$\def\bm{\boldsymbol}$
概要
- オンラインで開催している『モデルベース深層学習と深層展開』読み会で得られた知見や気づきをメモしていく
- ついでに、中身の理解がてらJuliaサンプルコードをPythonに書き直したコードを晒していく
- 自動微分ライブラリにはJAXを使用する
第3回
大まかな内容
- 勾配法に深層展開を適用する方法について
- 停留点への高速な収束を実現するのに最適なステップサイズ系列を深層展開を用いて獲得する
- 今後の教科書に出てくる問題設定の多くに共通の”問題アンサンブル”の概念について
- 特定のひとつの最適化問題の解を導くのではなく、ある分布に従って生成される問題集合について、解の誤差の期待値を最小化していくというスタンスで考える
議論になったこと
3.1.1節 あたり
- 一次元探索技法というのは、具体的にはAdam法とかモメンタム法とか?
- ->結論出ず
3.1.2節 あたり
- 勾配法のステップサイズを取得するのにAdamオプティマイザ(やはり勾配法)を使っているのが、なんか一瞬気持ち悪くみえたり、メタくて困惑する
- しかし重要なのは、あくまで学習後に得たいのは、「ある分布をもつ最適化問題に対して性能のよいステップサイズ系列」であり、学習後はそれが固定で使われるということ
- P49の「誤差関数は探索点と真の最適解との誤差」的な書きぶりが気持ち悪い。最適化問題の解を知っている前提なのか
- ->後の節の問題アンサンブル(3.2.1節)の内容に関係するのでそちらに記す
- サンプルコードを眺めながら
- Adamオプティマイザのハイパーパラメータによって結構収束性が結構変わるね
3.1.3節 あたり
- トータルで、計算量が少なくなるわけではないよね
- ->そう。あくまで、何らかの方法で$\eta$を得た後の勾配法の収束速度が早くなる話。$\eta$を得るための計算量を含めると深層展開の方が大きいはず。
- サンプルコードを眺めながら
- 内側のループと外側のループの役割の違いは?
- ->外側は通常の繰り返し学習数であり、インクリメンタル学習ではこの数に応じて、勾配を下る回数が増えていく。内側ループは、ある降下回数で複数回学習を回すというTipsのひとつっぽい(詳しくは次回扱う内容)
- 内側のループと外側のループの役割の違いは?
3.2.1節 あたり
- 問題アンサンブルとその実現値問題インスタンスについて
- 確率変数を内部に持っていて、特定の分布に従って最適化問題が生成されるようなものを考えていて、学習の目的はその問題集合に対して解の誤差の期待値を最小化すること
- そのため、問題インスタンスとして、解の分かっている問題が教師データ的に与えられる事もある(3.1.2節の違和感の正体)
- そういう問題設定って具体的にはどんなイメージ?
- 無線通信において、ノイズが混じるのは分かっていて、受信側で受け取り方を工夫して補完したい。実際のノイズは毎回変わるので受信側が解く問題も毎回変わるのだが、ノイズの混じり方を統計的手法などでモデリングする事ができれば、全体として問題アンサンブル的に考えられるのでは?
- 確率変数を内部に持っていて、特定の分布に従って最適化問題が生成されるようなものを考えていて、学習の目的はその問題集合に対して解の誤差の期待値を最小化すること
- 式(3.16)の$\bm{x}_{opt}$は、ある問題インスタンスの最適解という理解でよい?
- たぶんそう。
3.2.2節 あたり
- P58の”確率変数組$\mathcal{V}$の確率モデルが既知の場合に実現値をサンプリングしてからミニバッチを作る話”と”有限データからミニバッチを作る話”の理解について
- 一般的な観測データからの機械学習は後者であることが多いが、教科書では前者のような人工データによる学習みたいな問題設定が先に出てきたり、多く出てくるのでちょっと困惑した。という意見
- いや、前者もあくまで一般的な機械学習の話で、十分大きな母集団からミニバッチを組む事を指しているのではないのか。という意見
- 一般的な観測データからの機械学習は後者であることが多いが、教科書では前者のような人工データによる学習みたいな問題設定が先に出てきたり、多く出てくるのでちょっと困惑した。という意見
個人的な気づきなど
- 初見でピンと来なかった、問題アンサンブルの考え方が、皆との議論の中でよく理解できるようになったのが嬉しかった。
プログラムでの理解
問題設定
-
$f (\bm{x})= \bm{x^{\top}Ax}$という二次形式の関数に対して最小値を探す制約なし連続最適化問題を勾配法を使って解く
- 勾配法の更新則は$\bm{x}_{new}\gets\bm{x}_{old} - \eta\nabla_{\bm{x}}f|_{\bm{x} = \bm{x}_{old}}$
- $\nabla_{\bm{x}}f = 2\bm{Ax}$
- 深層展開版では、$\eta$を学習パラメータとして取り扱う
- 勾配法の更新則は$\bm{x}_{new}\gets\bm{x}_{old} - \eta\nabla_{\bm{x}}f|_{\bm{x} = \bm{x}_{old}}$
-
正直勾配法をわざわざ使う必要のない問題だが、深層展開の例を示すのに使われたという認識
- この場合、$\bm{A}$が正定値なら$\bm{x}= \bm{0}$で最小値0である
-
また、$\eta$は少数個用意して、ステップ毎に順繰りで使っていく(教科書で学習パラメータの周期条件と呼ばれているもの)
- 下の実装では用意する個数が
Tとなっている
- 下の実装では用意する個数が
Pythonで実装
必要ライブラリインポート
import numpy as np
import jax
import jax.numpy as jnp
from jax.example_libraries import optimizers
from tqdm.notebook import trange
from functools import partial
グローバル変数設定
n = 100
K = 50
A = np.diag(np.arange(1,100+1))
A = jnp.array(A)
- $\bm{A}$には対角成分が$1,2,\dots,100$となっている正定値対角行列をあてる
反復関数の定義
@partial(jax.jit, static_argnums=0)
def DU_GD(max_itr, x0, eta, T):
x = x0
for i in range(max_itr):
k = (i % T)
x -= eta[k] * A @ x
return x
- for文の繰り返し回数など、引数によって内部処理が大きく変わる場合、jit化できない事があり、そういう際に、その変数を除いてjit化するために
partialデコレータを使っている-
static_argnumsで定数扱いする引数が何番目の引数なのかを指定している
-
ステップサイズ学習のための損失関数の定義
@jax.jit
def get_dot(x):
return x @ x.T
batch_get_dot = jax.vmap(get_dot, in_axes=-1, out_axes=-1)
@partial(jax.jit, static_argnums=0)
def loss(max_itr, x0, T, eta):
x_hat = DU_GD(max_itr, x0, eta, T)
return jnp.sum(batch_get_dot(x_hat))/K
- 損失関数は$\bm{x}$のノルム(のバッチ平均)とする。はじめはこれが、原点が解だと知っている前提の実装になっているという意味で気持ち悪かったのだが、ここでは、あくまで問題インスタンスの解については既知という前提の例になっていると、読み会を経て理解した。
-
ちなみに、サンプルコードはバッチ行列のフロベニウスノルムをとっているように感じたがここでは明確にベクトルノルム計算している(サンプルコードに対するその理解が間違っているのか、あってて数学的にはそれで良いのか、その辺分かる人が居たら教えてほしい。。。)->サンプルコードの実装で問題ないことを確認した。jax.numpyではjax.numpy.linalg.norm()を使って同様の計算が行える。-
jax.vmapは任意の関数をバッチ化する関数- ここでは、元々、”入力:ベクトルで出力:スカラ”だったものが、
jax.vmapによって”入力:行列で出力:ベクトル”と高次元化されている - バッチの次元をどこに挿し込むは引数(in_axes=-1, out_axes=-1)で一番後ろに設定している
- ここでは、元々、”入力:ベクトルで出力:スカラ”だったものが、
-
学習
max_inner = 20
train_itr = 25
num_itr = 30
adam_lr = 1e-3
opt_init, opt_update, get_params = optimizers.adam(adam_lr)
@partial(jax.jit, static_argnums=0)
def step(max_itr, x0, T, step, opt_state):
value, grads = jax.value_and_grad(loss, argnums=-1)(max_itr, x0, T, get_params(opt_state))
new_opt_state = opt_update(step, grads, opt_state)
return value, new_opt_state
def train(eta, T, train_itr):
opt_state = opt_init(eta)
rng = jax.random.PRNGKey(11)
for itr in trange(train_itr, leave=False):
for i in range(max_inner):
rng, subkey = jax.random.split(rng, num=2)
x0 = jax.random.normal(subkey, (n, K))
value, opt_state = step(itr+1, x0, T, i, opt_state)
print("\r"+"\rloss:{}".format(value), end=" ")
return get_params(opt_state)
T = 3
eta_init = jnp.zeros(num_itr)
eta_trained = train(eta_init, T, train_itr)
- 基本的には前回と同じような流れ
- 複数のループが回っているが、以下のようなしくみ
-
train_itrは任意の打ち切り数(学習回数)であり、あるタイミングの学習回数itrはインクリメンタル学習で増やしていく数の現在値として使われる -
max_innerはインクリメンタル学習の内部反復数- 一回のインクリメンタル学習中に複数回学習ステップを踏むのが常套手段らしいが、その回数はハイパーパラメータっぽい
- このとき一回の学習毎に$\bm{x}$の初期値を乱数で引き直すことで、$\eta$の汎化性を上げていると思われる
-
-
num_itrは学習後の評価時に勾配法で下っていく回数にあたる
結果
-
ステップサイズを$\frac{2}{\lambda_{max}+\lambda_{min}}$とした勾配法との比較を示す($\lambda_{max},\lambda_{min}$は$\bm{A}$の最大固有値と最小固有値)
-
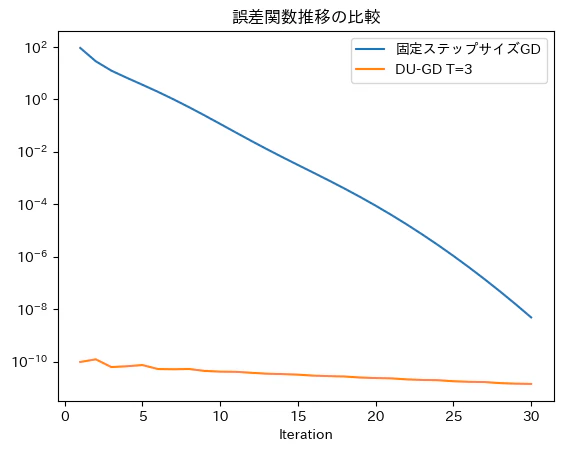
- 深層展開で獲得したステップサイズを用いた方が、収束が速いことが見て取れる(というか、一回目のステップでだいぶ最適値に近づく)
- (比較対象側の実装は全文のほうを参照)
- 深層展開で獲得したステップサイズを用いた方が、収束が速いことが見て取れる(というか、一回目のステップでだいぶ最適値に近づく)
-
-
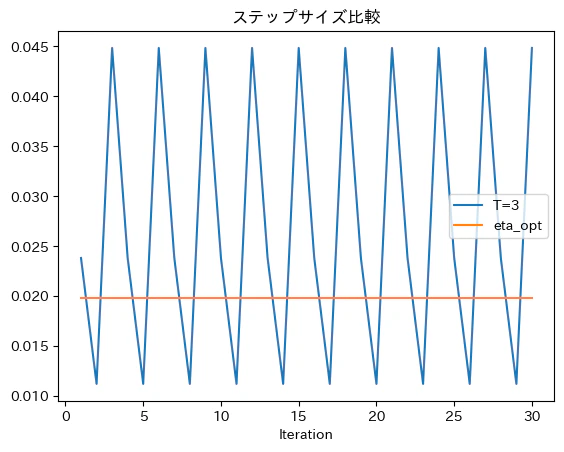
学習で獲得した$\eta$は、各勾配法のステップに対して、以下のようになった(教科書とだいたい同じ結果が確認できた)
その他
- 今回、結構議論が白熱したりして、進度は牛歩気味^^;
- まあ、議論が活発に交わされる事は望む所であるし、進行を急ぐ理由はないのでじっくりやっていきたいが、無駄に間延びすることは無いようにファシリテーションできるようには心がけたい
バックナンバー
- 『モデルベース深層学習と深層展開』読み会 レポート(開催前準備編)
- 『モデルベース深層学習と深層展開』読み会レポート#0
- 『モデルベース深層学習と深層展開』読み会レポート#1
- 『モデルベース深層学習と深層展開』読み会レポート#2