RのRMeCab、igraphの共起ネットワークで文字化け
解決したいこと
テキストマイニングで共起ネットワークを作成するために、Macで、RのRMeCabパッケージ、igraphパッケージを用いて、
NgramDF、graph.data.frame,plot関数を使ったのですが、文字化けしてしまいます。
par(family="HiraKakuProN-W3") や@purple_jpさんの.Rprofileを試しても解決しませんでした。
発生している問題・エラー
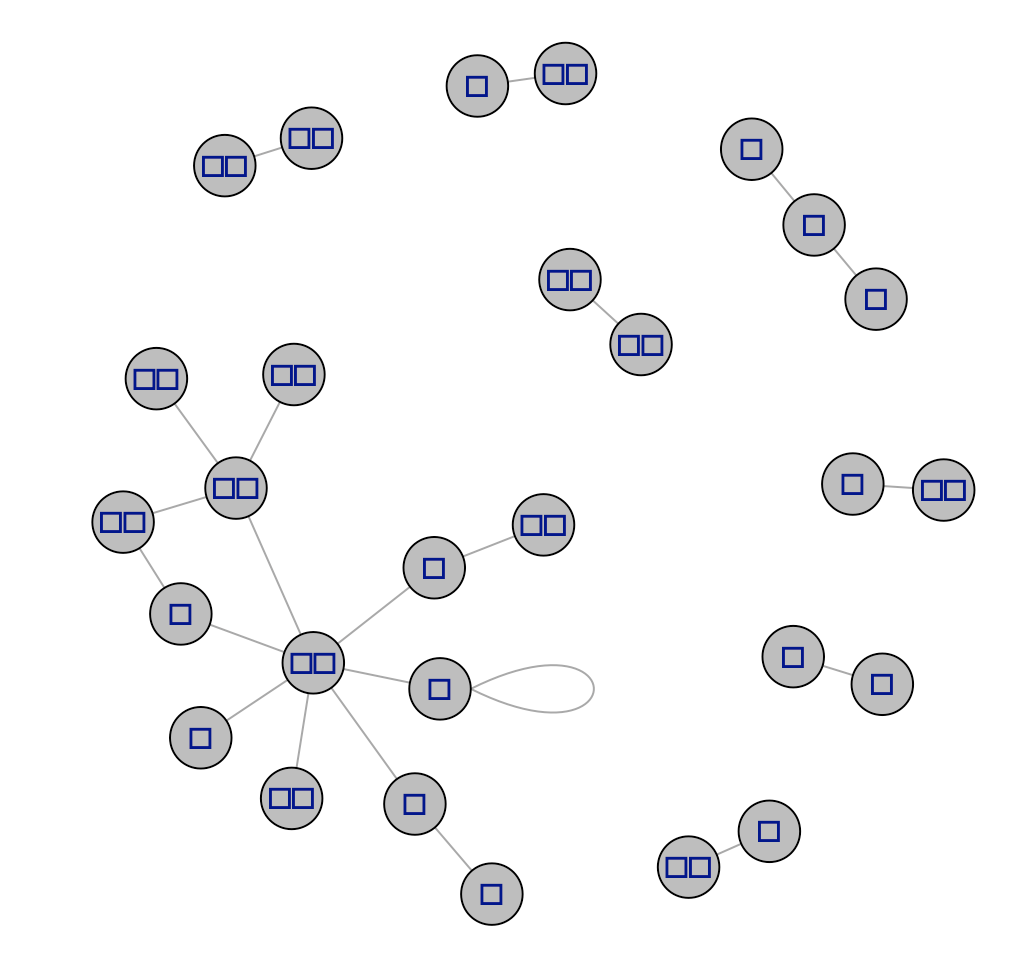
該当するソースコード
library(RMeCab) #インストール済み
library(igraph) #インストール済み
NgramDF.result <- NgramDF(file.choose(), type=1, N=2, pos ="名詞")
g <- graph.data.frame(NgramDF.result.2, directed = FALSE)
plot(g, vertex.label = V(g)$name, vertex.color="grey", family="HiraKakuProN-W3")
自分で試したこと
1)パッケージのアンインストールと再インストール
2)par(family="HiraKakuProN-W3")
3)@purple_jpさんの記事の.Rprofile
4)共起頻度のハードルを高めて、ノード数を減らす
関連情報
> version
_
platform x86_64-apple-darwin17.0
arch x86_64
os darwin17.0
system x86_64, darwin17.0
status
major 4
minor 0.3
year 2020
month 10
day 10
svn rev 79318
language R
version.string R version 4.0.3 (2020-10-10)
nickname Bunny-Wunnies Freak Out
ご助言お願いいたします!
0 likes