$の分布が分かってるみたいなことでおけ?
- ->多分そう
- 生成モデルと組み合わせる例の利点ってどこにある?
- ->議論する時間なし
- ->私の考えは、”個人的な気づき”に記入
- ->議論する時間なし
3.3.1節 あたり
- 図3.8の結果は学習時とは問題インスタンスで評価したMSEで汎化性能的なものを比較しているという理解でよい?
- ->いいと思う
- 周期条件やその定数$T$について
- 周期条件を入れる理由って?
- 深層展開が”反復処理”を時間展開したものってとこから来てる説
- 学習対象のパラメタ空間を意図的に狭める事で収束しやすくしている説
- $T$を大きくしすぎると過学習をしやすくなる(正則化の機能を果たしている)説
- 一般的な勾配法を考えると、「最初はステップでかくて、谷の近くでステップ小さく」ってカンジがいいとか言われるから、こんなにジグザグするのはあんま良さそうに感じない(ので不思議)
- 図3.11の右上の凡例は誤植だよね?要らんよね?
- ->多分そう
- 周期条件を入れる理由って?
3.3.4節 あたり
- 式(3.41)や式(3.33)に出てくる疑似逆行列について
- 最小二乗法の解析解に自然現れてくる行列であって、疑似逆行列で最適解を出しているという(ファシリテーター(私)の)理解は順番が逆
- 図3.13の結果はパラメタ$\lambda$を$2$とかにしたら$2$に収束するのか
- ->実際やってみたらそうなった
- はじめのほうに一度$\lambda=0$を経由するのが面白い
- 最初の方は正則化かけずに自由に最適化させてみるのがいいってこと?
- ハイパーパラメータの探索ってどうやるのがよい?
- ->optunaとか使いつつ、ある程度絞ったらグリッドサーチとかやってる。RLレンジテストというものもあるらしい
- 結局どこまでやればいいのかは分からない場合が多い
- ->optunaとか使いつつ、ある程度絞ったらグリッドサーチとかやってる。RLレンジテストというものもあるらしい
個人的な気づきなど
- 疑似逆行列が出てくるとこの経緯はちゃんと把握出来てなかったので、質問できて良かった。
- 3.2.4節の最後の深層生成モデルと深層展開の組み合わせの話は面白い話題。
- 議論の時間が取れなかったが、最後に「組み合わせる利点は?」という問いかけがあった
- 「データの生成過程のモデリングが深層生成モデルで出来てるなら、他に何を深層展開で学習するのか」的な意図の問いかけだと理解したが、個人的には深層生成モデルでは、物理的意味などのドメイン知識を残しながら学習させるのが難しいので、そのへんの気持ちを入れたい部分はモデルベースに深層展開、そもそもが外乱に近い部分の生成過程は深層生成モデルで扱うみたいな使い方なのでは?と想像している。(つまり、具体的な方法は想像ついてない^^;)
- 議論の時間が取れなかったが、最後に「組み合わせる利点は?」という問いかけがあった
プログラムでの理解
問題設定
- 最小自乗問題をリッジ正則化付きの最適化で解く
- $\bm{y} = \bm{A}\bm{x}$という連立方程式があり、$\bm{y}\in\mathbb{R}^{m},\bm{A}\in\mathbb{R}^{m\times n}$が与えられたときの$\bm{x}\in\mathbb{R}^{n}$を求めたい
- $m>n$のとき、決定変数より等式の数が多くなり、$\bm{A}$がランク落ちしない限り唯一解は存在しない
- そこで、妥当な解を得るために$||\bm{y} - \bm{A}\bm{x}||^2$を最小化する$\bm{x}$を求める
- 目的関数はリッジ正則化項を加えて$\frac{1}{2}||\bm{y} - \bm{A}\bm{x}||^2+\frac{\lambda}{2}||\bm{x}||^2$
- $\lambda$は正則化係数
- $m>n$のとき、決定変数より等式の数が多くなり、$\bm{A}$がランク落ちしない限り唯一解は存在しない
- DU-GD法では以下のように逐次的に$\bm{x}$を更新し停留点に収束させ、$\eta^{(t)},\lambda^{(t)}$を学習により獲得する
- $\bm{x}^{(t+1)}\gets\bm{x}^{(t)} - \eta^{(t)} \bm{A}^{T}(\bm{A}\bm{x}^{(t)}-\bm{y})+\lambda^{(t)}\bm{x}^{(t)}$
- 教師データとして、正則化左側疑似逆行列$\bm{A}^{\dagger}=(\bm{A}^T\bm{A}+\lambda\bm{I})^{-1}\bm{A}^T$を使って算出した以下の$\bm{x}^{\text{opt}}$を用いる
- $\bm{x}^{\text{opt}}=\bm{A}^{\dagger}\bm{y}$
- この$\bm{A}^{\dagger}$は最小二乗法の解析解として自然と現れるものである(と勉強会の中でわかった)
- 学習の目的は、学習時と別の$\bm{y}$が与えられたときも高速に勾配を下る事ができる$\eta^{(t)},\lambda^{(t)}$を獲得する事。($\bm{A}$は問題アンサンブルで変動するわけではなく固定なので注意)
- $\bm{y} = \bm{A}\bm{x}$という連立方程式があり、$\bm{y}\in\mathbb{R}^{m},\bm{A}\in\mathbb{R}^{m\times n}$が与えられたときの$\bm{x}\in\mathbb{R}^{n}$を求めたい
Pythonで実装
必要ライブラリインポート
import numpy as np
import numpy.linalg as LA
import jax
import jax.numpy as jnp
from jax.example_libraries import optimizers
from tqdm.notebook import trange
from functools import partial
グローバル定数
n = 50
m = 100
num_itr = 50
K = 100
Rambda = 3.0 #学習しない場合に使う正則化係数
A = np.random.randn(m, n)
- $\bm{A}$はガウス分布で生成したもの
x^optの生成関数
Pinv = LA.inv(A.T @ A + Rambda * np.eye(A.shape[-1]) ) @ A.T
def gen_x_opt(y):
return Pinv @ y
batch_gen_x_opt = jax.vmap(gen_x_opt, in_axes=-1,out_axes=-1)
勾配降下反復関数の定義
@partial(jax.jit, static_argnums=0)
def DU_GD(max_itr, y, eta, xi, enable_xi):
x = jnp.zeros((n, K))
for i in range(max_itr):
k = (i % T)
tmp = jnp.where( enable_xi == True, jnp.abs(xi[i]), Rambda )
x -= eta[k] * (A.T @ (A @ x -y) + tmp * x)
return x
- $\lambda$を学習するかしないかを選べるようにしているが、True,Falseでif文を書くとjit化したときにうまくコンパイル出来ないことがあるので、
jnp.where関数を使ってif分岐させている
誤差関数の定義
def get_dot(x):
return x @ x.T
batch_get_dot = jax.vmap(get_dot, in_axes=-1, out_axes=-1)
@partial(jax.jit, static_argnums=1)
def loss(x_opt, max_itr, y, enable_xi, eta, xi):
x_hat = DU_GD(max_itr, y, eta, xi, enable_xi)
return jnp.sum(batch_get_dot(x_opt - x_hat))/K
- 平均自乗誤差
学習
opt_init1, opt_update1, get_params1 = optimizers.adam(adam_lr1)
opt_init2, opt_update2, get_params2 = optimizers.adam(adam_lr2)
# @jax.jit
def step(x_opt, max_itr, y, step, opt_state, opt_update, eta, xi, grad_arg_num):
value, grads = jax.value_and_grad(loss, argnums=grad_arg_num)(x_opt, max_itr, y, enable_xi, eta, xi)
new_opt_state = opt_update(step, grads, opt_state)
return value, new_opt_state
def train(eta, xi, enable_xi):
opt_state1 = opt_init1(eta)
opt_state2 = opt_init2(xi)
for itr in trange(num_itr, leave=False):
for i in range(max_inner):
y = np.random.randn(m, K)
x_opt = jnp.array(batch_gen_x_opt(y))
value, opt_state1 = step(x_opt, itr+1, y, i, opt_state1, opt_update1, get_params1(opt_state1), get_params2(opt_state2), -2)
if(enable_xi):
_, opt_state2 = step(x_opt, itr+1, y, i, opt_state2, opt_update2, get_params1(opt_state1), get_params2(opt_state2), -1)
print("\r"+"\rloss:{}".format(value), end=" ")
return get_params1(opt_state1), get_params2(opt_state2)
T = 4
enable_xi = False
eta_init = jnp.zeros(num_itr)
xi_init = Rambda * jnp.ones(num_itr)
eta_trained, xi_trained = train(eta_init, xi_init, enable_xi)
- 2つの学習パラメタを連結してひとつのベクトルにして学習させることもできるが、今回は"片方は学習させない"といった事も試すためにoptimizerのインスタンスを2つ作っている
- また、教科書でも触れているように、異なる学習率を適用させたいという意図もある
-
Tは勉強会の中でも議論した周期条件のハイパーパラメータ。実装としては前回も出てきている。
結果
- 評価は以下の関数で行う
def comp_mse_DUGD(max_itr, eta, xi, enable_xi):
y = np.random.randn(m, K)
x_opt = jnp.array(batch_gen_x_opt(y))
return loss(x_opt, max_itr, y, enable_xi, eta, xi)
-
$\bm{y}$を乱数生成し直すことが、新しい問題インスタンスを生成することに相当するという理解
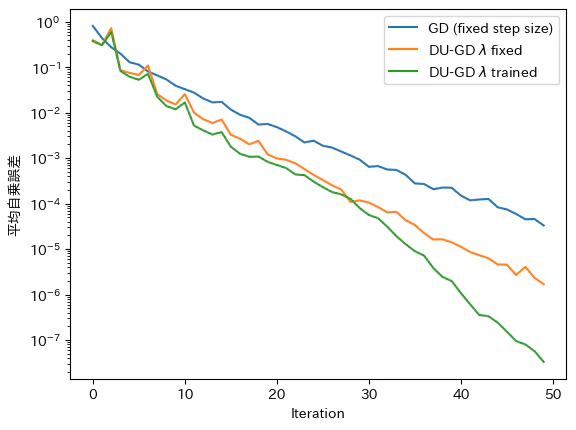
-
教科書と似た結果が得られた
- 深層展開を用いない方の実装などは、プログラム全文を参照
その他
- 勉強会後の雑談にて、深層展開の研究例関連の話ができて楽しかった
バックナンバー
- 『モデルベース深層学習と深層展開』読み会 レポート(開催前準備編)
- 『モデルベース深層学習と深層展開』読み会レポート#0
- 『モデルベース深層学習と深層展開』読み会レポート#1
- 『モデルベース深層学習と深層展開』読み会レポート#2
- 『モデルベース深層学習と深層展開』読み会レポート#3