主題のご質問をいただきました。
こんな感じの環境です。
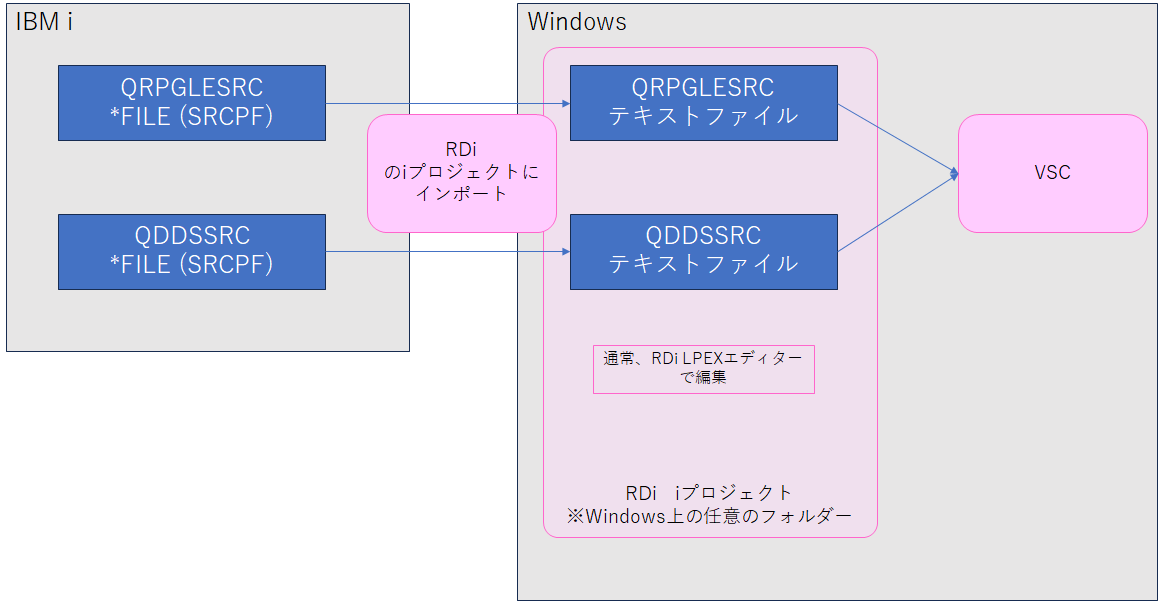
概要は、
・元のソースはIBM i 上のソース物理ファイル(SRCPF)
・ソース物理ファイルをRDiのiプロジェクトにインポートすると、Windowsローカルにソース物理ファイルがテキストファイルとしてインポートされます。
・RDiでインポートされたテキストファイル※1をVSCodeで開くと日本語が文字化けする、というものです。
※1 今回の例ではILE-RPGのソース、DDSソース(Db2 for i のテーブル定義=SQL DDLと同様なもの)
※1 補足すると、IBM i 上のソース物理ファイルの中には複数のプログラム、複数のデータベーステーブルのソースが含まれています(それぞれのソースをメンバーと呼びます)。(IBM i のファイル=オブジェクト管理としては複数ソースをまとめて1ソース物理ファイルとして管理されているが、)iプロジェクトにインポートすると、1メンバーのソースごとに1つのテキストファイルとしてインポートされます。
VSCodeで開いた時の文字化け
上図のWindowsにインポートされたテキストファイルのソースをVSCodeで開くと以下のようになりました。
例1) QRPGLESRC.K201R (ILE-RPGソース)
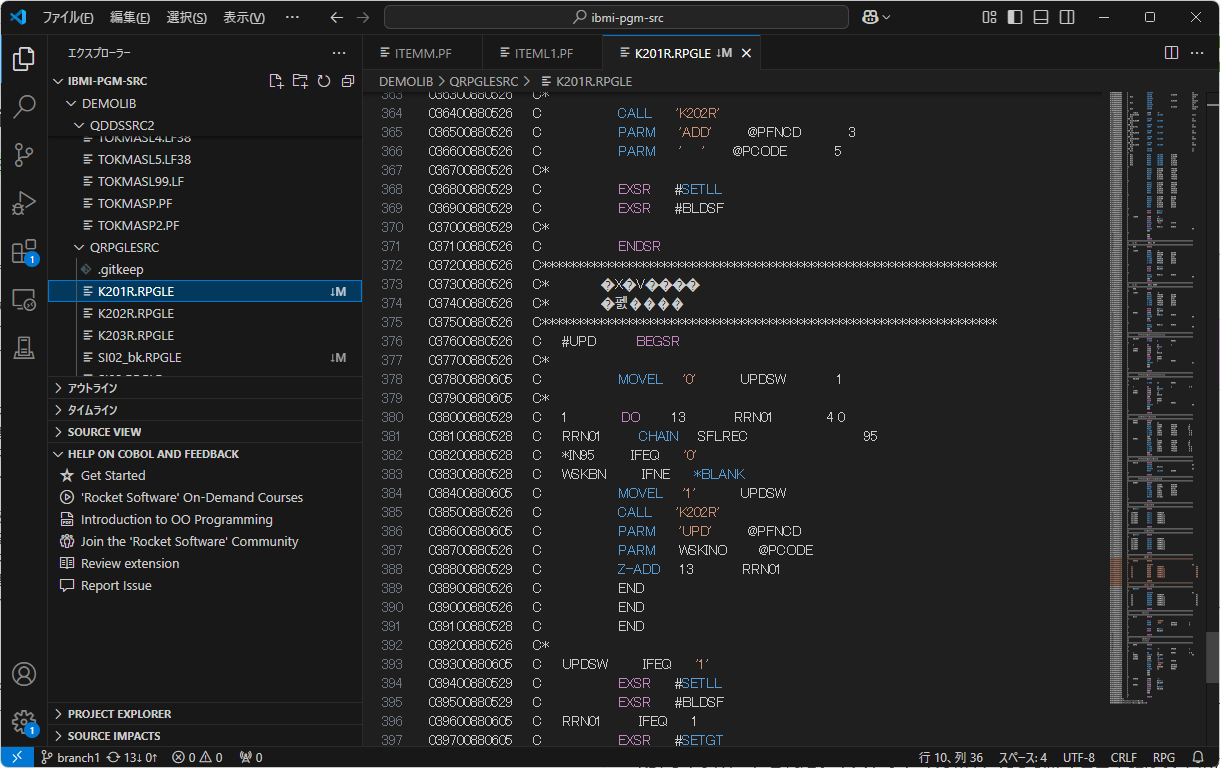
例2) QDDSSRC.ITEMM
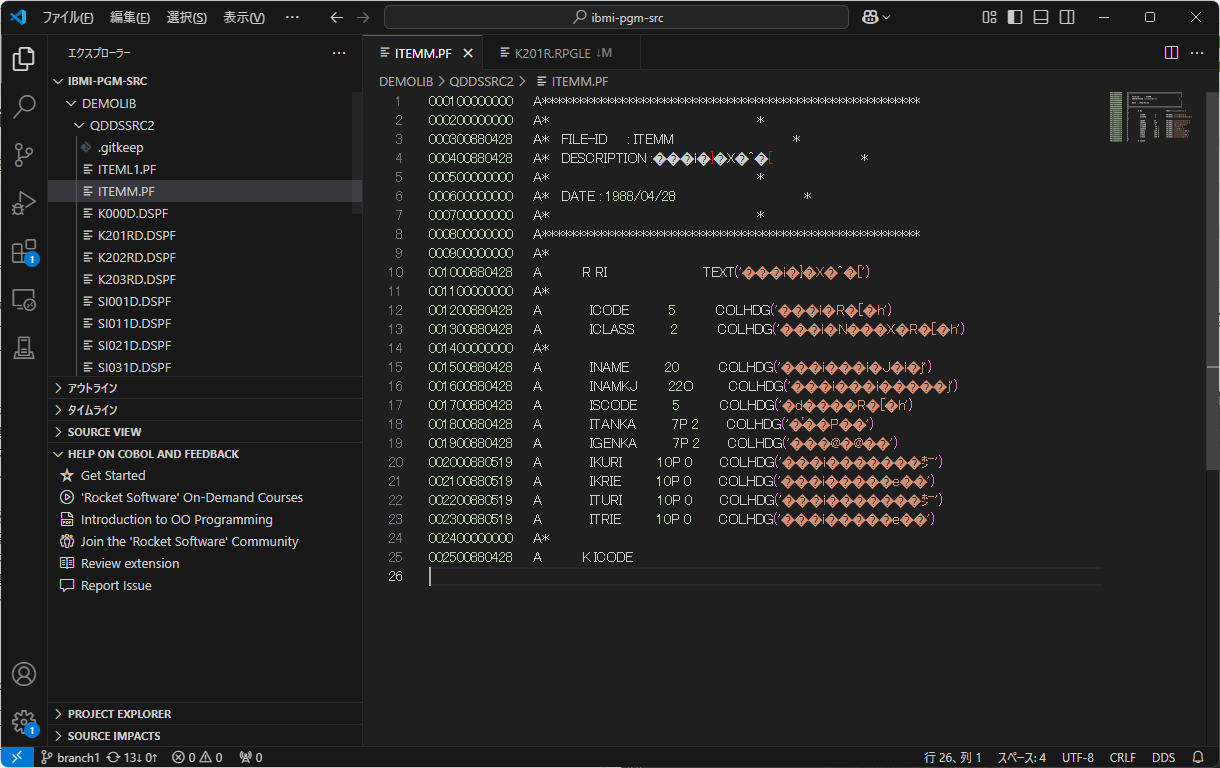
文字化けの原因
VSCodeで開いた際、エンコードがUTF-8になるのですが、RDi iプロジェクトでインポートされた際のテキストファイルはS-JISでエンコードされていました。大元のIBM i 上のソース物理ファイルのCCSID(文字属性)がEBCDIC(CCSID(5035))だったためと思われます。
(テストしていませんが、元のソース物理ファイルの属性がCCSID(1208) UTF-8ならRDi iプロジェクトでインポート時もUTF-8エンコードでインポートされるのではないでしょうか。)
文字化けの回避方法① 都度設定設定変更
ということで、VSCodeの画面右下部のこちら

を見ると、UTF-8エンコードと分かりますので、UTF-8のところをクリックすると、下記のパネルが表示されるので、エンコード付きで再度開く を選択して、、
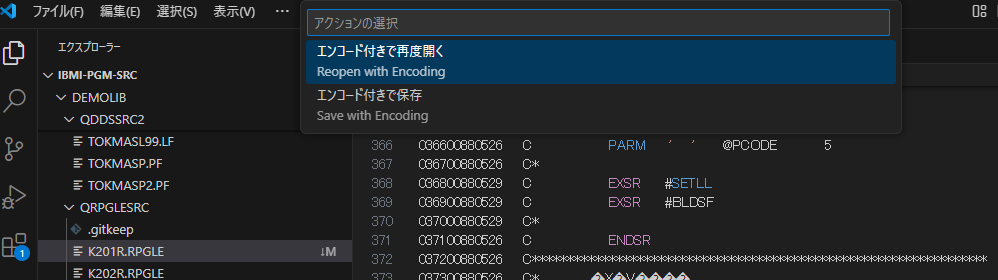
Japanese(Shift-jis) を選択します。

すると、以下のように文字化けが解消されました。
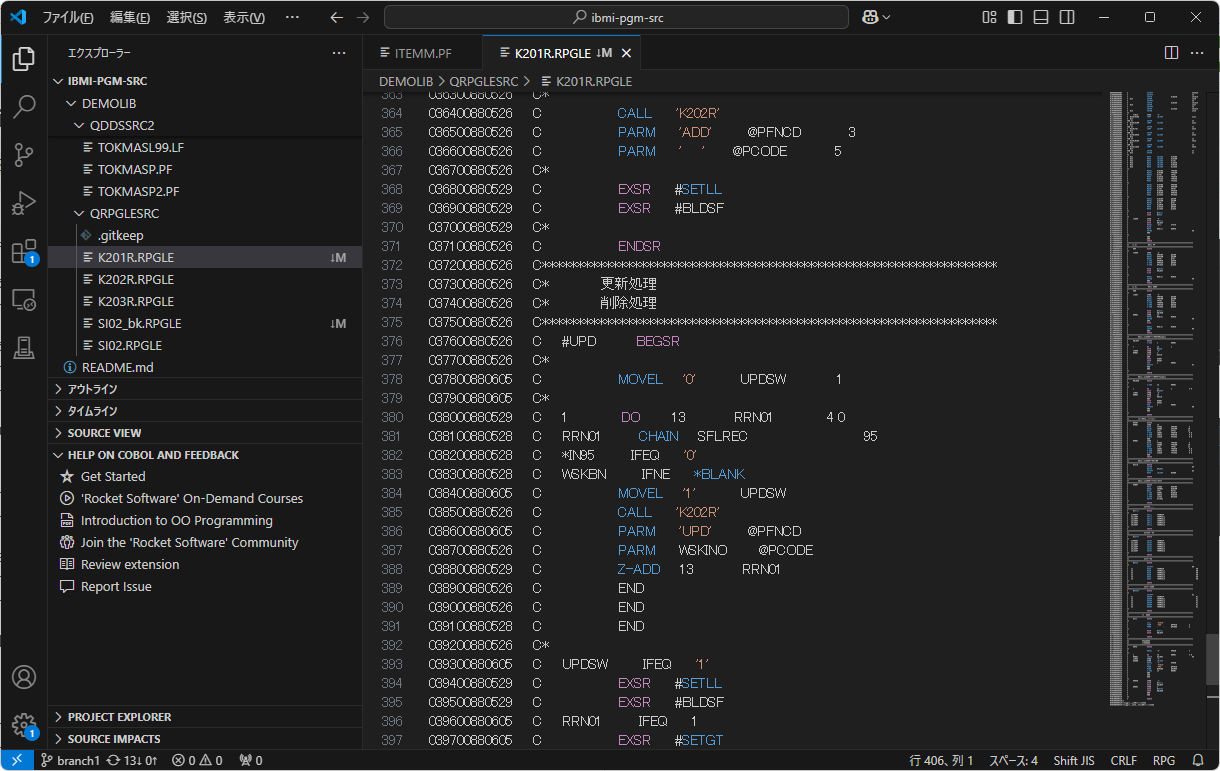
画面、最下部のエンコードで確認できます。

DDSSRC(Db2 for i テーブル定義)もOKでした。
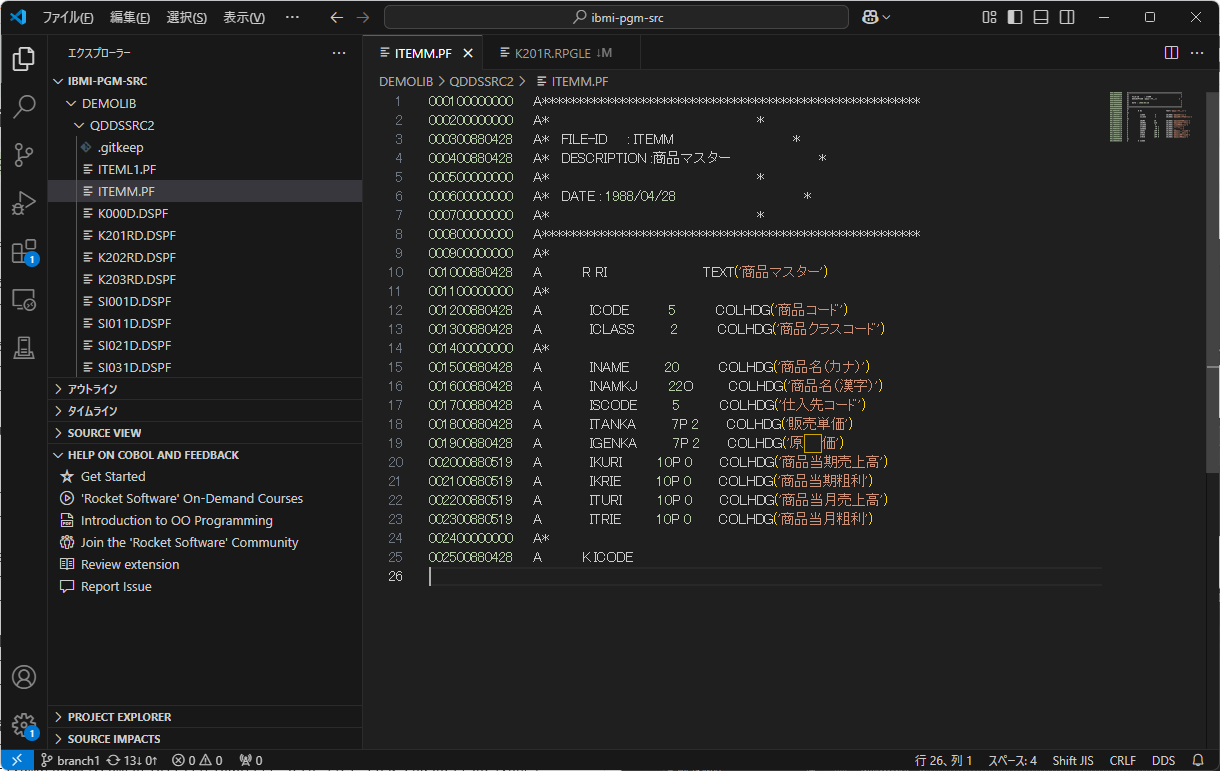
ん?これ(原価の間の□)は?

RDi LPEXエディターで開くと
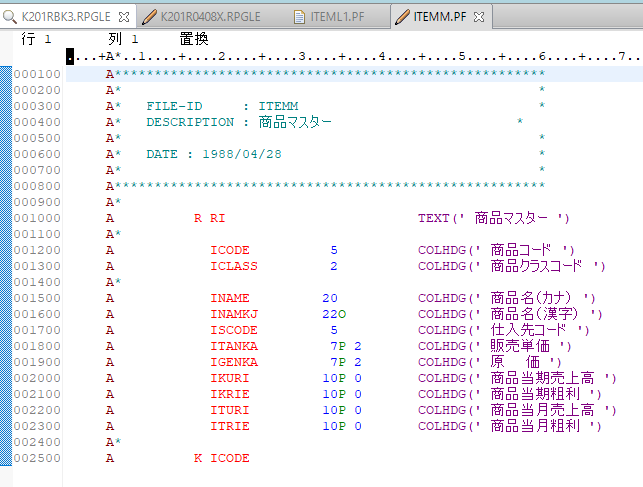
ふむ。
では、5250 SEUで見ると、
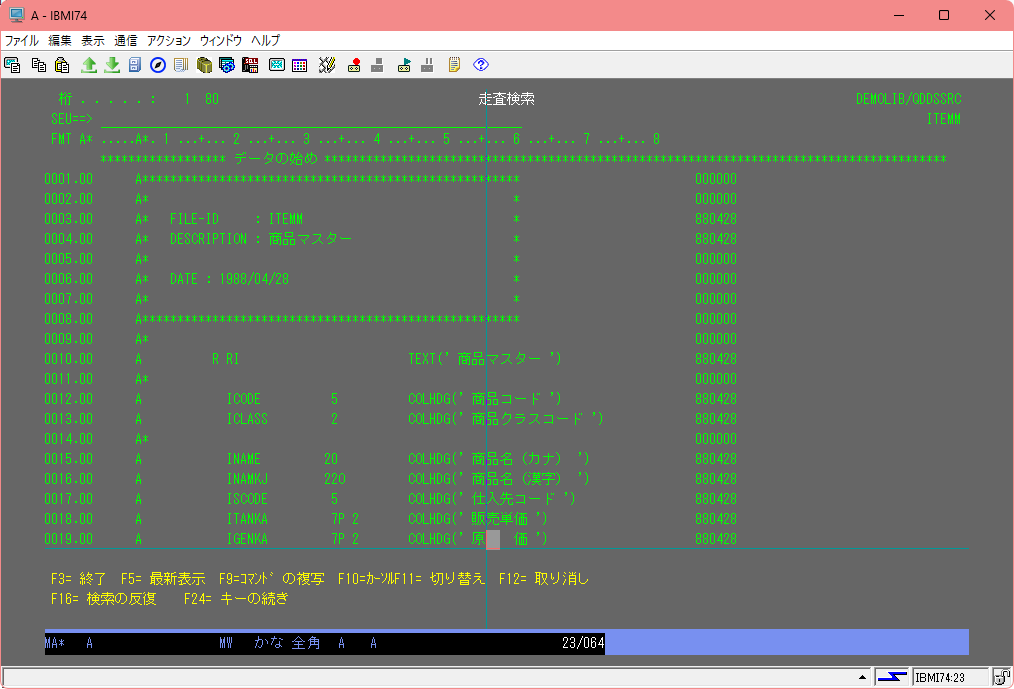
全角ブランクが2つ入っているものでした。
RDi LPEXエディターでも全角ブランク2つ、VSCodeでも全角ブランク2つを表示していましたので文字化けでは無いようです。
回避方法その2 files.autoGuessEncoding を設定する
guriguriさん提供w
VSCode に自動判別させる (files.autoGuessEncoding) のでは駄目でしょうか?
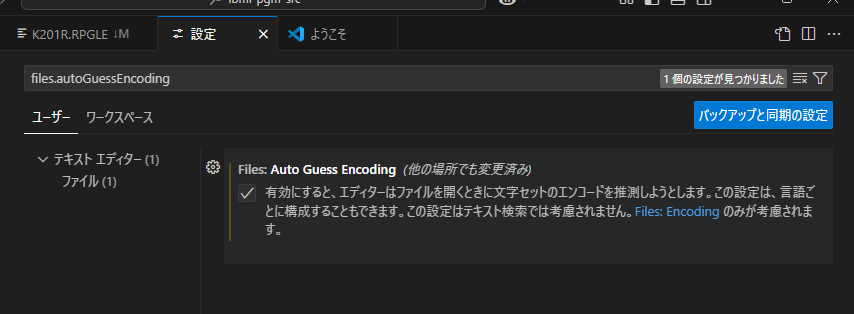
できました!
回避方法その3 RDi iプロジェクトでインポートする際の属性を変更してみる。
こちらもGURIGURIさんにサジェッション頂いた件です。
RDi の eclipse.ini で「 -Dfile.encoding=UTF-8 」を指定する、というのでは駄目でしょうか?
長くなったので別記事にしました。
結果だけ書くとVSCodeで開いた際UTF-8エンコードで文字化けなく開く事ができました。(ただし、現時点でRDi LPEXエディターで開いた際不具合あり・・)