$\def\bm{\boldsymbol}$
概要
- オンラインで開催している『モデルベース深層学習と深層展開』読み会で得られた知見や気づきをメモしていく
- ついでに、中身の理解がてらJuliaサンプルコードをPythonに書き直したコードを晒していく
- 自動微分ライブラリにはJAXを使用する
第2回
大まかな内容
- 学習可能モジュールの”学習”の概念を具体例で理解
- 放射基底関数を用いた例
- 三層ニューラルネットワークの例
- フレームワークを用いた実装について
議論になったこと
2.4.4節 あたり
- Juliaの
do...end構文って他に書き方ないのか- ->アロー演算子ぽいのを使って書く方法があるっぽい(↓例)
gs = Flux.gradient(()->f(x), ps)
- ->アロー演算子ぽいのを使って書く方法があるっぽい(↓例)
2.5.1節 あたり
- NN以外の関数近似器(RBFを使った方法)はこの後の節で出てこないが、ここで紹介した意図は?
- ->回帰モデルの学習のチュートリアル的な意味で説明したのではないか
- ->基底関数を使った近似も特定の条件下では有用説
- 解析対象からして、基底が決められる場合(逆にNNはその辺わかんなくてもテキトーに学習できる)
- 勾配使った繰り返し計算に頼らずに、基底の直交性を使って解析的に解を出せる場合がある(最小二乗法的な)
- いずれにせよ、ニューラルネットとRBFの性能や性質の比較をもうちょいやってくれてたら嬉しかった…
2.5.2節 あたり
- $g$の定義域を連結コンパクト集合に限定している意図は?
- ->NNの万能近似性を担保するための条件を与えているのでは
- 近似対象$f(x)$を有界閉集合(コンパクト集合)にしておきたい(それ以外の集合の近似は考えたくない)
- 近似関数$g(x)$もコンパクト集合の範囲内で考える
- $g$が連続関数で定義域がコンパクトなら$g(x)$もコンパクト
- ->NNの万能近似性を担保するための条件を与えているのでは
個人的な気づきなど
- 万能近似器が近似出来る集合空間の範囲みたいなことはあんまり考えた事なかったので興味深かった。
- 集合と位相をもうちょっとちゃんと勉強したほうがいいかも…
プログラムでの理解
問題設定
- 2章のサンプルコードはいくつかあるが、ここでは代表して回帰問題の例を扱う(その他の例もこの辺に上げている)
- 回帰対象式
- $f(x) \equiv 5\exp(-2x)+\frac{3}{2}$
- 回帰モデル
- $g(x) = p_1 \exp(-p_2 x)+ p_3$
- $p_1, p_2, p_3$が学習パラメータ
- $g(x) = p_1 \exp(-p_2 x)+ p_3$
Pythonで実装
必要ライブラリインポート
- OptimizerはOptaxなどの外部ライブラリも使えるが、ここではJAX内部に実装されているものを使う
import numpy as np
import jax
import jax.numpy as jnp
from jax.example_libraries import optimizers
教師データのサンプリング
- 真の関数にガウスノイズを混ぜてサンプリングする
#回帰対象
def f(x):
return 5 * np.exp(-2*x) + 1.5
#サンプリング用入力
start = 0
step_length = 0.1
limit = 1.0
num = limit/step_length + 1
xs = start + np.arange(num) * step_length
std = 0.5 #ノイズ
Y = [f(x) + std * np.random.normal() for x in xs] #サンプリング
xs = jnp.array(xs)
Y = jnp.array(Y)
回帰モデルと誤差関数
- 誤差関数は、後で勾配をとる変数を引数とする形で定義しておく
#回帰モデル 3パラメータ
def g(x, p):
return p[0] * jnp.exp(-1.0*p[1]*x) + p[2]
#誤差関数 (二乗誤差)
def loss(x, y, p):
return (g(x, p) - y)**2
学習
#Adamオプティマイザを利用(引数は初期学習率)
opt_init, opt_update, get_params = optimizers.adam(1.0)
@jax.jit
def step(x, y, step, opt_state):
value, grads = jax.value_and_grad(loss, argnums=-1)(x, y, get_params(opt_state))
new_opt_state = opt_update(step, grads, opt_state)
return value, new_opt_state
def train(X, Y, p, max_itr):
opt_state = opt_init(p)
loss_log = []
for _ in range(max_itr):
for i, (x, y) in enumerate(zip(X,Y)):
value, opt_state = step(x, y, i, opt_state)
loss_log.append(value)
return loss_log, get_params(opt_state)
max_itr = 20
p = jnp.ones(3)
loss_log, p = train(xs, Y, p, max_itr)
-
@jax.jitはjust in timeコンパイラのデコレータ- このデコレータがついた関数は最初の実行時にコンパイルされ、2度目移行の実行は高速で行える
-
jax.value_and_gradで勾配(と誤差関数値)を計算して、一回分パラメータを更新する関数stepを定義して、train関数ではそれを学習回数分呼ぶというカタチで実装している
結果
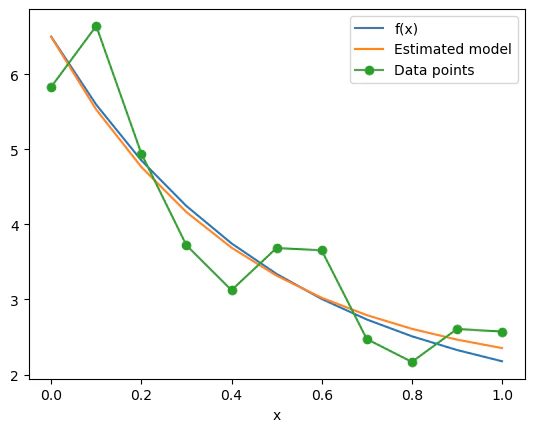
学習後のパラメータを使って、回帰関数をプロットすると以下のように、元の関数$f(x)$をよく近似できていることが分かる。
その他
- 特になし